RuleEngine -- 一款使用简单,入门方便的数据库规则引擎
规则引擎是嵌入在应用程序中的组件,实现了决策逻辑和业务系统的分离功能。在现实业务场景中,决策逻辑的复杂性和可变性,使得决策引擎的应用越来越多,把决策逻辑单独分离出来也显得越来越重要了。
目前市场上常用的规则引擎有IlogJRules,Drools,Jess,Visual Rules等。Ilog JRules 是最有名的商用BRMS;Drools 是最活跃的开源规则引擎;Jess 是Clips的java实现,就如JRuby之于Ruby,是AI系的代表; Visual Rules(旗正规则引擎)国内商业规则引擎品牌。但是这些规则引擎都需要生成大量的bean类和Judgment类,在实现规则判断的时候,需要编写大量的java代码,或者使用rete规范,另外编写脚本。然后我们实际编程中,这些bean的数据大多数存于数据库中,规则引擎的判断实际上是SQL脚本运行的一部分。
因此在这里介绍一款可以使用SQL脚本来定义规则的中间件 --RuleEngine。RuleEngine已经登记在Maven中的中央库中了,我们可以直接在POM.xml文件中包含就可以了。
使用前,需要先配RuleEngine的配置文件ruleEngine.properties,RuleEngine支持3种规则定义方式,分别是1,数据库table配置;2,xml文件配置;3,Drools的drl文件方式。
在ruleEngine.properties中设置rule.reader字段即可,下面分别说明:
1, 数据库table配置方式,在ruleEngine.properties中,设置rule.reader = database
此时需要配置下面的信息
a) db.rule.table字段,设置db.rule.table=tl_rule_define(表名)。此表结构的定义在https://github.com/Hale-Lee/RuleEngine/tree/dev/referenc中有定义(有oralce和mysql的2种方式)。
b) db.accesser数据连接方式,RuleEngine提供了直接的jdbc连接,Druid连接池,Spring框架连接3种方式。如果使用jdbc链接或者是Druid链接,那么需要设置db.accesser=tech.kiwa.engine.utility.DirectDBAccesser(设置DirectDBAccesser的UseDruid可以区别是否使用Druid连接池,默认是true使用)。如果直接使用Spring框架的连接,那么需要设置db.accesser= tech.kiwa.engine.utility. SpringDBAccesser。
RuleEngine也提供DBAccesser的接口,我们可以通过实现DBAccessor的接口的方法来自己获得自己的连接。
c) 如果使用jdbc链接或者是Druid链接,那么需要配置jdbc属性,或者是Druid的连接池参数,RuleEngine可以独立配置连接池参数,也可以直接使用项目中现有的连接参数。
典型的配置文件的方式如下(使用Druid配置):
#数据驱动
jdbc.driver=com.mysql.cj.jdbc.Driver
#jdbc.driver=oracle.jdbc.driver.OracleDriver
#数据库连接
jdbc.url=jdbc:mysql://127.0.0.1:3306/hosp?useUnicode=true&characterEncoding=utf-8&zeroDateTimeBehavior=convertToNull&useSSL=true
#数据库用户名
jdbc.username=oracle
jdbc.password=user
#规则定义的表
