实时同步工具canal入门
canal主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费。在大数据中广泛用于实时数据的采集。
1.canal原理
mysql并没有实现增量数据的查阅消费功能,先来说说mysql主备复制原理。
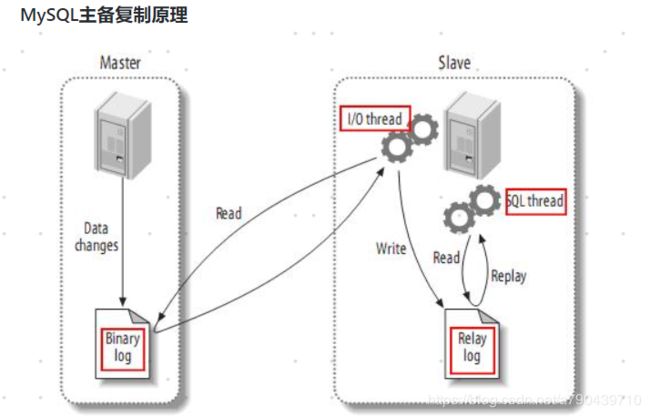
mysql主节点对数据库做了任何写操作,都会写入Binary log文件。而slave备份节点会主动去master节点读取Binary log文件,拷贝到自己的节点上,变为Relay log。最后slave节点读取Relay log看看它对数据库做了哪些操作,按照顺序执行日志的操作,达到同步更新的结果。

而canal正是利用了mysql主备复制原理。canal将自己伪装成一个mysql的备份节点,从master拉取binary log拷贝到自己节点上,然后根据用户的自定义的程序执行操作,可以写入mysql,kafka,es,hbase等。
插曲:
其实最开始canal并不是用于大数据的,而是用于缓存的。比如一些并发访问量大的程序可能会做一些缓存处理,而不是直接从mysql读取。比如客户端查询苹果手机价格,先从redis查询,没有查询到,继续从mysql查询。查询到价格后是5000元,将苹果手机价格5000保存在redis中,下次客户端直接从redis缓存中读取数据。过了一段时间,保存在mysql的苹果手机降价了,价格是4500元,如果现在再从redis缓存读取,那么价格是错误的。可是客户端发现缓存中已经有数据了,它不可能再从mysql读取数据了。所以我们需要实时更新redis缓存的数据,因此canal就起到了至关重要的作用。

2.canal搭建
1.开启mysql的binlog。
默认情况下mysql的binlog是没有开启的,所以我们首先要开启binlog。
修改 /etc/my.cnf 文件,在文件末尾加入以下几句话。

server-id相当于每一个mysql服务器的唯一标识,后面的canal也要设定,和mysql的不一样即可。
log-bin是设置日志文件的前缀名。设置完成后操作数据库,在 /var/lib/mysql/ 目录下就可以看到以mysql-bin开头的文件。

