Python源码之内存管理机制(一)---内存管理架构
文章目录
- 1、Python内存管理架构
- 2、小块空间的内存池
- 2.1 Block
- 2.2 pool
- 2.3 arena
- 2.4 内存池
1、Python内存管理架构
在Python中,内的管理被抽象成一种层次化的结构,在解析Python的内存管理机制前,有必要对Python的内存管理架构模型做一些了解。
在最底层也就是第0层,是操作系统所提供的一些内存管理的接口,例如C中的malloc, realloc,free等。在这一层是由操作系统来实现并管理的,对于Python来说touch不到这一层的行为权限。
再往上就是第一层,这一层实际上是在最底层的基础之上对接口提供了简单的包装,但是并没有其他的行为,这一层主要就是为了给Python提供统一的raw memory的接口。我们知道在C中已经有了一些基于操作系统的内存管理接口,但是要知道不同的平台在进行相同的动作时可能会返回不一样的结果。例如在调用malloc(0)的时候,有些系统会返回NULL,证明内存分配失败,可是在有的系统却可以返回一个指针,但是这个指针所指向的内存并非一个有效的内存。为了良好的可移植性,Python提供了这一层的包装来处理由平台环境引起的不同。这一层就是以PyMem_为前缀的函数簇:
PyAPI_FUNC(void *) PyMem_Malloc(size_t size);
PyAPI_FUNC(void *) PyMem_Realloc(void *ptr, size_t new_size);
PyAPI_FUNC(void) PyMem_Free(void *ptr);
//obmalloc.c
void *
PyMem_Malloc(size_t size)
{
/* see PyMem_RawMalloc() */
if (size > (size_t)PY_SSIZE_T_MAX)
return NULL;
return _PyMem.malloc(_PyMem.ctx, size);
}
void *
PyMem_Realloc(void *ptr, size_t new_size)
{
/* see PyMem_RawMalloc() */
if (new_size > (size_t)PY_SSIZE_T_MAX)
return NULL;
return _PyMem.realloc(_PyMem.ctx, ptr, new_size);
}
void
PyMem_Free(void *ptr)
{
_PyMem.free(_PyMem.ctx, ptr);
}
此外,在第一层除了那些仅仅是与raw memory内存分配相关的接口外还有与Python中内存相关的接口,就是PyMem_New(),这个接口提供类型和数量,系统将自动检测类型大小从而分配内存。
再往上就是第二层,第二层是一组以PyObject_为前缀的函数簇,这一层主要是为了给Python对象的创建提供接口。我们知道Python对象的创建需要很多初始化的操作,例如引用计数,对象参数的类型等,原始的raw memory午饭完成这些工作,因此需要构建第二层内存管理。
第三层主要就是缓冲池机制,我们之前解析的整数对象,字符串对象等,都建立了自己私有的更高层次的内存管理机制。我们在解析Python的内建对象时已经解析过了。而我们要解析的重点就是这第二层模型。
2、小块空间的内存池
在上面我们讲到过,在Python中的对象例如字符串,list对象等拥有自己的缓冲机制,它们位于内存管理的第三层结构中。但是如果对于小块内存的分配我们并不用于创建对象这种情况呢?是不是意味着,我们需要想系统频繁地申请内存并释放,底层将会频繁地进行malloc和free操作,因此操作系统会在用户态和核心之间频繁切换严重影响执行性能。因此对于这种没有对象一级缓冲机制的小块内存分配引入了小块内存池的机制,来管理内存的分配和释放,也就是我们前面说到的第二层机制,它提供了PyObject_malloc, PyObject_realloc,以及PyObject_free接口。在这一层也有一个抽象的层次模型,最底层为Block,接着分别是pool, arena,和内存池。
-
2.1 Block
block就是一个内存块,这个内存块具有固定的大小,在Python中有不同种类的内存块,这些不同种类的内存块被定义了不同的大小,而这些内存块的大小都是8的倍数,并且具有上限,这个上限在Python3.6中被定义为512 bytes,当申请的内存大小小于512字节的时候,Python就使用这些内存块,当大于这个上限的时候,那么这个内存的申请就由第一层来完成也就是PyMem_函数簇
// obmalloc.c
#define ALIGNMENT 8 /* must be 2^N */
#define ALIGNMENT_SHIFT 3
#define SMALL_REQUEST_THRESHOLD 512
#define NB_SMALL_SIZE_CLASSES (SMALL_REQUEST_THRESHOLD / ALIGNMENT)
因此根据上面的定义我们能得到以下的关系:
// Request in bytes Size of allocated block Size class idx
// ----------------------------------------------------------------
// 1-8 8 0
// 9-16 16 1
// 17-24 24 2
// 25-32 32 3
// 33-40 40 4
// 41-48 48 5
// 49-56 56 6
// 57-64 64 7
// 65-72 72 8
// ... ... ...
