整理自keras:https://keras-cn.readthedocs.io/en/latest/other/callbacks/
回调函数Callbacks
回调函数是一个函数的合集,会在训练的阶段中所使用。你可以使用回调函数来查看训练模型的内在状态和统计。你可以传递一个列表的回调函数(作为 callbacks 关键字参数)到 Sequential 或 Model 类型的 .fit() 方法。在训练时,相应的回调函数的方法就会被在各自的阶段被调用。
Callback
keras.callbacks.Callback()
这是回调函数的抽象类,定义新的回调函数必须继承自该类
类属性
params:字典,训练参数集(如信息显示方法verbosity,batch大小,epoch数)
model:keras.models.Model对象,为正在训练的模型的引用
回调函数以字典logs为参数,该字典包含了一系列与当前batch或epoch相关的信息。
目前,模型的.fit()中有下列参数会被记录到logs中:
在每个epoch的结尾处(on_epoch_end),logs将包含训练的正确率和误差,acc和loss,如果指定了验证集,还会包含验证集正确率和误差val_acc)和val_loss,val_acc还额外需要在.compile中启用metrics=['accuracy']。
在每个batch的开始处(on_batch_begin):logs包含size,即当前batch的样本数
在每个batch的结尾处(on_batch_end):logs包含loss,若启用accuracy则还包含acc
ModelCheckpoint
keras.callbacks.ModelCheckpoint(filepath, monitor='val_loss', verbose=0, save_best_only=False, save_weights_only=False, mode='auto', period=1)
该回调函数将在每个epoch后保存模型到filepath
filepath 可以包括命名格式选项,可以由 epoch 的值和 logs 的键(由 on_epoch_end 参数传递)来填充。
参数:
filepath: 字符串,保存模型的路径。
monitor: 被监测的数据。val_acc或这val_loss
verbose: 详细信息模式,0 或者 1 。0为不打印输出信息,1打印
save_best_only: 如果 save_best_only=True, 将只保存在验证集上性能最好的模型
mode: {auto, min, max} 的其中之一。 如果 save_best_only=True,那么是否覆盖保存文件的决定就取决于被监测数据的最大或者最小值。 对于 val_acc,模式就会是 max,而对于 val_loss,模式就需要是 min,等等。 在 auto 模式中,方向会自动从被监测的数据的名字中判断出来。
save_weights_only: 如果 True,那么只有模型的权重会被保存 (model.save_weights(filepath)), 否则的话,整个模型会被保存 (model.save(filepath))。
period: 每个检查点之间的间隔(训练轮数)。
代码实现过程:
① 从keras.callbacks导入ModelCheckpoint类
from keras.callbacks import ModelCheckpoint
② 在训练阶段的model.compile之后加入下列代码实现每一次epoch(period=1)保存最好的参数
checkpoint = ModelCheckpoint(filepath,
monitor='val_loss', save_weights_only=True,verbose=1,save_best_only=True, period=1)
③ 在训练阶段的model.fit之前加载先前保存的参数
if os.path.exists(filepath):
model.load_weights(filepath)
# 若成功加载前面保存的参数,输出下列信息
print("checkpoint_loaded")
④ 在model.fit添加callbacks=[checkpoint]实现回调
model.fit_generator(data_generator_wrap(lines[:num_train], batch_size, input_shape, anchors, num_classes), steps_per_epoch=max(1, num_train//batch_size), validation_data=data_generator_wrap(lines[num_train:], batch_size, input_shape, anchors, num_classes), validation_steps=max(1, num_val//batch_size), epochs=3, initial_epoch=0, callbacks=[checkpoint])
