面试总结(三)——连连支付
面试总结(三)——连连支付
- 1、solr用什么分词
- 2、关于Spring的面试题
- 3、HashMap的结构
- 4、HashMap和HashTable的区别
- 5、B树和B+树
- 6、Java数据类型,有几个字节
- 7、重载和重写
- 8、缓存器脏读和击穿的解决办法
- 9、封装、继承、多态
- 10、网络的7层模型
- 11、TCP三次握手四次挥手
- 12、进程和线程的区别
昨天下午(2019.4.25),连连支付来学校校招,我舔着个脸就跟着大部队去了。形式是宣讲会+笔试+面试,宣讲会中有两个介绍人还是在阿里有过十几年工作经验的,顿时感觉这家公司实力不俗啊。笔试地题目涵盖范围挺广的,有Java基础、JVM、数据库、tcp/ip、多线程、高并发等,过了笔试的就可以进入面试(这是一句废话),过了一面还有一个群面(我没进,原地爆炸!),最后一个群面是四人(两个Java一个测试、一个算法)组成一队分析一个项目,多个队伍各派一名队员进行陈述。先把面试中遇到问题总结在这里吧。
1、solr用什么分词
大家都知道,solr是一个搜索引擎,先利用分词器建立倒排索引,在对索引进行搜索,但是solr自带的分词器对于中文不是很好用,所以在对中文进行分词的情况中,常用的分词器是IK分词工具。
这里顺便提一个问题,虽然这个概念没被问到,但是学solr的时候已经见到过无数次了。
数据可以分为两类,结构化数据和非结构化数据,那啥是结构化数据、啥又是非结构化数据?
- 结构化数据,简单来说就是数据库。存储在数据库里,可以用二维表结构来逻辑表达实现的数据。结合到典型场景中更容易理解,比如企业ERP、财务系统;医疗HIS数据库;教育一卡通;政府行政审批;其他核心数据库等。这种类别的数据最好处理,只要简单的建立一个对应的表就可以了。
- 非结构化数据是数据结构不规则或不完整,没有预定义的数据模型,不方便用数据库二维逻辑表来表现的数据。包括所有格式的办公文档、文本、图片、XML, HTML、各类报表、图像和音频/视频信息等等。这类信息我们通常无法直接知道他的内容,数据库也只能将它保存在一个BLOB字段中,对以后检索非常麻烦。一般的做法是,建立一个包含三个字段的表(编号 number、内容描述 varchar(1024)、内容 blob)。引用通过编号,检索通过内容描述。现在还有很多非结构化数据的处理工具,市面上常见的内容管理器就是其中的一种。
- 这样的数据和上面两种类别都不一样,它是结构化的数据,但是结构变化很大。因为我们要了解数据的细节所以不能将数据简单的组织成一个文件按照非结构化数据处理,由于结构变化很大也不能够简单的建立一个表和他对应。通常有两种储存方式:化解为结构化数据、用XML格式来组织并保存到CLOB字段中。
2、关于Spring的面试题
由于我还没怎么深入学习Spring框架,所以这里问了一些简单的IOC、DI、AOP的相关问题就过去了。(是得好好看看Spring了)
3、HashMap的结构
HashMap采取数组加链表的存储方式来实现。亦即数组(散列桶)中的每一个元素都是链表,如下图:

为什么需要有这些长度不一的链表呢?
