ACL2019之对话系统
目录
0. 前言
1. 语义理解
2. 检索式对话
3 生成式对话
4. 情感对话
5. 主动对话
6. 在线学习
7. 强化学习
8. 迁移学习
9. 对抗学习
参考
0. 前言
期盼已久的ACL2019大会刚刚结束,一大波论文向我们袭来,由于本人一直关注对话系统,所以将这方面的文章进行汇总学习,作为一枚码农,虽然不创造算法,但希望能做好搬运工,让算法产生应用价值。这篇文章仅仅为粗读,接下来会选择一些进行精读学习。
1. 语义理解
1.1 Joint Slot Filling and Intent Detection via Capsule Neural Networks
Chenwei Zhang, Yaliang Li, Nan Du, Wei Fan and Philip Yu
本文来自伊利诺大学芝加哥分校、阿里巴巴、腾讯医疗AI Lab和清华大学。在自然语言理解中,识别槽位(slot)和用户的意图非常重要,现有的工作要么以pipeline的方式将槽位填充和意图检测分别建模,要么直接采用联合模型同时得到槽位和意图,但并没有显式地保持词、槽位和意图的层级关系。为了利用语义层级来更有效地建模,我们提出了一个胶囊神经网络来进行槽位填充和意图识别,它通过一个动态路由协议(routing-by-agreement)来实现,并且提出了一个路由协议利用推断出来的意图表示来合成槽位填充的性能。实验表明我们的模型非常有效。
本文提出的模型由3种类型的胶囊构成:
(1)WordCaps:学习上下文感知的词表示;
(2)SlotCaps:利用动态路由来对词的槽位类型进行分类,并构建每个槽位类型的表示;
(3)InentCaps:利用槽位表示和句子的上下文来确定意图标签。

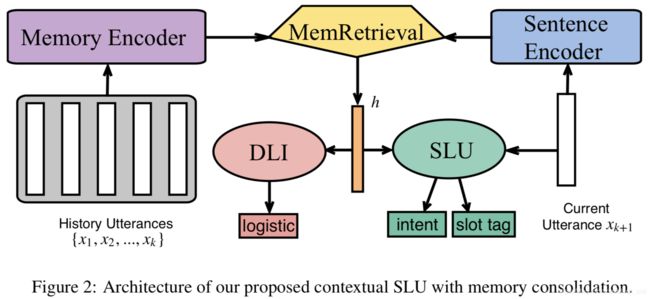
1.2 Memory Consolidation for Contextual Spoken Language Understanding with Dialogue Logistic Inference
He Bai, Yu Zhou, Jiajun Zhang and Chengqing Zong
本文来自中科院自动化所。对话上下文在口语理解中非常重要,它通常采用明确的记忆表示来编码,然而,大多数之前的工作建模上下文记忆的目标只有一个,就是最大化SLU的效果,但这并没有充分利用它的价值。本文提出了一个新的对话逻辑推断(DLI)任务来加强上下文记忆,和SLU一起进行多任务训练,DLI的定义是从随机乱序的对话中恢复原始的逻辑顺序,它和SLU模型共享记忆编码器和检索机制。实验表明很多上下文SLU都可以从这个方法中受益,提升很明显。
方法结构如下,包括以下几个部分:
(1)记忆编码器:采用BiGRU;
(2)句子编码器:采用BiGRU;
(3)记忆检索:基于注意力的方法、基于序列编码的方法(全连接+BiGRU)
(4)上下文SLU:BiGRU + BiLSTM
(5)DLI
2. 检索式对话
