高德APP启动耗时剖析与优化实践(iOS篇)
前言
最近高德地图APP完成了一次启动优化专项,超预期将双端启动的耗时都降低了65%以上,iOS在iPhone7上速度达到了400毫秒以内。就像产品们用后说的,快到不习惯。算一下每天为用户省下的时间,还是蛮有成就感的,本文做个小结。
(文中配图均为多才多艺的技术哥哥手绘)
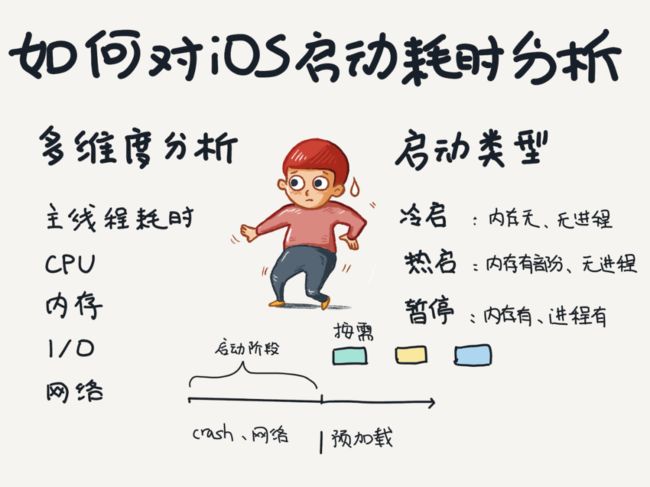
启动阶段性能多维度分析
要优化,首先要做到的是对启动阶段的各个性能纬度做分析,包括主线程耗时、CPU、内存、I/O、网络。这样才能更加全面的掌握启动阶段的开销,找出不合理的方法调用。
启动越快,更多的方法调用就应该做成按需执行,将启动压力分摊,只留下那些启动后方法都会依赖的方法和库的初始化,比如网络库、Crash库等。而剩下那些需要预加载的功能可以放到启动阶段后再执行。
启动有哪几种类型,有哪些阶段呢?
启动类型分为:
Cold:APP重启后启动,不在内存里也没有进程存在。
Warm:APP最近结束后再启动,有部分在内存但没有进程存在。
Resume:APP没结束,只是暂停,全在内存中,进程也存在。
分析阶段一般都是针对Cold类型进行分析,目的就是要让测试环境稳定。为了稳定测试环境,有时还需要找些稳定的机型,对于iOS来说iPhone7性能中等,稳定性也不错就很适合,Android的Vivo系列也相对稳定,华为和小米系列数据波动就比较大。
除了机型外,控制测试机温度也很重要,一旦温度过高系统还会降频执行,影响测试数据。有时候还会设置飞行模式采用Mock网络请求的方式来减少不稳定的网络影响测试数据。最好是重启后退iCloud账号,放置一段时间再测,更加准确些。
了解启动阶段的目的就是聚焦范围,从用户体验上来确定哪个阶段要快,以便能够让用户可视和响应用户操作的时间更快。
简单来说iOS启动分为加载Mach-O和运行时初始化过程,加载Mach-O会先判断加载的文件是不是Mach-O,通过文件第一个字节,也叫魔数来判断,当是下面四种时可以判定是Mach-O文件:
0xfeedface对应的loader.h里的宏是MH_MAGIC
0xfeedfact宏是MH_MAGIC_64
NXSwapInt(MH_MAGIC)宏MH_GIGAM
NXSwapInt(MH_MAGIC_64)宏MH_GIGAM_64
Mach-O主要分为:
中间对象文件(MH_OBJECT)
可执行二进制(MH_EXECUTE)
VM 共享库文件(MH_FVMLIB)
Crash 产生的Core文件(MH_CORE)
preload(MH_PRELOAD)
动态共享库(MH_DYLIB)
动态链接器(MH_DYLINKER)
静态链接文件(MH_DYLIB_STUB)符号文件和调试信息(MH_DSYM)这几种。
确定是Mach-O后,内核会fork一个进程,execve开始加载。检查Mach-O Header。随后加载dyld和程序到Load Command地址空间。通过 dyld_stub_binder开始执行dyld,dyld会进行rebase、binding、lazy binding、导出符号,也可以通过DYLD_INSERT_LIBRARIES进行hook。
dyld_stub_binder给偏移量到dyld解释特殊字节码Segment中,也就是真实地址,把真实地址写入到la_symbol_ptr里,跳转时通过stub的jump指令跳转到真实地址。dyld加载所有依赖库,将动态库导出的trie结构符号执行符号绑定,也就是non lazybinding,绑定解析其他模块功能和数据引用过程,就是导入符号。
Trie也叫数字树或前缀树,是一种搜索树。查找复杂度O(m),m是字符串的长度。和散列表相比,散列最差复杂度是O(N),一般都是 O(1),用 O(m)时间评估 hash。散列缺点是会分配一大块内存,内容越多所占内存越大。Trie不仅查找快,插入和删除都很快,适合存储预测性文本或自动完成词典。
为了进一步优化所占空间,可以将Trie这种树形的确定性有限自动机压缩成确定性非循环有限状态自动体(DAFSA),其空间小,做法是会压缩相同分支。
对于更大内容,还可以做更进一步的优化,比如使用字母缩减的实现技术,把原来的字符串重新解释为较长的字符串;使用单链式列表,节点设计为由符号、子节点、下一个节点来表示;将字母表数组存储为代表ASCII字母表的256位的位图。
