用爬虫获取网易云音乐热门歌手评论数
转载请注明作者和出处:http://blog.csdn.net/Monkey_D_Newdun
运行平台:Windows 10
IDE:Pycharm
Python版本:3.6.0
浏览器:Chrome
- 前言
- 所需模块
- 步骤解析
- 爬取歌曲评论数
- 爬取热门歌手ID
- 爬取歌手热门单曲ID
- 总体代码
- 总结
1.前言
刚开始学Python和爬虫,由于也是网易云音乐的忠实用户,所以就想做一个网易云音乐的爬虫。本来想做一个爬取所有歌曲评论数的爬虫,发现已经有大佬写过了,并且爬取5亿多首歌评论数的工作量也有点大,所以就改做爬取当下各热门歌手每首热单的评论数,再统计一下各位歌手热单的评论总数。由于每位歌手的TOP50单曲已经集中了其绝大多数评论,所以可以近似当作他们所有歌曲的评论总数。(由于这是我第次一写博客,且刚开始学Python和爬虫所以用语上可能有些错误)
2.所需模块
urllib、BeautifulSoup、request、requests、re、json
3.步骤解析
3.1爬取歌曲评论数
进入到一首歌曲的详细页面,可以看到歌曲的ID,比如《等你下课》的ID是531051217,直接尝试使用BeautifulSoup对链接“http://music.163.com/#/song?id=531051217”进行解析,发现找不到评论信息
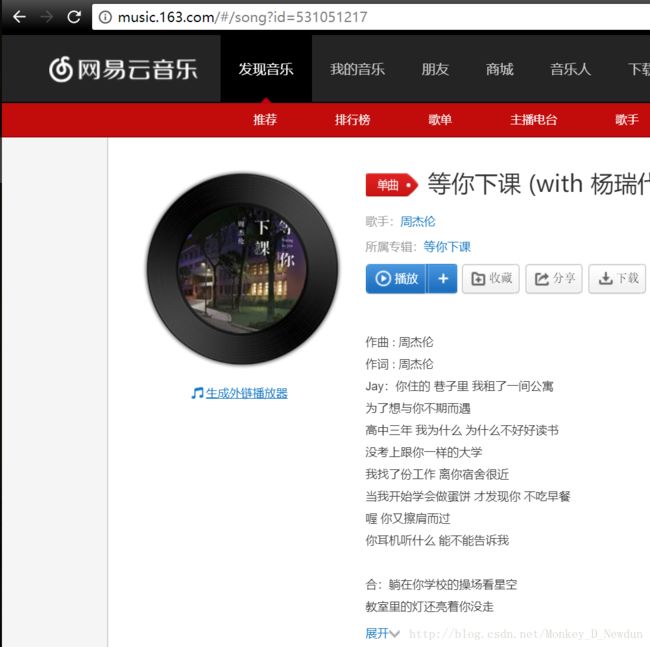
这是因为网易对评论数据采取的是异步传输,所以不能直接通过解析网页内容得到评论数据。打开Chrome开发者工具(Fn+f12)观察,发现奥秘在一个名为“R_SO_4_531051217?csrf_token=”的POST请求中,如下图
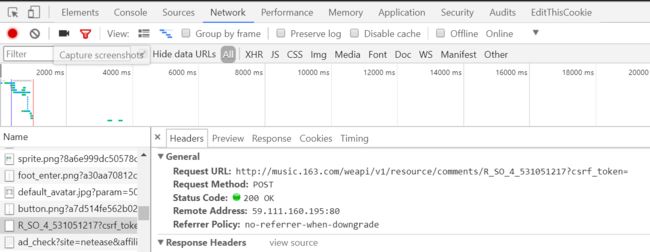
其中R_SO_4_后面的数字531051217为当前歌曲的ID,再观察所上传数据可以看到这里上传了两个参数:params、encSecKey,经过测试发现两个参数对每首歌都是通用的。也就是说将上面链接的歌曲ID替换后传入该参数也能获得数据
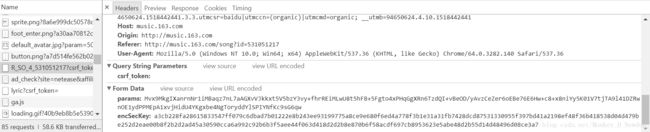
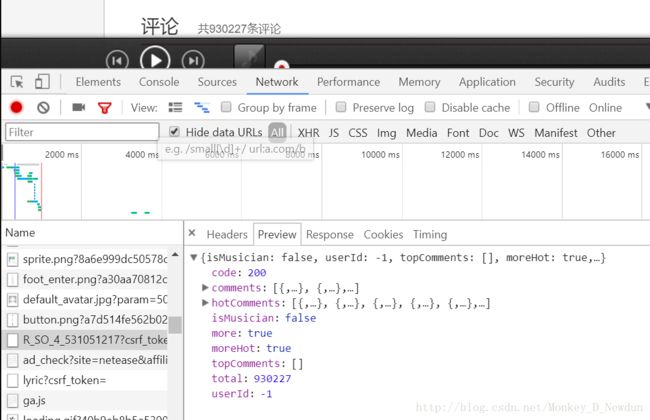
再观察服务器所返回的数据可知评论数保存在“total”中,其中“comments”存的是评论内容,“hotComments”存的是热门评论内容,如果想扒一扒评论内容就可以从这里获取。注意这些是JSON数据,到时候要解析一下
代码部分
#-*-coding:UTF-8-*-
from urllib import request
from bs4 import BeautifulSoup
import requests
import json
import re
from urllib import parse
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36"}
def comment_count(song_id):
url="http://music.163.com/weapi/v1/resource/comments/R_SO_4_"+song_id+"?csrf_token="
data = {
