云计算论文读书笔记1
论文读书笔记
论文:
Predicting Workflow Task Execution Time in the Cloud Using A Two-Stage Machine Learning Approach
作者:
Thanh-Phuong Pham , Juan J. Durillo, and Thomas Fahringer , Member, IEEE
期刊:
IEEE TRANSACTIONS ON CLOUD COMPUTING, VOL. 8, NO. 1, JANUARY-MARCH 2020
摘要:
许多技术,例如调度和资源配置等,都依赖于对不同输入数据的工作流任务的性能预测。然而,这样的预测很难在云计算系统中生成。本文介绍了一种新的两阶段机器学习方法,用于预测云计算系统中不同输入数据的工作流任务执行时间。为了实现高精度的预测,我们的方法依赖于反映运行时信息的参数和两个预测阶段。对四个现实世界中的工作流应用程序和几个商业云提供商的实证结果表明,我们的方法优于现有的预测方法。在我们的实验中,我们的方法分别得到的最佳情况估计误差和最坏情况估计误差为1.6%和12.2%,而现有的方法在超过75%的评估工作流任务中得到了超过20%的误差(在某些情况下甚至超过50%)。此外,我们还展示了我们预测特定云的方法产生的模型可以很容易地移植到新云上,并且只需要少量的运行就可以产生低误差。
一. 研究背景
本文的研究背景主要有两个部分:
1,工程背景
云计算范式为科学应用提供了各种优势,包括资源的快速提供、按使用付费和资源的灵活弹性。现在,许多科学家也使用科学工作流来组合他们的应用程序,以便在云上运行。工作流应用程序[1]由大量组件组成,如遗留程序、数据分析或计算方法、复杂模拟或更小的子工作流。
科学工作流应用程序非常耗时,在云基础设施上运行它们的成本非常高。所以科学工作流应用程序的一个重点就是对它运行时间、资源使用和经济成本进行有效优化。优化可以由不同技术实现,重点是调度资源去每个执行工作流任务的地方,以及确定任务所需要资源的种类和数量[2]。这些调度和资源配置技术通常可以从工作流任务的运行时间信息中获益。然而,由于各种原因,任务运行时间并不容易在运行前得知。所以,作者需要一种方法来预测工作流任务的运行时间。
2,学术背景
对集群、网格或云的性能预测的研究已经活跃了几十年。传统的方法可以分为三类:1,分析建模;2,仿真模拟;3,经验评价。第一类,分析建模,包括基于应用程序和体系结构的高级抽象的方法,这些方法易于快速评估。第二类,仿真模拟,是基于模拟/仿真应用程序如何在给定的目标体系结构上运行的思想。模拟器/仿真器允许一个高精确度的硬件细节模型,但是生成的计算成本很高。典型的模拟器/仿真器需要应用程序的源代码和精确的硬件信息,根据这些信息计算机器指令的数量及其执行时间。第三类,经验评估,依赖于一个更快的硬件模型原型来评估和测量应用程序运行时。这类方法的适用性取决于此类硬件原型的可用性。对于云计算来说,很难确定任务运行的硬件,因此,第三类方法不适用于作者的情况。接下来,作者进一步分析属于前两类的一些相关工作。
一些预测方法基于一个回归函数,该函数从一组独立变量估计应用程序的运行时间。这种方法就属于分析建模的范畴。相关的论文有很多,不同之处在于确定回归函数的方式及其所依赖的变量。最流行的回归方法是机器学习,简化形式就是线性回归;还有其他回归方法,如最近邻,实例模型学习,回归树,或者是以上这些方法的组合。性能预测方法所依赖的自变量的典型例子是应用程序输入数据、内核数量和其他特定的硬件细节。例如,作业名、用户名和提交时间被用来预测集群[3]、[4]中的执行时间。其他工作需要系统性能属性(CPU微架构、大小、内存和存储速度)[5]。据[6]、[7]报告,CPU架构、内存和存储速度是提高预测应用程序执行时间准确性的重要属性。然而,相关工作用到的大多数变量都不适用于商业云,例如,商业云通常没有用户向其提交任务的队列,而商业供应商很少提供关于其物理硬件的信息。
