Spark Streaming接收kafka数据,输出到HBase
需求
Kafka + SparkStreaming + SparkSQL + HBase
输出TOP5的排名结果
排名作为Rowkey,word和count作为Column
实现
创建kafka生产者模拟随机生产数据
object producer {
def main(args: Array[String]): Unit = {
val topic ="words"
val brokers ="master:9092,slave1:9092,slave2:9092"
val prop=new Properties()
prop.put("metadata.broker.list",brokers)
prop.put("serializer.class", "kafka.serializer.StringEncoder")
val kafkaConfig=new ProducerConfig(prop)
val producer=new Producer[String,String](kafkaConfig)
val content:Array[String]=new Array[String](5)
content(0)="kafka kafka produce"
content(1)="kafka produce message"
content(2)="hello world hello"
content(3)="wordcount topK topK"
content(4)="hbase spark kafka"
while (true){
val i=(math.random*5).toInt
producer.send(new KeyedMessage[String,String](topic,content(i)))
println(content(i))
Thread.sleep(200)
}
}
}创建spark streaming
val conf = new SparkConf().setMaster("local[2]").setAppName("Networkcount")
val sc = new SparkContext(conf)
val ssc = new StreamingContext(sc, Seconds(1))配置kafka,通过KafkaUtils.createDirectStream读取kafka传递过来的数据
val topic = Set("words")
val brokers = "master:9092,slave1:9092,slave2:9092"
val kafkaParams = Map[String, String]("metadata.broker.list" -> brokers, "serializer.class" -> "kafka.serializer.StringEncoder")
val kafkaStream = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](ssc, kafkaParams, topic)使用sparksql进行wordcount与topN处理,写入hbase
var rank = 0; //用来记录当前数据序号
val sqlcontext = new SQLContext(sc)
import sqlcontext.implicits._
val lines = kafkaStream.window(Seconds(10), Seconds(3)).flatMap(line => {
Some(line._2.toString)
}).foreachRDD({ rdd: RDD[String] =>
val df = rdd.flatMap(_.split(" ")).toDF.withColumnRenamed("_1", "word")
val table = df.registerTempTable("words")
val ans = sqlcontext.sql("select word, count(*) as total from words group by word order by count(*) desc").limit(5).map(x => {
rank += 1
(rank, x.getString(0), x.getLong(1))
})
rank = 0数据写入hbase的方式一(批量写入)
ans.map(x => {
val put = new Put(Bytes.toBytes(x._1.toString))
put.addColumn(Bytes.toBytes("cf"), Bytes.toBytes("word"), Bytes.toBytes(x._2.toString))
put.addColumn(Bytes.toBytes("cf"), Bytes.toBytes("count"), Bytes.toBytes(x._3.toString))
put
}).foreachPartition(x => {
val conn = ConnectionFactory.createConnection(HBaseConfiguration.create)
val table = conn.getTable(TableName.valueOf("window"))
