SpringData JPA 使用
主要记录实际使用
文章目录
- 1.SpringData 概述
- 2.访问数据库的传统方式
- 3.SpringData JPA
- ==**单 表**==
- ==多表==
- 4.SpringData JPA常用接口的解析
1.SpringData 概述
spring data 是spring这个系列的一个框架,并不属于某个框架,在一个框架使用了另一个框架这不是属于框架之间的整合,spring 和springboot 都能很好的整合其他的框架,并且不仅仅是整合spring 系列的框架,spring 和springboot 中的关系型数据访问都可以使用原生的JDBC(使用的意义不大)
spring还提供了JdbcTemplate 模板,在JDBC的基础上简化数据访问(仍旧需要完成持久化业务逻辑层);而springBoot 中可以整合SpringData 最简化数据访问(由框架完成持久化业务层)。spring 中当然也是可以整合springdata 框架的
简化了对数据库的操作,可以操作关系型数据库也可以操作分关系型数据库(noSql),
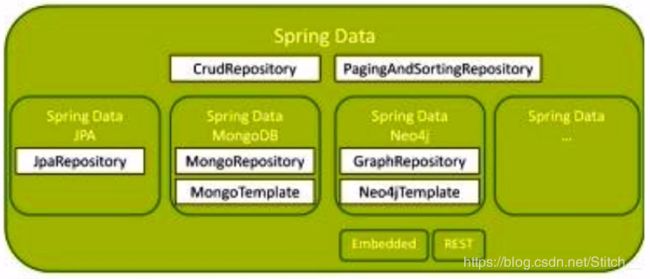
SpringData 的子项目:
4. Springdata JPA :简化数据层的开发,是基于JPA,主要是访问关系型数据库
5. springData MangoDB:分布式数据访问
6. SpringData Redis : key-value 键值对处理,属于noSql
Springdata JPA 是springdata 下的一个基于JPA( JPA是Java Persistence API,java 中的数据持久化API) 设计的简化关系型数据库访问的框架
2.访问数据库的传统方式
1.传统的JDBC
spring 中的JdbcTemplate 模板
传统的JDBC :connection(连接) Statement(执行者) ResultSet(结果集)
1. 获取链接
String url = "jdbc:mysql:localhost:3306/数据库的名称"
String user ="root";
String password = "";
String diverClass = "com.mysql.jadb.Driver";
Connection con = DiverManager.getConnection(url,user,password);
2. 编写sql 获取语句执行者
PreparesStatement pre = conn.prepareStatement(sql);
3. 语句执行,操作结果集ResultSet
4. 释放资源
Dao 先写接口再写实现
2. Spring 中使用 JdbcTemplate
添加相关的依赖Mave ;DataSource & JdbcTemplate 注入
实际上就是将 连接的获取管理资源的释放等都交给spring 进行管理,在bean 配置文件中配置JdbcTemplate 并且,在使用的时候获取
使用:
JdbcTemplaye jdbcTemplate = ctx.getBean("JdbcTemplate");
String sql = ; sql 语句
jdbcTemplate.各种执行方式,在执行方式中写入参数和结果集的处理
重点注意几个概念的理解
- SpringData:spring 系类的子项目,用于处理数据访问,包括:springData JAP (关系型数据库) SpringData Redis(Redis) 等。
- JPA:全称Java Persistence API,可以通过注解或者XML描述【对象-关系表】之间的映射关系,并将实体对象持久化到数据库中。是一套规范接口。需要有底层的实现。Hibernate 就是实现JPA的ORM 框架
- springData JPA :spirng data jpa是spring提供的一套简化JPA开发的框架,按照约定好的【方法命名规则】写dao层接口,就可以在不写接口实现的情况下,实现对数据库的访问和操作。同时提供了很多除了CRUD之外的功能,如分页、排序、复杂查询等等
Spring Data JPA 可以理解为 JPA 规范的再次封装抽象,底层还是使用了 Hibernate 的 JPA 技术实现。
3.SpringData JPA
简化关系型数据库的访问,开发者无需写DAO 层的代码,只需要声明 持久层接口,springdata 实现持久层访问的方式:根据开发者定义的方法名来确定该方法要执行的操作;开发者也可以通过@Query 注解自己定义相应的”sql“ 语句。使用JPA,如何定义自己的Repository接口让框架能正确的明白我们想让他完成的操作这就是一个重点。
一:将对象实体持久化到数据库中:实现对象-----数据库中的表
//注解:
@Id(主键) @GeneratedValue(主键的生成策略) :一般使用strategy = GenerationType.IDENTITY 主键自增
@Entity :表明这个类要对数据表做一个映射
@Table(表名):对应数据表的名字
@Colum :可以对字段作相应的要求,一般是
二:使用:xxxRepository 的编写
xxxRepository 的继承方式有两种
//1. 继承JpaRepository
xxxRepository extends jpaRepository<类名,表的主键在类中的类型>
{
重点在这个抽象类的编写
}
//2. 继承Repository
xxxRepository extends Repository<类名,表的主键在类中的类型>
{
重点在这个抽象类的编写
}
重点都是编写这个接口中的抽象方法
这两种继承方式不一样的是:
extends Repository: Repository 是一个空的接口,里面没有任何内容,是一个标识接口,表明的继承他的xxxRepository 会被Springboot 管理,才能实现写抽象方法可以使用。
extends jpaRepository: jpaRepository 是Repository 的一个子接口,里面定义了一些方法,在使用这些方法的时候回出现一些局限性。
这里的局限性主要针对JpaRepository 中已经定义好的一些方法,有一些返回值,或者是异常处理的局限性。比如:findById(Integer id) 的返回值类型:Optional;getOne(Integer id) 如果查找不到id 就会直接报错
单 表
- 添加数据:
xxxRepository.save(对象)
