手写实现一个简单的卷积神经网络
git详细代码仓库: https://github.com/justDoForever/deep_learning/digital_recognition_fc.py(python 2.7)
理论分析:https://www.zybuluo.com/hanbingtao/note/485480
往期回顾
在前面的文章中,我们介绍了全连接神经网络,以及它的训练和使用。我们用它来识别了手写数字,然而,这种结构的网络对于图像识别任务来说并不是很合适。本文将要介绍一种更适合图像、语音识别任务的神经网络结构——卷积神经网络(Convolutional Neural Network, CNN)。说卷积神经网络是最重要的一种神经网络也不为过,它在最近几年大放异彩,几乎所有图像、语音识别领域的重要突破都是卷积神经网络取得的,比如谷歌的GoogleNet、微软的ResNet等,打败李世石的AlphaGo也用到了这种网络。本文将详细介绍卷积神经网络以及它的训练算法,以及动手实现一个简单的卷积神经网络。
一个新的激活函数——Relu
最近几年卷积神经网络中,激活函数往往不选择sigmoid或tanh函数,而是选择relu函数。Relu函数的定义是:

Relu函数图像如下图所示:

Relu函数作为激活函数,有下面几大优势:
- 速度快 和sigmoid函数需要计算指数和倒数相比,relu函数其实就是一个max(0,x),计算代价小很多。
- 减轻梯度消失问题 回忆一下计算梯度的公式。其中,是sigmoid函数的导数。在使用反向传播算法进行梯度计算时,每经过一层sigmoid神经元,梯度就要乘上一个。从下图可以看出,函数最大值是1/4。因此,乘一个会导致梯度越来越小,这对于深层网络的训练是个很大的问题。而relu函数的导数是1,不会导致梯度变小。当然,激活函数仅仅是导致梯度减小的一个因素,但无论如何在这方面relu的表现强于sigmoid。使用relu激活函数可以让你训练更深的网络。
# encoding:utf-8
#手写实现一个简单的卷积神经网络
#一些 工具函数
import numpy as np
from activator import ReluActivator, IdentityActivator
def padding(input_array, zero_padding):
#为数组周围添zero_padding圈0, 由input_array.ndim自动适配输入为2D和3D的情况
if zero_padding == 0:
return input_array
elif input_array.ndim == 2:
input_height = input_array.shape[0]
input_width = input_array.shape[1]
padded_array = np.zeros((input_height+ 2*zero_padding,input_width+2*zero_padding))
padded_array[zero_padding:zero_padding+input_height,zero_padding:zero_padding+input_width] = input_array
return padded_array;
elif input_array.ndim == 3:
depth = input_array.shape[0]
height = input_array.shape[1]
width = input_array.shape[2]
padded_array = np.zeros((depth,height+2*zero_padding,width+2*zero_padding))
padded_array[:,zero_padding:zero_padding+height,zero_padding:zero_padding+width] = input_array;
return padded_array;
def get_patch(input_array, i, j, filter_height, filter_width, stride):
#获得输入矩阵和filter相乘对应的部分矩阵
#首先得到部分矩阵的左上角起始点位置
start_i = i * stride;
start_j = j * stride;
if input_array.ndim == 2:
return input_array[start_i:start_i+filter_height,start_j:start_j+filter_width]
elif input_array.ndim == 3:
return input_array[:,start_i:start_i+filter_height,start_j:start_j+filter_width]
def conv(filter, input_array, bias, stride, output_array):
output_height = output_array.shape[0]
output_width = output_array.shape[1]
filter_height = filter.shape[-2]#0
filter_width = filter.shape[-1]#1
#从输出数组索引遍历
for i in range(output_height):
for j in range(output_width):
# * 为两个数组对应元素相乘仍为一个数组 3维数组.sum()为所有元素之和
output_array[i][j] = (get_patch(input_array,i,j,filter_height,filter_width,stride) * filter).sum()+bias
def element_wise_op(output_array, activator):
#按元素操作 逐元素激活
for i in np.nditer(output_array,op_flags=['readwrite']):
i[...] = activator(i)
# i[...]=2*i
class Filter(object):
#Filter类保存了卷积层的参数以及梯度,并实现了梯度下降算法更新参数
def __init__(self,depth, height, width):
#权重初始化用了常用的策略,即权重初始化一个小的随机数,偏置项置为0
self.weights = np.random.uniform(-1e-4, 1e-4,(depth,height,width))
self.bias = 0;
#梯度元素和权重元素一一对应
self.weights_grad = np.zeros(self.weights.shape)
self.bias_grad = 0;
def get_weights(self):
return self.weights
def get_bias(self):
return self.bias
def update(self,learning_rate):
self.weights = self.weights - self.weights_grad * learning_rate
