一步一步教你做微博用户画像分析:Python微博爬虫+词云生成
Python练习项目
- 目标
- 编写Python微博爬虫
- 数据来源
- 微博列表请求分析
- 应答报文分析
- 获取微博正文
- 微博正文文本提取
- 获取多页微博
- 反爬虫机制应对处理
- 爬虫完整代码
- 词云图生成
- 成果展示
目标
用爬虫程序抓取目标用户人民日报的微博文本,通过分析词频,生成直观的词云图。
编写Python微博爬虫
所谓爬虫程序,其实就是通过计算机运行程序,模拟用户浏览网页的行为,向特定网站发送连接请求,获取网站返回的数据。
- 所以首先需要确定发送请求的对象,也就是请求的目标网址
- 其次需要确定发送请求的url中所需要携带的请求参数,从而实现检索特定网页信息
- 最后则是如何从返回的网页数据中,定位出自己需要的有效信息
注意:微博的接口可能会发生变化,所以请不要盲目照抄,建议按照下述流程独立分析。
数据来源
微博移动版网页(点此跳转)
内容简洁,便于分析,因此选用移动版网页作为爬取对象。
微博列表请求分析
打开目标用户的移动版微博主页:人民日报
注意:此处需要退出微博登录来保证请求内容的普适性。
F12打开开发者工具,这里使用的是谷歌浏览器。选中最上方的Network标签页,刷新页面来监测网络连接请求。

通过分析preview和response两个标签页的内容,可以确定获取微博列表的链接请求为:
https://m.weibo.cn/api/container/getIndex?uid=2803301701&t=0&luicode=10000011&lfid=100103type%3D1%26q%3D%E4%BA%BA%E6%B0%91%E6%97%A5%E6%8A%A5&type=uid&value=2803301701&containerid=1076032803301701
在开发者工具中查看该请求的头部信息,下拉到最后查看请求参数:
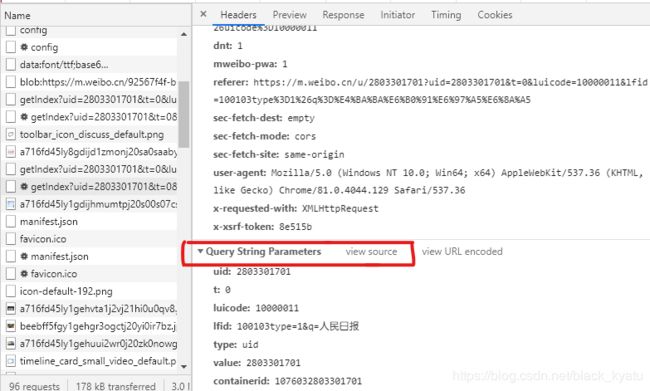
分析到请求参数一共有七个:
- uid: 2803301701
- t: 0
- luicode: 10000011
- lfid: 100103type=1&q=人民日报
- type: uid
- value: 2803301701
- containerid: 1076032803301701
其中uid和value都是用来唯一标识用户的,内容相同,lifd是用来标识微博用户名,containerid用来标识不同范围的微博, 107603 + u i d \rm107603+uid 107603+uid表示公开的所有微博,其他参数则都是默认无需变化。
去掉参数后的请求地址为
https://m.weibo.cn/api/container/getIndex?
请求地址+特定参数即可访问特定用户的微博列表。
应答报文分析
通过开发者工具可以发现微博服务器回应请求的是一个较为复杂的json格式文件。
不要慌,一步步分析。
首先,通过request库的get方法,向上述分析出的url地址发送请求,获得回应的字符串文件,代码如下:
import requests
import json
url = 'https://m.weibo.cn/api/container/getIndex?'
