Windows10下实现Faster R-cnn+Tensorflow+python且训练自己的数据集
文章目录
- 背景
- 小试牛刀--训练
- 基础操作
- VOC_2007数据集
- 下载模型
- 惊心动魄--测试
- 修改部分代码
- 修改训练模型位置
- 测试
- 训练自己的数据集
- 前言
- 文件结构
- 制作自己的数据集
- JPEGImages文件夹
- Annotations文件夹
- ImageSets文件夹
- 其余两个文件夹不需要操作
- LabelImg标记大法
- 生成txt文件
- 修改代码--训练
- 修改代码--测试
- tensorboard进行可视化
- 结束语
背景
为了满足项目中目标检测需要,而Faster R-CNN最大的亮点在于提出了一种有效定位目标区域的方法,然后按区域在特征图上进行特征索引,大大降低了卷积计算的时间消耗,所以速度上有了非常大的提升。并且准确率相对较高,所以博主准备采坑Faster R-cnn。本博文先采坑Faster R-cnn流程,即复现,然后针对自己的数据集,进行训练并测试,实现初步需要。
附本博文采用的源码地址:https://github.com/dBeker/Faster-RCNN-TensorFlow-Python3.
特别强调:此github项目也适用于python3.6。后文有相应操作
本文默认读者已经配置好了tensorflow-gpu环境,未配置的客官详见:https://blog.csdn.net/shangzhihaohao/article/details/89766368.
小试牛刀–训练
基础操作
这一步骤根据github的Reademe部分向下进行:
1.安装必要的安装包:cython, python-opencv, easydict,通过pip命令安装在你的tensorflow-gpu环境下的python中
2.进入到data/coco/Python文件夹中打开命令窗口(即cmd)运行两个python文件,分别运行:
python setup.py build_ext --inplace
python setup.py build_ext install
这步可能会出现“error: Unable to find vcvarsall.bat”错误,因为源码是基于python3.5编译,而在python3.6下运行就会报错,所以必须在python3.6环境下重新编译。首先要安装Visual Studio2015,然后执行代码进行再次编译
python setup.py build_ext --inplace
这里可能还会有错误,具体我忘了,如果有错误评论区见~~~到这里基础操作告一段落
VOC_2007数据集
下载数据集参考:VOC_2007数据集.
在这里也给出具体操作流程:
1.打开某网页在地址栏分别输入
http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtrainval_06-Nov-2007.tar
http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtest_06-Nov-2007.tar
http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCdevkit_08-Jun-2007.tar
将压缩包下载到相应文件夹下,我下载到了data文件夹下
2.将压缩包解压在data文件夹下的一个新建的文件夹并将文件夹重命名为VOCdevkit2007
此时文件结构为:

别问为什么把结构放上,问就是我之前好想看好想看结构,生怕自己错了,就是没有!!!()
下载模型
下载预训练模型VGG16网络和其他你感兴趣的网络,下载地址: https://github.com/tensorflow/models/tree/master/research/slim#pre-trained-models.
在data文件夹下新建imagenet_weights文件夹,将下载好的网络放到此文件夹下。注意要将vgg_16.ckpt重命名为vgg16.ckpt
文件结构:
训练之前修改lib.config.config.py下的代码,在第30行的max_iters中将40000修改成10000,能节省点时间。此时可以运行train.py文件了,此处建议先修改lib.config.config.py下的代码tf.app.flags.DEFINE_integer(‘snapshot_iterations’, 5000, “Iteration to take snapshot”),将5000改成1000,这个意思是每迭代1000次存储一次模型。(config.py文件是定义默认参数的python文件,想调什么超参数一般都会在这个文件中)。不出意外的话,模型训练成功是时间的问题,最后训练出来的模型会存储在default\voc_2007_trainval\default文件夹下,如图:

惊心动魄–测试
修改部分代码
首先进入demo.py文件,修改几处代码:
1.39行的vgg16_faster_rcnn_iter_70000.ckpt修改为vgg16_faster_rcnn_iter_10000.ckpt
2.由于本文是复现VGG16模型,所以将demo.py的第108行原来默认的res101,改成我们现在用的vgg16。
3.110行的default='pascal_voc_0712’改为pascal_voc
修改训练模型位置
在根目录下新建output/vgg16/voc_2007_trainval/default,将训练好的第10000次的模型放入此文件夹中,结构如图:
测试
运行demo.py,不出意外的话,出现很多个下图所示的画面:

为了使其显示在同一张图片上。只修改了demo.py文件中的vis_detections 与demo俩个函数中小小的一部分,代码如下
def vis_detections(ax, class_name, dets, thresh=0.5):
"""Draw detected bounding boxes."""