// 497-504 504 62
// 505-512 512 63
在上面的关系中,可以看到最右边由一个size class idx,它与后面所讲的pool有关,这里可以暂且理解为它是和Block的对应关系,每一个size class idx都对应了一种大小的Block。而这些Block的集合又是通过pool来进行管理的。
-
2.2 pool
pool在这里被定义为一组Block的集合,换句话说一个pool管理着一堆大小固定的Block的集合,pool管理着一大块内存,它根据一定的策略将这一大块内存划分为很多小的内存块。那么pool的大小是多少呢?通常一个pool被定义为一个系统page的大小就是4KB.我们来看看它的底层定义
// obmalloc.c
#define SYSTEM_PAGE_SIZE (4 * 1024)
#define SYSTEM_PAGE_SIZE_MASK (SYSTEM_PAGE_SIZE - 1)
// ..........
#define POOL_SIZE SYSTEM_PAGE_SIZE /* must be 2^N */
#define POOL_SIZE_MASK SYSTEM_PAGE_SIZE_MASK
/* Pool for small blocks. */
struct pool_header {
// 当前pool中已分配Block的数量
union { block *_padding;
uint count; } ref; /* number of allocated blocks */
// 用于指向下一个可用Block的链表
block *freeblock; /* pool's free list head */
// 指向下一个pool的指针
struct pool_header *nextpool; /* next pool of this size class */
// 指向上一个pool的指针
struct pool_header *prevpool; /* previous pool "" */
// 在arenas里面的索引
uint arenaindex; /* index into arenas of base adr */
// Block的大小的index
uint szidx; /* block size class index */
// 下一个可用Block的偏移量
uint nextoffset; /* bytes to virgin block */
// pool中最后一个Block与第一个Block的距离
uint maxnextoffset; /* largest valid nextoffset */
};
typedef struct pool_header *poolp;
从结构体的名称的定义中,我们可以看出这个结构体定义了一个pool的头部,这个pool的头部中维护了许多变量,在代码中给出了注释。前面解析Block时我们知道,每一个Block都有固定的大小,而pool也是如此,每一个pool所管理的Block的大小也是一样的。 也就是说每一个pool都只能管理一种大小类型Block,pool通过size class index联系在一起从而确定该pool中维护的是多大的Block内存块,这就是上面代码中的szidx变量。
现在我们来看看pool是用什么策略将一块大的内存划分为Block的集合的。
static void *
_PyObject_Alloc(int use_calloc, void *ctx, size_t nelem, size_t elsize)
{
size_t nbytes;
block *bp;
poolp pool;
poolp next;
uint size;
// 指向了一块4KB的内存
// ............
init pool:
// .....
