《HTTP权威指南》学习笔记
HTTP权威指南学习笔记
第一部分 HTTP:WEB的基础
第一章 HTTP概述
媒体类型
http给每种要通过web传输的对象都打上了名为MIME(Multipurpose Internet Mail Extension,多用途因特网邮件扩展)类型的数据格式标签。
Web服务器会为所有HTTP对象数据附加一个MIME类型。当Web浏览器从服务器中取回一个对象时,回去查看相关的MIME类型,看看它是否知道应该如何处理这个对象。
MIME类型是一种文本标记,表示一种主要的对象类型和一个特定的子类型,中间由斜杠来分隔。
1、HTML格式的文本文档由 text/html 类型来标记
2、普通的ASCII文本文档由 text/plain 类型来标记
3、JPEG版本的图片为 image/jpeg 类型
4、GIF格式的图片为 image/gif类型
5、Apple的QuickTime电影为 video/quidktime 类型
6、微软的PowerPoint演示文件为 application/vnd.ms-powerpoint 类型
URI
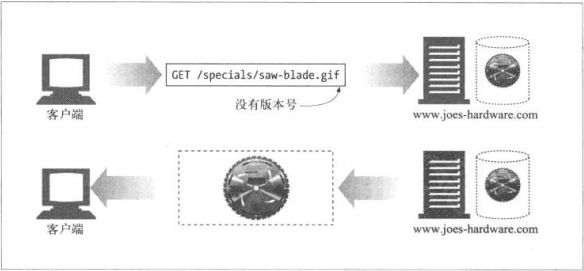
服务器资源名被称为统一资源标识符(Uniform Resource Identifier,URI).URI就像因特网上的邮政地址一样,在世界范围内唯一标识并定位信息资源。
例如一个图片资源的URI:
http://www.baidu.com/specials/sky.gif
当给定了URI,HTTP就可以解析出对象。URI有两种形式,分别称为URL和URN。
URL
统一资源定位符(URL)是资源标识符最常见形式。它描述了一台特定服务器上的某资源的特定位置。
URL说明了协议、服务器和本地资源。如下图:

URL实例:

大部分的URL都遵循一种标准格式,这种格式包含三个部分:、
①方案(scheme),说明了访问资源所使用的协议类型。这部分通常是HTTP协议(http://)
②给出服务器的因特网地址(www.baidu.com)
③其余部分指定了WEB服务器上的某个资源(/specials/sky.gif)
现在,几乎所有的URI都是URL。
URN
URI的第二种形式就是URN(统一资源名)。URN是作为特定内容的唯一名称使用的,与目前的资源所在地无关。使用这些与位置无关的URN,就可以将资源四处搬移。通过URN,还可以用同一个名字通过多种网络访问协议来访问资源。
例如:RFC 2141 无论在何处,甚至可以复制到多个地方,都可以用以下URN来命名:
urn:ietf:rfc:2141
URN仍处于试验阶段。
*事务*
一个HTTP事务由一条请求命令和一个响应结果组成。这种通信是通过名为HTTP报文的格式化数据块进行的。
方法
HTTP支持几种不同的请求命令,这些命令被称为HTTP方法(HTTP method)。
常见的HTTP方法:
GET—-从服务器向客户的发送命名资源
PUT—-将来自客户的的数据存储到一个命名的服务器资源中去
DELETE—-从服务器中删除命名资源
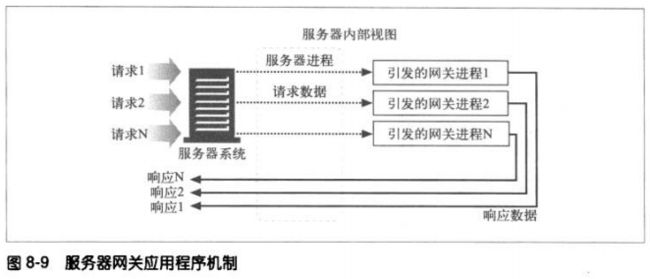
POST—-将客户端数据发送到一个服务器网关应用程序
HEAD—-仅发送命名资源响应中的HTTP首部
状态码
每条HTTP响应报文返回时都会携带一个状态码。状态码是一个三位数字的代码,告知客户端请求是否成功,或者是否需要采取其他动作。
常见状态码:
200—-OK,文档返回正确
302—-Redirect,重定向,到其他地方获取资源
404—-Not Found,无法找到这个资源
WEB页面中可以包含多个对象
一个WEB页面是一组资源的集合。web浏览器会发布一系列HTTP事务来获取并显示一个包含了丰富资源的页面。
*报文*