"params": "nHfVBsNbW+WCrz7pAbdaq4uW2+4kADa+gNEfGWK7M5n36mWvsmGXsM2KzVUAeR62mhYlsSvc23I58Rf0dvg1Cglxuf5/l1wVRBCRROpjz9WuYSlWdiwXT/x45iud30RmjbTUsMSQuiehO6Ef3vHSdKWHma9pYm/eeYUF7IQ0hXI3HIz42NgwllBj4cy1XlOH",
"encSecKey": "0587c5b45f3b0771db2b3fe449e7dd9640ab56f679d73a9189096283e776e7a9f749630c6e0fa3f947778f1588b9ec71bd779279006f352e5804036909d5d772c9572c64db575bcce675fcc9055614f1c955abb798eed602cb43945748d8b0a9ecf293cde0ef523e63c3115a1a12b7113be447fba7947090f0d98d2c37cff72a"}
req=requests.post(url=url,headers=headers,data=data)
req.encoding="utf-8"
comment= json.loads(req.text)
return comment["total"]
if __name__=="__main__":
print(comment_count("531051217"))运行结果
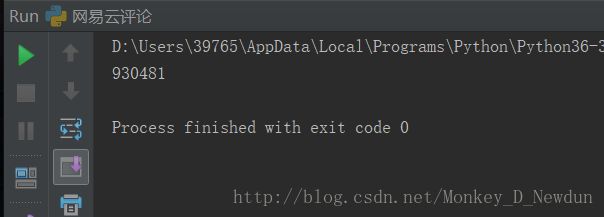
可以看到返回了评论数(这首歌是周杰伦近期超热门单曲《等你下课》,在写博客的这段时间又涨了许多评论,所以与刚刚浏览器看到的评论数有些出入)
3.2爬取热门歌手ID
打开歌手页面,用BeautifulSoup对链接“http://music.163.com/#/discover/artist”进行解析后发现也找不到歌手信息
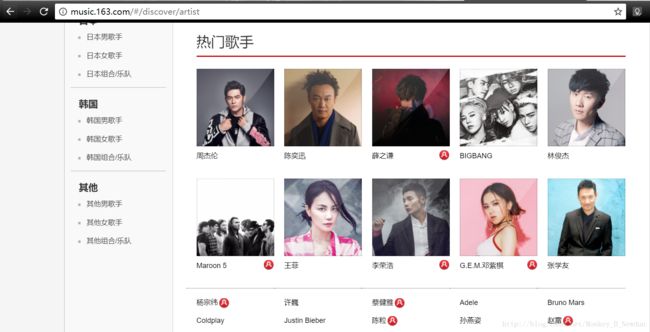
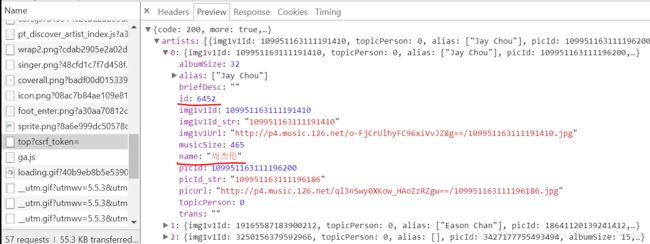
原来歌手信息这里也是采取的异步传输,同样打开Chrome开发者工具观察网页结构,发现奥秘在一个名为“top?csrf_token=”的POST请求中
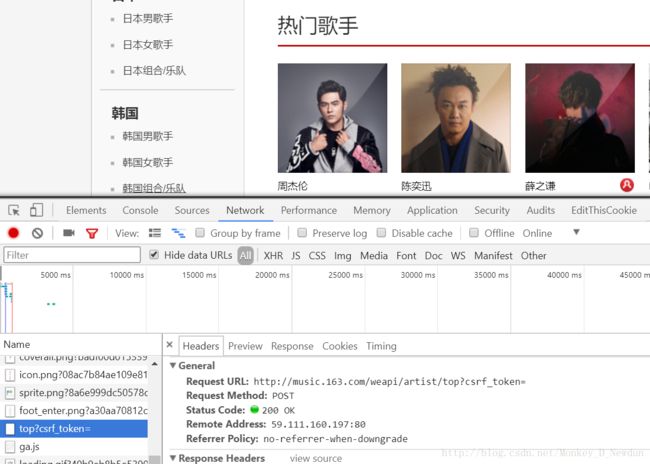
经过测试发现这个POST需要传入完整的Headers,不然得不到反馈,但要把“Accept-Encoding:gzip,deflate”去掉,不然到时候解码会报错
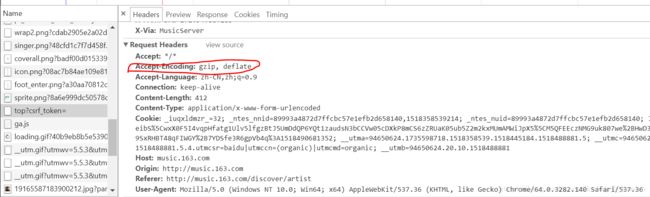
这个POST需要传入的数据参数和之前是一样,也是“params”和“encSecKey”两个,再观察返回的JSON数据就可以找到歌手的ID和姓名等详细信息了。这次换种方法解析这个POST,不用requests.post(),而用Request+urlopen,虽然麻烦点但是两种方法都熟悉一下。

代码部分
#-*-coding:UTF-8-*-
from urllib import request
from bs4 import BeautifulSoup
import requests
import json
import re
from urllib import parse
a_headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36"
