背景
让我们继续看看Binder的初始化流程。上一篇,经过千辛万苦终于到了内核驱动中的open方法。现在到了内存映射的阶段,也是binder为什么高效的主要原因。
注意下面的源码,是来自Android的Linux 内核 3.18
如果遇到问题请到:https://www.jianshu.com/p/4399aedb4d42
正文
binder_ioctl
我们继续回顾一下在用户控件binder初始化的二部分:
if ((ioctl(bs->fd, BINDER_VERSION, &vers) == -1) ||
(vers.protocol_version != BINDER_CURRENT_PROTOCOL_VERSION)) {
fprintf(stderr,
"binder: kernel driver version (%d) differs from user space version (%d)\n",
vers.protocol_version, BINDER_CURRENT_PROTOCOL_VERSION);
goto fail_open;
}
ioctl这个方法往往可以在系统做io操作,可以根据协议往内部文件内部的读写数据。也是涉及到了从用户态往内核态的转化。但是我不打算分析用户到内核的过程。根据数据结构:
static const struct file_operations binder_fops = {
...
.unlocked_ioctl = binder_ioctl,
.compat_ioctl = binder_ioctl,
...
};
我们直接看看binder_ioctl中处理。
static long binder_ioctl(struct file *filp, unsigned int cmd, unsigned long arg)
{
int ret;
struct binder_proc *proc = filp->private_data;
struct binder_thread *thread;
...
//出错等待队列
ret = wait_event_interruptible(binder_user_error_wait, binder_stop_on_user_error < 2);
if (ret)
goto err_unlocked;
binder_lock(__func__);
//绑定thread
thread = binder_get_thread(proc);
if (thread == NULL) {
ret = -ENOMEM;
goto err;
}
switch (cmd) {
...
case BINDER_VERSION: {
struct binder_version __user *ver = ubuf;
if (size != sizeof(struct binder_version)) {
ret = -EINVAL;
goto err;
}
if (put_user(BINDER_CURRENT_PROTOCOL_VERSION,
&ver->protocol_version)) {
ret = -EINVAL;
goto err;
}
break;
}
default:
ret = -EINVAL;
goto err;
}
ret = 0;
err:
if (thread)
thread->looper &= ~BINDER_LOOPER_STATE_NEED_RETURN;
binder_unlock(__func__);
wait_event_interruptible(binder_user_error_wait, binder_stop_on_user_error < 2);
if (ret && ret != -ERESTARTSYS)
pr_info("%d:%d ioctl %x %lx returned %d\n", proc->pid, current->pid, cmd, arg, ret);
err_unlocked:
trace_binder_ioctl_done(ret);
return ret;
}
别看这么多东西,实际上做的事情很少。首先经过binder_user_error_wait的校验,这个的意思是当全局变量binder_user_error_wait 这个链表大于而的时候,这个等待队列将会进入到等待状态。否则的话则继续向下走。
接着我们将会遇到binder中第二个重要的对象,binder_thread.还记得上一篇讲过的吧,此时在文件中私有数据就是binder_proc.此时把binder_thread初始化起来。
最后校验了binder的version是否符合要求,符合则返回让用户进程的binder继续初始化。
binder_get_thread
我们稍微看看binder_thread的初始化.
static struct binder_thread *binder_get_thread(struct binder_proc *proc)
{
struct binder_thread *thread = NULL;
struct rb_node *parent = NULL;
struct rb_node **p = &proc->threads.rb_node;
//寻找是否已经存在一样pid的binder_thread
while (*p) {
parent = *p;
thread = rb_entry(parent, struct binder_thread, rb_node);
if (current->pid < thread->pid)
p = &(*p)->rb_left;
else if (current->pid > thread->pid)
p = &(*p)->rb_right;
else
break;
}
if (*p == NULL) {
thread = kzalloc(sizeof(*thread), GFP_KERNEL);
if (thread == NULL)
return NULL;
binder_stats_created(BINDER_STAT_THREAD);
thread->proc = proc;
thread->pid = current->pid;
init_waitqueue_head(&thread->wait);
INIT_LIST_HEAD(&thread->todo);
rb_link_node(&thread->rb_node, parent, p);
rb_insert_color(&thread->rb_node, &proc->threads);
thread->looper |= BINDER_LOOPER_STATE_NEED_RETURN;
thread->return_error = BR_OK;
thread->return_error2 = BR_OK;
}
return thread;
}
这里面将会遇到第一个binder中重要的红黑树管理。如果熟悉我的红黑树那一篇文章的话。就能明白首先现充根本开始查找,看看有没有已经存在了pid一致的线程,有则跳出返回,没有则继续向下找,直到为空跳出循环。pid是指当前进程的id。
此时我们在上面的循环已经找到了合适的位置,其父亲是什么了。接着申请内存,绑定binder_proc,pid,初始化binder_thread中的等待队列,以及todo队列,把当前的binder_thread插入到红黑树中。就完成了binder_thread的初始化。
换句话说,不要被这个名字欺骗了,它并不是我们说的真正意义上通过内核申请线程诞生出来的线程(kthreadd诞生出来的线程,本质上是一个fork出来的轻量级进程)。而是通过内核的等待队列实现线程一样的效果。
内核的等待队列的实现实际上十分简单,和cas设计一致就是通过一个状态来判断是否继续进行该线程下面的工作,不满足条件则立即通过schedule()切换cpu调度。
这个东西有机会再聊聊吧。
binder_mmap
接下来看看用户空间binder的第三步
bs->mapsize = mapsize;
bs->mapped = mmap(NULL, mapsize, PROT_READ, MAP_PRIVATE, bs->fd, 0);
if (bs->mapped == MAP_FAILED) {
fprintf(stderr,"binder: cannot map device (%s)\n",
strerror(errno));
goto fail_map;
}
return bs;
这里我们稍微跟踪一下从内核开始mmap的运行原理
跟踪内核mmap的内核源码
经过查阅mmap在用户空间在用户空间由mmap2实现,我们直接找mmap2的实现。
文件:/arch/tile/kernel/sys.c
SYSCALL_DEFINE6(mmap2, unsigned long, addr, unsigned long, len,
unsigned long, prot, unsigned long, flags,
unsigned long, fd, unsigned long, off_4k)
{
#define PAGE_ADJUST (PAGE_SHIFT - 12)
if (off_4k & ((1 << PAGE_ADJUST) - 1))
return -EINVAL;
return sys_mmap_pgoff(addr, len, prot, flags, fd,
off_4k >> PAGE_ADJUST);
}
实际上,所有系统的mmap都会由这个处理核心。
文件:/mm/mmap.c
SYSCALL_DEFINE6(mmap_pgoff, unsigned long, addr, unsigned long, len,
unsigned long, prot, unsigned long, flags,
unsigned long, fd, unsigned long, pgoff)
{
struct file *file = NULL;
unsigned long retval = -EBADF;
...
