SpringBoot整合ElasticSearch(控制度查询,父子关系建立)
花了一个多月的时间,终于从懵懵懂懂到现在基本弄出了一个比较完整的结合需求的搜索引擎。中间遇到了很多问题,踩过很多的坑,中间也查阅过很多资料。但是感觉这方面深入一点的只是还是蛮少的,现在就将一个多月里做出来的东西做一个总结,希望大家共勉。
ElasticSearch安装什么的我就不多说了,安装完之后记得顺带装上Elastic-head和Sense(Beta)两个插件。在Chrome里面有,可以轻松的看到索引数据等信息。这几块资料很多,不会的同学自行百度一下。这里强调一下千万要记得你使用的版本,就我个人这些天的使用来说,版本不一样,可能里面的方法会有这很大的不同。反正尽量将版本统一。
一、集群配置
集群好处不言而喻,现在基本上这种微服务的框架都会支持集群的配置。ES集群的配置也很简单,只需要将下载的ES文件复制几份就可以了。我这里用的是ES5.2.0,也就是2.X的版本。

复制完成之后,打开目录下面的config,找到elasticsearch.yml文件,并编辑。
主机配置:
cluster.name: market #集群名称
node.name: master #该节点名称
transport.tcp.port: 9300 #对应内部端口
http.port: 9200 #外部访问端口
network.host: 127.0.0.1 #对应ip
discovery.zen.ping.unicast.hosts: ["127.0.0.1:9300"] #主机ip
node.master: true #是否为主机从机配置:
cluster.name: market
node.name: server1
transport.tcp.port: 9301
http.port: 9201
node.master: false
network.host: 127.0.0.1
discovery.zen.ping.unicast.hosts: ["127.0.0.1:9300"]多个从机只需要改变其中的 node.name, transport.tcp.port, http.port三个变量就可以了。等全部配置完成之后,先重启一下服务,注意三个服务全部重启。然后打开elasticsearch-head插件查看集群状态,如果为绿色的,则证明搭建成功。如果为黄色的,可能是配置有问题,需要查看一下配置。
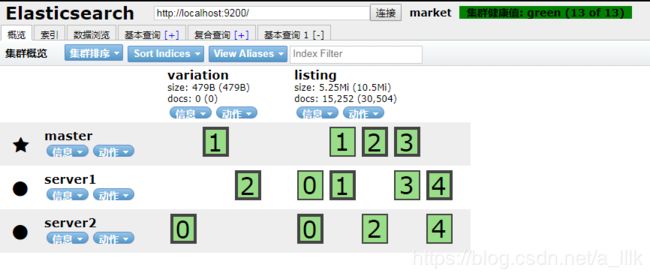
搭建成功示意。
二、SpringBoot+ElasticSearch
首先新建一个SpringBoot项目,然后导入Maven包。我Pom文件里东西太多了,我下面就只写与ES有关的包,其他的需要请自行添加。
org.springframework.boot
spring-boot-starter-data-elasticsearch
org.elasticsearch.client
transport
org.elasticsearch
elasticsearch
org.elasticsearch.plugin
transport-netty4-client
application.properties配置文件中加上如下配置,如果有集群的话,集群间使用逗号隔开,注意集群名字不要写错。
# elasticsearch搜索引擎
#节点名字,默认elasticsearch
spring.data.elasticsearch.cluster-name=market
#节点地址,多个节点用逗号隔开
spring.data.elasticsearch.cluster-nodes=127.0.0.1:9300,127.0.0.1:9301,127.0.0.1:9302
#是否开启本地存储
spring.data.elasticsearch.repositories.enabled=true
配置完之后去新建ES实体。这里的ES实体和普通的实体区别不大,只是需要加上@Document和@Field注解。
package com.isale.market.entity.es;
import lombok.*;
import lombok.extern.slf4j.Slf4j;
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.*;
import java.io.Serializable;
import java.math.BigDecimal;
import java.util.Date;
@Slf4j
@NoArgsConstructor
@AllArgsConstructor
@Data
@Document(indexName = "listing",type = "salesListing", shards = 3,replicas = 0, refreshInterval = "-1")
public class SalesListingES implements Serializable {
@Id
private Integer id;
@Field(type = FieldType.Text, searchAnalyzer="ik_max_word", analyzer="ik_max_word")
private String enTitle;
@Field(type = FieldType.Text, searchAnalyzer="ik_max_word", analyzer="ik_max_word")
private String cnTitle;
@Field(type = FieldType.Integer,store=true)
private int categoryId;
@Field(type = FieldType.Text, searchAnalyzer="ik_max_word", analyzer="ik_max_word")
