javaIO类的内部原理机制。
先看一个字节处理流程图
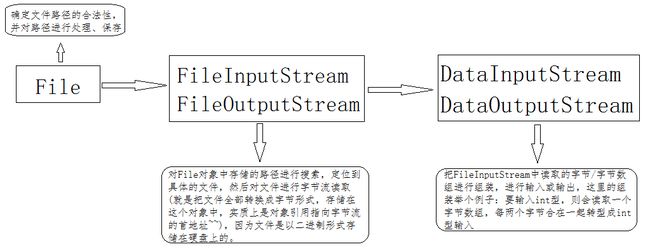
File类:
public File(String pathname) {
if (pathname == null) {
throw new NullPointerException();
}
this.path = fs.normalize(pathname);
this.prefixLength = fs.prefixLength(this.path);
}上面为File类的一个构造器源码,从这一个构造器就大概可以知道
File类的作用:即通过new一个File对象,对其构造器参数通过分析,进行精确定位(就是判断你输入的这个路径是否正确,会去你的电脑里查,路径合法,然后对你这个路径进行保存,后面要对这个路径上的文件/文件夹做一些事的话,就直接通过这个File对象进行操作即可)
上述的FileInputStream只能对字节型数据进行处理(参考源码方法中的参数都是字节型)
DataInputStream虽然可以对字节以外的类型进行处理,但是,很死板~~~下图为一段源码
public DataInputStream(InputStream in) {
super(in);
}
public final char readChar() throws IOException {
int ch1 = in.read();
int ch2 = in.read();
if ((ch1 | ch2) < 0)
throw new EOFException();
return (char)((ch1 << 8) + (ch2 << 0));
}此处截取读取字符型数据为例。
首先第一段代码数将FileInputStream读取的二进制字节流读取进来,第二段代码是按照通过两个字节拼接一个字符的方法来处理字符类型的数据。如果一段数据中有一个double型数据以及一个字符串呢?此时你得在你的代码中显示的对读取方法进行调用,太麻烦~~~~~~~~而且文件过大时,这样做根本不可能~~~~~~~~~~!!!
因此介绍第二种文件数据读取类
~BufferedReader/BufferedWriter
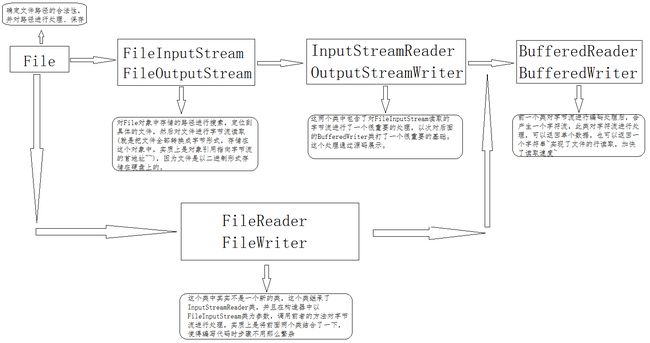
从上述两个处理流程图来看,其实实质上都是先将文件的字节流读取进来,再作进一步处理而已。
现在来看第二个流程图,第二个与第一个的重要区别就在与InputStreamReader类中。下面截取一段该类中对字节流处理的一段源码:
public InputStreamReader(InputStream in) {
super(in);
try {
sd = StreamDecoder.forInputStreamReader(in, this, (String)null); // ## check lock object
} catch (UnsupportedEncodingException e) {
// The default encoding should always be available
throw new Error(e);
}
}上述代码中对字节流通过默认的编码方式进行处理得到一个字符流(因为StreamDecoder的源码找不到,所以大家可以自己去找一下看一下怎么处理的),将这个字符流传给BufferedReader进行处理。
String readLine(boolean ignoreLF) throws IOException {
StringBuffer s = null;
int startChar;
synchronized (lock) {
ensureOpen();
boolean omitLF = ignoreLF || skipLF;
bufferLoop:
for (;;) {
if (nextChar >= nChars)
fill();
if (nextChar >= nChars) { /* EOF */
if (s != null && s.length() > 0)
return s.toString();
else
return null;
}
boolean eol = false;
char c = 0;
int i;
/* Skip a leftover '\n', if necessary */
if (omitLF && (cb[nextChar] == '\n'))
nextChar++;
skipLF = false;
omitLF = false;
charLoop:
for (i = nextChar; i < nChars; i++) {
c = cb[i];
if ((c == '\n') || (c == '\r')) {
eol = true;
break charLoop;
}
}
startChar = nextChar;
nextChar = i;
if (eol) {
String str;
if (s == null) {
str = new String(cb, startChar, i - startChar);
} else {
s.append(cb, startChar, i - startChar);
str = s.toString();
}
nextChar++;
if (c == '\r') {
skipLF = true;
}
return str;
}
if (s == null)
s = new StringBuffer(defaultExpectedLineLength);
s.append(cb, startChar, i - startChar);
}
}
}BufferedReader通过上述方法,将字符数组中的多个字符转成字符串进行返回,转型成字符串的时候对字符数据进行处理,其中的\r等都是InputStreamReader处理过后进行加入的。
最后看一个FileReader的源码,是如何简化步骤的。:
public FileReader(String fileName) throws FileNotFoundException {
super(new FileInputStream(fileName));
}
public InputStreamReader(InputStream in) {
super(in);
try {
sd = StreamDecoder.forInputStreamReader(in, this, (String)null); // ## check lock object
} catch (UnsupportedEncodingException e) {
// The default encoding should always be available
throw new Error(e);
}
}