Hadoop for .NET Developers(十二):实现简单的MapReduce作业
在本练习中,我们将使用C#和.NET SDK编写并执行非常简单的MapReduce作业。本练习的目的是说明MapReduce背后的最基本概念。
我们将创建的作业将在以前的博客文章中加载到本地桌面开发环境的integers.txt示例文件中运行。您可能会记得该文件由1到10,000之间的整数值列表组成,每个整数占据自己的行。
我们将写的map函数将接受一行(一个整数),确定该值是偶数还是奇数,并相应地发出一个“even”或“odd”的整数值。我们将写的reduce函数将接受与给定键相关联的所有整数值,即“even”或“odd”,然后对这些值进行计数和求和。然后,reduce函数将再次以“even”或“odd”的键值格式发出结果,并将相关的计数和和作为值分隔为简单选项卡。
要开始,请执行以下步骤:
- 启动Visual Studio并打开一个新的C#控制台应用程序项目。
- 使用NuGet将以下软件包添加到项目中:
Microsoft .NET Map Reduce API forHadoop
Microsoft ASP.NET Web API3.如果Program.cs文件尚未打开,请打开它。
4.将以下指令添加到程序中:
using Microsoft.Hadoop;
using Microsoft.Hadoop.MapReduce;
using Microsoft.Hadoop.WebClient.WebHCatClient;现在环境准备好编写MapReduce例程。 我们的下一步将是写一个Mapper类:
1.在程序中,导航到定义程序类结束的大括号。
2.将以下类添加到代码中:
using Microsoft.Hadoop.MapReduce;
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace MyApp
{
public class MySimpleMapper : MapperBase
{
public override void Map(string inputLine, MapperContext context)
{
//将传入的行解释为整数值
int value = int.Parse(inputLine);
//确定值是偶数还是奇数
string key = (value % 2 == 0) ? "even" : "odd";
//输出键分配值
context.EmitKeyValue(key, value.ToString());
}
}
}
在这段代码中,你会注意到Mapper类继承了MapperBase类。我们覆盖该类的Map方法来编写我们自己的Map方法。 Map方法接受来自输入文件的数据作为字符串和对MapperContext对象的引用,这是我们将通信回到MapReduce环境的手段。
由于输入数据由单个整数值组成,所以我们简单地将其转换为int数据类型,然后使用简单的模数计算来确定该值是偶数还是奇数,将“偶数”或“奇数”写入键字符串变量基于结果。该键值与原始整数值一起通过使用EmitKeyValue函数的上下文对象返回给MapReduce环境。请注意,EmitKeyValue函数仅接受字符串,以便将整数值转换为字符串数据类型作为调用的一部分。
现在我们将编写reduce函数:
- 在程序中,导航到定义Mapper类的结尾的大括号。
- 将以下类添加到代码中:
using Microsoft.Hadoop.MapReduce;
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace MyApp
{
public class MySimpleReducer : ReducerCombinerBase
{
public override void Reduce(string key, IEnumerable<string> values, ReducerCombinerContext context)
{
//初始化计数器
int myCount = 0;
int mySum = 0;
//计算和汇总输入值
foreach (string value in values)
{
mySum += int.Parse(value);
myCount++;
}
//输出结果
context.EmitKeyValue(key, myCount + "t" + mySum);
}
}
}
我们的Reducer类继承ReducerCombiner类并覆盖Reduce方法。 Reduce方法接受单个键值(作为字符串)和其关联值的无数集合。 Reduce方法还通过上下文对象接收对MapReduce环境的引用。
Reduce方法中的代码非常简单。 我们循环遍历值的集合,递增计数并在循环时加起值。 一旦完成,原始键值将与我们之前计算的计数和总和值一起返回。 请注意,myCount和mySum变量未显式转换为字符串。 通过将这些值与tab-string分隔符相连,+运算符对我们执行隐式转换。
现在我们已经定义了Mapper和Reducer类,我们可以创建一个MapReduce作业。 为此,请按照下列步骤操作:
- 导航到Program类中的Main方法。
- 为该类添加以下代码:
using Microsoft.Hadoop.MapReduce;
using Microsoft.Hadoop.WebClient.WebHCatClient;
using Microsoft.Hadoop.WebHDFS;
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace MyApp
{
public class SimpleMapReduceJob
{
public void test()
{
//建立作业配置
HadoopJobConfiguration myConfig = new HadoopJobConfiguration();
myConfig.InputPath = "/demo/simple/in";
myConfig.OutputFolder = "/demo/simple/out";
//连接到集群
Uri myUri = new Uri("http://localhost:50070");
//string userName = "hadoop";
string userName = "hadoop";
string passWord = null;
//IHadoop myCluster = Hadoop.Connect(myUri, "", "");
IHadoop myCluster = Hadoop.Connect();
//执行mapreduce作业
