开放开源 | DeepKE:基于深度学习的开源中文关系抽取工具
本文转载自公众号:浙大 KG。
作者:余海阳
机构:浙江大学
代码地址: https://github.com/zjunlp/deepke
OpenKG 发布地址: http://openkg.cn/tool/deepke
一、系统简介
本系统基于深度学习,以统一的接口实现了目前主流的关系抽取模型。包括卷积神经网络、循环神经网络、注意力机制网络、图卷积神经网络、胶囊神经网络以及使用语言预训练模型等在内的深度学习算法。后续仍将持续更新,添加如端到端实体关系联合抽取等新模型。
二、主要算法简介
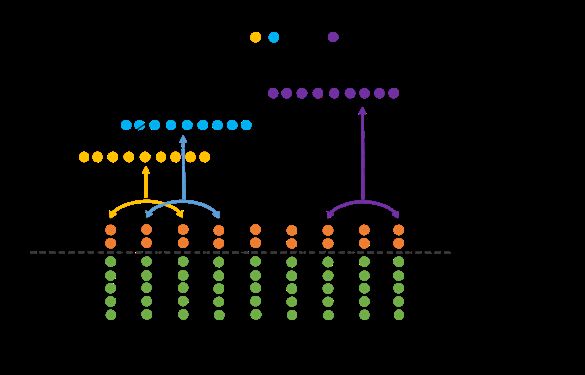
1. 基于 CNN 的关系抽取模型
使用 CNN 抽取每个句子中最重要的特征,得到句子的特征向量表示,并用于最终的分类。模型首先通过预训练或者随机初始化的 embedding 将句子中的词转化为词向量,同时使用句子中的实体词及其上下文相对位置表征实体词的位置向量;随后通过 CNN 网络抽取句子级别的特征,并使用池化方式得到压缩后的特征向量表示。最后将特征向量输入一个全连接的神经网络层对句子所表述的关系进行分类。
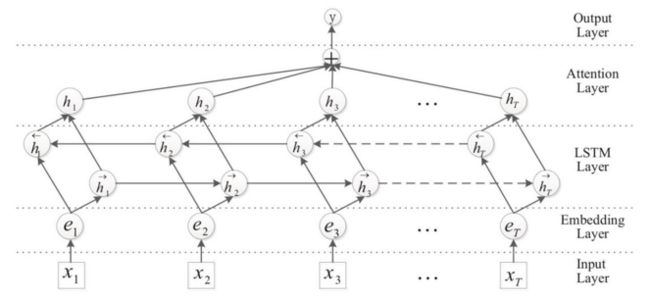
2. 基于 RNN 的关系抽取模型
与使用 CNN 网络抽取句子特征不同,本模型主要通过双向 LSTM 网络抽取句子的特征,并且加入 Attention 机制对输出的特征向量施加权重,最终生成有偏向性的向量表示;同样地,生成的向量输入全连接的神经网络层最终实现对关系的分类。
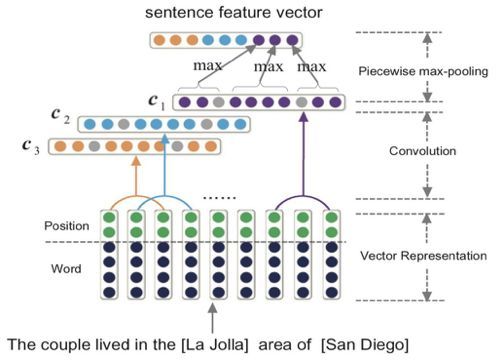
3、基于 PCNN 的远程监督关系抽取模型
在关系抽取任务中引入远程监督学习的方法,尤其是针对远程监督中的标记噪声问题,使用分段的 CNN(Piecewise CNN,简写为 PCNN)抽取句子特征向量表示的同时,考虑到同一个 Bag 中句子表达关系的不同重要性,引入了句子级别的Attention 机制。
句子特征向量表示: PCNN 与 CNN 模型抽取句子特征向量方法相同,组合词和词相对位置的 embedding 表示输入 CNN 模型进行卷积。不同的是在池化部分,使用分段池化取代前面的最大值池化操作。分段池化根据句子中两个实体的位置将句子分为三个片段,再分别进行池化操作,这样能捕捉句子中的结构信息以及更加细粒度的特征。
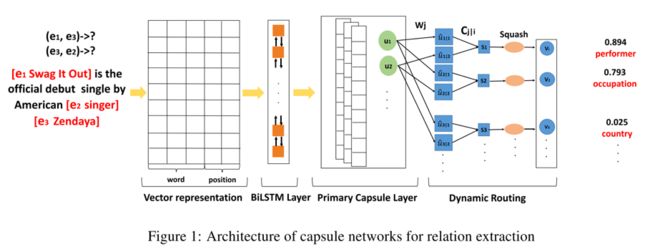
4. 基于 Capsule 的关系抽取模型
模型首先通过预训练的 embedding 将句子中的词转化为词向量;随后使用 BiLSTM 网络得到粗粒度的句子特征表示,再将所得结果输入到胶囊网络,首先构建出 primary capsule,经由动态路由的方法得到与分类结果相匹配的输出胶囊。胶囊的模长代表分类结果的概率大小。