补充知识:keras之多输入多输出(多任务)模型
keras多输入多输出模型,以keras官网的demo为例,分析keras多输入多输出的适用。
主要输入(main_input): 新闻标题本身,即一系列词语。
辅助输入(aux_input): 接受额外的数据,例如新闻标题的发布时间等。
该模型将通过两个损失函数进行监督学习。
较早地在模型中使用主损失函数,是深度学习模型的一个良好正则方法。
完整过程图示如下:
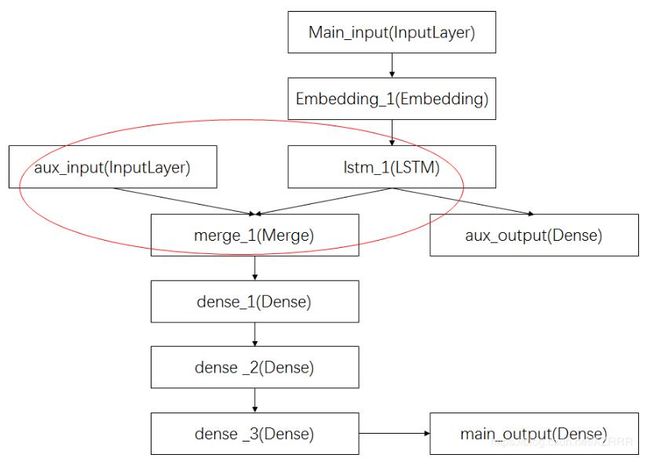
其中,红圈中的操作为将辅助数据与LSTM层的输出连接起来,输入到模型中。
代码实现:
import keras
from keras.layers import Input, Embedding, LSTM, Dense
from keras.models import Model
# 定义网络模型
# 标题输入:接收一个含有 100 个整数的序列,每个整数在 1 到 10000 之间
# 注意我们可以通过传递一个 `name` 参数来命名任何层
main_input = Input(shape=(100,), dtype='int32', name='main_input')
# Embedding 层将输入序列编码为一个稠密向量的序列,每个向量维度为 512
x = Embedding(output_dim=512, input_dim=10000, input_length=100)(main_input)
# LSTM 层把向量序列转换成单个向量,它包含整个序列的上下文信息
lstm_out = LSTM(32)(x)
# 在这里我们添加辅助损失,使得即使在模型主损失很高的情况下,LSTM层和Embedding层都能被平稳地训练
auxiliary_output = Dense(1, activation='sigmoid', name='aux_output')(lstm_out)
# 此时,我们将辅助输入数据与LSTM层的输出连接起来,输入到模型中
auxiliary_input = Input(shape=(5,), name='aux_input')
x = keras.layers.concatenate([lstm_out, auxiliary_output])
# 再添加剩余的层
# 堆叠多个全连接网络层
x = Dense(64, activation='relu')(x)
x = Dense(64, activation='relu')(x)
x = Dense(64, activation='relu')(x)
# 最后添加主要的逻辑回归层
main_output = Dense(1, activation='sigmoid', name='main_output')(x)
# 定义这个具有两个输入和输出的模型
model = Model(inputs=[main_input, auxiliary_input], outputs=[main_output, auxiliary_output])
# 编译模型时候分配损失函数权重:编译模型的时候,给 辅助损失 分配一个0.2的权重
model.compile(optimizer='rmsprop', loss='binary_crossentropy', loss_weights=[1., 0.2])
# 训练模型:我们可以通过传递输入数组和目标数组的列表来训练模型
model.fit([headline_data, additional_data], [labels, labels], epochs=50, batch_size=32)
# 另外一种利用字典的编译、训练方式
# 由于输入和输出均被命名了(在定义时传递了一个 name 参数),我们也可以通过以下方式编译模型
model.compile(optimizer='rmsprop',
loss={'main_output': 'binary_crossentropy', 'aux_output': 'binary_crossentropy'},
loss_weights={'main_output': 1., 'aux_output': 0.2})
# 然后使用以下方式训练:
model.fit({'main_input': headline_data, 'aux_input': additional_data},
{'main_output': labels, 'aux_output': labels},
epochs=50, batch_size=32)
相关参考:https://keras.io/zh/getting-started/functional-api-guide/
以上这篇keras 回调函数Callbacks 断点ModelCheckpoint教程就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持脚本之家。