//
pool->ref.count = 1;
if (pool->szidx == size) {
bp = pool->freeblock;
assert(bp != NULL);
pool->freeblock = *(block **)bp;
UNLOCK();
if (use_calloc)
memset(bp, 0, nbytes);
return (void *)bp;
}
// 设置pool的szidx,用于指示该index所对应的Block的大小
pool->szidx = size;
// 用于就将该index映射为对应的Block大小
size = INDEX2SIZE(size);
// 将bp指针指向除开pool head之外的内存区域
bp = (block *)pool + POOL_OVERHEAD;
// 将nextoffset的值设置为下一个可用Block的偏移量
pool->nextoffset = POOL_OVERHEAD + (size << 1);
pool->maxnextoffset = POOL_SIZE - size;
pool->freeblock = bp + size;
*(block **)(pool->freeblock) = NULL;
UNLOCK();
if (use_calloc)
memset(bp, 0, nbytes);
// 返回pool中第一块可用Block的指针
return (void *)bp;
}
}
从上面的代码中我们可以看到,当给定一个pool后在初始化的时候,会先将ref.count的数量置为1用于指示已经分配了一个Block,此时的bp就是用于指向第一块Block的指针,组要注意的是这个指针后有将近4KB的内存但是申请内存的函数只会用 bp----bp+size这个区间的内存。我们用一个图来说明改造后的内存区域
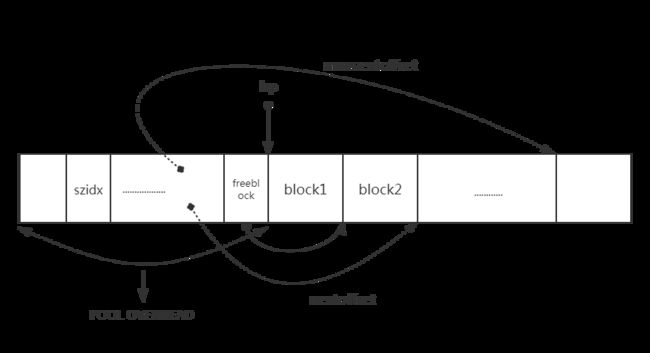
图中的实线是指针,虚线为相对于pool头部偏移位置的形象表示。我们接着往下看再次申请Block时pool_header中的各个域是怎么变化的。
// obmalloc.c
static void *
_PyObject_Alloc(int use_calloc, void *ctx, size_t nelem, size_t elsize)
{
// ............
if (pool != pool->nextpool) {
// 将pool中已分配的Block的数量自增
++pool->ref.count;
// 将下一个可用Block的地址赋给bp
bp = pool->freeblock;
assert(bp != NULL);
if ((pool->freeblock = *(block **)bp) != NULL) {
UNLOCK();
if (use_calloc)
memset(bp, 0, nbytes);
return (void *)bp;
}
/*
* Reached the end of the free list, try to extend it.
*/
// 如果下一个Block的偏移量小于最后一个Block的偏移量
if (pool->nextoffset <= pool->maxnextoffset) {
/* There is room for another block. */
// 需要移动指针指向下一个可用的Block
// freeblock等于当前block的地址+nextoffset(下一个可用block的偏移量)
pool->freeblock = (block*)pool +
pool->nextoffset;
// 调整下一个可用Block的偏移量
pool->nextoffset += INDEX2SIZE(size);
*(block **)(pool->freeblock) = NULL;
UNLOCK();
if (use_calloc)
memset(bp, 0, nbytes);
return (void *)bp;
}
// ........
}
// ...............
}
从代码中我们可以看到,每次当需要申请一块新的Block时只需要将freeblock指向的地址赋值给bp返回即可。每次在新申请了一块Block后都需要调整相应的域,此时就需要用nextoffset这个域来进行迭代,从上面的图我们可以知道,nextoffset指示的位置恰好是freeblock指向的地址的下一个可用block地址。每次分配Block后,这些变量都会相应往前移动。以此往复,就可以遍历完所有可用的block,当nextoffset的值大于maxnextoffset的值时就说明该pool中的block已经用完。
但是有一个问题,我们在解析整数对象的内存管理缓冲机制的时候说过,当原来的内存块被释放的时候Python的处理方式。同样,当分配了的block被释放的时候也就以为着pool中又有了新的可用的block,这个时候如何处理呢?实际上处理方式和整数对象中的缓冲机制相似,也是通过一个链表将离散可用的block联系起来。这个联系起来的操作自然就是在这个Block被释放的时候。
// obmalloc.c
static void
_PyObject_Free(void *ctx, void *p)
{
poolp pool;
block *lastfree;
poolp next, prev;
uint size;
if (p == NULL) /* free(NULL) has no effect */
return;
_Py_AllocatedBlocks--;
#ifdef WITH_VALGRIND
if (UNLIKELY(running_on_valgrind > 0))
goto redirect;
#endif
// 判断p所指向的地址是否在此pool中
pool = POOL_ADDR(p);
if (address_in_range(p, pool)) {
/* We allocated this address. */
LOCK();
assert(pool->ref.count > 0); /* else it was empty */
*(block **)p = lastfree = pool->freeblock;
pool->freeblock = (block *)p;
// ......
