强化学习论文阅读笔记(一)——强化学习研究综述_高阳
强化学习研究综述_高阳
目录
强化学习研究综述_高阳
一、与其他机器学习对比
二、分类
三、最优搜索型强化学习算法
四、经验强化型强化学习算法
五、部分感知
六、函数估计
七、多Agent强化学习
八、符号学习和强化学习偏差
九、强化学习应用
一、与其他机器学习对比
- vs 监督学习:无需训练集,在线学习
- vs 规划技术:无需构造复杂的状态图,强调行为与环境交互
- vs 自适应控制技术:有共同奖赏函数形式,不要求确定动态系统模型
二、分类
- 最优搜索型:获得最优策略,选择搜索未知状态和动作,长期性
- 经验强化型:获得策略性能改善,利用以获得的可以产生高回报的动作状态,短期性
- 面对环境:马尔可夫型&非马尔可夫型
- 面临任务:非顺序型任务&顺序型任务
非顺序型:动作获取环境奖赏,不影响后继动作和状态
顺序型:动作影响未来状态和未来奖赏

三、最优搜索型强化学习算法
环境为马尔可夫型,顺序型强化学习:马尔可夫决策过程建模
T函数和R函数未知
采用技术:迭代技术调整当前状态和下一状态的值函数估值
- 模型无关法:不学习马尔可夫决策模型知识(T函数和R函数),直接学习最优策略
TD算法(蒙特卡罗思想+动态规划思想)
①无需系统模型,从Agent经验中学习
②利用估计的值函数进行迭代
Q-学习算法(离策略TD学习)
估计函数:状态-动作对的奖赏和![]() (在状态s下采用动作a所获得的最优奖赏折扣)
(在状态s下采用动作a所获得的最优奖赏折扣)
采用值函数的最大值进行迭代
根据修改后的Q确定动作
只需要采用贪心策略选择动作
- 基于模型法:学习模型知识,根据其推导优化策略方法
Sara(基于模型)
采用Q值迭代,在策略TD学习
采用实际Q值进行迭代,依据当前Q确定下一状态
四、经验强化型强化学习算法
充分利用已获得的经验知识,根据经验维持的动作规则进行动作选择 - Q-PSP学习方法:
有限状态退回,agent获取经验知识,构造规则合集,在下一个状态生成备选规则合集,基于备选规则合集确定下一个动作;当agent再次从环境中获得奖赏时,依据一定规则将奖赏分配到备选规则合集上,再进行新一次学习。
会导致强化无用规则,不能满足收敛要求。较大状态步回退时算法性能降低。
对于动态环境性能较差。
核心问题:如何设计有效的奖赏分配函数
五、部分感知
Agent不能感知所有环境信息。部分感知问题属于非马尔可夫型环境。部分感知问题中,强化学习算法要进行处理后应用,否则算法无法收敛。
主要研究方法:预测模型法(基于部分可观察马尔可夫决策过程模型 POMDP)
POMDP:考虑动作和状态的不确定性
解决思路:将系统转换为MDP描述,假设部分可观测的隐状态集S满足马尔可夫属性
引入内部状态置信度(状态b在隐状态集S上的概率分布)
缺点:当环境复杂程度增加,预测模型的大小呈爆炸性增长
六、函数估计
大规模MDP或连续空间MDP问题:强化学习需要具有泛化能力
本质:用参数化的函数逼近强化学习的映射关系
并行迭代过程:值函数迭代过程,值函数逼近过程
函数估计的方法:状态聚类,函数插值,函数拟合,决策树,人工神经网络,CMAC
七、多Agent强化学习
非马尔可夫环境
应用领域:游戏 邮件路由选择 口语对话系统 机器人足球
分类:乘积 分割 交互
CIRL算法:每个Agent有独立学习机制,不与其他agent交互。
适用范围:合作多agent系统
交互强化学习:每个agent有独立学习机制,与其他agent交互
问题:结构信用分配问题&agent间为什么交互
典型算法:ACE AGE
多agent系统的马尔可夫对策模型:agent目标为最大化期望折扣奖赏
三种形式:合作型多agent强化学习 竞争型多agent强化学习 和半竞争型多agent强化学习
- 合作型:联合奖赏函数对每个agent一致、相等。 合作进化学习可达到问题最优解
- 竞争型:联合奖赏函数对每个agent互为相反的(目标相反);所有agent奖赏和为0;采用极小加大Q算法;不能得到稳定解
- 半竞争:奖赏和不为0;元对策理论
八、符号学习和强化学习偏差
Dyna-Q:基于模型的算法,明确地学习系统模型

规则抽取:将agent通过强化学习技术所得策略,通过抽取规则转化成其他学习技术所能处理的表示形式
Beam Search算法:从值函数中抽取无条件规划和条件规划
强化学习偏差:传统强化学习无先验的启发知识,收敛慢。偏差技术用于提高收敛速度。
主要技术类型:整形 局部强化 模仿 任务分解
研究内容:1.先验知识以何种形式影响agent强化学习过程 2. agent如何活动启发知识
主要方法:构造导师agent(增加软件系统的系统复杂度); 将先验知识直接综合到强化学习算法中
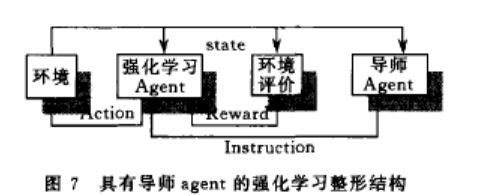
将先验知识综合到强化学习系统中,收敛性较好
九、强化学习应用
制造过程控制 各种任务调度 机器人设计和游戏