flags &= ~(MAP_EXECUTABLE | MAP_DENYWRITE);
retval = vm_mmap_pgoff(file, addr, len, prot, flags, pgoff);
out_fput:
if (file)
fput(file);
out:
return retval;
}
核心vm_mmap_pgoff,最后调用do_mmap_pgoff
unsigned long do_mmap_pgoff(struct file *file, unsigned long addr,
unsigned long len, unsigned long prot,
unsigned long flags, unsigned long pgoff,
unsigned long *populate)
{
struct mm_struct *mm = current->mm;
vm_flags_t vm_flags;
*populate = 0;
/*
* Does the application expect PROT_READ to imply PROT_EXEC?
*
* (the exception is when the underlying filesystem is noexec
* mounted, in which case we dont add PROT_EXEC.)
*/
if ((prot & PROT_READ) && (current->personality & READ_IMPLIES_EXEC))
if (!(file && (file->f_path.mnt->mnt_flags & MNT_NOEXEC)))
prot |= PROT_EXEC;
if (!len)
return -EINVAL;
if (!(flags & MAP_FIXED))
addr = round_hint_to_min(addr);
/* Careful about overflows.. */
len = PAGE_ALIGN(len);
if (!len)
return -ENOMEM;
/* offset overflow? */
if ((pgoff + (len >> PAGE_SHIFT)) < pgoff)
return -EOVERFLOW;
/* Too many mappings? */
if (mm->map_count > sysctl_max_map_count)
return -ENOMEM;
/* Obtain the address to map to. we verify (or select) it and ensure
* that it represents a valid section of the address space.
*/
addr = get_unmapped_area(file, addr, len, pgoff, flags);
if (addr & ~PAGE_MASK)
return addr;
/* Do simple checking here so the lower-level routines won't have
* to. we assume access permissions have been handled by the open
* of the memory object, so we don't do any here.
*/
vm_flags = calc_vm_prot_bits(prot) | calc_vm_flag_bits(flags) |
mm->def_flags | VM_MAYREAD | VM_MAYWRITE | VM_MAYEXEC;
if (flags & MAP_LOCKED)
if (!can_do_mlock())
return -EPERM;
if (mlock_future_check(mm, vm_flags, len))
return -EAGAIN;
if (file) {
struct inode *inode = file_inode(file);
switch (flags & MAP_TYPE) {
case MAP_SHARED:
if ((prot&PROT_WRITE) && !(file->f_mode&FMODE_WRITE))
return -EACCES;
/*
* Make sure we don't allow writing to an append-only
* file..
*/
if (IS_APPEND(inode) && (file->f_mode & FMODE_WRITE))
return -EACCES;
/*
* Make sure there are no mandatory locks on the file.
*/
if (locks_verify_locked(file))
return -EAGAIN;
vm_flags |= VM_SHARED | VM_MAYSHARE;
if (!(file->f_mode & FMODE_WRITE))
vm_flags &= ~(VM_MAYWRITE | VM_SHARED);
/* fall through */
case MAP_PRIVATE:
if (!(file->f_mode & FMODE_READ))
return -EACCES;
if (file->f_path.mnt->mnt_flags & MNT_NOEXEC) {
if (vm_flags & VM_EXEC)
return -EPERM;
vm_flags &= ~VM_MAYEXEC;
}
if (!file->f_op->mmap)
return -ENODEV;
if (vm_flags & (VM_GROWSDOWN|VM_GROWSUP))
return -EINVAL;
break;
default:
return -EINVAL;
}
} else {
switch (flags & MAP_TYPE) {
case MAP_SHARED:
if (vm_flags & (VM_GROWSDOWN|VM_GROWSUP))
return -EINVAL;
/*
* Ignore pgoff.
*/
pgoff = 0;
vm_flags |= VM_SHARED | VM_MAYSHARE;
break;
case MAP_PRIVATE:
/*
* Set pgoff according to addr for anon_vma.
*/
pgoff = addr >> PAGE_SHIFT;
break;
default:
return -EINVAL;
}
}
/*
* Set 'VM_NORESERVE' if we should not account for the
* memory use of this mapping.
*/
if (flags & MAP_NORESERVE) {
/* We honor MAP_NORESERVE if allowed to overcommit */
if (sysctl_overcommit_memory != OVERCOMMIT_NEVER)
vm_flags |= VM_NORESERVE;
/* hugetlb applies strict overcommit unless MAP_NORESERVE */
if (file && is_file_hugepages(file))
vm_flags |= VM_NORESERVE;
}
addr = mmap_region(file, addr, len, vm_flags, pgoff);
if (!IS_ERR_VALUE(addr) &&
((vm_flags & VM_LOCKED) ||
(flags & (MAP_POPULATE | MAP_NONBLOCK)) == MAP_POPULATE))
*populate = len;
return addr;
}
Linux内存管理以及进程地址空间基础知识回顾
说到操作系统的内存管理。首先有逻辑地址,线性地址,物理地址。我们直观的看名称就知道物理内存地址对应着主存上面的物理意义上的存储单元地址,对应着芯片上级上的内存单元;
线性地址 是一个32位的操作符,最高可以达到4G地址;
而逻辑地址对应的是机器语言读取每一个命令和操作数的地址,每一个逻辑地址对应着一个段和偏移量。
但实际上由于操作物理内存操作复杂,往往不可能由上层直接操作物理内存。因此各大操作系统会在内核帮你做一次转化,通过逻辑地址根据某种规律转化到线性地址最后再转化到物理内存,让我们找到物理层面上的存储单元。
那么从物理内存到逻辑内存有这么一些管理方式:
- 1 .段式管理
-
- 页式管理
-
- 段页式管理
这里我只聊聊Linux的分页式管理。Linux的分页管理。
首先先分清楚页式和段式管理的区别。
段式内存管理:段可以给每一个程序分配不同的线性地址。要做到逻辑地址往线性地址转化。
页式管理:每一页可以给为每个线性地址映射到物理地址。
段页式管理:先经过一个段表管理之后再去找到一个页表,相当于页式管理+段式管理。
Linux中进程的实现很大程度依赖内存的分页式管理。而Linux不选择分段式管理,一个是分段式对内存碎片化管理不是十分好的方案,反而分页式管理的方案能够利用上碎片物理地址;其次,当所有的进程都在使用同一个段寄存器,说明就能共享线性地址;而且大部分处理器对段的支持有限,Linux作为一个开源的移植性强的系统,必须兼容大部分主流的处理器。
这里稍微介绍一下Linux中三级分页内存管理,以32位机为例子:
一个基础的内存页式管理包含下面几个结构:
- 目录 最高10位
- 页表 中间 10位
- 偏移量 最后12位
线性地址转化为为物理地址在这里需要两步,第一步先通过目录表指向哪个页表,再从页表指向哪个页框,最后再通过页框的偏移量,找到页中的位置。

值得注意的是,这里面有一概念,页和页框。线性地址被分以固定长度为单位的组被称为页。页内连续的地址被映射到连续的物理地址。分页单元把RAM分成固定长度的页框。换句话说,页是一组数据,页框是物理地址。
而Linux四级页面是在这个基础上进行了强化,目的是为了兼容64位处理器。
这里有四种页表:
- 页全局目录
- 页上级目录
- 页中间目录
- 页表

这么设计有什么巧妙?我们增加一个中间目录。还记得后端大佬常说的一句话,没有什么问题不能通过增加一个中间键来解决。实际上思路也是来源这里。当我们运行32位且没有启动物理扩展的时候,页上级目录,页中间目录全部为0,这样就能相当于取消掉了页上级目录和页中间目录等于一个二级分页。当我们使用64位的时候,通过页上级目录,页中间目录也就等效的增加了更加多的页面了。
进程地址基础
在Linux有这么一个结构体mm_struct代表着Linux中进程的内存描述符。换句话说就是通过mm_struct来代表内存进行管理。所有的内存描述符都存放到一个双向链表mmlist。链表的第一个元素是init_mm,是进程0使用的(是内核初始化的第一个进程用来维护tss的全局表GDT等)。同时为了查询速度,mm_struct也会插入到一个根部为 mm_rb的红黑树中。
在这里面有一个关键的结构体vm_area_struct 代表着线性区描述符。每一个线性区代表着线性地址区间。进程中所有的线性区都是由简单的链表联系起来。vm_area_struct也会插入到一个根部为vm_rb红黑树中,进行管理。
回到mmap中
这里做了以下几个事情,之后我会分析mmkv源码的时候详细摊开来分析:
- 1.检测从用户空间传下来了想要申请的大小。首先要检测申请下来的长度是否合法就是不为0。
/* align addr on a size boundary - adjust address up/down if needed */
#define _ALIGN_UP(addr,size) (((addr)+((size)-1))&(~((size)-1)))
#define _ALIGN(addr,size) _ALIGN_UP(addr,size)
/* to align the pointer to the (next) page boundary */
#define PAGE_ALIGN(addr) _ALIGN(addr, PAGE_SIZE)
这里的计算很简单实际上就是把len对其pagesize(12位),在pagesize的基础上加上len。
接着看看偏移量是否合法,偏移量是否合法,有没有出现非法的情况,偏移量加上len出现小于当前页面偏移量。
最后看看内存描述符mm_struct中的map_count 是否达到内存描述符容许管理的线性区极限。
-
- get_unmapped_area去寻找空闲的线性区。寻找线性区的时候会遇到两种线性区。第一种是从线性地址0x40000000开始往高端地址增长。第二种真好从用户态堆栈开始向低端地址增长。现在这里是往高端地址增长。
值得注意的是,在这个方法会做一次检测此时申请的地址是否在TASK_SIZE之内。这个TASK_SIZE就是罗升阳常说用户空间分配的0~3G用户空间分配地址。这个大小就是TASK_SIZE,可以被内核态和用户态同时访问。当到了3G+896M+8M ~ 4G就是内核空间分配的线性区,为了和用户空间的线性区vm_area_struct作区分,内核态的线性区结构体为vm_struct。
3.根据上面传下来的vm_flag做处理。此时传下来的是MAP_PRIVATE,此时file存在。判断当前file是否合法,有没有实现mmap的方法指针。
4.mmap_region 将会把刚才找到空闲的线性地址调用slab分配函数kmem_cache_zalloc在内存生成vm_area_struct并插入到链表和红黑树中,并且调用file的mmap操作符。
unsigned long mmap_region(struct file *file, unsigned long addr,
unsigned long len, vm_flags_t vm_flags, unsigned long pgoff)
{
struct mm_struct *mm = current->mm;
struct vm_area_struct *vma, *prev;
int error;
struct rb_node **rb_link, *rb_parent;
unsigned long charged = 0;
...