2.1 Learning a Matching Model with Co-teaching for Multi-turn Response Selection in Retrieval-based Dialogue Systems
Jiazhan Feng, Chongyang Tao, wei wu, Yansong Feng, Dongyan Zhao and Rui Yan
本文来自北京大学和微软。我们研究检索式对话系统中的匹配模型,为了学习对训练数据中噪声更加鲁棒的匹配模型,我们提出了一个通用的共同学习(co-teaching)框架,它包括三个具体的学习策略,同时覆盖基于损失函数和数据课程表的学习,在这个框架下,我们采用不同的训练集合同时学习两个匹配模型,在每一轮迭代中,一个模型将它从训练集中学到的知识迁移到另一个模型,同时接受另一个模型关于克服噪声的指导。两个模型同时作为学生和老师,相互学习共同提高。实验结果表明提升很明显。

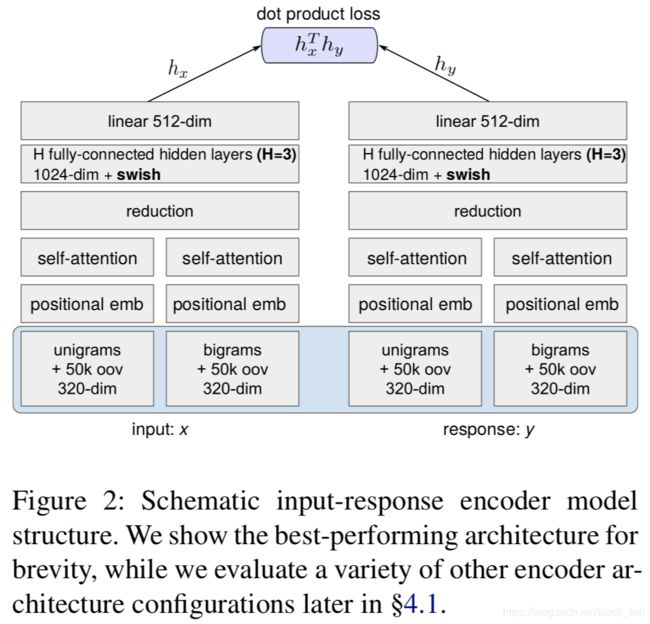
2.2 Training Neural Response Selection for Task-Oriented Dialogue Systems
Matthew Henderson, Ivan Vulić, Daniela Gerz, Iñigo Casanueva, Paweł Budzianowski, Sam Coope, Georgios Spithourakis, Tsung-Hsien Wen, Nikola Mrkšić and Pei-Hao Su
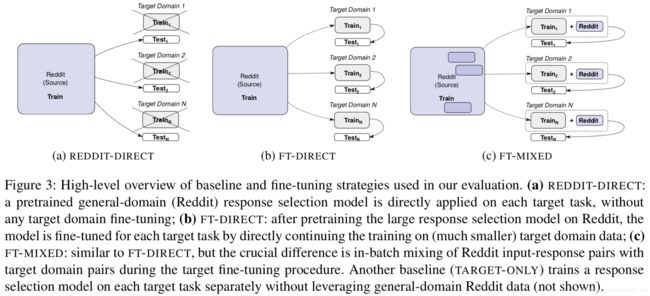
本文来自PolyAI。尽管检索式模型在聊天机器人的文献中非常流行,但是它对任务型对话的作用并不是太大,因为大多数对话都面临数据缺少的问题。受到最近预训练语言模型成功的启发,我们提出了一种有效的方法来进行任务型对话的回复选择,我们的方法如下:(1)在大而通用的对话语料上进行回复选择的预训练;(2)在目标对话领域,利用少量的领域内数据进行模型调优。实验结果表明,我们的模型非常有效。
模型预训练时的结构如下,首先从原始输入文本中提取一元和二元特征,每个特征用320维度的向量来表示;然后参考transformer的结构,位置embedding和自注意力机制应用于前面提取的特征,接着分别把它们的embedding相加并除以词序列长度的平方根,两个向量平均得到一个320维度的文本表示;再通过一个前馈网络得到一个512的表示,最后基于这个表示计算相似度。
调优的方式包括以下几种:(a)不调优,直接用;(2)目标域调优;(3)目标域+源域调优。
3 生成式对话
3.1 Fine-Grained Sentence Functions for Short-Text Conversation
Wei Bi, Jun Gao, Xiaojiang Liu, Shuming Shi
