七周成为数据分析师--python篇④
python 篇
讲讲python吧,主要分为数据科学环境、基础、numpy和pandas、数据可视化、数据分析案例、数据分析平台这几块。
1. 数据环境
数据环境anaconda(狂蟒之灾),可以直接百度清华镜像下载。接着构建运行环境 jupyter notebook,最后写下第一行代码print(‘hello world’),告诉大家我来啦!
2.基础小知识
操作方面:
shift+tab 常常用来看函数的内涵步骤
shift+回车 执行完跳至下一单元格
ctrl+回车 单纯执行本单元格
python 很注重缩进,特别是if elif这样的嵌套时,
左缩进 Ctrl + [
右缩进 Ctrl + ]
加注释 Alt + 3
去注释 Alt + 4
知识点:
转义字符

type()查询数据类型
例如type(1)=int; type(1.1)=float;type(‘a’)=str;拓展至其他float(1)=1.1;int(1.1)=1;str(1)=‘1’
讲讲余数、整除
3//2=1 7//2=3 (表示去余数,取商)
3/2=1.5 7/2=3.5(正常的除法)
3%2=1 7%2=1 4%2=0 (表示取余数,常常用来判定是否整除)
讲到这里要讲一点整除这样的逻辑判断,在SQL和PYTHON中都是用‘==’,两个等于号。等于在语言里面的概念其实是赋值。
字符串
在这里,‘’和“”其实表达的意思都差不多,也可以用来表示字符串,但就是用法不一样,比如存在嵌套的情况,“hello ‘xcw’”或者‘hello “xcw”’,如果里面既有双引号又有单引号,或是其他一些特殊符号就用’’'来包裹。
一些逻辑运算
‘1’+‘1’会报错;int(‘1’)+1不会报错
True、False 表述时一定要大写首字哦,称为布尔的一种数据类型,type(True)=bool,True表示1,False表示0
比如True +1=2,可以运算。False+1=1,可以运算。
(1<2)+1=2,可以运算
1<2+1=1,在运算中,先算加减乘除,再判断逻辑条件。
None和‘ ’
None表示的是缺失而不是0,常常sql 中left join 出来的会有很多none,none+1是无法运算的,把他想象成一个单元格的缺失。而‘’
表示的是值为空,也不是为0。 两者的区别可以认为‘’表示的是有这样一个单元格,但是还没赋上值,而none表示的是连这个单元格都还没有,直接缺失了。
变量
比如 a是一个变量,可以是字符串也可以重新赋值
a=1,b=2
a+b=3
a=2
a+b=4
数据结构
python中的数据结构有三个,
列表[]类似数组
字典{} 也称键值对例a={‘name’:‘xcw’}
元组()
列表有序,查询快,增删慢,所占空间小(类似数组),允许赋值修改
字典无序,查询慢,增删快,所占空间大(类似链表),不论多少查询速度都是相等的,允许赋值修改
元组不可替换修改,但可以索引。
1、列表
num=[1,2,3]
len(num)=3
len([1,2,3,4])=4
列表有点类似我们大学学的线性代数,矩阵。
2、索引,有时候也叫切片。
可以索引位置、关键值key。
比如num[0],表示取num列表的第一个位置。
涉及到两个知识点,第一在python中,只要是索引都是用[],
第二,英文中习惯把0当做顺序第一位,比如num[2]表示索引第3个位置,num[-1]表示索引最后一个位置。
索引一个段落num[0:1] 其中num=[1,2,3]
只反馈[1] 原因是 系统默认左闭右开,比如想取前两个数,我们要用num[0:2],当然默认num[ :2]也行,系统会自动索引到第2个位置;num[0:]表示从第一个位置,索引到最后一个位置
索引的是列,向一列切片。合并是按行,例如num=[[1,2],[3,4]] num[0]+num[1]=[1,2,3,4],比如索引后直接相加,表示的是合并,并不是值相加
3、增、删、替换
注意:一般调用函数都是xx.函数加()
增:num.insert(,),第一个_表示某某位置前,第二个表示对象
比如:

num.append(),表示在末尾加一个数,等同于num=num+[7,8]都只是合并的,如果要看相加,只有一种用numpy中转化为数组,另一种就是用for循环,具体可以看另一篇博文