}
// 当存在自由链表时的操作
if ((pool->freeblock = *(block **)bp) != NULL) {
UNLOCK();
if (use_calloc)
memset(bp, 0, nbytes);
return (void *)bp;
}
因此我们可以这样理解Python如何将已经释放的Block重新组织起来,此时freeblock指向一块可用的block的首地址,这块可用的Block由于未被使用因此其值为NULL,此时已经使用的某个Block内存被释放的时候,会将这块内存的第一个字节存放当前freeblock的值,然后让freeblock指向这块block,如果再有一块block被释放的时候,就让当前这个Bock的第一个字节存放之前被释放掉的那个block的值,并让freeblock指向当前这个被释放的block,因此可以看见这些离散的Block就又被重新链接起来,当需要申请时就从链表里拿出来。因此就可以用freeblock = freeblock的方式遍历这条链表,当freeblock==NULL时说明链表到头这时需要重新申请block了。因此在上面的代码中最后我贴出了一段代码就是当freeblock所指向的内存非空时,也就是存在自由链表,就将这个内存区域初始化为0,并将此内存块直接返回即可。
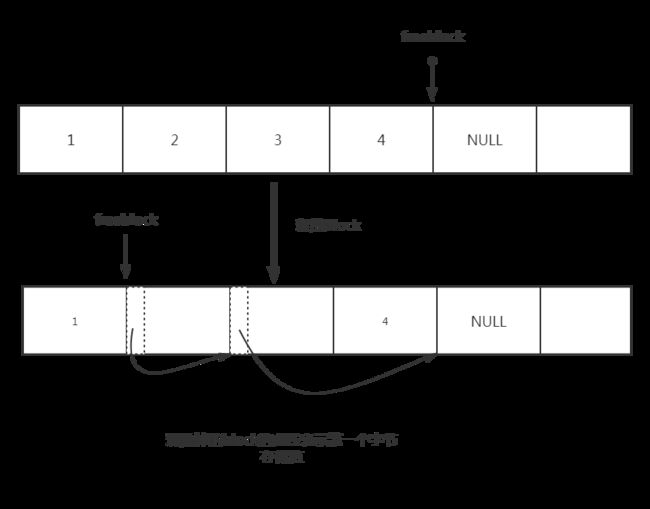
-
2.3 arena
上面我们提到的只是一个pool的情形,当很多pool的时候就是arena,每个pool的大小为4KB,而每个arena的大小默认值为 256KB。我们来看看它的底层定义
// obmalloc.c
#define ARENA_SIZE (256 << 10) /* 256KB */
struct arena_object {
uintptr_t address;
/* Pool-aligned pointer to the next pool to be carved off. */
block* pool_address;
/* The number of available pools in the arena: free pools + never-
* allocated pools.