首先我们需要知道什么是哈希冲突。
其实就是再采用哈希函数对输入域进行映射到哈希表的时候,因为哈希表的位桶的数目远小于输入域的关键字的个数,所以,对于输入域的关键字来说,很可能会产生这样一种情况,也就是,不同的关键字会映射到同一个位桶中的情况,这种情况就就叫做哈希冲突。
一般来说,解决哈希冲突有四种方法:拉链法(链地址法)、开放地址法、再哈希法和建立公共溢出区(如果说解决哈希冲突的三种方法,就说前三种),这里只稍微介绍一下,暂时不细说。
- 链地址法:这种方法的基本思想是将所有哈希地址为i的元素构成一个称为同义词链的单链表,并将单链表的头指针存在哈希表的第i个单元中,因而查找、插入和删除主要在同义词链中进行。链地址法适用于经常进行插入和删除的情况。其实HashMap这里的的链表就是对拉链法的一种实现。
- 开放地址法:当冲突发生时,使用某种探查(亦称探测)技术在散列表中形成一个探查(测)序列。沿此序列逐个单元地查找,直到找到给定的关键字,或者碰到一个开放的地址(即该地址单元为空)为止(若要插入,在探查到开放的地址,则可将待插入的新结点存人该地址单元)。查找时探查到开放的地址则表明表中无待查的关键字,即查找失败。(开放地址英文是Open addressing,网上好多博客把开发地址法写成了开放定址法,不知道啥情况)
- 再哈希法:这种方法是同时构造多个不同的哈希函数,如果第一个哈希函数发生冲突,那就计算第二个哈希函数,如果第二个哈希函数发生冲突,那就计算第三个哈希函数……这种方法不易产生聚集,但增加了计算时间。
- 建立公共溢出区:这种方法的基本思想是:将哈希表分为基本表和溢出表两部分,凡是和基本表发生冲突的元素,一律填入溢出表。
4、HashMap和HashTable的区别
HashMap和Hashtable都实现了Map接口,但决定用哪一个之前先要弄清楚它们之间的分别。主要的区别有:线程安全性,同步(synchronization),以及速度。
- HashMap几乎可以等价于Hashtable,除了HashMap是非synchronized的,并可以接受null(HashMap可以接受为null的键值(key)和值(value),而Hashtable则不行)。
- HashMap是非synchronized,而Hashtable是synchronized,这意味着Hashtable是线程安全的,多个线程可以共享一个Hashtable;而如果没有正确的同步的话,多个线程是不能共享HashMap的。Java 5提供了ConcurrentHashMap,它是HashTable的替代,比HashTable的扩展性更好。
- 另一个区别是HashMap的迭代器(Iterator)是fail-fast迭代器,而Hashtable的enumerator迭代器不是fail-fast的。所以当有其它线程改变了HashMap的结构(增加或者移除元素),将会抛出ConcurrentModificationException,但迭代器本身的remove()方法移除元素则不会抛出ConcurrentModificationException异常。但这并不是一个一定发生的行为,要看JVM。这条同样也是Enumeration和Iterator的区别。
- 由于Hashtable是线程安全的也是synchronized,所以在单线程环境下它比HashMap要慢。如果你不需要同步,只需要单一线程,那么使用HashMap性能要好过Hashtable。
- HashMap不能保证随着时间的推移Map中的元素次序是不变的。
我们能否让HashMap同步?
答案是肯定的,HashMap可以通过下面的语句进行同步:
Map m = Collections.synchronizeMap(hashMap);
结论
Hashtable和HashMap有几个主要的不同:线程安全以及速度。仅在你需要完全的线程安全的时候使用Hashtable,而如果你使用Java 5或以上的话,请使用ConcurrentHashMap吧。
(以上内容引用自博客)
5、B树和B+树