基于前两类方法的工作有很多,比如ASPEN [17],COMPASS [8],PALM [9], 或PEMOGEN [10]。它们都试图以类似的方式解决这个问题:定义一种用于注释应用程序源代码的特定于领域的语言。这些注释必须由专家分析人员提供,并用于估计该应用程序所执行的机器指令的数量。这些估计是基于类似回归的方法和对机器指令执行的模拟。这些方法的不同之处在于它们如何处理各种硬件架构。例如,在PALM中获得的估计是特定于硬件的。在其他情况下,需要一个详细描述硬件的模型。例如,COMPASS和ASPEN需要关于每个CPU核心的详细信息,比如它是否支持双精度指令以及是否存在乘法加法指令;容量、延迟和内存带宽;缓存信息(内核之间的共享缓存,以及它们的容量),以及同一套接字内的核之间的链接类型(快速互连(QPI)、超传输或PCI)。虽然这些方法可以实现较低的预测误差,但它们对于作者目标的可用性是有限的。首先,在作者的工作中,作者不假设应用程序的源代码是可用的;对于可用代码的情况,作者不限制用特定语言编写的应用程序,这使得注释的使用更加困难。其次,作者不希望依赖于专家分析师,作者的目标是提供一种完全自动化的方法。最后,作者不能依赖于特定于体系结构的方法,因为应用程序所运行的云系统中的目标体系结构通常是未知的。在云计算领域,CloudProphet[11]是第二种方法的代表,它使用代理来模拟任务的运行行为。
在这篇文章的工作中,作者提出了一种性能预测方法,它属于第一种分析建模方法,用于预测云的工作流任务的运行时间。这种方法是完全自动化的,不需要任何专家分析师。
二,基础知识
在开始介绍本文的方法前,需要简单介绍一下基础知识,主要是三个方面:机器学习、云计算和工作流。
1,机器学习
机器学习(ML)方法,通常学习一组输入数据和输出之间的关系。这种关系通常是在观察一组已知输入和输出值的数据后得出的。在ML领域,这组数据通常被称为训练集或简称为训练数据。输出可以是任何函数或值集。ML通常使用关于工作流的过去执行的历史数据作为培训数据。本文研究问题要学习的输出是任务执行次数。通常用于执行时间预测的方法有线性回归[12]、回归树[13]、使用回归树的套袋法[14]和人工神经网络[15]。在本文中,作者评估了这些ML方法,以及另一种称为随机森林[16]的ML集成方法,该方法通常在有噪声数据的情况下提供更好的预测精度。作者还将聚类技术应用于数据,以识别历史数据的子集,这些子集暴露了与执行时间的高度相关性。
2,云计算
云计算是一种模型,它支持按需网络访问可配置计算服务的共享池,这些服务可以用最少的管理工作或服务提供者交互来快速供应和发布。作者的工作集中于基础设施即服务(IaaS)云,它为用户提供对计算资源的访问。本文使用的云模型类似于商业云,如Amazon Elastic Compute cloud (EC2)、谷歌计算引擎(GCE)和RackSpace cloud (RS)。在这个模型中,计算资源通过虚拟化提供给用户,虚拟化是一种允许在单个物理服务器上运行一个或多个VM的技术。VM是由软件表示的物理机器,它定义了自己的一套虚拟化硬件(RAM、虚拟CPU (vCPU)、硬盘等),在这些硬件上装载操作系统和应用程序。
3,科学工作流
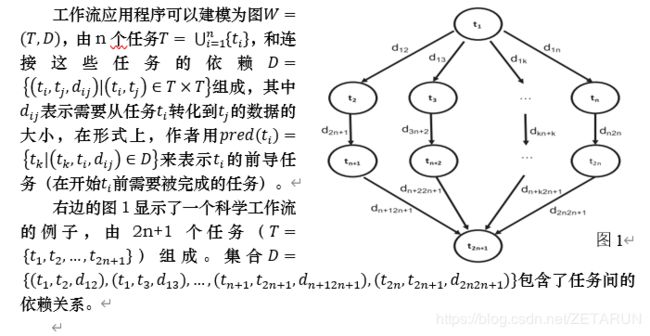
三,方法介绍
形式化一组IaaS云 C={c_1,c_2,…,c_p }和一组VM类型V={v_1,v_2,…,v_t },每种类型都由一些虚拟内核、特定的内存大小和给定的Linux操作系统版本组成。设一个工作流为W=(T,D),作者的目标是预测任务t_a∈ T在云系统c_r∈ C上的虚拟机v_v∈ V的运行时间。
作者使用机器学习来建立本文的模型,训练数据是一些在工作流上的运行任务,该工作流是在不同云上的许多虚拟机上对不同输入数据运行任务的。对于训练数据中涉及的每个任务运行,作者记录一组参数,ML方法使用这些参数来构建相应的运行时间模型。参数分为三部分,第一部分是工作流输入,第二部分是描述VM类型的参数,例如虚拟cpu数量或该VM提供的虚拟内存的数量,第三部分是运行时参数,包括CPU用户时间、CPU系统时间、I/O操作数量、网络带宽等信息。本文提出了一种两阶段机器学习预测技术的新方法:第一个阶段为每个运行时参数生成一个模型,目的是了解云分配给运行给定VM类型的硬件信息。这是用ML方法,通过将工作流输入与VM类型的信息与运行时参数相关联而得到的。第二个阶段使用第一阶段生成的运行时参数模型来预测任务的最终运行时间。
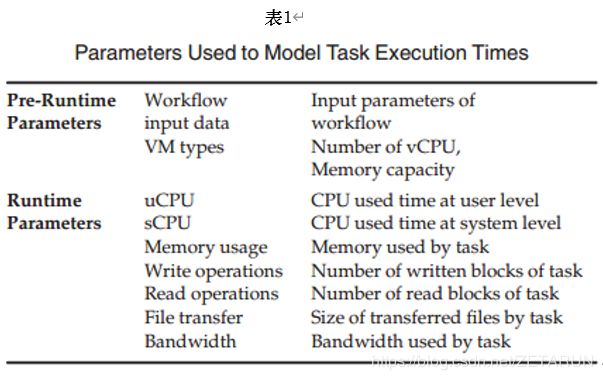