数据的添加和修改使用的都是save 判断的依据是主键,如果对象中没有赋值主键那么就是添加新的数据;如果对象中主键有值那就是对这行数据的修改。 - 根据id 的查找:
- getOne(id) :根据主键查找数据,缺点:当数据库中没有相应的数据的时候会直接抛出异常,当你在 查找数据发现出现的错误莫名其妙 ,找不到错在有可能就是它
- findById(id): 返回值为:Optional<类> Puser = xxxRepository.findById(id);
可以对返回值进行处理:
User user = null;
try{
user = Puser.get();
}catch(Exception ex){
出现异常说明:Puser 中没有 user
}
这样的获取就不会有异常抛出,user=Null 就表示没有查询得到数据
使用场景:常用在用户登录;为了判断数据是否在数据库中,可能在也可能不在;如果是单纯的为了把数据拿
出来用其实可以使用getOne(id)。前提是保证数据表中也一定有这个数据,在测试的时候要注意
这两个方法都是JpaRepository 中写好的方法,换句话说如果你的repository 继承JpaRepository 使用时就要注意这样的问题
- 使用规范的方法命名查找
规范的方法名不仅能完成查找还能完成count 操作
在Repository 子接口中声明方法:
①、不是随便声明的,而需要符合一定的规范
②、查询方法以 find | read | get 开头
③、涉及条件查询时,条件的属性用条件关键字连接
④、要注意的是:条件属性以首字母大写
spring data 支持的关键字
| 连接查询条件关键字 | 方法命名 | 对应的sql where字句 |
| And | findByNameAndPwd | where name= ? and pwd =? |
| Or | findByNameOrSex | where name= ? or sex=? |
| Is,Equals | findById,findByIdEquals | where id= ? |
| Between | findByIdBetween | where id between ? and ? |
| LessThan | findByIdLessThan | where id < ? |
| LessThanEquals | findByIdLessThanEquals | where id <= ? |
| GreaterThan | findByIdGreaterThan | where id > ? |
| GreaterThanEquals | findByIdGreaterThanEquals | where id > = ? |
| After | findByIdAfter | where id > ? |
| Before | findByIdBefore | where id < ? |
| IsNull | findByNameIsNull | where name is null |
| isNotNull,NotNull | findByNameNotNull | where name is not null |
| Like | findByNameLike | where name like ? |
| NotLike | findByNameNotLike | where name not like ? |
| StartingWith | findByNameStartingWith | where name like '?%' |
| EndingWith | findByNameEndingWith | where name like '%?' |
| Containing | findByNameContaining | where name like '%?%' |
| OrderBy | findByIdOrderByXDesc | where id=? order by x desc |
| Not | findByNameNot | where name <> ? |
| In | findByIdIn(Collection c) | where id in (?) |
| NotIn | findByIdNotIn(Collection c) | where id not in (?) |
| True | findByAaaTue | where aaa = true |
| False | findByAaaFalse | where aaa = false |
| IgnoreCase | findByNameIgnoreCase | where UPPER(name)=UPPER(?) |
- 使用注解完成sql
@Query 完成关键字定义方法无法完成的查询
- 索引参数:
- @Query("SELECT p FROM Person p WHERE p.lastName = ?1 AND p.email = ?2")
- List<Person> testQueryAnnotationParams1(String lastName, String email);
?1,?2 是占位符,需要方法传递的参数顺序与其保持一致
- 命名参数:
- @Query("SELECT p FROM Person p WHERE p.lastName = :lastName AND p.email = :email")
- List<Person> testQueryAnnotationParams2(@Param("email") String email, @Param("lastName") String lastName);
- 含有like关键字的查询:
在占位符上添加%,在查询方法的参数中就不需要添加%
- @Query("SELECT p FROM Person p WHERE p.lastName LIKE %?1% OR p.email LIKE %?2%")
- List<Person> testQueryAnnotationLikeParam(String lastName, String email);
在命名参数上添加%,在查询方法的参数中就不需要添加%
- @Query("SELECT p FROM Person p WHERE p.lastName LIKE %:lastName% OR p.email LIKE %:email%")
- List<Person> testQueryAnnotationLikeParam3(@Param("email") String email, @Param("lastName") String lastName);
