深度前馈网络学习方法
深度前馈网络学习方法
- 什么是深度前馈网络
- 学习路线
- 实例:关于学习 X O R XOR XOR
- 基于梯度的学习
- 输出单元
- 隐藏单元
- 架构设计
- 反向传播算法
- 术语介绍
- 凸函数
- 极大似然函数
- 仿射变换
- 正定矩阵
- 总结
什么是深度前馈网络
深度前馈网络(deep feedforward network),也叫做前馈神经网络(feedforward neurnal network)或者多层感知机(multilayer perceptron, MLP),是典型的深度学习模型。前馈网络的目标是近似某个函数f*。例如,对于分类器,y=f*(x)将输入x映射到一个类别y。前馈网络定义了一个映射y=f(x;θ),并且学习参数θ的值,使它能够得到最佳的函数近似。
#我们可以把'深度前馈网络'拆开来看:
'深度':在解释这个概念之前我们要明确一点就是,所谓的机器学习,我们的目标就是研究
一个可以解决实际问题的数学模型(函数)。 例如,我们有三个函数f,g和t,
连接在一个链上以形成h(x)=f(g(t(x)))。这些链式结构是神经网络中最常用的结构。
在这种情况下,f(1)被称为网络的第一层(first layer),f(2)被称为第二层(second layer),
依此类推。链的全长称为模型的深度(depth)。正是因为这个术语才出现了”深度学习”这个名字。
'前馈':在前馈神经网络内部,参数从输入层向输出层单向传播,有异于递归神经网络,它的内部不会构成有向环。
'网络':前馈神经网络被称作网络(network)是因为它们通常用许多不同函数复合在一起来表示。
该模型与一个有向无环图相关联,而图描述了函数是如何复合在一起的。学习路线
一种理解前馈网络的方式是从线性模型开始,并考虑如何克服它的局限性。线性模型如逻辑回归和线性回归,他们无论是通过闭解形式还是凸优化,他们都能高效且可靠的拟合。但是线性模型也有明显的缺陷,就是模型的能力被局限在线性函数里,无法理解任何两个输入变量间的关系。
为了解决线性模型的这种局限性问题,我们会使用一种扩展的线性模型来表示 x x x的非线性函数:我们不用线性模型表示 x x x本身,而是用在一个变换后的 φ ( x ) φ(x) φ(x)上。这里的 φ φ φ是一个非线性变换。
深度学习的策略就是去学习 φ φ φ
实例:关于学习 X O R XOR XOR
为了使前馈网络的想法更加具体,我们首先从一个可以完整工作的前馈网络说起。这个例子解决一个非常简单的任务:学习 X O R XOR XOR函数。
X O R XOR XOR函数(‘异或’逻辑)是两个二进制值 x 1 x_{1} x1和 x 2 x_{2} x2的运算。当这些二进制值中恰好有一个为1时, X O R XOR XOR函数返回值为1.其余情况返回值为0. X O R XOR XOR函数提供了我们想要学习的目标函数 y = f ∗ ( x ) y=f^{*}(x) y=f∗(x).我们的模型给出了一个函数 y = f ( x ; θ ) y=f(x;\theta ) y=f(x;θ),并且我们的学习算法会不断调整参数 θ \theta θ来使得 f f f尽可能接近 f ∗ f^{*} f∗。