munmap_back:
....
/*
* Determine the object being mapped and call the appropriate
* specific mapper. the address has already been validated, but
* not unmapped, but the maps are removed from the list.
*/
vma = kmem_cache_zalloc(vm_area_cachep, GFP_KERNEL);
if (!vma) {
error = -ENOMEM;
goto unacct_error;
}
vma->vm_mm = mm;
vma->vm_start = addr;
vma->vm_end = addr + len;
vma->vm_flags = vm_flags;
vma->vm_page_prot = vm_get_page_prot(vm_flags);
vma->vm_pgoff = pgoff;
INIT_LIST_HEAD(&vma->anon_vma_chain);
if (file) {
if (vm_flags & VM_DENYWRITE) {
error = deny_write_access(file);
if (error)
goto free_vma;
}
if (vm_flags & VM_SHARED) {
error = mapping_map_writable(file->f_mapping);
if (error)
goto allow_write_and_free_vma;
}
/* ->mmap() can change vma->vm_file, but must guarantee that
* vma_link() below can deny write-access if VM_DENYWRITE is set
* and map writably if VM_SHARED is set. This usually means the
* new file must not have been exposed to user-space, yet.
*/
vma->vm_file = get_file(file);
error = file->f_op->mmap(file, vma);
...
addr = vma->vm_start;
vm_flags = vma->vm_flags;
} else if (vm_flags & VM_SHARED) {
...
}
...
return addr;
}
注意,在mmap调用系统调用的时候,Linux并没有把实际的物理页面和对应的线性区互相绑定起来。仅仅代表找到了一个空闲的区域对象,并且管理起来。此时交给驱动进行映射管理。如果是普通的文件则会把操作映射绑定延迟到数据读出写入。
回到Binder的mmap
根据上面的操作符,binder_mmap方法中。这里将会到这里还是分步分析。
binder_mmap 第一步准备内核空间的线性区
static int binder_mmap(struct file *filp, struct vm_area_struct *vma)
{
int ret;
struct vm_struct *area;
struct binder_proc *proc = filp->private_data;
const char *failure_string;
struct binder_buffer *buffer;
if (proc->tsk != current)
return -EINVAL;
//限制映射大小
if ((vma->vm_end - vma->vm_start) > SZ_4M)
vma->vm_end = vma->vm_start + SZ_4M;
...
//判断是否可写
if (vma->vm_flags & FORBIDDEN_MMAP_FLAGS) {
ret = -EPERM;
failure_string = "bad vm_flags";
goto err_bad_arg;
}
vma->vm_flags = (vma->vm_flags | VM_DONTCOPY) & ~VM_MAYWRITE;
//上锁,此时需要做不可被打扰的分配线性区操作
mutex_lock(&binder_mmap_lock);
if (proc->buffer) {
ret = -EBUSY;
failure_string = "already mapped";
goto err_already_mapped;
}
area = get_vm_area(vma->vm_end - vma->vm_start, VM_IOREMAP);
if (area == NULL) {
ret = -ENOMEM;
failure_string = "get_vm_area";
goto err_get_vm_area_failed;
}
proc->buffer = area->addr;
proc->user_buffer_offset = vma->vm_start - (uintptr_t)proc->buffer;
mutex_unlock(&binder_mmap_lock);
...
}
首先,我们可以看到首先Linux内核先限制了每一次从内核用户空间映射下内核空间最大只能4M。
其次将会检验这块线性区是否能够读写。还记得我在上面写的此时打开binder模式是读写模式,所以能够正常进行下去。
最后会通过get_vm_area获取一段大小和vm_area_struct大小一致的内核线性区vm_struct。此时把内核线性区的地址交给buffer_proc代表注册进入binder驱动中的进程对象。这样binder_proc就持有了当前映射对应的内核线性区。此时,已经知道用户空间的线性区,此时采用的策略不是存起来,而是通过加减来计算地址。
每个进程对应映射区的内核线性区 + user_buffer_offset = 每个进程映射区的用户态线性区
有了这些基础数据之后,就能为快速通过binder快速在内核态地址和用户态快速切换。
binder_mmap 第二步开始为binder_proc绑定物理页
proc->pages = kzalloc(sizeof(proc->pages[0]) * ((vma->vm_end - vma->vm_start) / PAGE_SIZE), GFP_KERNEL);
if (proc->pages == NULL) {
ret = -ENOMEM;
failure_string = "alloc page array";
goto err_alloc_pages_failed;
}
proc->buffer_size = vma->vm_end - vma->vm_start;
vma->vm_ops = &binder_vm_ops;
vma->vm_private_data = proc;
if (binder_update_page_range(proc, 1, proc->buffer, proc->buffer + PAGE_SIZE, vma)) {
ret = -ENOMEM;
failure_string = "alloc small buf";
goto err_alloc_small_buf_failed;
}
- 1.我们会为buffer_proc中pages的数组通调用kzalloc从内核的缓存中申请内存。pages就是代表了页框的数据结构。申请的大小为此时vma大小可以分配多少4kb大小页框。
- 2.此时申请出来的内核缓冲区大小刚好也是vma的大小。
- 3.此时为vma的操作设置操作用的方法指针,把binder_proc设置为vma私有数据。
-
- 此时我们只是在内存中准备好了象征内核虚拟空间的描述符,我们还需要binder_update_page_range 真实的绑定的物理页面。
让我们来聊聊binder_update_page_range吧。
binder_update_page_range
static int binder_update_page_range(struct binder_proc *proc, int allocate,
void *start, void *end,
struct vm_area_struct *vma)
{
void *page_addr;
unsigned long user_page_addr;
struct vm_struct tmp_area;
struct page **page;
struct mm_struct *mm;
...
