Geometric deep learning: going beyond Euclidean data(几何深度学习:超越欧几里得数据)
目录
前言:
1.介绍
2.几何学习问题
3.欧几里得域的深度学习
4.流行和图的几何形状(流形完全没看明白)
5.谱方法
6.无谱方法
7.基于计费的方法
8.结合空间和光谱方法
9.应用
名词解释:
原文地址:https://arxiv.org/pdf/1611.08097.pdf
前言:
许多科学领域都研究具有非欧几里得空间的基础结构的数据。一些示例包括计算社会科学中的社交网络,通讯中的传感器网络,大脑成像中的功能网络,遗传学中的调节网络以及计算机图形学中的网状表面。在许多应用中,此类几何数据既庞大又复杂(对于社交网络而言,规模为数十亿美元),并且是机器学习技术的自然目标。特别是,我们希望使用深度神经网络,最近证明它是解决计算机视觉,自然语言处理和音频分析等广泛问题的强大工具。但是,这些工具在具有基本欧几里得或类网格结构的数据上以及在将这些结构的不变性内置到用于建模的网络中的情况下,最为成功。
几何深度学习是新兴技术的总称,这些技术试图将(结构化的)深度神经模型推广到非欧几里德领域,如图和流形。本文的目的是概述几何深度学习问题的不同实例,并提出在这一新兴领域的可用解决方案、关键难点、应用以及未来的研究方向。
1.介绍
“深度学习”是指通过以层次或多层的方式从较简单的概念中构建复杂的概念来学习它们。人工神经网络是这种深层多层体系的流行实现。在过去的几年中,基于现代GPU的计算机不断增长的计算能力以及大型训练数据集的可用性已使成功训练具有多个层次和自由度的神经网络成为可能[1]。从语音识别[2],[3]和机器翻译[4]到图像分析和计算机视觉[5],[6],[7],[8],这导致了许多任务的质性突破。,[9],[10],[11](有关深度学习成功应用的许多其他示例,请参阅[12],[13])。如今,深度学习已经发展成为一种广泛用于商业应用的技术,包括Apple iPhone中的Siri语音识别,Google文本翻译以及用于自动驾驶汽车的Mobileye视觉技术。
深度神经网络成功的关键原因之一是它们能够通过局部统计来利用数据的统计特性,例如平稳性和合成性,这些能力存在于自然图像,视频和语音中[14],[15]。这些统计特性已经与物理学有关[16],并在卷积神经网络(CNN)的特定类别中正式化[17],[18],[19]。在图像分析应用程序中,可以将图像视为在欧氏空间(平面)上以网格采样的函数。在这种情况下,平稳性归因于平移不变性,局部性归因于局部连通性,而合成性则归因于网格的多分辨率结构。这些特性被卷积体系结构[20]开发,该体系由交替的卷积层和下采样(池化)层构成。卷积的使用具有双重效果。首先,它允许提取在整个图像域中共享的局部特征,并相对于通用深度架构大大减少了网络中的参数数量(从而也减少了过拟合的风险),而不会牺牲网络的表达能力。其次,卷积架构本身对数据施加了一些先验,这些先验显得特别适合于自然图像[21],[18],[17],[19]。
虽然深度学习模型在处理诸如语音,图像或视频之类的信号时特别成功,但其中存在潜在的欧几里得结构,但近来人们对尝试将学习应用于非欧几里得几何数据的兴趣日益浓厚。这类数据出现在众多应用中。例如,在社交网络中,可以将用户的特征建模为社交图的顶点上的信号[22]。传感器网络是分布式互连传感器的图形模型,其读数被建模为顶点上与时间相关的信号。在遗传学中,基因表达数据被建模为在监管网络中定义的信号[23]。在神经科学中,图模型用于表示大脑的解剖结构和功能结构。在计算机图形和视觉中,将3D对象建模为具有诸如颜色纹理之类的特性的黎曼流形(表面)。
这种数据的非欧几里德性质意味着不存在诸如全局参数化,通用坐标系,向量空间结构或平移不变性这样熟悉的属性。因此,在非欧几里得域上甚至没有很好地定义在欧几里得情况下理所当然的诸如卷积之类的基本运算。本文的目的是展示将成功的深度学习方法(例如卷积神经网络)的关键要素转换为非欧几里得数据的不同方法.
2.几何学习问题
广义上讲,我们可以区分两类几何学习问题。在第一类问题中,目标是表征数据的结构。第二类问题涉及分析在给定非欧氏域上定义的函数。这两个类是相关的,因为理解域上定义的功能的属性会传达有关该域的某些信息,反之亦然,因此域的结构会将某些属性强加于该域上的功能。
域的结构:作为第一类问题的示例,假定给定一组数据点,这些数据点具有一些嵌入到高维欧几里德空间中的底层低维结构。恢复较低维度的结构通常被称为流形学习或非线性降维,这是无监督学习的一个实例。减少非线性的维数的许多方法包括两个步骤:首先,它们从构造数据点的局部亲和力表示(通常是稀疏连接的图)开始。第二,将数据点嵌入到低维空间中,以保留原始亲和力的某些标准。例如,频谱嵌入倾向于将点之间具有许多连接的点映射到附近的位置,并且MDS类型的方法尝试保留全局信息,例如图形测地距离。流形学习的例子包括不同类型的多维缩放(MDS)[26],局部线性嵌入(LLE)[27],随机邻居嵌入(t-SNE)[28],频谱嵌入(例如拉普拉斯特征图[29])和扩散 地图[30]和深层模型[31]。最近的方法[32],[33],[34]尝试将成功的词嵌入模型[35]应用于图。除了嵌入顶点外,还可以通过将图结构分解为称为子图[36]或小图[37]的小子图来对其进行处理。
在某些情况下,数据在一开始就以流形或图形表示,而构建上述亲和结构的第一步是不必要的。例如,在计算机图形和视觉应用中,可以通过构造捕获例如图像的局部几何描述符来分析表示为网格的3D形状。弯曲特性[38],[39]。在诸如计算社会学之类的网络分析应用中,代表人与人之间社会关系的社会图的拓扑结构具有重要的见解,例如,可以对顶点进行分类并检测社区[40]。在自然语言处理中,语料库中的单词可以用共现图表示,如果两个单词经常出现在彼此附近,则可以将它们连接起来[41]。
域中的数据:我们的第二类问题涉及分析在给定的非欧氏域上定义的函数。我们可以将此类问题进一步细分为两个子类:域固定的问题和给出多个域的问题。例如,假设给定了社交网络用户的地理坐标,在社交图的顶点上表示为时间相关的信号。基于位置的社交网络中的一个重要应用是根据用户的过去和朋友的行为来预测用户的位置[42]。在此问题中,假定域(社会图)是固定的; 特别是,为了定义类似于谱域中卷积的运算,可以在此设置中应用先前已在该杂志[43]中进行过回顾的图形信号处理方法。反过来,这又允许将CNN模型泛化为图表[44],[45]。
简史:这篇综述的主要重点是第二类问题(在给定非欧氏域上定义的函数),即非欧氏结构域上的学习功能,尤其是尝试将流行的CNN推广到此类设置。最初尝试将神经网络推广到我们知道的图形是由于Scarselli等人。[49],他提出了一种结合递归神经网络和随机游走模型的方案。这种方法几乎没有引起注意,由于近来对深度学习的新兴趣,在[50],[51]中以现代形式重新出现。图上CNN的第一个公式应归功于Bruna等人。[52],他们在谱域中使用了卷积的定义。他们的论文虽然具有概念上的重要性,但存在严重的计算缺陷,没有真正有用的方法。这些缺点随后在Henaff等人的后续工作中得到了解决。[44]和Defferrard等[45]。
在计算机视觉和图形社区的平行努力中,Masci等人。[47]显示了在网状表面上的第一个CNN模型,诉诸于基于局部内在斑块的卷积运算的空间定义。在其他应用程序中,此类模型在寻找可变形3D形状之间的对应关系方面表现出了最先进的性能。后续工作提出了在点云[53],[48]和一般图[54]上构建不同内在斑块的方法。
在过去的一年中,对图或流形上的深度学习的兴趣激增,导致了许多尝试将这些方法应用于从生物化学[55]到推荐系统[56]的广泛问题。由于此类应用程序起源于通常不会交叉使用的不同领域,因此该领域的出版物倾向于使用不同的术语和符号,这使得新手很难掌握其基础和当前的最新技术。我们相信我们的论文是在正确的时间尝试将系统化并带入领域的。
本论文结构:我们将在第三节中概述传统的欧几里得深度学习,总结关于数据的重要假设,以及它们是如何在卷积网络架构中实现的.
在第四节中转到非欧几里德世界,然后我们定义了微分几何和图论中的基本概念。这些主题在信号处理社区中还不够为人所知,据我们所知,没有入门级的参考文献以常见的方式处理这些如此不同的结构。我们的目标之一是尽可能地依靠传统信号处理的直觉来提供这些模型的可访问概述。
在第五至第八节中,我们概述了主要的几何深度学习范例,强调了欧几里德学习方法与非欧几里德学习方法之间的相似之处和不同之处。这些方法之间的主要区别在于在图形和流形上形成类似卷积运算的方式。一种方法是诉诸卷积定理的类比,在谱域中定义卷积。另一种选择是将卷积视为在空间域中匹配的模板。但是,这种区别远非一个明确的定义:正如我们将看到的那样,某些方法虽然从光谱域中得出其公式,但实际上归结为在空间域中应用滤镜。也可以将这两种方法结合起来,采用时空分析技术,例如小波或开窗傅立叶变换。
在第九节中,我们展示了从网络分析,粒子物理学,推荐系统,计算机视觉和图形学领域中选择的问题的示例。在第十节中,我们得出了结论,并概述了几何深度学习中当前的主要挑战和潜在的未来研究方向。为了使本文更具可读性,我们使用插页来说明重要概念。最后,邀请读者访问专门的网站geometricdeeplearning.com,以获取其他材料,数据和代码示例。
3.欧几里得域的深度学习
几何先验:考虑一个紧凑的d维欧氏域Ω= [0,1]d⊂Rdon,其中定义了平方可积分函数f∈L2(Ω)(例如,在图像分析应用中,可以将图像视为单位平方Ω上的函数)= [0,1] 2)。我们考虑一个通用的监督学习设置,其中在训练集上观察到未知函数y:L2(Ω)→Y。