*/
uint nfreepools;
/* The total number of pools in the arena, whether or not available. */
uint ntotalpools;
/* Singly-linked list of available pools. */
struct pool_header* freepools;
struct arena_object* nextarena;
struct arena_object* prevarena;
};
与pool类似,上面定义的arena也只是它的头部,一个完整的arena包含这个头部与其维护的内存区域。下面我们就来说说这个头部究竟包含了些什么。
我们从pool中可以看到多个pool组成了一个集合由arena来维护,同样一个或多个arena构成了一个arena数组,数组的首地址由arenas维护,这个数组就是Python中通用小内存块的内存池。nextarena和prevarena用来构成链表。
arena是用来管理一组pool的集合的,arena_object的作用看上去和pool_header的作用是一样的。但是实际上,pool_header管理的内存和arena_object管理的内存有一点细微的差别。pool_header管理的内存pool_header自身是一块连续的内存,但是arena_object与其管理的内存则是分离的,它们的图示如下,
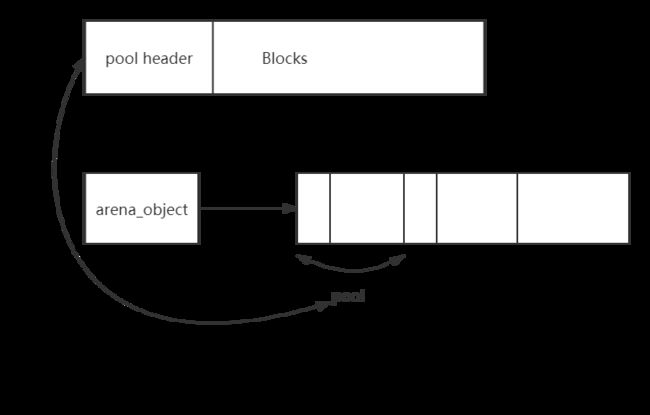
从它们结构上的差异我们可以看出两者的不同,当pool_header被创建时,由于它们内存是连续的因此它说维护的内存也一块被申请了。但是arena_object被申请时,它所维护的pool内存还没有被申请,那么arena_header在什么时候与pool集合联系起来的呢?
其实arena被分为两种状态,当arena还没有与pool集合联系起来时,我们称之为unused态(未使用状态);当arena已经与pool集合联系起来时称之为usable态(可用状态)。 每一种状态的arena都会通过链表连接起来。unused态的链表表头为unused_arena_objects,通过nextarena指针将这些arena连接起来,是一个单向链表;而usable态的链表表头为usable_arenas,通过prevarena和nextarena将这些arena连接起来是一个双向链表。我们也用一个图示来说明

接下来我们来看看一个arena是如何被创建的,在底层通过调用new_arena()函数来创建一个arena
//obmalloc.c
//arenas,多个arena组成的数组的首地址
static struct arena_object* arenas = NULL;
//当arena数组中的所有arena的个数
static uint maxarenas = 0;
//未使用的arena的链表表头
static struct arena_object* unused_arena_objects = NULL;
//可用的arena的链表
static struct arena_object* usable_arenas = NULL;
//初始化需要申请的arena的个数
#define INITIAL_ARENA_OBJECTS 16
static struct arena_object*
new_arena(void)
{
struct arena_object* arenaobj;
uint excess; /* number of bytes above pool alignment */
void *address;
static int debug_stats = -1;
// 对内存模式的判断,Python内村管理有两种模式,我们分析的都是在非debug模式下的
// 不用管这个,不是我们分析的重点
if (debug_stats == -1) {
char *opt = Py_GETENV("PYTHONMALLOCSTATS");
debug_stats = (opt != NULL && *opt != '\0');
}
if (debug_stats)
_PyObject_DebugMallocStats(stderr);
// 判断是否需要扩充的unused态的arena的链表
if (unused_arena_objects == NULL) {
uint i;
uint numarenas;
size_t nbytes;
// 扩充链表的个数,要么为原来的2倍,要么为初始化的大小
numarenas = maxarenas ? maxarenas << 1 : INITIAL_ARENA_OBJECTS;
if (numarenas <= maxarenas)
return NULL; /* overflow */
#if SIZEOF_SIZE_T <= SIZEOF_INT
if (numarenas > SIZE_MAX / sizeof(*arenas))
return NULL; /* overflow */
#endif
nbytes = numarenas * sizeof(*arenas);
arenaobj = (struct arena_object *)PyMem_RawRealloc(arenas, nbytes);
if (arenaobj == NULL)
return NULL;
arenas = arenaobj;
assert(usable_arenas == NULL);
assert(unused_arena_objects == NULL);
/* Put the new arenas on the unused_arena_objects list. */
// 将扩充后的arena放入未使用的链表中
for (i = maxarenas; i < numarenas; ++i) {
arenas[i].address = 0; /* mark as unassociated */
arenas[i].nextarena = i < numarenas - 1 ?