self.bias -= self.bias_grad * learning_rate
#打印输出信息 重载__repr__
def __repr__(self):
return 'filter weights:\n%s bias\n%s' % (repr(self.weights),repr(self.bias))
class ConvLayer(object):
def __init__(self,input_height,input_width,channel_number,
filter_height,filter_width,filter_number,
zero_padding,stride,activator,learning_rate):
'''
可以在构造函数里设置超参数
:param input_height:
:param input_width:
:param channel_number: 输入图像的深度和filter的深度相等
:param filter_height:
:param filter_width:
:param filter_number:filter的个数和输出数组的深度相等, 一个filter提取某种特征,他的深度为channel_number
:param zero_padding: 补零圈数
:param stride: 步长
:param activator:
:param learning_rate:
'''
self.input_height = input_height
self.input_width = input_width;
self.channel_number = channel_number
self.filter_height = filter_height
self.filter_width = filter_width
self.filter_number = filter_number
self.zero_padding = zero_padding
self.stride = stride
self.activator = activator
self.learning_rate = learning_rate
self.output_array_height = (input_height - filter_height + 2 * zero_padding) / stride + 1
self.output_array_width = (input_width - filter_width + 2 * zero_padding ) / stride + 1;
self.output_array = np.zeros((filter_number,self.output_array_height,self.output_array_width))
self.filters = []
for i in range(filter_number):
self.filters.append(Filter(channel_number,filter_height,filter_width))
def forward(self,input_array):
'''
计算卷积层的输出
输出结果保存在self.output_array
:param input_array: 输入样本矩阵
:return:
'''
self.input_array = input_array;
self.padded_input_array = padding(input_array, self.zero_padding);
#根据式1计算 aij = f(wmn*xi+m,y+n + wb)
for i in range(self.filter_number):
filter = self.filters[i]
#卷积 参数依次: 权值矩阵 补零的输入矩阵 权重矩阵的偏置项 步长 输出数组
conv(filter.get_weights(),self.padded_input_array,filter.get_bias(),self.stride,self.output_array[i])
#按元素激活输出数组的值
element_wise_op(self.output_array[i],self.activator.forward)
def backward(self, input_array, sensitivity_map, activator):
#这里的后向传播和之前的训练算法不太一样,该后向传播主要计算梯度未更新权重,之前的训练算法是更新的权重的
#计算传递给前一层的误差项,以及计算每个权重的梯度
#前一层的误差项保存在self.delta_array
#梯度保存在Filter.weights_grad
self.forward(input_array)
self.bp_sensitivity_map(sensitivity_map,activator)
self.bp_gradient(sensitivity_map)
def update(self):
#梯度下降算法更新权重
for filter in self.filters:
filter.update(self.learning_rate)
def bp_gradient(self,sensitivity_map):
expanded_array = self.expand_sensitivity_map(sensitivity_map)
#有几个filter就有几个误差项数组
for f_number in range(self.filter_number):
filter = self.filters[f_number]
#filter的深度和第l-1层输入的深度相等 每个误差项数组和一个filter的所有深度个数的元素数组相乘得到
# 这个filter的所有深度个数的梯度数组 梯度和每个权重元素是一一对应的
for d in range(filter.weights_grad.shape[0]):
#梯度更新为第l-1层的输入乘上第l层的误差项
conv(expanded_array[f_number],self.padded_input_array[d],0,1,filter.weights_grad[d])
filter.bias_grad = expanded_array[f_number].sum()
def expand_sensitivity_map(self, sensitivity_map):
#记得误差项一般会有深度的
depth = sensitivity_map.shape[0]
expand_height = (self.input_height - self.filter_height + 2 * self.zero_padding) / 1 + 1
expand_width = (self.input_width - self.filter_width + 2 * self.zero_padding) / 1 + 1
expand_array = np.zeros((depth, expand_height,expand_width))