在监督分类设置中,目标空间Y可以被认为是离散的,|Y|是类的数量。在多目标识别环境中,可以用k维单纯形代替Y, k维单纯形表示后验类概率p(Y |x)。在回归任务中,我们可以考虑Y = Rm(m在R的右上角)。
在绝大多数计算机视觉和语音分析任务中,对未知函数y有几个关键的先验假设。正如我们将在下文中看到的那样,卷积神经网络体系结构有效地利用了这些假设。为了更深入地了解CNNs及其应用,我们建议读者参考[12]、[1]、[13]及其参考文献。

平稳性公式:
![]()
是作用于函数f∈L2(Ω)的翻译算子。我们的第一个假设是,根据任务,函数y对于翻译而言是不变的还是相等的。在前一种情况下,对于任何f∈L2(Ω)和v∈Ω,我们的y(Tvf)= y(f)。在对象分类任务中通常是这种情况。在后者中,我们有y(Tvf)= Tvy(f),当模型的输出是翻译可以作用于其中的空间时(例如,在对象定位,语义分割或运动估计等问题中),可以很好地定义y(Tvf)=Tvy(f) )。我们对不变性的定义不应与信号处理中翻译不变性系统的传统概念相混淆,后者与我们语言中的平移等方差相对应(因为只要输入转换,输出即会转换)。
局部变形和尺度分离:类似地,当Lτf(x)= f(x-τ(x))时,变形Lτ作用在L2(Ω)上,其中τ:Ω→Ω是光滑的矢量场。变形可以模拟局部平移,视角变化,旋转和频率转换[18]。
计算机视觉中研究的大多数任务不仅具有平移不变/等变的性质,而且对于局部形变[57]、[18]也是稳定的。在平移不变量的任务中,我们有:
![]()
对于所有f,τ。在这里,![]() 措施给定变形场的光滑。换句话说,如果输入图像有轻微的变形,则预测的量变化不大。在翻译等变的任务中,我们有:
措施给定变形场的光滑。换句话说,如果输入图像有轻微的变形,则预测的量变化不大。在翻译等变的任务中,我们有:
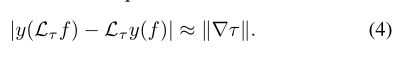
与d维平移组相反,此属性比以前的属性要强得多,因为局部变形的空间具有较高的维数。
从(3)中可以得出,我们可以通过对解调后的局部滤波器响应进行下采样而在较低的空间分辨率下提取足够的统计量,而不会损失逼近能力。这样做的重要后果是,可以将远程依赖项分解为多尺度的局部交互项,从而导致层次模型,其中空间分辨率逐渐降低。为了说明这一原理,用

两个图像像素彼此偏移v的联合分布。在存在长距离依赖关系的情况下,该关节分布对于任何v都是不可分离的。但是,变形稳定性先验表明![]()
![]() .换句话说,尽管远距离依赖性确实存在于自然图像中,并且对于对象识别至关重要,但它们可以以不同的比例进行捕获和下采样。这种对局部变形的稳定性的原理已在计算机视觉社区中的CNN以外的模型中得到了利用,例如,可变形零件模型[58]。
.换句话说,尽管远距离依赖性确实存在于自然图像中,并且对于对象识别至关重要,但它们可以以不同的比例进行捕获和下采样。这种对局部变形的稳定性的原理已在计算机视觉社区中的CNN以外的模型中得到了利用,例如,可变形零件模型[58]。
在实践中,欧几里得域Ω使用常规离散网格与n个点;平移和变形算子仍然定义良好,因此上述性质在离散设置中仍然成立。
CNN(输入p维生成q维):卷积神经网络利用了局部平移的平稳性和稳定性(参见insert IN1)。CNN由几种形式的卷积层g = CΓ(f),作用于p维输入f (x) = (f1 (x)。fp (x))通过一个过滤器![]() 和逐点非线性ξ
和逐点非线性ξ
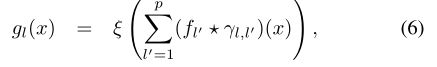
生成q维输出g(x) = (g1(x),…, gq(x))通常被称为特征图。在这里:

表示标准卷积。根据先验的局部变形,滤波器Γ具有紧凑的空间支撑。
此外,可以使用向下采样或池化层g = P(f),定义为
![]()
其中N (x)⊂Ω是x周围的邻域,P是置换不变函数,例如Lp范数(在后一种情况下,选择p = 1,2或∞会得出平均值,能量,或最大池)。
卷积网络是由几个卷积层和可选的池化层组成,得到一个通用的层次表示
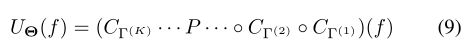
其中Θ= {Γ(1),。。。,Γ(K)}是网络参数(所有滤波器系数)的超向量。如果该模型包含多个层,则该模型被认为是深层的,尽管这一概念相当模糊,并且可以找到少至两层,多达数百个层的CNN示例[11]。输出特征享有平移不变性/协方差,具体取决于空间分辨率是通过合并逐渐丢失还是保持不变。此外,如果将卷积张量指定为复数小波分解算子,并使用复数模量作为点状非线性,则可以证明对局部变形具有稳定性[17]。尽管没有为通用的紧凑支持卷积张量严格证明这种稳定性,但它为CNN架构在各种计算机视觉应用中的经验成功奠定了基础[1]。
在监督学习任务中,通过最小化训练集{fi, yi}i∈i上的任务特定成本L,可以得到CNN参数
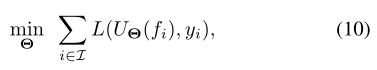
例如,L(x,y)= ||x-y||。如果模型足够复杂,并且训练集具有足够的代表性,则将学习的模型应用于以前看不见的数据时,可以期望U(f)≈y(f)。尽管(10)是一个非凸优化问题,但是随机优化方法提供了出色的经验性能。了解优化问题的结构(10)并找到有效的解决方案是深度学习的一个活跃领域[62],[63],[64],[65],[66]。
CNNs在许多任务中成功的一个关键优势是,CNNs所基于的几何先验导致了避免维数诅咒的学习复杂性(avoids the curse of dimensionality.)。由于平稳性和局部变形先验,每一层的线性算子的参数个数是常数,与输入尺寸n(图像中的像素个数)无关。此外,由于多尺度层次属性,层的数量以O(logn)的速度增长,导致O(logn)参数的总体学习复杂性。
4.流行和图的几何形状(流形完全没看明白)
我们的主要目标是将CNN类型的结构推广到非欧几里得域。在本文中,通过非欧几里德域,我们指的是两个原型结构:流形和图形。尽管这些结构出现在非常不同的数学领域(分别是微分几何和图论),但在我们的上下文中,这些结构具有几个共同的特征,我们将在整个审查过程中着重强调这些特征。
【IN1】CNN:CNN目前在各种任务中,尤其是在计算机视觉中,是最成功的深度学习架构之一。计算机视觉应用中使用的典型CNN(参见图1)由多个卷积层(6)组成,使输入图像通过一组滤波器Γ,然后是逐点非线性ξ(通常是半整流器ξ(z)= max (0,z)被使用,尽管从业者已经尝试了多种选择[13]。该模型还可以包括一个偏差项,该偏差项等同于向输入添加一个恒定坐标。由K个卷积层组成的网络将U(f)=(CΓ(K)...◦CΓ(2)◦CΓ(1))(f)放在一起,生成像素协方差w.r.t。平移和局部变形的近似协变。需要协方差的典型计算机视觉应用是语义图像分割[8]或运动估计[59]。
在需要不变性的应用中,例如图像分类[7],卷积层通常与池化层(8)交错插入,从而逐渐降低通过网络的图像的分辨率。或者,可以将卷积和下采样集成在一个线性算子中(跨步卷积)。最近,一些作者还对卷积层进行了实验,这些卷积层使用插值内核来提高空间分辨率[60]。通过模仿所谓的算法àtrous [61](也称为膨胀卷积)可以有效地学习这些内核。
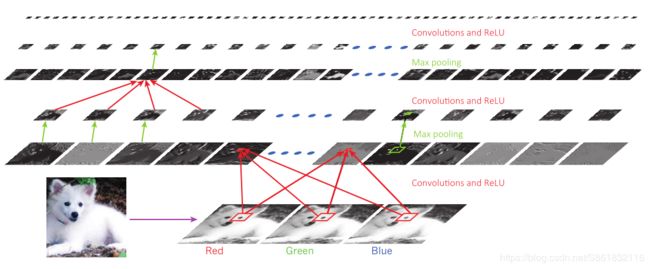 图1.计算机视觉应用中典型的卷积神经网络结构(图来自[1])。
图1.计算机视觉应用中典型的卷积神经网络结构(图来自[1])。
流形: 粗略地说,流形就是局部欧几里德空间。一个最简单的例子就是地球的球面模型:围绕着一个点,它似乎是平面的,这使几代人相信地球是平的。正式地说,(可微分的)d维流形X是一个拓扑空间,其中每个点X都有一个与d维欧氏空间拓扑等价(同态)的邻域,称为切线空间,用TxX表示(见图1,上图)。切线空间的集合点(更正式,不相交的联盟)被称为切丛和用TX。每个切线空间上,我们定义一个内积h··iTxX: TxX×TxX→R,这是另外假定顺利取决于位置x。这被称为内积微分几何和黎曼度量允许执行本地测量角度、距离和卷。带有度量的流形叫做黎曼流形。
重要的是要注意,黎曼流形的定义是完全抽象的,不需要任何空间的几何实现。然而,通过利用欧几里德空间的结构来诱发黎曼度量,可以将黎曼流形实现为欧几里德空间的子集(在这种情况下,据说它被嵌入到该空间中)。著名的纳什嵌入定理保证了在足够高尺寸的欧几里得空间中可以实现任何足够光滑的黎曼流形[67]。嵌入不一定是唯一的。黎曼度量的两种不同实现称为等距。
嵌入到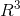 中的二维流形(表面)用于计算机图形和视觉中,以描述3D对象的边界表面,俗称“ 3D形状”。这个术语有点误导,因为此处的“ 3D”是指嵌入空间的尺寸,而不是流形的尺寸。考虑到这种形状由无限薄的材料制成,不会拉伸或撕裂的非弹性变形是等轴测的。等距同构不影响流形的度量结构,因此,保留可以用黎曼度量(称为内在度量)表示的任何数量。相反,与欧氏空间中流形的具体实现有关的特性称为外在特性。
中的二维流形(表面)用于计算机图形和视觉中,以描述3D对象的边界表面,俗称“ 3D形状”。这个术语有点误导,因为此处的“ 3D”是指嵌入空间的尺寸,而不是流形的尺寸。考虑到这种形状由无限薄的材料制成,不会拉伸或撕裂的非弹性变形是等轴测的。等距同构不影响流形的度量结构,因此,保留可以用黎曼度量(称为内在度量)表示的任何数量。相反,与欧氏空间中流形的具体实现有关的特性称为外在特性。
作为这种差异的直观说明,请想象一个生活在二维平面上的昆虫(图1,底部)。另一方面,人类观察者在三维空间中看到一个表面——这是一个外在的观点。
 图1.顶部:二维流形(表面)上的切空间和切向量。底部:等距变形的例子
图1.顶部:二维流形(表面)上的切空间和切向量。底部:等距变形的例子
流形上的微积分:我们的下一步是考虑在流形上定义的功能。我们对两种类型的函数特别感兴趣:标量场是流形上的光滑实函数f:X→R。切向量F:X→TX是将切向量F(x)∈TxX附加到每个点x的映射。正如我们将在下文中看到的那样,切向量场用于形式化流形上无穷小位移的概念。我们定义流形上标量场和矢量场的希尔伯特空间,分别用L2(X)和L2(TX)表示,并具有以下内积

