秒杀总结
一、系统基本架构
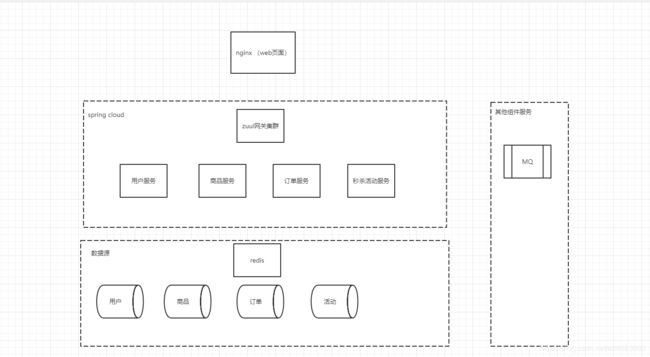
二、系统性能优化
web站点层 :
2.1 nginx和后端服务开启 keepalive 避免海量连接的创建。
查看当前nginx和某个tomcat的连接情况: ngtstat -an | grep ip | grep ESTABLISHED
2.2 商品基本信息等使用openresty开启nginx内存缓存dict。
使用这种方式是把数据推送到离用户最近的节点缓存上。nginx所有worker可见,lru淘汰。
但是更新机制不是很好,就是修改完数据不能及时更新这里的数据,如果能容忍脏读的话可以使用这种。
要平衡这个问题的话可以考虑使用 openresty redis的支持,只读不写数据.读redis的从节点数据,更新数据由后端的应用服务负者。
2.3 web页面可采用页面全静态化技术。(本项目中未使用)
服务层:
2.4 如果单实例服务压力过大则服务集群部署
查看linux系统使用情况,
1. top -H
1.1 %cpu(s) 0.2us 用户空间cpu的使用情况,就是应用程序运行消耗的cpu
1.2 0.1 sy 系统空间占用cpu的情况 ,应用程序发起系统调用后,程序处理消耗。 1.1 和 1.2l加起来不能超过cpu的核数
1.3 load average 0.2 0.1 00 分别是一分种,5分钟, 15分钟 cpu使用耗时情况 。几核cpu就要控制在几以内,超过则说明cpu饱和了
2.5 spingBoot的tomcat线程数优化。springboot有个默认的属性配置文件: spring-boot-autoconfigure spring-configuration-metadata.json
1.server.tomcat.** 都 是tomcat的一些默认配置参数
2.server.tomcat.accept-count: 当tomcat线程用完时等待队列的大小(默认 100)。再来的请求超过这个值则直接拒绝。
3.server.tomcat.min-spare-thread : 最小空闲数(默认10)
4.server.tomcat.max-connection :接口最大连接数 (默认10000)
5.server.tomcat.max-threads: tomcat最大支持的线程数(默认200) ,根据系统调用链路判断是否有较长时间的io等待,如果有则将线程设置大一些,最好不要超过1000。如果是几乎没有io操作,线程数是cpu核数的2位最佳。
2.6 对springCloud设置feign的参数,开启htppClient实现和连接数设置等,和hystix的线程池数量等。提高内部服务调用吞吐量。
2.7 修改内嵌tomcat参数,开启keepalive。减少连接创建消耗。
服务端设置参数:
keepAliveTimeOut:多少毫秒后不响应断开keepalive.
maxKeepAliveRequests: 多少次请求后keepalive断开。
2.8 当发布活动时将商品库存加载到redis中。下单校验及扣减库存都基于redis进行操作、数据库异步扣减(使用mq),并要保证缓存库存数量和数据库中的库存数量的一致性。
2.9 秒杀下单接口需要依赖合法令牌才能进入,将活动、用户等一些校验放到活动服务中,这些校验全部通过后生产令牌并发给用户,然后调用下单接口。
2.10 令牌大闸。就是控制令牌的发放数量,当活动发布时,将商品的库存数 乘以一个系数N做为令牌发放的数量。
2.11 如果商品库存多,并且商品种类多,令牌+大闸也是搞不住洪水的。这时就要引入队列泄洪,原理就是排队,实现就是用线程+队列。
可以使用 Executors.newFixedThreadPool 提交下单。
2.12 限流。防止系统被打挂 下单接口使用 gava 的 reteLimit
2.13 验证码防止刷,并且可以错峰。
数据库
2.14 将商品和库存表分成两张表设计 ,因为库存的修改并发高,分成多表后方便以后放到独立的库中,还可以根据库存表中的productId进行分表或分库,减少表的行级锁。修改频繁高的字段可考虑分出一张或多张子表存储。
2.15 数据库的查询和修改时的条件字段增加索引。
2.16 不同业务库冗余其他库的基本信息,减少跨库查询(主要是列表信息相关的查询)。