Redis原理和高可用场景实践总结
目录
1.Redis基础原理和知识
2.Redis持久化:RDB,AOF
3.部署redis企业级数据备份方案
4.如何通过读写分离来承载读请求QPS超过10万+(master+slave)
5 redis哨兵架构的相关基础知识的讲解
6 哨兵主备切换的数据丢失问题:异步复制、集群脑裂
7 redis的集群架构(企业级常用架构)
8.redis cluster的hash slot算法
9.Redis节点间的内部通信机制
10.高可用性与主备切换原理
11 .jedis cluster api与redis cluster集群交互的一些基本原理
12.redis在实践中的一些常见问题以及优化思路
13.redis的雪崩和穿透
14、Redis的并发竞争问题该如何解决
15、关于redis生产分布式集群的常见实现方案
16、你们生产环境中的redis是怎么部署的
17、Redis Java客户端的选择
1.Redis基础原理和知识
1.1 redis和memcached有啥区别
1)Redis支持服务器端的数据操作:Redis相比Memcached来说,拥有更多的数据结构和并支持更丰富的数据操作,通常在Memcached里,你需要将数据拿到客户端来进行类似的修改再set回去。这大大增加了网络IO的次数和数据体积。在Redis中,这些复杂的操作通常和一般的GET/SET一样高效。所以,如果需要缓存能够支持更复杂的结构和操作,那么Redis会是不错的选择。
2)集群模式:memcached没有原生的集群模式,需要依靠客户端来实现往集群中分片写入数据;但是redis目前是原生支持cluster模式的,redis官方就是支持redis cluster集群模式的,比memcached来说要更好
1.2 redis的线程模型
 redis单线程模型
redis单线程模型
1.2.1基础概念铺垫
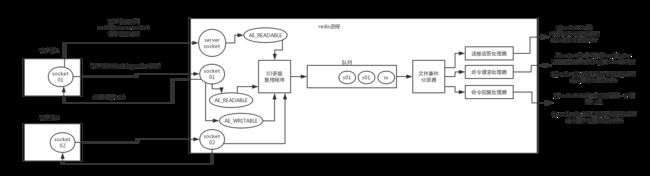
redis基于reactor模式开发了网络事件处理器,这个处理器叫做文件事件处理器
文件事件处理器是单线程模式运行的,但是通过IO多路复用机制监听多个socket,可以实现高性能的网络通信模型,又可以跟内部其他单线程的模块进行对接,保证了redis内部的线程模型的简单性。
文件事件处理器的结构包含4个部分:多个socket,IO多路复用程序,文件事件分派器,事件处理器(命令请求处理器、命令回复处理器、连接应答处理器,等等)
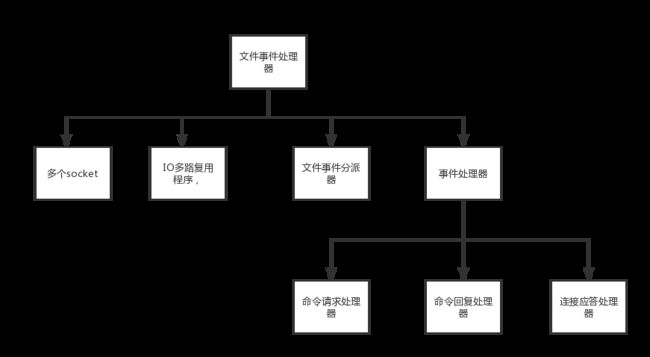 文件事件处理器的结构
文件事件处理器的结构
多个socket可能并发的产生不同的操作,每个操作对应不同的文件事件,但是IO多路复用程序会监听多个socket,但是会将socket放入一个队列中排队,每次从队列中取出一个socket给事件分派器,事件分派器把socket给对应的事件处理器。
当socket变得可读时,socket就会产生一个AE_READABLE事件。
当socket变得可写的时候,socket会产生一个AE_WRITABLE事件。
IO多路复用程序可以同时监听AE_REABLE和AE_WRITABLE两种事件,要是一个socket同时产生了AE_READABLE和AE_WRITABLE两种事件,那么文件事件分派器优先处理AE_REABLE事件,然后才是AE_WRITABLE事件。
如果是客户端要连接redis,那么会为socket关联连接应答处理器
如果是客户端要写数据到redis,那么会为socket关联命令请求处理器
如果是客户端要从redis读数据,那么会为socket关联命令回复处理器
1.2.2客户端与redis通信的一次流程
在redis启动初始化的时候,redis会将连接应答处理器跟AE_READABLE事件关联起来,接着如果一个客户端跟redis发起连接,此时会产生一个AE_READABLE事件,然后由连接应答处理器来处理跟客户端建立连接,创建客户端对应的socket,同时将这个socket的AE_READABLE事件跟命令请求处理器关联起来。
当客户端向redis发起请求的时候(不管是读请求还是写请求,都一样),首先就会在socket产生一个AE_READABLE事件,然后由对应的命令请求处理器来处理。这个命令请求处理器就会从socket中读取请求相关数据,然后进行执行和处理。
接着redis这边准备好了给客户端的响应数据之后,就会将socket的AE_WRITABLE事件跟命令回复处理器关联起来,当客户端这边准备好读取响应数据时,就会在socket上产生一个AE_WRITABLE事件,会由对应的命令回复处理器来处理,就是将准备好的响应数据写入socket,供客户端来读取。
命令回复处理器写完之后,就会删除这个socket的AE_WRITABLE事件和命令回复处理器的关联关系。
1.3为啥redis单线程模型也能效率这么高
1)纯内存操作(主要)
2)核心是基于非阻塞的IO多路复用机制(主要)
3)单线程反而避免了多线程的频繁上下文切换问题
1s内可以处理几万请求
1.4 redis的基础数据类型
| 类型 |
用途举例 |
|---|---|
| string |
|
| hash | |
| list | 比如可以通过lrange命令,就是从某个元素开始读取多少个元素,可以基于list实现分页查询 |
| set | |
| sorted_set | 排行榜:将每个用户以及其对应的什么分数写入进去,zadd board score username,接着zrevrange board 0 99,就可以获取排名前100的用户;zrank board username,可以看到用户在排行榜里的排名 |
1.5、Pipelining
客户端要连续执行的多次操作无法通过Redis命令组合在一起,例如:
SET a "abc"
INCR b
HSET c name "hi"
此时便可以使用Redis提供的pipelining功能来实现在一次交互中执行多条命令。
使用示例:
mysql -uroot -p123456.. -Dds_0 --default-character-set=utf8 --skip-column-names --raw < syns_data.sql | redis-cli -a 123456.. --pipePipelining的局限性
