Thanos 简介和实践
女主宣言
随着 Openstack 集群规模越来越大,监控数据呈现指数级增长,给后期计算、存储资源扩容带来了极大的考验。如何稳定、永久存储监控数据、快速查询热数据与历史数据一直是大规模云计算集群存在的问题,当然Openstack 社区的 Ceilometer 、Gnocchi、Aodh项目也未能很好解决我们目前存在的问题,在这里作者将介绍CNCF大杀器, Thanos + Prometheus TP组合(PS:并不是银弹)在Openstack与ceph集群中的概念和使用,将对以上问题作出有效的答复。
PS:丰富的一线技术、多元化的表现形式,尽在“360云计算”,点关注哦!

1
Thanos 是什么
英国游戏技术公司 Improbable 开源了他们的Prometheus 高可用解决方案。主页上简单易懂一段英文介绍如下:Open source, highly available Prometheus setup with long term storage capabilities。开源,高可用性的Prometheus 设置,并提供长期存储能力。
2
Thanos 有哪些特点
跨Prometheus 服务并提供统一的查询接口。
无限期的存储监控指标。目前支持S3、微软Azure、腾讯COS、Google GCP、Openstack Swift 等对象存储系统。
兼容现有的Prometheus API 接口 ,例如 Grafana 或者支持 Pormetheus Query API 等工具。
提供数据压缩功能和降准采样,提升查询速度。
重复数据删除和合并,并从Pormetheus HA 集群中收集指标。
3
Thanos 架构
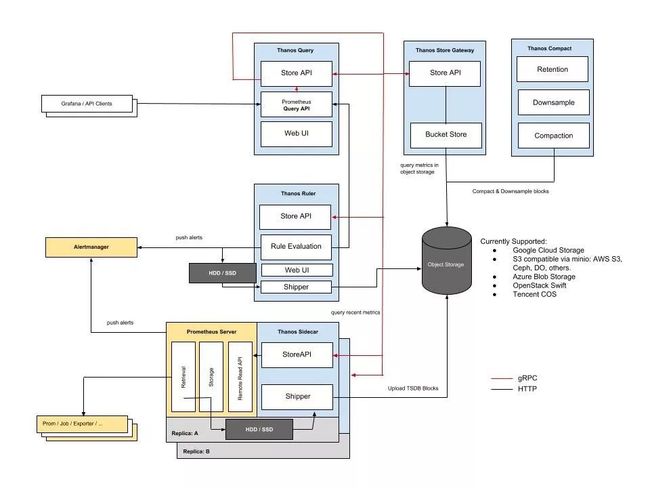
4
Thanos 架构中的组件
Compact
Compac提供数据降准和压缩功能,主要负责针对S3存储中的对象进行压缩,可以将历史数据中的Block合并压缩成大文件对象。实际上降准压缩并未节省任何空间,而且会在原始的Block增加2个块,但是在查询历史数据时会提升查询速度。
最后注意的是,由于进程运行时对中间数据进行处理,故本地需要足够的磁盘空间,随着数据增多空间需求越来越大,目前我们预留300GB 本地空间用作压缩中间数据的处理,并每三天进行一次压缩。
Querier
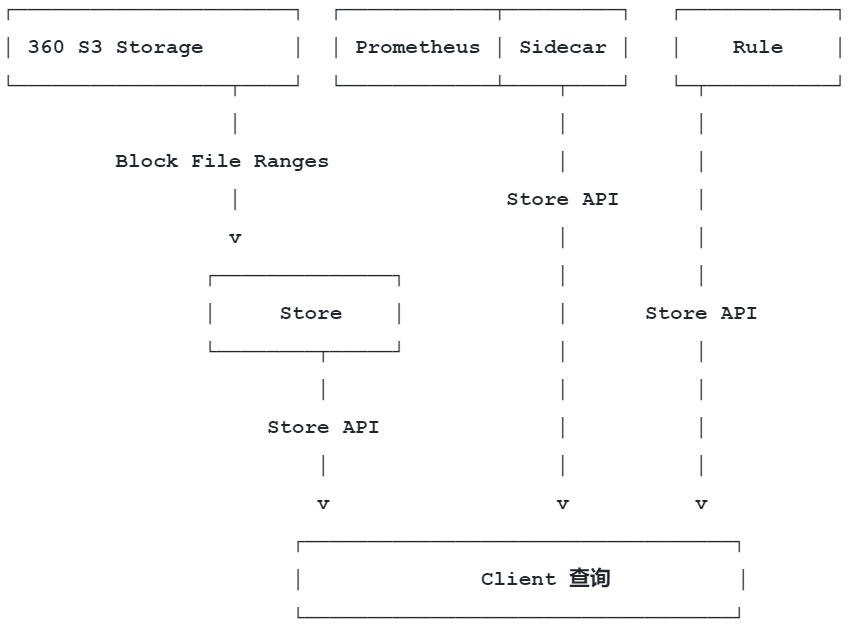
查询组件通过实现Pormetheus HTTP v1 API功能,组件接收到HTTP的PromSQL 查询请求后负责将数据查询和汇集。它是一个无状态的服务,支持水平扩展。