本文来自腾讯AI Lab与苏州大学。句子功能(Sentence function)是一个重要的语言学特征,该特征在对话中能够体现说话者的目的。已经有许多研究结果表明引入句子功能特征改善对话模型的性能。但是,目前仍旧不存在一个带有句子功能标注的大型对话数据。在这个工作中,我们构建了一个新的带有句子功能标注的短文本对话数据集。在此数据集上我们训练了分类网络用于:(1) 确定新的大型短文本对话数据中句子的功能类别;(2) 根据测试输入预测回复文本可能的句子功能。我们在此基础上搭建了基于检索和生成的两种对话模型。实验结果表明使用句子功能特征可以帮助这些对话模型提高生成回复的性能。
数据标注方面,我们将句子功能的label分为两个等级,level-1分4类:Declarative(DE,陈述句)、Interrogative(IN,疑问句)、Imperative(IM,祈使句)、Exclamatory(EX,感叹句),level-2在此基础上分的更细一些,比如,IN可以分为Wh-style IN,Yes-no IN等。
句子功能分类方面,分为两个任务:一是给定query或response,预测它的句子功能,二是给定query和它的功能,预测它的回复的句子功能。分类模型的选择上,可以采用CNN或者RNN作为encoder,然后再增加全连接和softmax即可。
那如何利用句子功能来对话呢?基于检索的方法中,在rerank模型中考虑句子功能;基于生成的方法中,在生成的过程中增加句子功能的信息。
3.2 Semantically Conditioned Dialog Response Generation via Hierarchical Disentangled Self-Attention
Wenhu Chen, Jianshu Chen, Pengda Qin, Xifeng Yan and William Yang Wang
本文来自腾讯AI Lab、加州大学Santa Barbara分校、北邮。本文主要解决用语义来控制对话回复生成的问题。在用语义控制多领域大规模对话的生成的问题中,因为多种语义输入的组合呈现指数增长,所以在实际解决时会面临很大困难。本文针对这个问题,将一系列对话决策整合成一个多层的分级图结构,并将这个结构整合到Transformer模型结构中,用于控制其对话文本生成过程。在大规模Multi-Domain-WOZ数据集上,我们提出的模型获得了超过4个BLEU点的提升,同时人工评测也显著超越其他基准方法。
3.3 Learning to Abstract for Memory-Augmented Conversational Response Generation
Zhiliang Tian,1,3∗ Wei Bi,2 Xiaopeng Li,1,3 Nevin L. Zhang
本文来自腾讯AI Lab与香港科技大学。神经网络生成模型在开发领聊天对话中是一个非常活跃的研究领域,现有生成式方法存在诸如生成的回复多样性差、信息量不足等一些问题。一些研究者尝试利用检索系统去增强生成模型的效果,但是该方法受限于检索系统的质量。在本文中,我们提出了一种记忆增强的生成模型,他可以对训练语料进行抽象,并且把抽象出来的有用的信息存储在记忆模块中,以便辅助生成模型去生成回复。具体来说,我们的模型会先对用户输入(query)-回复(response)对做聚类,接着抽取出每个类的共性,然后让生成模型学习如何利用抽出的共性信息。实验效果表面我们的模型可以大幅提升回复生成的效果。

