本项目地址:caffe/ssd
SSD: Single Shot MultiBox Detector
By Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, Scott Reed, Cheng-Yang Fu, Alexander C. Berg.
简介
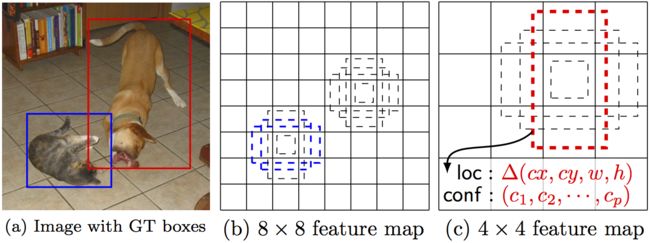
SSD是使用单个网络进行物体检测任务的统一框架. 你可以使用本代码训练/评估物体检测任务. 更多细节请见 arXiv paper 以及 slide.
| System | VOC2007 test mAP | FPS (Titan X) | Number of Boxes | Input resolution |
|---|---|---|---|---|
| Faster R-CNN (VGG16) | 73.2 | 7 | ~6000 | ~1000 x 600 |
| YOLO (customized) | 63.4 | 45 | 98 | 448 x 448 |
| SSD300* (VGG16) | 77.2 | 46 | 8732 | 300 x 300 |
| SSD512* (VGG16) | 79.8 | 19 | 24564 | 512 x 512 |

Note: SSD300* and SSD512* are the latest models. Current code should reproduce these results.
目录
- 安装
- 预备
- 训练/评估
- 模型
- 全新的数据集
安装
- 下载代码。假设把Caffe克隆到目录
$CAFFE_ROOT下
git clone https://github.com/weiliu89/caffe.git
cd caffe
git checkout ssd
- Build 代码. 按照 Caffe instruction 安装
必要的packages,然后build。
# 根据Caffe安装的方式修改Makefile.config。
cp Makefile.config.example Makefile.config
make -j8
# 确保include $CAFFE_ROOT/python到PYTHONPATH环境变量内.
make py
make test -j8
# 运行测试,可选
make runtest -j8
预备
下载 fully convolutional reduced (atrous) VGGNet. 假设文件被下载到了
$CAFFE_ROOT/models/VGGNet/目录-
下载VOC2007和VOC2012数据集.
对Pascal VOC数据集的简介:
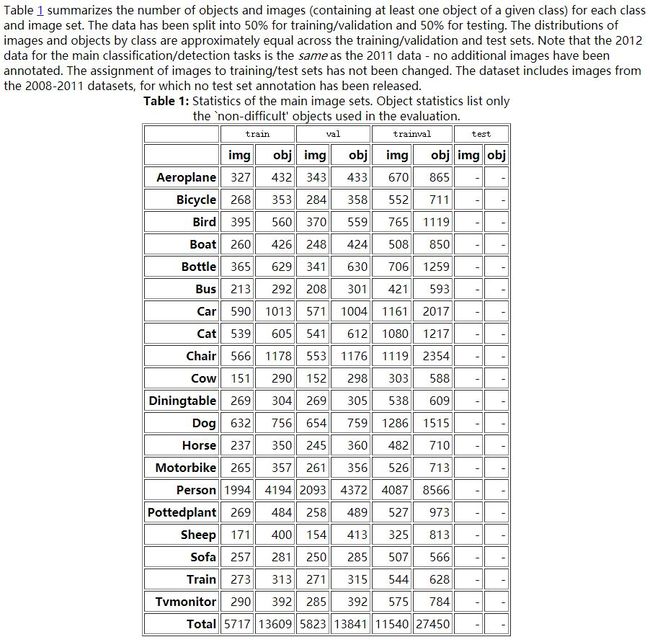 pascal_voc2012_detection_table.jpg
pascal_voc2012_detection_table.jpg
假设下载到了$HOME/data/目录
# 下载数据.
cd $HOME/data
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2012/VOCtrainval_11-May-2012.tar
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtrainval_06-Nov-2007.tar
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtest_06-Nov-2007.tar
# 解压数据.
tar -xvf VOCtrainval_11-May-2012.tar
tar -xvf VOCtrainval_06-Nov-2007.tar
tar -xvf VOCtest_06-Nov-2007.tar
VOC 2007年的数据分为VOCtrainval和VOCtest两个tar包,VOC 2012年的数据只有VOCtrainval一个tar包,如下

解压后,2007和2012两年的数据在VOCdevkit目录的VOC2007和VOC2012两个子目录中。每个子目录下,分别包含了五个文件夹,分别是Annotations ImageSets JPEGImages SegmentationClass 以及 SegmentationObject。对于SSD的Object任务,需要使用Annotations中的xml标注文件,ImagesSets/Main/目录中的trainval.txt和test.txt,以及JPEGImages目录下的图像。
- 创建LMDB文件.
