sql优化
1定位消耗资源的sql,可以查看v$sqlstats视图
-
The most common resources are:
-
Buffer gets (
V$SQLSTATS.BUFFER_GETS, for high CPU using statements) -
Disk reads (
V$SQLSTATS.DISK_READS, for high I/O statements) -
Sorts (
V$SQLSTATS.SORTS, for many sorts)
-
一般来说,如果选择性强的谓词在子查询使用in,如果选择性强的谓词在父查询使用exists
复杂视图的连接是不被推荐的,尤其是2个复杂视图的关联,通常的结果是整个视图实例化。
减少访问表的次数
使用case语句来连接多次的扫描
使用带retruing的dml
在一个语句中修改所有需要的数据
例子
SELECT COUNT (*) FROM employees WHERE salary < 2000; SELECT COUNT (*) FROM employees WHERE salary BETWEEN 2000 AND 4000; SELECT COUNT (*) FROM employees WHERE salary>4000;
However, it is more efficient to run the entire query in a single statement. Each number is calculated as one column. The count uses a filter with theCASE statement to count only the rows where the condition is valid. For example:
SELECT COUNT (CASE WHEN salary < 2000
THEN 1 ELSE null END) count1,
COUNT (CASE WHEN salary BETWEEN 2001 AND 4000
THEN 1 ELSE null END) count2,
COUNT (CASE WHEN salary > 4000
THEN 1 ELSE null END) count3
FROM employees;
视图合并
在查询中的每一个视图被分析器展开成一个独立的查询块,查询块本质代表着视图定义,也是视图的结果。优化器的一个选项是分开分析视图查询块并产生视图子计划。优化器使用视图子定义生成整体的查询计划。这种技术通常导致次优的查询计划,因为视图与其余的查询分离开被优化。
查询转换器通过合并查询块到包含视图的查询块中来移除潜在的次优计划,产生子计划已经不再被需要了,因为视图查询块被消除了。
谓词推进
对这些没有被合并的视图,查询转换器可以推相关的谓词到包含视图查询块中,这个技术提高了没有合并视图的子计划,因为推入的谓词可以访问索引或是作为过滤器。
子查询展开
通常包含子查询的查询通过展开子查询,把他们转换成连接能提高性能,大多数的子查询会被查询转换期展开。对那些没有展开的子查询,独立的子查询被生成,为了提升整个查询计划的速度,子计划以有效的方式排序。
使用物化视图重写查询
物化视图是查询结果的物化存储在表中,当用户的查询和物化视图相匹配的时候,用户的查询可以被重写,这种技术提高用户的查询,因为大部分的查询结果已经被提前计算了,优化器查找物化视图,选择一个或多个物化视图来重写用户查询,这个是cbo的,也就是重写的cost高就不重写了,除非重写后的cost比较低。
评估器
评估器生成3个度量
selectivity,cardinality,cost
选择性
选择性绑定到一个查询谓语,谓语是过滤器,在行集合中过滤出特定的行。选择性的范围是0.0到1.0.如果没有统计信息,那么优化器或是使用动态采样或是内部默认的值,依赖与optimizer_dynamic_sampling的初始参数值。不同的默认值被使用,依赖与不同的谓词类型。
表连接的几个方法:
-
Nested Loop Joins
-
Hash Joins
-
Sort Merge Joins
-
Cartesian Joins
-
Outer Joins
优化器怎么为join选择执行计划
优化器考虑下面的来生成执行计划
1优化器先看是否有2个或更多的表连接会生成包含1行的行源,如果有优化器就先连接这些表,然后在连接剩余的表。
2对包含外连接的条件,外连接的操作一定在别的表连接后面出现,优化器不考虑违法这个条件的连接顺序。例如,当子查询转换成反连接或半连接,子查询的表一定出现在外部查询表的后面。hash反连接和半连接在一定的条件下会覆盖这个顺序。
oracle什么时候使用nested loop 连接
优化器当在连接小的行,在2个表上有好的驱动条件的时候使用netsted loop.内连接上最好使用索引。
hash join
对于大表连接有用,优化器会把较小的表在内存中构建一个hash table,然后扫描大表,探测hash表来找连接的行。
sort merge
对连接2个独立的行源,hash join通常要比sort merge好,如果下面的条件满足,sort merge要比hash join好:
1行源已经是排过序的。
2排序操作不必做。
sort merge在两个表是不等的条件下,sort merge在大数据量下比nest loop好,在不等条件下,不能使用hash join
In Example 13-9, the outer join is to a multitable view. The optimizer cannot drive into the view like in a normal join or push the predicates, so it builds the entire row set of the view.