这里dx表示由黎曼度量导出的d维体积元。
在微积分中,导数的概念描述了函数的值如何随其参数的微小变化而变化。将经典微积分与微分几何区分开的最大差异之一是流形上缺少向量空间结构,这使我们无法单纯使用f(x + dx)这样的表达式。将这些概念推广到流形所需的概念上的飞跃是需要在切线空间中局部工作。
为此,我们将f的微分定义为运算符d f:TX→R作用于切向量场。在每个点x处,可以将微分定义为线性函数(1-形式)df(x)=h∇f(x),·iTxX作用于切向量F(x)∈TxX,该模型对围绕x的小位移进行建模。通过将该形式应用于切向量df(x)F(x)=h∇f(x),F(x)iTxX,可以得出函数值随位移的变化。作为经典方向导数概念的扩展。
上面定义中的运算符∇f:L2(X)→L2(TX)被称为固有梯度,它与梯度的经典概念相似,后者定义了函数在某个点上最陡峭的变化方向。唯一不同的是,方向现在是切向量。类似地,内在散度是一个运算符div:L2(TX)→L2(X)作用于切向量场,并且(正式)与梯度运算符[71]相邻,
![]()
从物理上讲,切向量场可以看作是流形上的材料流。差异测量一个点的净流,从而可以区分“源”和“汇”。最后,拉普拉斯算子(或微分几何术语中的Laplace-Beltrami算子)∆: (X)→(X)是算子
(X)→(X)是算子

作用于标量场。利用关系(17),很容易看出拉普拉斯是自伴随的(对称的),
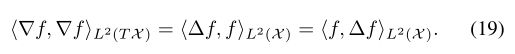
公式(19)中的lhs在物理学上被称为Dirichlet能量,它测量流形上标量场的平滑度(请参见插入IN3)。拉普拉斯算子可以解释为一个点周围无穷小球面上的函数平均值与该点本身的函数值之差。它是数学物理学中最重要的运算符之一,用于描述各种现象,例如热扩散(请参见插入IN4),量子力学和波传播。正如我们将在下文中看到的那样,拉普拉斯算子在非欧氏域的信号处理和学习中起着中心作用,因为其本征函数泛化了经典的傅立叶基础,从而可以对流形和图形进行频谱分析。
重要的是要注意,以上所有定义都是无坐标的。通过定义切线空间中的基数,可以将切线向量表示为d维向量,而黎曼度量表示为d×d个对称正定矩阵。
图和离散微分算子:我们感兴趣的另一种构造类型是图,它们是网络,交互作用以及不同对象之间的相似性的流行模型。为简单起见,我们将考虑加权无向图,它们被正式定义为一对(V,E),其中V = {1,...。。。,n}是n个顶点的集合,而E⊆V×V是边的集合,其中无向图意味着(i,j)∈E iff(j,i)∈E。此外,我们关联a每个顶点i∈V的权重ai> 0,每个边缘(i,j)∈E的权重wij≥0。
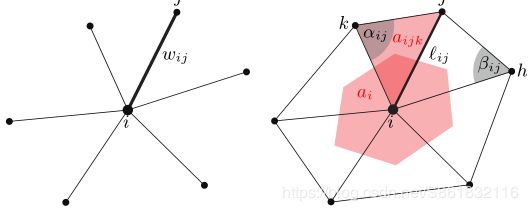 无向图(左)和三角网(右)
无向图(左)和三角网(右)
图2.二维流形的两种常用离散化:图形和三角形网格。
[IN2]离散流形上的拉普拉斯变换:在计算机图形学和视觉应用中,二维流形通常用于三维形状的建模。离散这样的流形有几种常用的方法。首先,假设流形在n个点上采样。它们的嵌入坐标为x1,…,xn被称为点云。第二,一个图是建立在这些点上,作为它的顶点。图的边表示流形的局部连通性,表示两个点是否属于一个邻域,例如,用高斯权边表示
![]()
然而,这种最简单的离散化不能正确地捕获下面的连续流形的几何形状(例如,随着采样密度的增加,图拉普拉斯算子通常不会收敛到流形的连续拉普拉斯算子[68])。曲面F∈V×V×V的附加结构可以实现几何上一致的离散化,其中(i,j,k)∈F表示(i,j),(i,k),(k,j)∈E。面的集合将下面的连续流形表示为一个由粘贴在一起的小三角形组成的多面体表面。三元组(V,E,F)称为三角形网格。为了使流形(流形网格)正确离散,每个边都必须正好由两个三角形面共享。如果流形具有边界,则任何边界边都必须恰好属于一个三角形。
在三角形网格上,通过为每个边分配一个长度![]() 来给出黎曼度量的最简单离散化,该长度必须另外满足每个三角形面中的三角形不等式。网格拉普拉斯算子由公式(25)给出
来给出黎曼度量的最简单离散化,该长度必须另外满足每个三角形面中的三角形不等式。网格拉普拉斯算子由公式(25)给出
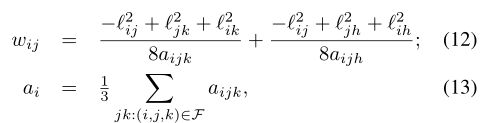
其中![]() 是Heron公式给出的三角形ijk的面积,而
是Heron公式给出的三角形ijk的面积,而![]() 是三角形ijk的半周长。顶点权重可以解释为局部区域元素(在图2中以红色显示)。请注意,权重(12-13)仅用离散量度
是三角形ijk的半周长。顶点权重可以解释为局部区域元素(在图2中以红色显示)。请注意,权重(12-13)仅用离散量度![]() 表示,因此是固有的。当在某些技术条件下对网格进行无限细化时,可以证明这种构造收敛于底层歧管的连续拉普拉斯算子[69]。
表示,因此是固有的。当在某些技术条件下对网格进行无限细化时,可以证明这种构造收敛于底层歧管的连续拉普拉斯算子[69]。
网格的嵌入(相当于指定顶点坐标x1,...,xn)会引起离散量度'ij = ||xi- xj||2,从而(12)成为余切权重广泛应用于计算机图形学[70]。
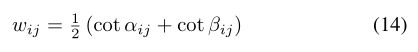
图的顶点和边上的实函数f:V→R和F:E→R分别是微分几何中连续标量和切向量场的离散类比4(右上标).我们可以定义希尔伯特空间L2(V)和通过指定各个内部乘积,使此类函数的L2(E),

