行人三维姿态与形状估计面试准备
1.SMPL
2.HMR
本文达到了实时的人体三维姿态与形状的估计,但是实际上测试最多能够达到5fps,可以在有2D-3D之间的对应关系来训练模型,也可以在没有2D-3D的情况下利用弱监督的方式训练模型,在人体存在遮挡或者截断的情况下仍然能够恢复出人体的三维模型,并且可以会恢复出人体的头部和肢体的朝向。
具体贡献点:(1)单幅RGB图像恢复人体的3Dmesh结构,主要的目标函数约束是三维关节点重投影回二维图像去拟合图像的二维关节点,但是仅靠这个约束难以获得较为理想的效果(约束过少);(2)HMR可以被在2D-3D数据之间不匹配的情况训练,只是在有3D数据(2D keypoints是一定有的)训练的模型效果最佳;(3)不是依据图像的 2Dkeypoints获得SMPL的形状beta和姿态sita参数,而是根据人体图像的像素来回归人体的参数;(4)模型可以在给出人体bounding box框的时候达到实时的效果;(5)在三维关节点估计和区域分割的模型上能够达到具有竞争力的效果。
目前的两阶段的方法,首先检测人体的二维关节点,利用二维关节点获得SMPL的参数,本文利用人体图像的像素信息,充分利用人体的像素信息,只利用二维关节点忽略很多有用的信息;本文输出人体三维mesh,在三维关节点和运行时间有优势;不利用2D-3D,只利用2D的信息(带有2d keypoints 标注信息)也可以训练,这样可以打开场景的限制(3D scan数据有实验场景的限制)
估计单幅图像的人体Mesh能够在前景和人体部位分割上得到大量的应用;在冲突和遮挡的情况下,总是恢复人体的三维mesh;本文输出的是人体三维关节点,具体而言是三维关节点(运动树结构)的旋转矩阵(而不是欧拉角),获得肢体和头部的朝向;(预测旋转矩阵可以确保肢体是对称和在有效的长度内???);模型会在人体的三维模型数据集中学习三维关节点旋转角度之间的限制。
目前问题的挑战:(1)缺少大规模的三维人体标注的in the wild 数据集,现有的数据集都是在有限的实验环境中获得的人体扫瞄的三维模型,这些数据集训练的三维模型在真实场景中的泛化能力较差;(2)单视角二维图像与三维映射之间的歧义,多个三维模型可以map到相同的二维信息(关节点或者轮廓信息);(3)生成器回归出SMPL的三维参数,鉴别器(会学习哪些参数符合人体学结构特征)判断参数是否符合人体学的结构特征,大多数现有的方法将人体姿态关节点的角度当成分类问题(将角度划分为一度一度的),这样的离散的角度的精度不足(角度的一点偏差对重投影回二维关节点的影响很大),本文采用一种迭代回归的方式获得三维模型的参数。
本文利用三维关节点来评估训练的模型,(本人认为可以用过mesh来衡量,都有了三维关节点可以利用SMPL拟合,得到SMPL模型呀),比两阶段的人体三维模型与姿态估计优,比单纯估计人体三维关节点的方法相当(在当时)。
训练的时候是需要人体二维关节点的,用来构成loss;一般是数据集带有的标注gt(比如 MS COCO),否则利用OpenPose获取二维关节点,所以自己的数据集可以利用Openpose构建(目前有更好的二维关节点检测算法,PIFPAF可以试一下,可以自己构建一个PTZ场景下的数据集,这样可以在图像域上,更为接近,恢复出来的效果应该更好);形状决定三维关节点的位置(宽,高和骨骼比列);
本文的损失函数:
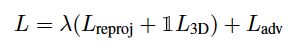