Pipelining只能用于执行连续且无相关性的命令,当某个命令的生成需要依赖于前一个命令的返回时,就无法使用Pipelining了。
1.6、事务与Scripting
Pipelining能够让Redis在一次交互中处理多条命令,然而在一些场景下,我们可能需要在此基础上确保这一组命令是连续执行的。
比如获取当前累计的PV数并将其清0
> GET vCount
12384
> SET vCount 0
OK
如果在GET和SET命令之间插进来一个INCR vCount,就会使客户端拿到的vCount不准确。
Redis的事务可以确保复数命令执行时的原子性。也就是说Redis能够保证:一个事务中的一组命令是绝对连续执行的,在这些命令执行完成之前,绝对不会有来自于其他连接的其他命令插进去执行。
通过MULTI和EXEC命令来把这两个命令加入一个事务中:
> MULTI
OK
> GET vCount
QUEUED
> SET vCount 0
QUEUED
> EXEC
1) 12384
2) OK
Redis在接收到MULTI命令后便会开启一个事务,这之后的所有读写命令都会保存在队列中但并不执行,直到接收到EXEC命令后,Redis会把队列中的所有命令连续顺序执行,并以数组形式返回每个命令的返回结果。
可以使用DISCARD命令放弃当前的事务,将保存的命令队列清空。
需要注意的是,Redis事务不支持回滚
2.Redis持久化:RDB,AOF
2.1、RDB和AOF两种持久化机制的介绍
RDB持久化机制,对redis中的数据执行周期性的持久化
AOF机制对每条写入命令作为日志,以append-only的模式写入一个日志文件中,在redis重启的时候,可以通过回放AOF日志中的写入指令来重新构建整个数据集
如果我们想要redis仅仅作为纯内存的缓存来用,那么可以禁止RDB和AOF所有的持久化机制
通过RDB或AOF,都可以将redis内存中的数据给持久化到磁盘上面来,然后可以将这些数据备份到别的地方去,比如说阿里云,云服务
如果redis挂了,服务器上的内存和磁盘上的数据都丢了,可以从云服务上拷贝回来之前的数据,放到指定的目录中,然后重新启动redis,redis就会自动根据持久化数据文件中的数据,去恢复内存中的数据,继续对外提供服务
如果同时使用RDB和AOF两种持久化机制,那么在redis重启的时候,会使用AOF来重新构建数据,因为AOF中的数据更加完整
2.2、RDB持久化机制的优点
(1)RDB会生成多个数据文件,每个数据文件都代表了某一个时刻中redis的数据,这种多个数据文件的方式,非常适合做冷备,可以将这种完整的数据文件发送到一些远程的安全存储上去,比如说Amazon的S3云服务上去,在国内可以是阿里云的ODPS分布式存储上,以预定好的备份策略来定期备份redis中的数据
(2)RDB对redis对外提供的读写服务,影响非常小,可以让redis保持高性能,因为redis主进程只需要fork一个子进程,让子进程执行磁盘IO操作来进行RDB持久化即可
(3)相对于AOF持久化机制来说,直接基于RDB数据文件来重启和恢复redis进程,更加快速
2.3、RDB持久化机制的缺点
(1)如果想要在redis故障时,尽可能少的丢失数据,那么RDB没有AOF好。一般来说,RDB数据快照文件,都是每隔5分钟,或者更长时间生成一次,这个时候就得接受一旦redis进程宕机,那么会丢失最近5分钟的数据
(2)RDB每次在fork子进程来执行RDB快照数据文件生成的时候,如果数据文件特别大,可能会导致对客户端提供的服务暂停数毫秒,或者甚至数秒
2.4、AOF持久化机制的优点
(1)AOF可以更好的保护数据不丢失,一般AOF会每隔1秒,通过一个后台线程执行一次fsync操作,最多丢失1秒钟的数据
(2)AOF日志文件以append-only模式写入,所以没有任何磁盘寻址的开销,写入性能非常高,而且文件不容易破损,即使文件尾部破损,也很容易修复
(3)AOF日志文件即使过大的时候,出现后台重写操作,也不会影响客户端的读写。因为在rewrite log的时候,会对其中的指导进行压缩,创建出一份需要恢复数据的最小日志出来。再创建新日志文件的时候,老的日志文件还是照常写入。当新的merge后的日志文件ready的时候,再交换新老日志文件即可。
(4)AOF日志文件的命令通过非常可读的方式进行记录,这个特性非常适合做灾难性的误删除的紧急恢复。比如某人不小心用flushall命令清空了所有数据,只要这个时候后台rewrite还没有发生,那么就可以立即拷贝AOF文件,将最后一条flushall命令给删了,然后再将该AOF文件放回去,就可以通过恢复机制,自动恢复所有数据
2.5、AOF持久化机制的缺点
(1)对于同一份数据来说,AOF日志文件通常比RDB数据快照文件更大
(2)AOF开启后,支持的写QPS会比RDB支持的写QPS低,因为AOF一般会配置成每秒fsync一次日志文件,当然,每秒一次fsync,性能也还是很高的
(3)以前AOF发生过bug,就是通过AOF记录的日志,进行数据恢复的时候,没有恢复一模一样的数据出来。所以说,类似AOF这种较为复杂的基于命令日志/merge/回放的方式,比基于RDB每次持久化一份完整的数据快照文件的方式,更加脆弱一些,容易有bug。不过AOF就是为了避免rewrite过程导致的bug,因此每次rewrite并不是基于旧的指令日志进行merge的,而是基于当时内存中的数据进行指令的重新构建,这样健壮性会好很多。
2.6、RDB和AOF到底该如何选择
(1)不要仅仅使用RDB,因为那样会导致你丢失很多数据
(2)也不要仅仅使用AOF,因为那样有两个问题,第一,你通过AOF做冷备,没有RDB做冷备,来的恢复速度更快; 第二,RDB每次简单粗暴生成数据快照,更加健壮,可以避免AOF这种复杂的备份和恢复机制的bug
(3)综合使用AOF和RDB两种持久化机制,用AOF来保证数据不丢失,作为数据恢复的第一选择; 用RDB来做不同程度的冷备,在AOF文件都丢失或损坏不可用的时候,还可以使用RDB来进行快速的数据恢复
3.部署redis企业级数据备份方案
3.1、企业级的持久化的配置策略