本文模型结构如下:
(1)输入-回复记忆模块:包含K个记忆单元,每个单元包含一个key和value,给定query,查找最相似的key并返回它的value,聚类时采用k均值算法。
(2)记忆增强的回复生成模块:包含两个分支,上面部分是记忆增强的seq2seq,下面部分是条件CAE,它可以学习回复表示,并写入记忆。

3.4 ReCoSa: Detecting the Relevant Contexts with Self-Attention for Multi-turn Dialogue Generation
Hainan Zhang, Yanyan Lan, Liang Pang, Jiafeng Guo and Xueqi Cheng
本文来自中科院计算所。在多轮对话生成中,回复往往只跟少量的上下文有关,因此,一个想法是检测出相关的上下文并根据它来生成回复。然而,广泛被采用的分层循环编解码模型以相同的方式考虑全部上下文,这将影响接下来的回复生成效果,一些研究者采用余弦相似度或者传统注意力机制来发现相关的上下文,但是存在相关性不充分或者位置偏见的问题。本文我们提出了一个新的模型ReCoSa,来解决这个问题,具体地,首先采用词级别的LSTM编码器来获取每个上下文的初始表示,然后利用自注意力来更新上下文的表示和经过掩码的回复的表示,最后计算上下文和回复的注意力权重,用于后续的解码阶段。实验表明我们的模型很有用。
模型结构如下图,包括上下文表示编码器、回复表示编码器、上下文-回复注意力解码器。

3.5 Neural Response Generation with Meta-words
Can Xu, wei wu, Chongyang Tao, Huang Hu, Matt Schuerman and Ying Wang
本文来自微软和北京大学。本文研究基于meta-words的开放域回复生成,meta-words是一个结构化的记录,它描述了回复的各个属性,允许我们明确地建模开放域对话的一对多关系,并且可解释可控制地生成回复。为了在对话生成中使用meta-word,我们在seq2seq框架中增加了一个跟踪记忆网络的目标,它用meta-word表示目标,并管理对话生成过程,通过一个状态记忆面板和状态控制面板来达到这个目标。实验表明我们的结果在相关性、多样性、一对多的准确性、meta-word准确性、以及人工评测上都提升明显。
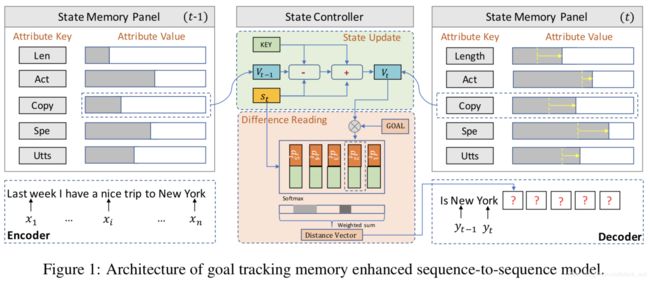
3.6 Are Training Samples Correlated? Learning to Generate Dialogue Responses with Multiple References
Lisong Qiu1,2, Juntao Li1,2, Wei Bi3, Dongyan Zhao1,2, Rui Yan1,2∗
