C++11学习
C++11学习
本章目的:
当Android用ART虚拟机替代Dalvik的时候,为了表示和Dalvik彻底划清界限的决心,Google连ART虚拟机的实现代码都切换到了C++11。C+11的标准规范于2011年2月正式落稿,而此前10余年间,C++正式标准一直是C++98/03[①]。相比C++98/03,C++11有了非常多的变化,甚至一度让笔者大呼不认识C++了[②]。不过,作为科技行业的从业者,我们要铭记在心的一个铁规就是要拥抱变化。既然我们不认识C++11,那就把它当做一门全新的语言来学习吧。
写在开头的话
从2007年到2010年,在我参加工作的头三年中,笔者一直使用C++作为唯一的开发语言,写过十几万行的代码。从2010年转向Android开发后,我才正式接触Java。此后很多年里,我曾经多次比较过两种语言,有了一些很直观,很感性的看法。此处和大家分享,读者不妨一看:
对于业务系统[③]的开发而言,Java相比C++而言,开发确实方便太多。比如:
- Java天生就是跨平台的。开发者无需考虑操作系统,硬件平台的差异。而C++开发则高度依赖于操作系统以及硬件平台。比如Windows的C++程序到Linux平台上几乎都无法直接使用。这其中的问题倒也不能全赖在C++语言本身上。只是选择一门开发语言不仅仅是选择语言本身,其背后的生态系统(OS,硬件平台,公共类库,开发资源,文档等)随之也被选择。
- 开发者无需考虑内存管理。虽然Java也有内存泄露之说,但至少在开发过程中,开发者不用斤斤计较于C++编程中必须要时刻考虑的“内存是否会泄露”,“对象被delete后是否会导致其他使用者操作无效内存地址”等问题。
- 最后也是最重要的一点,Java有非常丰富的类库,诸如网络操作类,容器类,并发类,XML解析类等等等等。正是有了这些丰富的类库,才使得业务系统开发者能聚焦在如何利用这些现成的工具、类库来开发自己的业务系统,而不是从头到脚得重复制造车轮。比如,当年我在Windows搞一套C++封装的多线程工具类,之后移植到Linux上又得搞一套,而且还要花很多精力维护它们。
个人感受:
我个人对C++是没有任何偏好的。之所以用C++,很大程度上是因为直接领导的选择。作为一个工作多年的老员工,在他印象里,那个年代的Java性能很差,比不得C++的灵巧和高效。另外,由于我们做得是高性能视音频数据网络传输(在局域网/广域网,几个GB的视音频文件类似FTP这样的上传下载),C++貌似是当时唯一能同时和“面向对象”,“性能不错”挂上钩的语言了。
在研究ART的时候,笔者发现其源码是用一种和我以前熟悉得C++差别很大的C++语言编写得,这种差别甚至一度让我感叹“不太认识C++语言了”。后来,我才了解到这种“全新的”C++就是C++11。当时我就在想,包括我自己在内,以及本书的读者们要不要学习它呢?思来覆去,我觉得还是有这个必要:
- 从Android 6.0源码来看,native模块改用C++11来编写已成趋势。所以我们需要尽快了解C++11,为将来的学习和工作做准备。
- 既然C++之父都说“C++11看起来像一门新的语言[6]”,那么我们完全可以把它当做一门新的语言来学习,而不用考虑是否有过C/C++基础的问题。这给了我们一个很好的学习机会。
既然下定决心,那么就马上开始学习。正式介绍C++11前,笔者要特别强调以下几点注意事项:
- 编程语言学习,以实用为主。所以本章所介绍的C++11内容,一切以看懂ART源码为最高目标。源码中没有涉及的C++11知识,本章尽量不予介绍。一些细枝末节,或者高深精尖的用法,笔者也不拟详述。如果读者想深入研究,不妨阅读本章参考文献所列出的六本C++专著。
- 学习是一个循序渐进的过程。对于初学者而言,应首先以看懂C++11代码为主,然后才能尝试模仿着写,直到完全自己写。用C++写程序,会碰到很多所谓的“坑”,只有亲历并吃过亏之后,才能深刻掌握这门语言。所以,如果读者想真正学好C++,那么一定要多写代码,不能停留在看懂代码的水平上。
注意:
最后,本章不是专门来讨论C++语法的,它更大的作用在于帮助读者更快得了解C++。故笔者会尝试采用一些通俗的语言来介绍它。因此,本章在关于C++语法描述的精准性上必然会有所不足。在此,笔者一方面请读者谅解,另一方面请读者及时反馈所发现的问题。
下面,笔者将正式介绍C++11,本章拟讲解如下内容:
- 数据类型
- C++源码构成及编译
- Class
- 操作符重载
- 函数模板与类模板
- lambda表达式
- STL介绍
- 其他一些常用知识点
1.1 数据类型
学习一门语言,首先从它定义的数据类型开始。本节先介绍C++基本内置的数据类型。
1.1.1 基本内置数据类型介绍
图1所示为C++中的基本内置数据类型(注意,图中没有包含所有的内置数据类型):

图1 C++基本数据类型
图1展示了C++语言中几种常用的基本数据类型。有几点请读者注意:
- 由于C++和硬件平台关联较大,规范没办法像Java那样严格规定每种数据类型所需的字节数,所以它只定义了每种数据类型最少需要多少字节。比如,规范要求一个int型整数至少占据2个字节(不过,绝大部分情况下一个int整数将占据4个字节)。
- C++定义了sizeof操作符,通过这个操作符可以得到每种数据类型(或某个变量)占据的字节个数。
- 对于浮点数,规范只要求最小的有效数字个数。对于单精度浮点数float而言,要求最少支持6个有效数字。对于双精度浮点数double类型而言,要求最少支持10个有效数字。
注意:
本章中,笔者可能会经常拿Java语言做对比。因为了解语言之间的差异更有助于快速掌握一门新的语言。
和Java不同的是,C++中的数据类型分无符号和有符号两种,比如:

图2 无符号数据类型定义
注意,无符号类型的关键词为unsigned。
1.1.2 指针、引用和void类型
现在来看C++里另外三种常用的数据类型:指针、引用和void,如图3所示:
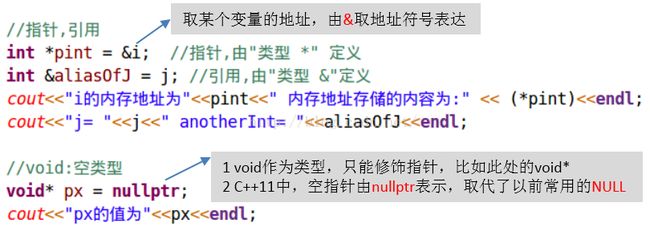
图3 指针、引用和void
由图3可知:
- 指针类型的书写格式为T *,其中T为某种数据类型。
- 引用类型的书写格式为T &,其中T为某种数据类型。
- void代表空类型,也就是无类型。这种类型只能用于定义指针变量,比如void*。当我们确实不关注内存中存储的数据到底是什么类型的话,就可以定义一个void*类型的指针来指向这块内存。
- C++11开始,空指针由新关键字nullptr[④]表示,类似于Java中的null。
下面我们着重介绍一下指针和引用。先来看指针:
1. 指针
关于指针,读者只需要掌握三个基本知识点就可以了:
- 指针的类型。
- 指针的赋值。
- 指针的解引用。
(1) 指针的类型
指针本质上代表了虚拟内存的地址。简单点说,指针就是内存地址。比如,在32位系统上,一个进程的虚拟地址空间为4G,虚拟内存地址从0x0到0xFFFFFFFF,这个段中的任何一个值都是内存地址。
一个程序运行时,其虚拟内存中会有什么呢?肯定有数据和代码。假设某个指针指向一块内存,该内存存储的是数据,C++中数据都得有数据类型。所以,指向这块内存的指针也应该有类型。比如:
² int* p,变量p是一个指针,它指向的内存存储了一个(对于数组而言,就是一组)int型数据。
² short* p,变量p指向的内存存储了一个(或一组)short型数据。
如果指针对应的内存中存储的是代码的话,那么指向这块代码入口地址(代码往往是封装在函数里的,代码的入口就是函数的入口)的指针就叫函数指针。函数指针的定义看起来有些古怪,如图4所示:

图4 函数指针定义示例
提示:
函数指针的定义语法看起来比较奇特,笔者也是实践了很多次才了解它。
(2) 指针的赋值
定义指针变量后,下一个要考虑的问题就是给它赋什么值。来看图5:

图5 指针变量的赋值
结合图5可知,指针变量的赋值有几种形式:
- 直接将一个固定的值(比如0x123456)作为地址赋给指针变量。这种做法很危险。除非明确知道这块内存的作用以及所存储的内容,否则不能使用这种方法。
- 通过new操作符在堆上分配一块内存,该内存的地址存储在对应的指针变量中。
- 通过取地址符&对获取某个变量或者函数的地址。
注意
函数指针变量的赋值也可以直接使用目标函数名,也可使用取地址符&。二者效果一致
(3) 指针的解引用
指针只是代表内存的某个地址,如何获取该地址对应内存中的内容呢?C++提供了解指针引用符号*来帮助大家,如图6所示:

图6 指针解引用
图6中:
- 对于数据类型的指针,解引用意味着获取对应地址中内存的内容。
- 对于函数指针,解引用意味着调用这个函数。
讨论:
为什么C/C++中会有指针呢?因为C和C++语言作为系统编程(System Programming)语言,出于运行效率的考虑,它提供了指针这样的机制让程序员能够直接操作内存。当然,这种做法的利弊已经讨论了几十年,其主要坏处就在于大部分程序员管不好内存,导致经常出现内存泄露,访问异常内存地址等各种问题。
2. 引用
相比C,引用是C++特有的一个概念。我们来看图7,它展示了指针和引用的区别:

图7 引用的用法示例(1)

图7 引用的用法示例(2)
由图7可知:
- 引用只是变量的别名。由于是别名,所以C++要求在定义引用型变量时就必须将它和实际变量绑定。
- 引用型变量绑定实际变量之后,这两个变量(原变量和它的引用变量)其实就代表同一个东西了。图7中(1)以鲁迅为例,“鲁迅”和“周树人”都是同一个人。
C语言中没有引用,一样工作得很好。那么C++引入引用的目的是什么呢[⑤]?
- 既然是别名,那么给原变量换一个更动听的名字可能是一个作用。
- 比较图7中(2)的changeRef和changeNoRef可知,当函数的形参为引用时,函数内部对该形参的修改就是对实参的修改。再次强调,对于引用类型的形参而言,函数调用时,形参就变成了实参的别名。
- 比较图7中(2)的changeRef和changePointers可知,指针型变量书写起来需要使用解地址引用*符号,不太方便。
- 引用和原变量是一对一的强关系,而指针则可以任意赋值,甚至还可以通过类型转换变成别的类型的指针。在实际编码过程中,一对一的强关系能减少一些错误的发生。
和Java比较
和Java语言比起来,如果Java中函数的形参是基础类型(如int,long之类的),则这个形参是传值的,与图7中的changeNoRef类似。如果这个函数的形参是类类型,则该形参类似于图7中的changeRef。在函数内部修改形参的数据,实参的数据相应会被修改。
1.1.3 字符和字符串
图8所示为字符和字符串的示例:

图8 字符和字符串示例
请读者注意图8中的Raw字符串定义的格式,它的标准格式为R"附加界定符(字符串)附加界定符"。附加界定符可以没有。而笔者设置图8中的附加界定符为"**123"。
Raw字符串是C++11引入的,它是为了解决正则表达式里那些烦人的转义字符\而提供的解决方法。来看看C++之父给出的一个例子,有这样一个正则表达式('(?:[ˆ\\']|\\.)∗'|"(?:[ˆ\\"]|\\.)∗")|)
- 在C++中,如果使用转义字符串来表达,则变成('(?:[ˆ\\\\']|\\\\.)∗'|\"(?:[ˆ\\\\\"]|\\\\.)∗\")|。使用转义字符后,整个字符串变得很难看懂了。
- ²如果使用Raw字符串,改成R"dfp(('(?:[ˆ\\']|\\.)∗'|"(?:[ˆ\\"]|\\.)∗")|)dfp"即可。此处使用的界定字符为"dfp"。
很显然,使用Raw字符串使得代码看起来更清爽,出错的可能性也降低很多。
1.1.4 数组
直接来看关于数组的一个示例,如图9所示:

图9 数组示例
由图9可知:
- 定义数组的语法格式为T name[数组大小]。数组大小可以在编译时由初值列表的个数决定,也可以是一个常量。总之,这种类型的数组,其数组大小必须在编译时决定。
- 动态数组由new的方式在运行时创建。动态数组在定义的时候就可以通过{}来赋初值。程序中,代表动态数组的是一个对应类型的指针变量。所以,动态数组和指针变量有着天然的关系。
和Java比较
Java中,数组的定义方式是T[]name。笔者觉得这种书写方式比C++的书写方式要形象一些。
另外,Java中的数组都是动态数组。
了解完数据类型后,我们来看看C++中源码构成及编译相关的知识。
1.2 C++源码构成及编译
源码构成是指如何组织、管理和编译源码文件。作为对比,我们先来看Java是怎么处理的:
- Java中,代码只能书写在以.java为后缀的源文件中。
- Java中,每一个Java源文件必须包含一个和文件同名的class。比如A.java必须定义公开的class A(或者是interface A)。
- 绝大部分情况下,class A隶属于一个package。所以class A的全路径名为xx.yy.zz.A。其中,xx.yy.zz是包名。
- 同一个package下的class B如果要使用class A的话,可以直接使用类A。如果class B位于别的package下的话,那么必须使用A的全路径名xx.yy.zz.A。当然,为了减少书写A所属包名的工作量,class B会通过import xx.yy.zz.A引入全路径名。然后,B也能直接使用类A了。
综其所述,源码构成主要讨论两个问题:
- 代码写在什么地方?Java中是放入.java为后缀的文件中。
- 如何解决不同源码文件中的代码之间相互引用的问题?Java中,同package下,源文件A的代码可以直接使用源文件B的内容。不同package下,则必须通过全路径名访问另外一个Package下的源文件A的内容(通过import可以减少书写包名的工作量)。
现在来看C++的做法:
- 在C++中,承载代码的文件有头文件和源文件的区别。头文件的后缀名一般为.h。也可以.hpp,.hxx结尾。源文件以.cpp,.cxx和.cc结尾。只要开发者之间约定好,采用什么形式的后缀都可以。笔者个人喜欢使用.h和.cpp做后缀名,而art源码则以.h和.cc为后缀名。
- 一般而言,头文件里声明需要公开的变量,函数或者类。源文件则定义(或者说实现)这些变量,函数或者类。那些需要使用这些公开内容的代码可以通过#include方式将其包含进来。注意,由于C++中头文件和源文件都可以承载代码,所以头文件和源文件都可以使用#include指令。比如,源文件a.cpp可以#include"b.h",从而使用b.h里声明的函数,变量或者类。头文件c.h也可以#include "b.h"。
下面我们分别通过头文件和源文件的几个示例来强化对它们的认识。
1.2.1 头文件示例
图10所示为一个非常简单头文件示例:

图10 Type.h示例
下面来分析图10中的Type.h:
- 首先,C++中,头文件的写法有一定规则需要遵循。比如图10中的
- #ifndef _TYPE_H_:ifndef是if not define之意。_TYPE_H_是宏的名称。
- #define _TYPE_H_:表示定义一个名为_TYPE_H_的宏、
- #endif:和前面的#ifndef对应。
这三个宏合起来的意思是,如果没有定义_TYPE_H_,则定义它。宏的名字可以任意取,但一般是和头文件的文件名相关,并且该宏不要和其他宏重名。为什么要定义一个这样的宏呢?其目的是为了防止头文件的重复包含。
探讨:如何防止头文件重复包含
编译器处理#include命令的方式就是将被包含的头文件的内容全部读取进来。一般而言,这种包含关系非常复杂。比如,a.h可以直接包含b.h和c.h,而b.h也可以直接包含c.h。如此,a.h相当于直接包含c.h一次,并间接包含c.h(通过b.包含c.h的方式)一次。假设c.h采用和图10一样的做法,则编译器在第一次包含c.h(因为a.h直接#include"c.h")的时候将定义_C_H_宏,当编译器第二次尝试包含c.h的时候(因为在处理#include "b.h"的时候,会将b.h所include的文件依次包含进来)会发现这个宏已经定义了。由于头文件中所有有价值的内容都是写在#ifndef和#endif之间的,也就是只有在没有定义_C_H_宏的时候,这个头文件的内容才会真正被包含进去。通过这种方式,c.h虽然被include两次,但是只有第一次包含会加载其内容,后续include等于没有真正加载其内容。
当然,现在的编译器比较高级,或许可以处理这种重复包含头文件的问题,但是建议读者自己写头文件的时候还是要定义这样的宏。
除了宏定义之外,图10中还定义了一个命名空间,名字为my_type。并且在命名空间里还声明了一个test函数:
- C++中的命名空间和Java中的package类似,但是要求上要简单很多。命名空间是一个范围(Scope),可以出现在任意头文件,源文件里。凡是放在某个命名空间里的函数,类,变量等就属于这个命名空间。
- Type.h只是声明(declare)了test函数,但没有这个函数的实现。声明仅是告诉编译器,我们有一个名叫test的函数。但是这个函数在什么地方呢?这时就需要有一个源文件来定义test函数,也就是实现test函数。
下面我们来看一个源文件示例:
1.2.2 源文件示例
源文件示例一如图11所示:

图11 Test.cpp示例
图11是一个名为Test.cpp的示例,在这个示例中:
- 包含Type.h和TypeClass.h。
- 调用两个函数,其中一个函数是Type.h里声明的test。由于test位于my_type命名空间里,所以需要通过my_type::test方式来调用它。
接着来看图12:

图12 Type.cpp
图12所示为Type.cpp:
- 从文件名上看,Type.cpp和Type.h可能会有些关系。确实如此。正如前文所说,头文件一般做声明用,而真正的实现往往放在源文件中。出于文件管理方便性的考虑,头文件和对应的源文件有着相同的文件名。
- Type.cpp还包含了iostream和iomanip两个头文件。需要特别注意的是,这两个include使用的是尖括号<>,而不是""。根据约定俗成的习惯,尖括号中的头文件往往是操作系统和C++标准库提供的头文件。包含这些头文件时不用携带.h的后缀。比如,#include
这条语句无需写成#include 。这是因为C++标准库的实现是由不同厂商来完成的。具体实现的时候可能头文件没有后缀名,或者后缀名不是.h。所以,C++规范将这个问题交给编译器来处理,它会根据情况找到正确的文件。 - C++标准库里的内容都定义在一个独立的命名空间里,这个命名空间叫std。如果需要使用某个命名空间里的东西,比如图12中的代表标准输出对象的cout,可以通过std::cout来访问它,或者像图12一样,通过using std::cout的方式来避免每次都书写"std::"。当然,也可以一次性将某个命名空间里的所有内容全部包含进来,方法就是usingnamespace std。这种做法和java的import非常类似。
- my_type命名空间里包含test和changeRef两个函数。其中,test函数实现了Type.h中声明的那个test函数。而由于changeRef完全是在Type.cpp中定义的,所以只有Type.cpp内部才知道这个函数,而外界(其他源文件,头文件)不知道这个世界上还有一个changeRef函数。在此请读者注意,一般而言,include指令用于包含头文件,极少用于包含源文件。
- Type.cpp还定义了一个changeNoRef函数,此函数是在my_type命名空间之外定义的,所以它不属于my_type命名空间。
到此,我们通过几个示例向读者展示了C++中头文件和源文件的构成和一些常用的代码写法。现在看看如何编译它们。
1.2.3 编译
C/C++程序一般是通过编写Makefile来编译的。Makefile其实就是一个命令的组合,它会根据情况执行不同的命令,包括编译,链接等。Makefile不是C++学习的必备知识点,笔者不拟讨论太多,读者通过图13做简单了解即可:

图13 Makefile示例
图13中,真正的编译工作还是由编译器来完成的。图13中展示了编译器的工作步骤以及对应的参数。此处笔者仅强调三点:
- Makefile是一个文件的文件名,该文件由make命令解析并处理。所以,我们可认为Makefile是专门供make命令使用的脚本文件。其内容的书写规则遵守make命令的要求。
- C++中,编译单元是源文件(即.cpp文件)。如图中①所示的内容,编译命令的输入都是xxx.cpp源文件,极少有单独编译.h头文件的。
- 笔者习惯先编译单个源文件以得到对应的obj文件,然后再链接这些obj文件得到最终的目标文件。链接的步骤也是由编译器来完成,只不过其输入文件从源文件变成了obj文件。
make命令如何执行呢?很简单:
- 进入到包含Makfile文件的目录下,执行make。如果没有指明Makefile文件名的话,它会以当前目录下的Makefile文件为输入。make将解析Makefile文件里定义的任务以及它们的依赖关系,然后对任务进行处理。如果没有指明任务名的话,则执行Makefile中定义的第一个任务。
- 可以通过make任务名来执行Makefile中的指定任务。比如,图13中最后两行定义了clean任务。通过make clean可执行它。clean任务的目标就是删除临时文件(比如obj文件)和上一次编译得到的目标文件。
提示
Makefile和make是一个独立的知识点,关于它们的故事可以写出一整本书了。不过,就实际工作而言,开发者往往会把Makefile写好,或者可借助一些工具以自动生成Makefile。所以,如果读者不了解Makefile的话也不用担心,只要会执行make命令就可以了。
1.3 Class介绍
本节介绍C++中面向对象的核心知识点——类(Class)。笔者对类有三点认识:
- Class是C++构造面向对象世界的核心单元。面向对象在编码中的直观体现就是程序员可以用Class封装成员变量和成员函数。以前用C写程序的时候,是面向过程的思维方法,考虑的是函数和函数之间的调用和跳转关系。C++出现后,我们看待问题和解决问题的思路发生了很大的变化,更多考虑是设计合适的类并处理对象和对象之间的关系。当然,面向对象并不是说程序就没有过程了。程序总还是有顺序,有流程的。但是在这个流程里,开发者更多关注的是对象以及对象之间的交互,而不是孤零零的函数。
- 另外,Class还支持抽象,继承和多态。这些概念完全就是围绕面向对象来设计和考虑的,它关注的是类和类之间的关系。
- 最后,从类型的角度来看,和C++基础内置数据类型一样,类也是一种数据类型,只不过它是一种可由开发者自定义的数据类型罢了。
探讨:
笔者以前几乎没有从类型的角度来看待过类。直到接触模板编程后,才发现类型和类型推导在模板中的重要作用。关于这个问题,我们留待后续介绍模板编程时再继续讨论。
下面我们来看看C++中的Class该怎么实现。先来看图14所示的TypeClass.h,它声明了一个名为Base的类。请读者重点关注它的语法:

图14 Base类的声明
来看图14的内容:
- 首先,笔者用class关键字声明了一个名为Base的类。Base类位于type_class命名空间里。
- C++类有和Java一样的访问权限控制,关键词也是public、private和protected三种。不过其使用方法和Java略有区别。Java中,每个成员(包含函数和变量)都需要单独声明访问权限,而C++则是分组控制的。例如,位于"public:"之后的成员都有相同的public访问权限。如果没有指明访问权限,则默认使用private访问权限。
- 在类成员的构成上,C++除了有构造函数,赋值函数,析构函数等三大类特殊成员函数外,还可以定义其他成员函数和成员变量。成员变量如图14中的size变量可以像Java那样在声明时就赋初值,但笔者感觉C++的习惯做法还是只声明成员变量,然后到构造函数中去赋初值。
- C++中,函数声明时可以指明参数的默认值,比如deleteC函数,它有三个参数,后面两个参数均有默认值(参数b的默认值是100,参数test的默认值是true)。
接下来,我们先介绍C++的三大类特殊函数。
注意,
这三类特殊函数并不是都需要定义。笔者此处列举它们仅为学习用。
1.3.1 构造,赋值和析构函数
C++类的三种特殊成员函数分别是构造、赋值和析构,其中:
- 构造函数:当创建类的实例对象时,这个对象的构造函数将被调用。一般在构造函数中做该对象的初始化工作。Java中的类也有构造函数,和C++中的构造函数类似。
- 赋值函数:赋值函数其实就是指"="号操作符,用于将变量A赋值给同类型(不考虑类型转换等情况)的变量B。比如,可以将整型变量(假设变量名为aInt)的值赋给另一个整型变量bInt。在此基础上,我们也可以将类A的某个实例(假设变量名为aA)赋值给类A的另外一个实例bA。请读者注意,1.3节一开始就强调过,类只不过是一种自定义的数据类型罢了。如果整型变量(或者其他基础内置数据类型)可以赋值的话,类也应该支持赋值操作。
- 析构函数:当对象的生命走向终结时,它的析构函数将被调用。一般而言,该函数内部会释放这个对象占据的各种资源。Java中,和析构函数类似的是finalize方法。不过,由于Java实现了内存自动回收机制,所以Java程序员几乎不需要考虑finalize的事情。
下面,我们分别来讨论这三种特殊函数。
1. 构造函数
来看类Base的构造函数,如图15所示:

图15 构造函数示例
图15中的代码实现于TypeClass.cpp中:
- 在类声明之外实现类的成员函数时,需要通过"类名::函数名"的方式告诉编译器这是一个类的成员函数,比如图15中的Base::Base(int a)。
- 默认构造函数:默认构造函数是指不带参数或所有参数全部有默认值的构造函数。注意,C++的函数是支持参数带默认值的,比如图14中Base类的deleteC函数,
- 普通构造函数:带参数的构造函数。
- 拷贝构造函数:用法如图15中的③所示。详情可见下文介绍。
下面来介绍图15中几个值得注意的知识点:
(1) 构造函数初始值列表
构造函数主要的功能是完成类实例的初始化,也就是对象的成员变量的初始化。C++中,成员变量的初始化推荐使用初始值列表(constructor initialize list)的方法(使用方法如图15所示),其语法格式为:
构造函数(...):
成员变量A(A的初值),成员变量B(B的初值){
...//也可以使用花括号,比如成员变量A{A的初值},成员变量B{B的初值}
}
当然,成员变量的初值设置也可以通过赋值方式来完成:
构造函数(...){
成员变量A=A的初值;
成员变量B=B的初值;
....
}
C++中,构造函数中使用初值列表和成员变量赋初值是有区别的,此处不拟详细讨论二者的差异。但推荐使用初值列表的方式,原因大致有二:
- 使用初值列表可能运行效率上会有提升。
- 有些场合必须使用初值列表,比如子类构造函数中初始化基类的成员变量时。后文中将看到这样的例子。
提示:
构造函数中请使用初值列表的方式来完成变量初始化。
(2) 拷贝构造函数
拷贝构造,即从一个已有的对象拷贝其内容,然后构造出一个新的对象。拷贝构造函数的写法必须是:
构造函数(const 类& other)
注意,const是C++中的常量修饰符,与Java的final类似。
拷贝过程中有一个问题需要程序员特别注意,即成员变量的拷贝方式是值拷贝还是内容拷贝。以Base类的拷贝构造为例,假设新创建的对象名为B,它用已有的对象A进行拷贝构造:
- memberA和memberB是值拷贝。所以,A对象的memberA和memberB将赋给B的memberA和memberB。此后,A、B对象的memberA和memberB值分别相同。
- 而对pMemberC来说,情况就不一样了。B.pMemberC和A.pMemberC将指向同一块内存。如果A对这块内存进行了操作,B知道吗?更有甚者,如果A删除了这块内存,而B还继续操作它的话,岂不是会崩溃?所以,对于这种情况,拷贝构造函数中使用了所谓的深拷贝(deepcopy),也就是将A.pMemberC的内容拷贝到B对象中(B先创建一个大小相同的数组,然后通过memcpy进行内存的内容拷贝),而不是简单的进行赋值(这种方式叫浅拷贝,shallow copy)。
值拷贝、内容拷贝和浅拷贝、深拷贝
由上述内容可知,浅拷贝对应于值拷贝,而深拷贝对应于内容拷贝。对于非指针变量类型而言,值拷贝和内容拷贝没有区别,但对于指针型变量而言,值拷贝和内容拷贝差别就很大了。
图16解释了深拷贝和浅拷贝的区别:

图16 浅拷贝和深拷贝的区别
图16中,浅拷贝用红色箭头表示,深拷贝用紫色箭头表示:
- 浅拷贝最明显的问题就是A和B的pMemberC将指向同一块内存。绝大多数情况下,浅拷贝的结果绝不是程序员想要的。
- 采用深拷贝的话,A和B将具有相同的内容,但彼此之间不再有任何纠葛。
- 对于非指针型变量而言,深拷贝和浅拷贝没有什么区别,其实就是值的拷贝
最后,笔者还要特别说明拷贝构造函数被触发的场合。来看代码:
Base A; //构造A对象
Base B(A);// ①直接用A对象来构造B对象,这种情况是“直接初始化”
Base C = A;// ②定义C的时候即赋值,这是真正意义上的拷贝构造。二者的区别见下文介绍。
除了上述两种情况外,还有一些场合也会导致拷贝构造函数被调用,比如:
- 当函数的参数为非引用的类类型时,调用这个函数并传递实参时,实参的拷贝构造函数被调用。
- 函数的返回类型为一个非引用的对象时,该对象的拷贝构造函数被调用。
直接初始化和拷贝初始化的细微区别
Base B(A)只是导致拷贝构造函数被调用,但并不是严格意义上的拷贝构造,因为:
- Base确实定义了一个形参为constB&的构造函数。而B(A)的语法恰好满足这个函数,所以这个构造函数被调用是理所当然的。这样的构造是很直接的,没有任何疑义的,所以叫直接初始化。
- 而对于Base C = A的理解却是将A的内容拷贝到正在创建的C对象中,这里包含了拷贝和构造两个概念,即拷贝A的内容来构造C。所以叫拷贝构造。惭愧得说,笔者也很难描述上述内容在语法上的精确含义。不过,从使用角度来看,读者只需记住这两种情况均会导致拷贝构造函数被调用即可。
2. 拷贝赋值函数
拷贝赋值函数是赋值函数的一种,我们先来思考下赋值函数解决什么问题。请读者思考下面这段代码:
int a = 0;
int b = a;//将a赋值给b
所有读者应该对上述代码都不会有任何疑问。是的,对于基本内置数据类型而言,赋值操作似乎是天经地义的合理,但对于类类型呢?比如下面的代码:
Base A;//构造一个对象A
Base B; //构造一个对象B
B = A; //①A可以赋值给B吗?
从类型的角度来看,没有理由不允许类这种自定义数据类型的进行赋值操作。但是从面向对象角度来看,把一个对象赋值给另外一个对象会得到什么?现实生活中似乎也难以到类似的场景来比拟它。
不管怎样,C++是支持一个对象赋值给另一个对象的。现在把注意力回归到拷贝赋值上来,来看图17所示的代码:

图17 拷贝赋值函数示例
赋值函数本身没有什么难度,无非就是在准备接受另外一个对象的内容前,先把自己清理干净。另外,赋值函数的关键知识点是利用了C++中的操作符重载(Java不支持操作符重载)。关于操作符重载的知识请读者阅读本文后续章节。
3. 移动构造和移动赋值函数
前面两节介绍了拷贝构造和拷贝赋值函数,还了解了深拷贝和浅拷贝的区别。但关于构造和赋值的故事并没有完。因为C++11中,除了拷贝构造和拷贝赋值之外,还有移动构造和移动赋值。
注意
这几个名词中:构造和赋值并没有变,变化的是构造和赋值的方法。前2节介绍的是拷贝之法,本节来看移动之法。
(1) 移动之法的解释
图18展示了移动的含义:

图18 Move的示意
对比图16和图18,读者会发现移动的含义其实非常简单,就是把A对象的内容移动到B对象中去:
- 对于memberA和memberB而言,由于它们是非指针类型的变量,移动和拷贝没有不同。
- 但对于pMemberC而言,差别就很大了。如果使用拷贝之法,A和B对象将各自有一块内存。如果使用移动之法,A对象将不再拥有这块内存,反而是B对象拥有A对象之前拥有的那块内存。
移动的含义好像不是很难。不过,让我们更进一步思考一个问题:移动之后,A、B对象的命运会发生怎样的改变?
- 很简单,B自然是得到A的全部内容。
- A则掏空自己,成为无用之物。注意,A对象还存在,但是你最好不要碰它,因为它的内容早已经移交给了B。
移动之后,A居然无用了。什么场合会需要如此“残忍”的做法?还是让我们用示例来阐述C++11推出移动之法的目的吧:

图19 有Move和没有Move的区别
图19中,左上角是示例代码:
- test函数:将getTemporyBase函数的返回值赋给一个名为a的Base实例。
- getTemporyBase函数:构造一个Base对象tmp并返回它。
图19展示了没有定义移动构造函数和定义了移动构造函数时该程序运行后打印的日志。同时图中还解释了执行的过程。结合前文所述内容,我们发现tmp确实是一种转移出去(不管是采用移动还是拷贝)后就不需要再使用的对象了。对于这种情况,移动构造所带来的好处是显而易见的。
注意:
对于图中的测试函数,现在的编译器已经能做到高度优化,以至于图中列出的移动或拷贝调用都不需要了。为了达到图中的效果,编译时必须加上-fno-elide-constructors标志以禁止这种优化。读者不妨一试。
下面,我们来看看代码中是如何体现移动的。
(2) 移动之法的代码实现和左右值介绍
图20所示为Base的移动构造和移动赋值函数:

图20 移动构造和移动赋值示例
图20中,请读者特别注意Base类移动构造和移动赋值函数的参数的类型,它是Base&&。没错,是两个&&符号:
- 如果是Base&&(两个&&符号),则表示是Base的右值引用类型。
- 如果是Base&(一个&符号),则表示是Base的引用类型。和右值引用相比,这种引用也叫左值引用。
什么是左值,什么是右值?笔者不拟讨论它们详细的语法和语义。不过,根据参考文献[5]所述,读者掌握如下识即可:
- 左值是有名字的,并且可以取地址。
- 右值是无名的,不能取地址。比如图19中getTemporyBase返回的那个临时对象就是无名的,它就是右值。
我们通过几行代码来加深对左右值的认识:
int a,b,c; //a,b,c都是左值
c = a+b; //c是左值,但是(a+b)却是右值,因为&(a+b)取地址不合法
getTemporyBase();//返回的是一个无名的临时对象,所以是右值
Base && x = getTemoryBase();//通过定义一个右值引用类型x,getTemporyBase函数返回
//的这个临时无名对象从此有了x这个名字。不过,x还是右值吗?答案为否:
Base y = x;//此处不会调用移动构造函数,而是拷贝构造函数。因为x是有名的,所以它不再是右值。
如果读者想了解更多关于左右值的区别,请阅读本章所列的参考书籍。此处笔者再强调一下移动构造和赋值函数在什么场合下使用的问题,请读者注意把握两个关键点:
- 第一,如果确定被转移的对象(比如图19中的tmp对象)不再使用,就可以使用移动构造/赋值函数来提升运行效率。
- 第二,我们要保证移动构造/赋值函数被调用,而不是拷贝构造/赋值函数被调用。例如,上述代码中Base y = x这段代码实际上触发了拷贝构造函数,这不是我们想要的。为此,我们需要强制使用移动构造函数,方法为Base y = std::move(x)。move是std标准库提供的函数,用于将参数类型强制转换为对应的右值类型。通过move函数,我们表达了强制使用移动函数的想法。
如果没有定义移动函数怎么办?
如果类没有定义移动构造或移动赋值函数,编译器会调用对应的拷贝构造或拷贝赋值函数。所以,使用std::move不会带来什么副作用,它只是表达了要使用移动之法的愿望。
4. 析构函数
最后,来看类中最后一类特殊函数,即析构函数。当类的实例达到生命终点时,析构函数将被调用,其主要目的是为了清理该实例占据的资源。图21所示为Base类的析构函数示例:

图21 析构函数示例
Java中与析构函数类似的是finalize函数。但绝大多数情况下,Java程序员不用关心它。而C++中,我们需要知道析构函数什么时候会被调用:
² 栈上创建的类实例,在退出作用域(比如函数返回,或者离开花括号包围起来的某个作用域)之前,该实例会被析构。
² 动态创建的实例(通过new操作符),当delete该对象时,其析构函数会被调用。
1. 总结
1.3.1节介绍了C++中一个普通类的大致组成元素和其中一些特殊的成员函数,比如:
- 构造函数,分为默认构造,普通构造,拷贝构造和移动构造。
- 赋值函数,分为拷贝赋值和移动赋值。请读者先从原理上理解拷贝和移动的区别和它们的目的。
- 析构函数。
1.3.2 类的派生和继承
C++中与类的派生、继承相关的知识比较复杂,相对琐碎。本节中,笔者拟将精力放在一些相对基础的内容上。先来看一个派生和继承的例子,如图22所示:

图22 派生和继承示例
图22中:
- 右边居中方框①定义了一个Base类,它和图14中的内容一样。
- 右下方框②定义了一个VirtualBase类,它包含构造函数,虚析构函数,虚函数test1,纯虚函数test2和一个普通函数test3。
- 左边方框③定义了一个Derived类,它同时从Base和VirtualBase类派生,属于多重继承。
- 图中给出了10个需要读者注意的函数和它们的简单介绍。
和Java比较
Java中虽然没有类的多重继承,但一个类可以实现多个接口(Interface),这其实也算是多重继承了。相比Java的这种设计,笔者觉得C++中类的多重继承太过灵活,使用时需要特别小心,否则菱形继承的问题很难避免。
现在,先来看一下C++中派生类的写法。如图22所示,Derived类继承关系的语法如下:
class Derived:private Base,publicVirtualBase{
}
其中:
- classDerived之后的冒号是派生列表,也就是基类列表,基类之间用逗号隔开。
- 派生有public、private和protected三种方式。其意义和Java中的类派生方式差不多,大抵都是用于控制派生类有何种权限来访问继承得到的基类成员变量和成员函数。注意,如果没有指定派生方式的话,默认为private方式。
了解C++中如何编写派生类后,下一步要关注面向对象中两个重要特性——多态和抽象是如何在C++中体现的。
注意:
笔者此处所说的抽象是狭义的,和语言相关的,比如Java中的抽象类。
1. 虚函数、纯虚函数和虚析构函数
Java语言里,多态是借助派生类重写(override)基类的函数来表达,而抽象则是借助抽象类(包括抽象方法)或者接口来实现。而在C++中,虚函数和纯虚函数就是用于描述多态和抽象的利器:
- 虚函数:基类定义虚函数,派生类可以重写(override)它。当我们拥有一个派生类对象,但却是通过基类引用类型或者基类指针类型的变量来调用该对象的虚函数时,被调用的虚函数是派生类重写过的虚函数(如果该虚函数被派生类重写了的话)。
- 纯虚函数:拥有纯虚函数的类不能实例化。从这一点看,它和Java的抽象类和接口非常类似。
C++中,虚函数和纯虚函数需要明确标示出来,以VirtualBase为例,相关语法如下:
virtual voidtest1(bool test); //虚函数由virtual标示
virtual voidtest2(int x, int y) = 0;//纯虚函数由"virtual"和"=0"同时标示
派生类如何override这些虚函数呢?来看Derived类的写法:
/*
基类里定义的虚函数在派生类中也是虚函数,所以,下面语句中的virtual关键词不是必须要写的,
override关键词是C++11新引入的标识,和Java中的@Override类似。
override也不是必须要写的关键词。但加上它后,编译器将做一些有用的检查,所以建议开发者
在派生类中重写基类虚函数时都加上这个关键词
*/
virtual void test1(bool test) override;//可以加virtual关键词,也可以不加
void test2(int x, int y) override;//如上,建议加上override标识
注意,virtual和override标示只在类中声明函数时需要。如果在类外实现该函数,则并不需要这些关键词,比如:
TypeClass.h
class Derived ....{
.......
voidtest2(int x, int y) override;//可以不加virtual关键字
}
TypeClass.cpp
void Derived::test2(int x, int y){//类外定义这个函数,不能加virtual等关键词
cout<<"in Derived::test2"< } 提示: 注意,art代码中,派生类override基类虚函数时,大都会添加virtual关键词,有时候也会加上override关键词。根据参考文献[1]的建议,派生类重写虚函数时候最好添加override标识,这样编译器能做一些额外检查而能提前发现一些错误。 除了上述两类虚函数外,C++中还有虚析构函数。虚析构函数其实就是虚函数,不过它稍微有一点特殊,需要开发者注意: 阻止虚函数被override C++中,也可以阻止某个虚函数被override,方法和Java类似,就是在函数声明后添加final关键词,比如 virtual void test1(boolean test) final;//如此,test1将不能被派生类override了 最后,我们通过一段示例代码来加深对虚函数的认识,如图23所示: 图23 虚函数测试示例 图23是笔者编写的一个很简单的例子,左边是代码,右边是运行结果。简而言之: 提示: 1 请读者尝试修改测试代码,然后观察打印结果。 2 读者可将图23中代码的最后一行改写成pvb->~VirtualBase(),即直接调用基类的析构函数,但由于它是虚析构函数,所以运行时,~Derived()将先被调用。 类的构造函数在类实例被创建时调用,而析构函数在该实例被销毁时调用。如果该类有派生关系的话,其基类的构造函数和析构函数也将被依次调用到,那么,这个依次的顺序是什么? 补充内容: 如果派生类含有类类型的成员变量时,调用次序将变成: 构造函数:基类构造->派生类中类类型成员变量构造->派生类构造 析构函数:派生类析构->派生类中类类型成员变量析构->基类析构 多重派生的话,基类按照派生列表的顺序/反序构造或析构 Java中,如果程序员没有为类编写构造函数函数,则编译器会为类隐式创建一个不带任何参数的构造函数。这种编译器隐式创建一些函数的行为在C++中也存在,只不过C++中的类有构造函数,赋值函数,析构函数,所以情况会复杂一些,图24描述了编译器合成特殊函数的规则: 图24 编译器合成特殊函数的规则 图24的规矩可简单总结为: 从上面的描述可知,C++中编译器合成特殊函数的规则是比较复杂的。即使如此,图24中展示的规则还仅是冰山一角。以移动函数的合成而言,即使图中的条件满足,编译器也未必能合成移动函数,比如类中有无法移动的成员变量时。 关于编译器合成规则,笔者个人感觉开发者应该以实际需求为出发点,如果确实需要移动函数,则在类声明中定义就行。 有些时候我们需要一种方法来控制编译器这种自动合成的行为,控制的目的无外乎两个: 借助=default和=delete标识,这两个目的很容易达到,来看一段代码: //定义了一个普通的构造函数,但同时也想让编译器合成默认的构造函数,则可以使用=default标识 Base(int x); //定义一个普通构造函数后,编译器将停止自动合成默认的构造函数 //=default后,强制编译器合成默认的构造函数。注意,开发者不用实现该函数 Base() = default;//通知编译器来合成这个默认的构造函数 //如果不想让编译器合成某些函数,则使用= delete标识 Base&operator=(const Base& other) = delete;//阻止编译合成拷贝赋值函数 注意,这种控制行为只针对于构造、赋值和析构等三类特殊的函数。 一般而言,派生类可能希望有着和基类类似的构造方法。比如,图25所示的Base类有3种普通构造方法。现在我们希望Derived也能支持通过这三种方式来创建Derived类实例。怎么办?图25展示了两种方法: 图25 派生类“继承”基类构造函数 注意,这种“继承”其实是一种编译器自动合成的规则,它仅支持合成普通的构造函数。而默认构造函数,移动构造函数,拷贝构造函数等遵循正常的规则来合成。 探讨 前述内容中,我们向读者展示了C++中编译器合成一些特殊函数的做法和规则。实际上,编译器合成的规则比本节所述内容要复杂得多,建议感兴趣的读者阅读参考文献来开展进一步的学习。 另外,实际使用过程中,开发者不能完全依赖于编译器的自动合成,有些细节问题必须由开发者自己先回答。比如,拷贝构造时,我们需要深拷贝还是浅拷贝?需不需要支持移动操作?在获得这些问题答案的基础上,读者再结合编译器合成的规则,然后才选择由编译器来合成这些函数还是由开发者自己来编写它们。 前面我们提到过,C++中的类访问其实例的成员变量或成员函数的权限控制上有着和Java类似的关键词,如public、private和protected。严格遵守“信息该公开的要公开,不该公开的一定不公开”这一封装的最高原则无疑是一件好事,但现实生活中的情况是如此变化万端,有时候我们也需要破个例。比如,熟人之间是否可以公开一些信息以避开如果按“公事公办”走流程所带来的过高沟通成本的问题? C++中,借助友元,我们可以做到小范围的公开信息以减少沟通成本。从编程角度来看,友元的作用无非是:提供一种方式,使得类外某些函数或者某些类能够访问一个类的私有成员变量或成员函数。对被访问的类而言,这些类外函数或类,就是被访问的类的朋友。 来看友元的示例,如图26所示: 图26 类的友元示意 图26展示了如何为某个类指定它的“朋友们”,C++中,类的友元可以是: 基类的友元会变成从该基类派生得来的派生类的友元吗? C++中,友元关系不能继承,也就是说: 1 基类的友元可以访问基类非公开成员,也能访问派生类中属于基类的非公开成员。 2 但是不能访问派生类自己定义的非公开成员。 友元比较简单,此处就不拟多说。现在我们介绍下图26中提到的类的前向声明,先来回顾下代码: class Obj;//类的前向声明 void accessObj(Obj& obj); C++中,数据类型应该先声明,然后再使用。但这会带来一个“先有鸡还是先有蛋”的问题: 怎么破解这个问题?这就用到了类的前向声明,以图26为例,Obj前向声明的目的就是告诉类型系统,Obj是一个class,不要把它当做别的什么东西。一般而言,类的前向声明的用法如下: 这就是类的前向声明的用法,即在头文件里进行类的前向声明,在源文件里去包含该类的头文件。 类的前向声明的局限 前向声明好处很多,但同时也有限制。以Obj为例,在看到Obj完整定义之前,不能声明Obj类型的变量(包括类的成员变量),但是可以定义Obj引用类型或Obj指针类型的变量。比如,你无法在图26中class Obj类代码之前定义ObjaObj这样的变量。只能定义Obj& refObj或Obj* pObj。之所以有这个限制,是因为定义Obj类型变量的时候,编译器必须确定该变量的大小以分配内存,由于没有见到Obj的完整定义,所以编译器无法确定其大小,但引用或者指针则不存在此问题。读者不妨一试。 explicit构造函数和类型的隐式转换有关。什么是类型的隐式转换呢?来看下面的代码: int a, b = 0; short c = 10; //c是short型变量,但是在此处会先将c转成int型变量,然后再和b进行加操作 a = b + c; 对类而言,也有这样的隐式类型转换,比如图27所示的代码: 图27 隐式类类型转换示例 图27中测试代码里,编译器进行了隐式类型转换,即先用常量2构造出一个临时的TypeCastObj对象,然后再拷贝构造为obj2对象。注意,支持这种隐式类型转换的类的构造函数需要满足一个条件: 注意: TypeCastObj obj3(3) ;//这样的调用是直接初始化,不是隐式类型转换 如果程序员不希望发生这种隐式类型转换该怎么办?只需要在类声明中构造函数前添加explicit关键词即可,比如: explicit TypeCastObj(intx) :mX(x){ cout<<"in ordinay constructor"< } struct是C语言中的古老成员了,在C中它叫结构体。不过到了C++世界,struct不再是C语言中结构体了,它升级成了class。即C++中的struct就是一种class,它拥有类的全部特征。不过,struct和普通class也有一点区别,那就是struct的成员(包含函数和变量)默认都是public的访问权限。 对Java程序员而言,操作符重载是一个陌生的话题,因为Java语言并不支持它[⑥]。相反,C++则灵活很多,它支持很多操作符的重载。为什么两种语言会有如此大相径庭的做法呢?关于这个问题,前文也曾从面向对象和面向数据类型的角度探讨过: 上述“从面向对象的角度和从数据类型的角度看待是否应该支持操作符重载”的观点只是笔者的一些看法。至于两种语言的设计者为何做出这样的选择,想必其背后都有充足的理由。 言归正传,先来看看C++中哪些操作符支持重载,哪些不支持重载。答案如下: /* 此处内容为笔者添加的解释 */ 可以被重载的操作符: + - * / % ^ &/*取地址操作符*/ | ~ ! , /*逗号运算符*/ =/*赋值运算符*/ < > < = >= ++ -- <</*输出操作符*/ >>/*输入操作符*/ == != && || += -= /= %= ^= &= |= *= <<= >>= []/*下标运算符*/ ()/*函数调用运算符*/ ->/*类成员访问运算符,pointer->member */ ->*/*也是类成员访问运算符,但是方法为pointer->*pointer-to-member */ /*下面是内存创建和释放运算符。其中new[]和delete[]用于数组的内存创建和释放*/ new new[] delete delete[] 不能被重载的操作符: ::(作用域运算符) ?:(条件运算符) . /*类成员访问运算符,object.member */ .* /*类成员访问运算符,object.*pointer-to-member */ 除了上面列出的操作符外,C++还可以重载类型转换操作符,比如: class Obj{//Obj类声明 ... operator bool();//重载bool类型转换操作符。