在企业中,RDB的生成策略,用默认的也差不多
save 60 10000:60s内数据更改达到10000就save
10000->生成RDB,1000->RDB,这个根据你自己的应用和业务的数据量,你自己去决定
AOF一定要打开,fsync,everysec
auto-aof-rewrite-percentage 100: 就是当前AOF大小膨胀到超过上次100%,上次的两倍
auto-aof-rewrite-min-size 64mb: 根据你的数据量来定,16mb,32mb
3.2、企业级的数据备份方案
RDB非常适合做冷备,每次生成之后,就不会再有修改了
数据备份方案
(1)写crontab定时调度脚本去做数据备份
(2)每小时都copy一份rdb的备份,到一个目录中去,仅仅保留最近48小时的备份
(3)每天都保留一份当日的rdb的备份,到一个目录中去,仅仅保留最近1个月的备份
(4)每次copy备份的时候,都把太旧的备份给删了
(5)每天晚上将当前服务器上所有的数据备份,发送一份到远程的云服务上去
/usr/local/redis
每小时copy一次备份,删除48小时前的数据
crontab -e
0 * * * * sh /usr/local/redis/copy/redis_rdb_copy_hourly.shredis_rdb_copy_hourly.sh
#!/bin/sh
cur_date=`date +%Y%m%d%k`
rm -rf /usr/local/redis/snapshotting/$cur_date
mkdir /usr/local/redis/snapshotting/$cur_date
cp /var/redis/6379/dump.rdb /usr/local/redis/snapshotting/$cur_date
del_date=`date -d -48hour +%Y%m%d%k`
rm -rf /usr/local/redis/snapshotting/$del_date
每天copy一次备份
crontab -e
0 0 * * * sh /usr/local/redis/copy/redis_rdb_copy_daily.shredis_rdb_copy_daily.sh
#!/bin/sh
cur_date=`date +%Y%m%d`
rm -rf /usr/local/redis/snapshotting/$cur_date
mkdir /usr/local/redis/snapshotting/$cur_date
cp /var/redis/6379/dump.rdb /usr/local/redis/snapshotting/$cur_date
del_date=`date -d -1month +%Y%m%d`
rm -rf /usr/local/redis/snapshotting/$del_date每天一次将所有数据上传一次到远程的云服务器上去
3.3、数据恢复方案
3.3.1如果redis当前最新的AOF和RDB文件出现了丢失/损坏,那么可以尝试基于该机器上当前的某个最新的RDB数据副本进行数据恢复
当前最新的AOF和RDB文件都出现了丢失/损坏到无法恢复,一般不是机器的故障,人为把/var/redis/6379下的文件给删除了
在数据安全丢失的情况下,基于rdb冷备,如何完美的恢复数据,同时还保持aof和rdb的双开?
停止redis,关闭aof,拷贝rdb备份,重启redis,确认数据恢复,直接在命令行热修改redis配置,打开aof,这个redis就会将内存中的数据对应的日志,写入aof文件中
此时aof和rdb两份数据文件的数据就同步了
redis config set热修改配置参数,可配置文件中的实际的参数没有被持久化的修改,再次停止redis,手动修改配置文件,打开aof的命令,再次重启redis
为什么要按照上面的步骤操作:
appendonly.aof 和 dump.rdb都开启的情况表下,优先用appendonly.aof去恢复数据,虽然你删除了appendonly.aof,但是因为打开了aof持久化,redis就一定会优先基于aof去恢复,即使文件不在,那就创建一个新的空的aof文件,停止redis,暂时在配置中关闭aof,然后拷贝一份rdb过来,再重启redis,数据能不能恢复过来,可以恢复过来。脑子一热,再关掉redis,手动修改配置文件,打开aof,再重启redis,数据又没了,空的aof文件,所有数据又没了
3.3.2 如果当前机器上的所有RDB文件全部损坏,那么从远程的云服务上拉取最新的RDB快照回来恢复数据
3.3.3 如果是发现有重大的数据错误,比如某个小时上线的程序一下子将数据全部污染了,数据全错了,那么可以选择某个更早的时间点,对数据进行恢复
举个例子,12点上线了代码,发现代码有bug,导致代码生成的所有的缓存数据,写入redis,全部错了
找到一份11点的rdb的冷备,然后按照上面的步骤,去恢复到11点的数据,不就可以了吗
4.如何通过读写分离来承载读请求QPS超过10万+(master+slave)
redis单机qps可支撑几万,一般来说,对缓存,一般都是用来支撑读高并发的,写的请求是比较少的,可能写请求也就一秒钟几千,大量的请求都是读,一秒钟二十万次读
4.1 redis replication(复制)的核心机制
(1)redis采用异步方式复制数据到slave节点,不过redis 2.8开始,slave node会周期性地确认自己每次复制的数据量
(2)一个master node是可以配置多个slave node的
(3)slave node也可以连接其他的slave node
(4)slave node做复制的时候,是不会block master node的正常工作的
(5)slave node在做复制的时候,也不会block对自己的查询操作,它会用旧的数据集来提供服务; 但是复制完成的时候,需要删除旧数据集,加载新数据集,这个时候就会暂停对外服务了
(6)slave node主要用来进行横向扩容,做读写分离,扩容的slave node可以提高读的吞吐量
4.2、master持久化对于主从架构的安全保障的意义
如果采用了主从架构,那么建议必须开启master node的持久化!