db.rule.table=TL_RULE_DEFINE
db.accesser=tech.kiwa.engine.utility.DirectDBAccesser
rule.reader=database
数据库表结构的定义如下:
|
|
-- Table structure for TL_RULE_DEFINE |
|
-- ---------------------------- |
|
DROPTABLE"TL_RULE_DEFINE"; |
|
CREATETABLE "TL_RULE_DEFINE" ( |
|
"ITEM_NO" NVARCHAR2(32) NOT NULL , |
|
"CONTENT" NVARCHAR2(256) NULL , |
|
"EXE_SQL" NVARCHAR2(512) NULL , |
|
"EXE_CLASS" NVARCHAR2(128) NULL , |
|
"PARAM_NAME" NVARCHAR2(128) NULL , |
|
"PARAM_TYPE" NVARCHAR2(128) NULL , |
|
"COMPARISON_CODE" NVARCHAR2(32) NULL , |
|
"COMPARISON_VALUE" NVARCHAR2(64) NULL , |
|
"BASELINE" NVARCHAR2(64) NULL , |
|
"RESULT" NVARCHAR2(6) NULL , |
|
"PRIORITY" NVARCHAR2(32) NULL , |
|
"CONTINUE_FLAG" NVARCHAR2(2) NULL , |
|
"PARENT_ITEM_NO" NVARCHAR2(2) NULL , |
|
"PARENT_EXPRESS" NVARCHAR2(256) NULL , |
|
"EXECUTOR" NVARCHAR2(64) NULL , |
|
"REMARK" NVARCHAR2(64) NULL , |
|
"COMMENTS" NVARCHAR2(64) NULL , |
|
"ENABLE_FLAG" NVARCHAR2(2) NULL , |
|
"CREATE_TIME"TIMESTAMP(6) NULL , |
|
"UPDATE_TIME"TIMESTAMP(6) NULL |
|
) |
|
LOGGING |
|
NOCOMPRESS |
|
NOCACHE; |
|
|
|
|
|
COMMENT ON TABLE "TL_RULE_DEFINE" IS '规则引擎定义表'; |
|
COMMENT ON COLUMN "TL_RULE_DEFINE"."ITEM_NO" IS '主key'; |
|
COMMENT ON COLUMN "TL_RULE_DEFINE"."CONTENT" IS '中文的内容说明'; |
|
COMMENT ON COLUMN "TL_RULE_DEFINE"."EXE_SQL" IS '执行的SQL语句'; |
|
COMMENT ON COLUMN "TL_RULE_DEFINE"."EXE_CLASS" IS '执行检查的java类名,与exe_sql二者只填写一项'; |
|
COMMENT ON COLUMN "TL_RULE_DEFINE"."PARAM_NAME" IS 'SQL语句的参数,多个参数用,分割,读值时需要完成和继承DefaultCustomerCheck类。'; |
|
COMMENT ON COLUMN "TL_RULE_DEFINE"."PARAM_TYPE" IS 'exe_sql或者exe_class的参数类型,多个类型用逗号(,)分割,与param_name需一一对应。'; |
|