注意,没有返回值的类型 bool mRealValue; } Obj::operator bool(){ //bool类型转换操作符函数的实现,没有返回值的类型 return mRealValue; } Obj obj; bool value = (bool)obj;//将obj转换成bool型变量 C++操作符重载机制非常灵活,绝大部分运算符都支持重载。这是好事,但同时也会因灵活过度造成理解和使用上的困难。 提示: 实际工作中只有小部分操作符会被重载。关于C++中所有操作符的知识和示例,请读者参考http://en.cppreference.com/w/cpp/language/operators。 接着来看C++中操作符重载的实现方式。 操作符重载说白了就是将操作符当成函数来对待。当执行某个操作符运算时,对应的操作符函数被调用。和普通函数比起来,操作符对应的函数名由“operator 操作符的符号”来标示。 既然是函数,那么就有类的成员函数和非类的成员函数之分,C++中: 本节先来看一个可以采用两种方式来重载的加操作符的示例,如图28所示: 图28 Obj对+号的重载示例 图28中,Obj类定义了两个+号重载函数,分别实现一个Obj类型的变量和另外一个Obj类型变量或一个int型变量相加的操作。同时,我们还定义了一个针对Obj类型和布尔类型的+号重载函数。+号重载为类成员函数或非类成员函数均可,程序员应该根据实际需求来决定采用哪种重载方式。下面是一段测试代码: Obj obj1, obj2; obj1 = obj1+obj2;//调用Obj类第一个operator+函数 int x = obj1+100;//调用Obj类第二个operator+函数 x = obj1.operator+(1000); //显示调用Obj类第二个operator+成员函数 int z = obj1+true;//调用非类的operator+函数 强调: 实际编程中,加操作符一般会重载为类的成员函数。并且,输入参数和返回值的类型最好都是对应的类类型。因为从“两个整型操作数相加的结果也是整型”到“两个Obj类型操作数相加的结果也是Obj类型”的推导是非常自然的。上述示例中,笔者有意展示了操作符重载的灵活性,故而重载了三个+操作符函数。 本章很多示例代码都用到了C++的标准输出对象cout。和标准输出对象相对应的是标准输入对象cin和标准错误输出对象cerr。其中,cout和cerr的类型是ostream,而cin的类型是istream。ostream和istream都是类名,它们和Java中的OutputStream和InputStream有些类似。 cout和cin如何使用呢?来看下面的代码: using std::cout;//cout,endl,cin都位于std命名空间中。endl代表换行符 using std::endl; using std:cin; int x = 0, y =1;//定义x和y两个整型变量 cout <<”x = ” << x <<” y = ” << y << endl; /* 上面这行代码表示: 1 将“x = ”字符串写到cout中 2 整型变量x的值写到cout中 3 “ y = ”字符串写到cout中 4 整型变量y的值写到cout中 5 写入换行符。最终,标准输出设备(一般是屏幕)中将显示: x = 0 y = 1 */ 上面语句看起来比较神奇,<<操作符居然可以连起来用。这是怎么做到的呢?来看图29: 图29 等价转换 如图29可知,只要做到operator <<函数的返回值就是第一个输入参数本身,我们就可以进行代码“浓缩”。那么,operator<<函数该怎么定义呢?非常简单: ostream&operator<<(ostream& os,某种数据类型 参数名){ ....//输出内容 return os;//第一个输入参数又作为返回值返回了 } istream&operator>>(istream& is, 某种数据类型 参数名){ ....//输入内容 return is; } 通过上述函数定义,"cout<<....<<..."和"cin>>...>>.."这样的代码得以成功实现。 C++的>>和<<操作符已经实现了内置数据类型和某些类类型(比如STL标准类库中的某些类)的输出和输入。如果想实现用户自定义类的输入和输出则必须重载这两个操作符。来看一个例子,如图30所示: 图30 <<和>>操作符重载示例 通过图30的重载,我们可以通过标准输入输出来操作Obj类型的对象了。 比较: <<输出操作符重载有点类似于我们在Java中为某个类重载toString函数。toString的目的是将类实例的内容转换成字符串以方便打印或者别的用途。 ->和*操作符重载一般用于所谓的智能指针类,它们必须实现为类的成员函数。在介绍相关示例代码前,笔者要特别说明一点:这两个操作符如果操作的是指针类型的对象,则并不是重载,比如下面的代码: //假设Object类重载了->和*操作符 Object *pObject =new Object();//new一个Object对象 //下面的->操作符并非重载。因为pObject是指针类型,所以->只是按照标准语义访问它的成员 pObject->getSomethingPublic(); //同理,pObject是指针类型,故*pObject就是对该地址的解引用,不会调用重载的*操作符函数 (*pObject).getSomethingPublic(); 按照上述代码所说,对于指针类型的对象而言,->和*并不能被重载,那这两个操作符的重载有什么作用?来看示例代码,如图31所示: 图31 ->和*操作符重载示例 图31中,笔者实现了一个用于保护某个new出来的Obj对象的SmartPointerOfObj类,通过重载SmartPointerOfObj的->和*操作符,我们就好像直接在操作指针型变量一样。在重载的->和*函数中,程序员可以做一些检查和管理,以确保mpObj指向正确的地址,目的是避免操作无效内存。这就是一个很简单的智能指针类的实现。 提示: STL标准库也提供了智能指针类。ART中大量使用了它们。本章后续将介绍STL中的智能指针类。使用智能指针还有一个好处。由于智能指针对象往往不需要用new来创建,所以智能指针对象本身的内存管理是比较简单的,不需要考虑delete它的问题。另外,智能指针的目标是更智能得管理它所保护的对象。借助它,C++也能做到一定程度的自动内存回收管理了。比如图31中测试代码的spObj对象,它不是new出来的,所以当函数返回时它自动会被析构。而当它析构的时候,new出来的Obj对象又将被delete。所以这两个对象(new出来的Obj对象和在栈上创建的spObj对象)所占据的资源都可以完美回收。 new和delete操作符的重载与其他操作符的重载略有不同。平常我们所说的new和delete实际上是指new表达式(expression)以及delete表达式,比如: Object* pObject =new Object; //new表达式,对于数组而言就是new Object[n]; deletepObject;//delete表达式,对于数组而言就是delete[] pObject 上面这两行代码分别是new表达式和delete表达式,这两个表达式是不能自定义的,但是: ² new表达式执行过程中将首先调用operator new函数。而C++允许程序员自定义operatornew函数。 ² delete表达式执行过程的最后将调用operator delete函数,而程序员也可以自定义operatordelete函数。 所以,所谓new和delete的重载实际上是指operator new和operator delete函数的重载。下面我们来看一下operator new和operator delete函数如何重载。 提示: 为行文方便,下文所指的new操作符就是指operator new函数,delete操作符就是指operator delete函数。 我们先来看new操作符的语法,如图32所示: 图32 new的语法 new操作符一共有12种形式,用法相当灵活,其中: 请读者务必注意,如果我们在类中重载了任意一种new操作符,那么系统的new操作符函数将被隐藏。隐藏的含义是指编译器如果在类X中找不到匹配的new函数时,它也不会去搜索系统定义的匹配的new函数,这将导致编译错误。 注意:何谓“隐藏”? http://en.cppreference.com/w/cpp/memory/new/operator_new提到了只要类重载任意一个new函数,都将导致系统定义的new函数全部被隐藏。关于“隐藏”的含义,经过笔者测试,应该是指编译器如果在类中没有搜索到合适的new函数后,将不会主动去搜索系统定义的new函数,如此将导致编译错误。 如果不想使用类重载的new操作符的话,则必须通过::new的方式来强制使用全局new操作符。其中,::是作用域操作符,作用域可以是类(比如Obj::)、命名空间(比如stl::),或者全局(::前不带名称)。 综上所述,new操作符重载很灵活,也很容易出错。所以建议程序员尽量不要重载全局的new操作符,而是尽可能重载特定类的new操作符(图32中的(9)到(12))。 接着来看delete操作符的语法,如图33所示: 图33 delete操作符的语法 delete用法比new还要复杂。此处需要特别说明的是: 上面的描述不太直观,我们通过一个例子进一步来解释它,如图34所示: 图34 delete操作符的用法示例 图34中: 图34中还特别指出代码中不能直接使用delete p1这样的表达式,这会导致编译错误,提示没有匹配的delete函数,这是因为: 提示: 关于全局delete函数被隐藏的问题,读者不妨动手一试。 现在我们来看new和delete操作符重载的一个简单示例。如图35所示: 强调: 考虑到new和delete的高度灵活性以及和它们和内存分配释放紧密相关的重要性,程序员最好只针对特定类进行new和delete操作符的重载。 图35 new/delete操作符重载的示例 图35中,笔者为Obj重载了两个new操作符和两个delete操作符: 讨论:重载new和delete操作符的好处 通过重载new和delete操作符,我们有机会在对象创建和释放的时候做一些内存管理的工作。比如,每次new一个Obj对象,我们递增new被调用的次数。delete的时候再递减。当程序退出时,我们检查该次数是否归0。如果不为0,则表示有Obj对象没有被delete,这很可能就是内存泄露的潜在原因。 我们用new表达式创建一个对象的时候,系统将在堆上分配一块内存,然后这个对象在这块内存上被构造。由于这块内存分配在堆上,程序员一般无法指定其地址。这一点和Java中的new类似。但有时候我们希望在指定内存上创建对象,可以做到吗?对于C++这种灵活度很高的语言而言,这个小小要求自然可以轻松满足。只要使用特殊的new即可: ² void* operator new(size_t count, void* ptr):它是placement new中的一种。此函数第二个参数是一个代表内存地址的指针。该函数的默认实现就是直接将ptr作为返回的内存地址,也就是将传入的内存地址作为new的结果返回给调用者。 使用这种方式的new操作符时,由于返回的内存地址就是传进来的ptr,这就达到了在指定内存上构造对象的功能。马上来看一个示例,如图36所示: 图36 new/delete示例 图36展示了placement new的用法,即在指定内存中构造对象。这个指定内存是在栈上创建的。另外,对于这种方式创建的对象,如果要delete的话必需小心,因为系统提供的delete函数将回收内存。在本例中,对象是构造在栈上的,其占据的内存随testPlacementNew函数返回后就自动回收了,所以图35中没有使用delete。不过请读者务必注意,这种情况下内存不需要主动回收,但是对象是需要析构的。 显然,这种只有new没有delete的使用方法和平常用法不太匹配,有点别扭。如何改进呢?方法很简单,我们只要按如下方式重载delete操作符,就可以在图35的实例中使用delete了: //Class Obj重载delete操作符 void operator delete(void* obj){ cout<<"delete--"< //return ::operator delete(obj);屏蔽内存释放,因为本例中内存在栈上分配的 }//读者可以自行修改测试案例以加深对new和delete的体会。 如果Obj类按如上方式重载了delete函数,我们在图36的代码中就可以“delete pObj1”了。 探讨:重载new和delete的好处 一般情况下,我们重载new和delete的目的是将内存创建和对象构造分隔开来。这样有什么好处呢?比如我们可以先创建一个大的内存,然后通过重载new函数将对象构造在这块内存中。当程序退出后,我们只要释放这个大内存即可。 另外,由于内存创建和释放与对象构造和析构分离了开来,对象构造完之后切记要析构,delete表达式只是帮助我们调用了对象的析构函数。如果像本例那样根本不调用delete的话,就需要程序员主动析构对象。 ART中,有些基础性的类重载了new和delete操作符,它们的实例就是用类似方式来创建的。以后我们会见到它们。 最后,new和delete是C++中比较复杂的一个知识点。关于这一块的内容,笔者觉得参考文献里列的几本书都没有说太清楚和全面。请意犹未尽的读者阅读如下两个链接的内容: http://en.cppreference.com/w/cpp/memory/new/operator_new http://en.cppreference.com/w/cpp/memory/new/operator_delete 函数调用运算符使得对象能像函数一样被调用,什么意思呢?我们知道C++和Java一样,函数调用的写法是“函数名(参数)”。如果我们把函数名换成某个类的对象,即“对象(参数)”,就达到了对象像函数一样被调用的目的。这个过程得以顺利实施的原因是C++支持函数调用运算符的重载,函数调用运算符就是“()”。 来看一个例子,如图37所示: 图37 operator ()重载示例 图37展示了operator ()重载的示例: ² 此操作符的重载比较简单,就和定义函数一样可以根据需要定义参数和返回值。 ² 函数调用操作符重载后,Obj类的实例对象就可以像函数一样被调用了。我们一般将这种能像函数一样被调用的对象叫做函数对象。图37也提到,普通函数是没有状态的,但是函数对象却不一样。函数对象首先是对象,然后才是可以像函数一样被调用。而对象是有所谓的“状态”的,比如图中的obj和obj1,两个对象的mX取值不同,这将导致外界传入一样的参数却得到不同的调用结果。 模板是C++语言中比较高级的一个话题。惭愧得讲,笔者使用C++、Java这么些年,极少自己定义模板,最多就是在使用容器类的时候会接触它们。