HTTP报文是由一行一行的简单字符串组成。它是纯文本,并非二进制代码。
HTTP报文包含以下三个部分:
1、起始行
报文的第一行,在请求报文中用来说明要做些什么。在响应报文中说明出现了什么情况。
2、首部字段
起始行后面有零个或者多个首部字段。每个字段都包含一个名字和一个值,为了便于解析,两者之间用冒号(:)分隔。首部以一个空行结束。
3、主体
空行之后就是可选的报文主体了,其中包含了所有类型的数据。请求主体中包括了要发送个web服务器的数据;响应主体中装载了要返回给客户端的数据。起始行和首部都是文本形式且都是结构化的,而主体则不同,主体可以包含任意的二进制数据和文本。
*连接*
TCP/IP
HTTP是个应用层协议,联网的细节都交给了TCP/IP协议。
TCP提供:
无差错的数据传输;按序传输;未分段的数据流(可以在任意时刻以任意尺寸将数据发送出去)
连接、IP地址及端口号
在HTTP客户端向服务器发送报文之前,需要用网际协议(Internet Protocol,IP)地址和端口号在客户端与服务器之间建立一条TCP/IP 连接。
协议版本
HTTP/0.9
HTTP的1991原型版本。仅支持GET方法,不支持多媒体内容的MIME类型、各种HTTP首部,或者版本号。
HTTP/1.0
1.0是第一个得到广泛使用的HTTP版本。HTTP/1.0添加了版本号、各种HTTP首部、一些额外的方法以及对多媒体对象的处理。
HTTP/1.0+
由很多流行的web客户端和服务器向HTTP中添加各种特性,包括keep-alive连接、虚拟主机支持、以及代理连接支持等,称为非官方的事实标准。这种的HTTP扩展版本通常称为HTTP/1.0+
HTTP/1.1
这个版本重点关注的是校正HTTP设计中的结构性缺陷,明确语义,引入重要的性能优化措施,并删除一些不好的特性。它还包含了对20世纪90年代末正在发展中的更复杂的WEB应用程序和部署方式的支持。它也是当前使用的版本。
HTTP-NG(HTTP/2.0)
是HTTP/1.1后继结构的原型建议,它重点关注的是性能的大幅优化以及更强大的服务逻辑远程执行框架。它的研究工作终止于1998年。
*WEB的结构组件*
代理
代理位于客户端和服务器之间,接收所有客户端的HTTP请求,并将这些请求转发给服务器(可能会对请求进行修改之后转发)。
缓存
WEB缓存(cache)或代理缓存是一种特殊的HTTP代理服务器,可将经过代理传送的常用文档复制保存起来。下一个请求同一文档的客户端就可以享受缓存的私有副本所提供的服务了。
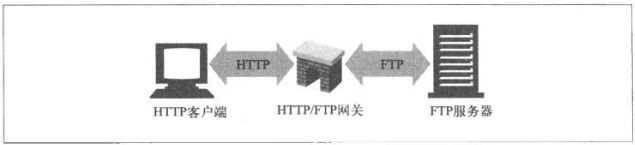
网关
网关(gateway)是一种特殊的服务器,作为其他服务器的中间实体使用。通常用于将HTTP流量转换成其他的协议。网关接受请求时就好像自己是资源的源端服务器一样,客户端可能并不知道自己在与一个网关进行通信。
隧道
隧道(tunnel)是建立起来之后,就会在两条连接之间对原始数据进行盲转发的HTTP应用程序。通常用来在一条或多条HTTP连接上转发非HTTP数据,转发时不会窥探数据。
HTTP隧道一种常见用途是通过HTTP连接承载加密的安全套接字层(SSL,Secure Sockets Layer)流量。这样SSL流量就可以穿过只允许WEB流量通过的防火墙了。
Agent代理
Agent代理是代表用户发起HTTP请求的客户端程序。所有发布WEB请求的应用程序都是HTTP Agent代理。web浏览器。
第二章 URL与资源
浏览因特网资源
URL 可以通过HTTP之外的其他协议来访问资源。它们可以指向因特网上的任意资源。比如个人邮箱账户。或者其他协议FTP、或者从流视频服务器下载电影
rtsp://www.xxxx.com:554/cto_video
URL的语法
大多数URL方案的URL语法都建立在这个由9部分构成的通用格式上:
://:@:/;?#