inds = np.where(dets[:, -1] >= thresh)[0]
if len(inds) == 0:
return
for i in inds:
bbox = dets[i, :4]
score = dets[i, -1]
ax.add_patch(
plt.Rectangle((bbox[0], bbox[1]),
bbox[2] - bbox[0],
bbox[3] - bbox[1], fill=False,
edgecolor='red', linewidth=3.5)
)
ax.text(bbox[0], bbox[1] - 2,
'{:s} {:.3f}'.format(class_name, score),
bbox=dict(facecolor='blue', alpha=0.5),
fontsize=14, color='white')
plt.axis('off')
plt.tight_layout()
plt.draw()
def demo(sess, net, image_name):
"""Detect object classes in an image using pre-computed object proposals."""
# Load the demo image
im_file = os.path.join(cfg.DATA_DIR, 'demo', image_name)
im = cv2.imread(im_file)
# Detect all object classes and regress object bounds
timer = Timer()
timer.tic()
scores, boxes = im_detect(sess, net, im)
timer.toc()
print('Detection took {:.3f}s for {:d} object proposals'.format(timer.total_time, boxes.shape[0]))
# Visualize detections for each class
CONF_THRESH = 0.8
NMS_THRESH = 0.3
im = im[:, :, (2, 1, 0)]
fig, ax = plt.subplots(figsize=(12, 12))
ax.imshow(im, aspect='equal')
plt.ion()
for cls_ind, cls in enumerate(CLASSES[1:]):
cls_ind += 1 # because we skipped background
cls_boxes = boxes[:, 4 * cls_ind:4 * (cls_ind + 1)]
cls_scores = scores[:, cls_ind]
dets = np.hstack((cls_boxes,
cls_scores[:, np.newaxis])).astype(np.float32)
keep = nms(dets, NMS_THRESH)
dets = dets[keep, :]
vis_detections(ax, cls, dets, thresh=CONF_THRESH)
至此,复现成功!
文章复现部分可能会遇到我没遇到过的情概况,也可能有一些我遇到过但是忘记写在博文里的问题,评论,我捞你。然后在将遗漏的问题补充到博文中。
训练自己的数据集
前言
利用Faster R-cnn等深度网络训练自己的数据集一般都是将自己的数据格式修改成VOC2007的格式,之前在VOC_2007数据集中我们已经下载下来了。
文件结构
解压VOC2007数据集后可以看到VOC2007文件夹下有以下5个文件夹,分别是:
-
Annotations
该文件下存放的是xml格式的标签文件,每个xml文件都对应于JPEGImages文件夹的一张图片。XML前面部分声明图像数据来源,大小等元信息 -
JPEGImages
此文件夹下存放的是你数据集图片,包括训练和测试图片。格式必须是JPG格式,这个要特别注意!如果你打算使用VO2007格式生成数据,那么原始图像格式在采样时候请用JPG格式保存,这些图像的像素尺寸大小不一,但是横向图的尺寸大约在500375左右,纵向图的尺寸大约在375500左右,基本不会偏差超过100。(在之后的训练中,第一步就是将这些图片都resize到300300或是500500,所有原始图片不能离这个标准过远。 -
ImageSets
该文件夹下存放了三个文件,分别是Layout、Main、Segmentation。Layout中的txt文件表示包含Layout标注信息的图像文件名列表,Main文件夹中包含20个类别每个类别一个txt文件,每个txt文件都是包含该类别的图像文件名称列表,Segmentation则是包含语义分割信息图像文件的列表。在这里我们只用存放图像数据的Main文件,其他两个暂且不管。
Main文件夹下包含了每个分类的train.txt、val.txt和trainvaltxt、test.txt
train.txt表示是的训练数据集合
val.txt 表示验证集数据
trainval.txt表示训练与验证集数据
test.txt表示测试集数据
这些txt中的内容都差不多如下:
000005 -1
000007 -1
000009 1
000016 -1
000019 -1
前面的表示图像的name,后面的1代表正样本,-1代表负样本。