不建议用slave node作为master node的数据热备,因为那样的话,如果你关掉master的持久化,可能在master宕机重启的时候数据是空的,然后可能一经过复制,salve node数据也丢了
master -> RDB和AOF都关闭了 -> 全部在内存中
master宕机,重启,是没有本地数据可以恢复的,然后就会直接认为自己IDE数据是空的
master就会将空的数据集同步到slave上去,所有slave的数据全部清空,100%的数据丢失
5 redis哨兵架构的相关基础知识的讲解
5.1、哨兵的介绍
sentinal,中文名是哨兵
哨兵是redis集群架构中非常重要的一个组件,主要功能如下
(1)集群监控,负责监控redis master和slave进程是否正常工作
(2)消息通知,如果某个redis实例有故障,那么哨兵负责发送消息作为报警通知给管理员
(3)故障转移,如果master node挂掉了,会自动转移到slave node上
(4)配置中心,如果故障转移发生了,通知client客户端新的master地址
哨兵本身也是分布式的,作为一个哨兵集群去运行,互相协同工作
(1)故障转移时,判断一个master node是宕机了,需要大部分的哨兵都同意才行,涉及到了分布式选举的问题
(2)即使部分哨兵节点挂掉了,哨兵集群还是能正常工作的,因为如果一个作为高可用机制重要组成部分的故障转移系统本身是单点的,那就很坑爹了
目前采用的是sentinal 2版本,sentinal 2相对于sentinal 1来说,重写了很多代码,主要是让故障转移的机制和算法变得更加健壮和简单
5.2、哨兵的核心知识
(1)哨兵至少需要3个实例,来保证自己的健壮性
(2)哨兵 + redis主从的部署架构,是不会保证数据零丢失的,只能保证redis集群的高可用性
(3)对于哨兵 + redis主从这种复杂的部署架构,尽量在测试环境和生产环境,都进行充足的测试和演练
5.3、为什么redis哨兵集群只有2个节点无法正常工作
哨兵集群必须部署2个以上节点
如果哨兵集群仅仅部署了个2个哨兵实例,quorum=1
+----+ +----+
| M1 |---------| R1 |
| S1 | | S2 |
+----+ +----+
Configuration: quorum = 1
master宕机,s1和s2中只要有1个哨兵认为master宕机就可以还行切换,同时s1和s2中会选举出一个哨兵来执行故障转移
同时这个时候,需要majority,也就是大多数哨兵都是运行的,2个哨兵的majority就是2(2的majority=2,3的majority=2,5的majority=3,4的majority=2),2个哨兵都运行着,就可以允许执行故障转移
但是如果整个M1和S1运行的机器宕机了,那么哨兵只有1个了,此时就没有majority来允许执行故障转移,虽然另外一台机器还有一个R1,但是故障转移不会执行
5.4、经典的3节点哨兵集群
+----+
| M1 |
| S1 |
+----+
|
+----+ | +----+
| R2 |----+----| R3 |
| S2 | | S3 |
+----+ +----+
Configuration: quorum = 2,majority
如果M1所在机器宕机了,那么三个哨兵还剩下2个,S2和S3可以一致认为master宕机,然后选举出一个来执行故障转移
同时3个哨兵的majority是2,所以还剩下的2个哨兵运行着,就可以允许执行故障转移
5.5、sdown和odown转换机制
sdown是主观宕机,就一个哨兵如果自己觉得一个master宕机了,那么就是主观宕机
odown是客观宕机,如果quorum数量的哨兵都觉得一个master宕机了,那么就是客观宕机
5.6、slave->master选举算法
如果一个master被认为odown了,而且majority哨兵都允许了主备切换,那么某个哨兵就会执行主备切换操作,此时首先要选举一个slave来
会考虑slave的一些信息
(1)跟master断开连接的时长
(2)slave优先级
(3)复制offset
(4)run id
如果一个slave跟master断开连接已经超过了down-after-milliseconds的10倍,外加master宕机的时长,那么slave就被认为不适合选举为master
(down-after-milliseconds * 10) + milliseconds_since_master_is_in_SDOWN_state
接下来会对slave进行排序
(1)按照slave优先级进行排序,slave priority越低,优先级就越高
(2)如果slave priority相同,那么看replica offset,哪个slave复制了越多的数据,offset越靠后,优先级就越高
(3)如果上面两个条件都相同,那么选择一个run id比较小的那个slave
5.7、哨兵的生产环境部署
daemonize yes
logfile /var/log/sentinal/5000
mkdir -p /var/log/sentinal/5000
6 哨兵主备切换的数据丢失问题:异步复制、集群脑裂
6.1、两种数据丢失的情况
主备切换的过程,可能会导致数据丢失
(1)异步复制导致的数据丢失
因为master -> slave的复制是异步的,所以可能有部分数据还没复制到slave,master就宕机了,此时这些部分数据就丢失了
(2)脑裂导致的数据丢失
脑裂,也就是说,某个master所在机器突然脱离了正常的网络,跟其他slave机器不能连接,但是实际上master还运行着
此时哨兵可能就会认为master宕机了,然后开启选举,将其他slave切换成了master
这个时候,集群里就会有两个master,也就是所谓的脑裂
此时虽然某个slave被切换成了master,但是可能client还没来得及切换到新的master,还继续写向旧master的数据可能也丢失了
因此旧master再次恢复的时候,会被作为一个slave挂到新的master上去,自己的数据会清空,重新从新的master复制数据
6.2、解决异步复制和脑裂导致的数据丢失
min-slaves-to-write 1 要求至少有1个slave,数据复制和同步的延迟不能超过10秒