private String description;
}
@Document中indexName对应的是索引名称,type对应的是该片段的名称,shard代表分片的数量,replicas代表副本数量。这些注解的具体意思可以到下面这个地址去看,写的很详细。
https://www.cnblogs.com/huangfox/p/3543351.html
这里注意es的indexName是不能用大写的,所有字母必须是小写。我当时某次使用大写,然后搞了半天索引无法创建。最后才发现是因为indexName写成了大写的原因。type名称没有要求。
@Field注解主要是对字段进行一些限制,type设置字段类型,因为我用的这个版本没有String类型,可以使用Text代替。后面SearchAnalyzer是设置分词器,如果在安装阶段没有安装分词器插件或者没有这个需求,就无需设置。分词器的安装可自行百度。
建完索引之后,去建相关的ESRepository接口,并继承,ElasticsearchRepository接口。
@Repository
public interface SalesListingESRepository extends ElasticsearchRepository {
} 然后Service层中注入该接口,就和JAP的使用方法一样,可以调用其中的CRUD方法对ES中的数据进行操作。这步比较简单,间不用多说了。
三、批量数据插入
想要把MySQL的数据批量插入到ES实体中,现在比较流行是使用logstash-input-jdbc插件。我本人也使用过这个插件,但是这个插件有一个巨大的问题,就是假如已经生成了ES实体,并指定某些字段的格式,如分词,类型等。如果使用logstash-input-jdbc批量插入,则会覆盖你指定的格式,也就是类似于重新生成一份index。如果需要指定mapping的同学还是不要使用这个工具,如果只是开始学,想加入测试数据的,可以使用这个工具。具体安装我就不多逼逼了,想要使用这个,必须安装node.js和logstash,不会的同学自行百度,这里主要讲一下配置。安装好以上两个插件之后,打开logstash目录下面的bin目录。在bin目录中新建一个后缀为.conf的文件,我这里就叫mysql.conf。然后打开这个配置文件,写入如下代码。
input {
stdin {
}
jdbc {
jdbc_connection_string => "jdbc:mysql://localhost/item"#数据库名称
jdbc_user => "root"#用户名
jdbc_password => "1234"#密码
jdbc_driver_library => "F:/downsoft/logstash-5.3.2/jdbc/mysql-connector-java-5.1.47.jar"#mysql驱动位置
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_paging_enabled => "true"
jdbc_page_size => "50"
statement => "select * FROM item_cat"#想要插入的表名
schedule => "* * * * *"
type => "itemCat" #type名称
}
}
filter {
json {
source => "message"
remove_field => ["message"]
}
}
output {
elasticsearch {
hosts => ["localhost:9200"]
index => "item"
document_id => "%{cid}"#索引id对应的数据库id
# template_name => "test"
# template => "F:/downsoft/logstash-5.3.2/jdbc/item.json"
}
stdout {
codec => json_lines
}
}
这里注意记得导入mysql的jar包存放的位置,然后把数据库的信息改成自己对应的信息就可以了。改完之后,保存一下。然后打开dos,进入该配置文件存放的地址。输入logstash -f +配置文件名。然后按回车。
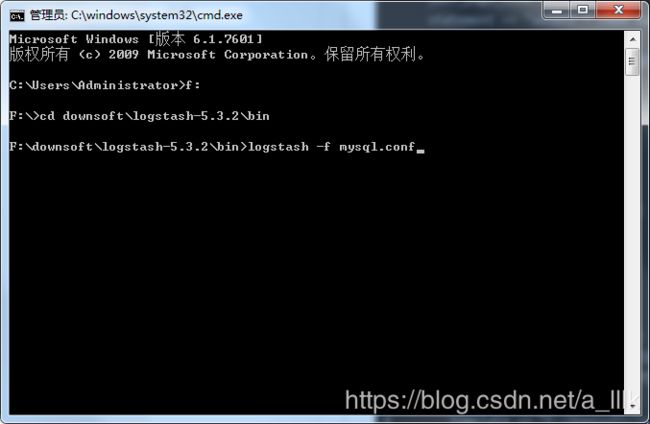
如果这里有success,就配置文件没有问题,如果现实unsuccess,则会把配置文件的错误提示出来,根据提示修改配置就可以了。

等待所有数据跑完,可以去elasticsearch-head里面查看索引状况。
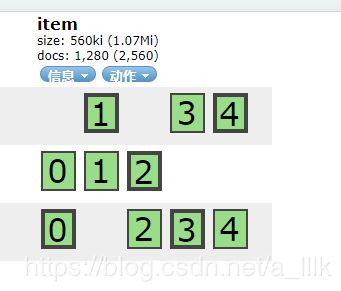
这边多说一句,如果是指定了maping(ES字段)的格式,是无法使用这个工具批量导入的。目前来说我没找到比较好用的批量导入的工具。如果各位朋友有什么好用的,也可以在下面留言告诉我。我目前导入数据的方式还是使用比较笨的,查一条提交一条,这个方法超级慢。但是可以保证不会去覆盖已定义的mapping。
四、查询控制相关度
这个功能在日常开发中也比较常用,主要作用就是查询某个字段,然后通过设置条件去将查询结果和设置条件的结果整合,得到一个最期望拿到的数据。比如淘宝搜索一个商品,搜出来的结果可能会加上销量,价格等条件,综合考虑去给出结果。个人觉得ES在这方面做了很多的设定,用户可以通过设置不同的算法和参数,去拿到自己最期望得到的值。先附上ES的开发文档地址,弄不懂的同学可以去这里查看一下,注意换到自己对应的版本,不同版本可能会有一些出入。
https://www.elastic.co/guide/cn/elasticsearch/guide/current/controlling-relevance.html
