JAVA中集合的理解
首先看一个树状图:
Collection
├List
│├LinkedList
│├ArrayList
│└Vector
│ └Stack
└Set
├HashSet
└TreesSet
└Queue
Map
├Hashtable
├HashMap
└WeakHashMap

图形:

继承: 实线
实现: 虚线
1 Collection
查看: https://blog.csdn.net/Judy_c/article/details/78230222
Collection是一个接口,是高度抽象出来的集合,它包含了集合的基本操作和属性。
Collection接口抽象出来了集合都具有的特性。例如添加、删除、得到集合中的元素个数、检测某一元素是否存在在该集合… …
Collection是一个接口 继承了 Iterable
首先查看Collection的源码以及方法:
![]()

然后查看了一下Collection的基类Iterable :


查看了上面的代码,当时就有一个疑问,为什么Collection接口又要去继承Iterable接口呢?
引用至: https://www.zhihu.com/question/48503724/answer/119178460
通过继承我们可以保留父接口中定义的行为,同时对其可以做扩展。


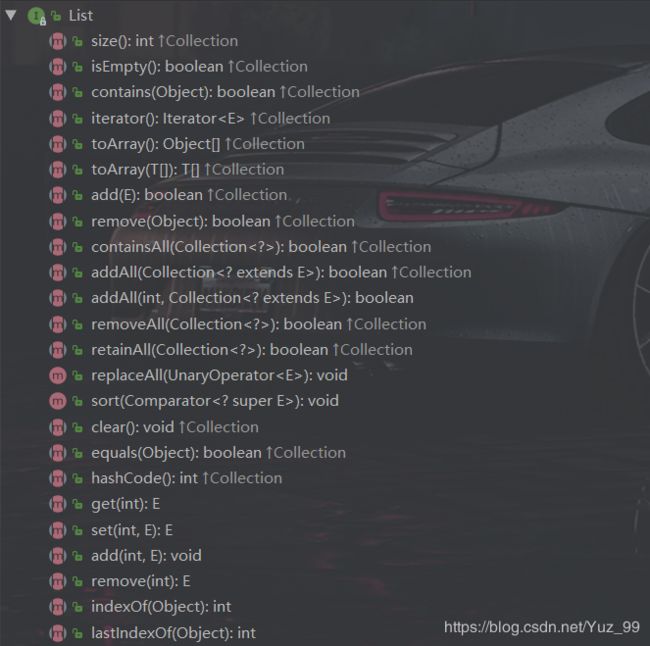
1.1 List
查看: https://blog.csdn.net/jack__frost/article/details/58072072
- 代表有序、重复的集合。
- 像一个数组,可以记住每次添加元素的顺序(要以对象的形式来理解),且长度是可变的。3.访问的时候根据元素的索引值来访问。
可以看到List同样继承了Collection
![]()
1.1.1 ArrayList
查看: https://blog.csdn.net/hehexiaoyou/article/details/23338101
https://blog.csdn.net/opensuns/article/details/82777473
![]()
ArrayList是一个大小可变的数组,但它在底层使用的是数组存储(也就是elementData变量),而且数组是定长的,要实现动态长度必然要进行长度的扩展。
//添加单个元素
public boolean add(E e) {
//判断添加后的长度是否需要扩容
ensureCapacityInternal(size + 1);
//在数组末尾添加上当前元素,并且修改size大小
elementData[size++] = e;
return true;
}
//集合的初始容量为10
private static final int DEFAULT_CAPACITY = 10;
//判断是否是第一次初始化数组
private void ensureCapacityInternal(int minCapacity) {
//判断当前数组是否 == EMPTY_ELEMENTDATA,因为默认构造函数创建时是将空数组EMPTY_ELEMENTDATA赋值给elementData
if (elementData == EMPTY_ELEMENTDATA) {
//判断默认容量10和当前数据长度的大小,取其中大的值作为判断本次是否需要扩容的依据,由于第一次数组是空的,所以默认要使数组扩容到10的长度
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
//判断是否需要扩容
ensureExplicitCapacity(minCapacity);
}
//判断扩容的方法
private void ensureExplicitCapacity(int minCapacity) {
//如果需要扩容modCount++,此参数是指当前列表结构被修改的次数
modCount++;
// 判断当前数据量是否大于数组的长度
if (minCapacity - elementData.length > 0)
//如果大于则进行扩容操作
grow(minCapacity);
}
//扩容方法
private void grow(int minCapacity) {
// 记录扩容前数组的长度
int oldCapacity = elementData.length;
//将原数组的长度扩大0.5倍作为扩容后新数组的长度(如果扩容前数组长度为10,那么经过扩容后的数组长度应该为15)
int newCapacity = oldCapacity + (oldCapacity >> 1);
//如果扩容后的长度小于当前数据量,那么就将当前数据量的长度作为本次扩容的长度
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
//判断新数组长度是否大于可分配数组的最大大小
if (newCapacity - MAX_ARRAY_SIZE > 0)
//将扩容长度设置为最大可用长度
newCapacity = hugeCapacity(minCapacity);
// 拷贝,扩容,构建一个新的数组
elementData = Arrays.copyOf(elementData, newCapacity);
}
//判断如果新数组长度超过当前数组定义的最大长度时,就将扩容长度设置为Interger.MAX_VALUE,也就是int的最大长度
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE : MAX_ARRAY_SIZE;
}
- 不指定ArrayList的初始容量,在第一次add的时候会把容量初始化为10个,这个数值是确定的;
- ArrayList的扩容时机为add的时候容量不足,扩容的后的大小为原来的1.5倍,扩容需要拷贝以前数组的所有元素到新数组。
1.1.2 Vector
查看: https://www.cnblogs.com/chenssy/p/3802826.html
我先了解了一下vector的扩容原理,vecctor底层是数组结构,是一段连续的数组,当集合也就是数组装满以后,如果还需要增加数据,为保证连续性,会重新申请更大的内存空间,然后将现有数据复制到新的内存空间中,再将新增数据添加到数组里面,释放原来的内存,其内存地址也相应改变,指向原vector的所有迭代器就都会失效。