尽管Trie对于性能会做很多优化,但是符号过多依然会增加性能消耗,对于动态库导出的符号不宜太多,尽量保持公共符号少,私有符号集丰富。这样维护起来也方便,版本兼容性也好,还能优化动态加载程序到进程的时间。
然后执行attribute的constructor函数。举个例子:
#include
__attribute__((constructor))
static void prepare() {
printf("%s\n", "prepare");
}
__attribute__((destructor))
static void end() {
printf("%s\n", "end");
}
void showHeader() {
printf("%s\n", "header");
}
运行结果:
ming@mingdeMacBook-Pro macho_demo % ./main "hi"
prepare
hi
end
运行时初始化过程分为:
加载类扩展。
加载C++静态对象。
调用+load函数。
执行main函数。
Application初始化,到applicationDidFinishLaunchingWithOptions执行完。
初始化帧渲染,到viewDidAppear执行完,用户可见可操作。
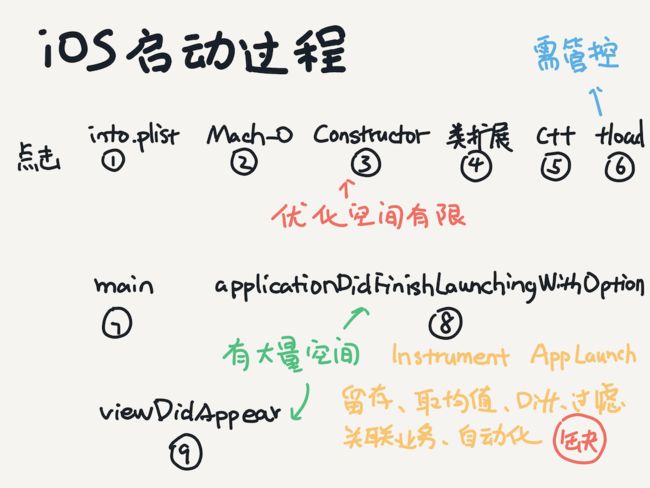
也就是说对启动阶段的分析以viewDidAppear为截止。这次优化之前已经对Application初始化之前做过优化,效果并不明显,没有本质的提高,所以这次主要针对Application初始化到viewDidAppear这个阶段各个性能多纬度进行分析。
工具的选择其实目前看来是很多的,Apple提供的System Trace会提供全面系统的行为,可以显示底层系统线程和内存调度情况,分析锁、线程、内存、系统调用等问题。总的来说,通过System Trace能清楚知道每时每刻APP对系统资源的使用情况。
System Trace能查看线程的状态,可以了解高优线程使用相对于CPU数量是否合理,可以看到线程在执行、挂起、上下文切换、被打断还是被抢占的情况。虚拟内存使用产生的耗时也能看到,比如分配物理内存,内存解压缩,无缓存时进行缓存的耗时等。甚至是发热情况也能看到。
System Trace还提供手动打点进行信息显式,在你的代码中导入sys/kdebug_signpost.h后,配对kdebug_signpost_start和kdebug_signpost_end就可以了。这两个方法有五个参数,第一个是id,最后一个是颜色,中间都是预留字段。
Xcode11开始XCTest还提供了测量性能的Api。苹果在2019年WWDC启动优化专题:
https://developer.apple.com/videos/play/wwdc2019/423/
也介绍了Instruments里的最新模板App launch如何分析启动性能。但是要想达到对启动数据进行留存取均值、Diff、过滤、关联分析等自动化操作,App launch目前还没法做到。
下面针对主线程耗时、CPU、网络、内存、I/O 等多维度进行分析:

主线程耗时
多个纬度性能分析中最重要、最终用户体感到的是主线程耗时分析。对主线程方法耗时可以直接使用Massier,这是everettjf开发的一个Objective-C方法跟踪工具:
https://everettjf.github.io/2019/05/06/messier/
生成trace json进行分析,或者参看这个代码
GCDFetchFeed/SMCallTraceCore.c at master · ming1016/GCDFetchFeed · GitHub
https://github.com/ming1016/GCDFetchFeed/blob/master/GCDFetchFeed/GCDFetchFeed/Lib/SMLagMonitor/SMCallTraceCore.c
自己手动hook objc_msgSend生成一份Objective-C方法耗时数据进行分析。还有种插桩方式,可以解析IR(加快编译速度),然后在每个方法前后插入耗时统计函数。