SideCar
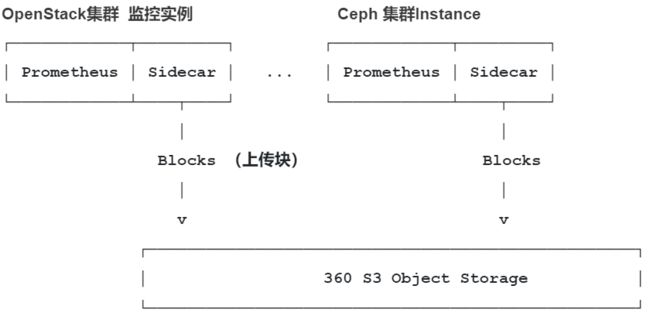
此组件需要和Pormetheus 实例一起部署,它主要起到两个作用,第一代理Querier 组件对本地Prometheus数据读取;第二是将Prometheus 本地监控数据通过对象存储接口上传到对象存储中。最后sidecar 会监视Prometheus的本地存储,若发现有新的监控数据保存到磁盘,会将这些监控数据上传至对象存储。
Store
Store 主要提供查询历史数据功能,当Querier组件调用Stroe 接口,Stroe 再通过对象存储接口获取数据,并将存储数据转换成Querier所需的数据格式。
Bucket
用于检查对象存储中的数据命令,通常作为独立命令运行并帮助我们进行故障排查,支持通过Web UI 查看目前Buket的数量。

Check
通过Thanos check 可以检查和验证Pormetheus Rules 是否正确,实现函数如下。
//定义检查Rules函数
func checkRules(logger log.Logger, filename string) (int, errors.MultiError) {
//记录日志,返回检测的文件名称和详细的日志信息
level.Info(logger).Log("msg", "checking", "filename", filename)
checkErrors := errors.MultiError{}
b, err :=
//读取Rules文件
ioutil.ReadFile(filename)
if err != nil {
checkErrors.Add(err)
return 0, checkErrors
}
//由于rules 格式需要纯Yaml格式,需要验证Yaml 格式是否正确
var rgs ThanosRuleGroups
if err := yaml.UnmarshalStrict(b, &rgs); err != nil {
checkErrors.Add(err)
return 0, checkErrors
}
// We need to convert Thanos rules to Prometheus rules so we can use their validation.
promRgs := thanosRuleGroupsToPromRuleGroups(rgs)
if errs := promRgs.Validate(); errs != nil {
for _, e := range errs {
checkErrors.Add(e)
}
return 0, checkErrors
}
numRules := 0
for _, rg := range rgs.Groups {
numRules += len(rg.Rules)
}
//函数结尾返回检查的rules 数量和错误的数量及错误信息
return numRules, checkErrors
}
5
Thanos 实践中我们遇到的问题
由于Thanos Store 启动时会加载可以访问的数据,他会在本地磁盘或者内存中加载少量的对象存储的块信息,随着时间的推移会造成本地磁盘和内存的爆满,导致集群异常,并引入如下多个问题。大量查询缓慢导致内存暴增并出现Store OOM。前期我们使用POD 方式部署Thanos集群,由于POD改变后IP发生变化,导致集群脑裂并崩溃,最后无法查询历史数据。考虑到Stroe组件比较消耗资源,我们将其转移到物理机上,Sidecar 和Pormetheus放入POD 当中。由于早期的版本性能比较差,我们将版本也进行了升级,并启用压缩功能。
启用压缩功能后:
9月28日至11月07日产生的监控数据量:

目前集成监控场景如下:
Ceph / Cephfs 、Lvs、Openstack、Etcd、K8s 、Istio 、Openstack 虚机监控。
提供API 查询接口与StackStorm 联动处理指定事件信息。
6
总结
Thanos 方案本身对于Prometheus 没有任何强势侵入,并增强了Prometheus的短板。最后Thanos 依赖于对象存储系统,这部分的资源尽量要考虑。目前线上包含了约40+套 Openstack,70+ 套的Ceph集群,约10000 +的OSD 节点数量,每天约产生约50G 监控数据。
Thanos 帮忙解决了哪些问题
由于存储大小的限制,历史数据存储的时间的问题 First Blood。
集群数量越来越多,Prometheus 查询性能出现卡顿 double kill。
Openstack 、ceph 集群数量比较多,无法通过统一的接口去查询数据和告警 triple kill。
360云计算
由360云平台团队打造的技术分享公众号,内容涉及数据库、大数据、微服务、容器、AIOps、IoT等众多技术领域,通过夯实的技术积累和丰富的一线实战经验,为你带来最有料的技术分享