Vector在对象创建史如果没有传任何参数,同样默认初始容量是10;若传递了一个 初始容量参数,则创建的对象的容量值为指定的初始容量值;
minCapacity: 当前需要的长度



看完源码,我们会发现添加元素的时候 先确认容器大小,比如我里面已经存了几个数组了,容量和容器大小的概念是不同的。
为什么vector增长为原来的一倍,而arrayList增长为原来的一半多?
ArrayList有两个属性,存储数据的数组elementData,和存储记录数目的size。
Vector有三个属性,存储数据的数组elementData,存储记录数目的elementCount,还有扩展数组大小的扩展因子 capacityIncrement。
对比两者结构,arrayList没有扩展因子,也就是说vector可以指定每次增长的容量,arrayList不可以指定扩展大小。
那么modcount是用来干嘛的?
查看: https://blog.csdn.net/DG237/article/details/70037539
https://blog.csdn.net/badguy_gao/article/details/78989637
这是用来记录容器的修改次数
在ArrayList,LinkedList,HashMap等等的内部实现增,删,改中我们总能看到modCount的身影,modCount字面意思就是修改次数,但为什么要记录modCount的修改次数呢?
大家有没有发现一个公共特点,所有使用modCount属性的全是线程不安全的,这是为什么呢?说明这个玩意肯定和线程安全有关系喽,那有什么关系呢?
由以上代码可以看出,在一个迭代器初始的时候会赋予它调用这个迭代器的对象的mCount,如果在迭代器遍历的过程中,一旦发现这个对象的mcount和迭代器中存储的mcount不一样就抛异常
Fail-Fast 机制 (快速失败)
在java的集合类中存在一种Fail-Fast的错误检测机制,当多个线程对同一集合的内容进行操作时,可能就会产生此类异常。
比如当A通过iterator去遍历某集合的过程中,其他线程修改了此集合,此时会抛出ConcurrentModificationException异常。
此类机制就是通过modCount实现的,在迭代器初始化时,会赋值expectedModCount,在迭代过程中判断modCount和expectedModCount是否一致。
1.1.3 LinkedList
查看 : https://mp.weixin.qq.com/s?src=11×tamp=1561865736&ver=1699&signature=FICvoT5sXiYO9AYflXSQrlHM2Wt2VrHE9s2vm6VVmOcKYPP5GH08aYJK-FLvLISkEOlUKNk-R7Spr5BVtkfU7fMPti0OpLSCGgV7Hm97y4tWVAO0PuFXmuMjxufx&new=1

查看LinkedList的源码,发现其继承自AbstractSequentialList,实现了List,Deque,Cloneable以及Serializable接口,如:
也就意味着:
-
LinkedList 是一个继承于AbstractSequentialList的双向链表。它也可以被当作堆栈、队列或双端队列进行操作。
-
LinkedList 实现 List 接口,能对它进行列表操作。
-
LinkedList 实现 Deque 接口,即能将LinkedList当作双端队列使用。
-
LinkedList 实现了Cloneable接口,即覆盖了函数clone(),能克隆。
-
LinkedList 实现java.io.Serializable接口,这意味着LinkedList支持序列化,能通过序列化去传输。
1.2 Set
1.2.1 HashSet
查看: https://blog.csdn.net/zhaojie181711/article/details/80480421