min-slaves-max-lag 10 一旦所有的slave,数据复制和同步的延迟都超过了10秒钟,那么这个时候,master就不会再接收任何请求了
上面两个配置可以减少异步复制和脑裂导致的数据丢失
(1)减少异步复制的数据丢失
有了min-slaves-max-lag这个配置,就可以确保说,一旦slave复制数据和ack延时太长,就认为可能master宕机后损失的数据太多了,那么就拒绝写请求,这样可以把master宕机时由于部分数据未同步到slave导致的数据丢失降低的可控范围内
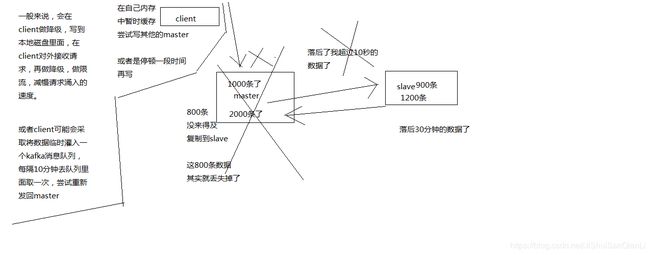 异步复制导致数据丢失如何降低损失
异步复制导致数据丢失如何降低损失
(2)减少脑裂的数据丢失
如果一个master出现了脑裂,跟其他slave丢了连接,那么上面两个配置可以确保说,如果不能继续给指定数量的slave发送数据,而且slave超过10秒没有给自己ack消息,那么就直接拒绝客户端的写请求,因此在脑裂场景下,最多就丢失10秒的数据
7 redis的集群架构(企业级常用架构)
7.1、什么是redis cluster
1能够自动将数据分散在多个节点上
2当访问的key不在当前分片上时,能够自动将请求转发至正确的分片
3当集群中部分节点失效时仍能提供服务
其中第三点是基于主从复制来实现的,Redis Cluster的每个数据分片都采用了主从复制的结构,原理和前文所述的主从复制完全一致,唯一的区别是省去了Redis Sentinel这一额外的组件,由Redis Cluster负责进行一个分片内部的节点监控和自动failover
在redis cluster架构下,每个redis要放开两个端口号,比如一个是6379,另外一个就是加10000的端口号,比如16379
16379端口号是用来进行节点间通信的,也就是cluster bus的东西,集群总线。cluster bus的通信,用来进行故障检测,配置更新,故障转移授权
cluster bus用了另外一种二进制的协议(gossip协议),主要用于节点间进行高效的数据交换,占用更少的网络带宽和处理时间
7.2、redis cluster vs. replication + sentinal
从各个方面看,Redis Cluster都是优于主从复制的方案
Redis Cluster能够解决单节点上数据量过大的问题
Redis Cluster能够解决单节点访问压力过大的问题
Redis Cluster包含了主从复制的能力
软件架构永远不是越复杂越好,复杂的架构在带来显著好处的同时,一定也会带来相应的弊端。采用Redis Cluster的弊端包括:
维护难度增加
客户端资源消耗增加。
性能优化难度增加
事务和LUA Script的使用成本增加
7.2.1 如果你的数据量很少,主要是承载高并发高性能的场景,比如你的缓存一般就几个G,单机足够了
replication,一个mater,多个slave,要几个slave跟你的要求的读吞吐量有关系,然后自己搭建一个sentinal集群,去保证redis主从架构的高可用性,就可以了
7.2.2 redis cluster,主要是针对海量数据+高并发+高可用的场景,海量数据,如果你的数据量很大,那么建议就用redis cluster
8.redis cluster的hash slot算法
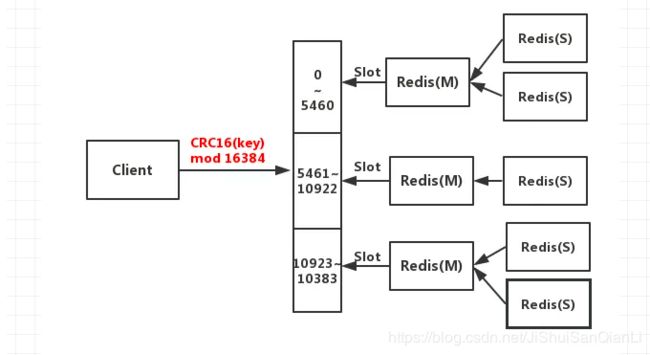 Redis Cluster的Hash slot算法
Redis Cluster的Hash slot算法
工作原理如下
1、客户端与Redis节点直连,不需要中间Proxy层,直接连接任意一个Master节点
2、根据公式HASH_SLOT=CRC16(key) mod 16384,计算出映射到哪个分片上,然后Redis会去相应的节点进行操作
具有如下优点:
(1)无需Sentinel哨兵监控,如果Master挂了,Redis Cluster内部自动将Slave切换Master
(2)可以进行水平扩容
(3)支持自动化迁移,当出现某个Slave宕机了,那么就只有Master了,这时候的高可用性就无法很好的保证了,万一Master也宕机了,咋办呢? 针对这种情况,如果说其他Master有多余的Slave ,集群自动把多余的Slave迁移到没有Slave的Master 中。
缺点:
(1)批量操作是个坑
(2)资源隔离性较差,容易出现相互影响的情况
9.Redis节点间的内部通信机制
9.1、基础通信原理
(1)redis cluster节点间采取gossip协议进行通信(必须基于redis3)
跟集中式不同,不是将集群元数据(节点信息,故障,等等)集中存储在某个节点上,而是互相之间不断通信,保持整个集群所有节点的数据是完整的
维护集群的元数据一种叫做集中式,一种叫做gossip
集中式:好处在于,元数据的更新和读取,时效性非常好,一旦元数据出现了变更,立即就更新到集中式的存储中,其他节点读取的时候立即就可以感知到; 不好在于,所有的元数据的跟新压力全部集中在一个地方,可能会导致元数据的存储有压力
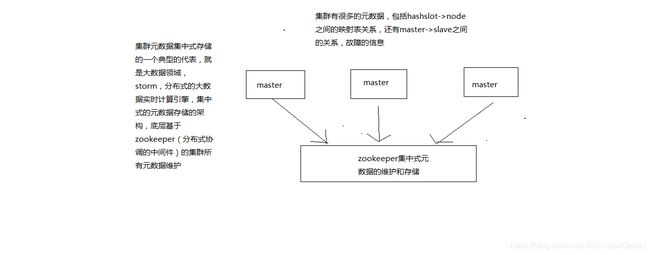 集中式的集群元数据存储和维护
集中式的集群元数据存储和维护
gossip:好处在于,元数据的更新比较分散,不是集中在一个地方,更新请求会陆陆续续,打到所有节点上去更新,有一定的延时,降低了压力; 缺点,元数据更新有延时,可能导致集群的一些操作会有一些滞后
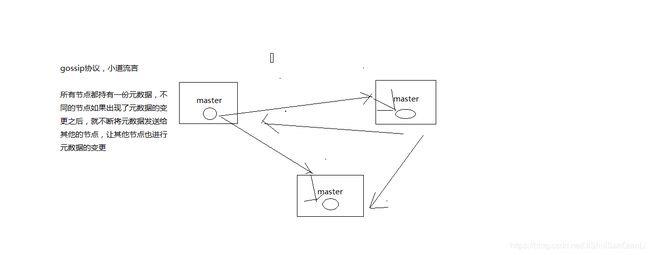 gossip协议维护集群元数据
gossip协议维护集群元数据
(2)10000端口
每个节点都有一个专门用于节点间通信的端口,就是自己提供服务的端口号+10000,比如7001,那么用于节点间通信的就是17001端口
每隔节点每隔一段时间都会往另外几个节点发送ping消息,同时其他几点接收到ping之后返回pong
(3)交换的信息
故障信息,节点的增加和移除,hash slot信息,等等
9.2、gossip协议
gossip协议包含多种消息,包括ping,pong,meet,fail,等等
meet: 某个节点发送meet给新加入的节点,让新节点加入集群中,然后新节点就会开始与其他节点进行通信
redis-trib.rb add-node
其实内部就是发送了一个gossip meet消息,给新加入的节点,通知那个节点去加入我们的集群