Example 13-9 Outer Join to a Multitable View
SELECT c.cust_last_name, sum(revenue)
FROM customers c, v_orders o
WHERE c.credit_limit > 2000
AND o.customer_id(+) = c.customer_id
GROUP BY c.cust_last_name;
----------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)|
----------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 144 | 4608 | 16 (32)|
| 1 | HASH GROUP BY | | 144 | 4608 | 16 (32)|
|* 2 | HASH JOIN OUTER | | 663 | 21216 | 15 (27)|
|* 3 | TABLE ACCESS FULL | CUSTOMERS | 195 | 2925 | 6 (17)|
| 4 | VIEW | V_ORDERS | 665 | 11305 | |
| 5 | HASH GROUP BY | | 665 | 15960 | 9 (34)|
|* 6 | HASH JOIN | | 665 | 15960 | 8 (25)|
|* 7 | TABLE ACCESS FULL| ORDERS | 105 | 840 | 4 (25)|
| 8 | TABLE ACCESS FULL| ORDER_ITEMS | 665 | 10640 | 4 (25)|
----------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("O"."CUSTOMER_ID"(+)="C"."CUSTOMER_ID")
3 - filter("C"."CREDIT_LIMIT">2000)
6 - access("O"."ORDER_ID"="L"."ORDER_ID")
7 - filter("O"."CUSTOMER_ID">0)
The view definition is as follows:
CREATE OR REPLACE view v_orders AS
SELECT l.product_id, SUM(l.quantity*unit_price) revenue,
o.order_id, o.customer_id
FROM orders o, order_items l
WHERE o.order_id = l.order_id
GROUP BY l.product_id, o.order_id, o.customer_id;
统计信息包含下面的东西
-
Table statistics
-
Number of rows
-
Number of blocks
-
Average row length
-
-
Column statistics
-
Number of distinct values (NDV) in column
-
Number of nulls in column
-
Data distribution (histogram)
-
-
Index statistics
-
Number of leaf blocks
-
Levels
-
Clustering factor
-
-
System statistics
-
I/O performance and utilization
-
CPU performance and utilization
-
优化器的统计信息自动的使用gather_stats_job来收集,这个job收集下面的信息:
丢失的信息
无效的信息
这个job是自动创建的,并使用scheduler来管理,gather_stats_job调用dbms_stats.gather_database_stats_job_proc存储过程,这个存储过程收集丢失的信息,和无效的信息(就是那些数据10%以上被修改的)。
启用自动收集
1select * from dba_scheduler_jobs where job_name='GATHER_STATS_JOB';
禁用自动收集
BEGIN
DBMS_SCHEDULER.DISABLE('GATHER_STATS_JOB');
END;
/
什么时候手工收集信息
1在statistics_level是basic的时候,自动统计收集不能检测无效统计信息,需要手工收集
2系统的统计数据,需要手工收集,动态性能视图的统计信息应该使用gather_fixed_objects_stats来收集
使用dbms_stats的存储过程收集统计信息的时候,需要注意的地方:
-
Statistics Gathering Using Sampling
-
Parallel Statistics Gathering
-
Statistics on Partitioned Objects
-
Column Statistics and Histograms
-
Determining Stale Statistics
-
User-defined Statistics
EXECUTE DBMS_STATS.GATHER_SCHEMA_STATS('OE',DBMS_STATS.AUTO_SAMPLE_SIZE);
并行收集信息
oracle建议并行收集的degree参数设置成DBMS_STATS.AUTO_DEGREE,根据对象的大小和并行参数的设置,自动的来决定并行度。
决定无效的统计信息
为了决定对象是否需要新的统计信息,oracle提供了一个工具,user_tab_modifications视图,这个视图反映该表的dml操作,oracle需要几分钟来同步这个视图,可以使用dbms_stats.flush_database_monitoring_info存储过程来马上查看内存中的信息。
gather_database_stats或gather_schema_stats存储过程的options参数被设置成gather stale或ather auto会自动收集无效的统计信息,表超过了10%的数据被修改了,就认为该表上的统计信息是无效的了。
动态采样是怎么工作的
主要的性能属性是编译时间,oracle在编译时候决定一个查询是否能从动态采样中受益,如果可以,那么一些sql扫描一小部分随机的样例数据,应用到相应的表上来评估谓词选择性。
当没有统计信息也没有动态采样的时候
Table 14-3 Default Table Values When Statistics Are Missing
| Table Statistic | Default Value Used by Optimizer |
|---|---|
Cardinality |
num_of_blocks * (block_size - cache_layer) / avg_row_len |
Average row length |
100 bytes |
Number of blocks |
100 or actual value based on the extent map |
Remote cardinality |
2000 rows |
Remote average row length |
100 bytes |
Table 14-4 Default Index Values When Statistics Are Missing
| Index Statistic | Default Value Used by Optimizer |
|---|---|
Levels |
1 |
Leaf blocks |
25 |
Leaf blocks/key |
1 |
Data blocks/key |
1 |
Distinct keys |
100 |
Clustering factor |
800 |
查看直方图
在tab_col_statistics视图中histogram列是直方图,可以使height balanced frequency 或是none
等高直方图
等高直方图中,列值被分成几个组,每个组大约有相同的行。假如一个列C的值是1到100,如果c是唯一值分布的,那么就如下面的图:

在每一个桶中的行数是总量的10分之1。
如果数据不是唯一值分布的,那么直方图可以使下面的这样
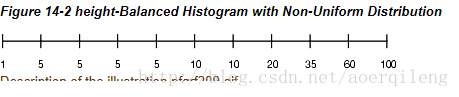
这种情况下,列中很多的行是5,60到100之间的行占总行的1/10.
Example 14-1 Viewing Height-Balanced Histogram Statistics
BEGIN
DBMS_STATS.GATHER_table_STATS (OWNNAME => 'OE', TABNAME => 'INVENTORIES',
METHOD_OPT => 'FOR COLUMNS SIZE 10 quantity_on_hand');
END;
/
SELECT column_name, num_distinct, num_buckets, histogram
FROM USER_TAB_COL_STATISTICS
WHERE table_name = 'INVENTORIES' AND column_name = 'QUANTITY_ON_HAND';
COLUMN_NAME NUM_DISTINCT NUM_BUCKETS HISTOGRAM
------------------------------ ------------ ----------- ---------------
QUANTITY_ON_HAND 237 10 HEIGHT BALANCED
SELECT endpoint_number, endpoint_value
FROM USER_HISTOGRAMS
WHERE table_name = 'INVENTORIES' and column_name = 'QUANTITY_ON_HAND'
ORDER BY endpoint_number;
ENDPOINT_NUMBER ENDPOINT_VALUE
--------------- --------------
0 0
1 27
2 42
3 57
4 74
5 98
6 123
7 149
8 175
9 202
10 353