HashSet总结:
HashSet()
构造一个新的空 set,其底层 HashMap 实例的默认初始容量是 16,加载因子是 0.75。
HashSet(Collection c)
构造一个包含指定 collection 中的元素的新 set。
HashSet(int initialCapacity)
构造一个新的空 set,其底层 HashMap 实例具有指定的初始容量和默认的加载因子(0.75)。
HashSet(int initialCapacity, float loadFactor)
构造一个新的空 set,其底层 HashMap 实例具有指定的初始容量和指定的加载因子。
1.实现原理,基于哈希表(hashmap)实现。
2. 不允许重复键存在,但可以有null值。
3. 哈希表存储是无序的。
4. 添加元素时把元素当作hashmap的key存储,HashMap的value是存储的一个固定值object
5. 排除重复元素是通过equals检查对象是否相同。
6. 判断2个对象是否相同,先根据2个对象的hashcode比较是否相等(如果两个对象的hashcode相同,它们也不一定是同一个对象,如果不同,那一定不是同一个对象)如果不同,则两个对象不是同一个对象,如果相同,在将2个对象进行equals检查来判断是否相同,如果相同则是同一个对象,不同则不是同一个对象。
7. 如果要完全判断自定义对象是否有重复值,这个时候需要将自定义对象重写对象所在类的hashcode和equals方法来解决。
8. .哈希表的存储结构就是:数组+链表,数组的每个元素都是以链表的形式存储的。
hashSet的实现原理?
往HashSet添加元素的时候,HashSet会先调用元素的hashCode方法得到元素的哈希值,然后通过元素的哈希值经过移位等运算,就可以算出该元素在哈希表中的存储位置。
情况1:如果算出元素存储的位置目前没有任何元素存储,那么该元素可以直接存储到该位置上。
情况2:如果算出该元素的存储位置目前已经存在有其他的元素了,那么会调用该元素的equals方法与该位置的元素再比较一次,如果equals返回的是true,那么该元素与这个位置上的元素就视为重复元素,不允许添加。如果equals方法返回的是false,那么添加该元素运行
总结:
HashSet基于HashMap实现,与HashMap一样无序,线程不安全,利用HashMap的key不可重复从而实现HashSet不含重复元素
1.2.2 TreeSet
查看: https://blog.csdn.net/zhaojie181711/article/details/80494318

总结:
TreeSet是通过TreeMap实现的一个有序的、不可重复的集合,底层维护的是红黑树结构。当TreeSet的泛型对象不是java的基本类型的包装类时,对象需要重写Comparable#compareTo()方法
2 Map
查看: https://www.sogou.com/link?url=DOb0bgH2eKh1ibpaMGjuy6YnbQPc3cuK0GfiVt0s695omuBEhdSpHkUUZED5fr2OOHHhgxC6LoA84Z3J1tKSNg…
什么是Map?
Map是将键映射到值( key-value )的对象。
一个映射不能包含重复的键;每个键最多只能映射到一个值。
Map 接口提供三种collection 视图,
允许以键集(keySet())、
值集(values())或键-值映射关系集(entrySet())的形式查看某个映射的内容
( 即获取键值对的内容 )。
Map与Collection的区别
- 1.Map 存储的是键值对形式的元素,键唯一,值可以重复。
- 2.Collection 存储的是单列元素,子接口Set元素唯一,子接口List元素可重复。
- 3.Map集合的数据结构值针对键有效,跟值无关,Collection集合的数据结构是针对元素有效
2.1 HashMap
查看以及引用: 两篇实属好文!
https://www.jianshu.com/p/8e668a010f43
https://www.jianshu.com/p/c45ec96868a8
https://www.jianshu.com/p/7db6fedc6df6

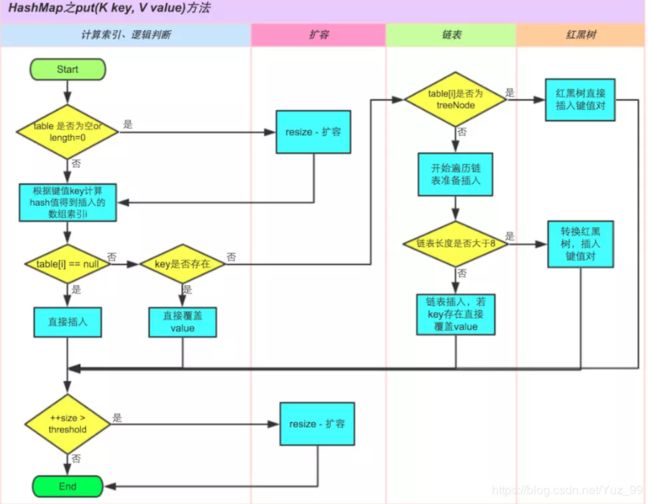

扩容机制 (resize):
- 1.之前说过HashMap是懒加载,第一次hHashMap的put方法的时候table还没初始化,
- 这个时候会执行resize,进行table数组的初始化,table数组的初始容量保存在threshold中(如果从构造器
- 中传入的一个初始容量的话),如果创建HashMap的时候没有指定容量,那么table数组的初始容
- 量是默认值:16。即,初始化table数组的时候会执行resize函数
- 2.扩容的时候会执行resize函数,当size的值>threshold的时候会触发扩容,即执行resize方法,
- 这时table数组的大小会翻倍。



2.2 Hashtable
查看: https://www.cnblogs.com/baxianhua/p/9254155.html
https://zhuanlan.zhihu.com/p/62321102


扩容:


2.3 HashMap和Hashtable的区别
查看: https://zhuanlan.zhihu.com/p/62321102

查看引用: https://www.jianshu.com/p/cc56440b3b6d