cd $CAFFE_ROOT
# Create the trainval.txt, test.txt, and test_name_size.txt in data/VOC0712/
./data/VOC0712/create_list.sh
# 如有必要,可以按需修改create_data.sh文件.
# 编码trainval和test原始图像,生成lmdb文件:
# - $HOME/data/VOCdevkit/VOC0712/lmdb/VOC0712_trainval_lmdb
# - $HOME/data/VOCdevkit/VOC0712/lmdb/VOC0712_test_lmdb
# and make soft links at examples/VOC0712/
./data/VOC0712/create_data.sh
生成的trainval.txt格式如图,文件内容是图像的路径和标注文件的路径,中间用空格分隔开:
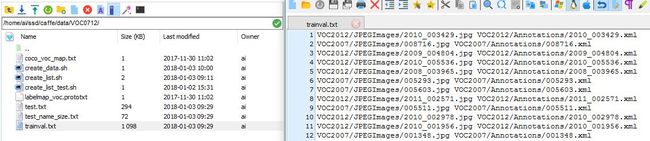
生成的test_name_size.txt是测试图像的id height 和 width
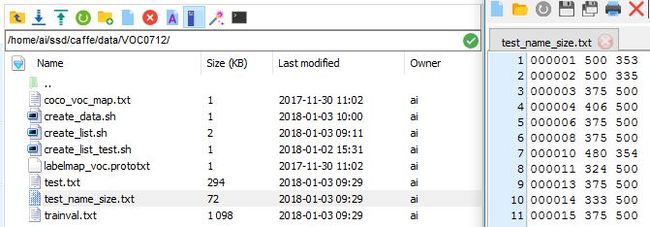
最终,生成trainval和test两个lmdb数据库,分别用来训练和测试SSD模型。
trainval LMDB
同时,在.../caffe/examples/VOC0712/路径下保存了上面两个lmdb数据库的链接,截图如下:
训练/评估
- 训练你自己的模型并评估.
# 创建模型定义文件并保存模型训练快照到如下路径:
# - $CAFFE_ROOT/models/VGGNet/VOC0712/SSD_300x300/
# and job file, log file, and the python script in:
# - $CAFFE_ROOT/jobs/VGGNet/VOC0712/SSD_300x300/
# 保存当前评估结果到:
# - $HOME/data/VOCdevkit/results/VOC2007/SSD_300x300/
# 120K次迭代之后,应该可以达到77.*的mAP.
python examples/ssd/ssd_pascal.py
如果不乐意自己训练模型,可以在here下载预训练好的模型.注意是用PASCAL VOC数据集训练的。
通过分析ssd_pascal.py的源码,可以知道训练ssd模型需要几个文件输入,分别是
train_data = "examples/VOC0712/VOC0712_trainval_lmdb"
test_data = "examples/VOC0712/VOC0712_test_lmdb"
name_size_file = "data/VOC0712/test_name_size.txt"
pretrain_model = "models/VGGNet/VGG_ILSVRC_16_layers_fc_reduced.caffemodel"
label_map_file = "data/VOC0712/labelmap_voc.prototxt"
train_net_file = "models/VGGNet/VOC0712/SSD_300x300/train.prototxt"
test_net_file = "models/VGGNet/VOC0712/SSD_300x300/test.prototxt"
deploy_net_file = "models/VGGNet/VOC0712/SSD_300x300/deploy.prototxt"
solver_file = "models/VGGNet/VOC0712/SSD_300x300/solver.prototxt"
其中,train_data和test_data是之前创建的LMDB数据库文件,用于训练和测试模型。name_size_file是之前创建的测试图像集的图像id和size文件,用于模型的测试。pretrain_model是base network部分(VGG_16的卷积层)的预训练参数。label_map_file保存的是物体的name和label的映射文件,用于训练和测试。这五个文件是之前都准备好的.
