- Flink 2.0 DataStream算子全景
Edingbrugh.南空
大数据flinkflink人工智能
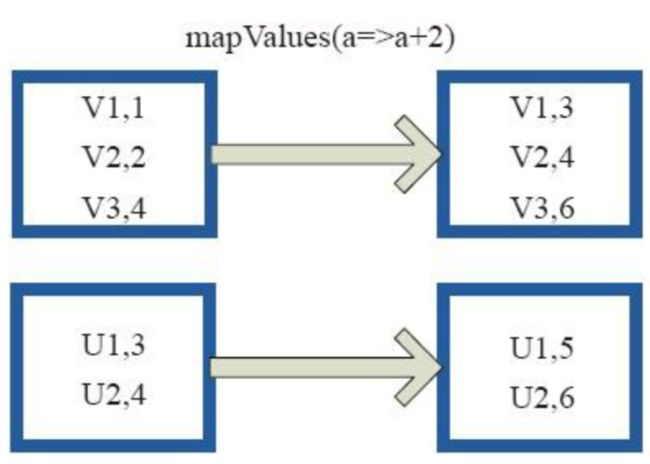
在实时流处理中,ApacheFlink的DataStreamAPI算子是构建流处理pipeline的基础单元。本文基于Flink2.0,聚焦算子的核心概念、分类及高级特性。一、算子核心概念:流处理的"原子操作1.数据流拓扑(StreamTopology)每个Flink应用可抽象为有向无环图(DAG),由源节点(Source)、算子节点(Operator)和汇节点(Sink)构成,算子通过数据流(S
- flink自定义函数
逆风飞翔的小叔
flink入门到精通flink大数据bigdata
前言在很多情况下,尽管flink提供了丰富的转换算子API可供开发者对数据进行各自处理,比如map(),filter()等,但在实际使用的时候仍然不能满足所有的场景,这时候,就需要开发人员基于常用的转换算子的基础上,做一些自定义函数的处理1、来看一个常用的操作原始待读取的文件核心代码importorg.apache.flink.api.common.functions.FilterFunction
- Flink DataStream API详解(二)
一、引言咱两书接上回,上一篇文章主要介绍了DataStreamAPI一些基本的使用,主要是针对单数据流的场景下,但是在实际的流处理场景中,常常需要对多个数据流进行合并、拆分等操作,以满足复杂的业务需求。Flink的DataStreamAPI提供了一系列强大的多流转换算子,如union、connect和split等,下面我们来详细了解一下它们的功能和用法。二、多流转换2.1union算子union算
- Halcon算子--shape_trans,用于变换区域的形状
X-Vision
函数原型:shape_trans(Region:RegionTrans:Type:)shape_trans仍然是区域,smallest_rectangle1可以获得四个角的坐标函数作用:变换区域的形状参数列表:Region(in):被变换的区域RegionTrans(out):变换后的区域Type(in):变换类型参数Type的可选项解释如下:convex:凸包性ellipse:与输入区域有相同的
- 从十六进制字节字符串到UTF-8文本:解码原理与JavaScript实现
在Web开发和数据处理中,我们经常需要处理不同编码格式的数据。本文将深入探讨如何将十六进制表示的UTF-8字节字符串转换为可读的文本内容,并提供一个完整的JavaScript实现方案。一、UTF-8编码基础UTF-8(8-bitUnicodeTransformationFormat)是一种针对Unicode的可变长度字符编码,也是互联网上使用最广泛的一种Unicode编码方式。它有以下特点:兼容A
- 安全运维的 “五层防护”:构建全方位安全体系
KKKlucifer
安全运维
在数字化运维场景中,异构系统复杂、攻击手段隐蔽等挑战日益突出。保旺达基于“全域纳管-身份认证-行为监测-自动响应-审计溯源”的五层防护架构,融合AI、零信任等技术,构建全链路安全运维体系,以下从技术逻辑与实践落地展开解析:第一层:全域资产纳管——筑牢安全根基挑战云网基础设施包含分布式计算(Hadoop/Spark)、数据流处理(Storm/Flink)等异构组件,通信协议繁杂,传统方案难以全面纳管
- 【目标检测】Yolov7 的 ELAN 和 E-ELAN 模块演进(涉及到分组卷积,cardinality,梯度路径)
Jiangnan_Cai
深度学习目标检测YOLO人工智能
感觉从YOLOv6开始,YOLOv6系列感觉优化点都着重于推理速度上面,YOLOv6的RepBlock重参数化,给我的感觉就是算子融合进行加速。而YOLOv7,为了在各种架构的边缘设备上获得极致的推理速度。YOLOv7的工作:新的bagoffreebies(有效的训练技巧,不会增加推理的计算量)有规划的重参数化模型(不同边缘设备架构,不同的重参数化方法)新的动态标签分配方法为了更好的理解YOLOv
- Hive 事务表(ACID)问题梳理
文章目录问题描述分析原因什么是事务表概念事务表和普通内部表的区别相关配置事务表的适用场景注意事项设计原理与实现文件管理格式参考博客问题描述工作中需要使用pyspark读取Hive中的数据,但是发现可以获取metastore,外部表的数据可以读取,内部表数据有些表报错信息是:AnalysisException:org.apache.hadoop.hive.ql.metadata.HiveExcept
- Apache Cloudberry 向量化实践(二):如何识别和定位向量化系统的性能瓶颈?