&arenas[i+1] : NULL;
}
/* Update globals. */
unused_arena_objects = &arenas[maxarenas];
maxarenas = numarenas;
}
/* Take the next available arena object off the head of the list. */
assert(unused_arena_objects != NULL);
// 从未使用的链表中取出一个arena
arenaobj = unused_arena_objects;
// 让链表指向下一个未使用的arena
unused_arena_objects = arenaobj->nextarena;
assert(arenaobj->address == 0);
// 申请arena_object所管理的内存
address = _PyObject_Arena.alloc(_PyObject_Arena.ctx, ARENA_SIZE);
if (address == NULL) {
/* The allocation failed: return NULL after putting the
* arenaobj back.
*/
arenaobj->nextarena = unused_arena_objects;
unused_arena_objects = arenaobj;
return NULL;
}
// 将申请的内存的地址赋值给arenaobj的address域
arenaobj->address = (uintptr_t)address;
++narenas_currently_allocated;
++ntimes_arena_allocated;
if (narenas_currently_allocated > narenas_highwater)
narenas_highwater = narenas_currently_allocated;
// 设置pool集合的信息
arenaobj->freepools = NULL;
/* pool_address <- first pool-aligned address in the arena
nfreepools <- number of whole pools that fit after alignment */
//
arenaobj->pool_address = (block*)arenaobj->address;
// 设置空闲pool的数量
arenaobj->nfreepools = ARENA_SIZE / POOL_SIZE;
assert(POOL_SIZE * arenaobj->nfreepools == ARENA_SIZE);
// 将pool的地址调整为系统page的边界
excess = (uint)(arenaobj->address & POOL_SIZE_MASK);
if (excess != 0) {
--arenaobj->nfreepools;
arenaobj->pool_address += POOL_SIZE - excess;
}
arenaobj->ntotalpools = arenaobj->nfreepools;
return arenaobj;
}
首先检查unused_arena_objects链表中是否还有 “未使用” 的arena,如果还有未使用的arena则直接从链表中取出使用,并且让链表表头指向下一个未使用的arena。接着会申请一块内存,这个内存大小是256KB,这块内存就是pool的集合,然后将这块内存的地址赋值给了arena的address域,此时arena就与pool建立了关系了。需要注意的一点是代码中将freepools设置为NULL,这个域需要在释放一个pool时才会用到。在将这块内存与系统page对其后就将地址赋值给pool_address,此后就由这个域来维护了。
-
2.4 内存池
前面我们介绍了关于arena的底层,现在我们知道所有arena的集合就是小块内存池,实际上Python在进行内存申请的时候,最基本的操作单元并非arena而是pool,为什么呢?因为一个pool总是与一组大小确定的block相对应,pool_header中的szidx变量就是存储block的大小所对应的索引,而arena中并没有这样一个size的概念,因此在小块内存的分配与销毁时都是以pool为单元来进行的。当我们需要分配一个大小的内存时,就会先在内存池中寻找到一块合适的pool并取出一个Block返回。在Python运行时刻一个pool总是处于下面三种状态中的一种:
1、used态:pool中至少有一个Block已经被使用,而且至少还有一个未被使用的Block
2、full态:pool中所遇的Block均被使用,这种状态的pool在arena中但不在arena的freepools链表中
3、empty态:pool中所有Block均未被使用,这种状态下的pool通过pool_header中的nextpool构成一条链表,这个链表的表头就是arena中的freepools
所有处于used态的pool都由一个usedpools数组来维护,当申请内存时,就会从这个数组中寻找一块处于used态的pool从中分配Block。我们来看看这个数组的定义
// obmalloc.c