本文来自腾讯AI Lab与北京大学。开放域对话生成因为有很大的应用价值,所以变得越来越流行,并且取得了一些重要进展,但仍然面临通用回复的问题。之前的工作通常将对话建模为一对一的提问和回复映射,忽略了对话中自然存在的一对多的映射关系。对此,本文通过考虑多个参考回复之间的相关性,提出了一种两步式的对话生成模型,第一步提取不同回复的共同特征,第二步中提取各自的个性特征,两步结合得到多样且合适的回复。实验结果显示本文提出的方法可以生成多样且合理的回复,并且相较于基准模型在自动与人工评测指标下均有着更好的表现。
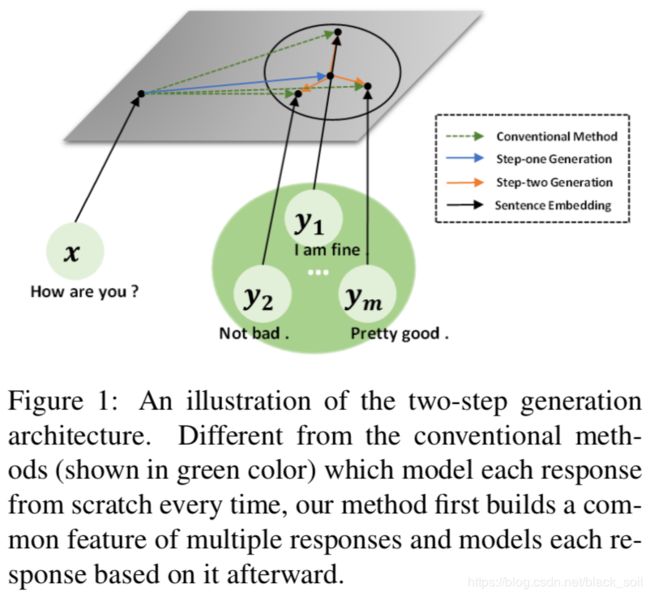
训练数据定义为一对多的形式:{(x, {y})},模型结构如下图:
(1)第一步生成:提取回复集合的共同特征,首先利用bi-GRU编码提问,然后经过一个匹配网络(前馈神经网络)计算共同特征c,接着经过回复解码器得到输出yc,yc认为是所有有效回复的近似,另外,为了度量yc对回复中间点的近似,我们建立一个判别器,因此最终的损失函数来自这两部分。
(2)第二步生成:提取回复的个性特征,采用CVAE架构,略有不同点。
(3)预测过程。

实验结果样例如下:

4. 情感对话
4.1 Towards Empathetic Open-domain Conversation Models: a New Benchmark and Dataset
Hannah Rashkin1⋆, Eric Michael Smith2, Margaret Li2, Y-Lan Boureau2
本文来自华盛顿大学和Facebook AI团队。准确地识别对方的情感并作出相应的回复,是对话机器人遇到的一个重要挑战,尽管对于人类来说比较容易,但是对于AI系统却非常困难,因为能够用来训练和评测的合适和公开可用数据集非常缺乏。本文提出了一个情感对话的基线方法和数据集,该数据集包括25k个对话,实验表明我们的数据和方法在人工评测上更有情感,效果更好。

模型采用典型的encoder-decoder框架,只是在编码的过程中增加情感标签的辅助信息,采用Transformer编解码。

4.2 Generating Responses with a Specific Emotion in Dialog
Zhenqiao Song, Xiaoqing Zheng, Lu Liu, Mu Xu and Xuanjing Huang
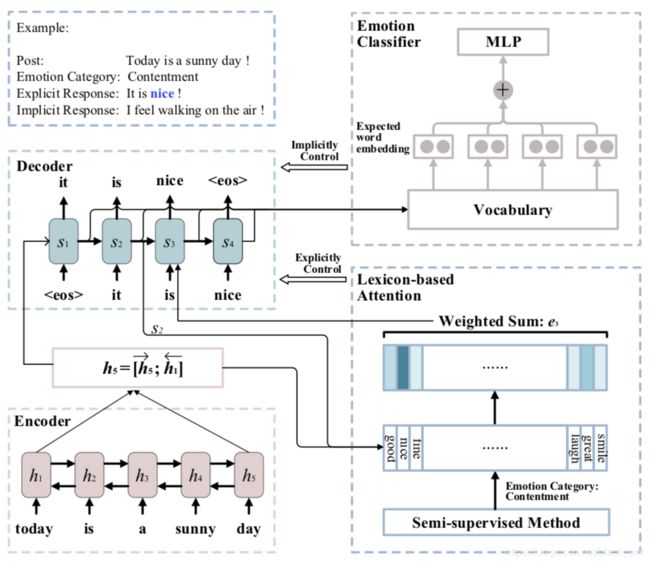
本文来自复旦大学和加州大学Santa Barbara分校。如果对话系统可以表达具体的情感,那么对可用性和用户满意度将会有很大提升,经过调研我们发现,至少有两种方式通过语言来表达情感,一是显式地采用较强的情感词,二是隐式地结合不同中立词来增加情感体验的强度。本文提出一个情感对话系统(EmoDS),一方面可以生成一致的、有意义的回复,另一方面可以显式或隐式地表达情感。实验表明,EmoDS在BLEU、多样性和情感表达质量上均优于baseline。
问题定义:给定输入的post和情感e,生成回复。具体结构如下,左下角利用双向LSTM对post进行编码,右下角利用attention得到当前的情感(显式地),左上角利用LSTM基于编码和情感进行解码生成回复(生成每个词的时候区分普通词和情感词),右上角预测生成回复的情感(仅用于训练过程)。模型的损失函数包括两部分:生成回复的交叉熵损失、情感预测的损失。