后面的四个文件,train_net_file test_net_file deploy_net_file和solver_file是在ssd_pascal.py脚本中根据模型定义和训练策略参数自动生成的。例如,train_net_file,也就是train.prototxt,生成语句是shutil.copy(train_net_file, job_dir),具体的代码片段如下:
# Create train net.
net = caffe.NetSpec()
net.data, net.label = CreateAnnotatedDataLayer(train_data, batch_size=batch_size_per_device,
train=True, output_label=True, label_map_file=label_map_file,
transform_param=train_transform_param, batch_sampler=batch_sampler)
VGGNetBody(net, from_layer='data', fully_conv=True, reduced=True, dilated=True,
dropout=False)
AddExtraLayers(net, use_batchnorm, lr_mult=lr_mult)
mbox_layers = CreateMultiBoxHead(net, data_layer='data', from_layers=mbox_source_layers,
use_batchnorm=use_batchnorm, min_sizes=min_sizes, max_sizes=max_sizes,
aspect_ratios=aspect_ratios, steps=steps, normalizations=normalizations,
num_classes=num_classes, share_location=share_location, flip=flip, clip=clip,
prior_variance=prior_variance, kernel_size=3, pad=1, lr_mult=lr_mult)
# Create the MultiBoxLossLayer.
name = "mbox_loss"
mbox_layers.append(net.label)
net[name] = L.MultiBoxLoss(*mbox_layers, multibox_loss_param=multibox_loss_param,
loss_param=loss_param, include=dict(phase=caffe_pb2.Phase.Value('TRAIN')),
propagate_down=[True, True, False, False])
with open(train_net_file, 'w') as f:
print('name: "{}_train"'.format(model_name), file=f)
print(net.to_proto(), file=f)
shutil.copy(train_net_file, job_dir)
- 使用最新模型快照评估模型.
# 如果你需要对训练的模型进行评估,执行脚本:
python examples/ssd/score_ssd_pascal.py
- 使用webcam摄像头测试模型. 注意: 按 esc 停止.
# 连接webcam摄像头和预训练的模型进行演示,运行:
python examples/ssd/ssd_pascal_webcam.py
Here 展示了一个在 MSCOCO 数据集上训练的模型SSD500的演示视频.
查看
examples/ssd_detect.ipynb或者examples/ssd/ssd_detect.cpp如何使用ssd模型检测物体. 查看examples/ssd/plot_detections.py如何绘制 ssd_detect.cpp的检测结果.如果使用其他数据集训练, 请参考data/OTHERDATASET 了解更多细节. 目前支持COCO 和 ILSVRC2016数据集. 建议使用
examples/ssd.ipynb检查新的数据集是否符合要求.
模型
在不同数据集上训练了模型以供下载. 为了复现论文Table 6中的结果, 每个模型文件夹内都包含一个.caffemodel 文件, 几个.prototxt 文件, 以及python脚本文件.
-
PASCAL VOC 模型:
- 07+12: SSD300*, SSD512*
- 07++12: SSD300*, SSD512*
- COCO[1]: SSD300*, SSD512*
- 07+12+COCO: SSD300*, SSD512*
- 07++12+COCO: SSD300*, SSD512*
-
COCO 模型:
- trainval35k: SSD300*, SSD512*
-
ILSVRC 模型:
- trainval1: SSD300*, SSD500
全新的数据集
在之前的训练/评估的第一部分,我们介绍了如何准备数据集:
dbname_trainval_lmdbdbname_test_lmdbtest_name_size.txtlabelmap_dbname.prototxtVGG_ILSVRC_16_layers_fc_reduced.caffemodel
全新的数据意味着不同的训练/测试图像,不同的object name label映射关系,不同的网络模型定义参数。首先,我们需要根据新的图像数据集生成模型的输入部分,也就是上面的五个文件。
VGG_ILSVRC_16_layers_fc_reduced.caffemodel是预训练好的VGG_16的卷积层的参数,直接下载使用即可,这里不再介绍如何重新训练VGG_16分类模型。-
labelmap_dbname.prototxt是标注文件中object的name和label的映射文件,一般类别不会太多,直接编写此文件即可。例如,一个可能的映射文件:item { name: "none_of_the_above" label: 0 display_name: "background" } item { name: "Car" label: 1 display_name: "car" } item { name: "Bus" label: 2 display_name: "bus" } item { name: "Van" label: 3 display_name: "van" } ... -
test_name_size.txt文件保存了所有测试图像的idheightwidth信息,由create_list.sh脚本完成创建。通过分析create_list.sh脚本可知道,该脚本共创建了三个txt文件,分别是trainval.txttest.txt和dbname_name_size.txt。-
trainval.txt和test.txt中,每一行保存了图像文件的路径和图像标注文件的路径,中间以空格分开。片段如下:
VOC2012/JPEGImages/2010_003429.jpg VOC2012/Annotations/2010_003429.xml VOC2007/JPEGImages/008716.jpg VOC2007/Annotations/008716.xml VOC2012/JPEGImages/2009_004804.jpg VOC2012/Annotations/2009_004804.xml VOC2007/JPEGImages/005293.jpg VOC2007/Annotations/005293.xml注意,trainval中的顺序是打乱的,test中的顺序不必打乱。