直接回归85维参数难以实现,所以本文借鉴前人工作,设计了迭代的三维回归器,三维回归器的输入是人体图像的feature map特证和上一次回归的85维参数,三维回归器估计的是residual ,然后
![]()
初始的85维参数为惨的均值,85维参数和输入特征是被简单级联在一起的,这样的效果不错。
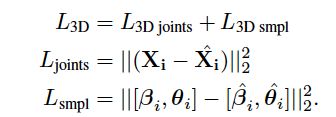
利用鉴别器网络鉴别产生的参数是否符合人体学结构学特征(身体部位的交叉以及极限的身体姿态以及形状)
鉴别器:为每个姿态的关节点设置一个鉴别器,然后为关节点设置了一个联合的关节点鉴别器捕获关节点的联合分布;当没有与2D gt对应的3Dgt的时候,会提高鉴别器损失函数的权重;本文提出来的生成对抗模型,没有经历崩塌的原因是除了对抗损失之外还有重投影损失,3D损失进行约束;在K+2个鉴别器中(K是三维姿态关节点),每个鉴别器的输出是【0-1】,代表着来自真实数据分布的概率。
带有2D keypoints 标注的二维数据集LSP, LSP-Extend, MPII,MS COCO;过滤了少于6个关节点可见的图像;带有2D和3D标注的数据集human3.6M和MPI-INF-3DHP;这两个数据集都是在有限的环境下获得的,本文利用Mosh方法获得了Human3.6M的SMPL模型。利用CMU, Human3.6M,Pose Prior数据集构成范围变化很广泛的鉴别器训练集。
所有的图像被resize到224*224应为编码网络是resnet50,人体区域裁剪是对角线像素为150大小;数据增强方法有随机scale, translated, and flipped;minibatch 64。
3维回归器的组成是两个带有1024个神经元的全连接层和一个dropout层,最后一层是85维的神经元的输出
对于形状鉴别器是两个10,5 全联接层, 对于每个姿态关节点会将sita角度利用罗格里格斯公司转换为旋转矩阵,然后通过两个32个神经元的嵌入式全联接网络;编码输出进入姿态的鉴别器网络,姿态的鉴别器网络是由10,5, 1和1024,1024,1
实验结果:

3.denseBody
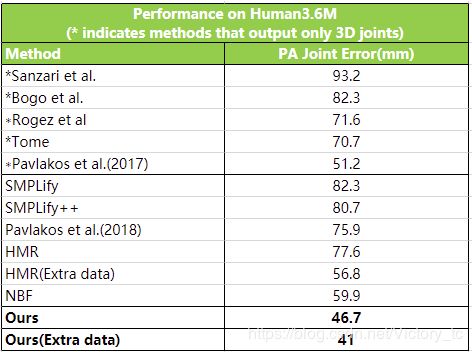
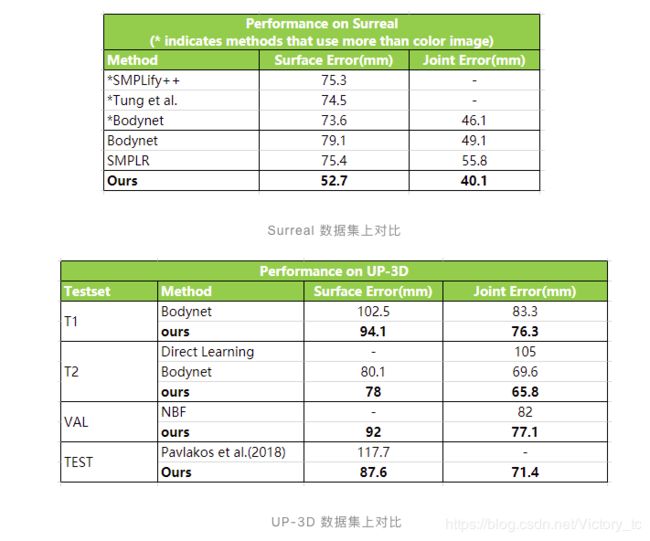
云从科技提出的基于单桢图像的3D人体重建技术,在Human3.6M、Surreal 和 UP-3D 三大数据集上创造了最新的世界纪录,将原有最低误差记录大幅降低 30%。
(1)在human 3.6M上的方法对比
(2)在surreal 和 UP-3D数据集上的误差
时间仅需5ms,达到了超越实时;单帧图像的 3D 重建技术不仅能输出骨骼关节点信息,更能同时预测大量的人体表面关键点信息,预测结果更加丰富,而且每个点的坐标都是 3D 的,能够体现不同躯干的纵深信息。传统 3D 重建技术大多需要连续的图像序列或是多视角的图像;在硬件设备上一般需要采用双目摄像机或者结构光摄像机等设备,因此在手机等便携设备上往往难以实现;另一方面,专用设备还会增加部署成本,增加大规模普及 3D 重建技术的难度。行业应用:这项技术可通过重要人员影像重建、医疗仿真肢体打印、虚拟试衣、美颜化妆、表情姿态动画合成等应用场景在大型商场、直播平台、美颜软件、影视特效制作等行业普及。
基于参数的学习模型,例如SMPL模型,将3D人体形状限制在低维线性空间,使CNN模型更加容易学习,但是受到线性模型的限制,其性能可能达到最优。
本文提出的方法没有结合任何参数化的人体模型,因此该网络的输出不会受到任何低维空间的限制;该方法的预测过程是一步到位的,没有依赖于中间任务和结果来预测 3D 人体。
研究的主要贡献点:
- 提出了一个端到端的方法,从单个彩色图像直接得到 3D 人体网格。为此,研究者开发了一种新型 3D 人体网格表示。它能够把 2D 图像中的完整人体编码为姿势和形状信息,无需依赖任何参数化的人体模型。
- 把 3D 人体估计的复杂度从两步降到了一步。该研究训练了一个编码器-解码器网络,可直接把输入 RGB 图像映射到 3D 表示,无需解决任何中间任务,如分割或 2D 姿态估计。
- 进行了多次实验来评估以上方法的效果,并与现有的最优方法进行对比。结果显示,该方法在多个 3D 数据集上实现了显著的性能提升,运行速度也更快。
本文用 UV 位置映射图来表示 3D 人体几何结构, UV 映射图作为一种物体表面的图片表达方式,经常被用来渲染纹理图。大多数的 3D 人体数据集提供的三维标注是基于 SMPL 模型的,SMPL 模型本身提供了一个自带的 UV 映射图,把人体切分成了 10 个区域。DensePose 里面提供了另一种人体切分的方式,并提供了一个 UV 映射图,将人体切分成了 24 个区域。我们实验了两种切分方式,SMPL 的 UV 映射图获得了更好的实验结果。因此,在我们的方法中,我们采用这个 UV 映射图来存储整个人体表面的三维位置信息。 本文选择了 256 的分辨率,它引入的 1 毫米全身精度误差可以忽略不计。另外,256 分辨率的 UV 映射图能够表示六万多个顶点,远多于 SMPL 的顶点数。
我们的网络采用编码器-解码器结构,输入是 256*256 的彩图,输出是 256*256 的 UV 位置映射图,其中编码器部分使用 ResNet-18,解码器是由四层上采样和卷积层组成。不同于以前的方法中需要仔细设计和融合多种不同损失函数的做法,我们直接针对预测的 UV 位置映射图进行监督和设计损失函数;为了平衡不同的身体区域对训练的影响,我们采用了权重掩模图来调整损失函数。此外,关节点附近的点的权重也进行了加重。

实现细节:
所有的图像都先做了对齐,使人位于正中。通过裁剪和缩放调整到 256x256,使得紧凑的边界框和图像边缘之间距离适中。图像经过了随机的平移、旋转、翻转和色彩抖动。我们要注意,数据增强的操作大都不简单,因为对应的真值数据也要进行相应的形变。
对于人体表面上的每个3D顶点,X和Y坐标对应于图像中的点,Z坐标是到root point的相对深度。我们将顶点的X、Y、Z坐标存储为UV图中的R、G、B颜色值。



4.常用数据集
5.openpose
Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields ;
输入一张图片,经过一个backbone(比如vgg,resnet,mobilenet),再经过6个stage,每个stage有两个branch,一个用来检测heatmap,一个用来检测vectmap。有了heatmap和vectmap就可以知道图片中所有关键点,再通过PAFs把点对应到每个人身上。