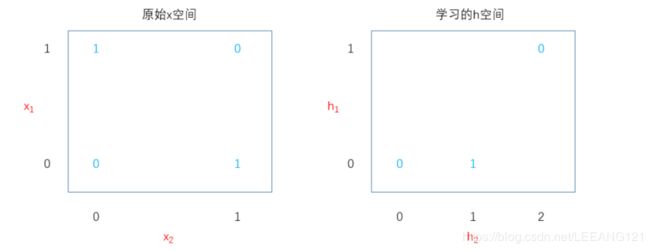
上图中的蓝色字体表明学习的函数必须在每个点输出的值。
左图 :直接应用于原始输入的线性模型不能实现 X O R XOR XOR函数。当 x 1 = 0 x_{1}=0 x1=0时,模型的输出必须随着 x 2 x_{2} x2的增大而增大。当 x 1 = 1 x_{1}=1 x1=1时,模型的输出必须随着 x 2 x_{2} x2的增大而减小。线性模型必须对 x 2 x_{2} x2使用固定的系数,因此,线性模型无法解决这个问题。
右图:右图由神经网络提取了特征并形成了新的空间,在这个空间中线性模型可以解决这个问题了:我们在新的空间中将输出必须为1的两个点折叠到了特征空间中的单个点。换句话说,非线性特征将 x = [ 1 , 0 ] T x=[1,0]^{T} x=[1,0]T和 x = [ 0 , 1 ] T x=[0,1]^{T} x=[0,1]T都映射到了特征空间中的单个点 h = [ 1 , 0 ] T h=[1,0]^{T} h=[1,0]T。这样做的好处是增加了函数的表达能力。新的空间可以用一条直线将0和1分开。
'这个实例想要说明的问题是',线性模型在表达上很多时候会有局限性,这也是为什么线性模型计算简单但是
我们神经网络却通常使用非线性模型的原因。基于梯度的学习
梯度学习的目的:寻求最优的方式使得代价函数下降。
现在问题来了,什么是代价函数?它可以做什么?
百度百科的解释如下:
损失函数(loss function)或代价函数(cost function)是将随机事件或其有关随机变量的取值映射为非负实数以表示该随机事件的“风险”或“损失”的函数。在应用中,损失函数通常作为学习准则与优化问题相联系,即通过最小化损失函数求解和评估模型。例如在统计学和机器学习中被用于模型的参数估计(parameteric estimation)。
百度百科的解释太抽象,实际情况是这样:
我们为了解决实际问题,会给出一个解决问题的数学模型,注意,这里的数学模型是我们根据经验得出的,它的准确度使我们要关心的问题。而我们在进行模型优化的时候,我们事先知道的是真实的结果。现在我们就要拿我们设计的模型计算出来一个结果去匹配这个真实的结果。这中间就产生了误差,这个误差就是我们的代价或者损失。我们现在要去尽可能的减少这个损失。
通俗的说,我们优化网络做的事情就是最小化代价函数
概率论中我们分析数据间的差距大不大,通常会采用均方误差或者平均绝对误差。但是当我们结合梯度下降的方法进行优化的时候,效果往往很差。原因是一些饱和的输出单元在结合这些代价函数时会产生非常小的梯度。为了解决这个问题,我们代价函数通常会采用交叉熵方法。