#headers信息防止触发反爬虫机制
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36'}
parameter = {
'uid': '2803301701',
't': '0',
'luicode': '10000011',
'lfid': '100103type=1&q=人民日报',
'type': 'uid',
'value': '2803301701',
'containerid': '1076032803301701',
'page_type': '60',
'page': '1'
}
respones = requests.get(url + urlencode(parameter), headers=headers)
#通过json库的loads方法将返回的字符串转换为字典数据格式
data = json.loads(respones.text)
通过使用代码循环遍历字典中的键值对,对每个值输出其类型,是字典则迭代遍历,可以很快搞清楚该json文件的结构,并定位到我们所需用的信息。
该json文件最外层有两个键,一个是ok,值为0或1,代表查询成功或失败。
一个是data,值是一个字典,我们需要的信息在该字典的键cards对应的值中,而cards对应的值则是一个列表。在这里可以推测,因为移动版微博的每条微博都是卡片样式,所以cards中的每一个元素,对应主页的一条微博。
获取微博正文
通过访问微博正文,可以发现url格式为: h t t p s : / / m . w e i b o . c n / d e t a i l / + 标 识 数 字 \boxed {\rm https://m.weibo.cn/detail/+标识数字} https://m.weibo.cn/detail/+标识数字每条微博对应一个独一无二的标识数字,而我们需要获取这个标识来访问每条微博。
cards对应的列表中,每个元素都是一个字典,对应了一条微博的主要内容和各种信息,其中我们需要的标识数字,在mblog键对应的值当中。mblog对应的值又是一个字典,而我们需要的数字,则是该字典中的idstr或mid键值对
将获取到的微博标识数字与url请求部分结合,可以获取到微博正文。
循环遍历cards列表,即可获取所有微博的正文
对应的代码如下:
#接上述得到的data字典
if data['ok'] == 0:
print("爬取完成~")
break
if data['ok'] == 1:
for item in data['data']['cards']:
if 'mblog' not in item:
continue
blog = requests.get('https://m.weibo.cn/detail/' + item['mblog']['idstr'], headers=headers)
微博正文文本提取
获取到微博正文页面的html代码后,需要从中提取出正文内容。
检查html代码,可以很容易定位到微博正文部分,特征为"text":后面的内容,正文内容被双引号包裹,且不存在换行字符,据此可以正则匹配出正文内容,正则表达式如下:
" t e x t " : . ∗ " \tt"text":.*" "text":.∗"
其中.代表任一不是换行符的字符,*表示匹配任意多次,即采用贪婪匹配模式,尽可能多的匹配字符,因为正文对应的代码中可能含有"。而正文结束后会有换行符,所以不担心过度匹配。
匹配完成后,会发现正文中依然含有html代码和首部的"text":多余字符,需要再次匹配除去。采用re库的sub函数,利用正则匹配表达式去除匹配到的字符串。
- 去除html代码:html代码都在<>中,非贪婪模式匹配尖括号,来防止正文被除去,这里需要注意,并不是所有微博正文都会含有代码,没有时会抛出异常,需要进行异常处理 < . ∗ ? > \tt<.*?> <.∗?>
- 去除首部的
"text":,\s用来匹配空格 : " t e x t " : \ s " ? \tt"text":\backslash s"? "text":\s"? - 去除尾部的
“:因为引号也会出现在正文中,故这里采用字符串转列表,直接操作列表后再改字符串的方法去多多余的引号
正文处理部分的代码如下:
#接上部分的for循环
for item in data['data']['cards']:
if 'mblog' not in item:
continue
blog = requests.get('https://m.weibo.cn/detail/' + item['mblog']['idstr'], headers=headers)
res = re.search('"text":.*"', blog.text)
try:
blog_text = re.sub('<.*?>', '', res.group())
#正文纯文字无代码时捕获异常,继续后续流程
except AttributeError:
blog_text = res.group()
#
去除首尾用来定位匹配的字符串
final_text = list(re.sub(r'"text":\s"?', '', blog_text))
final_text[-1] = ''
final_text = ''.join(final_text)
获取多页微博
使用上述请求参数爬取微博时存在一个问题,即微博服务器只会返回10条微博数据。通过向下滑动页面,使用开发者工具检测请求,可以看到下拉页面加载时,多出了page_type和page参数。

首先猜测page参数代表页码,在请求参数字典中加入这两个参数,遍历完response报文中的cards列表后,对page参数执行递增操作,发现可以获取到新的页面微博列表。
实际运行一下程序,发现最多只能抓取2000条左右的微博数据,之后返回的json数据中的ok键值对的值为0,没有微博列表数据。
猜测需要增大page_type,对page_type参数进行测试,当page不变时,改变page_type参数,对结果无影响,但是增大’page_type’之后,page参数可以继续获取微博数据,故page_type决定了你能获取的最大微博数目。
所以当返回的json文件ok值为0,对page_type和page值进行递增,实现抓取大规模微博数据。
当目标微博数量在2000以下时,则只需要递增page值。
反爬虫机制应对处理
实际测试中发现微博对爬虫有着很多限制:
- 首先,如果无限制爬取网页,很快会被微博服务器发现,会拒绝返回有效数据,提示无内容。所以需要在循环中加入睡眠时间,降低爬取速度。经过测试,1-4秒内随机请求一次即可避坑。
- 其次,需要在get请求中设置headers参数中的user-agent,通过观察开发者工具中的headers即可获取该参数。否在会触发418状态码错误,即被识别出爬虫程序。
- 还有,有些情况下,刷新页码后会获取到相同的微博,需要对比微博id,及时跳过
- 最后,对于每个ip地址,微博似乎限制了其每小时最多能获取的微博数量,会直接拒绝访问,抛出拒绝访问错误。这种情况下只能更换ip地址或者等待一段时间。
爬虫完整代码
将捕获的文本存入文本文档,代码如下:
import random
import re
import traceback
from urllib.parse import urlencode
import json
import time
import requests
# 自定义异常类,用于跳出多重循环
class Getoutofloop(Exception):
pass
# 获取微博列表的url地址
url = 'https://m.weibo.cn/api/container/getIndex?'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36'}
parameter = {
'uid': '2803301701',
't': '0',
'luicode': '10000011',
'lfid': '100103type=1&q=人民日报',
'type': 'uid',
'value': '2803301701',
'containerid': '1076032803301701',
'page_type': '03',
'page': '1'
}
txt = open("spider.txt", 'w', encoding='utf-8')
i = 1
j = 1
former = ''
while True:
# 人为设定循环最大次数
if j >= 5000:
print("爬取结束,i = {},j = {}".format(i, j))
# 用于捕获各种异常,保证读取到的数据能正常存入文件
try:
respones = requests.get(url + urlencode(parameter), headers=headers)
time.sleep(random.uniform(1, 4))
# 运行状态查看,可以省略
print('status:', respones.status_code)
if respones.status_code != 200:
print('爬虫暴露了!')
print('status:', respones.status_code)
break
data = json.loads(respones.text)
# 返回ok值为0,改变page_type值
if data['ok'] == 0:
parameter['page_type'] = str(int(parameter['page_type']) + 1)
parameter['page'] = str(int(parameter['page']) + 1)
i = i + 1
j = j + 1
print("i=", i)
print("j=", j)
continue
if data['ok'] == 1:
# 循环当前微博列表
for item in data['data']['cards']:
if 'mblog' not in item:
continue
# 打印微博id,可以忽略
print(item['mblog']['mid'])
if former == item['mblog']['mid']:
break
blog = requests.get('https://m.weibo.cn/detail/' + item['mblog']['mid'], headers=headers)
# 请求状态码不正常,则直接结束程序
if blog.status_code != 200:
print("爬虫被限制了")
raise Getoutofloop()
res = re.search('"text":.*"', blog.text)
# 当前页面没找到文本的异常处理
try:
blog_text = re.sub('<.*?>', '', res.group())
except AttributeError:
print('找不到文本')
print(blog.text)
continue
# 正则表达式提前文字
final_text = list(re.sub(r'"text":"?', '', blog_text))
final_text[-1] = ''
final_text = ''.join(final_text)
txt.write(final_text + '\n')
former = item['mblog']['mid']
else:
print('failed')
break
j = j + 1
parameter['page'] = str(int(parameter['page']) + 1)
except BaseException as err:
print(type(err))
traceback.print_exc()
print('no response')
break
txt.close()
词云图生成
词云图生成部分比较简单,用到第三方中文分词库jieba分词,再用worldcloud库生成词云即可,需要事先准备好背景图片,生成词云字体颜色从图片背景中获取自动生成,代码如下:
import jieba
import matplotlib
import matplotlib.pyplot as plt
from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator
fin1 = open("文本.txt", "r", encoding='UTF-8')
def split_word(fin):
text = ''
# 读取文件,去除换行符
for line in fin.readlines():
line = line.strip('\n')
# 分词并存入text,注意用空格隔开
text += " ".join(jieba.cut(line))
# 设置背景图
background_picture = "背景图片.jpg"
background_Image = plt.imread(background_picture)
wc = WordCloud(
background_color='white',
mask=background_Image,
# 设置字体
font_path=r'C:\Windows\Fonts\simhei.ttf',
# 设置词云中的词语数量
max_words=int(100),
# 分词用到的停止词,默认即可,也可以自定义
stopwords=STOPWORDS,
# 最大字号
max_font_size=400,
# 字体颜色种类
random_state=10
)
wc.generate_from_text(text)
wc.recolor(color_func=ImageColorGenerator(background_Image))
plt.imshow(wc)
plt.axis("off")
plt.show()
split_word(fin1)
成果展示
应用上述程序分析了2020年3月底到5月初的人民日报微博,生成词云图如下:

可以非常直观的看到,整个四月份,新馆肺炎依然牢牢占据人民日报的关注,并且关注点主要放在了境外输入的确诊病例上。
我们修改程序,爬取2017年12月至2020年5月份的两万多条微博进行分析,结果如下:

可以看到时间跨度拉长后,境外输入占比大大降低,而新冠肺炎确诊病例成为主要高频词,说明了新冠疫情可以算得上是近三年以来中国社会发生的最占据公共注意力的大事件。