//两种获得table的方式
// var jobConf = new JobConf(HBaseConfiguration.create)
// val table = new HTable(jobConf, TableName.valueOf("window"))
import scala.collection.JavaConversions._
table.put(seqAsJavaList(x.toSeq))
})数据写入hbase的方式一(单条写入)
ans.foreachPartition(partitionRecords=>{
val tablename = "window"
val hbaseconf = HBaseConfiguration.create()
val conn = ConnectionFactory.createConnection(hbaseconf)
val tableName = TableName.valueOf(tablename)
val table = conn.getTable(tableName)
partitionRecords.foreach(x => {
val put = new Put(Bytes.toBytes(x._1.toString))
put.addColumn(Bytes.toBytes("cf"), Bytes.toBytes("word"), Bytes.toBytes(x._2.toString))
put.addColumn(Bytes.toBytes("cf"), Bytes.toBytes("count"), Bytes.toBytes(x._3.toString))
table.put(put)
})
table.close()
})
})
使用saveAsHadoopDataset
saveAsHadoopFile是将RDD存储在HDFS上的文件中,支持老版本Hadoop API
saveAsHadoopDataset用于将RDD保存到除了HDFS的其他存储中,比如HBase
var jobConf = new JobConf(HBaseConfiguration.create)
jobConf.set(TableOutputFormat.OUTPUT_TABLE, "window")
jobConf.setOutputFormat(classOf[TableOutputFormat])//不加这句会报错Undefined job output-path
//在JobConf中,通常需要关注或者设置五个参数
文件的保存路径、key值的class类型、value值的class类型、RDD的输出格式(OutputFormat)、以及压缩相关的参数
ans.map(x => {
val put = new Put(Bytes.toBytes(x._1.toString))
put.addColumn(Bytes.toBytes("cf"), Bytes.toBytes("word"), Bytes.toBytes(x._2.toString))
put.addColumn(Bytes.toBytes("cf"), Bytes.toBytes("count"), Bytes.toBytes(x._3.toString))
(new ImmutableBytesWritable , put)
}).saveAsHadoopDataset(jobConf)
使用新版API:saveAsNewAPIHadoopDataset
sc.hadoopConfiguration.set(TableOutputFormat.OUTPUT_TABLE,"lxw1234")
var job = new Job(sc.hadoopConfiguration)
job.setOutputKeyClass(classOf[ImmutableBytesWritable])
job.setOutputValueClass(classOf[Result])
job.setOutputFormatClass(classOf[TableOutputFormat[ImmutableBytesWritable]])//这句会报错,不知原因
ans.map(x => {
val put = new Put(Bytes.toBytes(x._1.toString))
put.addColumn(Bytes.toBytes("cf"), Bytes.toBytes("word"), Bytes.toBytes(x._2.toString))
put.addColumn(Bytes.toBytes("cf"), Bytes.toBytes("count"), Bytes.toBytes(x._3.toString))
(new ImmutableBytesWritable , put)
}).saveAsNewAPIHadoopDataset(job.getConfiguration)//运行会报空指针启动spark streaming
ssc.start()
ssc.awaitTermination() //等待处理停止,stop()手动停止运行
producer生产数据
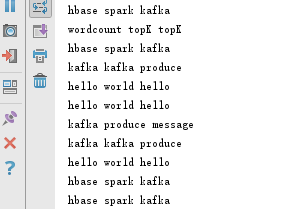
hbase实时更新数据
批量写入,时间戳一致
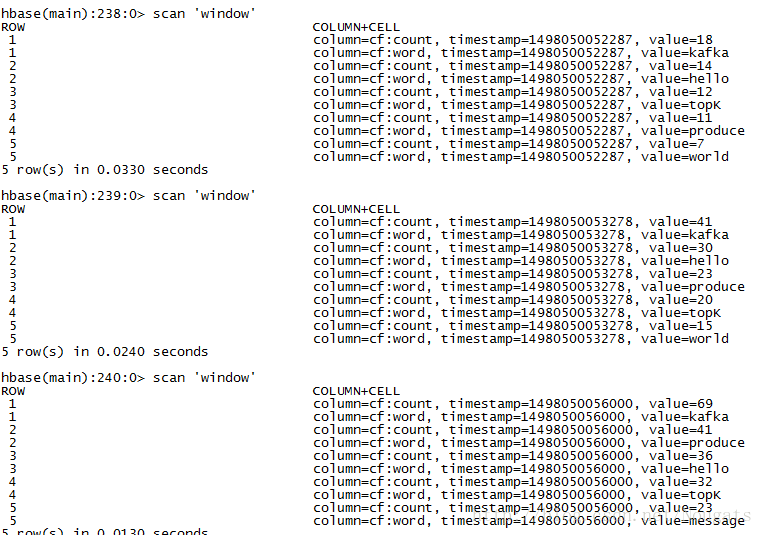
单条写入,时间戳有差异