文章后面我会着重介绍如何开发工具进一步分析这份数据,以达到监控启动阶段方法耗时的目的。
hook所有的方法调用,对详细分析时很有用,不过对于整个启动时间影响很大,要想获取启动每个阶段更准确的时间消耗还需要依赖手动埋点。
为了更好的分析启动耗时问题,手动埋点也会埋的越来越多,也会影响启动时间精确度,特别是当团队很多,模块很多时,问题会突出。但是每个团队在排查启动耗时往往只会关注自己或相关某几个模块的分析,基于此,可以把不同模块埋点分组,灵活组合,这样就可以照顾到多种需求了。
CPU
为什么分析启动慢除了分析主线程方法耗时外,还要分析其它纬度的性能呢?
我们先看看启动慢的表现,启动慢意味着界面响应慢、网络慢(数据量大、请求数多)、CPU超负荷降频(并行任务多、运算多),可以看出影响启动的因素很多,还需要全面考虑。
对于CPU来说,WWDC的
What’s New in Energy Debugging - WWDC 2018 - Videos - Apple Developer
https://developer.apple.com/videos/play/wwdc2018/228/
介绍了用Energy Log来查CPU耗电,当前台三分钟或后台一分钟CPU线程连续占用80%以上就判定为耗电,同时记录耗电线程堆栈供分析。还有一个MetrickKit专门用来收集电源和性能统计数据,每24小时就会对收集的数据进行汇总上报,Mattt在NShipster网站上也发了篇文章专门进行介绍:
https://nshipster.com/metrickit/
那么,CPU的详细使用情况如何获取呢?也就是说哪个方法用了多少CPU。
有好几种获取详细CPU使用情况的方法。线程是计算机资源调度和分配的基本单位。CPU使用情况会提现到线程这样的基本单位上。task_theads的act_list数组包含所有线程,使用thread_info的接口可以返回线程的基本信息,这些信息定义在thread_basic_info_t结构体中。这个结构体内的信息包含了线程运行时间、运行状态以及调度优先级,其中也包含了CPU使用信息cpu_usage。
获取方式参看:
objective c - Get detailed iOS CPU usage with different states - Stack Overflow
https://stackoverflow.com/questions/43866416/get-detailed-ios-cpu-usage-with-different-states
GT GitHub - Tencent/GT
https://github.com/Tencent/GT
也有获取CPU的代码。
整体CPU占用率可以通过host_statistics函数取到host_cpu_load_info,其中cpu_ticks数组是CPU运行的时钟脉冲数量。通过cpu_ticks数组里的状态,可以分别获取CPU_STATE_USER、CPU_STATE_NICE、CPU_STATE_SYSTEM这三个表示使用中的状态,除以整体CPU就可以取到CPU的占比。
通过NSProcessInfo的activeProcessorCount还可以得到CPU的核数。线上数据分析时会发现相同机型和系统的手机,性能表现却截然不同,这是由于手机过热或者电池损耗过大后系统降低了CPU频率所致。
所以,如果取得CPU频率后也可以针对那些降频的手机来进行针对性的优化,以保证流畅体验。获取方式可以参考:
https://github.com/zenny-chen/CPU-Dasher-for-iOS
内存
要想获取APP真实的内存使用情况可以参看WebKit的源码:
https://github.com/WebKit/webkit/blob/52bc6f0a96a062cb0eb76e9a81497183dc87c268/Source/WTF/wtf/cocoa/MemoryFootprintCocoa.cpp
JetSam会判断APP使用内存情况,超出阈值就会杀死APP,JetSam获取阈值的代码在这里:
https://github.com/apple/darwin-xnu/blob/0a798f6738bc1db01281fc08ae024145e84df927/bsd/kern/kern_memorystatus.c