需要保证的是train和val两者没有交集,也就是训练数据和验证数据不能有重复,在选取训练数据的时候 ,也应该是随机产生的。
- SegmentationClass文件和SegmentationObject
这两个文件都是与图像分割相关,跟本文无关,暂且不管。
制作自己的数据集
JPEGImages文件夹
1.清空JPEGImages文件夹下的原有图片数据,将自己项目或实验准备的图像数据放到该文件夹中(JPG格式),也可以后期通过代码改变图片存储格式。
2.resize:
在实际的应用中,这个数据集肯定是自己项目里面拍摄的。
首先,拍摄的图片可能分辨率太大,不利于训练,通过一顿操作把他们差不多缩小到跟voc数据集里的图片差不多大小。通过以下代码实现:
# coding=utf-8
import os # 打开文件时需要
from PIL import Image
import re
Start_path = 'D:/1Aqilei/photos/' # 你的图片目录
width_max = 375 # 图片最大宽度
depth_max = 500 # 图片最大高度
list = os.listdir(Start_path)
# print list
count = 0
for pic in list:
path = Start_path + pic
print(path)
im = Image.open(path)
w, h = im.size
print (w,h)
#如果图片分辨率超过这个值,进行图片的等比例压缩
if w > width_max:
print(pic)
print("图片名称为" + pic + "图片被修改")
h_new = width_max * h // w
w_new = width_max
count = count + 1
out = im.resize((w_new, h_new), Image.ANTIALIAS)
new_pic = re.sub(pic[:-4], pic[:-4] , pic)
# print new_pic
new_path = Start_path + new_pic
out.save(new_path)
if h > depth_max:
print(pic)
print("图片名称为" + pic + "图片被修改")
w_new = depth_max * w // h
h_new = depth_max
count = count + 1
out = im.resize((w_new, h_new), Image.ANTIALIAS)
new_pic = re.sub(pic[:-4], pic[:-4] , pic)
# print new_pic
new_path = Start_path + new_pic
out.save(new_path)
print('END')
count = str(count)
print("共有" + count + "张图片尺寸被修改")
3.rename: 将图片重命名统一修改成0000001.jpg格式,代码如下:
import os
path = "D:\\1Aqilei\\data"
filelist = os.listdir(path) #该文件夹下所有的文件(包括文件夹)
count=0
for file in filelist:
Olddir = os.path.join(path, file) # 原来的文件路径
if os.path.isdir(Olddir): # 如果是文件夹则跳过
continue
filename = os.path.splitext(file)[0] # 文件名
filetype = os.path.splitext(file)[1] # 文件扩展名
print(filename)
Newdir = os.path.join(path, str(count).zfill(5) + filetype) # 用字符串函数zfill 以0补全所需位数
os.rename(Olddir, Newdir) # 重命名
count += 1
# os.path.splitext(“文件路径”) 分离文件名与扩展名;默认返回(fname,fextension)元组,可做分片操作
print ('END')
count=str(count)
print("共有"+count+"张图片尺寸被修改")
4.如果需要对数据进行其他预处理,都可以通过代码进行实现,但要注意的是,一定要把rename这一步骤放在最后进行!!!
Annotations文件夹
针对此文件夹,首先删除里面所有的xml文件,然后放入通过labelImg对JPEGImages文件夹中数据集标注后,自动产生的相应的xml文件。后面会有对数据集进行标注的具体讲解
ImageSets文件夹
针对此文件夹,首先删除Layout文件夹,Segmentation文件夹下的所有txt文件,(因为用不到,我不知道不删除会不会有影响,大家可以试一试,我个人认为不删也没有影响)然后针对Main文件夹,删除所有的txt文件,后面会详细介绍生成对应四个txt(还记得是那四个txt吗?)的详细操作以及代码。
其余两个文件夹不需要操作
LabelImg标记大法
想要训练自己的数据集,对数据集进行标注是重要且很烦的过程(对于特别大的数据集,急需解决大规模数据集标注的问题,如果有好的方法,评论或私信给博主!!不发牢骚了进入正题)
传送门:https://github.com/tzutalin/labelImg.
