Druid 安装部署(单机版)
1.安装包下载
从https://imply.io/get-started 下载最新版本安装包
2.安装部署
Imply提供了一套完整的部署方式,包括依赖库Druid,图形化的数据展示页面,SQL查询组件等,下面将基于Imply套件进行说明如何部署。
2.1 将imply-2.7.10.tar.gz上传到hadoop102的/opt/software目录下,并解压
[mkluo@hadoop102 software]$ tar -zxvf imply-2.7.10.tar.gz -C /opt/module
2.2 修改/opt/module/imply-2.7.10名称为/opt/module/imply
[mkluo@hadoop102 module]$ mv imply-2.7.10/ imply
2.3 修改配置文件
(1)修改Druid的ZK配置
[mkluo@hadoop102 _common]$ vi /opt/module/imply/conf/druid/_common/common.runtime.properties
修改如下内容
druid.zk.service.host=hadoop102:2181,hadoop103:2181,hadoop104:2181
(2)修改启动命令参数,使其不校验不启动内置ZK
[mkluo@hadoop102 supervise]$
vim /opt/module/imply/conf/supervise/quickstart.conf
修改如下内容
:verify bin/verify-java
#:verify bin/verify-default-ports
#:verify bin/verify-version-check
:kill-timeout 10
#!p10 zk bin/run-zk conf-quickstart
2.4 启动
(1)启动Zookeeper
[mkluo@hadoop102 imply]$ zk.sh start
(2)启动imply
[mkluo@hadoop102 imply]$ bin/supervise -c conf/supervise/quickstart.conf
说明:每启动一个服务均会打印出一条日志。可以通过/opt/module/imply/var/sv/查看服务启动时的日志信息
(3)启动采集Flume和Kafka(主要是为了节省内存开销,同时hadoop102内存调整为8G)
[mkluo@hadoop102 imply]$ f1.sh start
[mkluo@hadoop102 imply]$ kf.sh start
3.Web页面使用
3.0 启动日志生成程序(延时1秒发送一条日志)
[mkluo@hadoop102 server]$ lg.sh 1000 5000
3.1 登录hadoop102:9095查看
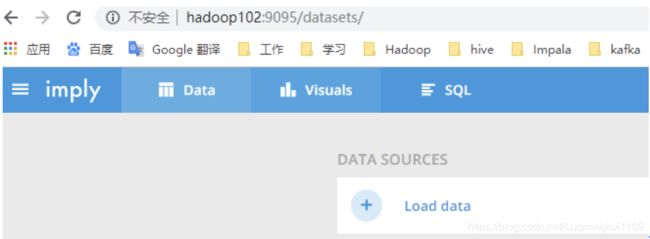
3.2 点击Load data->点击Apache Kafka

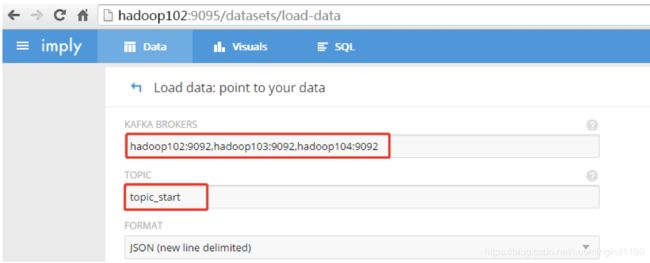
3.3 添加Kafka Broker和要消费的topic
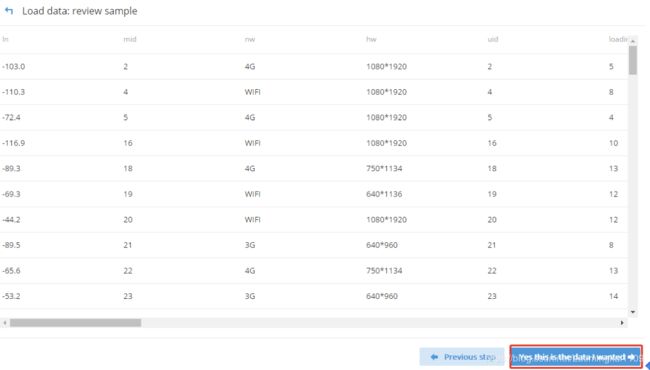
3.4 确认数据样本格式
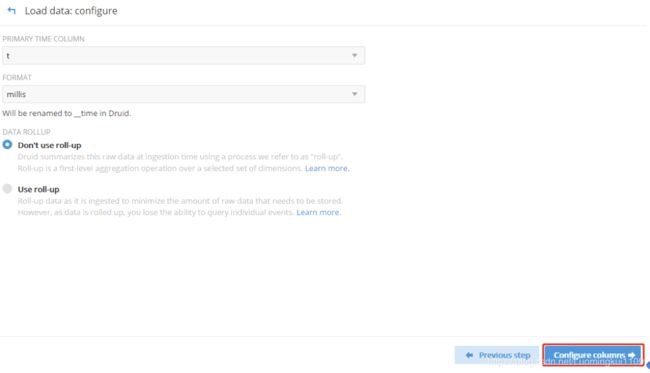
3.5 加载数据,必须要有时间字段
3.6 配置要加载哪些列
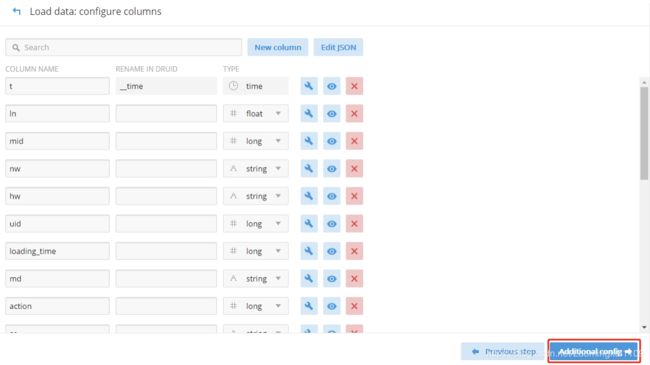
3.7 创建数据库表名
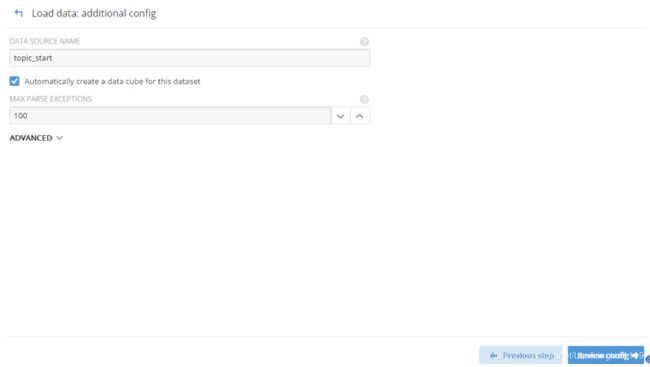
3.8 重新观察一下配置