因为日常工作中用得很少,所以对它的认识并不深刻。这一次由于ART代码中大量使用了模板,所以笔者也算是被逼上梁山,从头到尾仔细研究了C++中的模板。介绍模板具体知识之前,笔者先分享几点关于模板的非常重要的学习心得: 简而言之,对于模板而言,程序员需要重点关注两个事情,一个是对数据类型进行抽象,另一个是利用具体数据类型来绑定某个模板以将其实例化。 好了,让我们正式进入模板的世界,故事先从简单的函数模板开始。 提示: 模板编程是C++中非常难的部分,参考文献[4]用了六章来介绍与之相关的知识点。不管怎样,模板的核心依然是笔者前面提到的两点,一个是数据类型抽象,一个是实例化。 先来看函数模板的定义方法,如图38所示: 图38 函数模板的定义 图38所示为两个函数模板的定义,其中有几点需要读者注意: 提示: 图38中的函数模板定义中,template可以和其后的代码位于同一行,比如: template 建议开发者将其分成两行,因为这样的代码阅读起来会更容易一些。 下面继续讨论template和模板参数: 首先,可以定义任意多个模板参数,模板参数也可以像函数参数那样有默认值。 其次,函数的参数都有数据类型。类似,模板参数(如上面的T)也有类型之分: ² 代表数据类型的模板参数:用typename关键词标示,表示该参数代表数据类型,实例化时应传入具体的数据类型。比如typename T是一个代表数据类型的模板参数,实例化的时候必须用数据类型来替代T(或者说,T的取值为数据类型,比如int,long之类的)。另外,typename关键词也可以用class关键词替代,所以"template ² 非数据类型参数:非数据类型的参数支持整型、指针(包括函数指针)、引用。但是这些参数的值必须在实例化期间(也就是编译期)就能确定。 关于非类型参数,此处先展示一个简单的示例,后续介绍类模板时会碰到具体用法。 //下面这段代码中,T是代表数据类型的模板参数,N是整型,compare则是函数指针 //它们都是模板参数。 template<typename T,int N,bool (*compare)(constT & a1,const T &a2)> void comparetest(const T& a1,const T& a2){ cout<<"N="< compare(a1,a2);//调用传入的compare函数 } 图39所示为图38所定义的两个函数模板的实例化示例: 图39 函数模板的实例化 图39所示为add和add123这两个函数模板的实例化示意。结合前文反复强调的内容,函数模板的实例化就是当程序用具体数据类型来使用函数模板时,编译器将生成具体的函数: 上文介绍了函数模板的实例化,实例化就是指编译器进行类型推导,然后得到具体的函数。实例化得到的这些函数除了数据类型不一样之外,函数内部的功能是完全一样的。有没有可能为某些特定的数据类型提供不一样的函数功能? 显然,C++是支持这种做法的,这也被称为模板的特例化(英文简称specialization)。特例化就是当函数模板不太适合某些特定数据类型时,我们单独为它指定一套代码实现。 读者可能会觉得很奇怪,为什么会有这种需求?以图38中的add123为例,如果程序员传入的参数类型是指针的话,显然我们不能直接使用add123原函数模板的内容(那样就变成了两个指针值的相加),而应该单独实现一个针对指针类型的函数实现。要达到这个目的就需要用到特例化了。来看具体的做法,如图40所示: 图40 特例化示例 类模板的规则比函数模板要复杂,我们来看一个例子,如图41所示: 图41 类模板示例 图41中定义一个类模板,其语法格式和函数模板类型,class关键字前需要由template<模板参数>来修饰。另外,类模板中可以包含普通的成员函数,也可以有成员模板。这导致类模板的复杂度(包括程序员阅读代码的难度)大大增加。 注意: 普通类也能包含成员模板,这和函数模板类似,此处不拟详述。 接着来看类模板的特例化,它分为全特化和偏特化两种情况,如图42所示: 图42 类模板的全特化和偏特化 图42展示了类模板的全特化和偏特化,其中: 偏特化也叫部分特例化(partial specialization)。但笔者觉得“部分特例化”有些言不尽意,因为偏特化不仅仅包括“为部分模板参数指定具体类型”这一种情况,它还可以为模板参数指定某些特殊类型,比如: template //偏特化Test类模板,模板参数类型变成了T*。这就是偏特化的第二种表现形式 template 类模板的使用如图43所示: 图43 类模板使用示例 图43展示了类模式的使用示例。其中,值得关注的是C++11中程序员可通过using关键词定义类模板的别名。并且,使用类模板别名的时候可以指定一个或多个模板参数。 最后,类模板的成员函数也可以在类外(即源文件)中定义,不过这会导致代码有些难阅读,图44展示了如何在类外定义accessObj和compare函数: 图44 在源文件中定义类模板中的成员函数 图44中: 最后,关于类模板还有很多知识,比如友元、继承等在类模板中的使用。本书对于这些内容就不拟一一道来,读者以后可在碰到它们的时候再去了解。 C++11引入了lambda表达式(lambda expression),这比Java直到Java 8才正式在规范层面推出lambda表达式要早三年左右。lambda表达式和另一个耳熟能详的概念closure(闭包)密切相关,而closure最早被提出来的目的也是为了解决数学中的lambda演算(λ calculus)问题[⑧]。从严格语义上来说,closure和lambda表达式并不完全相同,不过一般我们可以认为二者描述得是同一个东西。 提示:closure和lambda的区别 关于二者的区别,读者可参考Effective C++作者Scott Meyers的一篇博文,地址如下: http://scottmeyers.blogspot.com/2013/05/lambdas-vs-closures.html 我们在“函数调用运算符重载”一节中曾介绍过函数对象,函数对象是那些重载了函数调用操作符的类的实例,和普通函数比起来: 通过上面的描述,我们知道函数对象的两个特点,一个是可以保存状态,另外一个是可以执行。不过,和函数一样,程序员要使用函数对象的话,首先要定义对应的类,然后才能创建该类的实例并使用它们。 现在我们来思考这样一个问题,可不可以不定义类,而是直接创建某种东西,然后可以执行它们? 以上问题的讨论就引出了C++中的lambda表达式,规范中没有明确说明lambda表达式是什么,但实际上它就是匿名函数对象。下面的代码展示了创建一个lambda表达式的语法结构: auto f = [ 捕获列表,英文叫capture list ] ( 函数参数 ) ->返回值类型 { 函数体 } 其中: 下面我们通过例子进一步来认识lambda表达式,来看图45: 图45 lambda表达式示例(1) 图45 lambda表达式示例(2) 图45展示了lambda表达式的用法: 图45所示例子的捕获列表显示指定了要捕获的变量。如果变量比较多的话,要一个一个写上变量名会变得很麻烦,所以lambda表达式还有更简单的方法来捕获所有变量,如下所示: 此处仅关注捕获列表中的内容 [=,&变量a,&变量b] = 号表示按值的方式捕获该lambda创建时所能看到的全部变量。如果有些变量需要通过引用方式来捕获的话就把它们单独列出来(变量前带上&符号) [&,变量a,变量b] &号表示按引用方式捕获该lambda创建时所能看到的全部变量。如果有些变量需要通过按值方式来捕获的话就把它们单独列出来(变量前不用带上=号) STL是StandardTemplate Library的缩写,英文原意是标准模板库。由于STL把自己的类和函数等都定义在一个名为std(std即standard之意)的命名空间里,所以一般也称其为标准库。标准库的重要意义在于它提供了一套代码实现非常高效,内容涵盖许多基础功能的类和函数,比如字符串类,容器类,输入输出类,多线程并发类,常用算法函数等。虽然和Java比起来,C++标准库涵盖的功能并不算多,但是用法却非常灵活,学习起来有一定难度。 熟练掌握和使用C++标准库是一个合格C++程序员的重要标志。对于标准库,笔者感觉是越了解其内部的实现机制越能帮助程序员更好得使用它。所以,参考文献[2]几乎是C++程序员入门后的必读书了。 STL的内容非常多,本节仅从API使用的角度来介绍其中一些常用的类和函数,包括: STL string类和Java String类很像。不过,STL的string类其实只是模板类basic_string的一个实例化产物,STL为该模板类一共定义了四种实例化类,如图46所示: 图46 string的家族 图46中: string类的完整API可参考http://www.cplusplus.com/reference/string/string/?kw=string。其使用和Java String有些类似,所以上手难度并不大。图47中的代码展示了string类的使用: 图47 string类的使用 好在Java中也有容器类,所以C++的容器类不会让大家感到陌生,表1对比了两种语言中常见的容器类。 表1 容器类对比 容器类型 STL类名 Java类(仅用于参考) 说明 动态数组 vector ArrayList 动态大小的数组,随机访问速度快 链表 list LinkedList 一般实现为双向链表 集合 set,multiset SortedSet 有序集合,一般用红黑树来实现。set中没有值相同的多个元素,而multiset允许存储值相同的多个元素 映射表 map、multimap SortedMap 按Key排序,一般用红黑树来实现。map中不允许有Key相同的多个元素,而multimap允许存储Key相同的多个元素 哈希表 unordered_map HashedMap 映射表中的一种,对Key不排序 本节主要介绍表1中vector、map这两种容器类的用法以及Allocator的知识。关于list、set和unordered_map的详细用法,读者可阅读参考文献[2]。 提示: list、set和unordered_map的在线API查询链接: list的API:http://en.cppreference.com/w/cpp/container/list set的API:http://en.cppreference.com/w/cpp/container/set unordered_map的API:http://en.cppreference.com/w/cpp/container/unordered_map vector是模板类,使用它之前需要包含 图48 vector用法示例 图48中有三个知识点需要读者注意: 关于vector的知识我们就介绍到此。 注意: 再次提醒读者,STL容器类的学习绝非知道几个API就可以的,其内部有相当多的知识点需要注意才能真正用好它们。强烈建议有进一步学习欲望的读者研读参考文献[2]。 map也叫关联数组。图49展示了map类的情况: 图49 map类 图49中: 讨论:Compare和Allocator map类的声明中,Compare和Allocator虽然都是模板参数,但很明显不能随便给它们设置数据类型,比如Compare和Allocator都取int类型可以吗?当然不行。实际上,Compare应该被设置成这样一种类型,这个类型的变量是一个函数对象,该对象被执行时将比较两个Key的大小。map为Compare设置的默认类型为std::less 同理,Allocator模板参数也不能随便设置成一种类型。后文将继续介绍Allocator。 图50展示了map类的用法: 图50 map的用法展示 图50定义了一个key和value类型都是string的map对象,有两种方法为map添加元素: map默认的Compare模板参数是std::less,它将按从小到大对key进行排序,如何为map指定其他的比较方式呢?来看图51: 图51 map的用法之Compare 图51展示了map中和Compare模板参数有关的用法,其中: Java程序员在使用容器类的时候从来不会考虑容器内的元素的内存分配问题。因为Java中,所有元素(除int等基本类型外)都是new出来的,容器内部无非是保存一个类似指针这样的变量,这个变量指向了真实的元素位置。 这个问题在C++中的容器类就没有这么简单了。比如,我们在栈上构造一个string对象,然后把它加到一个vector中去。vector内部是保存这个string变量的地址,还是在内部构造一个新的存储区域,然后将string对象的内容保存起来呢?显然,我们应该选择在内部构造一个区域,这个区域存储string对象的内容。 STL所有容器类的模板参数中都有一个Allocator(译为分配器),它的作用包括分配内存、构造对应的对象,析构对象以及释放内存。STL为容器类提供了一个默认的类,即std::allocator。其用法如图52所示: 图52 allocator的用法 图52展示了allocator模板类的用法,我们可以为容器类指定自己的分配器,它只要定义图52中的allocate、construct、destory和deallocate函数即可。当然,自定义的分配器要设计好如何处理内存分配、释放等问题也是一件很考验程序员功力的事情。 提示: ART中也定义了类似的分配器,以后我们会碰到它们。 STL还为C++程序员提供了诸如搜索、排序、拷贝、最大值、最小值等算法操作函数以及一些诸如less、great这样的函数对象。本节先介绍算法操作函数,然后介绍STL中的函数对象。 STL中要使用算法相关的API的话需要包含头文件 表2 ART源码中常用的算法函数 函数名 作用 fill fill_n fill:为容器中指定范围的元素赋值 fill_n:为容器内指定的n个元素赋值 min/max 返回容器某范围内的最小值或最大值 copy 拷贝容器指定范围的元素到另外一个容器 accumulate 定义于 sort 对容器类的元素进行排序 binary_search 对已排序的容器进行二分查找 lexicographical_compare 按字典序对两个容器内内指定范围的元素进行比较 equal 判断两个容器是否相同(元素个数是否相等,元素内容是否相同) remove_if 从容器中删除满足条件的元素 count 统计容器类满足条件的元素的个数 replace 替换容器类旧元素的值为指定的新元素 swap 交换两个元素的内容 图53展示了表2中一些函数的用法: 图53 fill、copy和accumulate等算法函数示例 图53中包含一些知识点需要读者了解: 提示: STL的迭代器也是非常重要的知识点,由于本书不拟介绍它。请读者阅读相关参考文献。 