,"Referer": "http://music.163.com/discover/artist"
,"Origin": "http://music.163.com"
,"Host":"music.163.com"
,"Cookie":"_iuqxldmzr_=32; _ntes_nnid=9bab5ebb9f8ceee069cb78f0a2981abe,1518338855311; _ntes_nuid=9bab5ebb9f8ceee069cb78f0a2981abe; __utmc=94650624; __utmz=94650624.1518338856.1.1.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; __utma=94650624.44525748.1518338856.1518338856.1518341295.2; JSESSIONID-WYYY=M%2BRH6YHhfp2cVhqPvhYY8trjkopMxYU3p0mKWwFJaAXHw7UlmXOaYo%5CvvrlS8hQo%2FFydkqEhQUD56EmaA8jdh3fbWXdZ%2BuG7JCt8SeWr08UY8agb%5C%2Fs5Maq3jkD8%2BjcZoxcJtjmwNMSzZUwlTAtFNMYqr3xfWEIO6zDMzqZTx0qDrSS7%3A1518344136402; __utmb=94650624.21.10.1518341295"
,"Content-Type":"application/x-www-form-urlencoded"
,"Content-Length":"414"
,"Connection":"keep-alive"
,"Accept-Language":"zh-CN,zh;q=0.9"
,"Accept":"*/*"}
def artist_id():
url="http://music.163.com/weapi/artist/top?csrf_token="
data={"params":"uAE0hN7yRCy+plWTUJw7imQQW+wUSFRuVlFD8UTgXNfJTVLzNyqfnLRqSByCjs40san8rbwMfpasdpJRNit6vKkbQE0F7MZEgRPgSEVfXrHIB/wGiyYQ/VIaZnyTql1m",
"encSecKey":"def9762a8c6ff1f3ae1a7ee23cbc095b3dd6c888f28e974ca00f927fd044a48cfdde49af3138aa99fa7da17fdb97809c7d1abd4ddfc40ab7ef3c0e574e56b2d623c0c23af4d08c629087fd5e1996c961af133140dc81b9fb2322aca668a8079c6cd01a0699fc860b2bb0df47b3887d563f1b18e6585198bb5d9c718a5fa92f04"}
#用Requests和urlopen解析歌手页面的POST
post_data = parse.urlencode(data).encode("utf-8")
req=request.Request(url=url,headers=a_headers)