如果大家对交叉熵不是很理解,可以关注我的这篇博文
啥也不懂照样看懂交叉熵损失函数
如果大家想更多一些了解代价函数、梯度相关的概念,可以参考我的这篇文章
简明扼要解释梯度下降
输出单元
下面我们简单的讨论一下输出单元这个概念。这个概念很重要,因为它和代价函数的选择紧密相关。大多数时候,我们简单的使用数据分布和模型分部间的交叉熵。选择如何表示输出决定了交叉熵函数的形式。
用于高斯输出分布的线性单元
一种简单的输出单元是基于仿射变换的输出单元,放射变换不具有非线性。这些单元往往被称为线性单元。
线性输出层经常被用来产生条件高斯分布的均值:
p ( y ∣ x ) = N ( y ; y ^ , I ) p(y|x)=N(y;\hat{y},I) p(y∣x)=N(y;y^,I)
最大化其对数似然此时等价于最小化均方误差。因为线性单元不会饱和,所以他们易于采用基于梯度的优化算法,甚至可以使用其他多种优化算法。
用于Bernoulli输出分布的sigmoid单元
许多任务需要预测二值型变量 y y y的值。具有两个类的分类问题可以归结为这种形式。
此时最大似然的方法就是定义 y y y在 x x x条件下的Bernoulli分布。
但是这种分布策略有一个严重的问题就是,由于它是一个二值分布,当输出的值在我们的设定区间外部时,模型的输出对其参数的梯度全部变为0.梯度为0通常是有问题的,因为学习算法对于如何改善相应的参数不再具有指导意义。
这个时候我们期望使用一种新的方法来保证无论何时模型给出了错误的答案时,总能有一个较大的梯度。这种方法就是基于sigmoid输出单元结合最大似然来实现的。
如果大家对于sigmoid不了解,可以关注我的另外一篇博文
说一说激活函数是个啥
用于Multinoulli输出分布的softmax单元
上面我们提到了输出结果是一个二元分类的问题时的解决方案,但是很多时候我们想要表示的结果往往是多元化的。这时候我们可以使用softmax分类函数。
softmax的输出结果是一个归一化的概率分布。
关于softmax函数,大家可以参考博文
通俗易懂的讲解Softmax
隐藏单元
以上我们简单的讨论了神经网络的设计选择问题,这对于使用基于梯度的优化方法来训练的大多数参数化机器学习模型都是通用的。现在我们讨论一个前馈神经网络独有的问题:该如何选择隐藏单元的类型,这些隐藏单元用在模型的隐藏层中。
为什么叫隐藏单元
在我们讨论隐藏单元之前,搞清楚为什么叫隐藏单元是有必要的。
我们在神经网络的训练过程中,我们让训练的模型去匹配最终的输出值。训练数据为我们提供了在不同训练点上取值的、含有噪声的近似实例。每个样本 x x x都伴随着一个标签 y y y。训练样本直接指明了输出层在每个 x x x上必须做什么:它必须产生一个接近标签的值。但是训练数据并没有直接说明其他层应该怎么做。学习算法必须决定如何使用这些层来产生想要的输出,但是训练数据并没有说每个单独的层应该做什么。相反,学习算法必须决定如何使用这些层来最好的实现最终真实结果的近似。因为训练数据没有给出这些层中每一层所需要的输出,所以这些层被称为隐藏层。