我在这边主要去讲一下function_score查询。这个查询算比较完整的控制了用户想要考虑的各个因素。这是弱弱的吐槽一句,ES这个文档弄得有点恼火,你看懂了ES的语句,如果想要获得javaAPI,又要花大量的时间去找对应版本的API。还不如把两个开发文档合在一起,将某个功能javaAPI的链接加在该功能介绍的最下面。这样能减轻很多负担。function_score对应的javaAPI地址。
https://www.elastic.co/guide/en/elasticsearch/client/java-api/5.2/java-compound-queries.html
package com.elasticsearch.demo;
import org.apache.lucene.search.join.ScoreMode;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.transport.TransportClient;
import org.elasticsearch.common.settings.Settings;
import org.elasticsearch.common.transport.InetSocketTransportAddress;
import org.elasticsearch.common.unit.TimeValue;
import org.elasticsearch.index.query.QueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.index.query.functionscore.FunctionScoreQueryBuilder;
import org.elasticsearch.rest.RestStatus;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.elasticsearch.transport.client.PreBuiltTransportClient;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import static org.elasticsearch.index.query.QueryBuilders.boostingQuery;
import static org.elasticsearch.index.query.QueryBuilders.matchQuery;
import static org.elasticsearch.index.query.QueryBuilders.rangeQuery;
import static org.elasticsearch.index.query.functionscore.ScoreFunctionBuilders.*;
import java.net.InetAddress;
/**
* @Author: lk
* @Date: 2018/10/3 0003 下午 3:22
* @Description:
*/
@RestController
@RequestMapping("test2")
public class Test2 {
private String host = "127.0.0.1";
private int port = 9300;
@GetMapping("test")
public String test(String search) throws Exception {
search = "0.46/0.71MM 20PCS Smooth Acoustic Guitar Pick Picks Plectrum Celluloid Electric";
Settings settings = Settings.builder()
.put("client.transport.sniff", true)
.put("cluster.name", "market")
.build();
TransportClient client = new PreBuiltTransportClient(settings)
.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"), 9300))
.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"), 9301))
.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"), 9302));
float a = (float) 1;
float b = (float) 2;
FunctionScoreQueryBuilder.FilterFunctionBuilder[] functions = {
new FunctionScoreQueryBuilder.FilterFunctionBuilder(
QueryBuilders.termQuery("sold", "0"), weightFactorFunction(a)
),
new FunctionScoreQueryBuilder.FilterFunctionBuilder(
rangeQuery("price").from("15").to("30"), weightFactorFunction(b)
),
};
SearchRequest searchRequest = new SearchRequest("market");
searchRequest.types("item");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder.query(QueryBuilders.functionScoreQuery(QueryBuilders.termQuery("description", search), functions));
searchRequest.source(sourceBuilder);