实验结果样例如下:
5. 主动对话
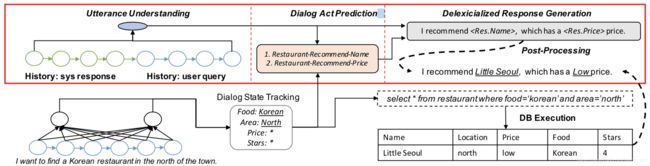
5.1 Proactive Human-Machine Conversation with Explicit Conversation Goals
Wenquan Wu, Zhen Guo, Xiangyang Zhou, Hua Wu, Xiyuan Zhang, Rongzhong Lian and Haifeng Wang
本文来自百度王海峰老师团队。目前人机对话虽然取得了较大进展,但是现有系统往往只是被动地输出回复,本文旨在建立一个可以主动引导对话的机器人,体现在它可以保持当前主题或者引入一个新主题。为了达到这个目标,我们创建了一个新的数据集DuConv,对话角色包括leader和follower,给定对话目标的情况下,leader可以利用知识图谱来有序的保持对话和改变主题,尽可能的保持follower的参与度。DuConv需要模型能够理解对话,并可以基于知识图谱规划对话,该数据集包括30k个对话、270k个句子。数据集和基线系统都已开源。
这个工作也是在今年“知识驱动对话”竞赛中的baseline方法,参加竞赛的同学应该比较熟悉。

检索式模型包括:
(1)Encoder:采用Transformer;
(2)Knowledge Encoder:采用GRU;
(3)Knowledge Reasoner:选择最优的知识;
(4)Matcher:度量输入的编码和选定知识的匹配度。
生成式模型包括:
(1)Utterance Encoder:采用GRU;
(2)Knowledge Encoder:采用GRU;
(3)Knowledge Manager;
(4)Decoder。

实验结果样例如下:

6. 在线学习
6.1 Learning from Dialogue after Deployment: Feed Yourself, Chatbot!
Braden Hancock, Antoine Bordes, Pierre-Emmanuel Mazare
本文来自斯坦福大学和Facebook AI团队。对话机器人的大部分对话都发生在训练和部署之后,这里有很大的提升空间,本文提出了一个自反馈机器人(self-feeding chatbot),它可以在实际应用中提取新的训练样本,在对话进行的过程中,机器人会评估用户对回复的满意度。具体地,当对话看上去正在顺利进行时,用户的的回复就会变成新的训练样本,当机器人认为自己出了错误时,它会询问反馈,并学着去预测反馈。在PERSONACHAT数据集上,实验证明该方法比传统方法好很多。
模型结构如下:
(1)初始训练过程,在两个任务上进行,一是对话任务(它接下来要说什么)、二是满意度任务(用户对回复是否满意),初始的样本标记为Human-Human(HH),它是人与人之间的对话;