[如图是在第4行加了7,8
删除num.pop(位置)
空白的话是默认删去最后一个
替换直接用等号赋值,num[0]=1;num[0]=2;num,最后num输出2
注意元组不能修改,比如a=(1,2),再使a=(3,4),此时是会报错的
但元组的索引还是[],a=[1,2],a[0]=1是ok的
索引info[1][0] 举例info=[[‘1’,‘2’,‘3’],[‘4’,‘5’,‘6’]] 输出第二行第一列,输出‘4’,这时4是字符串
快速生成几列 row=[0]3=[0,0,0] row4=[[0,0,0],[0,0,0],[0,0,0],[0,0,0]] 4行3列
4、set(列表) 集合化
配合list去重,例如list(set([1,2,2,3,1])) 推出[1,2,3,1]
集合不能加减乘除,但可以求交集、并集、补集
例如:set(a)-set(b),差集,表示在a中排除b的值
- 字典 {}
键值对 ,‘key’: ‘value’
举例a={‘name’:‘qinlu’,‘sex’:‘female’,‘age’=‘18’}
一般前面会加’id’:1
索引还是用a[‘id’]=1,a[‘name’] =qiulu,但比如索引a[1],这时候时会报错的,因为字典本身没有什么顺序的概念。
讲讲区别只有字典可以直接索引字符串,前面元组和列表不能索引字符串,只能索引位置。
例a.keys(),提取字典的关键字,a.values(),提取字典的值
讲讲字典和列表的区别,字典无论多少,他的查找速度是相同的,性能占比比较小,因为他无序存放,但他占的空间大。
而列表占得空间小,但由于有序存放,他的后期效率会变慢,性能占比大,查找速度会逐渐变慢。
字典允许修改,直接给key重新赋值,a[‘id’]=2。
- 增:a[键]=值,直接在后面加上键值对的赋值,
比如a={‘a’:‘b’,‘c’:‘1’},a[‘5’]=‘d’,a={‘a’:‘b’,‘c’:‘1’,‘5’:d"} - **删 ** a.pop(‘键’),直接把键删了,对应的值也会删了
3、提取的是字典中的 键 、值、整个字典
a={‘name’:‘1’,‘b’:‘2’}
a.keys()=dict_keys([‘name’,‘b’])再加一个list(),直接列表化
list(a.value())=[‘1’,‘2’]
list(a.items())=[(‘name’,‘1’),(‘b’,‘2’)] []里面是元组的形式
4、讲讲取字典的数 a.get()
a.get(‘键’,‘none’),表示取到就是keys对应的值,没取到返回none
5、讲讲字典中的更新值a.setdefault()
比如a.setdefault(键,值)
如果在a中查到相应的键,就会替换更新,没查到相应的键,就会自动在后面加上新的键值对
6、讲讲控制流
a=10
if a>10:
print(‘more than10’)
if a=10:
print…
else:
print(’’)
讲讲elif 和不加elif 区别
a = True
b=True
if a:
print(“代码块1”)
if b:
print(“代码块2”)
代码块1和代码块2都会被输出,而再想一下如果是使用elif:
a = True
b=True
if a:
print(“代码块1”)
elif b:
print(“代码块2”)
只会输出代码块1,而不会输出代码块2了
elif翻译过来大概是 ”否则的话如果…‘’
就是说一个是同时并列判断,另一个有点互斥判断,elif前如果 碰到true的逻辑,就会跳出判断,而if碰到true,还是会往下继续判断下一个if是不是满足条件。
最后再来讲讲循环语句(while,for)
1、while是一直循环+条件判断,直到逻辑判断为false,同时记得要加逻辑判断条件,不然会死循环。
break 直接断开,但是要注意缩进
2、for i in range():,for 比较不容易死循环
print(i)
range(3,5),左闭右开,不含5
a=0
for i in range(1,11):
a=a+i #注意缩进,不然执行不了
print(a)
列表中的循环
a =[‘a’,‘b’,‘c’]
for i in a: #记得加:哦,帅哥
print(i)
a b c
字典中的循环
dict={‘a’:1,‘b’:3,‘c’:5}
for k in dict.keys():
print (k)
a b c
同时for 支持多循环
for v,m in dist.items()
print(k)
print(m)
循环进阶
1、输出1-100的数字
list=[]
for i in range(1,101):
list.append(i) #记得缩进!!!!!!!!!!
print(list)
2、取字典中的值进行平方
dict={‘a’:1,‘b’:2,‘c’:3}
[v**2 for v in dict.values()] #记得加上【】
[1,4,9]
3、输出1-10偶数
[i for i in range(1,11)if i%2==0]
逻辑放后面,加[]
小运用的例子:
1、def() 定义函数
拿python构建四则运算器
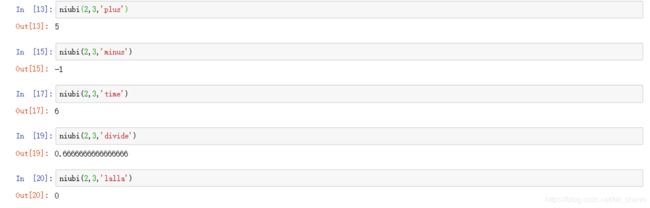
def niubi(x,y,z):
if z=='plus':
return x+y
elif z=='minus':
return x-y
elif z=='time':
return x*y
elif z=='divide':
return x/y
else:
return 0
定义一个函数名为niubi
进行多次判断,注意elif此时不是嵌套,是并列的逻辑判断
2、用python充当excel
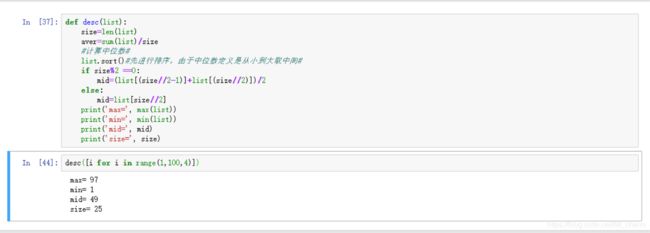
def desc(list):
size=len(list)
aver=sum(list)/size
#计算中位数#
list.sort()#先进行排序,由于中位数定义是从小到大取中间#
if size%2 ==0:
mid=(list[(size//2-1)]+list[(size//2)])/2
else:
mid=list[size//2]
print('max=', max(list))
print('min=', min(list))
print('mid=', mid)
print('size=', size)
list是一个列表也就是数组,看成线性代数的[]。三大数据结构之一,其他两个是字典{},和元组()。
size//2表示去余数的值,比如10//2=5,10/2=5,10%2=0(这个是取余数,常用于判断奇偶)
这样,我们输入的值也要是数组的形式,a=[1,2,3,4,5]类似这样
由于实际之中,本身的值不一定会从小到大排列,因此要加一个list.sort()
最后输入相应的数组值就好啦!
以生成1至100的数值,间隔4为例
desc([i for i in range(1,100,4)])
3、+号和合并
在python项目中,很多时候需要对列表的各项进行加减操作,今天我们一起来学习一下吧!
当需要对列表进行相加时,一般意义上的【+】在python中却表示连接的意思。这里提供两种方法供大家参考一下;第一种是利用【for】循环,第二种是利用numpy函数;首先构建两个列表a和b;