ping: 每个节点都会频繁给其他节点发送ping,其中包含自己的状态还有自己维护的集群元数据,互相通过ping交换元数据
每个节点每秒都会频繁发送ping给其他的集群,ping,频繁的互相之间交换数据,互相进行元数据的更新
pong: 返回ping和meet,包含自己的状态和其他信息,也可以用于信息广播和更新
fail: 某个节点判断另一个节点fail之后,就发送fail给其他节点,通知其他节点,指定的节点宕机了
9.3、ping消息深入
ping很频繁,而且要携带一些元数据,所以可能会加重网络负担
每个节点每秒会执行10次ping,每次会选择5个最久没有通信的其他节点
当然如果发现某个节点通信延时达到了cluster_node_timeout / 2,那么立即发送ping,避免数据交换延时过长,落后的时间太长了
比如说,两个节点之间都10分钟没有交换数据了,那么整个集群处于严重的元数据不一致的情况,就会有问题
所以cluster_node_timeout可以调节,如果调节比较大,那么会降低发送的频率
每次ping,一个是带上自己节点的信息,还有就是带上1/10其他节点的信息,发送出去,进行数据交换
至少包含3个其他节点的信息,最多包含总节点-2个其他节点的信息
10.高可用性与主备切换原理
redis cluster的高可用的原理,几乎跟哨兵是类似的
10.1、判断节点宕机
如果一个节点认为另外一个节点宕机,那么就是pfail,主观宕机
如果多个节点都认为另外一个节点宕机了,那么就是fail,客观宕机,跟哨兵的原理几乎一样,sdown,odown
在cluster-node-timeout内,某个节点一直没有返回pong,那么就被认为pfail
如果一个节点认为某个节点pfail了,那么会在gossip ping消息中,ping给其他节点,如果超过半数的节点都认为pfail了,那么就会变成fail
10.2、从节点过滤
对宕机的master node,从其所有的slave node中,选择一个切换成master node
检查每个slave node与master node断开连接的时间,如果超过了cluster-node-timeout * cluster-slave-validity-factor,那么就没有资格切换成master
这个也是跟哨兵是一样的,从节点超时过滤的步骤
10.3、从节点选举
哨兵:对所有从节点进行排序,slave priority,offset,run id
每个从节点,都根据自己对master复制数据的offset,来设置一个选举时间,offset越大(复制数据越多)的从节点,选举时间越靠前,优先进行选举
所有的master node开始slave选举投票,给要进行选举的slave进行投票,如果大部分master node(N/2 + 1)都投票给了某个从节点,那么选举通过,那个从节点可以切换成master
从节点执行主备切换,从节点切换为主节点
10.4、与哨兵比较
整个流程跟哨兵相比,非常类似,所以说,redis cluster功能强大,直接集成了replication和sentinal的功能
11 .jedis cluster api与redis cluster集群交互的一些基本原理
11.1、基于重定向的客户端
redis-cli -c,自动重定向
(1)请求重定向
(2)计算hash slot
(3)hash slot查找
11.2、smart jedis
(1)什么是smart jedis
基于重定向的客户端,很消耗网络IO,因为大部分情况下,可能都会出现一次请求重定向,才能找到正确的节点
所以大部分的客户端,比如java redis客户端,就是jedis,都是smart的
本地维护一份hashslot -> node的映射表,缓存,大部分情况下,直接走本地缓存就可以找到hashslot -> node,不需要通过节点进行moved重定向
(2)JedisCluster的工作原理
在JedisCluster初始化的时候,就会随机选择一个node,初始化hashslot -> node映射表,同时为每个节点创建一个JedisPool连接池
每次基于JedisCluster执行操作,首先JedisCluster都会在本地计算key的hashslot,然后在本地映射表找到对应的节点
如果那个node正好还是持有那个hashslot,那么就ok; 如果说进行了reshard这样的操作,可能hashslot已经不在那个node上了,就会返回moved, 如果JedisCluter API发现对应的节点返回moved,那么利用该节点的元数据,更新本地的hashslot -> node映射表缓存
重复上面几个步骤,直到找到对应的节点,如果重试超过5次,那么就报错,JedisClusterMaxRedirectionException
12.redis在实践中的一些常见问题以及优化思路
12.1、fork耗时导致高并发请求延时
RDB和AOF的时候,其实会有生成RDB快照,AOF rewrite,耗费磁盘IO的过程,主进程fork子进程
fork的时候,子进程是需要拷贝父进程的空间内存页表的,也是会耗费一定的时间的
一般来说,如果父进程内存有1个G的数据,那么fork可能会耗费在20ms左右,如果是10G~30G,那么就会耗费20 * 10,甚至20 * 30,也就是几百毫秒的时间
info stats中的latest_fork_usec,可以看到最近一次form的时长
redis单机QPS一般在几万,fork可能一下子就会拖慢几万条操作的请求时长,从几毫秒变成1秒
优化思路
fork耗时跟redis主进程的内存有关系,一般控制redis的内存在10GB以内,slave -> master,全量复制
12.2、AOF的阻塞问题
redis将数据写入AOF缓冲区,单独开一个现场做fsync操作,每秒一次
但是redis主线程会检查两次fsync的时间,如果距离上次fsync时间超过了2秒,那么写请求就会阻塞
everysec,最多丢失2秒的数据
一旦fsync超过2秒的延时,整个redis就被拖慢
优化思路
优化硬盘写入速度,建议采用SSD,不要用普通的机械硬盘,SSD,大幅度提升磁盘读写的速度
12.3、主从复制延迟问题
主从复制可能会超时严重,这个时候需要良好的监控和报警机制