if (end <= start)
return 0;
...
// 第一步
if (vma)
mm = NULL;
else
mm = get_task_mm(proc->tsk);
if (mm) {
down_write(&mm->mmap_sem);
vma = proc->vma;
if (vma && mm != proc->vma_vm_mm) {
...
vma = NULL;
}
}
if (allocate == 0)
goto free_range;
if (vma == NULL) {
...
goto err_no_vma;
}
//第二步 绑定物理页
for (page_addr = start; page_addr < end; page_addr += PAGE_SIZE) {
int ret;
page = &proc->pages[(page_addr - proc->buffer) / PAGE_SIZE];
BUG_ON(*page);
*page = alloc_page(GFP_KERNEL | __GFP_HIGHMEM | __GFP_ZERO);
if (*page == NULL) {
...
goto err_alloc_page_failed;
}
tmp_area.addr = page_addr;
tmp_area.size = PAGE_SIZE + PAGE_SIZE /* guard page? */;
ret = map_vm_area(&tmp_area, PAGE_KERNEL, page);
if (ret) {
...
goto err_map_kernel_failed;
}
user_page_addr =
(uintptr_t)page_addr + proc->user_buffer_offset;
ret = vm_insert_page(vma, user_page_addr, page[0]);
if (ret) {
...
goto err_vm_insert_page_failed;
}
/* vm_insert_page does not seem to increment the refcount */
}
if (mm) {
up_write(&mm->mmap_sem);
mmput(mm);
}
return 0;
...
}
这里逻辑上分为2步。
-
- 先验证当前的vma是否有效,无效则从当前的进程描述符获取内存描述符,再取出binder_proc中的vma(用户空间的虚拟内存线性区)做校验。是的则取出vma作为新的vma。
- 2.绑定物理页。在上层函数为数组申请了页框数组的内存,这里就要通过循环,从vm的start开始到end,每隔4kb申请一次页框(因为Linux内核中是以4kb为一个页框,这样有利于Linux处理简单)。每一次通过alloc_page通过伙伴算法去申请物理页面,最后通过map_vm_area把vm_area(内核空间的线性区)和物理地址真正的绑定起来。根据计算上面总结,我们同时可以计算出每一页对应的用户空间的页面地址多少,并且最后插入到pagetable(页表)中管理。
在第二步才真正的绑定起Linux的物理内存。这里重新一次整个mmap映射中,我们先申请好了物理内存,接着再绑定物理内存和页框描述符,让页框产生实际意义,这里我们准备好了内核的物理的内存。
别忘了,我们通过调用mmap返回的是vma的start地址,而我们的终极目的就是为了让binder的binder_proc和进程映射到同一物理地址中。此时我们并没有真的使用这段内存,因此最好的办法就是申请一段大小正好需要的共享一段物理页交给应用层。
binder_mmap第三步
buffer = proc->buffer;
INIT_LIST_HEAD(&proc->buffers);
list_add(&buffer->entry, &proc->buffers);
buffer->free = 1;
binder_insert_free_buffer(proc, buffer);
proc->free_async_space = proc->buffer_size / 2;
barrier();
proc->files = get_files_struct(current);
proc->vma = vma;
proc->vma_vm_mm = vma->vm_mm;
/*pr_info("binder_mmap: %d %lx-%lx maps %p\n",
proc->pid, vma->vm_start, vma->vm_end, proc->buffer);*/
return 0;
此时,代表着进程对象的结构体binder_proc就已经映射到了内核空间中,而这个代表着进程映射到内核空间的对象就是binder_buffer。设置好proc中必要的参数,如vma,当前的文件描述符。并且binder_buffer加入到proc->buffers这个链表中,且此时新申请的buffer是一个等待使用的内核缓存区,因此加入到名为free的空闲缓存区的红黑树中。
binder_buffer内存管理
方法binder_insert_free_buffer值得注意:
static size_t binder_buffer_size(struct binder_proc *proc,
struct binder_buffer *buffer)
{
if (list_is_last(&buffer->entry, &proc->buffers))
return proc->buffer + proc->buffer_size - (void *)buffer->data;
return (size_t)list_entry(buffer->entry.next,
struct binder_buffer, entry) - (size_t)buffer->data;
}
获取binder_buffer 大小
这里我们稍微探讨一下binder中的binder_buffer的内核缓冲的内存管理机制吧。
binder_buffer作为内核缓冲区,往往承担着Binder驱动中数据的承载。我们思考一下,如果我们来设计binder_buffer,需要什么数据,第一个目标进程是什么,第二用于代表binder工作事务的对象,第三,我们还需要数据。下面就是binder_buffer的数据结构:
struct binder_buffer {
struct list_head entry; //binder_buffer的链表
struct rb_node rb_node; //binder_node的红黑树
unsigned free:1;
unsigned allow_user_free:1;
unsigned async_transaction:1;
unsigned debug_id:29;
struct binder_transaction *transaction;//binder通信时候的事务
struct binder_node *target_node;//目标binder实体
size_t data_size;//数据缓冲区大小
size_t offsets_size;//元数据区的偏移量
uint8_t data[0];//指向数据缓冲区的指针
};
从上面的数据结构大致上可以看出Binder_buffer分类为两大区域,第一是元数据区,从结构体开始到结构体的data对象位置,用来描述binder_buffer.而data对象代表了一个指向内核缓冲区的数据缓冲区。
因此可以得出这么一个公式:
真实内存缓冲区大小 = offset_size(有效缓冲区偏移量)+data_size(数据缓冲区大小)