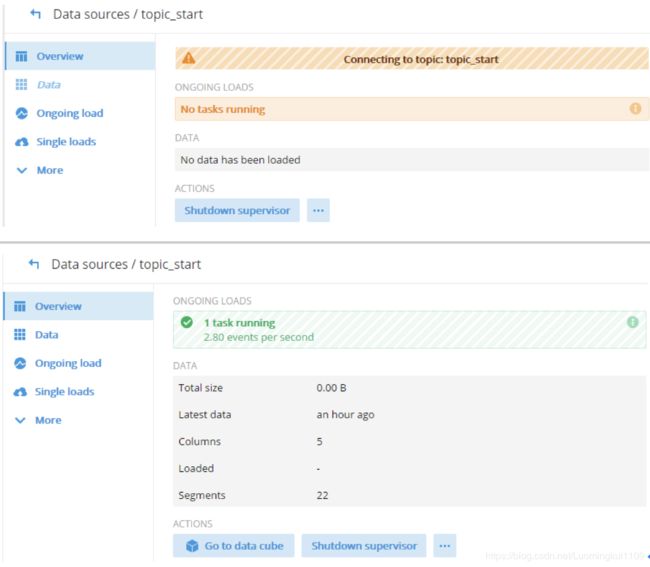
3.9 连接Kafka的topic_start
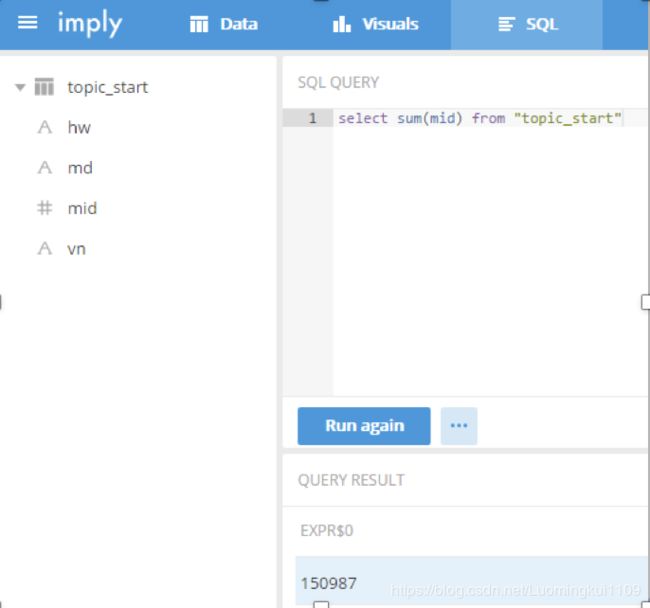
3.10 点击SQL

3.11 查询指标
select sum(mid) from “topic_start"
4.停止服务
按Ctrl + c中断监督进程,如果想中断服务后进行干净的启动,请删除/opt/module/imply/var/目录。