5. 基于 Transformer 的关系抽取模型
模型使用 Transformer 的 encoder 部分编码句子信息。使用 multi-head attention 模块不断的抽取句子中重要的特征,并且使用残差网络的叠加方法,将注意力层得到的输出与输入拼接到一起并正则化。如此方式可以堆叠多层,更好的抽取句子信息。最后将 Transformer 的结果接一层全连接层得到最终的分类效果。

6. 基于 GCN 的关系抽取模型
GCN 在图像领域的成功应用证明了以节点为中心的局部信息聚合同样可以有效的提取图像信息。因此仿照在图像领域的应用方式,将方法迁移到关系抽取中,利用句子的依赖解析树构成图卷积中的邻接矩阵,以句子中的每个单词为节点做图卷积操作。如此就可以抽取句子信息,再经过池化层和全连接层即可做关系抽取的任务。
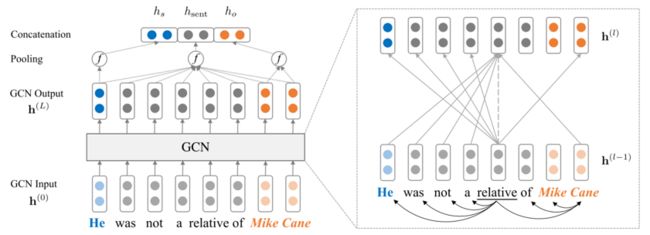
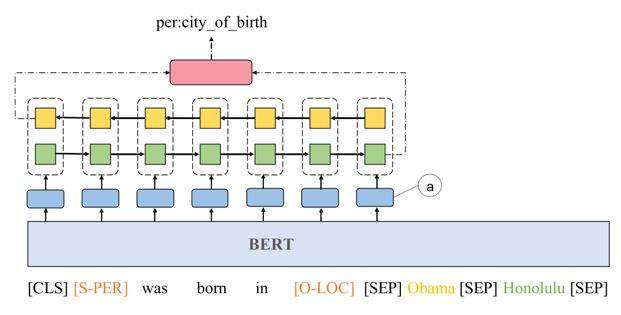
7. 基于 BERT 语言预训练模型的关系抽取模型
BERT 的问世证明了语言预训练模型对下游的 nlp 任务有很大的提升,可以帮助提升关系抽取的效果。简单的使用 BERT 语言预训练模型方式,将句子输入到 BERT 后,得到的结果输入到全连接层即可做关系抽取任务。实验结果表明可以取得相当不错的效果。
三、安装与使用
1. 首先推荐使用 Anaconda,可以更方便的管理python虚拟环境。在 Anaconda官网下载安装后,在终端输入:conda info 检查是否成功安装 conda。
2. 新建python虚拟环境。终端输入:conda create -n deepkeTest python=3.7,需要确认的命令时,输入 y,直到虚拟环境安装完成。此时终端中输入conda activate deepkeTest,即可进入新建的虚拟环境。
3. 安装python依赖包。终端输入命令:pip install -r requirements.txt,即可开始安装。若是安装速度较慢,建议添加pip国内镜像。具体方法为,终端输入命令:vim ~/.pip/pip.conf 打开pip配置文件,如果找不到该文件就新建一个。打开文件后写入如下内容:
[global]
index-url= https://mirrors.aliyun.com/pypi/simple/
[install]
trusted-host=mirrors.aliyun.com
写完保存之后,重新输入依赖包安装命令 pip install -r requirements.txt,即可大幅加快安装速度。
4. 安装完成后,即可开始使用本系统。终端输入:python main.py 即可立刻开始运行系统,此时为默认配置效果。具体运行效果如下:
===== start preprocess data =====
load raw files...