在info replication中,可以看到master和slave复制的offset,做一个差值就可以看到对应的延迟量
如果延迟过多,那么就进行报警
12.4、主从复制风暴问题
如果一下子让多个slave从master去执行全量复制,一份大的rdb同时发送到多个slave,会导致网络带宽被严重占用
如果一个master真的要挂载多个slave,那尽量用树状结构,不要用星型结构
12.5、vm.overcommit_memory
0: 检查有没有足够内存,没有的话申请内存失败(默认)
1: 允许使用内存直到用完为止
2: 内存地址空间不能超过swap + 50%
如果是0的话,可能导致类似fork等操作执行失败,申请不到足够的内存空间
cat /proc/sys/vm/overcommit_memory
echo "vm.overcommit_memory=1" >> /etc/sysctl.conf
sysctl vm.overcommit_memory=1
12.6、swapiness
cat /proc/version,查看linux内核版本
如果linux内核版本<3.5,那么swapiness设置为0,这样系统宁愿swap也不会oom killer(杀掉进程)
如果linux内核版本>=3.5,那么swapiness设置为1,这样系统宁愿swap也不会oom killer
保证redis不会在内存不充足时被杀掉
echo 0 > /proc/sys/vm/swappiness
echo vm.swapiness=0 >> /etc/sysctl.conf
12.7、最大打开文件句柄
ulimit -n 10032 10032
自己去上网搜一下,不同的操作系统,版本,设置的方式都不太一样
12.8、tcp backlog
cat /proc/sys/net/core/somaxconn
echo 511 > /proc/sys/net/core/somaxconn
12.9、长耗时命令
Redis提供了Slow Log功能,可以自动记录耗时较长的命令。相关的配置参数有两个:
slowlog-log-slower-than xxxms #执行时间慢于xxx毫秒的命令计入Slow Log
slowlog-max-len xxx #Slow Log的长度,即最大纪录多少条Slow Log
使用SLOWLOG GET [number]命令,可以输出最近进入Slow Log的number条命令。
使用SLOWLOG RESET命令,可以重置Slow Log
避免在使用这些O(N)命令时发生问题主要有几个办法:
1、不要把List当做列表使用,仅当做队列来使用
2、通过机制严格控制Hash、Set、Sorted Set的大小
3、可能的话,将排序、并集、交集等操作放在客户端执行
4、绝对禁止使用KEYS命令
5、避免一次性遍历集合类型的所有成员,而应使用SCAN类的命令进行分批的,游标式的遍历
Redis提供了SCAN命令,可以对Redis中存储的所有key进行游标式的遍历,避免使用KEYS命令带来的性能问题。同时还有SSCAN/HSCAN/ZSCAN等命令,分别用于对Set/Hash/Sorted Set中的元素进行游标式遍历。SCAN类命令的使用请参考官方文档:https://redis.io/commands/scan
13.redis的雪崩和穿透
13.1缓存雪崩
 缓存雪崩现象
缓存雪崩现象
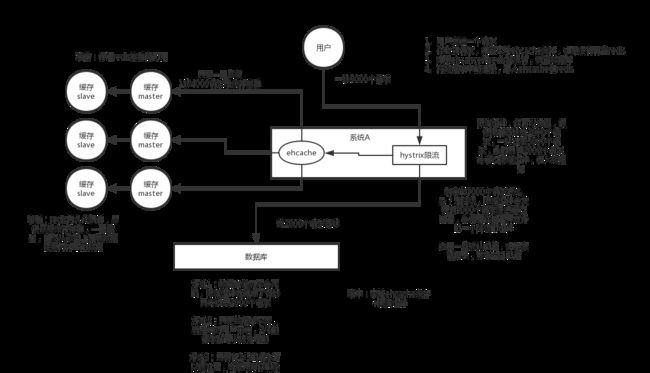 如何解决缓存雪崩
如何解决缓存雪崩
事前:redis高可用,主从+哨兵,redis cluster,避免全盘崩溃
事中:本地ehcache缓存 + hystrix限流&降级,避免MySQL被打死
事后:redis持久化,快速恢复缓存数据
13.2缓存穿透
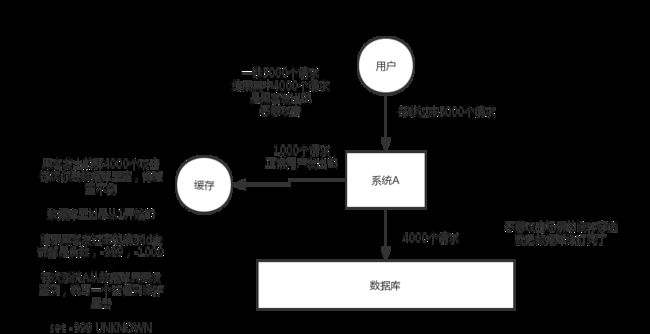 缓存穿透现象以及解决方案
缓存穿透现象以及解决方案
解决方案:每次从数据库里没查到数据,就写一个空值到缓存里 (或则利用布隆过滤器判断key是否存在)
注:缓存穿透要么是自己系统出bug,要么就是被黑客攻击
14、Redis的并发竞争问题该如何解决
这个也是线上非常常见的一个问题,就是多客户端同时并发写一个key,可能本来应该先到的数据后到了,导致数据版本错了。或者是多客户端同时获取一个key,修改值之后再写回去,只要顺序错了,数据就错了。
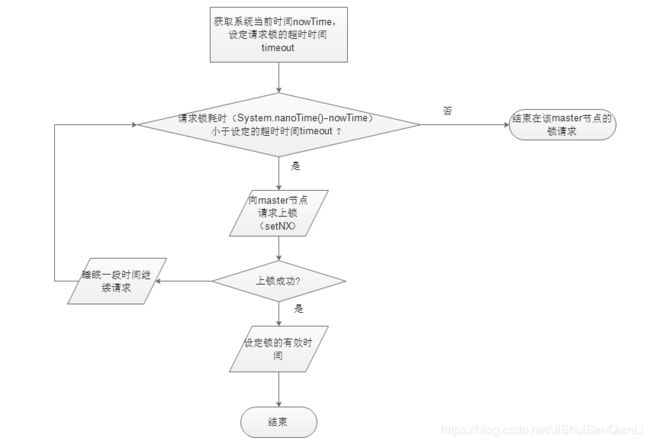
Redis有一系列的命令,特点是以NX结尾,NX是Not Exists的缩写,如SETNX命令就应该理解为:SET if Not Exists。这系列的命令非常有用,可以使用SETNX来实现分布式锁。
如果在公司里落地生产环境用分布式锁的时候,一定是会用开源类库的,比如Redis分布式锁,一般就是用Redisson框架就好了,非常的简便易用。
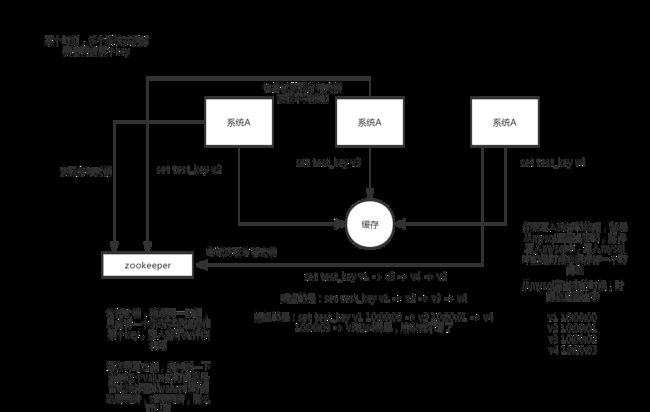
 Redis分布式锁实现原理
Redis分布式锁实现原理
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.dao.DataAccessException;
import org.springframework.data.redis.connection.RedisConnection;
import org.springframework.data.redis.core.RedisCallback;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.serializer.StringRedisSerializer;
/**
* 分布式锁
* 性能待测试
* @author lzhcode
*
*/
public class RedisLock {
private static Logger logger = LoggerFactory.getLogger(RedisLock.class);
private RedisTemplate redisTemplate;
private static final int DEFAULT_ACQUIRY_RESOLUTION_MILLIS = 100;
/**
* Lock key path.
