物体的三维识别与6D位姿估计:PPF系列论文介绍(四)
文章“3D Pose Estimation of Daily ObjectsUsing an RGB-D Camera”2012发表在IEEE/RSJInternational Conference on Intelligent Robots and Systems上,这篇文章对原始点对特征(PPF)作了一个很大的改进。
本文创新点
本文提出了一种利用深度和颜色信息的物体姿态估计算法。虽然许多方法假设目标区域是从背景中分割的,但我们的方法不依赖于这个假设,因此它可以估计目标物体在重杂波中的姿态。最近,引入了一个定向点对特征作为对象表面的低维描述,该特征已被应用于投票方案中,在对象模型和测试场景特征之间找到一组可能的三维刚性转换。虽然使用点对特征的几种方法需要一个精确的三维cad模型作为训练数据,但我们的方法只依赖于目标对象的几个扫描视图,因此学习新对象是很简单的。此外,我们认为,利用颜色信息可以显著提高投票过程的时间和准确性。为了利用颜色信息,我们定义了一个颜色点对特征,该特征用于投票方案中,以获得更有效的姿态估计。
本文主要内容
1.原始点对特征及改进的颜色点对特征
我们将一组点对的特征定义为下式,也就是四维特征。

其中d=||pi−pj||,∠(v1,v2)∈[0;π)表示两个向量之间的角度。第一个分量,d2=||pi−pj||2,表示两个表面点之间的欧几里德距离。 第二和第三分量分别是矢量d与表面法向量ni和nj之间的角度。最后一个分量是两个法向量之间的角度。原始PPF适用于表面法线变化丰富的物体,但它通常不足以描述平面或自对称物体。 因此,需要增加点对特征,以便该特征对这些类型的对象更加有效。 本文提出颜色点对特征Fcppf,它是通过连接点的两个三维颜色向量来定义的:

其中ci和cj∈R3是颜色向量,通常来说,每个颜色通道被归一化为c∈[0;1]。 如下图所示描述了CPPF特征。
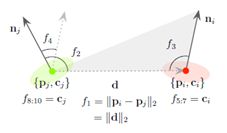
2.对象学习
要使用CPPF作为哈希表的密钥,我们需要量化特征描述符:

其中![]() 分别表示距离、角度和颜色向量的量化级别。符号
分别表示距离、角度和颜色向量的量化级别。符号![]() 表示按分量划分。利用特征CPPF的这个索引I,将姿态估计所需的信息保存在哈希表H中,通过将特征存储在H中,将相似的CPPFs分组在同一个时隙中,并可以在平均恒定时间内与场景CPPFs进行匹配。
表示按分量划分。利用特征CPPF的这个索引I,将姿态估计所需的信息保存在哈希表H中,通过将特征存储在H中,将相似的CPPFs分组在同一个时隙中,并可以在平均恒定时间内与场景CPPFs进行匹配。
在算法1中给出了对象学习过程,给定对象模型点云M,该算法返回学习的哈希表H,Nm表示M中的点数,是将在下文介绍的中间角。量化参数δ,θ,![]() 是重要的参数设置。根据我们的经验,在实验中δ=2mm、
是重要的参数设置。根据我们的经验,在实验中δ=2mm、![]() 、
、![]() ,并不能得到很好地效果。对于的颜色量化级别,我们使用HSV颜色空间。 v通道通常不受光照变化的影响,因此使用了更大的水平即0.4。
,并不能得到很好地效果。对于的颜色量化级别,我们使用HSV颜色空间。 v通道通常不受光照变化的影响,因此使用了更大的水平即0.4。

3.投票方案
如下图所示,![]() 是将
是将![]() 转化为原点,并将其法线
转化为原点,并将其法线![]() 旋转到X轴上,对于场景点对,
旋转到X轴上,对于场景点对,![]() 也是如此。
也是如此。

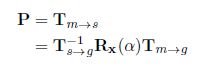
算法2详细地描述了投票过程,以哈希表H、对象模型点云M和测试场景点云N的点数Ns作为输入,然后以返回Np姿态假设P作为输出。场景点的采样比率![]() 和投票阈值都
和投票阈值都![]() 来控制速度和精度之间的权衡。实验中,我们考虑NP=10作为姿态假设,并检查
来控制速度和精度之间的权衡。实验中,我们考虑NP=10作为姿态假设,并检查![]() =1.0的所有场景点。我们通常设置,但根据对象的大小稍微调整。随机样本RandomSample(N)在不重复的情况下返回1到N之间的随机数,Intertransform (p,n)使用给定的点P和法向N计算来对齐变换。最后,PoseClustering(P,NP) 在一组NP分组姿态中将原始姿态假设P聚在一起,将在下一节中解释。
=1.0的所有场景点。我们通常设置,但根据对象的大小稍微调整。随机样本RandomSample(N)在不重复的情况下返回1到N之间的随机数,Intertransform (p,n)使用给定的点P和法向N计算来对齐变换。最后,PoseClustering(P,NP) 在一组NP分组姿态中将原始姿态假设P聚在一起,将在下一节中解释。

4.位姿聚类
我们采用了一种有效的聚集聚类方法,函数PoseClustering(P,Np)以未聚类的姿态假设P作为输入,并按投票数的递减顺序对它们进行排序,从创建一个具有最高票数的姿态假设的新集群开始,类似的姿态被分组在一起,如果一个姿态远离现有的集群,则创建一个新的集群,姿态之间的距离测试是基于平移和旋转中的固定阈值,当聚类完成后,再次对聚类进行排序,并返回顶部NP姿态聚类。
实验结果
1.测试对象

2.添加高斯噪声的结果

3.聚类场景分析

参考文献
[1] B. Drost, M. Ulrich, N. Navab, and S. Ilic, “Model globally,match locally: Efficient and robust 3D object recognition,” in Proceedings ofIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2010.
[2] A. S. Mian, M. Bennamoun, and R.Owens, “Three-dimensional model-based object recognition and segmentation incluttered scenes,” IEEE Transactions on Pattern Analysis and MachineIntelligence, pp.1584–1601, 2006.
上述内容,如有侵犯版权,请联系作者,会自行删文。
推荐阅读:
吐血整理|3D视觉系统化学习路线
那些精贵的3D视觉系统学习资源总结(附书籍、网址与视频教程)
超全的3D视觉数据集汇总
大盘点|6D姿态估计算法汇总(上)
大盘点|6D姿态估计算法汇总(下)
机器人抓取汇总|涉及目标检测、分割、姿态识别、抓取点检测、路径规划
汇总|3D点云目标检测算法
汇总|3D人脸重建算法
那些年,我们一起刷过的计算机视觉比赛
总结|深度学习实现缺陷检测
深度学习在3-D环境重建中的应用
汇总|医学图像分析领域论文
大盘点|OCR算法汇总
重磅!3DCVer-知识星球和学术交流群已成立
3D视觉从入门到精通知识星球:针对3D视觉领域的知识点汇总、入门进阶学习路线、最新paper分享、疑问解答四个方面进行深耕,更有各类大厂的算法工程人员进行技术指导,820+的星球成员为创造更好的AI世界共同进步,知识星球入口:
学习3D视觉核心技术,扫描查看介绍,3天内无条件退款

圈里有高质量教程资料、可答疑解惑、助你高效解决问题
欢迎加入我们公众号读者群一起和同行交流,目前有3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、学术交流、求职交流等微信群,请扫描下面微信号加群,备注:”研究方向+学校/公司+昵称“,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进去相关微信群。原创投稿也请联系。

▲长按加群或投稿