需要注意的是,相加两个列表的长度需要相等,所以在计算之前,可以使用【len】函数判断是否相等,其实若是很简单可以一眼看出的列表,这一步可以省去;![]()
定义一个空列表【c】用来当作新算出的列表;
c[]
接下来就可以使用一个【for】循环就能解决了,利用长度依次取出列表中的值,逐项相加,打印出【c】;
a=[1,2,3,4,5]
b=[2,3,4,5,6]
if len(a)==len(b):
c=[]
for i in range(len(a)):
c1=a[i]+b[i]
c.append(c1)
print( C)

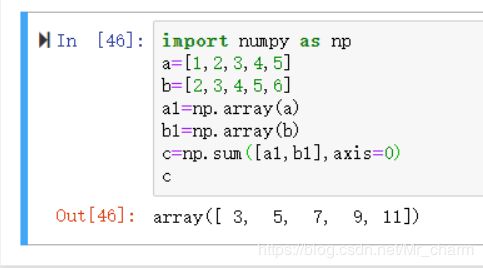
第二种就是利用numpy包来执行,首先导入numpy包;利用【array】函数将列表转换成数组形式,只有这种形式才能实现相加;

再利用numpy包的求和函数【sum】进行逐项相加,【axis】表示每一行中对应列数相加,可看出结果如下,对于大数据集来说,比之第一种要方便很多呢;
import numpy as np
a=[1,2,3,4,5]
b=[2,3,4,5,6]
a1=np.array(a)
b1=np.array(b)
print(a1)
print(b1)
c=np.sum([a1,b1],axis=0)
print©
axis=1