整个设备物理内存大小可以通过NSProcessInfo的physicalMemory来获取。
网络
对于网络监控可以使用Fishhook这样的工具Hook网络底层库CFNetwork。网络的情况比较复杂,所以需要定些和时间相关的关键的指标,指标如下:
DNS时间
SSL时间
首包时间
响应时间
有了这些指标才能够有助于更好的分析网络问题。启动阶段的网络请求是非常多的,所以HTTP的性能是非常要注意的。以下是WWDC网络相关的Session:
Your App and Next Generation Networks - WWDC 2015 - Videos - Apple Developer
https://developer.apple.com/videos/play/wwdc2015/719/
Networking with NSURLSession - WWDC 2015 - Videos - Apple Developer
https://developer.apple.com/videos/play/wwdc2015/711/
Networking for the Modern Internet - WWDC 2016 - Videos - Apple Developer
https://developer.apple.com/videos/play/wwdc2016/714/
Advances in Networking, Part 1 - WWDC 2017 - Videos - Apple Developer
https://developer.apple.com/videos/play/wwdc2017/707/
Advances in Networking, Part 2 - WWDC 2017 - Videos - Apple Developer
https://developer.apple.com/videos/play/wwdc2017/709/
Optimizing Your App for Today’s Internet - WWDC 2018 - Videos - Apple Developer
https://developer.apple.com/videos/play/wwdc2018/714/
I/O
对于I/O可以使用
Frida • A world-class dynamic instrumentation framework | Inject JavaScript to explore native apps on Windows, macOS, GNU/Linux, iOS, Android, and QNX
https://www.frida.re/
这种动态二进制插桩技术,在程序运行时去插入自定义代码获取I/O的耗时和处理的数据大小等数据。Frida还能够在其它平台使用。
关于多维度分析更多的资料可以看看历届WWDC的介绍。下面我列下16年来 WWDC关于启动优化的Session,每场都很精彩。
Using Time Profiler in Instruments - WWDC 2016 - Videos - Apple Developer
https://developer.apple.com/videos/play/wwdc2016/418/
Optimizing I/O for Performance and Battery Life - WWDC 2016 - Videos - Apple Developer
https://developer.apple.com/videos/play/wwdc2016/719/
Optimizing App Startup Time - WWDC 2016 - Videos - Apple Developer
https://developer.apple.com/videos/play/wwdc2016/406/
App Startup Time: Past, Present, and Future - WWDC 2017 - Videos - Apple Developer
https://developer.apple.com/videos/play/wwdc2017/413/