SearchResponse searchResponse = client.search(searchRequest).get();
return "success";
}
}
这里写了个小例子。首先我想去查询item中的description字段。然后设置了两个条件去影响查询结果。分别是sold的值为0,为它设置权重为1,price范围在15-30直接,为它设置权重为2。这两个字段的结果和查询的description结果想结合,最终得到的结果一点是越接近上面的条件,获得的分数越高,则排名越靠上。当然这里只是写了个简单的小例子,实际当中肯定没有这么简单,还是要多去读开发文档,然后按照实际的需求去选择不同的计算方法。
五、父子关系 (parent-child)建立
首先说明为什么要建立父子关系,因为在ES不能像平常的SQL一样通过设置主外键去查询其他type中的数据,所以必须建立父子关系(其实和主外键一样),才能同时查询到多个type的数据。
在实际的使用中,这个也是坑我很久的一个地方。因为不管是开发文档,还是其他资料。大多数都只是写ES语句去进行查询,如果要放在SpringBoot中,使用java语句去操作,很少有这方面的资料。我踩了很多的坑,才慢慢地摸索了出来。下面是官方文档的介绍。
https://www.elastic.co/guide/cn/elasticsearch/guide/current/parent-child.html
首先,假如你要建立父子关系,需要加上@Parent这个注解。这个注解加在子元素的实体中的某个字段上,去对应父元素的数据。
package com.isale.market.entity.es;
import lombok.*;
import lombok.extern.slf4j.Slf4j;
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.*;
import java.io.Serializable;
import java.math.BigDecimal;
import java.util.Date;
@Slf4j
@NoArgsConstructor
@AllArgsConstructor
@Data
@Document(indexName = "listing",type = "salesListing", shards = 3,replicas = 0, refreshInterval = "-1")
public class SalesListingES implements Serializable {
@Id
private Integer id;
@Field(type = FieldType.Text, searchAnalyzer="ik_max_word", analyzer="ik_max_word")
private String enTitle;
@Field(type = FieldType.Text, searchAnalyzer="ik_max_word", analyzer="ik_max_word")
private String cnTitle;
@Field(type = FieldType.Integer,store=true)
private int categoryId;
@Field(type = FieldType.Text, searchAnalyzer="ik_max_word", analyzer="ik_max_word")
private String description;
}
父元素实体。
package com.isale.market.entity.es;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.*;
import java.io.Serializable;
import java.math.BigDecimal;
import java.util.Date;
/**
* @Author: lk
* @Date: 2018/10/18 0018 下午 4:33
* @Description:
*/
@Slf4j
@NoArgsConstructor
@AllArgsConstructor
@Data
@Document(indexName = "listing",type = "salesVariationInfo", shards = 3,replicas = 0, refreshInterval = "-1")
public class SalesVariationGroupListingInfoES implements Serializable {
@Id
private Integer id;
@Field(type = FieldType.Text,store=true)
@Parent(type="salesListing")
private String listingId;
}
子元素实体(在这里加上@Parent注解)
注意:
- 注解必须加载子元素的某个字段上,且该字段的类型为String,@Parent注解中type对应的值为父元素的type值。
- 父子元素必须在同一个index下,否则关系不会被建立。
- 如果使用SpringBoot生成index,这里可能会出错。大致意思是无法建立父子关系。原因是父子关系必须在同一个请求中被创建,如果是SpringBoot生成index,是不同的请求。所以index建立失败,会报错。解决这个问题的方法是在Sense插件中首先去建立他们的父子关系,然后再启动SpringBoot导入各个字段。
PUT /listing { "mappings": { "salesListing": {}, "salesVariationInfo": { "_parent": { "type": "salesListing" } } } }建立两个索引,salesVariationInfo的parent就是salesListing。然后再启动SpringBoot,将不同字段导入。