有了这个基础之后,我们能明白一个buffer_size在驱动中分为两种情况来测量;
-
1.当binder_buffer位于binder_proc中的buffers链表中的中间时候。
直接去找binder_buffer的下一个buffer,减掉当前buffer 的data的地址,就得到了当前binder_buffer的大小。
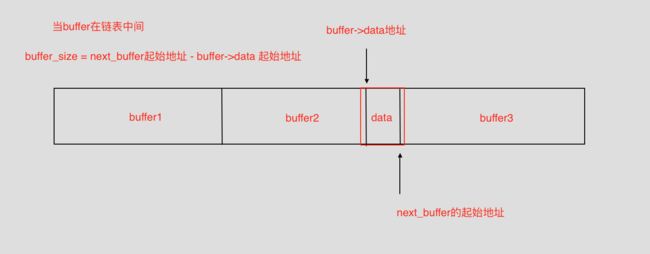 buffer大小在中间时候的计算.png
buffer大小在中间时候的计算.png -
2.当binder_buffer位于binder_proc中的buffers链表中的末端的时候。
我们无法找到下一个binder_buffer内核缓冲区,因此只能取出binder_proc中整体的binder_buffer的起始地址加上buffer_size就得到了当前的缓冲区大小,最后再减去buffer_data的地址。
 buffer大小在末尾时候的计算.png
buffer大小在末尾时候的计算.png
从上面两种情况可以得知,通过binder_buffer_size获取的buffer_size实际上是就是描述binder_buffer的有效数据大小。
binder_buffer 内核缓冲区的空红黑树闲和使用红黑树的管理
接下来我们还原场景,看看binder_insert_free_buffer方法。
static void binder_insert_free_buffer(struct binder_proc *proc,
struct binder_buffer *new_buffer)
{
struct rb_node **p = &proc->free_buffers.rb_node;
struct rb_node *parent = NULL;
struct binder_buffer *buffer;
size_t buffer_size;
size_t new_buffer_size;
new_buffer_size = binder_buffer_size(proc, new_buffer);
while (*p) {
parent = *p;
buffer = rb_entry(parent, struct binder_buffer, rb_node);
buffer_size = binder_buffer_size(proc, buffer);
if (new_buffer_size < buffer_size)
p = &parent->rb_left;
else
p = &parent->rb_right;
}
rb_link_node(&new_buffer->rb_node, parent, p);
rb_insert_color(&new_buffer->rb_node, &proc->free_buffers);
}
阅读过我对树的讲解就能很轻松的理解这一段了。
首先,先取出当前binder_proc中的空闲红黑树,通过分支循环,来寻找当前新建的空闲buffer应该插入到哪里去。
这里就出现了第一个重要的内存管理红黑树,free_buffers。有空闲的管理区,那一定有使用的管理区。让我们看看binder_proc的数据结构。
struct binder_proc {
//映射到binder中的进程管理红黑树
struct hlist_node proc_node;
//映射到binder中,binder_thread管理红黑树
struct rb_root threads;
//binder中的binder_node binder实体管理红黑树
struct rb_root nodes;
//binder中的binder_ref binder引用的描述管理红黑树
struct rb_root refs_by_desc;
//binder中的binder_ref binder引用的binder 实体管理红黑树
struct rb_root refs_by_node;
//代表映射进程的pid
int pid;
//代表用户空间映射下来的线性区
struct vm_area_struct *vma;
//代表进程对应的内存描述符
struct mm_struct *vma_vm_mm;
//代表进程的进程描述符
struct task_struct *tsk;
//代表当前binder文件的文件描述符
struct files_struct *files;
//binder驱动中的延时工作队列
struct hlist_node deferred_work_node;
int deferred_work;
//进程对应当前的整个 binder_buffer 内核缓冲区的起始地址
void *buffer;
//进程用户空间线性区和内核空间线性区的差值
ptrdiff_t user_buffer_offset;
//binder 内核缓冲区的链表
struct list_head buffers;
//binder 空闲内核缓冲区红黑管理区
struct rb_root free_buffers;
//binder 使用中的内核缓冲红黑树管理区
struct rb_root allocated_buffers;
size_t free_async_space;
//映射的物理页面
struct page **pages;
// 进程对应的整个内核缓冲区的大小
size_t buffer_size;
uint32_t buffer_free;
//todo todo预备完成工作的队列
struct list_head todo;
// 进程对应的等待队列,记住这个,这个是一个核心
wait_queue_head_t wait;
struct binder_stats stats;
//分发死亡信息的队列
struct list_head delivered_death;
int max_threads;
int requested_threads;
int requested_threads_started;
int ready_threads;
long default_priority;
struct dentry *debugfs_entry;
};
我在上面结构体注释出来的,都是本系列Binder就会围绕将会提到这些属性,看看binder机制中如何处理的。
这里我们只需要关注,free_buffers 以及 allocated_buffers两个红黑树。第一个就是我们看见的,当我们生成一个新的内核缓冲区,此时没人使用,将会插入到空闲缓冲区中。当我们使用的时候,我们将会从空闲缓冲区,取出做处理之后,再插入到到使用缓冲区。
为了探索这个问题,我单独抽出,binder_buffer申请时候的代码。
binder_alloc_buf
这个方法我分成三部分来慢慢说明。
第一部分
static struct binder_buffer *binder_alloc_buf(struct binder_proc *proc,
size_t data_size,
size_t offsets_size, int is_async)
{
struct rb_node *n = proc->free_buffers.rb_node;
struct binder_buffer *buffer;
size_t buffer_size;
struct rb_node *best_fit = NULL;
void *has_page_addr;
void *end_page_addr;
size_t size;
if (proc->vma == NULL) {
...