表1描述了本文的预测方法所考虑的参数,作者为所有工作流任务的每次执行收集这些参数。参数分为两组,分别称为运行前参数和运行时参数。在云上运行任务之前,可以静态地确定运行前参数。运行前参数包括工作流输入和描述虚拟化环境的参数。运行时参数反映了不同云提供商的不同虚拟机上任务的性能差异,并由实际运行任务决定。
算法描述:
设A={α_1,…,α_m}是运行前参数的集合。对于每一个运行前参数α_i,1≤i≤m,设Θ_i表示参数可能取值的集合。再设一个函数Γ_i,可以为任何执行在云c_r,虚拟机v_v上的任务t_a推导出上述的那个参数,这个函数可以用映射表示为:
Γ_i ∶T × V × C→ Θ_i ∀ 1≤i≤m
同理,设R={ρ_1,…,ρ_n}为n个运行时参数的集合。对于每一个运行前参数ρ_j,1≤j≤n,设Λ_j表示参数可能取值的集合。再设一个函数Δ_j,可以为任何执行在云c_r,虚拟机v_v上的任务t_a推导出上述的那个参数,这个函数可以用映射表示为:
Δ_j ∶T × V × C→ Λ_j ∀ 1≤j≤n

本文通过算法1所示的方法来预测工作流任务在云上的运行时间。算法的输入为任务t_a,虚拟机类型v_v,和云c_r。输出是任务的运行时间。最开始,处理给定的输入(行1-6),算法创造了一个向量,包含所有运行前参数α_i,1≤i≤m。然后,算法的第一步(行7-16)是通过输入来计算运行时参数。对于每一个运行时参数,有两种可能。如果输入在以前被运行过一次,那么运行时参数可以在历史数据中得到。否则,这个运行时参数要用算法2来预测。

在算法2中,输入和算法1相同,为任务t_a,虚拟机类型v_v,和云c_r。输出则是要预测的运行时参数。算法2的模型同样是使用ML,通过历史数据来训练。任何更好的机器学习方法都可以应用在这一个阶段。
一旦从历史数据中提取或预测了所有运行时参数的值,算法1就会进入第二步(行13),将运行前参数和运行时参数一起使用,以预测任务的运行时间。第二步再次合并了一个用历史数据训练的ML方法。
四,个人思考
总结:
在本文中,作者解决了预测不同IaaS云的不同输入数据的工作流任务执行时间的问题。给定要在特定云上执行的任务,作者的方法分两个阶段预测不同输入数据的执行时间。第一个阶段根据给定云或另一个云上的任务的历史数据预测运行时参数的值。第二阶段使用所有预测的运行时参数和运行前参数来预测任务的执行时间。
优点:
1,对构成四个实际工作流应用程序的任务的实验表明,作者的两阶段方法明显优于主要基于运行前参数的现有预测方法。为了说明作者的两阶段方法相对于基于运行前参数的预测方法的优势,作者评估了不同机器学习回归方法的使用,如线性回归、多层感知器、回归树、使用回归树的套袋法和随机森林。对这四种工作流程的平均相对绝对误差表明,两阶段方法在使用随机森林时比使用其他算法时具有更好的精度。作者还观察到,有两类任务比其他任务更难预测。这些类型执行时间短(少于1秒),并且/或者是依赖于带宽的任务。
2,此外,作者还演示了作者的两阶段模型可以用于预测新的IaaS云的任务运行时间。仅通过少量的运行,模型的精度就可以得到很大的提高。在将作者的模型移植到三个商业云:Amazon EC2、谷歌计算引擎和Rackspace时,作者分析了这种行为。作者展示了在新云上仅运行5次任务所产生的预测错误,对于某些工作流任务,其估计错误可以达到10%以下。增加新云上的训练数据后,预测精度不断提高。
缺点与改进:
1,为了建立模型的预测器,作者首先收集所有的训练数据,然后生成预测模型,这种方法对于高度动态的云工作负载可能是不明智的。一个可能克服这个问题的解决方案是在每次任务运行后更新作者的预测器,即每当有新数据可用时,就对模型重新训练。
2,在云计算领域,对任务的性能预测有助于更好地调度和资源配置。但本文的算法只针对了预测工作流的运行时间,实际上可以预测的与性能相关的数据还有很多,比如空间。本文可以在其他指标方面做拓展,得到更加综合的结果。
五,参考文献
[1] J. Qin and T. Fahringer, Scientific Workflow: Programming, Optimization,
and Synthesis with ASKALON and AWDL. Berlin, Germany:Springer, 2012.