接着来看图54,它继续展示了算法函数的使用方法: 图54 sort、binary_search等函数使用示例 图54中remove_if函数向读者生动展示了要了解STL细节的重要性: 是不是有种要抓狂的感觉?这个问题怎么破解呢?当使用者remove_if调用完毕后,务必要通过erase来移除容器中逻辑上不再需要的元素,代码如下: //newEnd和end()之间是逻辑上被remove的元素,我们需要把它从容器里真正移除! aIntVector.erase(newEnd,aIntVector.end()); 最后,关于 http://en.cppreference.com/w/cpp/header/algorithm STL中要使用函数对象相关的API的话需要包含头文件 表2 ART源码中常用的算法函数 类或函数名 作用 bind 对可调用对象进行参数绑定以得到一个新的可调用对象。详情见正文 function 模板类,图51中介绍过,用于得到一个重载了函数调用对象的类 hash 模板类,用于计算哈希值 plus/minus/multiplies 模板类,用于计算两个变量的和,差和乘积 equal_to/greater/less 模板类,用于比较两个数是否相等或大小 函数对象的使用相对比较简单,图55、图56给出了几个示例: 图55 bind函数使用示例 图55重点介绍了bind函数的用法。如图中所说,bind是一个很奇特的函数,其主要作用就是对原可调用对象进行参数绑定从而得到一个新的可调用对象。bind的参数绑定规则需要了解。另外,占位符_X定义在std下的placeholders命名空间中,所以一般要用placeholders::_X来访问占位符。 图56展示了有关函数对象的其他一些简单示例: 图56 函数对象的其他用例 图56展示了: 最后,关于 http://en.cppreference.com/w/cpp/header/functional 提示: 从容器类和算法以及函数对象来看,STL的全称标准模板库是非常名符其实的,它充分利用了和发挥了模板的威力。 我们在本章1.3.3“->和*操作符重载”一节中曾介绍过智能指针类。C++11此次在STL中推出了两个比较常用的智能指针类: shared_ptr和unqiue_ptr的思想其实都很简单,就是借助引用计数的概念来控制内存资源的生命周期。相比shared_ptr的共享式指针管理,unique_ptr的引用计数最多只能为1罢了。 注意:环式引用问题 虽然有shared_ptr和unique_ptr,但是C++的智能指针依然不能做到Java那样的内存自动回收。并且,shared_ptr的使用也必须非常小心,因为单纯的借助引用计数无法解决环式引用的问题,即A指向B,B指向A,但是没有别的其他对象指向A和B。这时,由于引用计数不为0,A和B都不能被释放。 下面分别来看shared_ptr和unique_ptr的用法。 图57为shared_ptr的用法示例,难度并不大: 图57 shared_ptr用法示例 图57中: 关于shared_ptr更多的信息,请参考:http://en.cppreference.com/w/cpp/memory/shared_ptr ART中使用unique_ptr远比shared_ptr多,它的用法比shared_ptr更简单,如图58所示: 图58 unique_ptr用法示例 关于unique_ptr完整的API列表,请参考http://en.cppreference.com/w/cpp/memory/unique_ptr 本章对STL进行了一些非常粗浅的介绍。结合笔者个人的学习和使用经验,STL初看起来是比较容易学的。因为它更多关注的是如何使用STL定义好的类或者函数。从“使用现成的API”这个角度来看,有Java经验的读者应该毫不陌生。因为Java平台从诞生之初就提供了大量的功能类,熟练的java程序员使用它们时早已能做到信手拈来。同理,C++程序员初学STL时,最开始只要做到会查阅API文档,了解API的用法即可。 但是,正如前面介绍copy、remove_if函数时提到的那样,STL的使用远比掌握API的用法要复杂得多。STL如果要真正学好、用好,了解其内部大概的实现是非常重要的。并且,这个重要性不仅停留在“可以写出更高效的代码”这个层面上,它更可能涉及到“避免程序出错,内存崩溃等各种莫名其妙的问题”上。这也是笔者反复强调要学习参考文献[2]的重要原因。另外,C++之父编写的参考文献[3]在第IV部分也对STL进行了大量深入的介绍,读者也可以仔细阅读。 要研究STL的源码吗? 对绝大部分开发者而言,笔者觉得研究STL的源码必要性不大。http://en.cppreference.com网站中会给出有些API的可能实现,读者查找API时不妨了解下它们。 本节介绍ART代码中其他一些常见知识。 initializer_list和C++11中的一种名为“列表初始化”的技术有关。什么是列表初始化呢?来看一段代码: vector vector 上面代码中,intvect和strvect的初值由两个花括号{}和里边的元素来指定。C++11中,花括号和其中的内容就构成一个列表对象,其类型是initializer_list,也属于STL标准库。 initializer_list是一个模板类,花括号中的元素的类型就是模板类型。并且,列表中的元素的数据类型必须相同。 另外,如果类创建的对象实例构造时想支持列表方式的话,需要单独定义一个构造函数。我们来看几段代码: class Test{ public: //①定义一个参数为initializer_list的构造函数 Test(initializer_list //②遍历initializer_list,它也是一种容器 for(auto item:a_list){ cout<<”item=”< } } } Test a = {1,2,3,4};//只有Test类定义了①,才能使用列表初始化构造对象 initializer_list using ILIter =initializer_list //③通过iterator遍历initializer_list for(ILIter iter =strlist.begin();iter != strlist.end();++iter){ cout<<”item = ” << *iter<< endl; } enum应该是广大程序员的老相识了,它是一个非常古老,使用广泛的关键词。不过,C++11中enum有了新的变化,我们通过两段代码来了解它: //C++11之前的传统enum,C++11继续支持 enum Color{red,yellow,green}; //C++11之后,enum有一个新的形式:enum class或者enum struct enum class ColorWithScope{red,yellow,green} 由上述代码可知,C++11为古老的enum添加了一种新的形式,叫enum class(或enum struct)。enum class和Java中的enum类似,它是有作用域的,比如: //对传统enum而言: int a_red = red;//传统enum定义的color仅仅是把一组整型值放在一起罢了 //对enum class而言,必须按下面的方式定义和使用枚举变量。 //注意,green是属于ColorWithScope范围内的 ColorWithScopea_green = ColorWithScope::green;//::是作用域符号 //还可以定义另外一个NewColor,这里的green则是属于AnotherColorWithScope范围内 enum class AnotherColorWithScope{green,red,yellow}; //同样的做法对传统enum就不行,比如下面的enum定义将导致编译错误, //因为green等已经在enum Color中定义过了 enum AnotherColor{green,red,yellow}; const一般翻译为常量,它和Java中的final含义一样,表示该变量定义后不能被修改。但C++11在const之外又提出了一个新的关键词constexpr,它是constexpression(常量表达式)的意思。constexpr有什么用呢?很简单,就是定义一个常量。 读者一定会觉得奇怪,const不就是用于定义常量的吗,为什么要再来一个constexpr呢?关于这个问题的答案,让我们通过例子来回答。先看下面两行代码: const int x = 0;//定义一个整型常量x,值为0 constexpr int y =1; //定义一个整型常量y,值为1 上面代码中,x和y都是整型常量,但是这种常量的初值是由字面常量(0和1就是字面常量)直接指定的。这种情况下,const和constexpr没有什么区别(注意,const和constexpr的变量在指向指针或引用型变量时,二者还是有差别,此处不表)。 不过,对于下面一段代码,二者的区别立即显现了: int expr(int x){//测试函数 if(x == 1) return 0; if(x == 2) return 1; return -1; } const int x = expr(9); x = 8;//编译错误,不能对只读变量进行修改 constexpr int y = expr(1);//编译错误,因为expr函数不是常量表达式 上面代码中: 所以,constexpr关键词定义的变量一定是一个常量。如果等号右边的表达式不是常量,那么编译器会报错。 提示: 常量表达式的推导工作是在编译期决定的。 assert,也叫断言。程序员一般在代码中一些关键地方加上assert语句用以检查参数等信息是否满足一定的要求。如果要求达不到,程序会输出一些警告语(或者直接异常退出)。总之,assert是一种程序运行时做检查的方法。 有没有一种方法可以让程序员在代码的编译期也能做一些检查呢?为此,C++11推出了static_assert,它的语法如下: static_assert (bool_constexpr , message ) 当bool_constexpr返回为false的时候,编译器将报错,报错的内容就是message。注意,这都是在编译期间做的检查。 读者可能会好奇,什么场合需要做编译期检查呢?举个最简单的例子。假设我们编写了一段代码,并且希望它只能在32位的机器上才能编译。这时就可以利用static_assert了,方法如下: static_assert(sizeof(void*) == 4,”can only be compiled in32bit machine”); 包含上述语句的源码文件在64位机器上进行编译将出错,因为64位机器上指针的字节数是8,而不是4。 本章对C++语言(以C++11的名义)进行了浮光掠影般的介绍。其内容不全面,细节不深入,描述更谈不上精准。不过,本章的目的在于帮助Java程序员、不熟悉C++11但是接触过C++98/03的程序员对C++11有一个直观的认识和了解,这样我们将来分析ART代码时才不会觉得陌生。对于那些有志于更进一步学习C++的读者们,下面列出的五本参考书则是必不可少的。 作者是Stanley B.Lippman等人,译者为王刚,杨巨峰等,由电子工业出版社出版。如果对C++完全不熟悉,建议从这本书入门。 作者是Nicolai M.Josuttis,此书中文版译者是台湾著名的IT作家侯捷。C++标准库即是TL(Standard Template Library,标准模板库)。相比Java这样的语言,C++其实也提供了诸如容器,字符串,多线程操作(C++11才正式提供)等这样的标准库。 作者是C++之父Bjarne Stroustrup,目前只有英文版。这本书写得很细,由于是英文版,所以读起来也相对费事。另外,书里的示例代码有些小错误。 作者Anthony Williams。C++11标准库增加了对多线程编程的支持,如果打算用C++11标准库里的线程库,请读者务必阅读此书。这本书目前只有英文版。说实话,笔者看完这本书前5章后就不打算继续看下去了。因为C++11标准库对多线程操作进行了高度抽象的封装,这导致用户在使用它的时候还要额外去记住C++11引入的特性,非常麻烦。所以,我们在ART源码中发现谷歌并未使用C++11多线程标准库,而是直接基于操作系统提供的多线程API进行了简单的,面向对象的类封装。 作者是Mical Wang和IBM XL编译器中国开发团队,机械工业出版社出版。 作者祁宇,机械工业出版社出版 [5],[6]这两本书都是由国人原创,语言和行文逻辑更符合国人习惯。相比前几本而言,这两本书主要集中在C++11的新特性和应用上,读者最好先有C++11基础再来看这两本书。 建议读者先阅读[5]。注意,[5]还贴心得指出每一个C++11的新特性适用于那种类别的开发者,比如所有人,部分人,类开发者等。所有,读者应该根据自己的需要,选择学习相关的新特性,而不是尝试一股脑把所有东西都学会。 [①] C++98规范是于1998年落地的关于C++语言的第一个国际标准(ISO/IEC15882:1998)。而C++03则是于2003年定稿的第二个C++语言国际标准(ISO/IEC15882:2003)。由于C++03只是在C++98上增加了一些内容(主要是新增了技术勘误表,Technical Corrigendum 1,简称TC1),所以之后很长一段时间内,人们把C++规范通称为C++98/03。 [②] 无独有偶,C++之父Bjarne Stroustrup也曾说过“C++11看起来像一门新的语言”[3]。 [③] 什么样的系统算业务系统呢?笔者也没有很好的划分标准。不过以Android为例,LinuxKernel,视音频底层(Audio,Surface,编解码),OpenGLES等这些对性能要求非常高,和硬件平台相关的系统可能都不算是业务系统。 [④] 没有nullptr之前,系统或程序员往往会定义一个NULL宏,比如#define NULL (0),不过这种方式存在一些问题,所以C++11推出了nullptr关键词。 [⑤] 虽然代码中使用的是引用,但很多编译器其实是将引用变成了对应的指针操作。 [⑥] Java中,String对象是支持+操作的,这或许是Java中唯一的“操作符重载”的案例。 [⑦] 此处描述并不完全准确。对于STL标准库中某些类而言,<<和>>是可以实现为类的成员函数的。但对于其他类,则不能实现为类的成员函数。 [⑧] 关于closure的历史,请阅读https://en.wikipedia.org/wiki/Closure_(computer_programming) [⑨] 编译器可能会将lambda表达式转换为一个重载了函数调用操作符的类。如此,变量f就是该类的实例,其数据类型随之确定。

