Python爬虫入门学习笔记.md
这是看一个教学视频整理的python爬虫入门 笔记,第一次尝试用.md文件来发布博客
Python网络爬虫
网络爬虫,又叫网络数据采集,又叫网络机器人
基本功能:
- 抓取你看到的网络数据
- 抓取你看不到的网络数据
- 代替你发送网络消息
- …
思想有多远,爬虫就能走多远,这个笔记只记录了爬去静态页面的方式,来做一个爬虫的简单入门。
第一章 网络数据采集的一般流程
- 通过网站域名获取HTML数据
- 根据目标信息解析数据
- 存储目标信息
- 若有必要,移动到另一个网页重复这个过程
一、通过网站域名获取HTML数据
- 可以用urllib库或者requests库来获取HTML数据
import requests
url='http://www.runoob.com/html/html-intro.html'
r=requests.get(url)
html=r.text.encode(r.encoding).decode()
html
- r.text是一个乱码的字符串(可能是非utf-8编码数据让utf-8编码的pycharm显示了出来)
- r.text.encode(r.encoding)是一串b’ ’的字节码数据
- html是一串非乱码正常显示的字符串
二、根据目标信息解析数据
1, HTML文件的结构
html文档由html元素组成,html元素包括:标签,属性,内容。标签包括起始标签和结束标签。html元素可以嵌套,如最外层的元素即由
html所定义,次外层通常为head和body。只有在body部分定义的内容才在浏览器中可见
2,利用BeautifulSoup解析html
import requests
from bs4 import BeautifulSoup
url='http://www.runoob.com/html/html-intro.html'
r=requests.get(url)
html=r.text.encode(r.encoding).decode()
soup=BeautifulSoup(html,'lxml')
list=[x.text for x in soup.findAll('h2')]
list
['HTML5',
'HTML 媒体',
'HTML 参考手册',
'HTML 实例',
'实例解析',
'什么是HTML?',
'HTML 标签',
'HTML 元素',
'Web 浏览器',
'HTML 网页结构',
'HTML版本',
' 声明',
'通用声明',
'中文编码',
'HTML 实例']
三、存储目标信息
'存储目标信息'
# 一般可以把爬取的数据存储到excel,csv,txt文件,或数据库中
import requests
from bs4 import BeautifulSoup
import pandas
url='http://www.runoob.com/html/html-intro.html'
r=requests.get(url)
html=r.text.encode(r.encoding).decode()
soup=BeautifulSoup(html,'lxml')
l=[x.text for x in soup.findAll('h2')]
df= pandas.DataFrame(l,columns=[url])
df.to_excel('爬虫.xlsx')
就是利用pandas库,将处理数据存储到了当前目录的:爬虫.xlsx ,文件中去
四、移至其他网页爬取
# import requests
from bs4 import BeautifulSoup
import pandas
import requests
url='http://www.runoob.com/html/html-intro.html'
r=requests.get(url)
html=r.text.encode(r.encoding).decode()
soup=BeautifulSoup(html,'lxml')
l=[x.text for x in soup.findAll('h2')]
df= pandas.DataFrame(l,columns=[url])
x=soup.findAll('a')[1]
x.has_attr('href')
x.attrs['href']
links=[i for i in soup.findAll('a') if i.has_attr('href') and i.attrs['href'][0:5]=='/html']
relative_urls=set([i.attrs['href'] for i in links])
absolute_urls={'http://www.runoob.com'+i for i in relative_urls}
absolute_urls.discard(url)
for i in absolute_urls:
ri=requests.get(i)
soupi=BeautifulSoup(ri.text.encode(ri.encoding),'lxml')
li=[x.text for x in soupi.findAll('h2')]
dfi=pandas.DataFrame(li,columns=[i])
df=df.join(dfi,how='outer')
df.to_excel('爬虫2.xlsx')
第二章 网络采集的常用工具
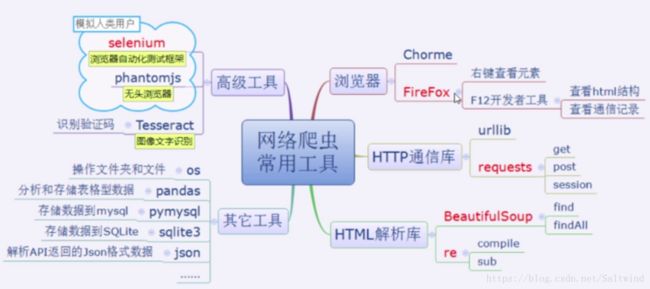
一、Firefox浏览器
主要功能:
- 定位网页元素【右键:查看元素】
- 查看通信记录【F12——>网络——>重新载入标签页】
- 查看请求headers【F12——>网络——>重新载入标签页——>双击——>消息头——>原始头】
- 定位HXR动态请求url【F12——>网络——>重新载入标签页——>XHR——>响应】
- …
简单地说:找url【抓包】,找元素,找headers
二、requests库
主要功能:
- 发送请求:get,post…
- 填写fform表单
- 身份认证
- …
简单地说:和服务器通信相关所有功能
requests库参考教程:http://docs.python-requests.org/zh_CN/latest/
三、BeautifulSoup和re
- 美丽汤 是用正则表达式 实现的
- 许多对正则表达式熟练的开发者直接使用re库解析HTML文档
- 但BeautifulSoup库更加简单,所以我们平时就用它,必要时配合re使用
- re还常常用于对采集的文本数据的清洗,如去除换行符引用标签等
简单地说:解析html,数据清洗
BeautifulSoup教程:https://cuiqingcai.com/1319.html
正则表达式教程:http://www.runoob.com/regexp/regexp-metachar.html
正则 表达式教程:https://cuiqingcai.com/977.html
四、Selenium和Phantomjs
requests的困难:无法运行css和JavaScript。
一个动态网页DHTML由html,css和JavaScript组成。
html是主体,装载各种dom元素;css用来装饰dom元素;JavaScript控制dom元素。
用一扇门比喻三者的关系是:html时门的门板,css时门上的油漆或花纹,JavaScript是门的开关;
运行JavaScript之后可以在不改变url的情况下改变页面。
处理动态网页DHTML困难的两种方法:抓包和Selenium
- Selenium原本是一个Web自动化测试框架,测试web脚本是否对IE,Chorme,Firefox等多种浏览器兼容
- Selenium测试直接运行在浏览器中,就像真正的用户在操作一样
- Selenium可以模拟用户点击链接,提交表单,拖动滑块等一系列操作
- Phantomjs是一个无头浏览器,可以解析html,css文件,运行JavaScript脚本,但没有图形界面
- Selenium+Phantomjs模式构建的爬虫可以很好地采集运行JavaScript脚本的动态网页
- Selenium+Phantomjs模式构建的爬虫可以破解网站的各种反爬虫策略,如蜜罐
- Selenium+Phantomjs模式构建的爬虫一般速度相对用requests构建的爬虫更慢
简单地说:模拟人类用户,破解反爬虫策略
Selenium教程:https://cuiqingcai.com/2599.html
Selenium操作鼠标键盘:http://blog.csdn.net/huilan_same/article/details/52305176
第三章 复杂html的解析
BeautifulSoup里的find()和findAll()可能是最常用的两个函数。
findAll查找满足条件的全部html元素,而find查找满足条件的第一个html元素。
这两个函数非常相似,find可以看做时findAll中limit参数取1的情况
findAll(name=None, attrs={}, recursive=True, text=None, limit=None, **kw)
find(name=None, attrs={}, recursive=True, text=None, **kw)
其中大部分时候是使用前两个参数:即标签和属性,rucursive意思是是否要在各个标签中递归查找
一、使用标签和属性
import requests
from bs4 import BeautifulSoup
url='http://www.runoob.com/html/html-intro.html'
r=requests.get(url)
html=r.text.encode(r.encoding).decode()
soup=BeautifulSoup(html,'lxml')
# print(soup.prettify()) # 可以用这个属性进行格式化输出
# 使用标签
soup.findAll(name={'h1','h2','h3','h4'}) # 这里的元素之间是 或 的关系
len(soup.body.findAll('div',recursive=True))
len(soup.body.findAll('div',recursive=False))
10
# 使用属性
divs=soup.findAll('div',attrs={'class':{'article','container navigation'}}) # 这里字典中的key-value是且的关系
divs[1].findAll('h2')
[HTML 实例
,
实例解析
,
什么是HTML?
,
HTML 标签
,
HTML 元素
,
Web 浏览器
,
HTML 网页结构
,
HTML版本
,
<!DOCTYPE> 声明
,
通用声明
,
中文编码
,
HTML 实例
]
二、使用文本和关键字
import requests
from bs4 import BeautifulSoup
url='http://www.runoob.com/html/html-intro.html'
r=requests.get(url)
html=r.text.encode(r.encoding).decode()
soup=BeautifulSoup(html,'lxml')
# 使用文本
import re
# 查看文本内容为‘HTML 标签’ 的所有html元素(tag对象)
soup.findAll(re.compile(''), text='HTML 标签')
# 查看文本内容以’HTML‘开头的tag对象
soup.findAll({'h1','h2','h3','h4'}, text=re.compile('^HTML'))
[HTML5
,
HTML 实例
,
HTML 标签
,
HTML 元素
,
HTML 网页结构
,
HTML版本
,
HTML5
,
HTML 4.01
,
HTML 实例
]
# 使用关键字
# 因为class时python关键字,而此处也要用class指定html属性名,为避免冲突,需要加下划线
soup.findAll(class_={'article', 'container navigation'})
len(soup)
2
# findAll,find 中,**kwarg参数和attrs参数可以相互替代,功能上存在一定的冗余性
# soup.find('div', id ={'footer'})
三、使用lambda表达式
import requests
from bs4 import BeautifulSoup
url='http://www.runoob.com/html/html-intro.html'
r=requests.get(url)
html=r.text.encode(r.encoding).decode()
soup=BeautifulSoup(html,'lxml')
# 使用lambda表达式
# 三者功能相同
soup.findAll(lambda tag:tag.name=='h2' and len(tag.attrs)==0)
[x for x in soup.findAll('h2') if len(x.attrs)==0]
list(filter(lambda tag:len(tag.attrs)==0,soup.findAll('h2')))
[实例解析
,
什么是HTML?
,
HTML 标签
,
HTML 元素
,
Web 浏览器
,
HTML 网页结构
,
HTML版本
,
<!DOCTYPE> 声明
,
通用声明
,
中文编码
]
四、使用正则表达式
常用正则表达式元字符:
. 匹配任意单个字符
* 匹配前面的表达式0次或多次
+ 匹配前面的表达式1次或多次
() 表达式编组
[] 匹配括号中的任意一个字符
{m,n}匹配前面的模式m至n次
[^] 匹配任意一个不在中括号中的字符
| 匹配任意一个由竖线分割的表达式
^ 表示字符串开始位置
$ 表示字符串结束位置
\ 表示转义
import requests
from bs4 import BeautifulSoup
url='http://www.runoob.com/html/html-intro.html'
r=requests.get(url)
html=r.text.encode(r.encoding).decode()
soup=BeautifulSoup(html,'lxml')
'使用正则表达式'
import re
# 查找标签名为h1至h9的tag
soup.findAll(re.compile('h[1-9]'))
# 查找标签名为h1至h9,且文本内容包括'HTML'或'html'的tag
soup.findAll(re.compile('h[1-9]'),text=re.compile('.*(HTML)|(html).*'))
# 查找地址为//www 或 //http:www 开头的链接
soup.find('a',attrs={'href':re.compile('^//(www)|(http\:www).*')}).prettify()
'\n 首页\n'
五、使用导航树
html文档的结构是一种树形结构。这个图形就脑海想一想吧
使用导航树方法利用相对位置查询标签
这种方法使得在找到某个易于定位的标签后,查找与之位置关联的标签十分容易。其只要属性有:
- children
- descendants
- next_siblings
- parent
第四章、采集单一网页特定数据训练
一、采集标题和文本
import requests
from bs4 import BeautifulSoup
import re
import os
import pandas as pd
# 获取诗的题目,作者信息和内容
url='http://www.shicimingju.com/chaxun/list/3710.html'
r=requests.get(url)
html=r.text.encode(r.encoding).decode()
soup=BeautifulSoup(html,'lxml')
content=soup.find('div', class_={'shici-content'}).text.strip()
title='《'+soup.find('h1', class_={'shici-title'}).text+'》'
info=soup.find('div', class_={'shici-info'}).text.strip()
'[宋] 苏轼'
# 对获取的信息进行存储,这里的相当于纯文本信息,就存储到.txt
filedir=os.getcwd()+'/苏轼的词' # os.getcwd ,current working directory,这里是在拼接一个路径
if not os.path.exists(filedir):
os.mkdir(filedir)
with open(filedir+'/%s.txt'%title, mode='w',encoding='utf-8') as f: # 这里是用open()打开这个文件,如果没有就创建它
f.write(title+'\n'+info+'\n'+content)
二、采集图片数据
import requests
from bs4 import BeautifulSoup
import re
import os
import pandas as pd
# 采集简书博客中的图片
url= 'https://www.jianshu.com/p/1376959c3679'
headers={'User-Agent':
'Mozilla/5.0 (Windows NT 6.3; WOW64; rv:57.0)'+\
'Gecko/20100101 Firefox/57.0'}
r=requests.get(url,headers=headers)
html=r.text.encode(r.encoding).decode()
soup=BeautifulSoup(html,'lxml')
imgs=soup.findAll(lambda tag:tag.name=='img' and tag.has_attr('data-original-src'))
srcs=['https:'+i.attrs['data-original-src'] for i in imgs]
filedir=os.getcwd()+'/户外风景独好'
if not os.path.exists(filedir):
os.mkdir(filedir)
for i in range(len(srcs)):
rpi=requests.get(srcs[i],headers=headers)
if rpi.status_code==200:
with open(filedir+'/%s.jpg'%(i+1),mode='wb') as f:
f.write(rpi.content)
print('正在下载第 %d 张图片......'%int(i+1))
正在下载第 1 张图片......
正在下载第 2 张图片......
正在下载第 3 张图片......
正在下载第 4 张图片......
正在下载第 5 张图片......
正在下载第 6 张图片......
正在下载第 7 张图片......
正在下载第 8 张图片......
正在下载第 9 张图片......
三、采集表格形式的数据
import requests
from bs4 import BeautifulSoup
import re
import os
import pandas as pd
import numpy as np
url='http://rl.fx678.com/date/20171229.html'
headers={'User-Agent':
'Mozilla/5.0 (Windows NT 6.3; WOW64; rv:57.0)'+\
'Gecko/20100101 Firefox/57.0'}
r=requests.get(url,headers=headers)
html=r.text.encode(r.encoding).decode()
soup=BeautifulSoup(html,'lxml')
# 发现了财经数据表格对应的id为current_data
table=soup.find('table',id='current_data')
# 查看table里有多少行数据
height=len(table.findAll(lambda tag:tag.name=='tr' and len(tag.findAll('td'))>=1))
# 查看有多少列数据,这里显示的结果跟此表格的结构密切相关
for row in table.findAll('tr'):
print(len(row.findAll('td')),end='\t')
0 0 9 7 7 7 7 9 7 7 9 7 7 9 7 9 7 9 7 7 7 9 9 7 9 9 7 9 7 7 7 9 7
# 收集表头,用来当做最终存储的表格的列名
columns=[x.text for x in table.tr.findAll('th')]
columns=[x.replace('\xa0',' ') for x in columns]
columns
['时间', '区域', '指标', '前值', '预测值', '公布值', '重要性', '利多 利空', '解读']
width=len(columns)
df=pd.DataFrame(data=np.full((height,width),' ',dtype='U'),columns=columns)
rows=[row for row in table.findAll('tr') if row.find('td')!=None]
# 逐行解析表格
for i in range(len(rows)):
cells=rows[i].findAll('td')
# 若该行单元格数量与dataframe列数相同
if len(cells)==width:
df.iloc[i]=[cell.text.replace(' ','').replace('\n','') for cell in cells] # 去掉空格和换行
# 若单元格跨多行,则进行多行填充
for j in range(len(cells)):
if cells[j].has_attr('rowspan'):
z=int(cells[j].attrs['rowspan'])
df.iloc[i:i+z,j]=[cells[j].text.replace(' ','').replace('\n','')]*z
else:
w=len(cells)
df.iloc[i,width-w:]=[cell.text.replace(' ','').replace('\n','') for cell in cells]
df.to_excel('20171229财经日历.xlsx')
df
| 时间 | 区域 | 指标 | 前值 | 预测值 | 公布值 | 重要性 | 利多 利空 | 解读 | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 00:00 | 美国截至12月22日当周EIA原油库存变动(万桶) | -649.5 | -384.42 | -460.9 | 高 | 利多加元石油 | ||
| 1 | 00:00 | 美国截至12月22日当周EIA精炼油库存变动(万桶) | 76.9 | 8.56 | 109 | 高 | 利空加元石油 | ||
| 2 | 00:00 | 美国截至12月22日当周EIA汽油库存变动(万桶) | 123.7 | 129.03 | 59.1 | 高 | 利多加元石油 | ||
| 3 | 00:00 | 美国截至12月22日当周EIA俄克拉荷马州库欣原油库存(万桶) | 75.4 | -158.4 |
第五章 遍历多个网页进行采集
这里对苏轼所有的诗词进行一个多个网页的下载存储
import requests
from bs4 import BeautifulSoup
import re
import os
import pandas as pd
base='http://www.shicimingju.com'
url='http://www.shicimingju.com/chaxun/zuozhe/9.html'
def gethrefs(url):
headers={'User-Agent':'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:61.0) Gecko/20100101 Firefox/61.0'}
r=requests.get(url,headers=headers)
soup=BeautifulSoup(r.text.encode(r.encoding),'lxml')
div=soup.find('div',class_='www-shadow-card www-main-container')
href=[x.a.attrs['href'] for x in div.findAll('h3')]
hrefs=[base+i for i in href]
try:
nexturl=base+soup.find('div', class_='pagination www-shadow-card').find(lambda tag:tag.name=='a' and tag.span.text=='下一页').attrs['href']
except Exception as e:
print('全部下载完毕!!!')
nexturl=''
ans={}
ans['hrefs']=hrefs
ans['nexturl']=nexturl
return ans
def writetotxt(url):
headers={'User-Agent':'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:61.0) Gecko/20100101 Firefox/61.0'}
r=requests.get(url,headers=headers)
html=r.text.encode(r.encoding).decode()
soup=BeautifulSoup(html,'lxml')
content=soup.find('div', class_={'shici-content'}).text.strip()
title='《'+soup.find('h1', class_={'shici-title'}).text+'》'
info=soup.find('div', class_={'shici-info'}).text.strip()
# 对获取的信息进行存储,这里的相当于纯文本信息,就存储到.txt
filedir=os.getcwd()+'/苏轼的词' # os.getcwd ,current working directory,这里是在拼接一个路径
if not os.path.exists(filedir):
os.mkdir(filedir)
with open(filedir+'/%s.txt'%title, mode='w',encoding='utf-8') as f: # 这里是用open()打开这个文件,如果没有就创建它
f.write(title+'\n'+info+'\n'+content)
ans=gethrefs(url)
allhrefs=ans['hrefs']
while ans['nexturl']:
ans=gethrefs(ans['nexturl'])
allhrefs=allhrefs+ans['hrefs']
for i in range(len(allhrefs)//50):
writetotxt(allhrefs[i])
print('全部存储完毕!!!')
全部下载完毕!!!
全部存储完毕!!!