nvidia-docker2 在 Kubernetes 上实践
女主宣言
nvida-docker2 可以帮助我们将旧的加速计算应用程序容器化,将特定的 GPU 资源分配给容器,并可以轻松地跨不同的环境共享应用程序、协同工作和测试应用程序。今天带来的分享是有关 nvidia-docker2 在大规模 Kubernetes 集群上的实践记录。本文首发于 OpsDev.cn,转载已获取作者授权。
PS:丰富的一线技术、多元化的表现形式,尽在“HULK一线技术杂谈”,点关注哦!

The Dunes in Mars' Wirtz Crater
by NASA IOTD
现在公司线上所有的k8s集群对GPU资源的使用都是nvidia-docker 1.0(历史遗留问题)。但是现在的kubernetes1.9推荐使用device plugin的方式来对接外部厂商的资源。这样所有的厂商资源就不要kubernetes去特定的支持,而是各服务厂商只要按照kubernetes提供的device plugin实现自己的一套就可以了。今天就针对nvidia-docker2.0 进行了下测试。在此做下记录。
1
实验环境
CentOS Linux release 7.2.1511 (Core)
kuberntes: 1.9
GPU: nvidia-tesla-k80
2
Installation (version 2.0)
直接参照官方的安装教程: Installation (version 2.0))
https://github.com/nvidia/nvidia-docker/wiki/Installation-(version-2.0)
在安装nvidia-docker 2.0需要做一些准备的工作,要求如下:
GNU/Linux x86_64 with kernel version > 3.10
Docker >= 1.12
NVIDIA GPU with Architecture > Fermi (2.1)
NVIDIA drivers~= 361.93 (untested on older versions)
Your driver version might limit your CUDA capabilities
(see CUDA requirements)
https://github.com/nvidia/nvidia-docker/wiki/CUDA#requirements
简单的描述下安装的过程:
CentOS 7 (docker-ce), RHEL 7.4/7.5 (docker-ce), Amazon Linux 1/2
# If you have nvidia-docker 1.0 installed: we need to remove it and all existing GPU containers
docker volume ls -q -f driver=nvidia-docker | xargs -r -I{} -n1 docker ps -q -a -f volume={} | xargs -r docker rm -f
sudo yum remove nvidia-docker
# Add the package repositories
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.repo | \
sudo tee /etc/yum.repos.d/nvidia-docker.repo
# Install nvidia-docker2 and reload the Docker daemon configuration
sudo yum install -y nvidia-docker2
sudo pkill -SIGHUP dockerd
# Test nvidia-smi with the latest official CUDA image
docker run --runtime=nvidia --rm nvidia/cuda:9.0-base nvidia-smi
nvidia-docker 2.0安装完成之后,需要配置docker的runtime为nvidia-container-runtime。
具体的内容如下:
{
"default-runtime":"nvidia",
"runtimes": {
"nvidia": {
"path": "/usr/bin/nvidia-container-runtime",
"runtimeArgs": []
}
},
}
重新启动docker服务:
systemctl restart docker
注意:If you have a custom /etc/docker/daemon.json, the nvidia-docker2 package might override it.
3
GPU on kubernetes
简述的描述下现在kubernetes对GPU的支持情况。kubernetes在1.6版本就开始对nvidia GPU的支持,并且仍然在不断的优化改进中。kubernetes对AMD GPU的支持是在1.9版本才支持。但是现在kubernetes仍然还没有支持多容器使用同一块GPU卡的情况。这样就会造成GPU资源的浪费。
kubernetes 官方文档描述:
Each container can request one or more GPUs. It is not possible to request a fraction of a GPU.