MapReduceResult jobResult = myCluster.MapReduceJob.Execute(myConfig);
//将作业结果写入控制台
int exitCode = jobResult.Info.ExitCode;
string exitStatus = "Failure";
if (exitCode == 0)
{
exitStatus = "Success";
}
exitStatus = exitCode + " (" + exitStatus + ")";
Console.WriteLine();
Console.Write("Exit Code = " + exitStatus);
Console.Read();
}
}
}
在代码的顶部,我们定义一个HadoopJobConfiguration对象来保存作业配置信息,例如保存输入文件的文件夹和文件夹到输出应该被引导到的位置。请注意,默认情况下,MapReduce作业将访问输入文件夹中的所有文件,并删除目标文件夹中的所有文件。因此,最好的做法是使用文件夹结构和命名方案,将输入文件保存在一起,并将不同作业的输出隔离。
接下来,我们连接到我们本地的Hadoop集群。连接非常简单,在这个例子中,我们仅使用默认用户hadoop,它具有空密码。
接下来,我们在集群上执行MapReduceJob,并将Mapper和Reducer类识别为Map和Reduce方法的源。 Execute方法有一些实现,允许我们仅使用Mapper,Mapper和Reducer,或Mapper,Reducer或Combiner。对于这个简单的工作,我们需要使用Mapper和Reducer的版本。配置信息被传递给Execute方法,结果由MapReduceResult对象捕获。
剩下的代码仅供演示用途。我们检查作业的退出代码,将其发送到我们的控制台,并将控制台固定位置,直到用户按下一个键。
准备:
hadoop fs -rmdir --ignore-fail-on-non-empty /user
hadoop fs -rm -r -f /tmp
hadoop fs -put "E:\integers.txt" /demo/simple/in
hadoop fs -chmod -R 755 /tmpintegers.txt里面是1到2000行对应的行号数字,每个数字一行
现在是时候运行这个作业:
1.从Visual Studio,单击开始按钮。
2.几秒钟后,控制台应该出现。
3.作业完成后,请查看控制台以验证作业已成功完成。
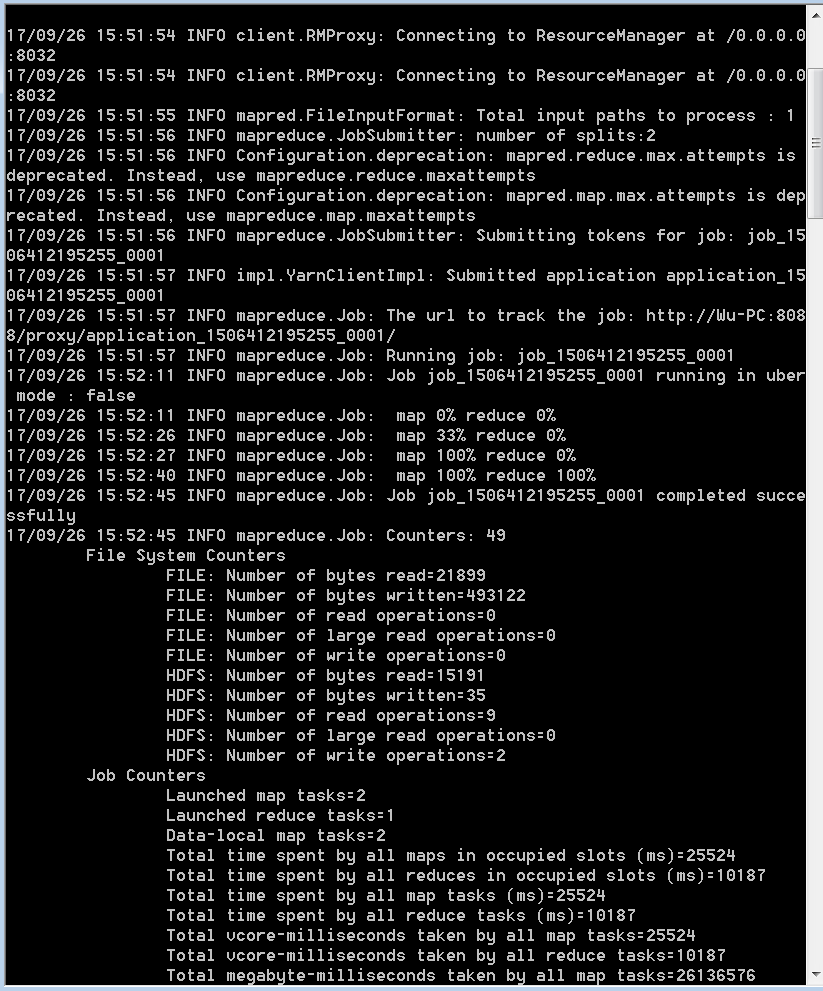
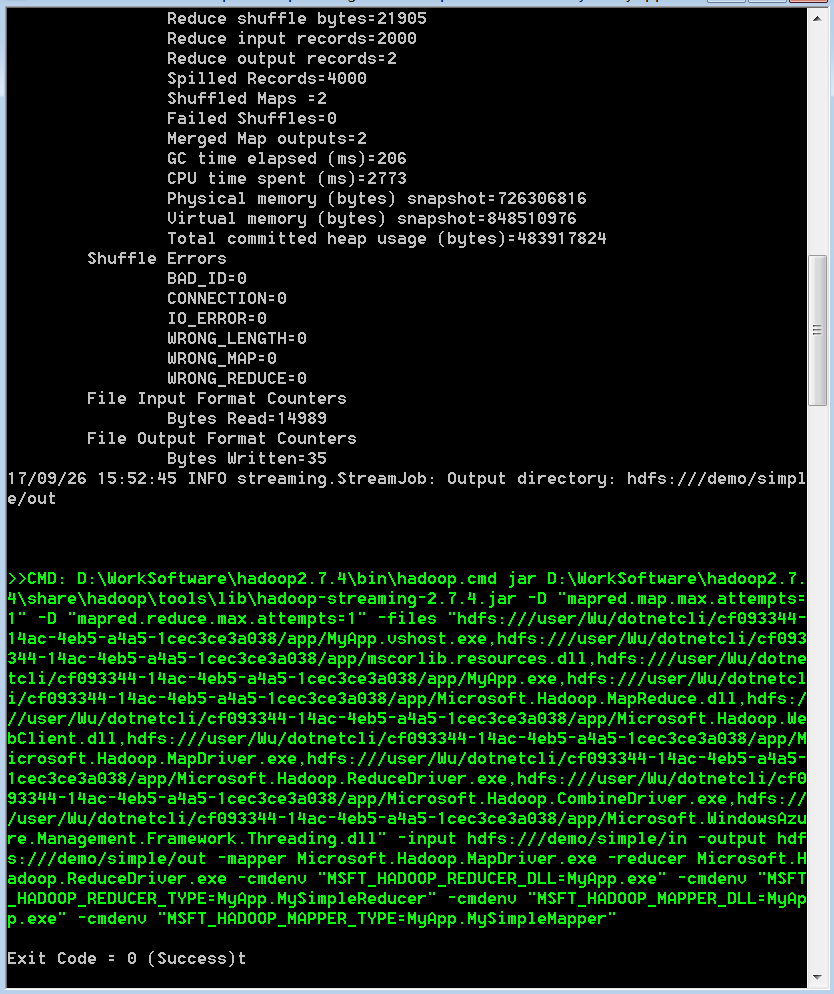

现在工作完成了,现在是检查结果的时候了:
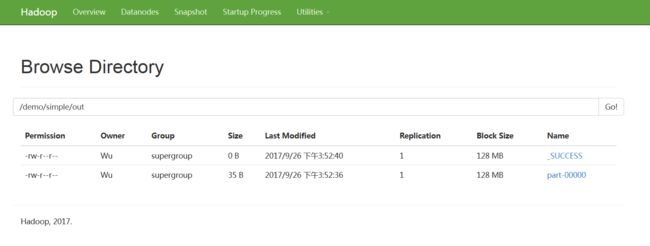
1.从桌面启动Hadoop命令提示符。
2.使用ls函数检查/demo/simple/out文件夹的内容,如上一篇文章所述。
3.使用cat功能检查/demo/simple/out/part-00000文件的内容,如上一篇文章所述。
hadoop fs -cat / demo / simple /out/ part - 00000
在此示例中,MapReduce确定单个reduce任务足以执行此作业的该阶段。 因此,输出文件夹中只有一个部分文件。