Practical Approaches to Great App Performance - WWDC 2018 - Videos - Apple Developer
https://developer.apple.com/videos/play/wwdc2018/407/
Optimizing App Launch - WWDC 2019 - Videos - Apple Developer
https://developer.apple.com/videos/play/wwdc2019/423/
延后任务管理
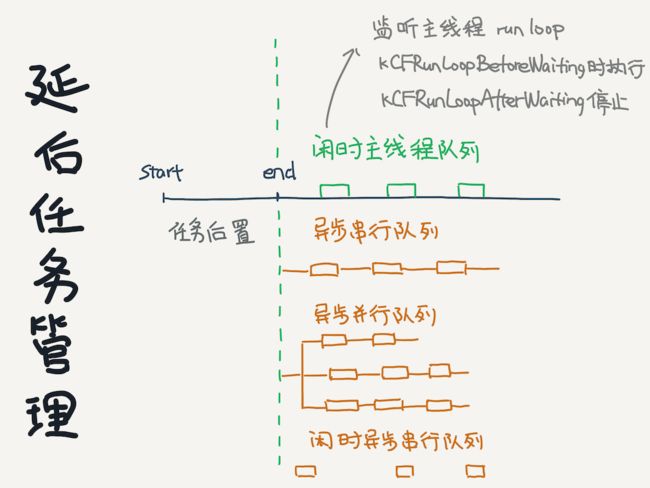
经过前面所说的对主线程耗时方法和各个纬度性能分析后,对于那些分析出来没必要在启动阶段执行的方法,可以做成按需或延后执行。
任务延后的处理不能粗犷的一口气在启动完成后在主线程一起执行,那样用户仅仅只是看到了页面,依然没法响应操作。那该怎么做呢?套路一般是这样,创建四个队列,分别是:
异步串行队列
异步并行队列
闲时主线程串行队列
闲时异步串行队列
有依赖关系的任务可以放到异步串行队列中执行。异步并行队列可以分组执行,比如使用dispatch_group,然后对每组任务数量进行限制,避免CPU、线程和内存瞬时激增影响主线程用户操作,定义有限数量的串行队列,每个串行队列做特定的事情,这样也能够避免性能消耗短时间突然暴涨引起无法响应用户操作。使用dispatch_semaphore_t在信号量阻塞主队列时容易出现优先级反转,需要减少使用,确保QoS传播。可以用dispatch group替代,性能一样,功能不差。异步编程可以直接GCD接口来写,也可以使用阿里的协程框架
coobjc GitHub - alibaba/coobjc
https://github.com/alibaba/coobjc
闲时队列实现方式是监听主线程runloop状态,在kCFRunLoopBeforeWaiting时开始执行闲时队列里的任务,在kCFRunLoopAfterWaiting时停止。
优化后如何保持?
攻易守难,就像刚到新团队时将包大小减少了48兆,但是一年多一直能够守住,除了决心还需要有手段。对于启动优化来说,将各个性能纬度通过监控的方式盯住是必要的,但是发现问题后快速、便捷的定位到问题还是需要找些突破口。我的思路是将启动阶段方法耗时多的按照时间线一条一条排出来,每条包括方法名、方法层级、所属类、所属模块、维护人。考虑到便捷性,最好还能方便的查看方法代码内容。
接下来我通过开发一个工具,详细介绍下怎么实现这样的效果。
解析json
如前面所说在输出一份Chrome trace规范的方法耗时json后,先要解析这份数据。这份json数据类似下面的样子:
{"name":"[SMVeilweaa]upVeilState:","cat":"catname","ph":"B","pid":2381,"tid":0,"ts":21},
{"name":"[SMVeilweaa]tatLaunchState:","cat":"catname","ph":"B","pid":2381,"tid":0,"ts":4557},
{"name":"[SMVeilweaa]tatTimeStamp:state:","cat":"catname","ph":"B","pid":2381,"tid":0,"ts":4686},
{"name":"[SMVeilweaa]tatTimeStamp:state:","cat":"catname","ph":"E","pid":2381,"tid":0,"ts":4727},
{"name":"[SMVeilweaa]tatLaunchState:","cat":"catname","ph":"E","pid":2381,"tid":0,"ts":5732},
{"name":"[SMVeilweaa]upVeilState:","cat":"catname","ph":"E","pid":2381,"tid":0,"ts":5815},
…
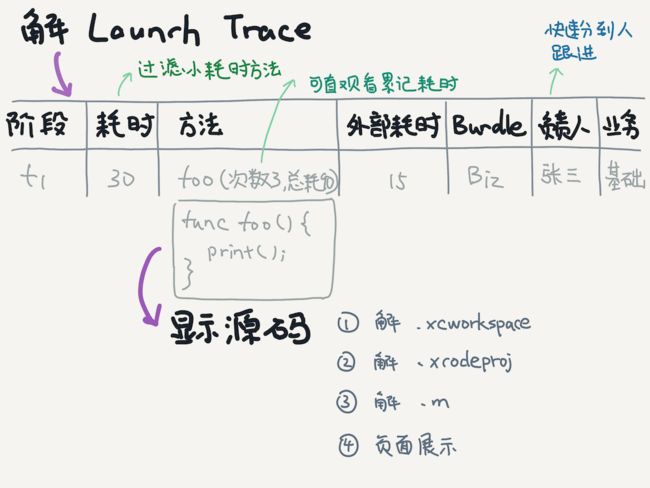
通过Chrome的Trace-Viewer可以生成一个火焰图。其中name字段包含了类、方法和参数的信息,cat字段可以加入其它性能数据,ph为B表示方法开始,为E表示方法结束,ts字段表示。