return NULL;
}
size = ALIGN(data_size, sizeof(void *)) +
ALIGN(offsets_size, sizeof(void *));
if (size < data_size || size < offsets_size) {
...
return NULL;
}
if (is_async &&
proc->free_async_space < size + sizeof(struct binder_buffer)) {
...
return NULL;
}
看看size的计算。
我们先来看看这个宏:
#define _ALIGN(addr,size) (((addr)+(size)-1)&(~((size)-1)))
ALIGN(data_size, sizeof(void *))
这个算法很有学习的意义。这个算法是为了让地址或者值变成size的倍数。假如此时我们需要对齐指针大小,假设是在32位机子上就是4字节对齐。
此时就是下面这个二进制运算:
( add + (100 - 001) )& (~(100 - 1)) = (add + 011) & 100
这样算出来的结果,通过且运算就能把最后两位忽略成0.如果换算会十进制你就会发现刚好能被4整除。
那么因此就可以知道
size = data_size + offset_size
缓冲区的size为经过指针大小对齐的有效数据区偏移量+元数据大小。
第二部分
while (n) {
buffer = rb_entry(n, struct binder_buffer, rb_node);
BUG_ON(!buffer->free);
buffer_size = binder_buffer_size(proc, buffer);
if (size < buffer_size) {
best_fit = n;
n = n->rb_left;
} else if (size > buffer_size)
n = n->rb_right;
else {
best_fit = n;
break;
}
}
if (best_fit == NULL) {
pr_err("%d: binder_alloc_buf size %zd failed, no address space\n",
proc->pid, size);
return NULL;
}
if (n == NULL) {
buffer = rb_entry(best_fit, struct binder_buffer, rb_node);
buffer_size = binder_buffer_size(proc, buffer);
}
原理很简单,binder驱动会从当前的进程的free_buffers寻找合适的buffer的大小。而大小合适的标准为小于等于当前空闲缓冲区节点的大小。
倘若此时的节点为空,但是找到了合适的区域。我们会从free_buffers取出当前大小的缓冲节点。并且测量好buffer_size.
第三部分
has_page_addr =
(void *)(((uintptr_t)buffer->data + buffer_size) & PAGE_MASK);
if (n == NULL) {
if (size + sizeof(struct binder_buffer) + 4 >= buffer_size)
buffer_size = size; /* no room for other buffers */
else
buffer_size = size + sizeof(struct binder_buffer);
}
end_page_addr =
(void *)PAGE_ALIGN((uintptr_t)buffer->data + buffer_size);
if (end_page_addr > has_page_addr)
end_page_addr = has_page_addr;
if (binder_update_page_range(proc, 1,
(void *)PAGE_ALIGN((uintptr_t)buffer->data), end_page_addr, NULL))
return NULL;
rb_erase(best_fit, &proc->free_buffers);
buffer->free = 0;
binder_insert_allocated_buffer(proc, buffer);
if (buffer_size != size) {
struct binder_buffer *new_buffer = (void *)buffer->data + size;
list_add(&new_buffer->entry, &buffer->entry);
new_buffer->free = 1;
binder_insert_free_buffer(proc, new_buffer);
}
...
buffer->data_size = data_size;
buffer->offsets_size = offsets_size;
buffer->async_transaction = is_async;
if (is_async) {
proc->free_async_space -= size + sizeof(struct binder_buffer);
...
