Python 随机森林6大参数调优(学习曲线与网格搜索)
关注微信公共号:小程在线
关注CSDN博客:程志伟的博客
主要从影响随机森林的参数入手调整随机森立的预测程度:

Python 3.7.3 (default, Apr 24 2019, 15:29:51) [MSC v.1915 64 bit (AMD64)]
Type "copyright", "credits" or "license" for more information.
IPython 7.6.1 -- An enhanced Interactive Python.
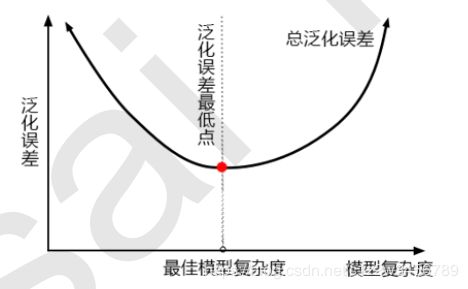
对树模型来说,树越茂盛,深度越深,枝叶越多,模型就越复杂。所以树模型是天生位于图的右上角的模型,随机森林是以树模型为基础,所以随机森林也是天生复杂度高的模型。随机森林的参数,都是向着一个目标去:减少模型的复杂度,把模型往图像的左边移动,防止过拟合。当然了,调参没有绝对,也有天生处于图像左边的随机森林,所以调参之前,我们要先判断,模型现在究竟处于图像的哪一边。
1)模型太复杂或者太简单,都会让泛化误差高,我们追求的是位于中间的平衡点
2)模型太复杂就会过拟合,模型太简单就会欠拟合
3)对树模型和树的集成模型来说,树的深度越深,枝叶越多,模型越复杂
4)树模型和树的集成模型的目标,都是减少模型复杂度,把模型往图像的左边移动
1. 导入需要的库
from sklearn.datasets import load_breast_cancer
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import cross_val_score
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
2. 导入数据集,探索数据
data = load_breast_cancer()
data.data.shape
Out[2]: (569, 30)
data.target
Out[3]:
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0,
......
1, 1, 1, 1, 1, 0, 1, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 1])
3. 进行一次简单的建模,看看模型本身在数据集上的效果
rfc = RandomForestClassifier(n_estimators=100,random_state=90)
score_pre = cross_val_score(rfc,data.data,data.target,cv=10).mean()
score_pre
Out[4]: 0.9666925935528475
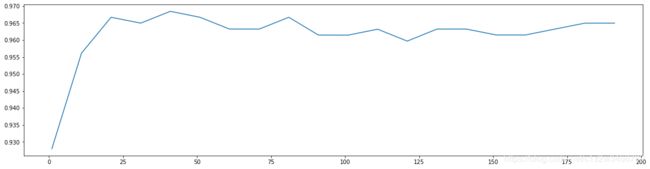
4. 随机森林调整的第一步:无论如何先来调n_estimators,以10为分隔点
scorel = []
for i in range(0,200,10):
rfc = RandomForestClassifier(n_estimators=i+1,
n_jobs=-1,
random_state=90)
score = cross_val_score(rfc,data.data,data.target,cv=10).mean()
scorel.append(score)
print(max(scorel),(scorel.index(max(scorel))*10)+1)
plt.figure(figsize=[20,5])
plt.plot(range(1,201,10),scorel)
plt.show()
0.9684480598046841 41
5. 根据上面的显示最优点在41附近,进一步细化学习曲线
scorel = []
for i in range(35,45):
rfc = RandomForestClassifier(n_estimators=i,
n_jobs=-1,
random_state=90)
score = cross_val_score(rfc,data.data,data.target,cv=10).mean()
scorel.append(score)
print(max(scorel),([*range(35,45)][scorel.index(max(scorel))]))
plt.figure(figsize=[20,5])
plt.plot(range(35,45),scorel)
plt.show()
0.9719568317345088 39
调整n_estimators的效果显著,模型的准确率立刻上升了0.005
我们将使用网格搜索对参数一个个进行调整
7. 调整max_depth
param_grid = {'max_depth':np.arange(1, 20, 1)}
# 一般根据数据的大小来进行一个试探,乳腺癌数据很小,所以可以采用1~10,或者1~20这样的试探
# 但对于像digit recognition那样的大型数据来说,我们应该尝试30~50层深度(或许还不足够
# 更应该画出学习曲线,来观察深度对模型的影响
rfc = RandomForestClassifier(n_estimators=39
,random_state=90
)
GS = GridSearchCV(rfc,param_grid,cv=10)
GS.fit(data.data,data.target)
H:\Anaconda3\lib\site-packages\sklearn\model_selection\_search.py:813: DeprecationWarning: The default of the `iid` parameter will change from True to False in version 0.22 and will be removed in 0.24. This will change numeric results when test-set sizes are unequal.