索引关系可以去elasticsearch-head插件中查看。点击索引信息,如果出啊先_parent,type属性,则证明关系建设成功。
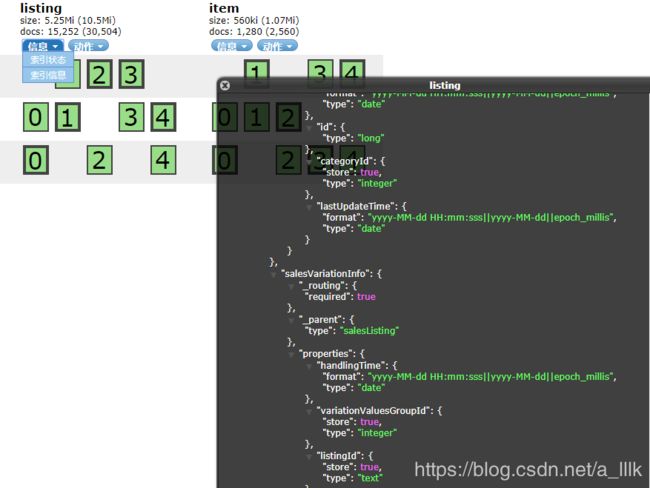
建好关系之后,可以去查询,这里查询有两种方式,根据父亲的信息查询儿子的信息,根据儿子的信息查询父亲的信息。
package com.isale.market.service.impl;
import com.isale.market.entity.es.SalesListingES;
import com.isale.market.entity.es.SalesVariationGroupListingInfoES;
import com.isale.market.repository.es.SalesListingESRepository;
import com.isale.market.repository.es.SalesVariationGroupListingInfoESRepository;
import com.isale.market.service.SearchService;
import org.apache.lucene.search.join.ScoreMode;
import org.elasticsearch.index.query.QueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.join.query.JoinQueryBuilders;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.PageRequest;
import org.springframework.data.domain.Pageable;
import org.springframework.data.elasticsearch.core.query.NativeSearchQueryBuilder;
import org.springframework.data.elasticsearch.core.query.SearchQuery;
import org.springframework.stereotype.Service;
import javax.servlet.http.HttpSession;
/**
* @Author: lk
* @Date: 2018/10/9 0009 下午 4:22
* @Description:
*/
@Service
public class SearchServiceImpl implements SearchService {
@Autowired
SalesListingESRepository salesListingESRepository;
@Autowired
SalesVariationGroupListingInfoESRepository salesVariationGroupListingInfoESRepository;
@Autowired
HttpSession sesession;
@Override
public Page searchByTitle(int pageIndex ,int pageSize) {
String title = (String) sesession.getAttribute("title");
QueryBuilder queryBuilder = JoinQueryBuilders.hasChildQuery("salesVariationInfo", QueryBuilders.matchQuery("searchTitle", title), ScoreMode.Max);
Pageable pageable = PageRequest.of(pageIndex, pageSize);
SearchQuery searchQuery = new NativeSearchQueryBuilder().withQuery(queryBuilder).withPageable(pageable).build();
searchQuery.addIndices("listing");
searchQuery.addTypes("salesListing");
Page list = salesListingESRepository.search(searchQuery);
long pageCount = list.getTotalPages();
long pageSize1 = list.getTotalElements();
return list;
}
}
上面简单的写了个小例子,根据儿子的索引信息得出父亲的数据。这里有个ScoreMode参数的设置。ES很有意思,如果这个参数设置为NONE的话,得出的结果是无序的。也就是说首先查到的儿子的信息是按照相关度从高到低去排列,而查询到的父亲的信息确实无序排列了。我就是这个坑饶了好久,最后将两块的数据同时查出来才发现相关度没有被排序。所以,如果想要父亲的结果也排序,建议加上这个字段。
假如需要根据父亲查儿子,主需要将上面的上方改成hasParent,然后将对应的索引名称修改一下就可以了。
这里需要注意的是hasChildQuery()和hasParent()两个方法,在ES5.5之前,是在QueryBuilders类中,在ES5.5之后,将这两个方法集成在了JoinQueryBuilders这个类中。所以,根据版本去选择不同的方法。
上面还用到了JPA中的分页插件,这个个人感觉用起来挺方便的,只需要给到对应的页数和每页的数据量就能自动返回查询后的页数,具体使用就不多说了。
总结的知识点大概就是这些,很多地方比较简单的我就没贴代码,可能没说清楚,看不懂的老哥可以在下面留言。