知识盲区,很重要,得细看,先把简单的处理掉
6、Java数据类型,有几个字节
基础中的基础,必备知识点,网上答案很多,我从博客中盗来一张图,感觉这个说得比较清楚。
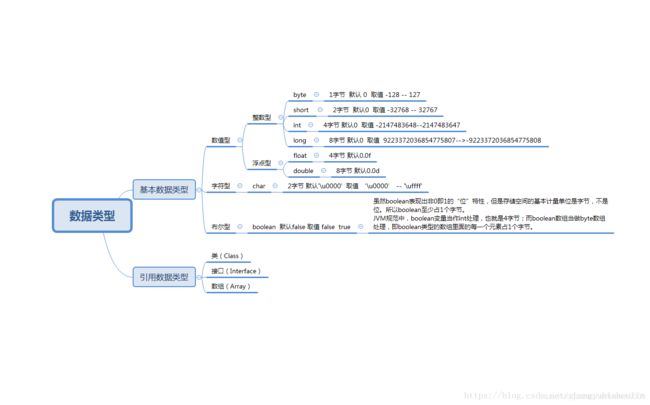
类型的简单对比
| 基本数据类型 | 引用数据类型 |
|---|---|
| 在栈中进行分配 | 在堆中进行分配,堆的读写速度远不及栈 |
| 变量名指向具体的数值 | 变量名指向存数据对象的内存地址,即变量名指向hash值 |
| 变量在声明之后java就会立刻分配给他内存空间 | 它以特殊的方式(类似C指针)指向对象实体(具体的值),这类变量声明时不会分配内存,只是存储了一个内存地址 |
| 基本类型之间的赋值是创建新的拷贝 | 对象之间的赋值只是传递引用 |
| “==”和“!=”是在比较值 | “==”和“!=”是在比较两个引用是否相同,值比较需要自己实现equals()方法 |
| 基本类型变量创建和销毁很快 | 类对象需要JVM去销毁 |
(该表格引用自博客)
7、重载和重写
这个问题在之前的文章里总结过,这里就不再细说了,看这篇《ALi面试题》。
8、缓存器脏读和击穿的解决办法
脏读就是指当一个事务正在访问数据,并且对数据进行了修改,而这种修改还没有提交到数据库中,这时,另外一个事务也访问这个数据,然后使用了这个数据。因为这个数据是还没有提交的数据,那么另外一个事务读到的这个数据是脏数据(Dirty Data),依据脏数据所做的操作可能是不正确的。
解决办法:在修改数据库的同时修改缓存器中的数据。(这是一个比较笼统的答案,应该还有比较细致、精确的答案,但我还没找到)
(下面的缓存击穿及解决办法的相关内容主要来自博客)
什么是缓存击穿:在高并发下,多线程同时查询同一个资源,如果缓存中没有这个资源,那么这些线程都会去数据库查找,对数据库造成极大压力,缓存失去存在的意义。
解决办法:
- 后台刷新:
- 后台定义一个job(定时任务)专门主动更新缓存数据。比如,一个缓存中的数据过期时间是30分钟,那么job每隔29分钟定时刷新数据(将从数据库中查到的数据更新到缓存中)。
- 这种方案比较容易理解,但会增加系统复杂度。比较适合那些 key 相对固定,cache 粒度较大的业务,key 比较分散的则不太适合,实现起来也比较复杂。
- 检查更新:
- 将缓存key的过期时间(绝对时间)一起保存到缓存中(可以拼接,可以添加新字段,可以采用单独的key保存……不管用什么方式,只要两者建立好关联关系就行)。在每次执行get操作后,都将get出来的缓存过期时间与当前系统时间做一个对比,如果缓存过期时间-当前系统时间<=1分钟(自定义的一个值),则主动更新缓存.这样就能保证缓存中的数据始终是最新的(和方案一一样,让数据不过期。)
- 这种方案在特殊情况下也会有问题。假设缓存过期时间是12:00,而 11:59 到12:00这1分钟时间里恰好没有get 请求过来,又恰好请求都在 11:30 分的时 候高并发过来,那就悲剧了。这种情况比较极端,但并不是没有可能。因为“高并发”也可能是阶段性在某个时间点爆发。
- 分级缓存:
- 采用 L1 (一级缓存)和 L2(二级缓存) 缓存方式,L1 缓存失效时间短,L2 缓存失效时间长。 请求优先从 L1 缓存获取数据,如果 L1缓存未命中则加锁,只有 1 个线程获取到锁,这个线程再从数据库中读取数据并将数据再更新到到 L1 缓存和 L2 缓存中,而其他线程依旧从 L2 缓存获取数据并返回。
- 这种方式,主要是通过避免缓存同时失效并结合锁机制实现。所以,当数据更新时,只能淘汰 L1 缓存,不能同时将 L1 和 L2 中的缓存同时淘汰。L2 缓存中可能会存在脏数据,需要业务能够容忍这种短时间的不一致。而且,这种方案可能会造成额外的缓存空间浪费。
- 加锁(详见参考博客)
9、封装、继承、多态
封装:
-
概念:
将类的某些信息隐藏在类的内部,不允许外部程序访问,而是通过该类提供的方法来实现对隐藏信息的操作和访问。 -
好处:
-
只能通过规定的方法访问数据
-