常用的一些隐藏层
整流线型单元
整流线型单元及其扩展:绝对值整流、渗漏整流线型单元、参数化整流线型单元
logistic sigmoid与双曲正切函数
其他隐藏单元
关于这些隐藏层的单元介绍,大家可以参照我的博文
说一说激活函数是个啥
这里面只是大概的介绍了每个激活函数的概念。详细的原理我之后会持续更新。
架构设计
神经网络设计的另一个关键点是确定它的架构:它应该具有多少个单元,以及这些单元该如何连接。
大多数神经网络被组织成称为层的单元组。大多数神经网络架构将这些层布置成链式结构,其中每一层都是前一层的函数。在这种结构中,第一层可以表示如下:
h 1 = g 1 ( W ( 1 ) T x + b ( 1 ) ) h^{1}=g^{1}(W^{(1)T}x+b^{(1)}) h1=g1(W(1)Tx+b(1))
第二层由
h 2 = g 2 ( W ( 2 ) T x + b ( 2 ) ) h^{2}=g^{2}(W^{(2)T}x+b^{(2)}) h2=g2(W(2)Tx+b(2))
给出,以此类推。
在这些链式架构中,主要的架构考虑是选择网络的深度和每一层的宽度。我们将会看到,即使只有一个隐藏层的网络也足够适应训练集。更深层的网络通常能够对每一层使用更少的单元数和更少的参数,并且经常容易泛化到测试集,但是通常也更难以优化。对于一个具体的任务,理想的网络架构必须通过实验,观测在验证集上的误差来找到。
关于架构的小结论:
1,具有单层的前馈网络足以表示任何函数,但是网络层可能大的不可实现;
2,使用更深的模型能够减少表示期望函数所需的单元的数量,并且可以减少泛化误差。
反向传播算法
当我们使用前馈神经网络接收输入并产生输出时,信息通过网络向前流动,这个过程称为前向传播。训练过程中,前向传播可以持续向前直到它产生了一个标量代价函数。反向传播算法允许来自代价函数的信息通过网络向后流动,以便计算梯度。
反向传播这个术语经常被误解为用于多层神经网络的整个学习算法,实际上,反向传播仅指用于计算梯度的算法。
关于反向传播的使用示例,大家可以参照我的博文
CNN卷积神经网络原理详解(下),这里面详细介绍了反向传播如何通过链式法则实现的全过程。
术语介绍
如果您已经阅读到了这里,那么恭喜您,关于前馈神经网络要掌握的概念基本上您已经全部看完了。(关于里面涉及到的模型细节问题,我们会在其他文章里面详细讨论。但是关于什么是前馈神经网络,这些就足够了)
上面的介绍里面涉及了一些可能会影响理解的术语,例如:凸函数、仿射变换、最大似然原理、正定矩阵等。如果您对这些非常了解,那么恭喜您,这篇文章剩下的内容您可以跳过了,如果您忘记了这些概念,想要了解一下,那么欢迎继续下面的内容。
凸函数
先从凸优化说起
凸优化问题(OPT,convex optimization problem)指定义在凸集中的凸函数最优化的问题。尽管凸优化的条件比较苛刻,但仍然在机器学习领域有十分广泛的应用。