COMMENT ON COLUMN "TL_RULE_DEFINE"."COMPARISON_CODE" IS '01: = , 02: > , 03 : < , 04 != , 05 >= , 06: <= , 07 include , 08 exclude , 09: included by 10: excluded by 11: equal , 12 : not equal 13: euqalIngoreCase 15: matches 16: NOT MATCHES'; |
|
COMMENT ON COLUMN "TL_RULE_DEFINE"."COMPARISON_VALUE" IS '=,>,<,>=,<=, !=, include, exclude等内容。'; |
|
COMMENT ON COLUMN "TL_RULE_DEFINE"."BASELINE" IS '参数值,比较目标值'; |
|
COMMENT ON COLUMN "TL_RULE_DEFINE"."RESULT" IS '1 - 通过 2 - 关注 3 -拒绝 逻辑运算满足目标值的时候读取改内容。'; |
|
COMMENT ON COLUMN "TL_RULE_DEFINE"."PRIORITY" IS '执行的优先顺序,值大的优先执行.'; |
|
COMMENT ON COLUMN "TL_RULE_DEFINE"."CONTINUE_FLAG" IS '是否继续执行下一条,如果某条规则满足中断的话,那么就设置为 2. 1 -- 继续 2 -- 中断'; |
|
COMMENT ON COLUMN "TL_RULE_DEFINE"."PARENT_ITEM_NO" IS '如果是子规则,那么需要填写父规则的item_no'; |
|
COMMENT ON COLUMN "TL_RULE_DEFINE"."PARENT_EXPRESS" IS '同一PARENT_ITEM的各个ITEM的运算表达式。 ( A AND B OR C)'; |
|
COMMENT ON COLUMN "TL_RULE_DEFINE"."EXECUTOR" IS '结果执行后的被执行体,从AbstractCommand中继承下来。'; |
|
COMMENT ON COLUMN "TL_RULE_DEFINE"."ENABLE_FLAG" IS '是否使用 1 - 有效 2 - 失效'; |
|
|
|
-- ---------------------------- |
|
-- Checks structure for table TL_RULE_DEFINE |
|
-- ---------------------------- |
|
ALTERTABLE"TL_RULE_DEFINE" ADD CHECK ("ITEM_NO"IS NOT NULL); |
其说明可以参考:
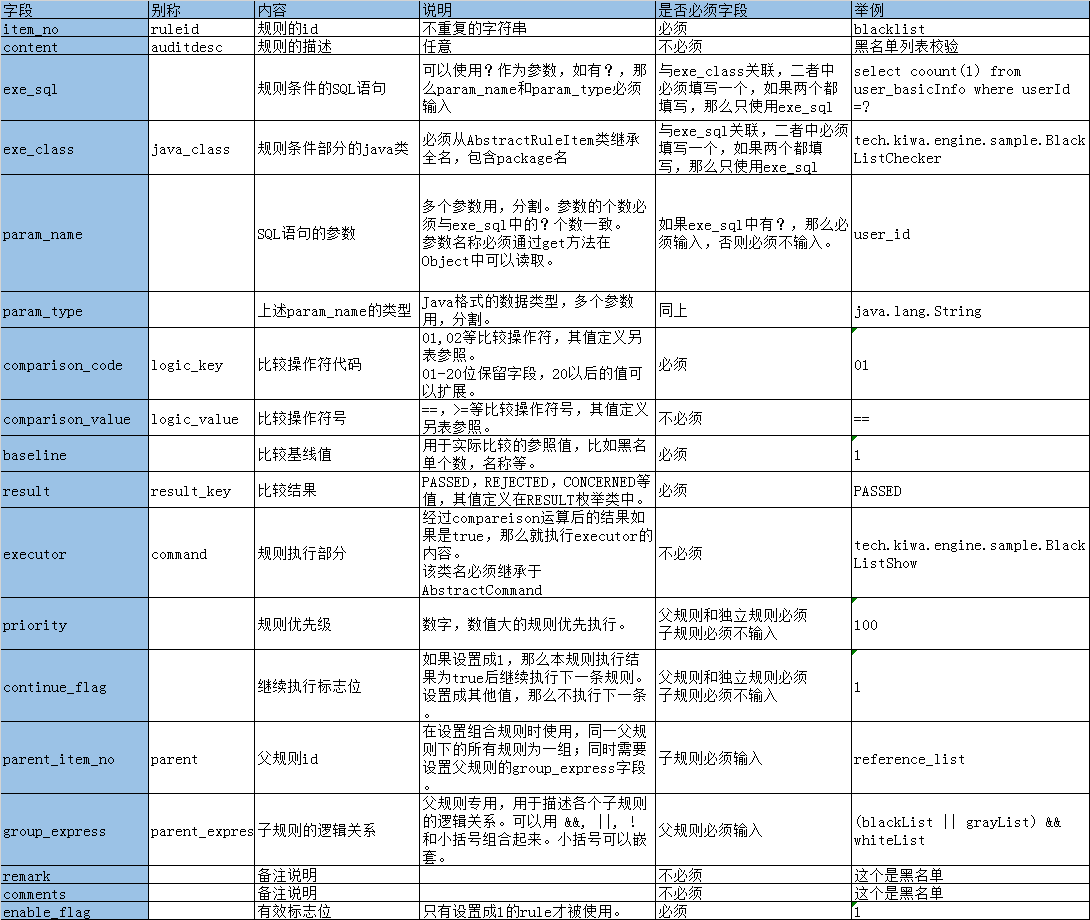
2, xml文件配置,xml文件配置的方式也需要在ruleEngine.properties中配置引擎的读写方式。仅仅配置两项内容即可。
rule.reader=xml
#指定规则文件的文件名,RuleEngine会从classpath中搜索该文件。
xml.rule.filename=ruleconfig.xml
XML文件的写法与table类似,典型的xml文件格式为:
xml version="1.0" encoding="UTF-8"?>
<rules >
<organization>
<url>www.kiwa.techurl>
organization>
<description>
Configuration for the rulelist which stores the rule information in-memory and executed by rule engineservice.