![]() 分别是图的顶点和边。我们可以将作用于这些函数的微分算子类似于作用于流形上的微分算子[72]。图像梯度算子∇:L2 (V)→L2 (E)顶点映射函数定义在函数上定义的边缘,
分别是图的顶点和边。我们可以将作用于这些函数的微分算子类似于作用于流形上的微分算子[72]。图像梯度算子∇:L2 (V)→L2 (E)顶点映射函数定义在函数上定义的边缘,
![]()
自动满足![]() 。图的散度是一个算子div: L2(E)→L2(V)反过来
。图的散度是一个算子div: L2(E)→L2(V)反过来

很容易证明这两个算子是伴随w.r.t的内积(20)- (21),
![]()
图拉普拉斯算子是一个操作符∆:L2 (V)→L2 (V)定义为∆=−div∇。结合定义(22)-(23),可以表示为熟悉的形式

请注意,公式(25)捕获了拉普拉斯算子的直观几何解释,即点周围函数的局部平均值与该点本身处的函数值之差。
用W = (wij)表示边权值的n×n矩阵(假设wij= 0 if (i, j) /∈E),由A = diag(a1,…(a)顶点权值的对角矩阵,并由D = diag(P j:j6=iwij)度矩阵,将图拉普拉斯变换应用于函数f∈L2(V)表示为列向量f = (f1,…, fn)>可以写成矩阵向量形式

(26)中A = I的选择称为未归一化图拉普拉斯算子;另一个流行的选择是A = D产生随机游走拉普拉斯算子[73]。
离散流形:正如我们所提到的,在许多实际情况下,采样点是由流形产生的,而不是流形本身。在计算机图形应用中,从点云重建流形的正确离散化是其自身的难题,称为网格划分(请参见插入IN2)。在流形学习问题中,流形通常近似为捕获局部亲和力结构的图。我们警告读者,在通用数据科学的上下文中使用的“流形”一词在几何上并不严格,并且其结构比我们之前定义的经典平滑流形要少。例如,在实践中“局部看似欧几里得”的一组点可能具有自相交,无限曲率,不同的尺寸,这取决于一个人所看的比例尺和位置,密度的极端变化以及具有混杂结构的“噪声”。
非欧几里德域的傅里叶分析:拉普拉斯算符是自伴的半正定的运营商,承认在一个紧凑的域本征分解与一组离散的标准正交特征函数φ0φ1,。(满足hφiφjiL2 (X) =δij)和非负实特征值0 =λ0≤λ1≤.....。(称为拉普拉斯谱),
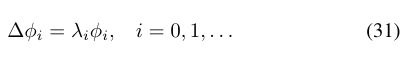
本征函数在Dirichlet能量的意义上是最平滑的函数(请参见插入IN3),并且可以解释为标准傅立叶基础的泛化(实际上由一维欧几里得拉普拉斯算子的本征函数给出,![]() )到非欧几里德域。必须强调的是,由于拉普拉斯算子本身的内在构造,所以拉普拉斯算子本征是固有的。
)到非欧几里德域。必须强调的是,由于拉普拉斯算子本身的内在构造,所以拉普拉斯算子本征是固有的。
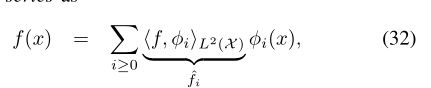
其中基于基函数的投影产生离散的傅立叶系数(![]() )集概括了经典信号处理中的分析(正向变换)阶段,将这些系数与基函数相加就是合成(逆变换)阶段。
)集概括了经典信号处理中的分析(正向变换)阶段,将这些系数与基函数相加就是合成(逆变换)阶段。
经典欧几里德信号处理的核心是对角化卷积算符的傅立叶变换的特性,俗称卷积定理。此属性可以将两个函数在谱域中的卷积f* g表示为其傅里叶变换的逐元素乘积,
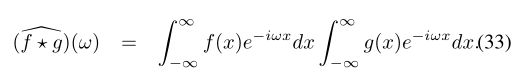
不幸的是,在非欧几里得的情况下,我们甚至无法在流形或图形上定义操作x-x0,因此卷积(7)的概念并没有直接扩展到这种情况。
将卷积推广到非欧几里德域的一种可能性是使用卷积定理作为定义,
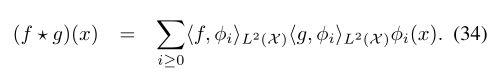
这种构造与经典卷积的主要区别之一是缺乏平移不变性。就信号处理而言,它可以解释为位置相关的滤波器。尽管在频域中由固定数量的系数参数化,但是滤波器的空间表示可以在不同点上发生巨大变化(参见图4)。
上面的讨论也适用于图而不是流形,其中仅需用离散的一个(20)替换方程式(32)和(34)中的内积。由于图拉普拉斯算子∆具有n个特征向量,因此i上的所有和都将变为有限。用矩阵矢量表示法,广义卷积f※g可以表示为Gf =Φdiag(ˆ g)Φ> f,其中ˆ g =(ˆ g1,...,ˆ gn)是滤波器的频谱表示,而Φ=(φ1,...,φn)表示拉普拉斯特征向量(30)。位移不变性的缺乏导致矩阵G中没有循环性(Toeplitz)结构,这是欧几里得设定的特征。此外,很容易看出卷积运算与Laplacian交换,G∆f = ∆Gf
唯一性和稳定性:最后,需要注意的是拉普拉斯特征函数不是唯一定义的。首先,它们被定义为符号。∆(±φ)=λ(±φ)。因此,甚至等距域也可能具有不同的拉普拉斯本征函数。此外,如果一个拉普拉斯特征值具有多重性,那么相关的特征函数可以被定义为生成相应的特征子空间的正交基(或者换句话说,特征函数被定义为特征子空间中的正交变换)。域的一个小扰动可以导致拉普拉斯特征向量的非常大的变化,特别是那些与高频相关的特征向量。与此同时,热内核(36)和扩散距离(38)的定义不存在这些歧义——例如,当特征函数平方时,符号歧义消失。热内核对域扰动也表现出较强的鲁棒性。
【IN3】拉普拉斯特征函数的物理解释:
给定域X上的函数f,狄利克雷能量
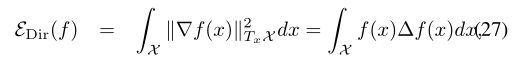
衡量它的平滑程度((27)中的最后一个标识源自(19))。我们正在通过解决优化问题,在X上寻找包含k个最平滑函数的正交基(图3)。
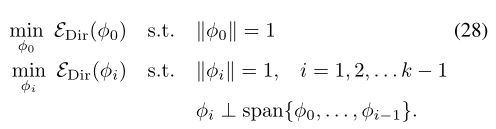
在离散情况下,当在n个点上对域进行采样时,问题(28)可以重写为

Φk =(φ0...φk−1)。(29)的解由∆满足的前k个特征向量给出
![]()
其中,Λk = diag(λ0,...,λk-1)是对应特征值的对角矩阵。特征值0 =λ0≤λ1≤...由于Laplacian的正半确定性,λk-1是非负的,可以解释为“频率”,其中φ0=常数,对应的特征值λ0= 0起DC的作用。
拉普拉斯特征分解可以通过两种方式进行。首先,方程(30)可以改写为广义特征问题(D-W)Φk=AΦkΛk,从而产生A正交特征向量Φ>kAΦk=I。或者,引入变量Ψk= A1 /2Φk的变化,我们可以求出标准特征分解问题A-1 / 2(D-W)A-1 /2Ψk=ΨkΛk,正交特征向量Ψ>kΨk=I。当使用A = D时,矩阵∆ = A-1 / 2(D − WA-1 / 2被称为归一化对称拉普拉斯算子。

图3.前四个拉普拉斯特征函数的示例φ1...φ3在欧几里德域(1D线,左上)和非欧几里德域(以2D流形建模的人形,右上;明尼苏达州路线图,下)。在欧几里得的情况下,结果是包含频率增加的正弦曲线的标准傅立叶基础。在所有情况下,与零本征值相对应的本征函数φ0为常数(“ DC”)。
5.谱方法
现在,我们终于达到了我们的主要目标,即在非欧几里得域上构建CNN体系结构的概括。我们将从一个假设出发,即我们正在工作的域是固定的,在本节的其余部分中,将使用固定图中信号的分类问题作为原型应用。
我们已经看到,卷积是与拉普拉斯算子相通的线性算子。因此,给定加权图,概括卷积体系结构的第一个途径是首先将我们的兴趣限制在与图拉普拉斯算子相通的线性算子上。反过来,此属性意味着对图权重的频谱进行操作,该权重由图拉普拉斯算子的特征向量给出。
光谱CNN(SCNN):与经典的欧几里得CNN的卷积层(6)相似,Bruna等人。[52]将频谱卷积层定义为
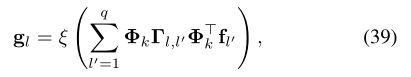
其中n×p和n×q矩阵F =(f1,...,fp)和G =(g1,...,gq)表示在其顶点上的p维和q维输入和输出信号。图(分别用n = | V |表示图中的顶点数),Γl,l0是表示频谱乘法器的ak×k对角矩阵,表示频域中的滤波器,ξ是施加在该图上的非线性顶点函数值。仅使用(39)中的前k个特征向量设置截止频率,该频率取决于图的固有规律性以及样本大小。通常,k《n,因为实际上仅描述图的平滑结构的第一拉普拉斯特征向量是有用的。
如果图具有一个基本组不变性,那么这样的构造可以发现它。特别是,标准CNNs可以从光谱域重新定义(参见insert In 5)。然而,在许多情况下,图没有组结构,或者组结构不与Laplacian交换,因此我们不能认为每个过滤器都是在V中传递一个模板并记录模板与该位置的相关性。
【IN4】非欧氏域上的热扩散:频谱分析的一个重要应用,以及历史上约瑟夫·傅里叶(Joseph Fourier)进行分析的主要动力,是偏微分方程(PDE)的求解。特别地,我们对非欧几里德域上的热传播感兴趣。这个过程由热扩散方程控制,在最简单的均质和各向同性扩散条件下,其形式为