(2)部署应用阶段,对于每一轮对话,它都会考虑之前的对话,用以生成接下来的回复,以及满意度分数,如果满意度达到一个特定的门槛,它就会利用之前的对话上下文以及人类的回复来提取训练集(HB);但是如果分数太低,机器人就会提出一个问题来询问人类的反馈,进而使用这一回复来为反馈任务创建一个新的样本。
6.2 Incremental Learning from Scratch for Task-Oriented Dialogue Systems
Weikang Wang, Jiajun Zhang, Qian Li, Mei-Yuh Hwang, Chengqing Zong and Zhifei Li
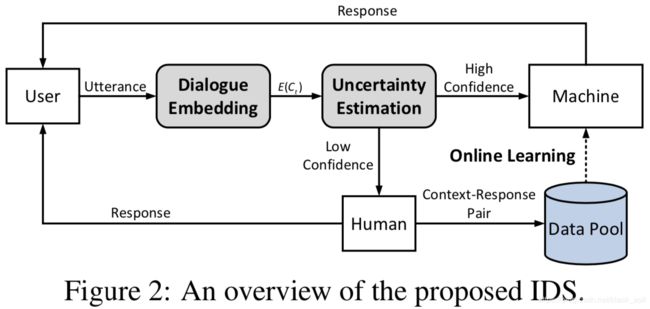
本文来自自动化所和出门问问。澄清用户的需求在现有任务型对话系统中非常重要,然而,在现实场景中,开发者在设计阶段不可能考虑全所有的用户需求,直接导致系统在遇到未考虑的需求时会崩掉。为了解决这个问题,本文提出了一个增量学习框架来设计任务型对话系统IDS,而不需要预先的定义好繁杂的用户需求,具体地,我们引入了一个不确定性估计模块,来评价当前给出正确回复的置信度,如果置信度较高,IDS会把回复返回给用户,反之,用户将会参与到对话过程中,IDS可以通过在线学习模块来学到用户的干预。为了评价我们方法,我们构架了一个新的数据集,它会在部署应用阶段,模拟预料之外的用户需求。实验表明,IDS对未考虑的用户动作具有鲁棒性,可以通过选择最有效的训练数据来在线更新它自己,获得了更好的效果、更少的标注成本。
方法结构如下,包括以下主要部分:
(1)Dialogue Embedding:每个句子利用GRU进行编码,句子的序列采用另外一个GRU进行编码,从而得到context的表示;
(2)Uncertainty Estimation:利用隐变量来建模对话过程;
(3)Online Learning:如果置信度较高,IDS直接返回最大分数的回复,反之,开始人工智能里面的人工。
7. 强化学习
7.1 Budgeted Policy Learning for Task-Oriented Dialogue Systems
Zhirui Zhang, Xiujun Li, Jianfeng Gao and Enhong Chen
本文来自中科大、微软和华盛顿大学。本文基于Deep Dyna-Q(DDQ)提出了一个新的方法,它结合一个预算感知规划(Budget-Conscious Scheduling,BCS)来最大程度地利用固定、有限的用户交互(预算),BSC包括(参考下图):(1)基于泊松的全局规划器,来分配训练过程不同步骤的预算;(2)控制器,来决定每一个训练步骤采用真实的还是模拟的数据;(3)用户目标采样模块,生成对策略学习最有效的经验数据。在电影票预定数据集上的实验表明,我们的方法提升很明显。
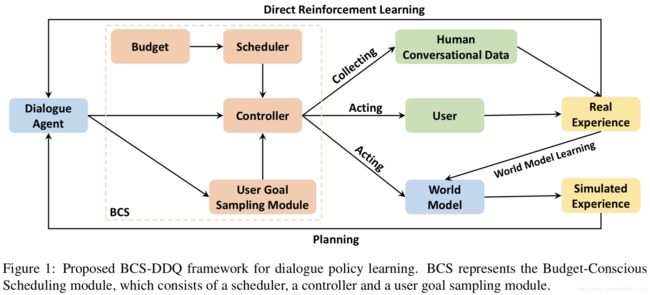
系统结构如下,总共包括6个模块:
(1)NLU:基于LSTM,识别用户意图和提取槽位;
(2)状态跟踪器;
(3)对话策略学习:基于当前状态和数据库结果;
(4)NLG:基于模型;
(5)世界模型:产生模拟的用户行为和奖励;
(6)BCS模块。

8. 迁移学习