#define PTA(x) ((poolp )((uint8_t *)&(usedpools[2*(x)]) - 2*sizeof(block *)))
#define PT(x) PTA(x), PTA(x)
static poolp usedpools[2 * ((NB_SMALL_SIZE_CLASSES + 7) / 8) * 8] = {
PT(0), PT(1), PT(2), PT(3), PT(4), PT(5), PT(6), PT(7)
#if NB_SMALL_SIZE_CLASSES > 8
, PT(8), PT(9), PT(10), PT(11), PT(12), PT(13), PT(14), PT(15)
#if NB_SMALL_SIZE_CLASSES > 16
, PT(16), PT(17), PT(18), PT(19), PT(20), PT(21), PT(22), PT(23)
#if NB_SMALL_SIZE_CLASSES > 24
, PT(24), PT(25), PT(26), PT(27), PT(28), PT(29), PT(30), PT(31)
#if NB_SMALL_SIZE_CLASSES > 32
, PT(32), PT(33), PT(34), PT(35), PT(36), PT(37), PT(38), PT(39)
#if NB_SMALL_SIZE_CLASSES > 40
, PT(40), PT(41), PT(42), PT(43), PT(44), PT(45), PT(46), PT(47)
#if NB_SMALL_SIZE_CLASSES > 48
, PT(48), PT(49), PT(50), PT(51), PT(52), PT(53), PT(54), PT(55)
#if NB_SMALL_SIZE_CLASSES > 56
, PT(56), PT(57), PT(58), PT(59), PT(60), PT(61), PT(62), PT(63)
#if NB_SMALL_SIZE_CLASSES > 64
#error "NB_SMALL_SIZE_CLASSES should be less than 64"
#endif /* NB_SMALL_SIZE_CLASSES > 64 */
#endif /* NB_SMALL_SIZE_CLASSES > 56 */
#endif /* NB_SMALL_SIZE_CLASSES > 48 */
#endif /* NB_SMALL_SIZE_CLASSES > 40 */
#endif /* NB_SMALL_SIZE_CLASSES > 32 */
#endif /* NB_SMALL_SIZE_CLASSES > 24 */
#endif /* NB_SMALL_SIZE_CLASSES > 16 */
#endif /* NB_SMALL_SIZE_CLASSES > 8 */
};
考虑一下当申请28字节的情形,前面我们说到,python首先会获得size class index,显然这里是3。那么在usedpools中,寻找第3+3=6个元素,发现usedpools[6]的值是指向usedpools[4]的地址。好晕啊,好吧,现在对照pool_header的定义来看一看usedpools[6] -> nextpool这个指针指向哪里了呢?显然是从usedpools[6] (即usedpools+4)开始向后偏移8个字节(一个ref的大小加上一个freeblock的大小)后的内存,正好是usedpools[6]的地址(即usedpools+6),这是python内部的trick. 想象一下,当我们手中有一个size class为32字节的pool,想要将其放入这个usedpools中时,要怎么做呢?从上面的描述我们知道,只需要进行usedpools[i+i] -> nextpool = pool即可,其中i为size class index,对应于32字节,这个i为3.当下次需要访问size class 为32字节(size class index为3)的pool时,只需要简单地访问usedpools[3+3]就可以得到了。python正是使用这个usedpools快速地从众多的pool中快速地寻找到一个最适合当前内存需求的pool,从中分配一块block。
现在我们来看看pool的初始化。我们知道在Python启动时这个内存池也就是usedpools数组中并不存在可用的内存,当Python开始申请小块内存时,才开始分配,这个时候会先在usedpools数组中查找是否有可用的pool,如果没有,则从usable_arena链表中取出第一个arena,我们来看看源码。
// obmalloc.c
static void *
_PyObject_Alloc(int use_calloc, void *ctx, size_t nelem, size_t elsize)
{
size_t nbytes;
block *bp;
poolp pool;
poolp next;
uint size;
//.....
size = (uint)(nbytes - 1) >> ALIGNMENT_SHIFT;
pool = usedpools[size + size];
if (pool != pool->nextpool) {
// 有可用的pool
//........