DeprecationWarning)
Out[7]:
GridSearchCV(cv=10, error_score='raise-deprecating',
estimator=RandomForestClassifier(bootstrap=True, class_weight=None,
criterion='gini', max_depth=None,
max_features='auto',
max_leaf_nodes=None,
min_impurity_decrease=0.0,
min_impurity_split=None,
min_samples_leaf=1,
min_samples_split=2,
min_weight_fraction_leaf=0.0,
n_estimators=39, n_jobs=None,
oob_score=False, random_state=90,
verbose=0, warm_start=False),
iid='warn', n_jobs=None,
param_grid={'max_depth': array([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17,
18, 19])},
pre_dispatch='2*n_jobs', refit=True, return_train_score=False,
scoring=None, verbose=0)
GS.best_params_
Out[8]: {'max_depth': 11}
GS.best_score_
Out[9]: 0.9718804920913884
将max_depth设置为有限之后,模型的准确率下降了。限制max_depth,是让模型变得简单,把模型向左推,而模型整体的准确率下降了,即整体的泛化误差上升了,这说明模型现在位于图像左边,即泛化误差最低点的左边(偏差为主导的一边)
当模型位于图像左边时,我们需要的是增加模型复杂度(增加方差,减少偏差)的选项,因此max_depth应该尽量
大,min_samples_leaf和min_samples_split都应该尽量小。这几乎是在说明,除了max_features,我们没有任何
参数可以调整了,因为max_depth,min_samples_leaf和min_samples_split是剪枝参数,是减小复杂度的参数。
在这里,我们可以预言,我们已经非常接近模型的上限,模型很可能没有办法再进步了。
8. 调整max_features
param_grid = {'max_features':np.arange(5,30,1)}
rfc = RandomForestClassifier(n_estimators=39
,random_state=90
)
GS = GridSearchCV(rfc,param_grid,cv=10)
GS.fit(data.data,data.target)
H:\Anaconda3\lib\site-packages\sklearn\model_selection\_search.py:813: DeprecationWarning: The default of the `iid` parameter will change from True to False in version 0.22 and will be removed in 0.24. This will change numeric results when test-set sizes are unequal.
DeprecationWarning)
Out[11]:
GridSearchCV(cv=10, error_score='raise-deprecating',
estimator=RandomForestClassifier(bootstrap=True, class_weight=None,
criterion='gini', max_depth=None,
max_features='auto',
max_leaf_nodes=None,
min_impurity_decrease=0.0,
min_impurity_split=None,
min_samples_leaf=1,
min_samples_split=2,
min_weight_fraction_leaf=0.0,
n_estimators=39, n_jobs=None,
oob_score=False, random_state=90,
verbose=0, warm_start=False),
iid='warn', n_jobs=None,
param_grid={'max_features': array([ 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21,
22, 23, 24, 25, 26, 27, 28, 29])},
pre_dispatch='2*n_jobs', refit=True, return_train_score=False,
scoring=None, verbose=0)
GS.best_params_
Out[12]: {'max_features': 5}
GS.best_score_
Out[13]: 0.9718804920913884
网格搜索返回了max_features的最小值,可见max_features升高之后,模型的准确率降低了。这说明,我们把模
型往右推,模型的泛化误差增加了。前面用max_depth往左推,现在用max_features往右推,泛化误差都增加,
这说明模型本身已经处于泛化误差最低点,已经达到了模型的预测上限,没有参数可以左右的部分了
9. 调整min_samples_leaf
param_grid={'min_samples_leaf':np.arange(1, 1+10, 1)}
#对于min_samples_split和min_samples_leaf,一般是从他们的最小值开始向上增加10或20
#面对高维度高样本量数据,如果不放心,也可以直接+50,对于大型数据,可能需要200~300的范围
#如果调整的时候发现准确率无论如何都上不来,那可以放心大胆调一个很大的数据,大力限制模型的复杂度
rfc = RandomForestClassifier(n_estimators=39
,random_state=90
)
GS = GridSearchCV(rfc,param_grid,cv=10)
GS.fit(data.data,data.target)
H:\Anaconda3\lib\site-packages\sklearn\model_selection\_search.py:813: DeprecationWarning: The default of the `iid` parameter will change from True to False in version 0.22 and will be removed in 0.24. This will change numeric results when test-set sizes are unequal.
DeprecationWarning)
Out[14]:
GridSearchCV(cv=10, error_score='raise-deprecating',
estimator=RandomForestClassifier(bootstrap=True, class_weight=None,
criterion='gini', max_depth=None,
max_features='auto',
max_leaf_nodes=None,
min_impurity_decrease=0.0,
min_impurity_split=None,
min_samples_leaf=1,
min_samples_split=2,
min_weight_fraction_leaf=0.0,
n_estimators=39, n_jobs=None,
oob_score=False, random_state=90,
verbose=0, warm_start=False),
iid='warn', n_jobs=None,
param_grid={'min_samples_leaf': array([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10])},
pre_dispatch='2*n_jobs', refit=True, return_train_score=False,
scoring=None, verbose=0)
GS.best_params_
Out[15]: {'min_samples_leaf': 1}
GS.best_score_
Out[16]: 0.9718804920913884
10.调整min_samples_split
param_grid={'min_samples_split':np.arange(2, 2+20, 1)}
rfc = RandomForestClassifier(n_estimators=39
,random_state=90
)
GS = GridSearchCV(rfc,param_grid,cv=10)
GS.fit(data.data,data.target)
H:\Anaconda3\lib\site-packages\sklearn\model_selection\_search.py:813: DeprecationWarning: The default of the `iid` parameter will change from True to False in version 0.22 and will be removed in 0.24. This will change numeric results when test-set sizes are unequal.
DeprecationWarning)
Out[18]:
GridSearchCV(cv=10, error_score='raise-deprecating',
estimator=RandomForestClassifier(bootstrap=True, class_weight=None,
criterion='gini', max_depth=None,
max_features='auto',
max_leaf_nodes=None,
min_impurity_decrease=0.0,
min_impurity_split=None,
min_samples_leaf=1,
min_samples_split=2,
min_weight_fraction_leaf=0.0,
n_estimators=39, n_jobs=None,
oob_score=False, random_state=90,
verbose=0, warm_start=False),
iid='warn', n_jobs=None,
param_grid={'min_samples_split': array([ 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18,
19, 20, 21])},
pre_dispatch='2*n_jobs', refit=True, return_train_score=False,
scoring=None, verbose=0)
GS.best_params_
Out[19]: {'min_samples_split': 2}
GS.best_score_
Out[20]: 0.9718804920913884
11. 调整criterion
param_grid = {'criterion':['gini', 'entropy']}
rfc = RandomForestClassifier(n_estimators=39
,random_state=90
)
GS = GridSearchCV(rfc,param_grid,cv=10)
GS.fit(data.data,data.target)
Out[21]:
GridSearchCV(cv=10, error_score='raise-deprecating',
estimator=RandomForestClassifier(bootstrap=True, class_weight=None,
criterion='gini', max_depth=None,
max_features='auto',
max_leaf_nodes=None,
min_impurity_decrease=0.0,
min_impurity_split=None,
min_samples_leaf=1,
min_samples_split=2,
min_weight_fraction_leaf=0.0,
n_estimators=39, n_jobs=None,
oob_score=False, random_state=90,
verbose=0, warm_start=False),
iid='warn', n_jobs=None,
param_grid={'criterion': ['gini', 'entropy']},
pre_dispatch='2*n_jobs', refit=True, return_train_score=False,
scoring=None, verbose=0)
GS.best_params_
Out[22]: {'criterion': 'gini'}
GS.best_score_
Out[23]: 0.9718804920913884
12. 调整完毕,总结出模型的最佳参数
rfc = RandomForestClassifier(n_estimators=39,random_state=90)
score = cross_val_score(rfc,data.data,data.target,cv=10).mean()
score
Out[24]: 0.9719568317345088
13.数据的提升程度
score - score_pre
Out[25]: 0.005264238181661218