很多工程在启动阶段会执行大量方法,很多方法耗时很少,可以过滤那些小于10毫秒的方法,让分析更加聚焦。

耗时的高低也做了颜色的区分。外部耗时指的是子方法以外系统或没源码的三方方法的耗时,规则是父方法调用的耗时减去其子方法总耗时。
目前为止通过过滤耗时少的方法调用,可以更容易发现问题方法。但是,有些方法单次执行耗时不多,但是会执行很多次,累加耗时会大,这样的情况也需要体现在展示页面里。另外外部耗时高时或者碰到自己不了解的方法时,是需要到工程源码里去搜索对应的方法源码进行分析的,有的方法名很通用时还需要花大量时间去过滤无用信息。
因此接下来还需要做两件事情,首先累加方法调用次数和耗时,体现在展示页面中,另一个是从工程中获取方法源码能够在展示页面中进行点击显示。
完整思路如下图:
展示方法源码
在页面上展示源码需要先解析.xcworkspace文件,通过.xcworkspace文件取到工程里所有的.xcodeproj文件。分析.xcodeproj文件取到所有.m和.mm源码文件路径,解析源码,取到方法的源码内容进行展示。
解析.xcworkspace
开.xcworkspace,可以看到这个包内主要文件是contents.xcworkspacedata。内容是一个xml:

解析.xcodeproj

通过XML的解析可以获取FileRef节点内容,xcodeproj的文件路径就在FileRef节点的location属性里。每个xcodeproj文件里会有project工程的源码文件。为了能够获取方法的源码进行展示,那么就先要取出所有project工程里包含的源文件的路径。
xcodeproj的文件内容看起来大概是下面的样子。

其实内容还有很多,需要一个个解析出来。
考虑到xcodeproj里的注释很多,也都很有用,因此会多设计些结构来保存值和注释。思路是根据XcodeprojNode的类型来判断下一级是key value结构还是array结构。如果XcodeprojNode的类型是dicStart表示下级是key value结构。如果类型是arrStart就是array结构。当碰到类型是dicEnd,同时和最初dicStart是同级时,递归下一级树结构。而arrEnd不用递归,xcodeproj里的array只有值类型的数据。
有了基本节点树结构以后就可以设计xcodeproj里各个p的结构。主要有以下的p:
PBXBuildFile:文件,最终会关联到PBXFileReference。
PBXContainerItemProxy:部署的元素。
PBXFileReference:各类文件,有源码、资源、库等文件。
PBXFrameworksBuildPhase:用于framework的构建。
PBXGroup:文件夹,可嵌套,里面包含了文件与文件夹的关系。
PBXNativeTarget:Target的设置。
PBXProject:Project的设置,有编译工程所需信息。
PBXResourcesBuildPhase:编译资源文件,有xib、storyboard、plist以及图片等资源文件。
PBXSourcesBuildPhase:编译源文件(.m)。
PBXTargetDependency:Taget的依赖。
PBXVariantGroup:.storyboard文件。
XCBuildConfiguration:Xcode编译配置,对应Xcode的Build Setting面板内容。
XCConfigurationList:构建配置相关,包含项目文件和target文件。
得到p结构Xcodeproj后,就可以开始分析所有源文件的路径了。根据前面列出的p的说明,PBXGroup包含了所有文件夹和文件的关系,Xcodeproj的pbxGroup字段的key是文件夹,值是文件集合,因此可以设计一个结构体XcodeprojSourceNode用来存储文件夹和文件关系。
接下来需要取得完整的文件路径。通过recusiveFatherPaths函数获取文件夹路径。这里需要注意的是需要处理 ../ 这种文件夹路径符。
解析.m .mm文件

对Objective-C解析可以参考LLVM,这里只需要找到每个方法对应的源码,所以自己也可以实现。分词前先看看LLVM是怎么定义token的。定义文件在这里:
https://opensource.apple.com/source/lldb/lldb-69/llvm/tools/clang/include/clang/Basic/TokenKinds.def
根据这个定义我设计了token的结构体,主体部分如下:
// 切割符号 [](){}.&=*+-<>~!/%^|?:;,#@
public enum OCTK {
case unknown // 不是 token
case eof // 文件结束
case eod // 行结束
case codeCompletion // Code completion marker
case cxxDefaultargEnd // C++ default argument end marker
case comment // 注释
case identifier // 比如 abcde123
case numericConstant(OCTkNumericConstant) // 整型、浮点 0x123,解释计算时用,分析代码时可不用
case charConstant // ‘a’
case stringLiteral // “foo”
case wideStringLiteral // L”foo”
case angleStringLiteral // 待处理需要考虑作为小于符号的问题
// 标准定义部分
// 标点符号
case punctuators(OCTkPunctuators)
// 关键字
case keyword(OCTKKeyword)
// @关键字
case atKeyword(OCTKAtKeyword)
}
完整的定义在这里:
MethodTraceAnalyze/ParseOCTokensDefine.swift
https://github.com/ming1016/MethodTraceAnalyze/blob/master/MethodTraceAnalyze/OC/ParseOCTokensDefine.swift
分词过程可以参看LLVM的实现:
clang: lib/Lex/Lexer.cpp Source File
http://clang.llvm.org/doxygen/Lexer_8cpp_source.html
我在处理分词时主要是按照分隔符一一对应处理,针对代码注释和字符串进行了特殊处理,一个注释一个token,一个完整字符串一个token。我分词实现代码:
MethodTraceAnalyze/ParseOCTokens.swift
https://github.com/ming1016/MethodTraceAnalyze/blob/master/MethodTraceAnalyze/OC/ParseOCTokens.swift
由于只要取到类名和方法里的源码,所以语法分析时,只需要对类定义和方法定义做解析就可以,语法树中节点设计:
// OC 语法树节点
public struct OCNode {
public var type: OCNodeType
public var subNodes: [OCNode]
public var identifier: String // 标识
public var lineRange: (Int,Int) // 行范围
public var source: String // 对应代码
}
// 节点类型
public enum OCNodeType {
case `default`
case root
case `import`
case `class`
case method
}
其中lineRange记录了方法所在文件的行范围,这样就能够从文件中取出代码,并记录在source字段中。
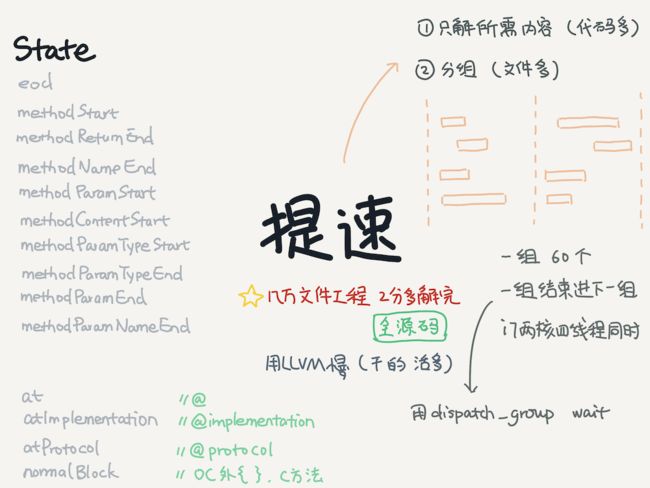
解析语法树需要先定义好解析过程的不同状态:
private enum RState {
case normal
case eod // 换行
case methodStart // 方法开始
case methodReturnEnd // 方法返回类型结束
case methodNameEnd // 方法名结束
case methodParamStart // 方法参数开始
case methodContentStart // 方法内容开始