如果域有边界,则使用附加边界条件。f(x, t)表示t时刻x点处的温度。式(35)采用牛顿冷却定律,根据该定律,物体的温度变化率(lhs)与自身温度与周围环境的温度变化率(rhs)成正比。比例系数c为热扩散系数;这里,为了简单起见,我们假设它等于1。(35)的解是通过对初始条件施加热算子Ht= e−t∆,可以在谱域中表示为

ht(x,x0)被称为热核,代表初始条件为f0(x)=δx0(x)或以信号处理术语为“脉冲响应”的热方程的解。从物理上讲,ht(x,x0)描述了在时间t内从点x到点x0流动了多少热量。在欧几里得的情况下,热核是位移不变的,ht(x,x0)= ht(x − x0),从而可以将(36)中的积分解释为卷积f(x,t)=(f0?ht )(X)。在频谱域中,与热核的卷积等于具有频率响应e-tλ的低通滤波。较大的扩散时间t值会导致较低的有效截止频率,从而导致空间中的解更平滑(对应于这样的直觉,即扩散时间越长,初始热分布越平滑)。
位于点x和x丿的两个热核之间的“串扰”允许测量固有距离.

称为扩散距离[30]。注意,将(37)和(38)分别解释为空间和频域范数k·kL2(X)和k·k’2,它们的等价性是Parseval恒等式的结果。与测量流形或图上最短路径长度的测地线距离不同,扩散距离对不同路径有平均效果。因此,它对域的扰动更健壮,例如图中边缘的引入或移除,或流形上的“切割”。
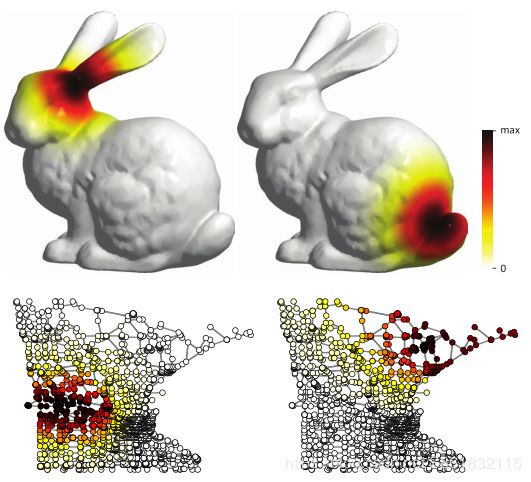
图4.热核在非欧几里德域上的例子(廖,顶;和图,底部)。观察移动热核到不同的位置如何改变它的形状,这是缺乏移位不变性的一个迹象。
我们应该强调谱结构的一个基本限制是它局限于一个单一的域。其原因是光谱滤波系数(39)是基相关的。这意味着如果我们学习一个过滤器w.r.t.Φkon一个域,然后试着把它应用在另一个领域与另一个Ψk基础,结果可能是非常不同(见图2和插入IN6)。通过联合对角化过程可以构建跨越不同域的兼容正交基[74],[75]。但是,这样的构造需要了解域之间的一些对应关系。例如,在社会网络分析等应用程序中,处理一个社会图的两个时间实例,其中添加了新的顶点和边,这样的对应关系很容易计算,因此是一个合理的假设。相反,在计算机图形学应用中,寻找形状之间的对应关系本身就是一个非常困难的问题,因此,假设已知的领域之间的对应关系是一个相当不合理的假设。

一个简单的例子说明了在非欧几里德域上泛化光谱滤波的困难。左:定义在流形上的函数(函数值用颜色表示);中:边缘检测滤波器在频域的应用结果;右:相同的滤波器应用在相同的函数上,但是在不同的(近等距)域上产生的结果完全不同。这种行为的原因是傅里叶基是依赖于域的,在一个域上学习的滤波系数不能直接应用于另一个域。
假设保留了Laplacian的k = O(n)个特征向量,则卷积层(39)需要pqk = O(n)个参数进行训练。接下来,我们将看到如何将图的全局和局部规则性结合起来以产生具有恒定数量参数的层(即,使得每层可学习参数的数量不取决于输入的大小),即经典欧几里得CNN中的例子。
池化的非欧几里得比是图粗化,(池是图粗化的非欧几里得的类比,)其中仅保留了图顶点的分数α<1。图拉普拉斯图在两个不同分辨率下的特征向量通过以下多重网格属性进行关联:Φ,〜Φ分别表示原始图和粗化图的拉普拉斯特征向量的n×n和αn×αn矩阵。然后,

其中P是一个αn×n二进制矩阵,其第i行编码原始图上粗图的第i个顶点的位置。因此,可以通过仅保留频谱的低频分量,使用频谱构造来概括跨步卷积。此属性还允许我们将(通过插值法)空间构造中较深层的局部滤波器解释为低频。但是,由于在(39)中将非线性应用于空间域,因此实际上必须在每个分辨率下重新计算图拉普拉斯特征向量,并在每个合并步骤之后直接应用它们。
频谱构造(39)为图拉普拉斯算子的每个特征向量分配自由度。在大多数图中,单个高频特征向量变得高度不稳定。但是,类似于欧几里得域中的小波构造,通过在每个八度音程中适当地分组高频特征向量,可以恢复有意义且稳定的信息。正如我们接下来将要看到的,该原理还带来了更好的学习复杂性。
具有平滑频谱倍增器的频谱CNN【52.54】:为了减少过度拟合的风险,调整学习复杂度以减少模型的自由参数数量非常重要。在欧几里德域上,这是通过学习具有较小空间支持的卷积核来实现的,这使模型能够学习许多与输入大小无关的参数。为了在频谱域中实现类似的学习复杂性,因此有必要将频谱乘法器的类别限制为与局部滤波器相对应的类别。
为此,我们必须在频域中表达滤波器的空间定位。在欧几里得的情况下,频域中的平滑度对应于空间衰减,因为

凭借Parseval身份。这表明,为了学习一层不仅可以跨位置共享特征而且可以在原始域中很好地定位的图层,可以学习平滑的频谱乘数。可以通过仅学习一组二次采样的倍频器并使用插值内核来获取余数(例如三次样条)来规定平滑度。
但是,平滑度的概念在光谱域中也需要一些几何形状。在欧几里得环境中,这种几何形状自然是由频率的概念引起的。例如,在平面上,两个傅立叶原子eiω> x和eiω0> x之间的相似度可以通过距离kω-ω0k来量化,其中x表示二维平面坐标,ω是二维频率向量。在图上,这种关系可以通过对偶图来定义,该图具有权重〜wijencoding两个特征向量φiandφj之间的相似度。
一个特别简单的选择包括选择一维排列,该排列是通过根据特征值对特征向量进行排序而获得的。6在这种情况下,频谱乘数的参数设置为
![]()
其中B =(bij)=(βj(λi))是k×q固定内插核(例如,βj(λ)可以是三次样条),α是q内插系数的向量。为了获得具有恒定空间支持(即与输入大小n无关)的滤波器,应在频谱域中选择一个采样步长γ〜n,这将导致常数nγ-1= O(1)的系数每个滤波器α1,l0。因此,通过将频谱层与图粗化相结合,该模型对于大小为n的输入具有O(logn)总可训练参数,从而恢复了与欧几里得网格上的CNN相同的学习复杂性。
即使具有滤波器的这种参数化,频谱CNN(39)仍需要执行向前和向后通过的高计算复杂度,因为它们需要矩阵乘以Φk和Φ> k的昂贵步骤。尽管在欧几里德域上,可以使用FFT类型的算法在O(nlogn)操作中有效地进行这种乘法,但是对于一般的图,这种算法并不存在,复杂度为O(n2)。接下来,我们将看到如何通过避免对拉普拉斯特征向量的显式计算来减轻这种成本。
【IN5】使用相关内核重新发现标准CNN:在数据构成图的情况下,图的边权值(11)的直接选择是数据的协方差。设F为输入数据分布
![]()
是数据协方差矩阵。如果每个点具有相同的方差σii=σ2,则拉普拉斯算子上的对角线运算符只需缩放F的主分量。
在自然图像中,由于其分布近似平稳,因此协方差矩阵具有循环结构σij≈σi-j,因此通过标准离散余弦变换(DCT)对角化。因此,F的主分量大致对应于按频率排序的DCT基向量。此外,自然图像表现出功率谱E | bf(ω)| 2〜|ω| -2,因为附近的像素比远处的像素更相关[14]。结果表明,协方差的主要成分从低频到高频基本上是有序的,这与傅立叶基础的标准组结构一致。当应用于以协方差定义的权重表示为图的自然图像时,频谱CNN构造可恢复标准CNN,而无需任何先验知识[76]。确实,(39)中的线性算子ΦΓl,10Φ>在傅立叶基础上是先前的对角线,因此平移不变,是经典卷积。此外,第六节说明了如何通过丢弃拉普拉斯频谱的最后一部分,合并并最终生成标准CNN来获得空间二次采样。