-
test_name_size.txt文件是由.../caffe/get_image_size程序生成的,其源码位于.../caffe/tools/get_image_size.cpp中。这段程序的作用是根据test.txt中提供的测试图像的路径信息和数据集根目录信息(两段路径拼合得到图像的绝对路径),自动计算每张图像的height和width。get_image_size.cpp中的核心代码段为:
// Storing to outfile boost::filesystem::path root_folder(argv[1]); std::ofstream outfile(argv[3]); if (!outfile.good()) { LOG(FATAL) << "Failed to open file: " << argv[3]; } int height, width; int count = 0; for (int line_id = 0; line_id < lines.size(); ++line_id) { boost::filesystem::path img_file = root_folder / lines[line_id].first; GetImageSize(img_file.string(), &height, &width); std::string img_name = img_file.stem().string(); if (map_name_id.size() == 0) { outfile << img_name << " " << height << " " << width << std::endl; } else { CHECK(map_name_id.find(img_name) != map_name_id.end()); int img_id = map_name_id.find(img_name)->second; outfile << img_id << " " << height << " " << width << std::endl; } if (++count % 1000 == 0) { LOG(INFO) << "Processed " << count << " files."; } } // write the last batch if (count % 1000 != 0) { LOG(INFO) << "Processed " << count << " files."; } outfile.flush(); outfile.close();保存到
test_name_size.txt中的内容片段如下:000001 500 353 000002 500 335 000003 375 500 000004 406 500 000006 375 500 000008 375 500 000010 480 354现在,
trainval.txttest.txt和test_name_size.txt的内容已经很清晰了,可以利用现成的代码程序,适当修改图像数据集名称和路径就可以创建这三个文件。当然,也可以根据自己的编程喜好,重新编写脚本生成符合上面格式的txt文件即可。 -
dbname_trainval_lmdb
生成该数据库文件的程序为create_data.sh,其核心代码是执行python脚本.../caffe/scripts/create_annoset.py,该脚本需要之前准备的labelmap_dbname.prototxt和trainval.txt作为输入,以及几个可配置项。
.../caffe/scripts/create_annoset.py脚本的核心代码是执行.../caffe/build/tools/convert_annoset程序。labelmap_dbname.prototxt和trainval.txt就是为convert_annoset程序准备的,其源码在.../caffe/tools/convert_annoset.cpp中。创建并写入数据库的核心代码片段如下:
// 创建一个新的数据库
scoped_ptr db(db::GetDB(FLAGS_backend));
db->Open(argv[3], db::NEW);
scoped_ptr txn(db->NewTransaction());
// 把数据存储到数据库
std::string root_folder(argv[1]);
AnnotatedDatum anno_datum;
Datum* datum = anno_datum.mutable_datum();
int count = 0;
int data_size = 0;
bool data_size_initialized = false;
for (int line_id = 0; line_id < lines.size(); ++line_id) {
bool status = true;
std::string enc = encode_type;
if (encoded && !enc.size()) {
// Guess the encoding type from the file name
string fn = lines[line_id].first;
size_t p = fn.rfind('.');
if ( p == fn.npos )
LOG(WARNING) << "Failed to guess the encoding of '" << fn << "'";
enc = fn.substr(p);
std::transform(enc.begin(), enc.end(), enc.begin(), ::tolower);
}
filename = root_folder + lines[line_id].first;
if (anno_type == "classification") {
label = boost::get(lines[line_id].second);
status = ReadImageToDatum(filename, label, resize_height, resize_width,
min_dim, max_dim, is_color, enc, datum);
} else if (anno_type == "detection") {
labelname = root_folder + boost::get(lines[line_id].second);
status = ReadRichImageToAnnotatedDatum(filename, labelname, resize_height,
resize_width, min_dim, max_dim, is_color, enc, type, label_type,
name_to_label, &anno_datum);
anno_datum.set_type(AnnotatedDatum_AnnotationType_BBOX);
}
if (status == false) {
LOG(WARNING) << "Failed to read " << lines[line_id].first;
continue;
}
if (check_size) {
if (!data_size_initialized) {
data_size = datum->channels() * datum->height() * datum->width();
data_size_initialized = true;
} else {
const std::string& data = datum->data();
CHECK_EQ(data.size(), data_size) << "Incorrect data field size "
