爬取抖音视频(二)
上个帖子已经抓了用户ID,下面我们来抓:
- 评论数
- 点赞数
- 视频链接
- 封面
由于评论和点赞数是实时跟新的,所以是异步加载的
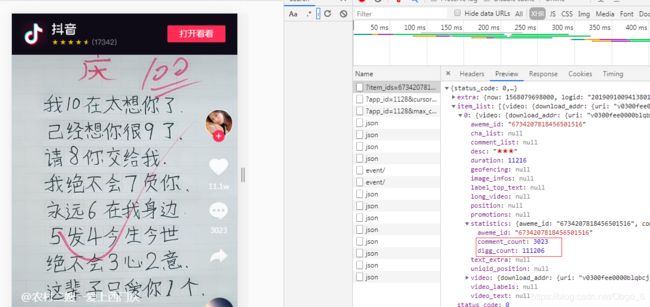

一、解析API接口
下面是链接
https://www.iesdouyin.com/web/api/v2/aweme/iteminfo/?item_ids=6734207818456501516&dytk=2911ae03c92dc0895d0cb6c663d0862cbf4b0633c6c562abaf962f4fd9ba1b36
这个是api接口
https://www.iesdouyin.com/web/api/v2/aweme/iteminfo/?
下面分析出来的参数

二、查找参数
item_ids:是视频的id
dytk:?

dytk参数是个固定值,可以在源码里找到
三、代码实现
下面是具体代码实现:
import requests,re
def get_url(url, params=None, headers=None, types=None):
r = requests.get(url, headers=headers, params=params)
if types:
return r.json()
else:
return r.text
def parent_dytk(html_text):
parent_rid = re.findall('parent_rid: "(.*?)",', html_text)[0]
dytk = re.findall('dytk: "(.*?)"', html_text)[0]
itemId = re.findall('itemId: "(.*?)"', html_text)[0]
return parent_rid, dytk, itemId
def main(url):
data2 = {
'item_ids': '6734207818456501516',
'dytk': '2911ae03c92dc0895d0cb6c663d0862cbf4b0633c6c562abaf962f4fd9ba1b36'
}
headers = {
'Referer': 'https://www.iesdouyin.com/share/video/6734207818456501516/?region=CN&mid=6509675750206606093&u_code=0&titleType=title&utm_source=copy_link&utm_campaign=client_share&utm_medium=android&app=aweme',
'Sec-Fetch-Mode': 'cors',
'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Mobile Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
}
urls = 'https://www.iesdouyin.com/web/api/v2/aweme/iteminfo/'
item = {}
re_html = get_url(url, headers=headers)
parent_rid, dytk, itemId = parent_dytk(re_html)
data2['dytk'] = dytk
data2['item_ids'] = itemId
# print(data2)
personage_html = get_url(urls, params=data2, types='json', headers=headers)
# print(personage_html)
personage_html = personage_html['item_list'][0]
# 点赞数
item['digg_count'] = personage_html['statistics']['digg_count']
# 评论数
item['comment_count'] = personage_html['statistics']['comment_count']
# 标题
item['desc'] = personage_html['desc']
# 音乐
# 封面
item['cover'] = personage_html['video']['cover']['url_list']
# 视频下载链接
item['download_addr'] = personage_html['video']['download_addr']['url_list']
print(item)
if __name__ == '__main__':
url ='https://www.iesdouyin.com/share/video/6734207818456501516/?region=CN&mid=6509675750206606093'
main(url)
下面是运行结果:
{'digg_count': 111218, 'comment_count': 3028, 'desc': '☀☀☀', 'cover': ['https://p3-dy.byteimg.com/img/tos-cn-p-0015/6e69ffe45d684822aaf79d8f6d3d7b0d~tplv-dy-cs:300:400.jpeg', 'https://p9-dy.byteimg.com/img/tos-cn-p-0015/6e69ffe45d684822aaf79d8f6d3d7b0d~tplv-dy-cs:300:400.jpeg', 'https://p1-dy.byteimg.com/img/tos-cn-p-0015/6e69ffe45d684822aaf79d8f6d3d7b0d~tplv-dy-cs:300:400.jpeg'], 'download_addr': ['https://aweme.snssdk.com/aweme/v1/play/?video_id=v0300fee0000blqbcjjck9jvpmusgceg&line=0&ratio=540p&watermark=1&media_type=4&vr_type=0&improve_bitrate=0&logo_name=aweme_self', 'https://api.amemv.com/aweme/v1/play/?video_id=v0300fee0000blqbcjjck9jvpmusgceg&line=1&ratio=540p&watermark=1&media_type=4&vr_type=0&improve_bitrate=0&logo_name=aweme_self']}
爬取抖音视频(一)
爬取抖音视频(三)