}
return buffer;
如果熟悉linux内核分配物理页面的伙伴算法的话,应该会发现这一段处理运用buffer的内存其核心和其十分相似。
binfer驱动会尝试的拿出当前的最合适buffer_size申请出一个新的binder_buffer。但是这样可能会造成内存浪费。毕竟binder找到合适的大小是小于等于当前的空闲缓存区节点大小。
此处,我们第一次mmap调用的时候,此时就申请了4m的大小作为一个大的buffer节点插进空闲缓冲区。如果按照这个算法取出来直接作为最合适的使用缓冲区,那么必定造成内存浪费。如果同时存在异步的binder操作,必定会出现内存不足。
因此,binder的解决办法模仿了伙伴算法。binder会尝试着从当前的大缓冲区切割一个小的buffer,当可以满足当前内核缓冲区的使用同时,并且能够满足一个binder_buffer的大小,就把当前的这个小的buffer切割下来,放进空闲内核缓冲区中。
核心思路思路明白了,看看源码是怎么处理这个问题的。
-
- has_page_addr 这个属性的计算实际上就是binder_buffer的末尾地址再通过PAGE_MASK清除4kb末尾的位数,来计算此时末尾地址位于哪个页面的起始。
- 2.当我们没有找到一摸一样大小的buffer_size的时候。说明我们要开始切割这个偏大的buffer。
if (n == NULL) {
if (size + sizeof(struct binder_buffer) + 4 >= buffer_size)
buffer_size = size; /* no room for other buffers */
else
buffer_size = size + sizeof(struct binder_buffer);
}
实际上这一部分是为了尝试检测,在原来的内核缓冲区基础上,再申请一个内核缓冲区。假如能够在基础上能够申请多一个binder_buffer+4的大小,说明能够切割,此时buffer_size就顺势加上下一个binder_buffer的大小。否则说明本次不能切割这个内核缓冲区节点,就保持原来大小。而这个4字节就是为了保证下一个缓冲区留有有效数据区的余地。
- 3.计算end_page_addr.此时的计算方式是buffer->data + (经过变化之后)buffer_size.此时代表的意思是如果算上后面切割的buffer.此时需要对地址进行PAGE_SIZE对齐,在这个情景就是4kb的倍数。
end_page_addr =
(void *)PAGE_ALIGN((uintptr_t)buffer->data + buffer_size);
if (end_page_addr > has_page_addr)
end_page_addr = has_page_addr;
if (binder_update_page_range(proc, 1,
(void *)PAGE_ALIGN((uintptr_t)buffer->data), end_page_addr, NULL))
return NULL;
为了避免end_page_addr 这个结束地址越界。因为以4kb的对齐可能会出现比原来的计算结束地址大,也能小,而has_page_addr因为是计算PAGE_MASK会比原来的小。为了保证不出现end_page_addr越界到下一个buffer中,此时选择has_page_addr作为结束地址。并且以这个新的end_page_addr 作为结束地址,buffer->data为起点,重新分配空闲内核缓冲区。
- 4.把当前从空闲内核缓冲区的合适节点从原来的空闲缓冲区删去,并且把当前这个binder_buffer加入到使用中缓冲区中。最后把刚才重新绑定好的小的空闲小缓冲区节点插入到空闲缓冲区中。最后再设置上binder_buffer的参数,就完成了内核缓冲区的生成。
总结
让我们回归场景,我们此时我们是在service manager的初始化场景。也就是说,此时我们的service manager作为第一个binder 服务映射到了binder驱动中。
用一张图来形象代表mmap的过程。
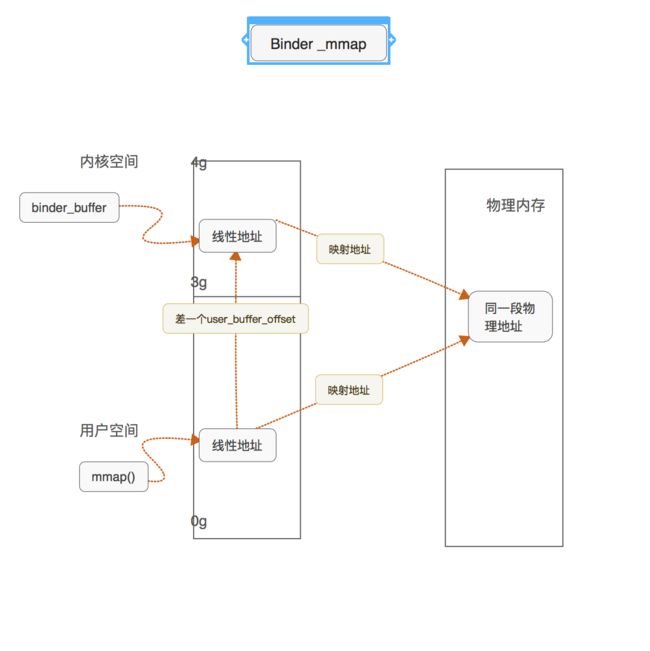
到这里我们就解析完service manager中的binder_open方法。此时虽然已经映射成功了,但是我们只是拿到了一段映射好的共享享地址还没使用。接下来继续service manager的初始化。
思考一下
为什么使用mmap,mmap这种方式比起传统的进程通信(ipc)有什么区别。就以最经典的ipc通信,pipe 管道为例子。pipe使用过两个文件描述符来分别控制读写。实际上通过pipe初始化两个文件描述符之后,会通过文件描述符读取,写入数据。大致上的流程是这样的。其源码核心就是在内核中alloc_file,并为这些文件设置上pipefifo_fops结构体。

那么比起我们的mmap,能够通过内存映射,直接找到对端地址,直接把数据拷贝过去,就直接少了一次数据拷贝的过程,这就极大的减小开销。记住每一次文件操作都是一次中断信号,到内核中做数据转移处理,这个过程实际上耗时和开销的比较大。
根据上面的mmap源码。我们去比较mmap的一些mmap的情况。
1.mmap 的MAP_PRIVATE 时候,并不会把数据反映到磁盘上。我们能够看到在Linux中和磁盘绑定一般是指结构体inode。从源码上的看到的是,mmap只和vma虚拟内存绑定起来,而inode并不是必须的,因此在mmap必定能够修改到内存,但是磁盘不一定。当MAP_PRIVATE的分支时候,inode没有参与进来。
2.mmap要构建映射区,必须要打开PROT_READ标志位。从
case MAP_PRIVATE:
if (!(file->f_mode & FMODE_READ))
return -EACCES;
可以看到此时如果没有打开PROT_READ则会返回错误。如果我们细抓binder_mmap后面几步,可以发现,我们mmap之后必定会读取当前的vma虚拟内存,进行绑定物理内存。所以不打开PROT_READ,就不能建立映射区。