}
// 诶有可用的pool则获取链表
// 如果链表为NULL
if (usable_arenas == NULL) {
/* No arena has a free pool: allocate a new arena. */
#ifdef WITH_MEMORY_LIMITS
if (narenas_currently_allocated >= MAX_ARENAS) {
UNLOCK();
goto redirect;
}
#endif // 创建一个新的arena
usable_arenas = new_arena();
if (usable_arenas == NULL) {
UNLOCK();
goto redirect;
}
// 调整链表的指向这里指向NULL
usable_arenas->nextarena =
usable_arenas->prevarena = NULL;
}
assert(usable_arenas->address != 0);
/* Try to get a cached free pool. */
// 从usable_arena链表中的第一个arena中抽取一个可用的pool
pool = usable_arenas->freepools;
if (pool != NULL) {
/* Unlink from cached pools. */
usable_arenas->freepools = pool->nextpool;
// 调整链表中可用pool的数量
--usable_arenas->nfreepools;
// 如果调整为0后则从usable_arenas链表中删除
if (usable_arenas->nfreepools == 0) {
/* Wholly allocated: remove. */
assert(usable_arenas->freepools == NULL);
assert(usable_arenas->nextarena == NULL ||
usable_arenas->nextarena->prevarena ==
usable_arenas);
usable_arenas = usable_arenas->nextarena;
if (usable_arenas != NULL) {
usable_arenas->prevarena = NULL;
assert(usable_arenas->address != 0);
}
}
else {
assert(usable_arenas->freepools != NULL ||
usable_arenas->pool_address <=
(block*)usable_arenas->address +
ARENA_SIZE - POOL_SIZE);
}
// ............
}
在上面可以看到,如果开始时usable_arenas为空,则会通过new_arena()函数申请一个新的arena,并构建usable_arena链表。然后会从这个链表中取出一个arena从中获取一个可用的pool,如果取出则进行一些维护更新的操作,如果可用pool的数量变为0,就将此pool从这个链表中摘除。如果现在有一块可用的pool,需要将这个pool放入到usedpools数组中去,这就是init_pool代码快中的操作:
init_pool:
/* Frontlink to used pools. */
next = usedpools[size + size]; /* == prev */
pool->nextpool = next;
pool->prevpool = next;
next->nextpool = pool;
next->prevpool = pool;
pool->ref.count = 1;
if (pool->szidx == size) {
/* Luckily, this pool last contained blocks
* of the same size class, so its header
* and free list are already initialized.
*/
bp = pool->freeblock;
assert(bp != NULL);
pool->freeblock = *(block **)bp;
UNLOCK();
if (use_calloc)
memset(bp, 0, nbytes);
return (void *)bp;
}
/*
* Initialize the pool header, set up the free list to
* contain just the second block, and return the first
* block.
*/
pool->szidx = size;
size = INDEX2SIZE(size);
bp = (block *)pool + POOL_OVERHEAD;
pool->nextoffset = POOL_OVERHEAD + (size << 1);
pool->maxnextoffset = POOL_SIZE - size;
pool->freeblock = bp + size;
*(block **)(pool->freeblock) = NULL;
UNLOCK();
if (use_calloc)
memset(bp, 0, nbytes);
return (void *)bp;
}
接下来我们来看看block的释放做了什么操作?对于Block的释放实际上就是就将该Block归还给pool,前面我们讲解了pool的三种状态,因此大家可以想象释放一个Block可能会引起pool状态的转换:
1、used态转换为empty态
2、full态转换为used态
假如释放一个Block其状态不发生转换是最简单的,前面解析Block的时候也分析了,仅仅将Block链入到自由链表中取而已。当pool的状态从full态变为used态的时候,也只是将pool重新链入到usedpools数组中去而已,也是比较简单的。最麻烦的就是从used态转换为empty态的时候,这里的代码态多了,就不详细讲述了,有兴趣的自己取看看源码吧。如果后面有时间我尽量补上吧,写太多了,有点写不下去了。