*/
private String lockKey;
/**
* 锁超时时间,防止线程在入锁以后,无限的执行等待
*/
private int expireMsecs = 60 * 1000;
/**
* 锁等待时间,防止线程饥饿
*/
private int timeoutMsecs = 10 * 1000;
private volatile boolean locked = false;
/**
* Detailed constructor with default acquire timeout 10000 msecs and lock expiration of 60000 msecs.
*
* @param lockKey lock key (ex. account:1, ...)
*/
public RedisLock(RedisTemplate redisTemplate, String lockKey) {
this.redisTemplate = redisTemplate;
this.lockKey = lockKey + "_lock";
}
/**
* Detailed constructor with default lock expiration of 60000 msecs.
*
*/
public RedisLock(RedisTemplate redisTemplate, String lockKey, int timeoutMsecs) {
this(redisTemplate, lockKey);
this.timeoutMsecs = timeoutMsecs;
}
/**
* Detailed constructor.
*
*/
public RedisLock(RedisTemplate redisTemplate, String lockKey, int timeoutMsecs, int expireMsecs) {
this(redisTemplate, lockKey, timeoutMsecs);
this.expireMsecs = expireMsecs;
}
/**
* @return lock key
*/
public String getLockKey() {
return lockKey;
}
private String get(final String key) {
Object obj = null;
try {
obj = redisTemplate.execute(new RedisCallback和RedisLock和Redisson表面来看,这个方案似乎很管用,但是这里存在一个问题:在我们的系统架构里存在一个单点故障,如果Redis的master节点宕机了怎么办呢?有人可能会说:加一个slave节点!在master宕机时用slave就行了!但是其实这个方案明显是不可行的,因为这种方案无法保证第1个安全互斥属性,因为Redis的复制是异步的。 总的来说,这个方案里有一个明显的竞争条件(race condition),举例来说:
- 客户端A在master节点拿到了锁。
- master节点在把A创建的key写入slave之前宕机了。
- slave变成了master节点
- B也得到了和A还持有的相同的锁(因为原来的slave里还没有A持有锁的信息)
下面的表格总结了Zookeeper和Redis分布式锁的优缺点:

15、关于redis生产分布式集群的常见实现方案
15.1基于代理的redis分片(Proxy+Replication+Sentinel)
proxy,客户端通过proxy与redis服务器进行交互,客户端并不知道proxy后方的redis服务器的架构部署,对客户端来说,proxy服务就相当于一台单独的redis服务,也就说对于客户端来说,redis的集群架构以及后期的扩容迁移等操作都是透明的,redis服务的集群分片、架构变化都是由代理服务proxy来维护的。
这里以Twemproxy为例说明,如下图所示
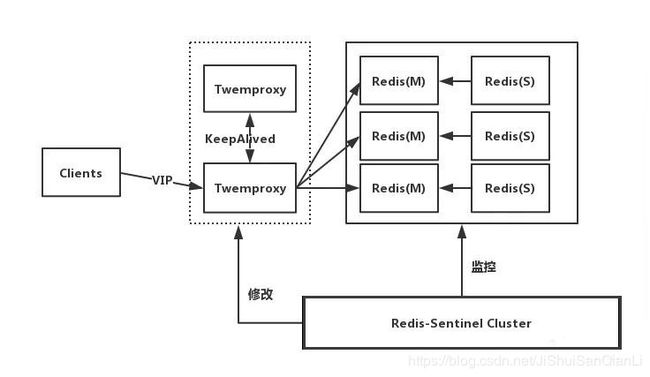 Proxy+Replication+Sentinel
Proxy+Replication+Sentinel
工作原理如下
1、前端使用Twemproxy+KeepAlived做代理,将其后端的多台Redis实例分片进行统一管理与分配
2、每一个分片节点的Slave都是Master的副本且只读
3、Sentinel持续不断的监控每个分片节点的Master,当Master出现故障且不可用状态时,Sentinel会通知/启动自动故障转移等动作
4、Sentinel 可以在发生故障转移动作后触发相应脚本(通过 client-reconfig-script 参数配置 ),脚本获取到最新的Master来修改Twemproxy配置
缺陷:
(1)部署结构超级复杂
(2)可扩展性差,进行扩缩容需要手动干预
(3)运维不方便
15.2基于redis服务器的分片(Redis Cluster)
基于redis服务器的分片,又可称之为“查询路由”,就是客户端随机连接redis集群中的一个节点,向其发送读写请求,如果这个请求不能够被当前节点处理,则这个节点会将请求转发给正确的节点来处理(这一点很像zookeeper中的主从写请求机制),有的实现并不会由当前节点转发给其他节点,而是当前节点响应给客户端一个正确节点的信息,由客户端再次向正确的节点发出请求。
16、你们生产环境中的redis是怎么部署的
redis cluster,10台机器,5台机器部署了redis主实例,另外5台机器部署了redis的从实例,每个主实例挂了一个从实例,5个节点对外提供读写服务,每个节点的读写高峰qps可能可以达到每秒5万,5台机器最多是25万读写请求/s。
机器是什么配置?32G内存+8核CPU+1T磁盘,但是分配给redis进程的是10g内存,一般线上生产环境,redis的内存尽量不要超过10g,超过10g可能会有问题。
5台机器对外提供读写,一共有50g内存。
因为每个主实例都挂了一个从实例,所以是高可用的,任何一个主实例宕机,都会自动故障迁移,redis从实例会自动变成主实例继续提供读写服务
你往内存里写的是什么数据?每条数据的大小是多少?商品数据,每条数据是10kb。100条数据是1mb,10万条数据是1g。常驻内存的是200万条商品数据,占用内存是20g,仅仅不到总内存的50%。
目前高峰期每秒就是3500左右的请求量
17、Redis Java客户端的选择
Redis的Java客户端很多,官方推荐的有三种:Jedis、Redisson和lettuce。
在这里对Jedis和Redisson进行对比介绍
Jedis:
轻量,简洁,便于集成和改造
支持连接池
支持pipelining、事务、LUA Scripting、Redis Sentinel、Redis Cluster
不支持读写分离,需要自己实现
文档差(真的很差,几乎没有……)
Redisson:
基于Netty实现,采用非阻塞IO,性能高
支持异步请求
支持连接池
支持pipelining、LUA Scripting、Redis Sentinel、Redis Cluster
不支持事务,官方建议以LUA Scripting代替事务
支持在Redis Cluster架构下使用pipelining
支持读写分离,支持读负载均衡,在主从复制和Redis Cluster架构下都可以使用
内建Tomcat Session Manager,为Tomcat 6/7/8提供了会话共享功能
可以与Spring Session集成,实现基于Redis的会话共享
文档较丰富,有中文文档