8.1 Pretraining Methods for Dialog Context Representation Learning
Shikib Mehri, Evgeniia Razumovskaia, Tiancheng Zhao and Maxine Eskenazi
本文来自CMU。本文关注学习对话上下文表示的无监督预训练目标,提出了两个预训练的对话上下文编码器,总共四个方法,每个预训练目标在下游任务中进行调优和评测,我们发现效果提升明显。实验表明,预训练目标不仅可以提升性能,还可以加快收敛,降低模型对数据的渴求,并且有更好的泛化。
预训练目标包括:next-utterance retrieval(下一句检索,NUR)、next-utterance generation(下一句生成,NUG)、masked-utterance retrieval(掩码句子检索)、inconsistency identification(不一致性检测,InI)
8.2 Transferable Multi-Domain State Generator for Task-Oriented Dialogue Systems
Chien-Sheng Wu, Andrea Madotto, Ehsan Hosseini-Asl, Caiming Xiong, Richard Socher and Pascale Fung
本文来自香港科技大学和Salesforce。对话跟踪任务中,领域本体之间的过度依赖、跨领域间的知识不共享是实际应用中经常遇到的问题,但是却很少被研究,现有方法通常不太擅长跟踪未知的槽位,并且在应用到新领域时往往比较困难。本文提出了一个可迁移的对话生成器(TRADE),它使用拷贝机制来生成对话,方便知识的迁移,模型包括句子编码器、槽位门、状态生成器(不同领域共享)。实验表明我们的模型达到SOTA效果,并且,我们展示了它的迁移能力。
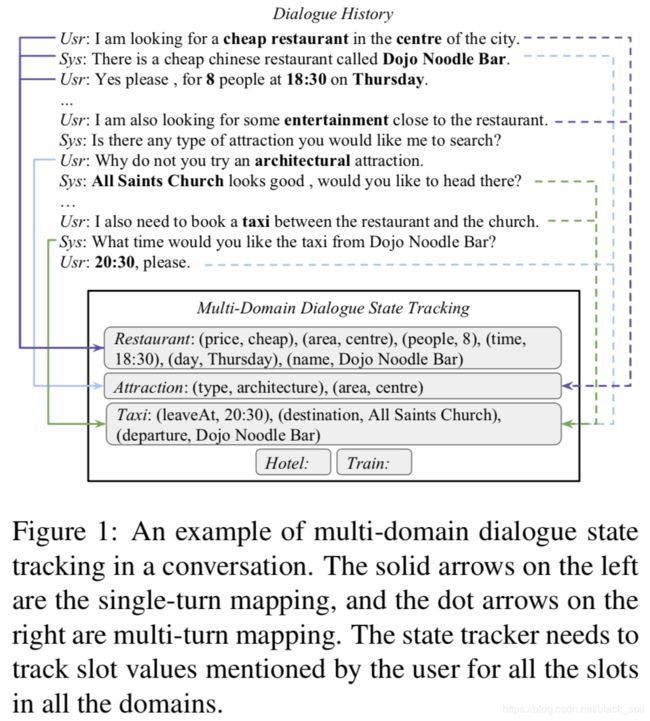
模型结构如下图,包含三个部分:
(1)句子编码器:采用bi-GRU
(2)槽位门
(3)状态生成器:采用GRU

9. 对抗学习
9.1 Retrieval-Enhanced Adversarial Training for Neural Response Generation
Qingfu Zhu, Lei Cui, Wei-Nan Zhang, Furu Wei and Ting Liu
本文来自哈工大和微软。对话模型通常要么是生成式,要么是检索式,相互之间不会相互促进,本文提出了一个检索增强的对抗训练(REAT)方法来进行对话生成,不同于现有方法,该方法基于编码器-解码器框架和对抗学习,并且充分利用了检索式模型得到n-best候选回复信息。实验表明,该方法效果提升明显。
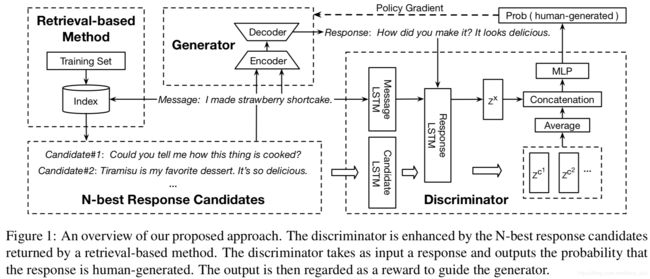
参考
http://www.acl2019.org/EN/program/papers.xhtml
https://blog.csdn.net/y80gdg1/article/details/97621870