res=request.urlopen(req,post_data)
html=res.read().decode("utf-8")
#解析所返回的JSON数据
a_data=json.loads(html)
a_list=a_data["artists"]#刚刚观察返回数据可以知道歌手的信息储存在artists键中
id_list=[]#用一个列表储存所有歌手的id和name
for i in range(len(a_list)):
a_dict = {}#用一个字典储存一个歌手的id和name
a_dict["name"]=a_list[i]["name"]
a_dict["id"]=a_list[i]["id"]
id_list.append(a_dict)
return id_list
if __name__=="__main__":
print(artist_id())运行结果

(得到了所有歌手的姓名和ID,并且储存在一个列表中,之后会用到歌手的ID爬取歌曲信息)
3.3爬取歌手热门单曲ID
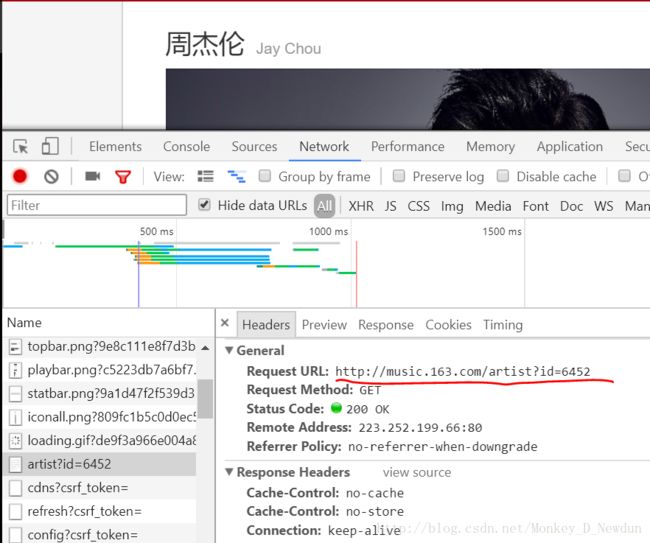
首先观察一个歌手的详情页面(如周杰伦),地址栏的id参数就决定歌手页面,我们就爬取热门50单曲的评论信息。这是尝试对页面“http://music.163.com/#/artist?id=6452”进行解析,发现还是找不到歌曲信息(真是醉了,大公司做项目果然严谨)
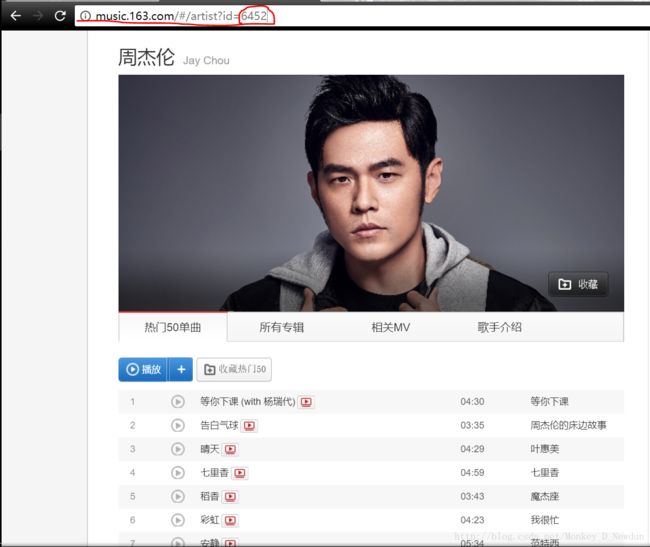
打开Chrome开发者工具找找玄机,发现有些信息是通过“http://music.163.com/artist?id=6452”(这尼玛少了个#号)GET请求发回来的。在返回的数据中还要仔细找一找,可以看到这50首歌曲的信息是储存在class="f-hide"的
- 标签里。每首歌的信息(ID和歌名)在标签中可以找到。所以用BeautifulSoup对“http://music.163.com/artist?id=歌手Id”进行解析,再用find_all("ul",class_="f-hide")就可以找到歌曲信息了

代码部分
#-*-coding:UTF-8-*-
from urllib import request
from bs4 import BeautifulSoup
import requests
import json
import re
from urllib import parse
s_url="http://music.163.com/artist"
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36"}
def song_id(artist_id):
data={"id":artist_id}#将歌手ID作为params参数传入requests.get()方法
req=requests.get(url=s_url,headers=headers,params=data)
req.encoding="utf-8"
soup=BeautifulSoup(req.text,"lxml")#对返回的数据进行解析
song_list=soup.find_all("ul",class_="f-hide")#找到class="f-hide"的标签
song_soup=BeautifulSoup(str(song_list),"lxml")#将......