方案
实际上是规定如何访问指定资源的主要标识符,它会告诉负责解析URL的应用程序应该使用什么协议。方案组件必须以一个字母符号开始,由第一个“:”符号将其与URL的其余部分分隔开来,大小写无关。
主机与端口
主机组件标识了因特网上能够访问资源的宿主机器。可以用主机名或者IP地址来表示。端口组件标识了服务器正在监听的网络端口。
用户名和密码
常见的如FTP服务器需要用户名和密码才允许用户访问。

如果某应用程序使用的URL方案要求用户输入用户名和密码,比如FTP,但是用户并未提供,它通常会插入一个默认的用户名和密码。比如FTP,会插入anonymous(匿名用户)作为你的用户名,并发送一个默认密码(IE会发送IEUser,Netscapegoat Navigator则会发送mozilla)。
路径
路径组件说明了资源位于服务器的什么地方,路径通常很像一个分级的文件系统路径。可以用“/”将HTTP URL 的路径组件划分成一些路径段(path segment),每个路径段都有自己的参数(param)组件。
参数
参数组件就是URL中的键值对列表,有字符“:”将其与URL的其他部分(以及各键值对)分隔开来,它们为应用程序提供了访问资源所需的所有附加信息。
ftp://prep.ai.mit.edu/pub/gnu;type=d
http://www.joes-hardware.com/hammers;sale=false/index.html;graphics=true
查询字符串
比如数据库服务,可以通过提问题或者进行查询来缩小所请求资源类型范围。
http://www.joes-hardware.com/inventory-check.cgi?item=12731
“?”右边的内容称为查询组件,它和标识网关资源的URL路径组件一起被发送给网关资源,基本上可以将网关当做访问其他应用程序的访问点。
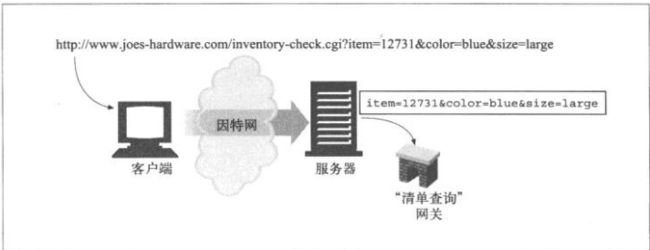
按照常规,很多网关都希望查询字符串以一系列“键/值”对的形式出现,键值对之间用“&”分隔。
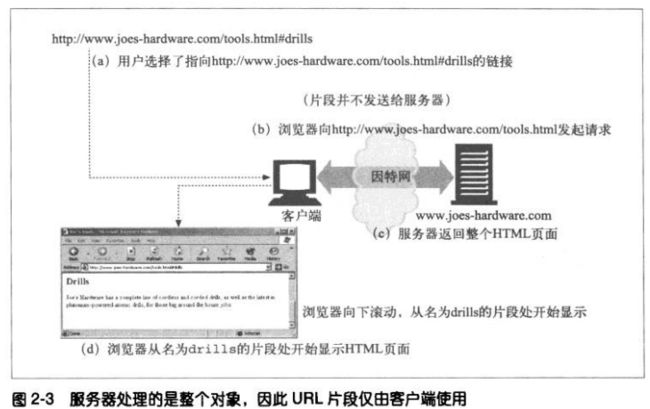
片段
有些资源类型,比如HTML,除了资源级之外,还可以做进一步的划分。比如一个带章节的大型文本文档,资源的URL会指向整个文档,但是理想情况是能够指向资源中那些章节。
为了引用部分资源或者资源的一部分,URL支持使用片段(frag)组件来表示一个资源内部的片段。比如:http://www.xxxx.com/tools.html#drills
HTTP服务器通常只处理整个对象,而不是对象的片段,客户端不能将片段传送给服务器。浏览器从服务器获取了整个资源后,会根据片段来显示感兴趣的那部分资源。
URL快捷方式
WEB客户端可以理解并使用集中URL快捷方式。相对URL是在某资源内部指定一个资源的便捷缩略方式。很多浏览器还支持URL 的“自动扩展”。
相对URL
相对URL是不完整的,要从相对URL中获取访问资源所需的全部信息,就必须相对于另一个,被称为基础的URL进行解析。相对URL是URL的一种便捷缩略记法。
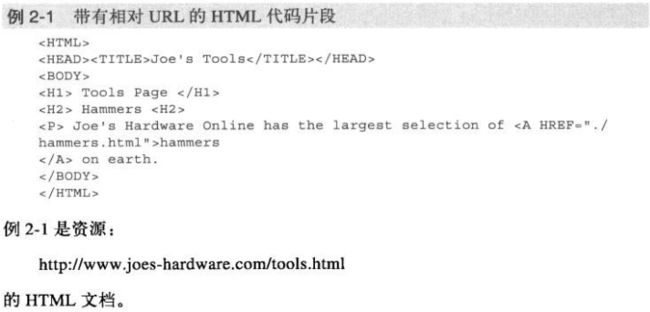
上图中的./hammers.html其实是个合法的相对URL,可以相对于它所在文档的URL对其进行解析,本例中就是/tools.html

相对URL只是URL的片段或是一小部分,处理URL的应用程序(浏览器)要能在两者之间进行转换。
需要注意,相对URL为保持一组资源的便携性提供了一种便捷方式。如果使用相对URL,就可以在搬移一组文档的同时,仍然保持链接的有效性,因为相对URL是相对于新基础进行解析的,这样就能实现在其他服务器上提供镜像之类的功能了。
1、基础URL
转换处理的第一步就是找到基础URL,基础URL 作为参考点可以来自以下几个不同的地方:
①在资源中显示提供
有些资源会显式的指定基础URL,比如,HTML文档中可能包含一个定义了基础 URL的HTML标记,通过它来转换那个文档中所有的相对URL。
②封装资源的基础URL
如果在一个没有显式指定基础URL的资源中发现了一个相对URL,如上例,可以将它所属资源的URL作为基础。
③没有基础URL
某些情况下,没有基础URL,这通常意味着你有一个相对URL,但有时可能只是一个不完整或损坏了的URL。
2、解析相对引用
要将相对URL转换为一个绝对URL,下一步就是将相对URL和基础URL划分成组件段。
实际上,这样只是在解析URL,但这种做法会将其划分成一个个组件,因此通常会称作分解(decomposing)URL。只要将基础和相对URL划分成了组件,就可以用如下的算法完成转换。
自动扩展URL
也就是常见的自动补全URL。
有两种方式:
1、主机名扩展
在主机名扩展中,只要有些小提示,浏览器通常就可以在没有帮助的情况下将你输入的主机名扩展为完整的主机名。比如输入yahoo,浏览器自动构建出www.yahoo.com
但是,这些主机名扩展技巧可能会为其他一些HTTP应用程序带来问题,比如代理。
2、历史扩展
将输入的URL与历史记录中URL的前缀进行匹配,并提供一些完整的选项。
各种令人头疼的字符
URL是可移植的(portable)。
URL字符集
默认是US-ASCII字符集。有些URL会包含任意的二进制数据。因此加入了转义序列,通过转义序列,就可用US-ASCII字符集的有限子集对任意字符值或数据进行编码了。
编码机制
转义法—-包含一个百分号(%),后面跟两个表示字符的ASCII码的十六进制数。
例如:

字符限制
在URL中,有几个字符被保留起来有着特殊的含义。有些字符不在定义的US-ASCII可打印字符集中。还有些字符会与某些因特网网关和协议产生混淆,因此不赞成使用。

方案的世界


HTTP报文
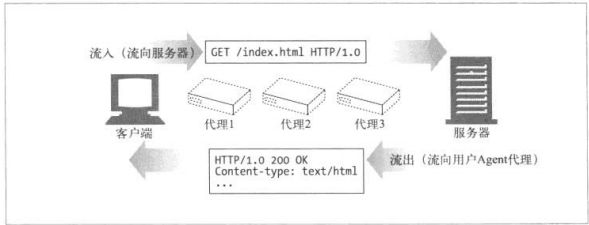
HTTP报文是在HTTP应用程序之间发送的数据块。这些数据块以一些文本形式的元信息(meta-information)开头,这些信息描述了报文的内容以及含义。
HTTP使用术语流入(inbound)和流出(outbound)来描述事务处理(transaction)的方向。报文流入源端服务器,工作完成后,会流回用户的Agent代理中。如下图:
报文的组成部分
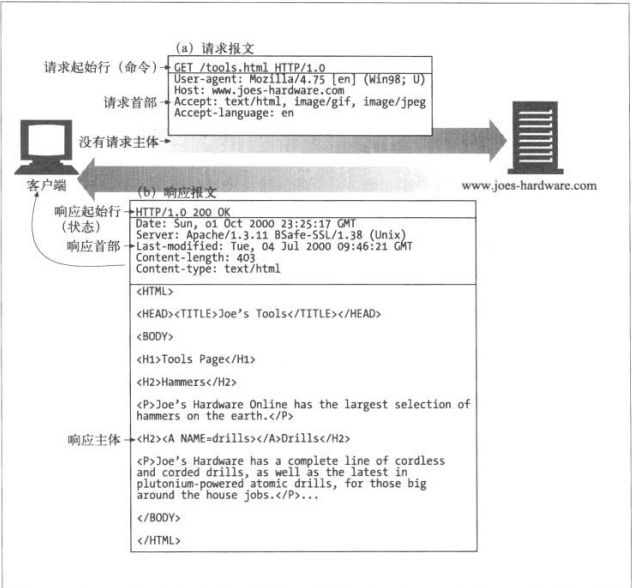
HTTP报文是简单的格式化数据块。每条报文都包含一条来自客户端的请求,或者一条来自服务器的响应。由三个部分组成:对报文描述的起始行(start line)、包含属性的首部(header)块,以及可选的、包含数据的主体(body)部分。
起始行和首部就是由行分隔的ASCII文本。每行都以一个由两个字符组成的行终止符作为结束,其中包括一个回车符和换行符。这个行终止序列可以写作CRLF。报文的主体是一个可选的数据块。与起始行和首部不同的是,主体中可以包含文本或二进制数据,也可以为空。
报文的语法
所有的HTTP报文都可以分为:请求报文(request message)和响应报文(response message)。请求报文会向WEB服务器请求一个动作。响应报文会将请求的结果返回给客户端。

各部分的简要描述:
1、方法(method)
客户端希望服务器对资源执行的动作,是一个单独的单词。
2、请求URL
命名了所请求的资源,或者URL路径组件的完整URL。
3、版本
报文所使用的HTTP版本
HTTP/.
主要版本号 次要版本号 都是整数。
4、状态码
这三位数字描述了请求过程中所发生的情况。每个状态码的第一位数字都用于描述状态的一般类别(成功、出错等)
5、原因短语(reason-phrase)
数字状态码的可读版本,包含行终止序列之前的所有文本。
6、首部
可以有零个或多个首部,每个首部都包含一个名字,后面跟着一个冒号(:),然后是一个可选的空格,接着是一个
值,最后是一个CRLF。首部是由一个空行(CRLF)结束的,表示了首部列表的结束和报文主体部分的开始。
7、实体的主体部分(entity-body)
这个部分包含一个由任意数据组成的数据块。
起始行
1、请求行
请求报文请求服务器对资源进行一些操作。请求报文的起始行或称为请求行,包含了一个方法和一个请求URL,还包含
了HTTP的版本,用来告知服务器,客户端使用的是哪种HTTP。
2、响应行
响应报文承载了状态信息和操作产生的所有结果数据,将其返回个客户端。它的起始行或称为响应行,包含了响应报
文使用的HTTP版本、数字状态码、以及描述操作状态的文本形式的原因短语。
3、方法
请求的起始行以方法作为开始,方法用来告知服务器要做些什么。

除了这些方法,其他服务器可能还会实现一些自己的请求方法,这些附加的方法是对HTTP规范的扩展,因此被称作扩
展方法。
4、状态码
状态码用来告知客户端,发生了什么事情。它位于响应的起始行中。通过三位数字代码对不同状态码进行分类。200
到299之间的状态码表示成功,300到399之间的表示资源已经被移走。400到499之间的表示客户端的请求出错了。
500到599之间的表示服务器出错了。

5、原因短语
原因短语是响应起始行中的最后一个组件。它为状态码提供了文本形式的解释。比如 HTTP/1.0 200 OK 中的OK 就是
原因短语。
6、版本号
使用版本号的目的是为使用HTTP的应用程序提供线索,以便互相了解对方的能力和报文格式。
首部
1、首部分类
通用首部–既可以出现在请求报文中,也可以出现在响应报文中。
请求首部
响应首部
实体首部–描述主体的长度和内容,或者资源自身。
扩展首部–规范中未定义的。

2、首部延续行
将长的首部行分为多行可以提高可读性,多出来的每行前面至少要有一个空格或制表符(tab)
例如:
HTTP/1.0 200 OK
Content-Type: image/gif
Content-Length: 8572
Server: Test Server
Version 1.0
这个例子中,响应报文里的server首部,其完整的值为: Test Server Version 1.0
版本0.9的报文
该报文也由请求和响应组成,但请求中只包含方法和请求URL,响应中只包含实体。他没有版本信息、状态码、原因短
语,也没有首部。
方法
安全方法
HTTP定义了一组被称为安全方法的方法。GET方法和HEAD方法都被认为是安全的。意味着使用GET和HEAD的HTTP请求都不会产生什么动作。不产生动作就意味着HTTP请求不会在服务器上产生什么结果。
GET
用于请求服务器发送某个资源
HEAD
与GET类似,但服务器在响应中只返回首部。不返回实体的主体部分。可以在不获取资源的情况下了解资源的情况;通过查看响应中的状态码,看看某个对象是否存在;测试资源是否被修改了。
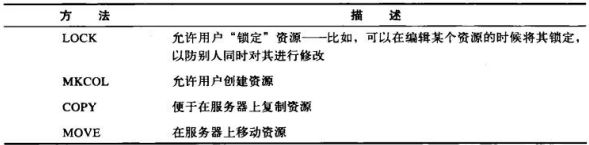
PUT
向服务器写入文档,有些发布系统允许用户创建WEB页面,并用PUT直接将其安装的WEB服务器上。
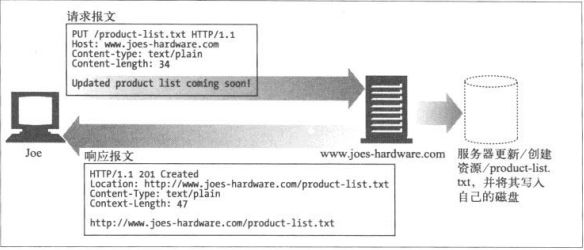
PUT方法的语义就是让服务器用请求的主体部分来创建一个由所请求的URL命名的新文档,如果那个URL存在的话,就用这个主体来替代它。
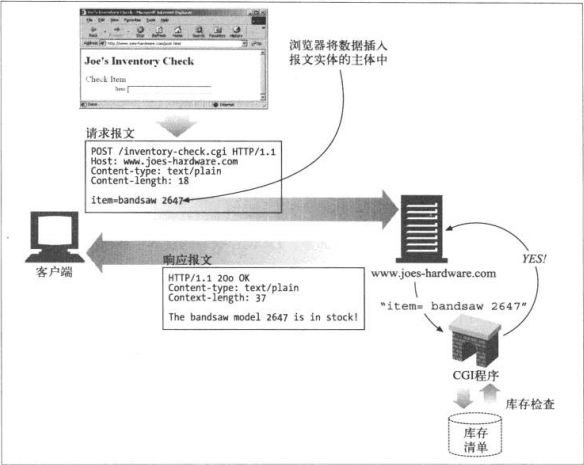
POST
该方法起初用来向服务器输入数据。实际上通常用来支持HTML的表单。
TRACE
客户端发起一个请求时,这个请求可能要穿过防火墙、代理、网关或其他应用程序。每个中间节点都可能修改原始的HTTP请求。TRACE方法允许客户端在最终请求发送给服务器时,看它变成了什么样子。 TRACE请求会在目的服务器端发起一个”环回“诊断。行程最后一站的服务器会弹回一条TRACE响应,并在响应主体中携带它收到的原始请求报文。
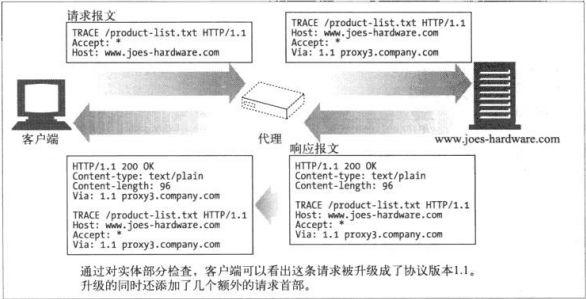
TRACE方法主要用于诊断—-用于验证请求是否如愿穿过了请求/响应链。可以查看代理和其他应用程序对用户请求所产生效果。 缺点:它假定中间应用程序对各种不同类型请求的处理是相同的。但很多HTTP应用程序会根据不同的方法做不同的事情,比如代理会将POST直接发送给服务器,而将GET发送给另外一个HTTP应用程序(比如WEB缓存)。但TRACE并不提供区分这些方法的机制。TRACE请求不能带有实体的主体部分,响应的实体的主体部分是服务器收到的请求的精确副本。
OPTIONS
该方法请求WEB服务器告知其支持的各种功能。可以询问服务器通常支持哪些方法,或者对某些特殊资源支持哪些方法。
DELETE
请服务器删除请求URL所指定的资源,但是客户端应用程序无法保证删除操作一定会被执行。因为HTTP规范允许服务器在不通知客户端的情况下撤销请求。
扩展方法
如果能够在不破坏端到端行为的情况下将带有未知方法的报文传递给下游服务器的话,代理会尝试着传递这些报文的,否则,它们会以501 Not Implemented(无法实现)状态码进行响应。
状态码
状态码为客户端提供了一种理解事务处理结果的便捷方式。
100-199—-信息性状态码
HTTP/1.1向协议中引入了信息性状态码。这些状态码较新。

1、客户端与100 Continue
如果客户端在向服务器发送一个实体,且愿意在发送实体之前等待100 Continue响应,那么客户端就要发送一个携带了值为100 Continue Expect 首部。发送了值为100 Continue的Expect首部的客户端不应该永远等待服务器发送100 Continue响应。超过一段时间之后,客户端应该直接将实体发送出去。
2、服务器与100 Continue
有些出错的服务器可能在没有收到100 Continue的Expect首部的请求,也会发出响应码。 出于某种原因,服务器在发送100 Continue 响应之前就收到了部分(或全部)实体,就说明客户端已经决定继续发送数据了,这样,服务器就不需要在发送这个状态码了。但是服务器读完请求之后,还是应该为请求发送一个最终状态码(它可以跳过100 Continue状态)。 如果服务器收到了带有100 Continue的请求,而且它决定在读取实体的主体部分之前结束请求(比如因为出错),就不应该仅仅是发送一条响应并关闭连接,因为这样会妨碍客户端接收响应。
3、代理与100 Continue
代理收到该请求后,若它知道下一跳服务器是HTTP/1.1兼容的,或者并不知道下一跳服务器与那个版本兼容,都应该将Expect首部放在请求中向下转发。如果它知道下一跳服务器只能与HTTP/1.1之前的版本兼容,就应该以417 Expectation Failed错误进行响应。(还有一种方法,就是想客户端返回100 Continue ,向服务器发送时删掉Expect首部)
200~299—-成功状态码

300~399—-重定向状态码
重定向状态码要么告知客户端使用替代位置来访问他们所感兴趣的资源,要么就提供一个替代的响应而不是资源的内容。
可以通过某些重定向状态码对资源的应用程序本地副本与源端服务器上的资源进行验证。


当HTTP/1.0客户端发起一个POST请求,并在响应中收到302状态码,它会接受Location首部的重定向URL,并向那个URL发起一个GET请求(而不是POST请求)。 在HTTP/1.1中使用303状态码来实现上述行为,为了避开这个问题,对于HTTP/1.1 客户端,用307状态码取代302进行临时重定向。这样服务器就可以将302保存起来为HTTP/1.0客户端使用了。
400~499—-客户端错误状态码
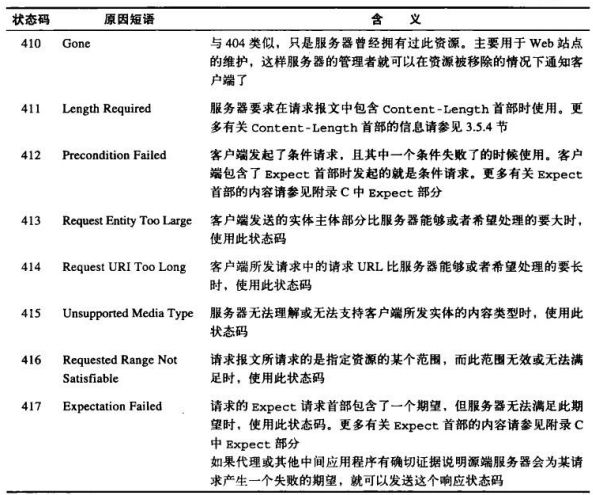
500~599—-服务器错误状态码


首部
五个主要的类型:
一、通用首部
比如Date首部,每一端都可以用它来说明构建报文的时间和日期:
Date: Tue, 3 Oct 1974 02:16:00 GMT
通用缓存首部—HTTP/1.0引入了第一个允许HTTP应用程序缓存对象本地副本的首部。

二、请求首部
请求报文特有,比如Accept首部用来告知服务器客户端会接受与其请求相符的任意媒体类型:
Accept: /


条件请求首部

安全请求首部

代理请求首部

三、响应首部

比如Server首部用来告知客户端与哪一个版本的服务器进行交互。
Server: TiKi-Hut/1.0
1、协商首部
资源有多种表示方法,比如某文档的法语和德语译稿,HTTP/1.1可以为服务器和客户端提供对资源的协商能力。

2、安全响应首部

四、实体首部
比如可以用实体首部来说明实体主体部分的数据类型。通过下列Content-Type首部告知应用程序,数据是以iso-latin-
I 字符集表示的HTML文档。
Content-Type: text/html; charset=iso-latin-1
实体首部提供了有关实体及其内容的大量信息,从有关对象类型的信息,到能够对资源使用的各种有效的请求方法。

1、内容首部—–提供了与实体内容有关的特定信息,说明其类型、尺寸以及处理它所需的其他有用信息。

2、实体缓存首部—-提供了与被缓存实体有关的信息——比如,验证已缓存的资源副本是否仍然有效所需的信息,以
及更好地估计已缓存资源何时失效所需的线索。

五、扩展首部
非标准首部,由应用程序开发者创建,还未添加到已批准的HTTP规范中。即使不知道这些扩展首部的含义,HTTP程
序也要接受它们并转发。
第四章 连接管理
一、TCP连接
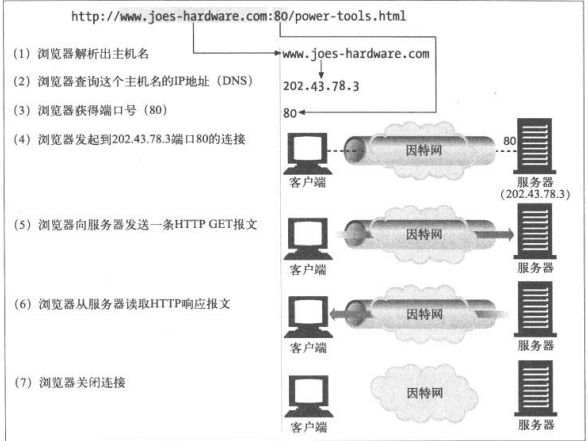
4.1.1 TCP的可靠数据管道
HTTP连接实际上就是TCP连接和一些使用连接的规则。TCP为HTTP提供了一条可靠的比特传输管道。
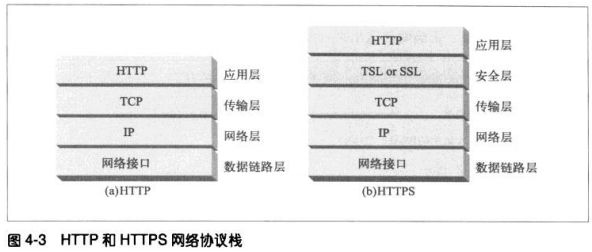
4.1.2 TCP流是分段的、由IP分组传送
TCP的数据是通过名为IP分组(或IP数据报)的小数据块来发送的。这样的话,如图所示,HTTP就是协议栈的最顶层
了,其安全版本HTTPS就是在HTTP和TCP之间插入了一个(称为TLS或者SSL的)密码加密层。
4.1.3 保持TCP连接的正确运行
在任意时刻计算机都可以有几条TCP连接处于打开的状态。TCP是通过端口号来保持这些连接的正确运行的。TCP连接
是通过4个值来识别的:
<源IP,源端口,目的IP,目的端口> 这4个值一起唯一确定一条连接。

4.1.4 用TCP套接字编程
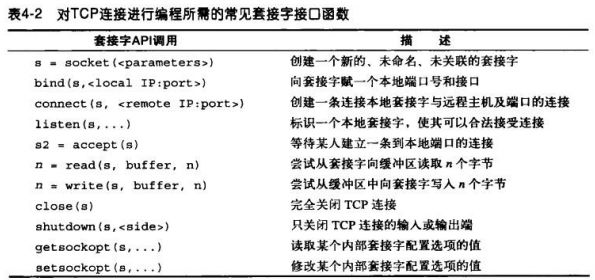
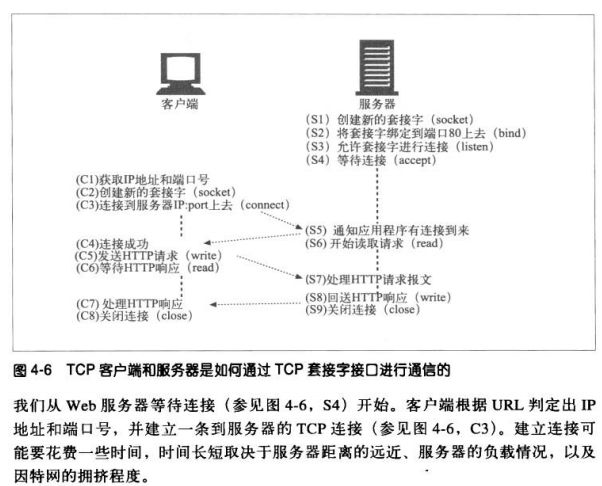
4.2 对TCP性能的考虑
4.2.1 HTTP事务的时延
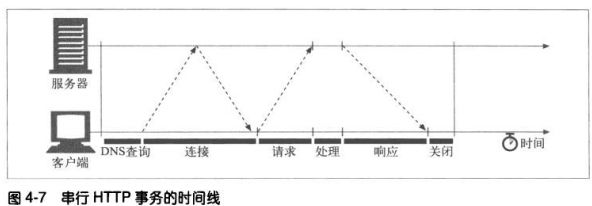
事务时延的主要原因:
1、 若之前未访问过某主机,则需要DNS解析,花费数十秒。但大多数HTTP客户端都有一个小的DNS缓存,用来保存
近期的IP地址。
2、 TCP连接建立大概一二秒,但如果有数百个HTTP事务,这个值会快速叠加。
3、 建立连接后,开始发送HTTP请求,到达server 来处理的时延
4、 server回送HTTP响应报文时延
4.2.2 性能聚焦区域
TCP连接建立握手
TCP慢启动拥塞控制
数据聚集的Nagle算法
用于捎带确认的TCP延迟确认算法
TIME_WAIT时延的端口耗尽
4.2.3 TCP连接的握手时延
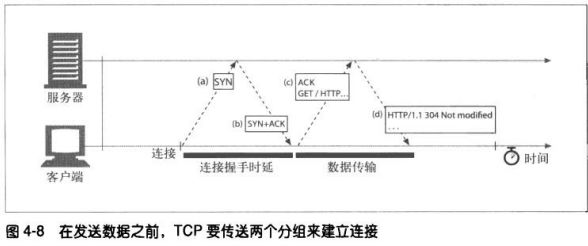
通常HTTP事务都不会交换太多数据。此时 SYN/SYN-ACK握手会产生一个可测量的时延。TCP连接的ACK分组通常足
够大,可以承载整个HTTP请求报文。而且很多HTTP服务器响应报文都可以放入一个IP分组中去(比如小型HTML文件
或是对浏览器高速缓存请求产生的304响应)。 这样就会导致小的HTTP事务可能会在TCP建立上花费%50多的时间。
4.2.4 延迟确认
TCP的确认机制。确认报文很小,所以TCP允许在发往相同方向的输出数据分组中对其进行”捎带“。TCP将返回的确
认信息与输出的数据分组结合在一起,可以有效利用网络。
为了增加确认报文找到同向传输数据分组的可能性,很多TCP栈都实现了一种”延迟确认“算法。该算法会在一个特定
的窗口时间(100–200毫秒)内将输出确认存放在缓冲区,以寻找能够捎带它的输出数据分组,若没有找到,则单独
传送。
但是,HTTP具有双峰特征的请求-应答行为降低了捎带信息的可能,所以延迟确认算法会引入相当大的时延。
4.2.5 TCP慢启动
TCP起初限制连接的最大速度,若数据传输成功,随着时间推移提高传输速度。
慢启动限制了一个TCP端点在任意时刻可以传输的分组数。每成功传输1个,发送方就获得了可以传送2个的权限。以
此类推,将会是4个,这样的方式称为”打开拥塞窗口”。由于存在拥塞控制,新连接的传输速度就比已经交换过数据
的连接慢。
4.2.6 Nagle算法与TCP_NODELAY
TCP有一个数据流接口,应用程序可以通过它将任意大小的数据放入TCP栈中——即使一次放一个字节。但是每个TCP
段中都至装载了40个字节的标记和首部,这样大量的包含少数据的分组就会影响网络性能。
Nagle算法试图在发送一个分组之前,将大量的TCP数据绑定在一起,提高网络效率。 RFC 896
该算法鼓励发送全尺寸(LAN上为约1500字节,因特网上是几百字节)的段。只有当所有其他分组都被确认后,此算
法才允许发送非全尺寸的分组。若其他分组仍在传输中,就将那部分数据缓存起来。只有当挂起分组被确认,或者缓
存中积累了足够发送一个全尺寸分组的数据时,才会将缓存数据发送出去。
该算法会引发几种HTTP性能问题,首先,小的HTTP报文可能无法填满一个分组,可能会因为等待那些永远不会到来
的额外数据而产生延迟。其次,Nagle算法与延迟确认之间的交互存在问题——Nagle算法会阻止数据的发送,直到有
确认分组抵达为止,但是确认分组本身会被延迟确认算法延迟100~200毫秒。
HTTP应用程序通常会在自己的栈中设置参数TCP_NODELAY禁用此算法。但这样就要确保向TCP写入大块数据。
4.2.7 TIME_WAIT累积与端口耗尽
当TCP端点关闭TCP连接时,会在内存中维护一个小的控制块,用来记录最近所关闭连接的IP地址和端口号。通常维持
是所估计的最大分段使用期的两倍左右(2MSL,通常为2分钟),以确保在这段时间内不会创建具有相同地址和端口