<< data.size();
}
}
// 序列化
string key_str = caffe::format_int(line_id, 8) + "_" + lines[line_id].first;
// 把数据Put到数据库
string out;
CHECK(anno_datum.SerializeToString(&out));
txn->Put(key_str, out);
if (++count % 1000 == 0) {
// Commit db
txn->Commit();
txn.reset(db->NewTransaction());
LOG(INFO) << "Processed " << count << " files.";
}// end if
}//end for
// 写入最后一个batch的数据
if (count % 1000 != 0) {
txn->Commit();
LOG(INFO) << "Processed " << count << " files.";
}
这段代码中最重要的一行是对ReadRichImageToAnnotatedDatum()方法的调用,将图像文件和标注信息一起写入到了anno_datum变量中,再序列化,提交到数据库缓存区,缓存到一定数量的记录后一次性写入数据库。
ReadRichImageToAnnotatedDatum()方法由Caffe提供,是caffe/src/util/io.cpp中定义的一个方法,该方法及其其调用的ReadImageToDatum方法和GetImageSize方法源码如下:
bool ReadImageToDatum(const string& filename, const int label,
const int height, const int width, const int min_dim, const int max_dim,
const bool is_color, const std::string & encoding, Datum* datum) {
cv::Mat cv_img = ReadImageToCVMat(filename, height, width, min_dim, max_dim,
is_color);
if (cv_img.data) {
if (encoding.size()) {
if ( (cv_img.channels() == 3) == is_color && !height && !width &&
!min_dim && !max_dim && matchExt(filename, encoding) ) {
datum->set_channels(cv_img.channels());
datum->set_height(cv_img.rows);
datum->set_width(cv_img.cols);
return ReadFileToDatum(filename, label, datum);
}
EncodeCVMatToDatum(cv_img, encoding, datum);
datum->set_label(label);
return true;
}
CVMatToDatum(cv_img, datum);
datum->set_label(label);
return true;
} else {
return false;
}
}
void GetImageSize(const string& filename, int* height, int* width) {
cv::Mat cv_img = cv::imread(filename);
if (!cv_img.data) {
LOG(ERROR) << "Could not open or find file " << filename;
return;
}
*height = cv_img.rows;
*width = cv_img.cols;
}
bool ReadRichImageToAnnotatedDatum(const string& filename,
const string& labelfile, const int height, const int width,
const int min_dim, const int max_dim, const bool is_color,
const string& encoding, const AnnotatedDatum_AnnotationType type,
const string& labeltype, const std::map& name_to_label,
AnnotatedDatum* anno_datum) {
// Read image to datum.
bool status = ReadImageToDatum(filename, -1, height, width,
min_dim, max_dim, is_color, encoding,
anno_datum->mutable_datum());
if (status == false) {
return status;
}
anno_datum->clear_annotation_group();
if (!boost::filesystem::exists(labelfile)) {
return true;
}
switch (type) {
case AnnotatedDatum_AnnotationType_BBOX:
int ori_height, ori_width;
GetImageSize(filename, &ori_height, &ori_width);
if (labeltype == "xml") {
return ReadXMLToAnnotatedDatum(labelfile, ori_height, ori_width,
name_to_label, anno_datum);
} else if (labeltype == "json") {
return ReadJSONToAnnotatedDatum(labelfile, ori_height, ori_width,
name_to_label, anno_datum);
} else if (labeltype == "txt") {
return ReadTxtToAnnotatedDatum(labelfile, ori_height, ori_width,
anno_datum);
} else {
LOG(FATAL) << "Unknown label file type.";
return false;
}
break;
default:
LOG(FATAL) << "Unknown annotation type.";
return false;
}
}
可以看到在上面的方法中继续调用了io.cpp中的两个方法ReadFileToDatum和ReadXMLToAnnotatedDatum,分别把图像和图像的标注XML写入到了anno_datum中。其中,图像保存到了anno_datum的mutable_datum中,XML标注信息被保存到了anno_datum的anno_group->anno->bbox中,anno_group还保存了label等信息。
-
dbname_test_lmdb
同4.dbname_trainval_lmdb - 使用
examples/ssd.ipynb核实上面生成的文件的正确性
[1]We use examples/convert_model.ipynb to extract a VOC model from a pretrained COCO model.