#用[:,i,j]遍历深度元素 先遍历小的即步长大的误差项数组 对应位置(i,j)一次乘步长得到的对应位置 得到对应位置元素拷贝到还原数组expand_array
for i in range(sensitivity_map.shape[1]):
for j in range(sensitivity_map.shape[2]):
i_pos = i * self.stride
j_pos = j * self.stride
expand_array[:,i_pos,j_pos] = sensitivity_map[:,i,j]
return expand_array
def bp_sensitivity_map(self, sensitivity_map, activator):
#计算前一层的误差项并保存在self.delta_array
#还原输入误差项步长为1
expanded_array = self.expand_sensitivity_map(sensitivity_map)
#周围补一圈0 由式2推导
expanded_width = expanded_array.shape[2]
zp = (self.input_width + self.filter_width - 1 - expanded_width) / 2
padded_array = padding(expanded_array,zp)
#将filter翻转180度
weights_height = self.filter_height
weights_width = self.filter_width
# fan_filter = self.create_delta_array()
self.delta_array = self.create_delta_array()
for f_number in range(self.filter_number):
filter = self.filters[f_number]
# for i in range(weights_height):
# for j in range(weights_width):
# fan_filter[:,weights_height - 1 - i, weights_width - 1 - j] = filter.weights[:, i, j]
# 上方注释的代码也是翻转180度为自己所写 下面的是numpy 将filter翻转180度
fan_filter = np.array(map(lambda i: np.rot90(i, 2),filter.weights))
#误差项和翻转的filter卷积,
delta_array = self.create_delta_array()
#注意是反向 所以padded_array[]为f_number 个数与filter个数对应
for d in range(self.channel_number):
conv(fan_filter[d],padded_array[f_number],0,1,delta_array[d])
#对于具有多个filter的卷积层而言,最终传递到上一层的 sensitivity_map
#等于所有filter的sensitivity_map之和
self.delta_array += delta_array
# 再和前一层的激活函数的导数逐元素相乘得到前一层的误差项并保存到self.delta_array
derivative_array = np.array(self.input_array)
element_wise_op(derivative_array,activator.backward)
self.delta_array *= derivative_array
def create_delta_array(self):
return np.zeros((self.channel_number, self.input_height, self.input_width))
def init_test():
a = np.array([
[[0,1,1,0,2],
[2,2,2,2,1],
[1,0,0,2,0],
[0,1,1,0,0],
[1,2,0,0,2]],
[[1,0,2,2,0],
[0,0,0,2,0],
[1,2,1,2,1],
[1,0,0,0,0],
[1,2,1,1,1]],
[[2,1,2,0,0],
[1,0,0,1,0],
[0,2,1,0,1],
[0,1,2,2,2],
[2,1,0,0,1]]
]);
b = np.array([
[[0,1,1],
[2,2,2],
[1,0,0]],
[[1,0,2],
[0,0,0],
[1,2,1]]
])
c = ConvLayer(5,5,3,3,3,2,1,2,IdentityActivator(),0.001)
c.filters[0].weights = np.array([[[-1,1,0],
[0,1,0],
[0,1,1]],
[[-1,-1,0],
[0,0,0],
[0,-1,0]],
[[0,0,-1],
[0,1,0],
[1,-1,-1]]],dtype=np.float64)
c.filters[0].bias = 1;
c.filters[1].weights = np.array([[[1,1,-1],
[-1,-1,1],
[0,-1,1]],
[[0,1,0],
[-1,0,-1],
[-1,1,0]],
[[-1,0,0],
[-1,0,1],
[-1,0,0]]],dtype=np.float64)
c.filters[1].bias = 0;
return a,b,c;
def gradient_check():
#卷积层梯度检查 本函数是针对一层卷积网络而言的
#建立误差函数
error_function = lambda o:o.sum();
#得到数据集
a,b,c1 = init_test()
#前向计算
c1.forward(a)
#获得误差项数组 因为是线性函数 所以误差项数组为一个全为一的数组
sensitivity_map = np.ones(c1.output_array.shape,dtype=np.float64)
#后向传播
# c1.backward(a,sensitivity_map,IdentityActivator())
c1.bp_gradient(sensitivity_map)
epision = 10e-4
#遍历每个权重,得到训练值并于计算值一起打印输出
for filter in c1.filters:
for d in range(filter.weights_grad.shape[0]):
for i in range(filter.weights_grad.shape[1]):
for j in range(filter.weights_grad.shape[2]):
weight = filter.weights[d,i,j]
#当前权重加一个精度epision=10^-4,前向计算,输出数组求和为误差Ed+
filter.weights[d,i,j] = weight + epision;
c1.forward(a)