binlog_format是设置以什么样的形式来存储数据库变更的数据。这里详细解释下mysql的几种记录方式。
(1)binlog_format=statement
直接保存mysql语句。比如你执行了一句sql,update user_info set update_time='xxxx' where create_time='xxxx';日志文件会直接保存这句sql,大大减少了日志文件存储的内容。但是有一个缺点。比如update user_info set age=rand() where update_time='xxxx';其中age的赋值是rand(),取值是随机的。所以第二次执行sql的时候赋值会出问题。
(2)binlog_format=row
保存每行记录的变化。也就是只要有一行变化就记录一行,这样做的确规避了rand()类似的问题。但是也有一个缺点,就是update user_info set update_time='xxxx' where create_time='xxxx';这句sql如果有100万的数据改变,那么binlog就要记录100万行的数据,这显然不是很方便。
(3)binlog_format=mixed
一般情况下mysql会用statement来记录,遇到特殊情况就用row来记录,相当于结合了statement和row。
介绍完3种情况,结合我们采集实时数据,是需要知道每行的数据变化的,所以这里我们需要将binlog_format设置为row。
binlog-do-db是设置要监控的数据库名称。
2.安装canal
(1)下载解压canal。
(2)修改 conf/canal.properties。
//设置canal端口号
canal.port=11111
//取消注释
canal.instance.parser.parallelThreadSize = 16
(3)修改 conf/example/instance.properties
//slaveId和mysql的server-id要不一样
canal.instance.mysql.slaveId=10
//设置要监控的mysql地址
canal.instance.master.address=hadoop102:3306
//由于canal要读取mysql的内容,所以要给予canal一个权限。这里在mysql里面创建了一个canal账户。(在库mysql执行的sql:GRANT ALL PRIVILEGES ON *.* TO canal@'%' IDENTIFIED BY 'canal' ,执行完可以在user表查询是否添加成功)
canal.instance.dbUsername=canal
canal.instance.dbPassword=canal
canal.instance.connectionCharset = UTF-8
3.启动canal
./bin/startup.sh
启动完成后可以在/bigdata/canal/logs/example.log中查看日志是否启动成功。
3.Canal客户端消费。
1.maven引入canal客户端,kafka客户端(我这里直接将结果保存在kafka中)。
com.alibaba.otter
canal.client
1.1.2
org.apache.kafka
kafka-clients
0.11.0.2
2.编写客户端代码
类CanalApp
import com.alibaba.fastjson.JSONObject;
import com.alibaba.otter.canal.client.CanalConnector;
import com.alibaba.otter.canal.client.CanalConnectors;
import com.alibaba.otter.canal.protocol.CanalEntry.Column;
import com.alibaba.otter.canal.protocol.CanalEntry.Entry;
import com.alibaba.otter.canal.protocol.CanalEntry.EntryType;
import com.alibaba.otter.canal.protocol.CanalEntry.EventType;
import com.alibaba.otter.canal.protocol.CanalEntry.RowChange;
import com.alibaba.otter.canal.protocol.CanalEntry.RowData;
import com.alibaba.otter.canal.protocol.Message;
import com.google.common.base.CaseFormat;
import com.google.protobuf.ByteString;
import com.google.protobuf.InvalidProtocolBufferException;
import java.net.InetSocketAddress;
import java.util.List;
public class CanalApp {
public static void main(String[] args) {
//创建连接器
CanalConnector canalConnector = CanalConnectors.newSingleConnector(new InetSocketAddress("192.168.1.128", 11111), "example", "", "");
while(true){
//连接,订阅,抓取
canalConnector.connect();
//监控数据库中某张表
canalConnector.subscribe("gmall.order_info");
//message:一次canal从日志中抓取的信息,一个message包含多个sql(event)
Message message = canalConnector.get(100);
int size = message.getEntries().size();
if(size == 0){
try {
System.out.println("没有数据,暂停5秒");
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}else{
//entry: 相当于一个sql命令,一个sql可能会对多行记录造成影响
for (Entry entry : message.getEntries()){
//判断事件类型,只处理行变化的数据,过滤掉事务变化的数据
if(entry.getEntryType().equals(EntryType.ROWDATA)){
ByteString storeValue = entry.getStoreValue();
RowChange rowChange = null;
try {
//rowchange : entry经过反序列化得到的对象,包含了多行记录的变化值
rowChange = RowChange.parseFrom(storeValue);
} catch (InvalidProtocolBufferException e) {
e.printStackTrace();
}
//获得行集
List rowDataList = rowChange.getRowDatasList();
//eventtype 数据的变化类型 insert update delete create alter drop
EventType eventType = rowChange.getEventType();
String tableName = entry.getHeader().getTableName();
//这里只监控order_info表新增的数据
if("order_info".equals(tableName) && EventType.INSERT.equals(eventType)){
for (RowData rowData : rowDataList){
List afterColumnsList = rowData.getAfterColumnsList();
JSONObject jsonObject = new JSONObject();
for (Column column : afterColumnsList){
System.out.println(column.getName() + ":" + column.getValue());
//驼峰命名处理
String propertyName = CaseFormat.LOWER_UNDERSCORE.to(CaseFormat.LOWER_CAMEL, column.getName());
jsonObject.put(propertyName, column.getValue());
}
MyKafkaSender.send("GMALL_ORDER", jsonObject.toJSONString());
}
}
}
}
}
}
}
}
类MyKafkaSender
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
public class MyKafkaSender {
public static KafkaProducer kafkaProducer = null;
public static void send(String topic, String msg) {
if(kafkaProducer == null){
kafkaProducer = createKafkaProducer();
}
kafkaProducer.send(new ProducerRecord(topic, msg));
}
private static KafkaProducer createKafkaProducer() {
Properties properties = new Properties();
properties.put("bootstrap.servers", "hadoop102:9092,hadoop103:9092,hadoop104:9092");
properties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer producer = new KafkaProducer(properties);
return producer;
}
}
3.运行程序查看结果。
运行zookeeper
运行kafka集群
开启kafka-console消费
启动canal服务端
运行CanalApp
向表gmall.order_info插入数据后控制台kafka消费如下:
