Keras文本分类
文章目录
- 内置样本
- 序列截断或补齐为等长
- 词嵌入
- 词嵌入+RNN
- 词嵌入+CNN
- CNN+RNN
- 双向RNN
- 双向RNN+Word2Vector
内置样本
影评正负2分类(已编码)
from keras.datasets import imdb # Internet Movie Database
# num_words设定较小时,会发现高频词多是停词
(x, y), _ = imdb.load_data(num_words=1)
print(x.shape, y.shape) # (25000,) (25000,)
# 词与ID间的映射
word2id = imdb.get_word_index()
id2word = {i: w for w, i in word2id.items()}
print(x[0])
print(' '.join([id2word[i] for i in x[0]]))
序列截断或补齐为等长
from keras.preprocessing.sequence import pad_sequences
maxlen = 2
print(pad_sequences([[1, 2, 3], [1]], maxlen))
"""[[2 3] [0 1]]"""
print(pad_sequences([[1, 2, 3], [1]], maxlen, value=9))
"""[[2 3] [9 1]]"""
print(pad_sequences([[1, 2, 3], [1]], maxlen, padding='post'))
"""[[2 3] [1 0]]"""
print(pad_sequences([[1, 2, 3], [1]], maxlen, truncating='post'))
"""[[1 2] [0 1]]"""
词嵌入
from keras.datasets.imdb import load_data # 影评情感2分类
from keras.preprocessing.sequence import pad_sequences
from keras.models import Sequential
from keras.layers import Embedding, Flatten, Dense
"""配置"""
num_words = 10000 # 按词频大小取样本前10000个词
input_dim = num_words # 词库大小(必须>=num_words)
maxlen = 25 # 序列长度
output_dim = 40 # 词向量维度
batch_size = 128
epochs = 2
"""数据读取与处理"""
(x, y), _ = load_data(num_words=num_words)
x = pad_sequences(x, maxlen)
"""建模"""
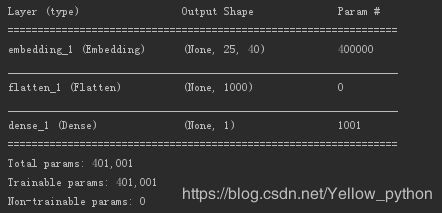
model = Sequential()
# 词嵌入:词库大小、词向量维度、固定序列长度
model.add(Embedding(input_dim, output_dim, input_length=maxlen))
# 平坦化:maxlen * output_dim
model.add(Flatten())
# 输出层:2分类
model.add(Dense(units=1, activation='sigmoid'))
# RMSprop优化器、二元交叉熵损失
model.compile('rmsprop', 'binary_crossentropy', ['acc'])
# 训练
model.fit(x, y, batch_size, epochs)
"""模型可视化"""
model.summary()
词嵌入+RNN
from keras.datasets.imdb import load_data # 影评情感2分类
from keras.preprocessing.sequence import pad_sequences
from keras.models import Sequential
from keras.layers import Embedding, Dense, SimpleRNN
import matplotlib.pyplot as mp
"""配置"""
num_words = 10000 # 按词频大小取样本前10000个词
input_dim = num_words # 词库大小(必须>=num_words)
maxlen = 25 # 序列长度
output_dim = 40 # 词向量维度
units = 32 # RNN神经元数量
batch_size = 128
epochs = 3
"""数据读取与处理"""
(x, y), _ = load_data(num_words=num_words)
x = pad_sequences(x, maxlen)
"""建模"""
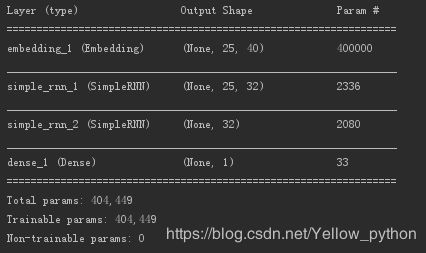
model = Sequential()
model.add(Embedding(input_dim, output_dim, input_length=maxlen))
model.add(SimpleRNN(units, return_sequences=True)) # 返回序列全部结果
model.add(SimpleRNN(units, return_sequences=False)) # 返回序列最尾结果
model.add(Dense(units=1, activation='sigmoid'))
model.summary()
"""编译、训练"""
model.compile('rmsprop', 'binary_crossentropy', ['acc'])
history = model.fit(x, y, batch_size, epochs, verbose=2,
validation_split=.1) # 取10%样本作验证
"""精度曲线"""