load data/origin/train.csv
load data/origin/test.csv
verify whether need split words...
need word segment, use jieba to split sentence
build sentence vocab...
after trim, keep words [6615 / 18645] = 35.48%
Directory 'data/out' do not exist; creating...
save vocab in data/out/vocab.pkl
build train data...
build test data...
build relation data...
save train data in data/out/train.pkl
save test data in data/out/test.pkl
===== end preprocess data =====
load data in data/out/vocab.pkl
load data in data/out/train.pkl
load data in data/out/test.pkl
CNN(
(embedding): Embedding(
(word_embed):Embedding(6615, 50, padding_idx=0)
(head_pos_embed):Embedding(102, 5, padding_idx=0)
(tail_pos_embed):Embedding(102, 5, padding_idx=0)
)
(mask_embed):Embedding(4, 3)
(convs): ModuleList(
(0): Conv1d(60, 100,kernel_size=(3,), stride=(1,), padding=(1,), bias=False)
(1): Conv1d(60, 100,kernel_size=(5,), stride=(1,), padding=(2,), bias=False)
)
(fc1):Linear(in_features=600, out_features=100, bias=True)
(fc2):Linear(in_features=100, out_features=10, bias=True)
(dropout):Dropout(p=0.3, inplace=False)
)
========== Starttraining ==========
Train Epoch: 1 [640/4000 (16%)] Loss:2.115848
Train Epoch: 1 [1280/4000 (32%)] Loss: 1.695553
Train Epoch: 1 [1920/4000 (48%)] Loss: 1.826675
Train Epoch: 1 [2560/4000 (63%)] Loss: 1.423478
Train Epoch: 1 [3200/4000 (79%)] Loss: 1.081029
Train Epoch: 1 [3840/4000 (95%)] Loss: 0.764394
Train Epoch: 1 [4000/4000 (100%)] Loss: 0.771318
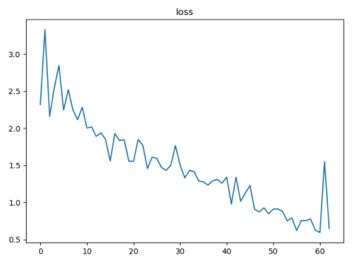
macro metrics: [p:0.8403, r:0.7970, f1:0.7709]
micro metrics: [p:0.7970, r:0.7970, f1:0.7970]
......
5. 其他配置详情见 deepke/config.py 文件。
参考文献
[1] Zeng, D., Liu, K., Lai, S., Zhou, G., Zhao, J.: Relation classification via convolutional deep neural network. In: COLING. pp. 2335–2344.ACL (2014)
[2] Zhou, P., Shi, W., Tian, J., Qi, Z., Li, B., Hao, H., Xu, B.: Attention-based bidirectional long short-term memory networks for relation classification. In:ACL (2). The Association for Computer Linguistics (2016)
[3] i, G., Liu, K., He, S., Zhao, J.: Distant supervision for relation extraction with sentence-level attention and entity descriptions. In: AAAI. pp. 3060–3066. AAAI Press (2017)
[4] Zhang N, Deng S, Sun Z, et al. Attention-based capsule networks with dynamic routingfor relation extraction[J]. arXiv preprint arXiv:1812.11321, 2018.
[5] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[C]//Advances in neural information processing systems. 2017: 5998-6008.
[6] Zhang Y, Qi P, Manning C D, et al. Graph Convolution over Pruned Dependency Trees Improves Relation Extraction[C]. Empirical Methods in Natural Language Processing, 2018: 2205-2215.
[7] Shi P, Lin J. Simple BERT Models for Relation Extraction and Semantic Role Labeling[J]. arXiv preprint arXiv:1904.05255, 2019.
OpenKG
开放知识图谱(简称 OpenKG)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

点击阅读原文,了解 DeepKE。