description>
<rule id="totallist"exe_class="" method=""parent="">
<property name="content"value="客户身份证号码规则"/>
<property name="result"value="RESULT.REJECTED" desc="拒绝"/>
<property name="continue_flag"value="1"/>
<property name="group_express"value="(blacklist || graylist)"/>
<property name="priority"value="10"/>
rule>
<rule id="blacklist"parent="totallist">
<property name="content"value="客户身份证号码命中内部黑名单"/>
<property name="exe_sql"value="select count(1) from customer_black_list where certificate_type>=1 and customer_no = ? and is_black = 1"/>
<property name="param"value="CUSTOMER_NO" type="java.lang.String" desc="客户编号"/>
<property name="comparison_code"value="02"/>
<property name="comparison_value"value=">"/>
<property name="baseline"value="0"/>
<property name="baseline_desc"value="客户的身份证号码在黑名单表个数中大于0"/>
rule>
<rule id="graylist"exe_class="" method=""parent="totallist">
<property name="content"value="客户身份证号码命中内部灰名单"/>
<property name="exe_sql"value="select count(1) from customer_black_list where certificate_type=1 and customer_no = ? and is_gray = 1"/>
<property name="param"value="CUSTOMER_NO" type="java.lang.String" desc="客户编号"/>
<property name="comparison_code"value="02"/>
<property name="comparison_value"value=">"/>
<property name="baseline"value="0"/>
<property name="baseline_desc"value="客户的身份证号码在黑名单表个数中大于0"/>
rule>
rules>
3, Drools文件方式,RuleEngine同样支持读取Drools的drl文件中的规则,并且可以直接执行其规则体。此时需要在ruleEngine.properties中配置引擎的读写方式。仅仅配置两项内容即可。
rule.reader=drools
drools.rule.filename=sample.drl
Drools的文件样式请参考具体Drools的文档,典型的样式为:
#thisis a test
packagetech.kiwa.engine.entity;
globalsjava.util.List myGlobalList
importtech.kiwa.engine.sample.Student;
functionvoid callOver(Student $student){
if($student != null){
System.out.println("student[" + $student.name + "] iscalled.");
}
}
functionvoid ageUp(Student $student, int age ){
if($student != null){
$student.setAge($student.getAge() + age);
}
}
declareteacher
age : int
name : String
sex : int
end
query"juniorBoy"
$student: Student( age <=14 && (age>10 || age !=12 , sex ==1 || sex == 2), name =="tony")
end
query"querymale"(int $gender)
$student: Student(sex == $gender)
end
rule"ageUp12"
salience 400
when
$student:Student(age < 8)
/* antoherrule */
then
System.out.println("I was called, my nameis : " + $student.name);
ageUp($student,12);
//callOver($student);
end
rule"isTom"
salience 30
date-expires"2018-12-01"
dialet "java"
when
$student: Student(name == tom)
then
$student.sex= 4;
callOver($student);
end
启动RuleEngine,RuleEngine是针对一个具体的目标对象(Bean)进行检测的,该目标对象(Bean)必须是可读的,必须提供对应的get方法,或者其成员变量是public的。比如学生对象,我们需要检测该学生对象是否符合我们定义的规则。因此,在调用规则引擎前,必须存在该对象,如果有多个对象,那请在循环体中执行该条件。
示例代码如下:
EngineServiceservice= newEngineService();
try {
Studentst = new Student(); //建立学生对象
st.setAge(5);
st.name = "tom";
st.sex = 1;
EngineRunResultresult = service.start(st);
System.out.println(result.getResult().getName());
System.out.println(st.getAge());
}catch(RuleEngineException e) {
e.printStackTrace();
}
上述代码中,Sutdent对象存在getAge方法,因此是可以被访问的,其规则也是可以执行的,否则会抛出RuleEngineException异常,在对应的规则中,执行了ageUp()的Command操作。