凸优化的优势:
1,凸优化问题的局部最优解就是全局最优解
2,很多非凸问题都可以被等价转化为凸优化问题或者被近似为凸优化问题(例如拉格朗日对偶问题)
3,凸优化问题的研究较为成熟,当一个具体被归为一个凸优化问题,基本可以确定该问题是可被求解的
几何意义:
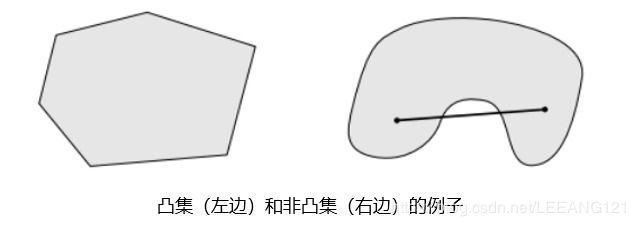
直观来说,任取一个集合中的两点练成一条线段,如果这条线段完全落在该集合中,那么这个集合就是凸集。
凸函数
定义:
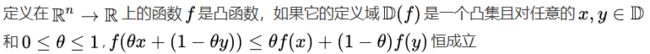
几何意义
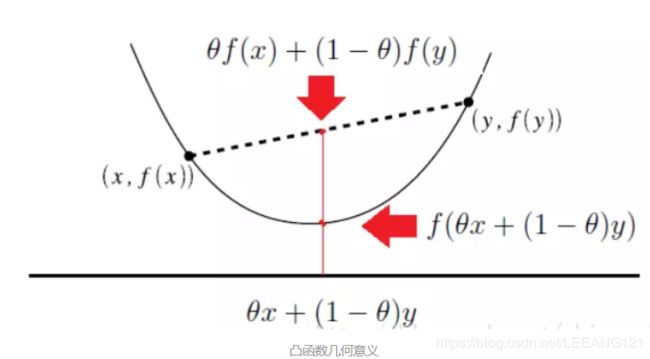
一句话总结:凸优化可以帮助我们更好的寻求最优解。
极大似然函数
首先我们用一张图来说明一下什么是极大似然原理
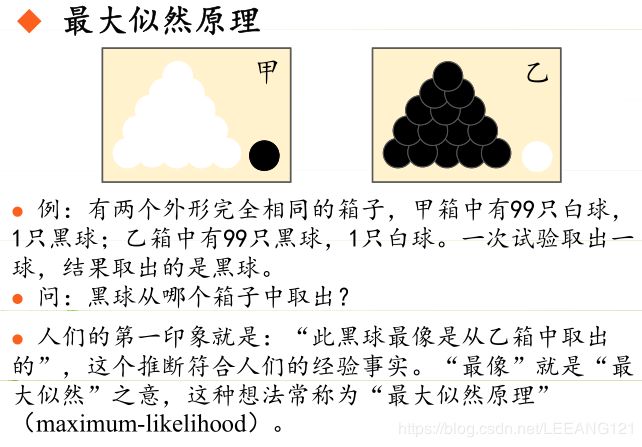
总结起来,最大似然估计的目的就是:利用已知的样本结果,反推最有可能(最大概率)导致这样结果的参数值。
原理:极大似然估计是建立在极大似然原理的基础上的一个统计方法,是概率论在统计学中的应用。极大似然估计提供了一种给定观察数据来评估模型参数的方法,即:“模型已定,参数未知”。通过若干次试验,观察其结果,利用试验结果得到某个参数值能够使样本出现的概率为最大,则称为极大似然估计。
关于极大似然估计的详细说明,大家可以参考
极大似然估计详解,写的太好了这篇文章。
仿射变换
神经网络的正向传播中进行的矩阵乘积运算在几何学领域被称为“仿射变换(Affine)
仿射变换的效果如下:
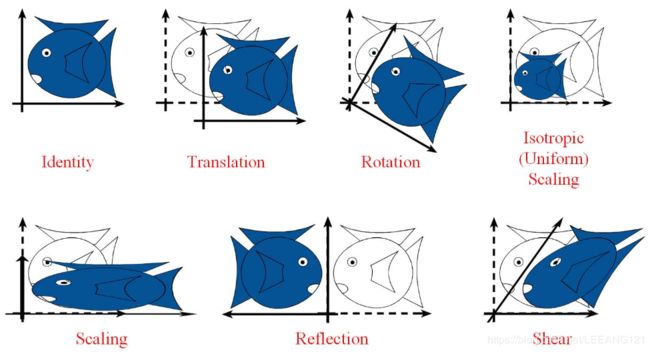
以上所有变换都属于仿射变换。
关于仿射变换的特点总结有三:
1,变换前是直线的,变换后依然是直线
2,直线比例保持不变
3,变换前是原点的,变换后依然是原点
仿射变换的好处就是:它不会改变原有数据的结构(这里的结构不是指形状,而是说,原有数据是线性的,变换后依然线性),但是可以增加数据的适配性。
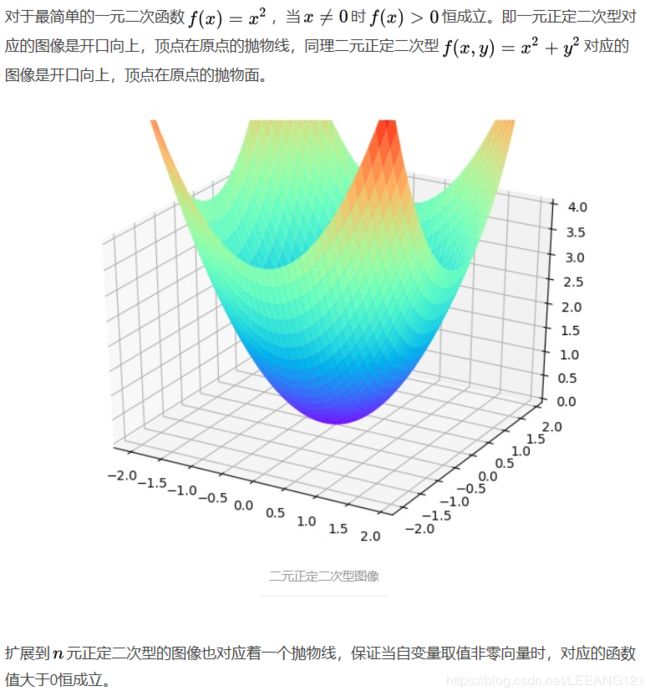
正定矩阵
正定矩阵的概念是从正定二次型引入的,对称矩阵 A A A为正定的充要条件即该矩阵的特征值全为正数。

几何意义理解正定矩阵为
总结
本篇博文主要是从概念上介绍了深度前馈网络在我们深度学习中的地位和重要性。其中包含了深度前馈网络名字的由来,了解该网络如何入手,通过一个实例 X O R XOR XOR阐述了线性模型的局限性。在梯度学习的小节里面讲述了交叉熵对比于均方误差的优势,介绍了sigmoid和softmax的使用区别。激活函数的大体用法是以对博文的引用形式进行了说明,架构设计里面说明了为何要讲网络做深的原因,最后提到了反向传播算法。这些介绍只是一个学习深度前馈网络的引子,如果想要进一步研究,还需要对里面的每个知识点认真研究。