对于很多人第一次接触可能不会用(没错就是我),首先将直接download下来,解压到某个文件夹,然后进入改文件夹,直接运行labelImg.py就可以了然后类似这样:
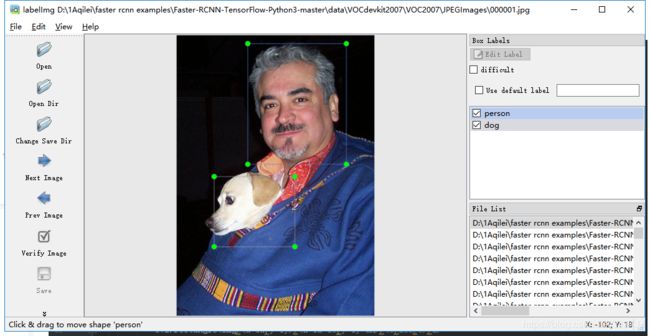
具体细节怎么标注就不详细介绍了,请自行百度。(算了,贴出来)
有一点注意是:想改变标注文件夹位置
点击Menu/File中的Change default saved annotation folder这里。我们一般会将标注之后生成的对应图片的xml文件放到上面提到的Annotations文件夹中。
生成txt文件
接下来要生成ImageSet/Main下的四个txt文件,分别是train.txt,val.txt,trainval_txt,text.txt,具体实现方法见下面代码:
# !/usr/bin/python
# -*- coding: utf-8 -*-
import os
import random
trainval_percent = 0.8 #trainval占整个数据集的百分比,剩下部分就是test所占百分比
train_percent = 0.7 # train占trainval的百分比,剩下部分就是val所占百分比
xmlfilepath = 'D:/1Aqilei---npupt/Faster-RCNN-TensorFlow-Python3-master/data/VOCdevkit2007/VOC2007/Annotations'
txtsavepath = 'D:/1Aqilei---npupt/Faster-RCNN-TensorFlow-Python3-master/data\VOCdevkit2007/VOC2007/ImageSets/Main'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open(txtsavepath+'/trainval.txt', 'w')
ftest = open(txtsavepath+'/test.txt', 'w')
ftrain = open(txtsavepath+'/train.txt', 'w')
fval = open(txtsavepath+'/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
此代码是python代码,使用matlab代码请进入matalb代码生成txt文件,下载后更改下VOC2007txt.m中d 路径就能用了。
此时数据集制作完成。接下来的工作就快接近尾声了!
修改代码–训练
1.进入 lib\datasets\pascal_voc.py中更改self._classes中的类别,注意,’'background’要保留,更改其余的类别。
2.进入lib/config/config.py中修改迭代次数30行的最大迭代次数,修改成你希望的次数;第44行修改迭代多少次保存一次模型,建议1000
3…在…\Faster-RCNN\data目录下,检查是否有个叫cache的文件夹,每次在训练模型前,清空这个文件夹里面的内容。
4.在开始训练之前,还需要把之前训练产生的模型以及cache删除掉
现在就可以进行训练了,激动吗??祈祷别出什么错误。
训练结束后,最后训练出来的模型会存储在default\voc_2007_trainval\default文件夹下。
修改代码–测试
1.demo,py中更改self._classes中的类别,注意,’'background’要保留,更改其余的类别。
然后直接运行demo.py就可以啦!!
2.demo.py中main函数中将im_names中的内容替换成自己的测试图片。然后将Faster-RCNN-TensorFlow-Python3.5/data/demo中替换上相应的图片
tensorboard进行可视化
训练结束后,根目录下会生成tensorboard文件夹,里面会有生成的log日志,文件结构如下

在命令行(gpu环境下)执行代码:
tensorboard --logdir=tensorboard/vgg16/voc_2007_trainval/
logdir是日志文件的存在位置,执行结果如图:
![]()
然后代开浏览器(我的是谷歌浏览器)执行http://DESKTOP-SOOUC5J:6006
结束语
文章的前半部分以及博文中的所有代码,博主亲测有效,博文后半部分,都是回忆部分。可能会有遗漏和错误。请大家在根据博文复现的时候遇到任何问题,请留言评论区,我会尽力解答,并把博文中遗漏的相关操作添加进去。
谢谢大家。多多指教!!!
过程中可能会遇到的问题及错误:
1.
m = cv2.imread(roidb[i][‘image’])
KeyError
解决:
将Faster-RCNN-TensorFlow-Python3.5-master\data\cache文件夹中之前生成的文件模型删除。
因为会自己读取cache中的文本,导致训练出现错误。