输入一幅图像,经过卷积网络提取特征,得到一组特征图,然后分成两个支路,分别使用CNN提取part confidence maps(图b)和part affinity fields(图c);
得到这两个信息后,我们使用图论中的bipartite matching(偶匹配)求出part association(图d),将同一个人的关节点连接起来,由于PAF自身的矢量性,使得生成的偶匹配很正确,最终合并为一个人的整体框架(图e)。
最后基于PAFs求multi-person parsing —把multi-person parsing问题转换成graphs问题—Hungarian algorithm(匈牙利算法)匈牙利算法
大概步骤:
1.以wh大小的彩色图像作为输入
2.经过VGG的前10层网络得到一个特征度F
3.网络分成两个循环分支,一个分支用于预测置信图S:关键点(人体关节),一个分支用于预测L:像素点在骨架中的走向(肢体)
4.第一个循环分支以特征图F作为输入,得到一组S1,L1
5.之后的分支分别以上一个分支的输出St-1,Lt-1和特征图F作为输入
6.网络最终输出S,L
7.损失函数计算S,L的预测值与groundtruth(S,L*)之间的L2范数;S和L的groundtruth根据标注的2D点计算,如果某个关键点标注缺失则不计算该点 。
(1)利用循环神经网络计算,CMP:confidence maps for part
(2)PAF:part affiity fields关节连接:(肢体)
(3)MultiPerson Parsing using PAFs
借助非最大抑制,从预测出的confidence maps得到一组离散的关键点候选位置
6.PIFPAF
7.Hourglass 沙漏网络
8.keep it SMPL
本文的系统叫做:SMPLify, 输入单幅RGB图像,(1)利用Deep Cut CNN去预测人体的二维身体关节点获得关节点的置信度,然后利用SMPL模型去拟合二维关节点。(2)提出胶囊结构防止身体各部位的冲突,每个胶囊有对应的半径和轴长,设计回归器(线性回归器)从身体的形状参数获得胶囊参数(SMPL利用形状去确定关节点的位置),通过三维姿态去放置胶囊。
本文提出了首次提出 Automatic Estimation of 3D Human Pose and Shape from a Single Image,而且实验证明二维关节点蕴含了丰富的人体形状的信息。
难点:(1)人体身体结构的复杂(链式结构),而且会出现遮挡,表观变化,光照变化; (2)3D到二维自身存在这歧义
本文在the Leeds Sports, HumanEva, and Human3.6M datasets数据集比较了恢复出来的三维关节点,是当时最好的方法;设计的 目标函数的目的是让三维关节点最大程度地与二维关节点融合。
实际内容:(1)构建交融项防止身体不同部位的融合,交融项的是由胶囊结构构建而来,胶囊的维度是由模型形状线性回归而来,交融项防止了不正确的人体怪物;(2)构建了中性的SMPL模型;(3)引入姿态先验,使用Mosh利用SMPL模型拟合CMU mocap marker data。
sita确定关节点的连接方式,J(beta)确定关节点的位置,R(sita)是通过sita的全局链式转换;通过形状的回归模型确定胶囊的半径和轴长。
目标函数:

姿势先验,也就是损失函数的第二项是膝盖和肘部的姿态旋转的约束,利用指数函数强烈的约束非自然的旋转情况,当关节点没有弯曲的时候sita等于零,负值是正常的所以惩罚小,正值是不正常的所以惩罚大。
利用CMU mocap marker data 训练姿势先验,利用高斯分布来拟合数据集中的姿态信息
将胶囊模型模型近似为一个球,物理上不相交的胶囊进行loss约束
更具形状先验直接对beta进行约束
9.Unite the people: Closing the Loop Between 3D and 2D Human Representations
贡献点:产生拥有丰富标注信息的UP-3D数据集,该数据集可以用于二维姿态(91个人体关节点)估计,身体部位(31个部位)分割,以及3d人体姿态与性状的估计。
获得人体二维姿态的标注数据集是容易的(比如the MPIIHumanPose dataset);本文采用的3D人体姿态和形状的估计(3D Fits)是在SMPLify的基础上做的进一步改进,使用随机森林的方法进行3维姿态的估计,速度上比SMPLify明显地变快了,在Human EVA,Human 3.6, 以及LSP(9.3%的更高的品质的人体姿态估计)。
SMPLify对于形状的估计只能通过人体的关节点之间的连接长度来决定,要准确的估计人体的形状,需要引入额外的人体形状监督信息;最佳的形状监督信息,是将恢复出来的SMPL模型的surface重投影回图像的二维轮廓中;引入轮廓监督信息的损失函数为:

本文通过决策树利用91个二维关节点预测SMPL的beta和sita(回归的是旋转矩阵,直接回归欧拉角不连续)
10.densepose