err1 = error_function(c1.output_array)
# 当前权重减一个精度10^-4,前向计算,输出数组求和为误差Ed-
filter.weights[d,i,j] = weight - epision;
c1.forward(a)
err2 = error_function(c1.output_array)
#计算梯度近似值为(Ed+ - Ed-)/(2*epision)
calc_gradient = (err1 - err2) / (2 * epision)
print "weights[%d,%d,%d]:actual_gradiet-calc_gradient: %f-%f" % (d,i,j,filter.weights_grad[d,i,j],calc_gradient)
#恢复权重
filter.weights[d,i,j] = weight
def test():
a,b,c1 = init_test()
c1.forward(a)
print c1.output_array
def test_bp():
a,b,c1 = init_test()
c1.backward(a,b,IdentityActivator())
c1.update()
print c1.filters[0]
print c1.filters[1]
def get_max_index(patch):
max = patch[0][0];
max_i = 0;
max_j = 0;
for i in range(patch.shape[0]):
for j in range(patch.shape[1]):
if patch[i][j] > max:
max = patch[i][j]
# max_i = i;
# max_j = j;
max_i, max_j = i, j
return max_i, max_j
class Maxpool(object):
def __init__(self,input_height,input_width,channel_number,
filter_height,filter_width,stride):
#池化层作用就是下采样 因此filter纬度就是2维
self.input_height = input_height
self.input_width = input_width
self.channel_number = channel_number
self.filter_height = filter_height
self.filter_width = filter_width
self.stride = stride
self.output_height = (input_height - filter_height) / stride + 1
self.output_width = (input_width - filter_width) / stride + 1
self.output_array = np.zeros((self.channel_number,self.output_height,self.output_width),dtype=np.float64)
def forward(self,input_array):
#因为纬度不变,所以要依次遍历每个输入数组
for d in range(self.channel_number):
for i in range(self.output_height):
for j in range(self.output_width):
self.output_array[d][i][j] = get_patch(input_array[d],i,j,self.filter_height,self.filter_width,self.stride).max()
# print (get_patch(input_array[d],i,j,self.filter_height,self.filter_width,self.stride).max())
def backward(self,input_array,sensitivity_map):
self.delta_array = np.zeros(input_array.shape)
for d in range(self.channel_number):
for i in range(self.output_height):
for j in range(self.output_width):
patch = get_patch(input_array[d],i,j,self.filter_height,self.filter_width,self.stride)
i_max,j_max = get_max_index(patch)
self.delta_array[d,i * self.stride + i_max,j * self.stride + j_max] = sensitivity_map[d,i,j]
def init_test_mpl():
a = np.array(
[[[1,1,2,4],
[5,6,7,8],
[3,2,1,0],
[1,2,3,4]],
[[0,1,2,3],
[4,5,6,7],
[8,9,0,1],
[3,4,5,6]]],dtype=np.float64)
b = np.array(
[[[1,2],
[2,4]],
[[3,5],
[8,2]]],dtype=np.float64)
mpl = Maxpool(4,4,2,2,2,2)
return a,b,mpl
def test_maxpool():
a,b,mpl = init_test_mpl()
mpl.forward(a)
print mpl.output_array
def test_bp_maxpool():
a,b,mpl = init_test_mpl()
#池化层没有梯度的计算 无激活函数 仅仅是将误差项传递到上一层
mpl.backward(a,b)
print "input: \n%s\n sensitity_map:\n %s\n delta_array:\n %s\n" % (a,b,mpl.delta_array)
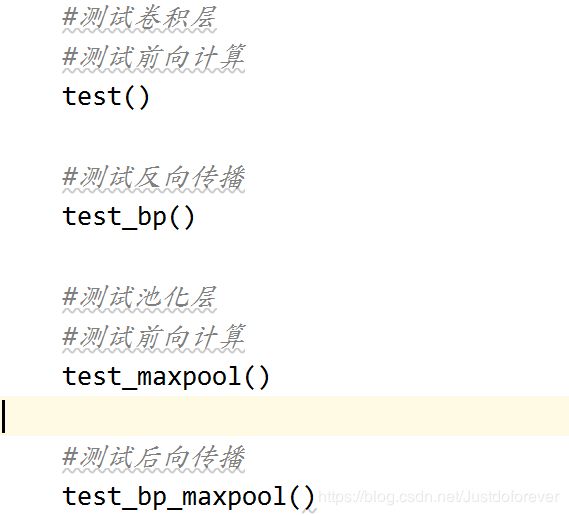
if __name__ == '__main__':
a = np.random.randint(2,9,(2,2))
print a
# # element_wise_op(a,2)
# print a
# for i in a:
# print i
# gradient_check()
#数组翻转180度
# b = np.zeros(a.shape)
# for i in range(2):
# for j in range(2):
# b[ 1 - i, 1 - j] = a[i, j]
# print b
# c = np.array(np.rot90(a,2))
# print c
#测试卷积层
#测试前向计算
test()
#测试反向传播
test_bp()
#测试池化层
#测试前向计算
test_maxpool()
#测试后向传播
test_bp_maxpool()