使用欧几里得RBF内核将像素二维嵌入16×16图像块中。通过使用两个特征之间的协方差σijas欧几里德距离,按照(11)的方式构造RBF内核。使用结果图拉普拉斯算子的前两个特征向量将像素嵌入2D空间中。左右图中的颜色分别代表像素的水平和垂直坐标。像素的空间排列可从相关测量中大致恢复.
6.无谱方法
拉普拉斯算子的多项式充当特征值的多项式。因此,代替如式(43)那样利用频谱乘法器在频域中明确地进行操作,可以通过多项式展开来表示滤波器。
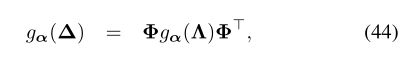
对应于

在此,α是多项式系数的r维向量,并且gα(Λ)= diag(gα(λ1),...,gα(λn)),得出滤波器矩阵![]() 条目在特征值方面具有显式形式。
条目在特征值方面具有显式形式。
此表示的一个重要属性是,由于以下原因,它会自动生成本地化的过滤器。由于拉普拉斯算子是本地运算符(在1跳邻域中工作),因此其j次方的作用仅限于j跳。由于滤波器是拉普拉斯幂的线性组合,因此整体(45)的行为就像扩散算子,限于每个顶点周围的r跳。
图CNN(GCNN)又称ChebNet:Defferrard等。由递归关系生成的Chebyshev多项式
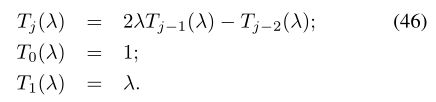
因此,滤波器可以通过阶次r -1的展开唯一地进行参数化,使得
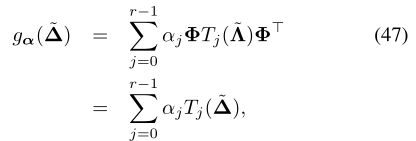
其中![]() 表示拉普拉斯算子的特征值从区间[0,λn]到[-1,1]的重新缩放(自切比雪夫以来是必需的)多项式在[-1,1]中形成正交基础。
表示拉普拉斯算子的特征值从区间[0,λn]到[-1,1]的重新缩放(自切比雪夫以来是必需的)多项式在[-1,1]中形成正交基础。
表示f(j)= Tj(〜Δ)f,我们可以使用递归关系(46)来计算f(j)= 2〜Δ¯f(j-1)-¯f(j-2)f(0)= f,f(1)=〜∆f。因此,此过程的计算复杂度为O(rn)运算,不需要显式计算拉普拉斯特征向量。

GCN【77】:Kipf和Welling通过进一步假设r = 2和λn≈2简化了该结构,从而得到了以下形式的滤波器

进一步限制α=α0=-α1,可以得到由单个参数表示的滤波器,

由于![]() 的特征值现在在[0,2]范围内,因此重复应用此类滤波器会导致数值不稳定。可以通过重新规范化来解决
的特征值现在在[0,2]范围内,因此重复应用此类滤波器会导致数值不稳定。可以通过重新规范化来解决
![]()
![]()
请注意,尽管我们是从光谱域开始的ChebNet和GCN的构造,但归根结底是应用了作用于空间域中图的r或1跳邻域的简单滤波器。我们认为这些构造是更通用的Graph Neural Network(GNN)框架的示例:
GNN【78】:图神经网络概括了通过图权重将过滤操作直接应用于图的概念。与欧几里得CNN将通用滤波器学习为局部,定向带通和低通滤波器的线性组合一样,图神经网络在每一层学习图低通和高通算子的通用线性组合。这些分别由f 7→Wf和f 7→Δf给出,因此由度矩阵D和扩散矩阵W生成。给定图顶点上的p维输入信号,用n×表示在p矩阵F上,GNN考虑了通用非线性函数ηθ:Rp×Rp→Rq,由可训练参数θ参数化,该参数适用于图的所有节点,

特别是,选择η(a,b)= b-a可以恢复拉普拉斯算子∆f,但更普遍的η非线性选择会产生可训练的,针对特定任务的扩散算子。与CNN架构类似,可以堆叠生成的GNN层g =Cθ(f)并将它们与图池化运算符交织。Chebyshev多项式Tr(∆)可以通过(51)的r层获得,原则上可以将ChebNet和GCN视为GNN框架的特定实例。
从历史上看,GNN的版本是在图[49],[78]中提出的基于图的深度学习的第一种形式。这些工作在图形上某些扩散过程(或随机游动)的参数化稳态上进行了优化。这可以用公式(51)来解释,但是要使用大量的层,其中每个Cθ都相同,因为通过Cθ的正向近似于稳态。最近的工作[55],[50],[51],[79],[80]放宽了达到稳态或重复使用相同Cθ的要求。
由于每一层的通信都是顶点邻域的局部通信,因此人们可能会担心要花费很多层才能将信息从图形的一部分传递到另一部分,这需要多次跃点(实际上,这是使用的原因之一)[78]中的稳态)。但是,对于许多应用程序,信息不必完全遍历图形。此外,请注意,网络每一层的图不必相同。因此,我们可以用自己喜欢的输入图的多尺度粗化代替原始的邻域结构,并对其进行操作,以获取与上述卷积网络相同的信息流(或更像是“局部连接的网络” [81]) 。通过将每个图连接到特殊的输出节点,这还允许为整个图形生成单个输出(用于“平移不变”任务),而不是为per-vertex(每个节点?)输出。或者,可以允许η不仅在每个节点上使用Wf和∆f,而且在多个扩散尺度s> 1时也使用Wsf(如[45]中所述),从而使GNN能够学习算法(例如幂方法) ,更直接地访问图的光谱属性。
可以进一步推广GNN模型,以在图上复制其他运算符。例如,逐点非线性η可以取决于顶点类型,从而允许非常丰富的体系结构[55],[50],[51],[79],[80]。
7.基于计费的方法
我们现在考虑非欧几里得学习问题的第二个子类,其中我们有多个域。读者在本节中应该记住的一个典型应用程序是查找形状之间的对应关系,建模为流形(参见insert in 7)。正如我们所看到的,在频域定义卷积有一个固有的缺陷,即不能跨不同的域适应模型。因此,我们将需要在空间域使用卷积的另一种泛化方法,这种方法没有这个缺点。
此外,请注意,在设置多个域时,由于不同域上的点数可以变化,并且其顺序是任意的,因此没有立即定义有意义的空间池操作的方法。但是,可以通过将所有本地信息聚合到单个向量中来合并网络产生的逐点特征。这种合并的一种可能性是计算逐点特征的统计量,例如均值或协方差[47]。注意,在进行这样的合并之后,所有空间信息都将丢失。
在欧几里德域上,由于移位不变性,卷积可以被认为是在域的每个点传递模板,并在该点记录模板与函数的相关性。考虑到图像过滤,这相当于提取一个像素块(通常为正方形),将其逐个元素与模板相乘并求和,然后以滑动窗口的方式移至下一个位置。移位不变性意味着在每个位置提取补丁的操作始终是相同的。
将同一范式应用于非欧几里德域的主要问题之一是缺乏移位不变性,这意味着提取局部“补丁”的“补丁操作员”将依赖于位置。此外,在某些局部固有坐标系中,图形或多种力表示补丁时通常缺乏有意义的全局参数化。这种映射可以通过定义一组权重函数v1(x,·),…来获得。, vJ(x,·)定位到x附近的位置(参见图3中的例子)。

提供卷积内在等价物的空间定义
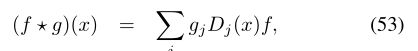
其中g表示应用于每个点提取的补丁的模板系数。总体而言,(52)-(53)充当f的一种非线性滤波,并且通过定义加权函数v1,...来指定面片算子D。。。,vJ。这样的滤波器通过结构定位,并且参数的数量等于加权函数的数量J = O(1)。非欧几里得CNN的几种框架实质上等于这些权重的不同选择。上一节中介绍的无谱方法(ChebNet和GCN)也可以从局部加权函数的角度考虑,因为很容易看到公式(53)和(47)之间的类比。
Geodesic CNN(测地线CNN?)【47】:由于流形自然带有与每个点关联的低维切线空间,因此很自然地在切线空间中的局部坐标系中工作。特别是,在二维流形上,可以创建一个围绕x的坐标极坐标系,其中径向坐标由某个固有距离ρ(x0)= d(x,x0)给出,并且获得了角坐标θ(x)从等距角度的点进行射线拍摄。在这种情况下,加权函数可以作为高斯积的乘积获得.

其中i = 1...J和j = 1...J(上标1)分别表示径向和角箱的索引。所得的JJ(上标1)权重在极坐标中为宽度σρ×σθ的区间(图3,右)。
各向异性CNN【48】:我们已经看到了非欧几里得热方程(35),其热核ht(x,·)在点x周围产生局部的斑点状权重(参见图4)。改变扩散时间t可控制内核的扩散。但是,这样的内核是各向同性的,这意味着热量在所有方向上的流动都一样快。流形上一个更一般的各向异性扩散方程
![]()
涉及热导张量A(x)(在二维流形的情况下,在每个点的切平面上将2×2矩阵应用于本征梯度),从而可以建模与位置和方向相关的热流[82]。[53]中提出的热导张量的特定选择是
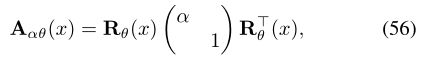
其中2×2矩阵Rθ(x)旋转θw.r.t.相对于某个参考方向(例如最大曲率)的方向,α> 0是控制各向异性程度的参数(α= 1对应于经典的各向同性情况)。这种各向异性扩散方程的热核由光谱扩展给出 .