nvidia-docker2.0 已经安装完成了,继续,下来就是如何在kubernetes上使用了。kubernetes要调度GPU 有这么几点要求:
开启kubernetes对GPU的支持。(在1.10之前需要指定--feature-gates="DevicePlugins=true"。1.10之后就不需要在指定了)。
在kubernetes计算节点安装GPU drivers及device plugin。
对Device Plugins进行下简单的描述:
从kuberntes 1.8版本开始提供一套device plugin framework来为服务厂商接入它们自己的资源(GPUs, High-performance NICs, FPGAs)。而不需要更改kubernetes的源码。
现在我们只关心Nvidia-GPU,让我们来部署GPU device plugin, 具体的部署流程如下:
nvidia-docker-plugin.yml
apiVersion: extensions/v1beta1
kind: DaemonSet
metadata:
name: nvidia-device-plugin-daemonset
namespace: kube-system
spec:
template:
metadata:
# Mark this pod as a critical add-on; when enabled, the critical add-on scheduler
# reserves resources for critical add-on pods so that they can be rescheduled after
# a failure. This annotation works in tandem with the toleration below.
annotations:
scheduler.alpha.kubernetes.io/critical-pod: ""
labels:
name: nvidia-device-plugin-ds
spec:
tolerations:
# Allow this pod to be rescheduled while the node is in "critical add-ons only" mode.
# This, along with the annotation above marks this pod as a critical add-on.
- key: CriticalAddonsOnly
operator: Exists
containers:
- image: nvidia/k8s-device-plugin:1.9
name: nvidia-device-plugin-ctr
securityContext:
allowPrivilegeEscalation: false
capabilities:
drop: ["ALL"]
volumeMounts:
- name: device-plugin
mountPath: /var/lib/kubelet/device-plugins
volumes:
- name: device-plugin
hostPath:
path: /var/lib/kubelet/device-plugins
创建GPU-device-plugin资源:
kubectl create -f nvidia-docker-plugin.yml
创建成功之后,在每台GPU机器上会有nvidia-device-plugin-daemonset的资源。
现在所有的准备工作都完成了。让我们来测试GPU能否正常的调度到GPU机器上吧。测试的gpu-pod资源mainfest内容如下:
nvidia-docker2-gpu-pod.yml
apiVersion: v1
kind: Pod
metadata:
name: cuda-vector-add
spec:
restartPolicy: OnFailure
containers:
- name: cuda-vector-add
image: "k8s.gcr.io/cuda-vector-add:v0.1"
resources:
limits:
nvidia.com/gpu: 1
nodeSelector:
accelerator: nvidia-tesla-k80 # or nvidia-tesla-k80 etc.
根据上面的文件创建资源并进行校验:
kubectl create -f nvidia-docker2-gpu-pod.yml
进入到容器中查看相关的设备及cuda库是否挂载到了容器中,并且验证我们给容器分配的只有一块卡。
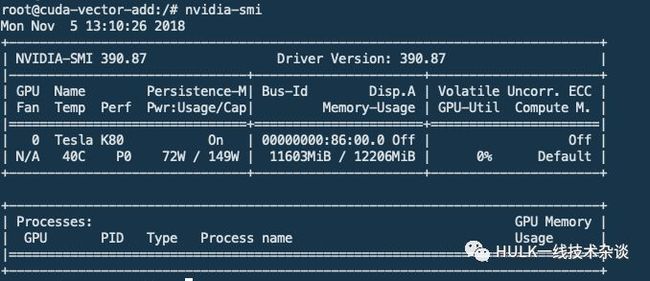
4
总结
在kubernetes中使用nvidia-docker 1.0的弊端在于,在使用资源对象进行资源创建的时候,需要在配置中将GPU Driver以volume的方式挂载到容器中,这步需要人为的进行干涉。
但是使用nvidia-docker 2.0的方式不要再在配置中指定GPU Driver的位置,完全有device plugin来做这件事,方便省事儿。并且kubernetes对外提供了device plugin的接口,也方便各个厂商来对自家的资源实现对k8s的无缝接入。
不仅仅是device plugin,kubernetes对容器运行时,也提供了同样的interface的方式,来对外提供对各家运行时的支持,这也就是kubernetes扩展性的强大之处吧。
HULK一线技术杂谈
由360云平台团队打造的技术分享公众号,内容涉及云计算、数据库、大数据、监控、泛前端、自动化测试等众多技术领域,通过夯实的技术积累和丰富的一线实战经验,为你带来最有料的技术分享
