pytorch实现wGAN(附代码)
WGAN在GAN上加入了wasserstein ditance做了改善:
有一个梯度惩罚项,X是做了一个线性插值。

梯度惩罚:惩罚系数取0.2,总训练5000次,批次为512,优化器同上。

代码:
# -*- coding: utf-8 -*-
"""
Created on Tue Jan 14 16:37:46 2020
@author: ZM
"""
import torch
#自动求导函数
from torch import nn,optim,autograd
import numpy as np
#visdom可视化数据
import visdom
import random
from matplotlib import pyplot as plt
h_dim = 400
batchsz = 512
viz = visdom.Visdom()
#Generator结构
class Generator(nn.Module):
def __init__(self):
super(Generator,self).__init__()
self.net = nn.Sequential(
# 输入z:[b,2] => 2 ; 4层
nn.Linear(2, h_dim),
nn.ReLU(True),
nn.Linear(h_dim,h_dim),
nn.ReLU(True),
nn.Linear(h_dim,h_dim),
nn.ReLU(True),
nn.Linear(h_dim,2),
)
def forward(self,z):
output = self.net(z)
return output
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator,self).__init__()
# 输入z:[b,2] => 2 2维的x分布
self.net = nn.Sequential(
nn.Linear(2, h_dim),
nn.ReLU(True),
nn.Linear(h_dim,h_dim),
nn.ReLU(True),
nn.Linear(h_dim,h_dim),
nn.ReLU(True),
nn.Linear(h_dim,1),
nn.Sigmoid() # [0,1]分布内
)
def forward(self,x):
output = self.net(x)
return output.view(-1)
def data_generator():
# 数据分布已知 8个高斯混合模型 生成数据集
scale = 2.
centers = [
(1,0),
(-1,0),
(0,1),
(0,-1),
(1./np.sqrt(2), 1./np.sqrt(2)),
(1./np.sqrt(2),-1./np.sqrt(2)),
(-1./np.sqrt(2),1./np.sqrt(2)),
(-1./np.sqrt(2),-1./np.sqrt(2))]
centers = [(scale * x,scale * y) for x,y in centers]
while True:
dataset = []
for i in range(batchsz):
#从center 8个高斯均值点中选择一个
point = np.random.randn(2) * 0.02
center = random.choice(centers)
#N(0.1) + center_x1/x2
point[0] += center[0]
point[1] += center[1]
dataset.append(point)
dataset = np.array(dataset).astype(np.float32)
dataset /=1.414
#yield 数据返回并保存状态
yield dataset
def generate_image(D, G, xr, epoch):
"""
Generates and saves a plot of the true distribution, the generator, and the
critic.
"""
N_POINTS = 128
RANGE = 3
plt.clf()
points = np.zeros((N_POINTS, N_POINTS, 2), dtype='float32')
points[:, :, 0] = np.linspace(-RANGE, RANGE, N_POINTS)[:, None]
points[:, :, 1] = np.linspace(-RANGE, RANGE, N_POINTS)[None, :]
points = points.reshape((-1, 2))
# (16384, 2)
# print('p:', points.shape)
# draw contour
with torch.no_grad():
points = torch.Tensor(points).cuda() # [16384, 2]
disc_map = D(points).cpu().numpy() # [16384]
x = y = np.linspace(-RANGE, RANGE, N_POINTS)
cs = plt.contour(x, y, disc_map.reshape((len(x), len(y))).transpose())
plt.clabel(cs, inline=1, fontsize=10)
# plt.colorbar()
# draw samples
with torch.no_grad():
z = torch.randn(batchsz, 2).cuda() # [b, 2]
samples = G(z).cpu().numpy() # [b, 2]
plt.scatter(xr[:, 0], xr[:, 1], c='orange', marker='.')
plt.scatter(samples[:, 0], samples[:, 1], c='green', marker='+')
viz.matplot(plt, win='contour', opts=dict(title='p(x):%d'%epoch))
def gradient_penalty(D, xr, xf):
"""
:param D:
:param xr:[b,2]
:param xf:[b,2]
:return:
"""
# only constrait for Discriminator
# xf = xf.detach()
# xr = xr.detach()
# [b, 1] => [b, 2]
t = torch.rand(batchsz, 1).cuda()
t = t.expand_as(xr)
#在真实数据和生成的做插值
mid = t * xr + ((1 - t) * xf)
#做导数
mid.requires_grad_()
pred = D(mid)
grads = autograd.grad(outputs=pred, inputs=mid,
grad_outputs=torch.ones_like(pred),
create_graph=True, retain_graph=True, only_inputs=True)[0]
#2范数越接近于1越好
gp = torch.pow((grads.norm(2, dim=1) - 1) , 2).mean()
return gp
def main():
#设置种子,seed固定住
torch.manual_seed(23)
np.random.seed(23)
data_iter = data_generator()
x = next(data_iter)
# x = next(data_iter)
# print(x.shape)
G = Generator().cuda()
D = Discriminator().cuda()
# print(G)
# print(D)
optim_G = optim.Adam(G.parameters(), lr=5e-4,betas=(0.5,0.9))
optim_D = optim.Adam(D.parameters(), lr=5e-4,betas=(0.5,0.9))
viz.line([[0,0]],[0],win = 'loss',opts = dict(title = 'loss',legend=['D','G']))
for epoch in range(5000):
#1.train D firstly 交替优化
for _ in range(5):
#1.train real data 真实数据送入D 越大越好
xr = next(data_iter)
xr = torch.from_numpy(xr).cuda()
#[b,2] =>[b,1]
predr = (D(xr))
#max predr
lossr = -(predr.mean())
#1.2 train on fake data
z = torch.randn(batchsz,2).cuda()
xf = G(z).detach() #tf.stop_gradient
predf = (D(xf))
#越小越好
lossf = (predf.mean())
#1.3 grad penalty
gp = gradient_penalty(D, xr, xf.detach())
#aggergate all
loss_D = lossr + lossf + gp*0.2
#optimize
optim_D.zero_grad()
loss_D.backward()
optim_D.step()
#2.train G
z = torch.randn(batchsz,2).cuda()
xf = G(z)
predf = (D(xf))
#max predr
loss_G = -(predf.mean())
#optimize
optim_G.zero_grad()
loss_G.backward()
optim_G.step()
if epoch % 100 == 0:
viz.line([[loss_D.item(),loss_G.item()]],[epoch],win = 'loss',update = 'append')
generate_image(D,G,xr.cpu(),epoch)
print(loss_D.item(), loss_G.item())
if __name__=='__main__':
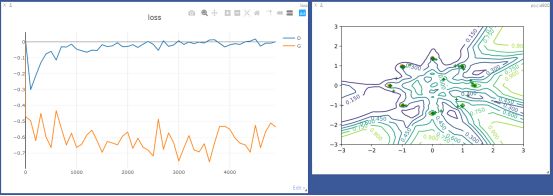
main()训练结果:可以看到,D的值趋近于0,G的值趋近于-0.6,比GAN稳定了许多。
问题:TupeError:can't convert CUDA to numpy.Use Tensor.cpu() to copy the tensor to host memory first.
![]()
解决:generate_image(D,G,xr,epoch)改为generate_image(D,G,xr.cpu(),epoch)
传输数据时不能将从numpy读取的tensor直接传给CUDA,要通过Tensor.cpu()进行转换。