其中φαθ0(x),φαθ1(x)...是本征函数和λαθ0,λαθ1...各向异性拉普拉斯算子的对应特征值。
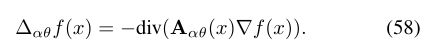
各向异性拉普拉斯算子的离散化是对网格上余切公式(14)或点云上图拉普拉斯算子(11)的修正[48]。
各向异性热核hαθt(x,·)看起来像拉长的旋转斑点(参见图3,中心),其中参数α,θ和t分别控制伸长率,取向和比例。在补丁运算符(52)的构造中使用诸如加权函数v之类的核,可以获得类似于测地补丁的图表(大致,θ起角坐标和径向半径t的作用)。
混合网络模型(MoNet)【54】:最后,作为补丁的最一般的构造,Monti等人。[54]建议在每个点定义一个围绕x的d维伪坐标u(x,x0)的局部系统。在这些坐标上,一组参数内核v1(u)....应用vJ(u)),在(52)中产生加权函数。Monti等人没有像以前的结构那样使用固定内核。而是使用高斯核。
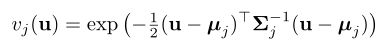
其参数(d×d协方差矩阵Σ1,...,ΣJ和d×1平均矢量µ1,...,μJ)被学习7。不仅学习滤波器,而且学习(53)中的补丁算子也提供了额外的自由度。MoNet架构,这使其成为当前几种应用程序中的最先进方法。还很容易看到这种方法可以概括以前的模型,例如 作为其特定实例,可以获得经典的欧几里得CNN以及测地线和各向异性CNN [54]。MoNet也可以使用一些局部图形特征(例如顶点度,测地距离等)作为伪坐标,应用于一般图形。
 左:传播的距离 中:各向异性热内核 右:测地线极坐标
左:传播的距离 中:各向异性热内核 右:测地线极坐标
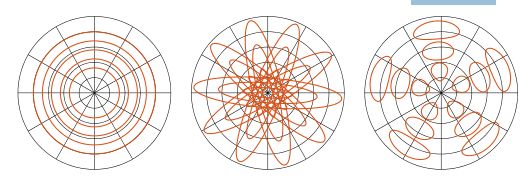
图3.顶部:用于在黑色标记点构造补丁运算符的固有加权函数示例(不同的颜色表示不同的加权函数)。扩散距离(左)允许根据相邻点到参考点的距离来映射它们,从而定义了局部固有坐标的一维系统。不同尺度和方向的各向异性热核(中)和测地极重(右)是二维坐标系。下图:局部极坐标(ρ,θ)坐标系中加权函数的表示(红色曲线表示0.5级水平)
8.结合空间和光谱方法
第三种构造非欧几里得域类卷积运算的方法是在空频域上联合使用。
窗口傅里叶变换:经典傅立叶分析的显着缺点之一是缺乏空间定位。根据不确定性原理(傅立叶变换的基本特性之一),空间定位是以频率定位为代价的,反之亦然。在经典信号处理中,可以通过在窗口g(x)中进行局部频率分析来解决此问题,从而确定了窗口化傅立叶变换(WFT,也称为信号处理中的短时傅立叶变换或频谱图)。
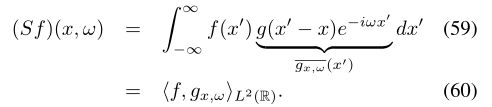
WFT是两个变量的函数:窗口x的空间位置和调制频率ω。窗口函数g的选择允许控制空间和频率本地化之间的权衡(更大的窗口可产生更好的频率分辨率)。请注意,WFT可以解释为具有转换和调制窗口gx,ω的函数f的内积(60),称为WFT原子.
将这种结构推广到非欧几里德域需要定义转换和调制算符[83]。尽管调制仅相当于通过拉普拉斯特征函数相乘,但由于缺少平移不变性,因此无法很好地定义转换。可以再次诉诸于类似卷积运算的频谱定义(34),将平移定义为具有增量函数的卷积。

所翻译和调制的原子可以表示为

其中该窗口是在频谱域中由其傅里叶系数gi确定的;因此,非欧氏域上的WFT采用以下形式:

由于定义中涉及的所有数量的内在本质,WFT也是内在的.
小波:用比例尺代替时频表示中的频率概念会导致小波分解。在一般图域中,小波已经得到了广泛的研究[84]。他们的目标是定义稳定的线性分解,其中原子在空间和频率上都很好地定位,可以有效地近似具有孤立奇点的信号。与欧几里得设置相似,可以根据其频谱约束或空间约束来构造小波族。
这些族中最简单的就是Haar小波。在[85]和[86]中研究了图上的几种自底向上的小波构造。在[87]中,作者开发了一种无监督方法,通过优化稀疏重建目标来学习图上的小波分解。在[88]中,Haar小波分解的合奏被用于定义一般域上的深小波散射变换,获得了出色的数值性能。学习等于找到每个尺度上的最优节点对,这可以在多项式时间内有效解决。
局部谱CNN(LSCNN)【89】:Boscaini等。使用WFT作为在流形和点云上构造补丁算子(52)的方法,并用于内在卷积样构造(53)。WFT允许以Dj(x)f =(Sf)(x,j)的形式在光谱域中的一个点周围表达函数。将可学习的过滤器应用于此类“补丁”(在这种情况下可以解释为频谱乘数),就有可能提取出有意义的特征,这些特征似乎也可以跨不同领域推广。窗口的定义是另一个自由度,也可以学习[89]。
几何深度学习的二分法

9.应用
网络分析:在网络分析的许多著作中使用的经典示例之一是引文网络。引用网络是一个图形,其中顶点表示纸张,并且如果纸张i引用了纸张j,则存在有向边(i,j)。通常,代表纸张内容的顶点特征(例如 本文中常用术语的直方图)。一个典型的分类应用是将每篇论文归于一个字段。传统方法是逐点工作的,分别对每个顶点的特征向量进行分类。最近,已经表明,使用来自相邻顶点的信息,例如图3中的信息,可以大大改善分类。在图表[45],[77]上使用CNN。插图IN6显示了在引用网络上应用光谱和空间图CNN模型的示例。
网络分析中的另一个基本问题是排名和社区检测。可以通过在图上适当定义的算符上求解特征值问题来估算这些特征:例如,Fiedler向量(与拉普拉斯算子的最小非平凡特征值相关的特征向量)在图分区上以最小割减的方式承载信息[73]],并且流行的PageRank算法使用修改的Laplacian算子的主要特征向量来近似页面排名。在某些情况下,可能需要开发此类算法的数据驱动版本,以适应模型不匹配并可能提供对角化方法的更快替代方法。通过展开幂迭代,可以得到一种图神经网络体系结构,其参数可以通过反向传播从标记的示例中学习,类似于“学习的稀疏编码”范例[91]。目前,我们通过构建多尺度的图神经网络来探索这种联系。
推荐系统:推荐Netflix上的电影,Facebook上的朋友或亚马逊上的产品是一些推荐系统的例子,最近这些推荐系统在广泛的应用程序中变得无处不在。在数学上,可以将推荐方法提出为矩阵完成问题[92],其中列和行分别代表用户和项目,矩阵值代表确定用户是否喜欢项目的分数。给定矩阵已知元素的一小部分,目标是填写其余部分。一个著名的例子是Netflix于2009年提出的挑战[93],该算法获得了100万美元的奖金,该算法可以根据先前的评分最佳地预测电影的用户评分。Netflix矩阵的大小为48万部电影×18K用户(8.5B元素),仅已知条目的0.011%。
几项最新的工作提出将几何结构合并到矩阵完成问题中[94],[95],[96],[97],其形式分别是代表用户和项目相似性的列图和行图( 参见图4)。这样的几何矩阵完成设置使得例如 矩阵值的平滑度的概念,并被证明对推荐系统的性能有益。
在最近的工作中,Monti等人。[56]提出通过结合多图CNN(MGCNN)和递归神经网络(RNN)的可学习模型解决几何矩阵完成问题。可以将多图卷积视为标准二维图像卷积的一般化,其中行和列的域现在不同(在我们的情况下,是用户图和项目图)。然后,借助MGCNN从得分矩阵中提取的特征将传递到RNN,后者会生成一系列得分值的增量更新。总的来说,该模型可以看作是分数的可学习的扩散,与传统方法相比,主要优势是与矩阵大小无关的固定数量的变量。MGCNN在几个经典的矩阵完成挑战上取得了最新的成果,并且从概念上讲,这可能是几何深度学习对经典信号处理问题的非常有趣的实际应用。
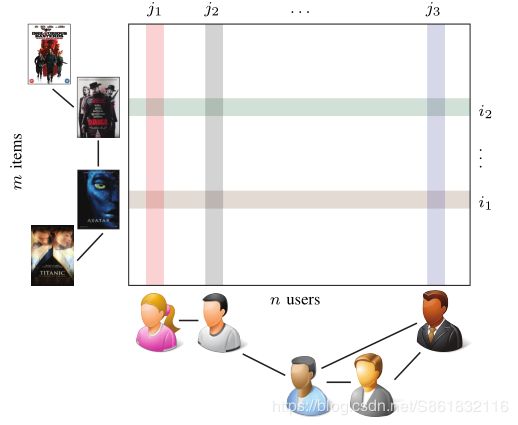
图4.几何矩阵的完成以著名的Netflix电影推荐问题为例。柱状图和行图分别表示用户和项目之间的关系
计算机视觉与图形学:计算机视觉社区最近对使用3D几何数据表现出了越来越高的兴趣,这主要是由于出现了负担得起的范围感应技术,例如Microsoft Kinect或Intel RealSense。许多成功处理图像的机器学习技术都在3D几何数据上按“原样”进行了尝试,为此,标准框架以某种方式“可消化”表示了这一点。作为范围图像[98],[99]或光栅化体积[100],[101]。这种方法的主要缺点是将几何数据视为欧几里得结构。首先,对于复杂的3D对象,诸如深度图像或体素之类的欧几里得表示可能会丢失该对象的重要部分或其精细细节,甚至破坏其拓扑结构。其次,欧几里得表示不是固有的,并且在更改姿势或使对象变形时会发生变化。实现形状变形的不变性是许多视觉应用中的常见要求,由于描述非刚性变形涉及大量的自由度,因此需要非常复杂的模型和庞大的训练集(图5,左)。