[2] J. Durillo and R. Prodan, “Multi-objective workflow scheduling in amazon EC2,” Cluster Comput., vol. 17, no. 2, pp. 169–189, 2014.
[3] H. Li, D. Groep, and L. Wolters, “An evaluation of learning and heuristic techniques for application run time predictions,” in Proc. 11 th Annu. Conf. Advance School Comput. Imag., 2005.
[4] W. Smith, I. Foster, and V. Taylor, “Predicting application run times with historical information,” J. Parallel Distrib. Comput., vol. 64, no. 9, pp.
1007–1016, Sep. 2004. [Online].
Available:http://dx.doi.org/10.1016/j.jpdc.2004.06.008
[5] A. Matsunaga and J. A. B. Fortes, “On the use of machine learning to predict the time and resources consumed by applications,” in Proc. 2010 10th IEEE/ACM Int. Conf. Cluster Cloud Grid Comput., 2010, pp. 495–504. [Online]. Available:http://dx.doi.org/10.1109/CCGRID.2010.98
[6] P. Dinda, “Online prediction of the running time of tasks,” in Proc.10th IEEE Int. Symp. High Perform. Distrib. Comput., 2001, pp. 383–394.
[7] P. Dinda and D. O’Hallaron, “An evaluation of linear models forhost load prediction,” in Proc. 8th Int. Symp. High Perform. Distrib. Comput., 1999, pp. 87–96.
[8] S. Lee, J. S. Meredith, and J. S. Vetter, “Compass: A framework forautomated performance modeling and prediction,” in Proc. 29th ACM Int. Conf. Supercomputing, 2015, pp. 405–414. [Online]. Avail- able: http://doi.acm.org/10.1145/2751205.2751220
[9] N. R. Tallent and A. Hoisie, “Palm: Easing the burden of analyticalperformance modeling,” in Proc. 28th ACM Int. Conf. Supercomput- ing, 2014, pp. 221–230. [Online]. Available: http://doi.acm.org/ 10.1145/2597652.2597683
[10] A. Bhattacharyya and T. Hoefler, “Pemogen: Automatic adaptive
performance modeling during program runtime,” in Proc. 23rd Int. Conf. Parallel Archit. Compilation, 2014, pp. 393–404. [Online]. Available: http://doi.acm.org/10.1145/2628071.2628100
[11] A. Li, X. Zong, S. Kandula, X. Yang, and M. Zhang,“Cloudprophet: Towards application performance prediction in cloud,” SIGCOMM Comput. Commun. Rev., vol. 41, no. 4, pp. 426–427, Aug. 2011. [Online]. Available: http://doi.acm.org/10.1145/ 2043164.2018502
[12] I. H. Witten, E. Frank, and M. A. Hall, Data Mining: Practical Machine Learning Tools and Techniques, 3rd ed. San Francisco, CA, USA: Morgan Kaufmann Publishers Inc., 2011.
[13] S. Salzberg, “C4.5: Programs for machine learning by j. ross quin-lan. morgan kaufmann publishers, inc., 1993, ” Mach. Learning, vol. 16, no. 3, pp. 235–240, 1994. [Online]. Available: http://dx.doi.org/10.1007/BF0099 3309
[14] D. A. Monge, M. Holec, F. Zelezny, and C. Garino, “Ensemble learning of runtime prediction models for gene-expression analysis workflows,” Cluster Comput., vol. 18, no. 4, pp. 1317–1329, 2015.
[Online]. Available: http://dx.doi.org/10.1007/s10586–015-0481-5
[15] J. W. Shavlik, R. J. Mooney, and G. G. Towell, “Symbolic and neural learning algorithms: An experimental comparison,” Mach. Learning, vol. 6, no. 2, pp. 111–143, 1991.
[16] L. Breiman, “Random forests,” Mach. Learning, vol. 45, no. 1,pp. 5–32, 2001. [Online]. Available: http://dx.doi.org/10.1023/A%3A10109334043 24
[17] K. L. Spafford and J. S. Vetter, “Aspen: A domain specific language for performance modeling,” in Proc. Int. Conf. High Perform. Comput., Netw. Storage Anal., 2012, pp. 84:1–84:11. [Online]. Avail- able: http://dl.acm.org/citation.cfm?id=2388996.2389110