再解析一次,以便使用find_all()方法把所有标签取出来
song_list=song_soup.find_all("a")
id_list=[]#存歌曲ID
name_list=[]#存歌名
for each in song_list:
s_id=each.get("href")#歌曲ID在标签href属性中
s_name=each.string
s=re.findall(r"\d+",s_id)#用正则找到href中的ID
id_list.append(s[0])#由于re.findall()返回的是一个列表,所以用下标将ID取出
name_list.append(s_name)
return id_list,name_list
if __name__=="__main__":
song_id_list,name_list=song_id(6452)
print(song_id_list)
print(name_list)
运行结果

(这样就找到了周杰伦热门50单曲的ID和歌名,将这些ID传入上面的comment_count()函数就可以得到每首歌曲的评论数了)
3.4总体代码
这一步主要就是将上面三个部分的代码做一个有机整合就可以了,其实就是用两个循环
#-*-coding:UTF-8-*-
from urllib import request
from bs4 import BeautifulSoup
import requests
import json
import re
from urllib import parse
a_headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36"
,"Referer": "http://music.163.com/discover/artist"
,"Origin": "http://music.163.com"
,"Host":"music.163.com"
,"Cookie":"_iuqxldmzr_=32; _ntes_nnid=9bab5ebb9f8ceee069cb78f0a2981abe,1518338855311; _ntes_nuid=9bab5ebb9f8ceee069cb78f0a2981abe; __utmc=94650624; __utmz=94650624.1518338856.1.1.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; __utma=94650624.44525748.1518338856.1518338856.1518341295.2; JSESSIONID-WYYY=M%2BRH6YHhfp2cVhqPvhYY8trjkopMxYU3p0mKWwFJaAXHw7UlmXOaYo%5CvvrlS8hQo%2FFydkqEhQUD56EmaA8jdh3fbWXdZ%2BuG7JCt8SeWr08UY8agb%5C%2Fs5Maq3jkD8%2BjcZoxcJtjmwNMSzZUwlTAtFNMYqr3xfWEIO6zDMzqZTx0qDrSS7%3A1518344136402; __utmb=94650624.21.10.1518341295"
,"Content-Type":"application/x-www-form-urlencoded"
,"Content-Length":"414"
,"Connection":"keep-alive"
,"Accept-Language":"zh-CN,zh;q=0.9"
,"Accept":"*/*"}
s_url="http://music.163.com/artist"
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36"}
def artist_id():
url="http://music.163.com/weapi/artist/top?csrf_token="
data={"params":"uAE0hN7yRCy+plWTUJw7imQQW+wUSFRuVlFD8UTgXNfJTVLzNyqfnLRqSByCjs40san8rbwMfpasdpJRNit6vKkbQE0F7MZEgRPgSEVfXrHIB/wGiyYQ/VIaZnyTql1m",
"encSecKey":"def9762a8c6ff1f3ae1a7ee23cbc095b3dd6c888f28e974ca00f927fd044a48cfdde49af3138aa99fa7da17fdb97809c7d1abd4ddfc40ab7ef3c0e574e56b2d623c0c23af4d08c629087fd5e1996c961af133140dc81b9fb2322aca668a8079c6cd01a0699fc860b2bb0df47b3887d563f1b18e6585198bb5d9c718a5fa92f04"}
#用Requests和urlopen解析歌手页面的POST
post_data = parse.urlencode(data).encode("utf-8")
req=request.Request(url=url,headers=a_headers)
res=request.urlopen(req,post_data)
html=res.read().decode("utf-8")
#解析所返回的JSON数据
a_data=json.loads(html)
a_list=a_data["artists"]#所有歌手的信息储存在artists键中
id_list=[]#用一个列表储存所有歌手的id和name
for i in range(len(a_list)):
a_dict = {}#用一个字典储存一个歌手的id和name
a_dict["name"]=a_list[i]["name"]
a_dict["id"]=a_list[i]["id"]
id_list.append(a_dict)
return id_list
def song_id(artist_id):
data={"id":artist_id}#将歌手ID作为params参数传入requests.get()方法
req=requests.get(url=s_url,headers=headers,params=data)
req.encoding="utf-8"
soup=BeautifulSoup(req.text,"lxml")#对返回的数据进行解析
song_list=soup.find_all("ul",class_="f-hide")#找到class="f-hide"的标签
song_soup=BeautifulSoup(str(song_list),"lxml")#将......