隐藏类的实例细节,方便修改和实现
- 封装的实现步骤
-
修改属性的可见性——设为private
-
创建getter/setter方法,用于属性的读写
-
在getter/setter方法中加入属性控制语句,对属性值的合法性进行判断

从上往下,封装性越差。
继承:
继承是类与类的一种关系,例如:动物和狗的关系,动物是父类(或基类),狗是子类(或派生类)。
要注意的是,在Java中的继承是单继承,也就是说一个儿子只能有一个爸爸
继承的好处:
-
子类拥有父类的所有属性和方法(private除外)
-
子类对父类代码的复用
提到继承,特别注意重载和重写的关系
继承的初始化顺序:
若创建一个子类对象,系统会先创建父类的属性进行初始化,再调用父类的构造方法,然后再创建子类的属性进行初始化,最后调用子类的构造方法。
多态:
多态指对象的多种引用形态,继承是多态的前提
- 引用多态
-
父类的引用可以指向本类对象 Animal object1=new Animal();
-
父类的引用可以指向子类对象 Animal object2=new Dog();
注意:子类的引用不可以指向父类对象Dog object3=new Animal();
- 方法多态
-
创建本类对象时,调用的方法为本类的方法;
-
创建子类对象时,调用的为方法为子类重写的方法或者继承的方法
注意:本类对象不能调用子类的方法
引用类型转换:
Dog dog=new Dog();
Animal animal=dog(); //向上类型转换:(不存在风险)
Dog dog2=(Dog)animal; //向下类型转换:(存在风险,可能出现数据溢出)
if(animal instenceof Cat){ //用instanceof运算符,来解决引用对象的类型,避免类型转换的安全问题,返回布尔值,来判断animal能否转换为Cat类型
Cat cat=(Cat)animal;
}
(参考博客1和博客2,还有我自己的这篇文章)
10、网络的7层模型
从上到下分别为:应用层、表示层、会话层、传输层、网络层、数据链路层、物理层。
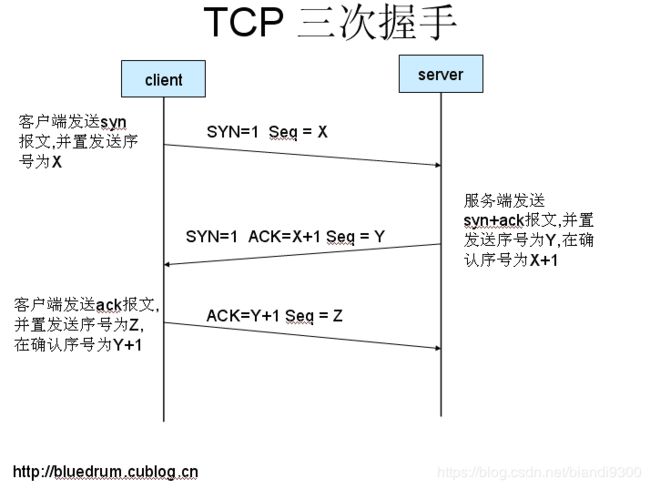
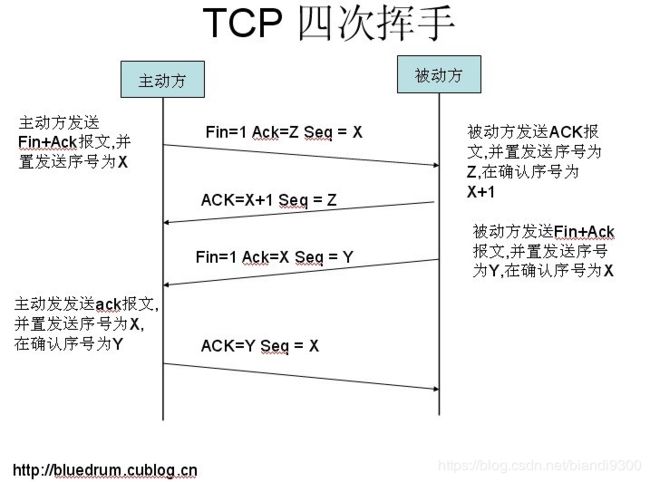
11、TCP三次握手四次挥手
先放两个图,后期再补详细点的
12、进程和线程的区别
- 首先是定义
-
进程:是执行中一段程序,即一旦程序被载入到内存中并准备执行,它就是一个进程。进程是表示资源分配的的基本概念,又是调度运行的基本单位,是系统中的并发执行的单位。
-
线程:单个进程中执行中每个任务就是一个线程。线程是进程中执行运算的最小单位。
-
一个线程只能属于一个进程,但是一个进程可以拥有多个线程。多线程处理就是允许一个进程中在同一时刻执行多个任务。
-
线程是一种轻量级的进程,与进程相比,线程给操作系统带来侧创建、维护、和管理的负担要轻,意味着线程的代价或开销比较小。
-
线程没有地址空间,线程包含在进程的地址空间中。线程上下文只包含一个堆栈、一个寄存器、一个优先权,线程文本包含在他的进程 的文本片段中,进程拥有的所有资源都属于线程。所有的线程共享进程的内存和资源。 同一进程中的多个线程共享代码段(代码和常量),数据段(全局变量和静态变量),扩展段(堆存储)。但是每个线程拥有自己的栈段, 寄存器的内容,栈段又叫运行时段,用来存放所有局部变量和临时变量。
-
父和子进程使用进程间通信机制,同一进程的线程通过读取和写入数据到进程变量来通信。
-
进程内的任何线程都被看做是同位体,且处于相同的级别。不管是哪个线程创建了哪一个线程,进程内的任何线程都可以销毁、挂起、恢复和更改其它线程的优先权。线程也要对进程施加控制,进程中任何线程都可以通过销毁主线程来销毁进程,销毁主线程将导致该进程的销毁,对主线程的修改可能影响所有的线程。
-
子进程不对任何其他子进程施加控制,进程的线程可以对同一进程的其它线程施加控制。子进程不能对父进程施加控制,进程中所有线程都可以对主线程施加控制。
(内容来自百家号)