- 在传递的参数上添加%
- @Query("SELECT p FROM Person p WHERE p.lastName LIKE ?1 OR p.email LIKE ?2")
- List<Person> testQueryAnnotationLikeParam2(String lastName, String email);
- 传递的参数: “%A%” ,"%[email protected]%"
使用原生的SQL 语句进行查询 设置 nativeQuery = true
@Query(value = "SELECT count(id) FROM jpa_persons", nativeQuery = true)
以上在@Query() 中写的类似sql 语句叫做 JPQL 是在JavaEE 中面向对象的查询语句,基于原生的SQL,JPQL 不支持INSERT,用save代替。但JPQL到SQL的转换无须开发者关心,JPQL解析器会负责完成这种转换,并负责执行这种转换的SQL语句来更新数据库。
- 使用原生的SQL 语句进行查询 设置 nativeQuery = true,f
@Query(value = "SELECT count(id) FROM jpa_persons", nativeQuery = true)
from 的后面接的 数据表名
参数传递的方式还是可以使用占位符和命名参数
多表
数据库中几个表之间往往有一对多,多对一,多对多的关系。如何使用SpringData JPA 体现在这种关系是关键点
(记住SpringData JPA 的底层实现使HIbernate,一些基本的处理都是HIbernate中的操作)
建立类之间的关系(表之间的关系)
/*
*类作为彼此的属性,使用@OneToMany @ManyToOne @ManyToMany 来表示类之间的关系,唯一需要注意的使=是,在这样的
*关系中多的一方是维护端,一的一端是被维护端,多对多任选;关注点在:要在被维护端进行声明 ,这是被维护端*/
//分类 和文章之间是一对多的关系
@Entities
@Table(name="tb_type")
class Type{
@Id
private Integer id;
private String name;
//表示与文章类之间的关系:一对多
@OneToMany(mappBy="type") //type 是在Article 类中Type类型的属性名
private Article article;
}
class Article{
private Integer id;
private String title;
private String content;
//表示artile 和type 之间的关系
@ManyToOne
private Type type
}
/*这样两个类之间的关系就建立起来了*/
总结:
语句对的书写:JPQL 面向对象,本地查询要修改nativeQuery= true,sql 面向数据表;参数:占位符和命名参数
- 删除/修改数据
在JpaRepository 中自定义了一个删除方式 :delectById(id)- 在Query注解中编写JPQL语句实现DELETE和UPDATA操作必须加上 @Modifying 注解,以通知Spring DATA这是一个DELETE或者UPDATA操作。
- UPDATA 和DELETE 操作需要使用事务,必须定义service层,在service层的方法上添加事务 操作。
默认情况下JPA的每个操作都是事务的,在默认的情况下,JPA的事务会设置为只读@Transational(readOnly = true),就是不能对数据库进行任何修改, 如果Query语句在执行的时候出现问题,将会回滚到执行前的状态
@Modifying 声明这是一个DELETE或者UPDATA的操作;@Transational 注释生命该方法的事务性,加上@Transational 本质上声明@Transational(readOnly = false)
@Modifying的返回值为:void 或者 int(表示改变的数据行数)
Delete/Updata 操作实现:@Modifying / @Trasational
1. 在Repository中定义的方法上添加@Modifying 和 @Trasational
public interface UserRepository extends JpaRepository<User,Integer> {
@Transactional
@Modifying
@Query("delete from User u where u.name =?1")
void DeleteUser(String name);
}
2. 在Serice 层对应的方法上添加注解 @Transational
Repostory:
@Modifying
@Query("delete from User u where u.name =?1")
void DeleteUser(String name);
Service:
@Transactional
@Override
public void TestModify(String name) {
测试Modify
userRepository.DeleteUser(name);
}
总结:
事务一般在service 层中进行处理,@Query @Modifying @Transational 综合时候
6. 使用SPEL表达式,在原生SQL语句中使用
'#{#entityName}'值为'Book'对象对应的数据表名称(book)。
@Query(value = "select * from #{#entityName} b where b.name=?1", nativeQuery = true)
‘#{#entityName}’ 获取到的是实体类的类名。实体类Book,使用@Entity注解后,spring会将实体类Book纳入管理。默认’#{#entityName}‘的值就是’Book’。
但是如果使用了 @Entity(name = “book”)来注解实体类Book,此时’#{#entityName}'的值就变成了’book’
到此,事情就明了了,只需要在用@Entity来注解实体类时指定name为此实体类对应的表名。在原生sql语句中,就可以把’#{#entityName}'来作为数据表名使用。
连表查询
4.SpringData JPA常用接口的解析
继承树:
Repository – CrudRepository – PagingAndSortingRepository – JpaRepository – xxxRepository
- CrudRepository : 定义了基本的crud 操作
save(entity) save(entities)
findOne(id):
findAll();
delete(id):
delete(entity);
delete(entities)
deleteAll()
exists() 根据主键查找是否存在这条数据
- PagingAndSortingRepository:定义了分页和排序查询
包含分页和排序的功能
带查找的排序 :findAll(Sort sort)
带排序的分页查询: findAll(Pageable pageable)
分页查询:findAll(Pageable)
构建Pageable
Pageable pageable = new PageRequest(0,1);
Page<User> page = userRepository.findAll(pageable);
注释:
PageRequest 是常用的Pageable 的子类
构造函数: public PageRequest(int page, int size) {} :当前要获取那一页,每一页的数据数量
public PageRequest(int page, int size, Sort sort) {} : 将当前页数据排序排序之后获取
可以通过Page的方法获得很多信息:
page.getTotalElements(); 数据的总数
page.getTotalPages(); 页数
page.getNumber(); 当前的页数
page.getContent(); 当前页数的所有元素
page.getNumberOfElements(); 当前页的数据总数
排序查询:findAll(Sort sort)
构建 Sort:
Sort.Order order = new Sort.Order(Sort.Direction.ASC,"id");
Sort sort = new Sort(order);
List list = userRepository.findAll(sort);
注释:
Order的参数:Sort.Direction.ASC 升序;Sort.Direction.DESC 降序;排序的数据
-
JpaRepository 接口:常用接口
findAll() : 获得所有数据 findAll(Sort sort) : 排序 save(entities) : 保存数据 flush() : 刷新数据 deleteInBatch(entities) : 删除数据
以上的接口是一个自上而下的继承树,通常使用的是JpaRepository。
- JpaSpecificationExecutor 接口详解
这个接口不属于上面的继承关系,是一个单独的接口。在实际的开发中使用的也比较多
在排序和分页的接口中中可以看见:分页,排序是没办法做任何过滤的,分页和排序的对象是所有数据
作用: Specification 定义了JPA critice 查询条件,在这个接口中的方法中传入Specification 为分页定义条件
源码:对于它的作用会更加清晰
public interface JpaSpecificationExecutor<T> {
Optional<T> findOne(@Nullable Specification<T> var1);
List<T> findAll(@Nullable Specification<T> var1);
Page<T> findAll(@Nullable Specification<T> var1, Pageable var2);
List<T> findAll(@Nullable Specification<T> var1, Sort var2);
long count(@Nullable Specification<T> var1);
}
使用:
1. xxxRepository 继承JpaRepository,JpaSpecificationExecutor
public interface UserRepositorySpecification extends JpaRepository<User,Integer>,JpaSpecificationExecutor<User>{}
2. 在Service层中构建Specification
public class ImSpecificationService implements SpecificationService {
@Autowired
UserRepositorySpecification userRepositorySpecification;
//测试Specification
@Override
public void TestSpecification() {
Pageable pageable = new PageRequest(0,1);
//构建Specification
Specification<User> specification = new Specification<User>() {
/**
*
* @param root: 将User 对象映射为 Root 可以通过它的对象获取对象中的各种字段
* @param criteriaQuery :查询条件的容器,存放查询条件;存放单个条件或者条件数组
* @param criteriaBuilder :构造查询条件,大于/小于/等于/like,比较对象
* @return predicate :定义查询条件;条件和比较的对象
*/
@Override
public Predicate toPredicate(Root<User> root, CriteriaQuery<?> criteriaQuery, CriteriaBuilder criteriaBuilder) {
Path path = root.get("id"); //查询过滤的对象,这里是id
//这个路径是 Root(User(id)),字段路径
//定义过滤条件
criteriaBuilder.gt(path,5);//条件是查询id >5 的数据进行分页
return criteriaBuilder.gt(path,5);
}
};
Page<User> page = userRepositorySpecification.findAll(specification,pageable);
}
}
总结:
JpaSpecificationExecutor 主要是为分页查询提供过滤条件