再解析一次,以便使用find_all()方法把所有标签取出来
song_list=song_soup.find_all("a")
id_list=[]#存歌曲ID
name_list=[]#存歌名
for each in song_list:
s_id=each.get("href")#歌曲ID在标签href属性中
s_name=each.string
s=re.findall(r"\d+",s_id)#用正则找到href中的ID
id_list.append(s[0])#由于re.findall()返回的是一个列表,所以用下标将ID取出
name_list.append(s_name)
return id_list,name_list
def comment_count(song_id):
url="http://music.163.com/weapi/v1/resource/comments/R_SO_4_"+song_id+"?csrf_token="
data = {
"params": "nHfVBsNbW+WCrz7pAbdaq4uW2+4kADa+gNEfGWK7M5n36mWvsmGXsM2KzVUAeR62mhYlsSvc23I58Rf0dvg1Cglxuf5/l1wVRBCRROpjz9WuYSlWdiwXT/x45iud30RmjbTUsMSQuiehO6Ef3vHSdKWHma9pYm/eeYUF7IQ0hXI3HIz42NgwllBj4cy1XlOH",
"encSecKey": "0587c5b45f3b0771db2b3fe449e7dd9640ab56f679d73a9189096283e776e7a9f749630c6e0fa3f947778f1588b9ec71bd779279006f352e5804036909d5d772c9572c64db575bcce675fcc9055614f1c955abb798eed602cb43945748d8b0a9ecf293cde0ef523e63c3115a1a12b7113be447fba7947090f0d98d2c37cff72a"}
req=requests.post(url=url,headers=headers,data=data)
req.encoding="utf-8"
comment= json.loads(req.text)
return comment["total"]
if __name__=="__main__":
f=open("网易云评论.txt","w",encoding="utf-8")
id_list=artist_id()
for artist in id_list:
total=0
f.write("\n\n"+artist["name"]+"热门歌曲以及评论数:")
song_id_list,name_list=song_id(artist["id"])
for i in range(len(song_id_list)):
if(name_list[i]!=None):#!!!这个地方一定要注意,下面会做说明
total+=comment_count(song_id_list[i])
f.write(name_list[i]+":"+str(comment_count(song_id_list[i]))+"条")
f.write("总计:"+str(total)+"条")
print(artist["name"]+"网易云音乐热门歌曲总评论数:"+str(total)+"条")
print("抓取完毕!")