2. 构造和析构函数的调用次序
3. 编译器合成的函数
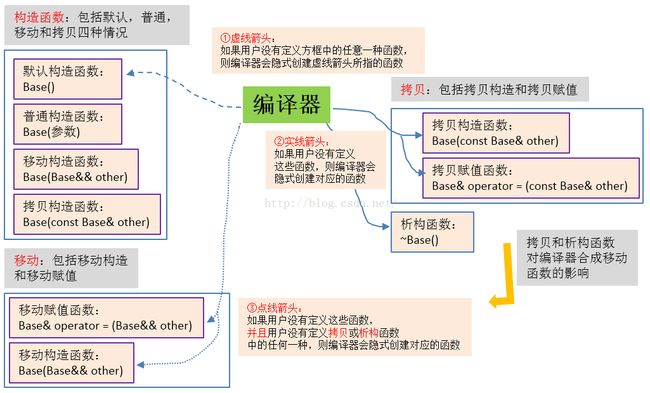
(1) =default和=delete
(2) “继承”基类的构造函数

1.3.3 友元和类的前向声明

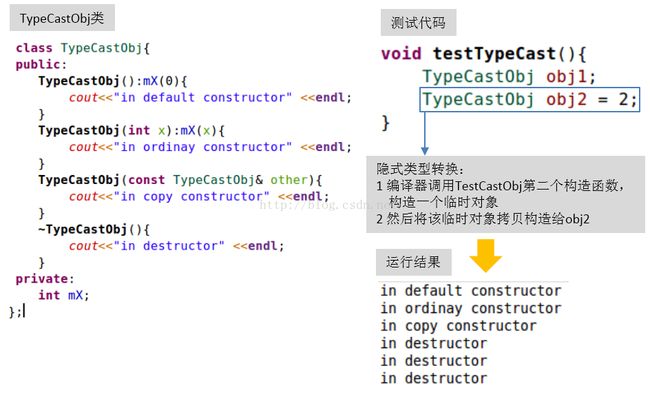
1.3.4 explicit构造函数
1.3.5 C++中的struct
1.4 操作符重载
1.4.1 操作符重载的实现方式

1.4.2 输出和输入操作符重载


1.4.3 ->和*操作符重载

1.4.4 new和delete操作符重载
1. new和delete操作符语法



2. new和delete操作符重载示例

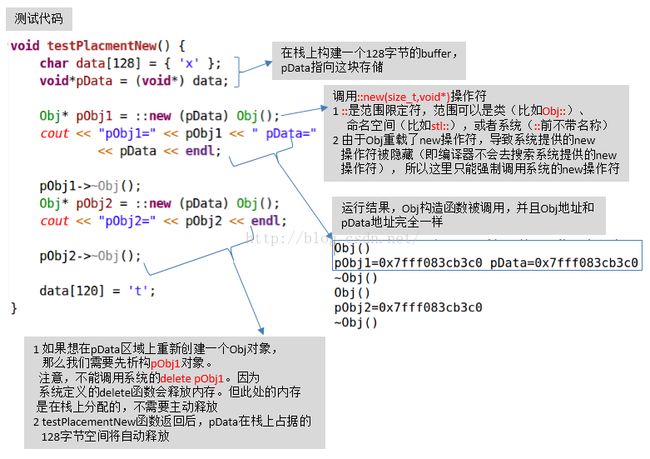
3. 如何在指定内存中构造对象
1.4.5 函数调用运算符重载

1.5 函数模板与类模板
1.5.1 函数模板
1. 函数模板的定义

2. 函数模板的实例化

3. 函数模板的特例化

1.5.2 类模板
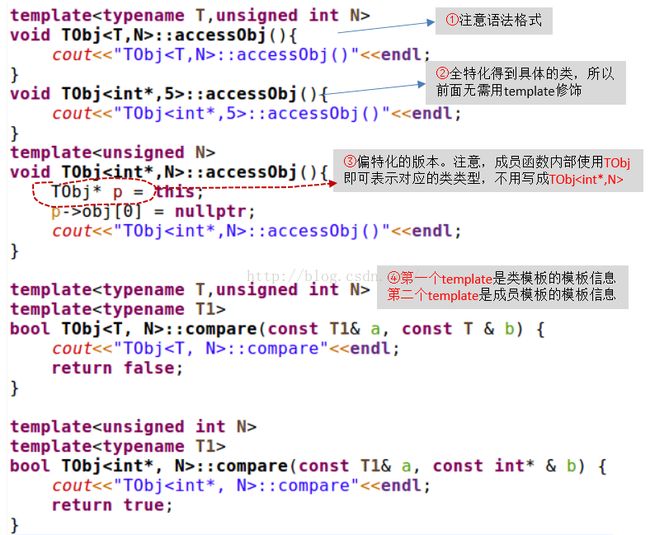
1. 类模板定义和特例化


2. 类模板的使用

1.6 lambda表达式


1.7 STL介绍
1.7.1 string类


1.7.2 容器类
1. vector类

2. map类
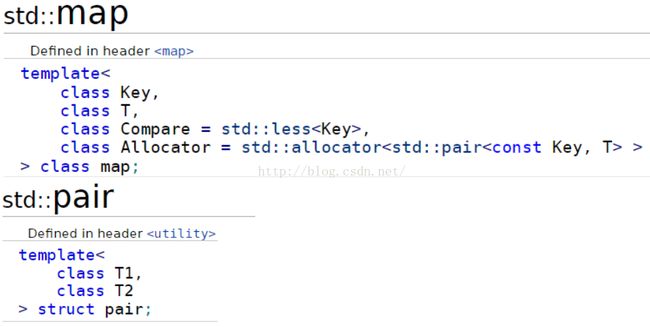


3. allocator介绍

1.7.3 算法和函数对象介绍
1. 算法


2. 函数对象


1.7.4 智能指针类
1. shared_ptr介绍

2. unique_ptr介绍

1.7.5 探讨STL的学习
1.8 其他常用知识
1.8.1 initializer_list
1.8.2 带作用域的enum
1.8.3 constexpr
1.8.4 static_assert
1.9 参考文献
[1] C++ Primer中文版第5版
[2] C++标准库第二版
[3] The C++Programming Language 4th Edition
[4] C++ ConcurrencyIn Action
[5] 深入理解C++11:C++11新特性解析与应用
[6] 深入应用C++11代码优化与工程级应用