case methodParamTypeStart // 方法参数类型开始
case methodParamTypeEnd // 方法参数类型结束
case methodParamEnd // 方法参数结束
case methodParamNameEnd // 方法参数名结束
case at // @
case atImplementation // @implementation
case normalBlock // oc方法外部的 block {},用于 c 方法
}
完整解析出方法所属类、方法行范围的代码在这里:
MethodTraceAnalyze/ParseOCNodes.swift
https://github.com/ming1016/MethodTraceAnalyze/blob/master/MethodTraceAnalyze/OC/ParseOCNodes.swift
解析.m和.mm文件,一个一个串行解的话,对于大工程,每次解的速度很难接受,所以采用并行方式去读取解析多个文件。经过测试,发现每组在60个以上时能够最大利用我机器(2.5 GHz双核Intel Core i7)的CPU,内存占用只有60M,一万多.m文件的工程大概2分半能解完。
使用的是dispatch group的wait,保证并行的一组完成再进入下一组。
现在有了每个方法对应的源码,接下来就可以和前面trace的方法对应上。页面展示只需要写段js就能够控制点击时展示对应方法的源码。
页面展示
在进行HTML页面展示前,需要将代码里的换行和空格替换成HTML里的对应的和 。
let allNodes = ParseOC.ocNodes(workspacePath: “/Users/ming/Downloads/GCDFetchFeed/GCDFetchFeed/GCDFetchFeed.xcworkspace”)
var sourceDic = [String:String]()
for aNode in allNodes {
sourceDic[aNode.identifier] = aNode.source.replacingOccurrences(of: “\n”, with: “”).replacingOccurrences(of: “ “, with: “ ”)
}
用p标签作为源码展示的标签,方法执行顺序的编号加方法名作为p标签的id,然后用display: none; 将p标签隐藏。方法名用a标签,click属性执行一段js代码,当a标签点击时能够显示方法对应的代码。这段js代码如下:
function sourceShowHidden(sourceIdName) {
var sourceCode = document.getElementById(sourceIdName);
sourceCode.style.display = “block”;
}
最终效果如下图:

将动态分析和静态分析进行了结合,后面可以通过不同版本进行对比,发现哪些方法的代码实现改变了,能展示在页面上。还可以进一步静态分析出哪些方法会调用到I/O函数、起新线程、新队列等,然后展示到页面上,方便分析。
读到最后,可以看到这个方法分析工具并没有用任何一个轮子,其实有些是可以使用现有轮子的,比如json、xml、xcodeproj、Objective-C语法分析等,之所以没有用是因为不同轮子使用的语言和技术区别较大,当格式更新时如果使用的单个轮子没有更新会影响整个工具。开发这个工具主要工作是在解析上,所以使用自有解析技术也能够让所做的功能更聚焦,不做没用的功能,减少代码维护量,所要解析格式更新后,也能够自主去更新解析方式。更重要的一点是可以亲手接触下这些格式的语法设计。
结语
本文小结了启动优化的技术手段,总的来说,对启动进行优化的决心的重要程度是远大于技术手段的,决定着是否能够优化的更多。技术手段有很多,我觉得手段的好坏区别只是在效率上,最差的情况全用手动一个个去查耗时也是能够解题的。
也许你还想看
高德客户端及引擎技术架构演进与思考
高德JS依赖分析工程及关键原理
高德APP全链路源码依赖分析工程
字节码技术在模块依赖分析中的应用
Android Native 内存泄漏系统化解决方案
阿里巴巴高德地图2020实习生热招中
欢迎加入丨高德技术线春招岗位汇总(附团介)
阿里春招时间过半,所有疑问,一网打尽!