解释一下这个判断条件
if(name_list[i]!=None):
从这位歌手说起
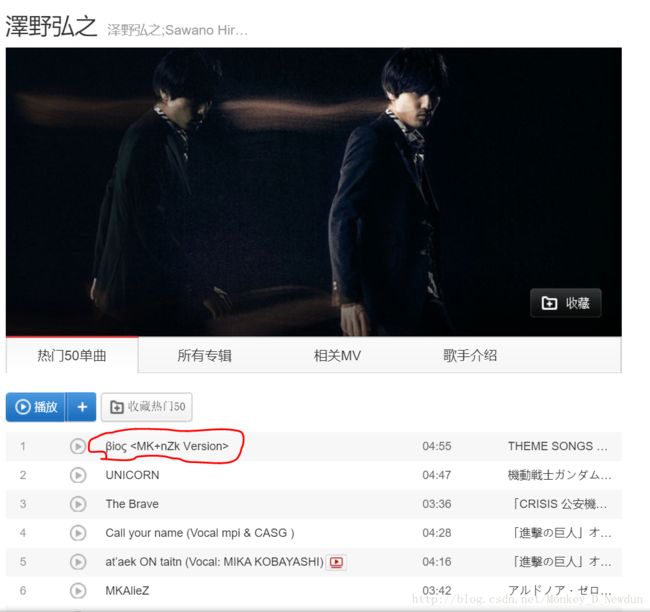
相信你看到这歌名会有点懵逼,没错就连Python解释器也认不到它,直接给当作None处理(没想到吧,手动滑稽)
运行结果
热门歌手热门单曲TOP50总评论数,如下
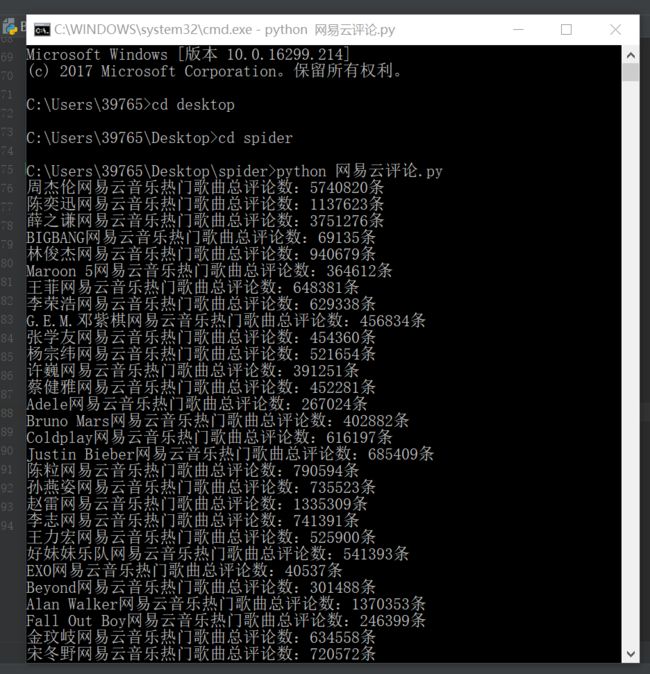
(这是网页的默认歌手顺序,有兴趣的小伙伴可以自己写个排序函数排下顺序,周杰伦这570多万条评论着实有点吓人,不愧为当今华语乐坛扛把子)
每首歌的评论数也存到了文件中,如下
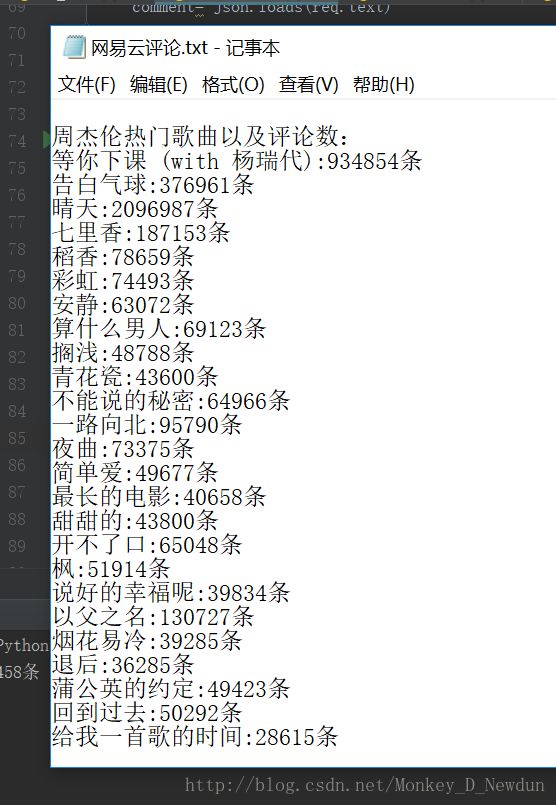
4总结
感觉爬取信息的关键就是要先分析好人家的网页结构~~~不然会走弯路,这个网易云音乐的爬虫也让自己学到了不少东西。想把这个过程记录下来,免得自己忘了,所以就写了这篇博客处女作。(毕竟处女作可能有很多错误之处,还请多多包涵)