acc = history.history['acc']
val_acc = history.history['val_acc']
mp.plot(range(epochs), acc)
mp.plot(range(epochs), val_acc)
mp.show()
词嵌入+CNN
from keras.datasets.imdb import load_data # 影评情感2分类
from keras.preprocessing.sequence import pad_sequences
from keras.models import Sequential
from keras.layers import Embedding, Dense,\
Conv1D, MaxPool1D, GlobalMaxPool1D
"""配置"""
num_words = 10000 # 按词频大小取样本前10000个词
input_dim = num_words # 词库大小(必须>=num_words)
maxlen = 25 # 序列长度
output_dim = 40 # 词向量维度
filters = 32 # 卷积层滤波器数量
kernel_size = 7 # 卷积层滤波器大小
batch_size = 128
epochs = 3
"""数据读取与处理"""
(x, y), _ = load_data(num_words=num_words)
x = pad_sequences(x, maxlen)
"""建模"""
model = Sequential()
model.add(Embedding(input_dim, output_dim, input_length=maxlen))
model.add(Conv1D(filters, kernel_size, activation='relu'))
model.add(MaxPool1D(pool_size=2)) # strides默认等于pool_size
model.add(Conv1D(filters, kernel_size, activation='relu'))
model.add(GlobalMaxPool1D()) # 对于时序数据的全局最大池化
model.add(Dense(units=1, activation='sigmoid'))
model.summary()
"""编译、训练"""
model.compile('rmsprop', 'binary_crossentropy', ['acc'])
model.fit(x, y, batch_size, epochs, 2)

CNN+RNN
from keras.datasets.imdb import load_data # 影评情感2分类
from keras.preprocessing.sequence import pad_sequences
from keras.models import Sequential
from keras.layers import Embedding, Dense,\
Conv1D, MaxPool1D, GRU # Gated Recurrent Unit
"""配置"""
num_words = 10000 # 按词频大小取样本前10000个词
input_dim = num_words # 词库大小(必须>=num_words)
maxlen = 25 # 序列长度
output_dim = 40 # 词向量维度
filters = 32 # 卷积层滤波器数量
kernel_size = 7 # 卷积层滤波器大小
units = 32 # RNN神经元数量
batch_size = 128
epochs = 3
"""数据读取与处理"""
(x, y), _ = load_data(num_words=num_words)
x = pad_sequences(x, maxlen)
"""建模"""
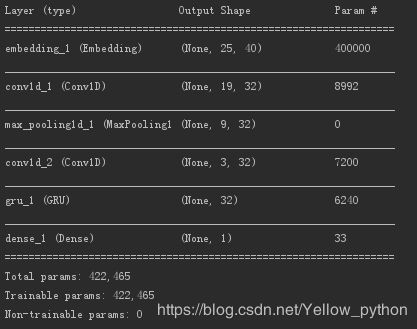
model = Sequential()
model.add(Embedding(input_dim, output_dim, input_length=maxlen))
model.add(Conv1D(filters, kernel_size, activation='relu'))
model.add(MaxPool1D())
model.add(Conv1D(filters, kernel_size, activation='relu'))
model.add(GRU(units)) # 门限循环单元网络
model.add(Dense(1, activation='sigmoid'))
model.summary()
"""编译、训练"""
model.compile('rmsprop', 'binary_crossentropy', ['acc'])
model.fit(x, y, batch_size, epochs, 2)
双向RNN
Bidirectional
from keras.datasets.imdb import load_data # 影评情感2分类
from keras.preprocessing.sequence import pad_sequences
from keras.models import Sequential
from keras.layers import Embedding, Dense, GRU, Bidirectional
import matplotlib.pyplot as mp
"""配置"""
num_words = 10000 # 按词频大小取样本前10000个词
input_dim = num_words # 词库大小(必须>=num_words)
maxlen = 25 # 序列长度
output_dim = 40 # 词向量维度
units = 32 # RNN神经元数量
batch_size = 128
epochs = 3
verbose = 2
"""数据读取与处理"""
(x, y), _ = load_data(num_words=num_words)
x = pad_sequences(x, maxlen)
"""建模"""
model = Sequential()
model.add(Embedding(input_dim, output_dim, input_length=maxlen))
model.add(Bidirectional(GRU(units))) # 双向RNN
model.add(Dense(units=1, activation='sigmoid'))
model.summary()
"""编译、训练"""
model.compile('rmsprop', 'binary_crossentropy', ['acc'])
history = model.fit(x, y, batch_size, epochs, verbose, validation_split=.1)
"""精度曲线"""
acc = history.history['acc']
val_acc = history.history['val_acc']
mp.plot(range(epochs), acc)
mp.plot(range(epochs), val_acc)
mp.show()
双向RNN+Word2Vector
from jieba import lcut
from sklearn.model_selection import train_test_split
from gensim.models import Word2Vec
from tensorflow.python.keras.preprocessing.sequence import pad_sequences
from tensorflow.python.keras.models import Sequential
from tensorflow.python.keras.layers import Dense, GRU, Bidirectional
from tensorflow.python.keras.callbacks import EarlyStopping
from numpy import zeros
"""配置"""
size = 20 # 词向量维度
units = 30 # RNN神经元数量
maxlen = 40 # 序列长度
batch_size = 1 # 每批数据量大小
epochs = 9 # 训练最大轮数
verbose = 2 # 训练过程展示
patience = 1 # 没有进步的训练轮数
callbacks = [EarlyStopping('val_acc', patience=patience)]
"""训练数据、分词"""
data = [
[0, '小米粥是以小米作为主要食材熬制而成的粥,口味清淡,清香味,具有简单易制,健胃消食的特点'],
[0, '煮粥时一定要先烧开水然后放入洗净后的小米'], [0, '蛋白质及氨基酸、脂肪、维生素、矿物质'],
[0, '小米是传统健康食品,可单独焖饭和熬粥'], [0, '苹果,是水果中的一种'],
[0, '粥的营养价值很高,富含矿物质和维生素,含钙量丰富,有助于代谢掉体内多余盐分'],
[0, '鸡蛋有很高的营养价值,是优质蛋白质、B族维生素的良好来源,还能提供脂肪、维生素和矿物质'],
[0, '这家超市的苹果都非常新鲜'], [0, '在北方小米是主要食物之一,很多地区有晚餐吃小米粥的习俗'],
[0, '小米营养价值高,营养全面均衡 ,主要含有碳水化合物'], [0, '蛋白质及氨基酸、脂肪、维生素、盐分'],
[1, '小米、三星、华为,作为安卓三大手机旗舰'], [1, '别再管小米华为了!魅族手机再曝光:这次真的完美了'],
[1, '苹果手机或将重陷2016年困境,但这次它无法再大幅提价了'], [1, '三星想要继续压制华为,仅凭A70还不够'],
[1, '三星手机屏占比将再创新高,超华为及苹果旗舰'], [1, '华为P30、三星A70爆卖,斩获苏宁最佳手机营销奖'],
[1, '雷军,用一张图告诉你:小米和三星的差距在哪里'], [1, '小米米聊APP官方Linux版上线,适配深度系统'],
[1, '三星刚刚更新了自家的可穿戴设备APP'], [1, '华为、小米跨界并不可怕,可怕的打不破内心的“天花板”'],
]
X, Y = [lcut(i[1]) for i in data], [i[0] for i in data]
X_train, X_test, y_train, y_test = train_test_split(X, Y)
"""词向量"""
word2vec = Word2Vec(X_train, size, min_count=1)
w2i = {w: i for i, w in enumerate(word2vec.wv.index2word)}
vectors = word2vec.wv.vectors
def w2v(w):
i = w2i.get(w)
return vectors[i] if i else zeros(size)
def pad(ls_of_words):
a = [[w2v(i) for i in x] for x in ls_of_words]
a = pad_sequences(a, maxlen, dtype='float')
return a
X_train, X_test = pad(X_train), pad(X_test)
"""建模"""
model = Sequential()
model.add(Bidirectional(GRU(units), input_shape=(maxlen, size))) # 双向RNN
model.add(Dense(units=1, activation='sigmoid'))
model.summary()
"""训练"""
model.compile('rmsprop', 'binary_crossentropy', ['acc'])
model.fit(X_train, y_train, batch_size, epochs, verbose, callbacks, validation_data=(X_test, y_test))