图5.应用于3D形状(方格表面)的欧式CNN(左图)与固有地应用于曲面的几何CNN(右)之间的区别说明。在后一种情况下,卷积滤波器(可视化为有色窗口)通过构造不变形。
另一方面,在计算机图形学领域,内部处理几何形状是一种标准做法。在此领域中,通常将3D形状建模为黎曼流形,并离散化为网格。许多研究(例如,参见[102],[103],[104],[105],[106])致力于设计局部和全局特征,例如图像特征。用于在可变形形状之间建立相似性或对应性,并保证等距不变。
此外,计算机视觉和图形学中的不同应用可能需要完全不同的功能:例如,为了在一组人类形状之间建立基于特征的对应关系,人们会希望对相应的解剖部位(鼻子,嘴等)进行描述。在整个馆藏中尽可能相似。换句话说,这样的描述符应该对于集合可变性是不变的。相反,对于形状分类,人们希望描述符能够强调特定于受试者的特征,例如,区分两种不同的鼻子形状(见图6)。先验地确定应该使用哪些结构以及应该忽略哪些结构通常是困难的,有时甚至是不可能的。此外,几何噪声(例如3D扫描伪像)的公理化建模非常困难。

图6.左:理想情况下,用于形状对应的特征应在整个形状类别中表现出不变性(例如,此处显示的“膝盖特征”不应取决于特定的人)。正确:相反,用于形状检索的特征应特定于班级中的形状,以便区分不同的人。相似的特征用相同的颜色标记。为每个应用程序手工设计正确的功能是一项非常艰巨的任务。
通过使用固有的深层神经网络,等轴测变形的不变性会自动建立到模型中,从而大大减少了描述不变性类所需的自由度数量。粗略地说,内在深层模型将尝试学习偏离等轴测模型的“残余”变形。几何深度学习可以应用于3D形状分析中的几个问题,可以分为两类。首先,诸如局部描述符学习[47],[53]或对应学习[48](参见插入IN7中的示例)之类的问题,其中网络的输出是点对点的。网络的输入是一些逐点特征,例如颜色纹理或简单的几何特征(例如法线)。使用具有多个固有卷积层的CNN架构,可以生成捕获每个点周围上下文的非局部特征。诸如形状识别之类的第二类问题要求网络产生全局形状描述符,使用例如图2将所有局部信息聚集到单个向量中。协方差合并[47]。
粒子物理与化学:实验科学的许多领域都对研究在低维相空间上定义的离散粒子系统感兴趣。例如,分子的化学性质由其原子的相对位置决定,粒子加速器中事件的分类取决于碰撞所涉及的所有粒子的位置,动量和自旋。
N粒子系统的行为最终是从Schrödinger方程的解得出的,但其精确解涉及对角化线性系统的指数大小。在这种情况下,一个重要的问题是,是否可以通过一种易于处理的模型来近似动力学,该模型通过构造并入了薛定ding方程所假定的几何稳定性,同时具有足够的灵活性来适应数据驱动的情况并捕获复杂的交互作用。
一个粒子系统的实例l可以表示为

其中(αj,l)建模特定于粒子的信息(例如自旋),而(xj,l)是粒子在给定相空间中的位置。可以将这种系统重铸为在具有| Vl |的图形上定义的信号。= Nl顶点和边缘权重Wl =(φ(αi,l,αj,l,xi,l,xj,l))通过捕获适当先验的相似性内核表示。图神经网络目前正用于在高能物理实验(例如IceCube天文台中的大型强子对撞机(LHC)和中微子探测)中执行事件分类,能量回归和异常检测。最近,基于图神经网络的模型已被用于预测N体系统的动力学[111],[112],显示出出色的预测性能。
分子设计:材料和药物设计中的关键问题是从其结构预测新分子的物理,化学或生物学特性(例如毒性的溶解度)。最先进的方法依赖于手工制作的分子描述符,例如圆形指纹[113],[114],[115]。哈佛大学的最新工作[55]提出将分子建模为图形(其中顶点表示原子,边表示化学键),并使用图卷积神经网络学习所需的分子特性。他们的方法明显优于手工制作的功能。这项工作为分子设计开辟了一条新途径,这可能会改变该领域。
医学成像:脑成像是一个应用领域,在该领域中自然可以在非欧几里德域上收集信号,而我们回顾的方法可能非常有用。神经科学的最新趋势是将功能性MRI迹线与预先计算的连通性相关联,而不是从迹线本身进行推断[116]。在这种情况下,挑战在于处理和分析通过复杂拓扑收集的信号阵列,从而导致微妙的依赖性。帝国理工学院的最新研究[117]中,使用图CNN来检测与自闭症相关的大脑功能网络的破坏。
10.开放的问题与未来的方向
我们试图在本文中概述在各个社区和应用领域中出现的几何深度学习方法的最新出现,这使我们可以谨慎地宣告,我们可能正在见证一个新领域的诞生。我们希望接下来的几年会带来令人兴奋的新方法和成果,并以对当前关键困难和未来研究潜在方向的一些观察来结束我们的综述。
许多处理几何数据的学科都采用一些经验模型或“手工”特征。这是几何处理和计算机图形学中的一种典型情况,其中使用公理构造的特征来分析3D形状或计算社会学,通常首先提出一个假设,然后对数据进行检验[22]。然而,这样的模型假设一些先验知识(例如,等距形状变形模型),并且经常不能正确地捕获数据的全部复杂性和丰富性。在计算机视觉中,从“手工”功能转变为以特定任务方式可从数据中学习的通用模型,这带来了性能上的突破,并导致社区中普遍倾向于使用深度学习方法。由于缺乏适当的方法,在处理几何数据的领域中尚未发生这种转变,但是首先有迹象表明即将发生范式转变。
一般化:将深度学习模型推广到几何数据,不仅需要找到基本构造块(例如卷积和池化层)的非欧几里得对应物,而且还需要跨不同领域进行推广。泛化能力是许多应用程序(包括计算机图形学)中的一项关键要求,在这种应用程序中,模型是在非欧氏域(3D形状)的训练集上学习的,然后应用于先前未见过的域。卷积的频谱表述允许在一个图上设计CNN,但是在一个图上以这种方式学到的模型不能直接应用于另一张图,因为卷积的频谱表示依赖于域。解决频谱方法泛化问题的一种可能方法是在[118]中提出的最新体系结构,在频谱域中应用空间变换器网络[119]的思想。这种方法使人联想到通过联合拉普拉斯对角化[75]来构造兼容的正交碱基,这可以解释为在k维空间中两个拉普拉斯特征根的对齐。
另一方面,空间方法允许跨不同域进行泛化,但是在图形上构造低维局部空间坐标的过程变得颇具挑战性。特别是,在一般图形上构造各向异性扩散是一个有趣的研究方向。
无谱方法至少在功能形式方面也允许跨图概括。但是,如果没有使用非线性或学习的参数θ的方程式(51)的多个层模拟了较高的扩散能力,则该模型在不同种类的图形上的行为可能会有所不同。目前正在研究了解在什么情况下以及在何种程度上将这些方法推广到整个图。
时变域:本文中讨论的几何深度学习问题的一个有趣扩展是处理动态变化结构上定义的信号。在这种情况下,我们不能假设一个固定的域,而必须跟踪这些变化如何影响信号。这可能对解决诸如社交或金融网络中的异常活动检测之类的应用很有用。在计算机图形和视觉领域,潜在的应用程序处理动态形状(例如,距离传感器捕获的3D视频)。
指示图:处理有向图也是一个具有挑战性的主题,因为此类图通常具有不对称的Laplacian矩阵,这些矩阵不具有正交本征分解,因此无法轻松解释光谱域构造。引文网络是有向图,通常被视为无向图(包括IN7中的示例),考虑了两篇论文之间的引文,而没有区分哪篇论文引用了哪篇论文。显然,这可能会丢失重要信息。
合成的问题:我们在这篇综述中的主要重点是非欧几里得域的分析问题。数据综合问题同样重要。最近进行了数种尝试来尝试学习生成模型,以合成新的图像[120]和语音波形[121]。将此类方法扩展到几何设置似乎是一个有前途的方向,尽管关键困难是需要从某些内在表示中重建几何结构(例如,将2D流形嵌入到可变形形状的3D欧氏空间中)[122]
计算:最后的考虑是计算上的。现有的所有深度学习软件框架都主要针对欧几里得数据进行了优化。深度学习架构的计算效率的主要原因之一(也是促成其复兴的因素之一)是假设在1D或2D网格上规则结构化数据,从而可以利用现代GPU硬件。 另一方面,几何数据在大多数情况下没有网格结构,因此需要使用不同的方法来实现有效的计算。似乎为大规模图形处理开发的计算范例对于此类应用程序而言是更合适的框架。
名词解释:
1.插值内核:
2.什么是DC:
3.傅里叶: