Pandas中第二好用的函数 | 优雅的apply
这是Python数据分析实战基础的第四篇内容,也是基础系列的最后一篇,接下来就进入实战系列了。本文主要讲的是Pandas中第二好用的函数——apply。
为什么说第二好用呢?做人嘛,最重要的就是谦虚,做函数也是一样的,而apply就是这样一个优雅而谦虚的函数。
我们单独用一篇来为apply树碑立传,原因有二,一是因为apply函数极其灵活高效,甚至是重新定义了pandas的灵活,一旦熟练运用,在数据清洗和分析界可谓是“屠龙在手,天下我有”;二是apply概念相对晦涩,需要结合具体案例去咀嚼和实践。
Apply初体验
apply函数,因为她总是和分组函数一起出现,所以在江湖得了个“groupby伴侣”的称号。她的主要作用是做聚合运算,以及在分组基础上根据实际情况来自定义一些规则,常见用法和参数如下:

如果把源数据比作面粉,groupby分组就是把面粉揉成一个个面团的过程,apply起到的作用,是根据数据需求来调馅,并且把每一个面团包成我们喜欢的包子。接下来,我们通过两个场景,更深入的感受下apply函数的优雅迷人。
场景一
背景:我们拿到了一份4位同学三次模拟考试的成绩,想知道每位同学历次模拟中最好成绩和最差成绩分别是多少。
思路:最好和最差,分别对应着max与min,我们先按姓名分组,再用apply函数返回对应的最大和最小值,最终将结果合并。
先导入源数据:
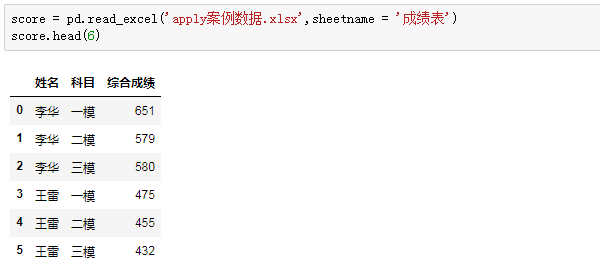
看一看每位同学最高成绩:

我们指定“综合成绩”列,然后把max函数直接传入apply参数内,返回了对应分组内成绩的最大值。有一些常见函数,如max、min、len等函数可以直接传入apply。
groupby分组默认会把分组依据列(姓名)变成索引,这里用reset_index方法重置或者说取消姓名索引,将它保留在列的位置,维持DataFrame格式,方便后续匹配。
再筛选出最低成绩:

两张表按姓名合并:

得到了我们预期的结果,只是列名略丑,可以用.columns方法来赋值更改。场景一比较死板和严肃,场景二我们换个更接地气的风格。
场景二
背景:Boss丢过来一份省市销售表,里面包含省份、城市、最近1个月销售额3个字段,没等你开口问需求,Boss就开腔了:“小Z啊,我最近对3这个数字有执念,我想看看每个省份销售排名第3的都是哪些城市,以及他们的销售额情况。对了,这个需求要尽快!”
思路:问题的关键是找到每个省份销售排名第3的城市,首先,应该对省份、城市按销售额进行降序排列,然后,找到对应排名第3的城市,Emmm,如果是排名第1的城市,我们可以通过排序后去重实现,但是这个排名第3,小Z疯狂挠头,还是没有什么思路。
于是弱弱的请求宽限时间:“领导,我觉得这个需求可能要花多一些时间,因为...”

“我不要你觉得!我要我觉得!现在是17:00,我觉得半个小时时间已经够充裕了!”Boss放下了手中的《明学是怎样炼成的》,语气斩钉截铁又毋庸置疑。
小Z在无奈和绝望之中,想起了那句诗“假如数据清洗难住了你,不要悲伤,不要心急,忧郁的日子里需要apply”,一瞬间通透了。
说干就干,先导入数据源,对数据做个初步了解:
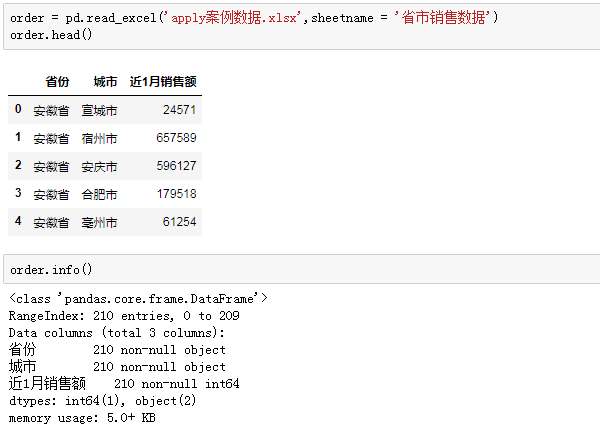
数据源有省份、城市、近1月销售额3个字段,一共210行(销售额)乱序排列,且都没有空值,整体比较规整。
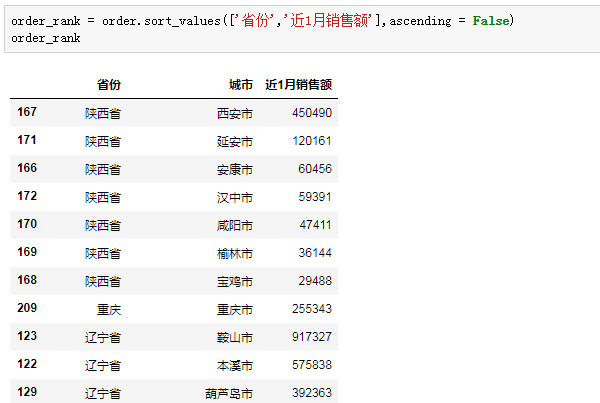
要得到销售排名第3的城市,要先进行排序,这里我们用省份、近1月销售额两个关键字段进行降序排列,得到我们期待的顺序:
接着,在apply函数登场前,我们先详细剖析一下整个过程:
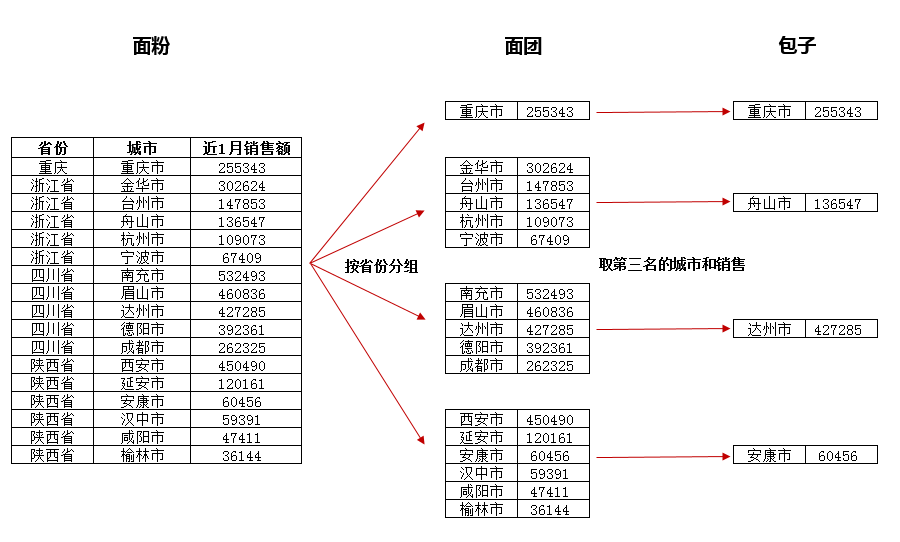
apply的精髓,在于揉面和DIY(调馅)包子。我们需要把源数据(面粉)给揉成一个个面团,再把一个个面团DIY成我们想要口味的包子。其中,揉面的过程就是groupby分组,而DIY调馅做包子就是apply自定义函数和应用的过程。
结合我们的目标,揉面是按省份进行分组,得到每个省各个城市和对应销售额的面团;DIY包子是在每个面团中取其第三名的城市和销售额字段。
第一步分组非常简单,按省份分组即可。而取第3名的城市和销售,表明我们需要城市和销售两个字段,所以在分组后指明这两列:

这一步,我们已经揉好了面,原始的面团也初步成型,虽然返回的结果有点晦涩,但是我们可以在脑海中构建一下这些面团,截图只展示了部分:
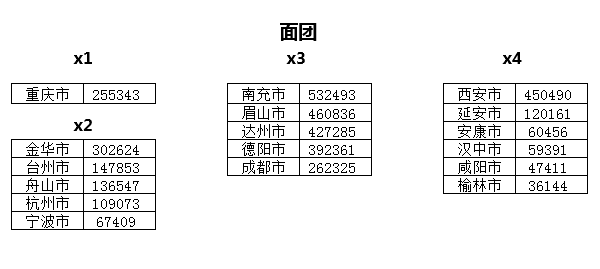
要把这些面团包成包子,就是要我们取出每一个面团中,排名第3的城市。有个问题需要注意,有一些直辖市是和省并列的,而作为城市只有单独的一行,这样的城市我们就默认返回其本身的数据;对于非直辖市省份来说,就需要定位筛选。
拿x2来举例,要找到这个面团中排名第三的城市和销售额,应该怎么做呢?答案是直接索引,把他看作是一个DataFrame格式的表,要选取第3行的所有值,包括城市和销售额,这里用iloc索引,很简单的一行代码:
![]()
下面把我们针对直辖市的判断和非直辖市的筛选逻辑整合成一个函数:

这个函数,将会在apply的带领下,对每一个分组进行批量化DIY,抽取出排名第3的城市和销售额,应用起来很简单:
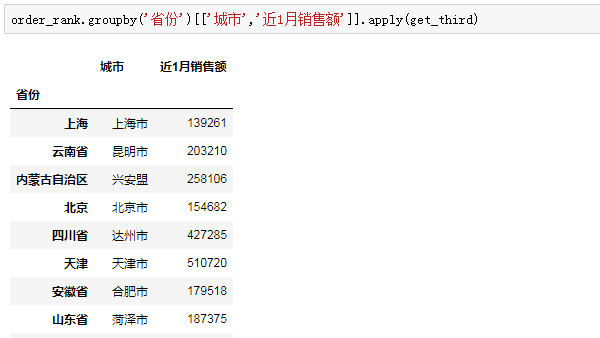
至此,每个省份,销售额排名第三的城市已经成功筛选出来。回顾整个操作流程,先排序,后分组,最后通过定义函数传入apply,提取出我们的目标值。分组后数据的抽象形态,以及如何判断和取出我们需要的值,是解决问题的关键和难点。
“报告老板!筛选任务已经完成!”apply在握,小Z底气变得格外的足。
注:数据源和详细操作代码,后台回复“apply”即可获取。
更多有趣有用文章

· Python数据分析实战基础 | 初识Pandas
· Python数据分析实战基础 | 灵活的Pandas索引
· Python数据分析实战基础 | 清洗常用4板斧
· 剧荒不慌 | 手把手教你爬取+DIY豆瓣电影新榜
· 深扒5000+招聘数据 | 听说产品拿不动刀了?
·《都挺好》弹幕比剧还精彩?394452条弹幕数据来告诉你答案