数据库
如何系统性识别并定位向量化执行链路中的性能瓶颈?本文将结合分析方法论与实践案例,帮助大家建立起优化的基本盘。性能问题从何而来?向量化系统中的性能瓶颈往往不易察觉。它可能是某个操作符计算效率低下,也可能是某次调度延迟过大,甚至是系统某一阶段发生了资源争抢。大致来看,性能瓶颈来源可分为以下几类:计算瓶颈(on-CPU):如表达式编译低效、算子计算逻辑复杂等。等待瓶颈(off-CPU):如线程调度延迟、
- 云原生--微服务、CICD、SaaS、PaaS、IaaS
青秋.
云原生docker云原生微服务kubernetesserverlessservice_meshci/cd
往期推荐浅学React和JSX-CSDN博客一文搞懂大数据流式计算引擎Flink【万字详解,史上最全】-CSDN博客一文入门大数据准流式计算引擎Spark【万字详解,全网最新】_大数据spark-CSDN博客目录1.云原生概念和特点2.常见云模式3.云对外提供服务的架构模式3.1IaaS(Infrastructure-as-a-Service)3.2PaaS(Platform-as-a-Servi
- Spark运行架构
EmoGP
Sparkspark架构大数据
Spark框架的核心是一个计算引擎,整体来说,它采用了标准master-slave的结构 如下图所示,它展示了一个Spark执行时的基本结构,图形中的Driver表示master,负责管理整个集群中的作业任务调度,图形中的Executor则是slave,负责实际执行任务。由上图可以看出,对于Spark框架有两个核心组件:DriverSpark驱动器节点,用于执行Spark任务中的main方法,负
- Spark 各种配置项
zhixingheyi_tian
大数据sparkSparkConfsparkjvmjava
/bin/spark-shell--masteryarn--deploy-modeclient/bin/spark-shell--masteryarn--deploy-modeclusterTherearetwodeploymodesthatcanbeusedtolaunchSparkapplicationsonYARN.Inclustermode,theSparkdriverrunsinside
- Spark RDD 及性能调优
Aurora_NeAr
sparkwpfc#
RDDProgrammingRDD核心架构与特性分区(Partitions):数据被切分为多个分区;每个分区在集群节点上独立处理;分区是并行计算的基本单位。计算函数(ComputeFunction):每个分区应用相同的转换函数;惰性执行机制。依赖关系(Dependencies)窄依赖:1个父分区→1个子分区(map、filter)。宽依赖:1个父分区→多个子分区(groupByKey、join)。
- Apache Iceberg数据湖基础
Aurora_NeAr
apache
IntroducingApacheIceberg数据湖的演进与挑战传统数据湖(Hive表格式)的缺陷:分区锁定:查询必须显式指定分区字段(如WHEREdt='2025-07-01')。无原子性:并发写入导致数据覆盖或部分可见。低效元数据:LIST操作扫描全部分区目录(云存储成本高)。Iceberg的革新目标:解耦计算引擎与存储格式(支持Spark/Flink/Trino等);提供ACID事务、模式
- Halcon学习之select_shape()算子参数介绍
一、算子介绍select_shape()是HALCON中用于基于形状特征筛选区域的关键算子,广泛应用于图像分割、目标检测和工业质检等领域。它允许用户根据指定的几何特征从输入区域集合中选择符合条件的区域。至于为什么单独介绍这个算子呢,因为他筛选特征的方式有太多种了,如果可以熟练的掌握这些特征,那在后面的例程学习以及实际应用中,可谓是得心应手了。二、算子参数select_shape(Regions:S
- Halcon例程学习四:pcb_inspection.hdev
CVer_
Halcon例程学习学习
一、例程介绍这个例程主要是检测pcb电路板中的一些电路线缺陷二、例程相关算子gray_opening_shape()//特定形状结构元的灰度开运算gray_closing_shape()//特定形状结构元的灰度闭运算dyn_threshold()//动态二值化操作三、例程处理流程1.对原图像进行灰度开运算,图像先腐蚀再膨胀。经过灰度开运算后,图像整体会变暗一些,并且会将黑色区域中的白色缺陷进行填充
- halcon算子翻译——gray_histo和gray_histo_abs
机器人自动化控制
HALCON
算子:gray_histo(Regions,Image:::AbsoluteHisto,RelativeHisto)功能:计算灰度值分布。算子gray_histo为区域内的图像计算灰度值的绝对和相对的直方图。两个直方图都是256个值的元组,它们从0开始,包含图像的各个灰度值的频率。输入参数:Regions:输入计算的区域;Image:输入图像(byte/cyclic/direction/intl/
- 大数据技术之Flink
第1章Flink概述1.1Flink是什么1.2Flink特点1.3FlinkvsSparkStreaming表Flink和Streaming对比FlinkStreaming计算模型流计算微批处理时间语义事件时间、处理时间处理时间窗口多、灵活少、不灵活(窗口必须是批次的整数倍)状态有没有流式SQL有没有1.4Flink的应用场景1.5Flink分层API第2章Flink快速上手2.1创建项目在准备
- 20.XLD轮廓
Echo``
Halcon系统化学习计算机视觉人工智能算法
目录1.xld概念2.画轮廓3.区域转轮廓4.边缘提取算子5.xld特征提取6.提取任意线条7.提取最长的线条8.xld分割10.xld合并11.xld拟合12.xld几何变换13.xld变换14.xld集合运算15.区域和轮廓精度16.轮廓的保存读取17.halcon操作CAD文件18.轮廓测量算子19.同心度计算1.xld概念*图像处理*1.处理对象HObject*1.图像-image*2.区
- Hadoop核心组件最全介绍
Cachel wood
大数据开发hadoop大数据分布式spark数据库计算机网络
文章目录一、Hadoop核心组件1.HDFS(HadoopDistributedFileSystem)2.YARN(YetAnotherResourceNegotiator)3.MapReduce二、数据存储与管理1.HBase2.Hive3.HCatalog4.Phoenix三、数据处理与计算1.Spark2.Flink3.Tez4.Storm5.Presto6.Impala四、资源调度与集群管
- Android及Harmonyos实现图片进度显示效果
谦和的大熊
harmonyosandroid华为
鸿蒙Harmonyos实现,使用ImageKnife自定义transform来实现图片进度效果import{Context}from'@ohos.abilityAccessCtrl';import{image}from'@kit.ImageKit';import{drawing}from'@kit.ArkGraphics2D';import{GrayScaleTransformation,Pixe
- 用Python解锁图像处理之力:从基础到智能应用的深度探索
熊猫钓鱼>_>
python图像处理开发语言
在像素构成的数字世界里,Python已成为解码图像奥秘的核心引擎。一、为何选择Python处理图像?超越工具的本质思考当人们谈论图像处理时,往往会陷入工具对比的漩涡(PythonvsMATLABvsC++)。但Python的真正价值在于其构建的完整生态闭环:科学计算基石:NumPy的ndarray结构完美对应图像的多维矩阵本质算法实现自由:从传统算子到深度学习模型的无缝衔接可视化即战力:Matpl
- 大数据分析技术的学习路径,不是绝对的,仅供参考
水云桐程序员
学习大数据数据分析学习方法
阶段一:基础筑基(1-3个月)1.编程语言:Python:掌握基础语法、数据结构、流程控制、函数、面向对象编程、常用库(NumPy,Pandas)。SQL:精通SELECT语句(过滤、排序、分组、聚合、连接)、DDL/DML基础。理解关系型数据库概念(表、主键、外键、索引)。MySQL或PostgreSQL是很好的起点。Java/Scala:深入理解Hadoop/Spark等框架会更有优势。初学者
- 大数据开发高频面试题:Spark与MapReduce解析
被招网约司机的盯上了好几天实习了六个月,到期被通知不能转正。外包裁员让我去友商我该去吗?offer比较华为状态码浏览器插件嵌入式项目推荐2019秋招总结+云从语音算法面经+银行群面面经科大讯飞语音算法面经语音算法美团一面已挂科大讯飞智能语音方向值得去吗?语音算法oc科大讯飞语音算法二面荣耀一面语音算法面经,已挂荣耀_语音算法工程一面科大讯飞语音一面凉经8.18携程机器学习(语音方向)一面【vivo
- 遗传算法Matlab代码实现及算法函数封装
文章目录前言一、遗传算法介绍二、遗传算法算子1.种群初始化1.1二进制数编码1.2浮点数编码1.3小结2.选择算子3.交叉算子4.变异算子5.小结三、算法实例1.例一2.例二3.例三4.小结四、算法函数封装1.示例一2.示例二3.示例三五、参考文献前言遗传算法(GA)作为求解单目标优化问题的有效算法,自提出以来,便被广泛采用。该算法主要是模仿达尔文进化论,通过种群不断的进行自然选择、繁衍交叉变异,
- Python面向对象编程:继承与多态
三笠o.0
Pythonpython开发语言
1.继承概念:继承是面向对象编程的核心特性之一,它允许一个类(子类/派生类)继承另一个类(父类/基类)的属性和方法,从而建立类之间的父子关系。通过继承,子类可以复用父类的功能,同时还能扩展或修改父类的行为。语法:class子类名(父类名):#子类的代码块pass关键特性:单继承子类仅继承一个父类,形成简单的层级关系。总结:子类可以继承父类的属性和方法,就算子类自己没有,也可以使用父类的#1.继承#
- spark处理kafka的用户行为数据写入hive
月光一族吖
sparkkafkahive
在CentOS上部署Hadoop(Hadoop3.4.1)和Hive(Hive3.1.2)的详细步骤说明。这份指南面向单机安装(伪集群模式),如果需要搭建真正的多节点集群,各节点间的网络互访、SSH免密登录以及配置同步需进一步调整。注意:本指南假设你已拥有root权限或者具有sudo权限,并且系统连接Internet(用于下载安装包)。步骤中的版本号可根据实际需要进行更改。一、环境准备更新系统软件
- Spark 4.0的VariantType 类型以及内部存储
鸿乃江边鸟
大数据SQLsparksparksql大数据
背景本文基于Spark4.0总结Spark中的VariantType类型,用尽量少的字节来存储Json的格式化数据分析这里主要介绍Variant的存储,我们从VariantBuilder.buildJson方法(把对应的json数据存储为VariantType类型)开始:publicstaticVariantparseJson(JsonParserparser,booleanallowDuplic
- 如何学习才能更好地理解人工智能工程技术专业和其他信息技术专业的关联性?
人工智能教学实践
python编程实践人工智能学习人工智能
要深入理解人工智能工程技术专业与其他信息技术专业的关联性,需要跳出单一专业的学习框架,通过“理论筑基-实践串联-跨学科整合”的路径构建系统性认知。以下是分阶段、可落地的学习方法:一、建立“专业关联”的理论认知框架绘制知识关联图谱操作方法:用XMind或Notion绘制思维导图,以AI为中心,辐射关联专业的核心技术节点。例如:AI(机器学习)├─数据支撑:大数据技术(Hadoop/Spark)+数据
- C++ 学习(2) ---- std::cout 格式化输出
小猪佩奇TONY
C++学习c++学习
目录std::cout格式化输出简介使用成员函数使用流操作算子std::cout格式化输出简介C++通常使用cout输出数据,和printf()函数相比,cout实现格式化输出数据的方式更加多样化;一方面,cout作为ostream类的对象,该类中提供有一些成员方法,可实现对输出数据的格式化;另一方面,为了方面用户格式化输出数据,C++标准库专门提供了一个头文件,该头文件中包含有大量的格式控制符,
- xml解析
小猪猪08
xml
1、DOM解析的步奏
准备工作:
1.创建DocumentBuilderFactory的对象
2.创建DocumentBuilder对象
3.通过DocumentBuilder对象的parse(String fileName)方法解析xml文件
4.通过Document的getElem
- 每个开发人员都需要了解的一个SQL技巧
brotherlamp
linuxlinux视频linux教程linux自学linux资料
对于数据过滤而言CHECK约束已经算是相当不错了。然而它仍存在一些缺陷,比如说它们是应用到表上面的,但有的时候你可能希望指定一条约束,而它只在特定条件下才生效。
使用SQL标准的WITH CHECK OPTION子句就能完成这点,至少Oracle和SQL Server都实现了这个功能。下面是实现方式:
CREATE TABLE books (
id &
- Quartz——CronTrigger触发器
eksliang
quartzCronTrigger
转载请出自出处:http://eksliang.iteye.com/blog/2208295 一.概述
CronTrigger 能够提供比 SimpleTrigger 更有具体实际意义的调度方案,调度规则基于 Cron 表达式,CronTrigger 支持日历相关的重复时间间隔(比如每月第一个周一执行),而不是简单的周期时间间隔。 二.Cron表达式介绍 1)Cron表达式规则表
Quartz
- Informatica基础
18289753290
InformaticaMonitormanagerworkflowDesigner
1.
1)PowerCenter Designer:设计开发环境,定义源及目标数据结构;设计转换规则,生成ETL映射。
2)Workflow Manager:合理地实现复杂的ETL工作流,基于时间,事件的作业调度
3)Workflow Monitor:监控Workflow和Session运行情况,生成日志和报告
4)Repository Manager:
- linux下为程序创建启动和关闭的的sh文件,scrapyd为例
酷的飞上天空
scrapy
对于一些未提供service管理的程序 每次启动和关闭都要加上全部路径,想到可以做一个简单的启动和关闭控制的文件
下面以scrapy启动server为例,文件名为run.sh:
#端口号,根据此端口号确定PID
PORT=6800
#启动命令所在目录
HOME='/home/jmscra/scrapy/'
#查询出监听了PORT端口
- 人--自私与无私
永夜-极光
今天上毛概课,老师提出一个问题--人是自私的还是无私的,根源是什么?
从客观的角度来看,人有自私的行为,也有无私的
- Ubuntu安装NS-3 环境脚本
随便小屋
ubuntu
将附件下载下来之后解压,将解压后的文件ns3environment.sh复制到下载目录下(其实放在哪里都可以,就是为了和我下面的命令相统一)。输入命令:
sudo ./ns3environment.sh >>result
这样系统就自动安装ns3的环境,运行的结果在result文件中,如果提示
com
- 创业的简单感受
aijuans
创业的简单感受
2009年11月9日我进入a公司实习,2012年4月26日,我离开a公司,开始自己的创业之旅。
今天是2012年5月30日,我忽然很想谈谈自己创业一个月的感受。
当初离开边锋时,我就对自己说:“自己选择的路,就是跪着也要把他走完”,我也做好了心理准备,准备迎接一次次的困难。我这次走出来,不管成败
- 如何经营自己的独立人脉
aoyouzi
如何经营自己的独立人脉
独立人脉不是父母、亲戚的人脉,而是自己主动投入构造的人脉圈。“放长线,钓大鱼”,先行投入才能产生后续产出。 现在几乎做所有的事情都需要人脉。以银行柜员为例,需要拉储户,而其本质就是社会人脉,就是社交!很多人都说,人脉我不行,因为我爸不行、我妈不行、我姨不行、我舅不行……我谁谁谁都不行,怎么能建立人脉?我这里说的人脉,是你的独立人脉。 以一个普通的银行柜员
- JSP基础
百合不是茶
jsp注释隐式对象
1,JSP语句的声明
<%! 声明 %> 声明:这个就是提供java代码声明变量、方法等的场所。
表达式 <%= 表达式 %> 这个相当于赋值,可以在页面上显示表达式的结果,
程序代码段/小型指令 <% 程序代码片段 %>
2,JSP的注释
<!-- -->
- web.xml之session-config、mime-mapping
bijian1013
javaweb.xmlservletsession-configmime-mapping
session-config
1.定义:
<session-config>
<session-timeout>20</session-timeout>
</session-config>
2.作用:用于定义整个WEB站点session的有效期限,单位是分钟。
mime-mapping
1.定义:
<mime-m
- 互联网开放平台(1)
Bill_chen
互联网qq新浪微博百度腾讯
现在各互联网公司都推出了自己的开放平台供用户创造自己的应用,互联网的开放技术欣欣向荣,自己总结如下:
1.淘宝开放平台(TOP)
网址:http://open.taobao.com/
依赖淘宝强大的电子商务数据,将淘宝内部业务数据作为API开放出去,同时将外部ISV的应用引入进来。
目前TOP的三条主线:
TOP访问网站:open.taobao.com
ISV后台:my.open.ta
- 【MongoDB学习笔记九】MongoDB索引
bit1129
mongodb
索引
可以在任意列上建立索引
索引的构造和使用与传统关系型数据库几乎一样,适用于Oracle的索引优化技巧也适用于Mongodb
使用索引可以加快查询,但同时会降低修改,插入等的性能
内嵌文档照样可以建立使用索引
测试数据
var p1 = {
"name":"Jack",
"age&q
- JDBC常用API之外的总结
白糖_
jdbc
做JAVA的人玩JDBC肯定已经很熟练了,像DriverManager、Connection、ResultSet、Statement这些基本类大家肯定很常用啦,我不赘述那些诸如注册JDBC驱动、创建连接、获取数据集的API了,在这我介绍一些写框架时常用的API,大家共同学习吧。
ResultSetMetaData获取ResultSet对象的元数据信息
- apache VelocityEngine使用记录
bozch
VelocityEngine
VelocityEngine是一个模板引擎,能够基于模板生成指定的文件代码。
使用方法如下:
VelocityEngine engine = new VelocityEngine();// 定义模板引擎
Properties properties = new Properties();// 模板引擎属
- 编程之美-快速找出故障机器
bylijinnan
编程之美
package beautyOfCoding;
import java.util.Arrays;
public class TheLostID {
/*编程之美
假设一个机器仅存储一个标号为ID的记录,假设机器总量在10亿以下且ID是小于10亿的整数,假设每份数据保存两个备份,这样就有两个机器存储了同样的数据。
1.假设在某个时间得到一个数据文件ID的列表,是
- 关于Java中redirect与forward的区别
chenbowen00
javaservlet
在Servlet中两种实现:
forward方式:request.getRequestDispatcher(“/somePage.jsp”).forward(request, response);
redirect方式:response.sendRedirect(“/somePage.jsp”);
forward是服务器内部重定向,程序收到请求后重新定向到另一个程序,客户机并不知
- [信号与系统]人体最关键的两个信号节点
comsci
系统
如果把人体看做是一个带生物磁场的导体,那么这个导体有两个很重要的节点,第一个在头部,中医的名称叫做 百汇穴, 另外一个节点在腰部,中医的名称叫做 命门
如果要保护自己的脑部磁场不受到外界有害信号的攻击,最简单的
- oracle 存储过程执行权限
daizj
oracle存储过程权限执行者调用者
在数据库系统中存储过程是必不可少的利器,存储过程是预先编译好的为实现一个复杂功能的一段Sql语句集合。它的优点我就不多说了,说一下我碰到的问题吧。我在项目开发的过程中需要用存储过程来实现一个功能,其中涉及到判断一张表是否已经建立,没有建立就由存储过程来建立这张表。
CREATE OR REPLACE PROCEDURE TestProc
IS
fla
- 为mysql数据库建立索引
dengkane
mysql性能索引
前些时候,一位颇高级的程序员居然问我什么叫做索引,令我感到十分的惊奇,我想这绝不会是沧海一粟,因为有成千上万的开发者(可能大部分是使用MySQL的)都没有受过有关数据库的正规培训,尽管他们都为客户做过一些开发,但却对如何为数据库建立适当的索引所知较少,因此我起了写一篇相关文章的念头。 最普通的情况,是为出现在where子句的字段建一个索引。为方便讲述,我们先建立一个如下的表。
- 学习C语言常见误区 如何看懂一个程序 如何掌握一个程序以及几个小题目示例
dcj3sjt126com
c算法
如果看懂一个程序,分三步
1、流程
2、每个语句的功能
3、试数
如何学习一些小算法的程序
尝试自己去编程解决它,大部分人都自己无法解决
如果解决不了就看答案
关键是把答案看懂,这个是要花很大的精力,也是我们学习的重点
看懂之后尝试自己去修改程序,并且知道修改之后程序的不同输出结果的含义
照着答案去敲
调试错误
- centos6.3安装php5.4报错
dcj3sjt126com
centos6
报错内容如下:
Resolving Dependencies
--> Running transaction check
---> Package php54w.x86_64 0:5.4.38-1.w6 will be installed
--> Processing Dependency: php54w-common(x86-64) = 5.4.38-1.w6 for
- JSONP请求
flyer0126
jsonp
使用jsonp不能发起POST请求。
It is not possible to make a JSONP POST request.
JSONP works by creating a <script> tag that executes Javascript from a different domain; it is not pos
- Spring Security(03)——核心类简介
234390216
Authentication
核心类简介
目录
1.1 Authentication
1.2 SecurityContextHolder
1.3 AuthenticationManager和AuthenticationProvider
1.3.1 &nb
- 在CentOS上部署JAVA服务
java--hhf
javajdkcentosJava服务
本文将介绍如何在CentOS上运行Java Web服务,其中将包括如何搭建JAVA运行环境、如何开启端口号、如何使得服务在命令执行窗口关闭后依旧运行
第一步:卸载旧Linux自带的JDK
①查看本机JDK版本
java -version
结果如下
java version "1.6.0"
- oracle、sqlserver、mysql常用函数对比[to_char、to_number、to_date]
ldzyz007
oraclemysqlSQL Server
oracle &n
- 记Protocol Oriented Programming in Swift of WWDC 2015
ningandjin
protocolWWDC 2015Swift2.0
其实最先朋友让我就这个题目写篇文章的时候,我是拒绝的,因为觉得苹果就是在炒冷饭, 把已经流行了数十年的OOP中的“面向接口编程”还拿来讲,看完整个Session之后呢,虽然还是觉得在炒冷饭,但是毕竟还是加了蛋的,有些东西还是值得说说的。
通常谈到面向接口编程,其主要作用是把系统��设计和具体实现分离开,让系统的每个部分都可以在不影响别的部分的情况下,改变自身的具体实现。接口的设计就反映了系统
- 搭建 CentOS 6 服务器(15) - Keepalived、HAProxy、LVS
rensanning
keepalived
(一)Keepalived
(1)安装
# cd /usr/local/src
# wget http://www.keepalived.org/software/keepalived-1.2.15.tar.gz
# tar zxvf keepalived-1.2.15.tar.gz
# cd keepalived-1.2.15
# ./configure
# make &a
- ORACLE数据库SCN和时间的互相转换
tomcat_oracle
oraclesql
SCN(System Change Number 简称 SCN)是当Oracle数据库更新后,由DBMS自动维护去累积递增的一个数字,可以理解成ORACLE数据库的时间戳,从ORACLE 10G开始,提供了函数可以实现SCN和时间进行相互转换;
用途:在进行数据库的还原和利用数据库的闪回功能时,进行SCN和时间的转换就变的非常必要了;
操作方法: 1、通过dbms_f
- Spring MVC 方法注解拦截器
xp9802
spring mvc
应用场景,在方法级别对本次调用进行鉴权,如api接口中有个用户唯一标示accessToken,对于有accessToken的每次请求可以在方法加一个拦截器,获得本次请求的用户,存放到request或者session域。
python中,之前在python flask中可以使用装饰器来对方法进行预处理,进行权限处理
先看一个实例,使用@access_required拦截:
?