的连接。
2MSL的连接关闭延迟通常不是问题。但在性能基准环境下,通常只有一台或几台用来产生流量的计算机连接到某系统
中去,这样就限制了连接到服务器的客户端IP地址数。而且,服务器通常会在HTTP的默认80端口监听。用
TIME_WAIT防止端口号重用时,这些情况也限制了可用的连接值组合。
在只有一个服务器一个客户端情况下,client每次连到server上都有一个新的源端口,实现连接的唯一性,但源端口数
量有限,且在2MSL秒(120s)内无法重用,这样连接率就限制在了500次/秒。若再进行优化,且server的连接率不
高于500次/秒,就能确保不会遇到TIME_WAIT端口耗尽问题。要修正此问题,可以增加client负载生产机器的数量,
或者确保client和server在循环使用几个虚拟IP。
即使没有遇到端口耗尽问题,也要特别小心有大量连接处于打开状态的情况,或者为处于等待状态的连接分配了大量
控制块的情况。
4.3 HTTP连接的处理
4.3.1 常被误解的Connection首部
HTTP允许在客户端和最终的源端服务器之间存在一串HTTP中间实体(代理、高速缓存等)。在某些情况下,两个相
邻的HTTP应用程序会为它们共享的连接应用一组选项。HTTP的Connection首部字段中有一个由逗号分隔的连接标签
列表,这些标签为此连接指定了一些不会传播到其他连接中去的选项。比如,可以用Connection:close 来说明发送
完下一条报文之后必须关闭的连接。
Connection首部可以承载3中不同类型的标签:
HTTP首部字段名,列出只与此连接有关的首部
任意标签值,用于描述此连接的非标准选项
值close,说明操作完成后需关闭这条持久连接
如果连接标签中包含了一个HTTP首部字段的名称,那么这个首部字段就包含了与一些连接有关的信息,不能将其转发
出去。在将报文转发出去之前,必须删除Connection首部列出的所有首部字段。由于Connection首部可以防止无意
中对本地首部的转发,因此将逐跳首部名放入Connection首部被称为“对首部的保护”。
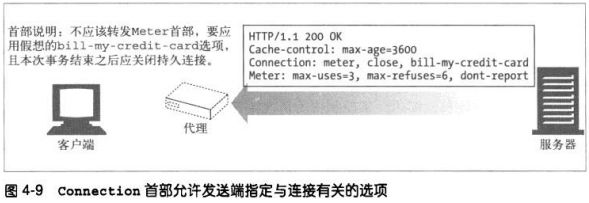
HTTP应用程序收到一条带有Connection首部的报文时,接收端会解析发送端请求的所有选项,并应用。然后会在将
此报文转发给下一跳地址之前,删除Connection首部以及Connection中列出的所有首部。而且还会有少量没有作为
Connection首部值列出,但一定不能被代理转发的逐条首部。其中包括Proxy-Authenticate/Proxy-
Connection/Transfer-Encoding/Upgrade.
4.3.2 串行事务处理时延
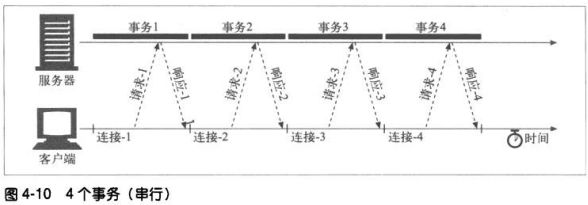
连接时延和慢启动时延会因为串行叠加起来。
串行加载另一缺点,有些浏览器在对象加载完毕之前无法获知对象的尺寸,而且它们可能需要尺寸信息来决定将对象
放在屏幕的什么位置,所以在加载足够多对象前,无法在屏幕上显示任何内容。
有几种新的方法可以提高HTTP连接性能:
并行连接—-通过多条TCP连接发起并发的HTTP请求
持久连接—-重用TCP连接,以消除连接以及关闭时延
管道化连接—-通过共享的TCP连接发起并发的HTTP请求
复用的连接—-交替传送请求和响应报文(实验阶段)
4.4 并行连接
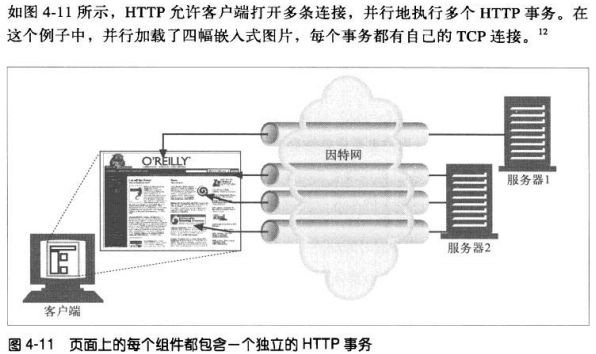
4.4.1 并行连接可能会提高页面的加载速度
包含嵌入对象的组合页面如果能通过并行连接克服单条连接的空载时间和带宽限制,加载速度也会有所提高。时延
可以重叠起来,而且如果单条连接没有充分利用客户端带宽,可以将未用带宽分配来装载其他对象。
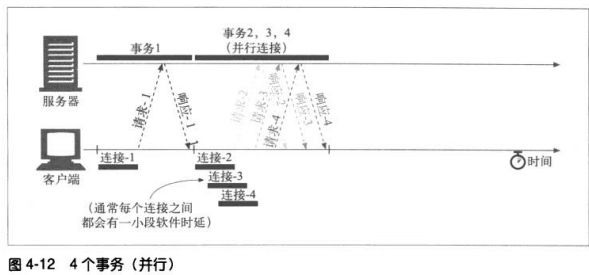
4.4.2 并行未必更快
客户端网络带宽不足时(比如,浏览器是通过一个28.8Kbps的Modem连接到因特网上去),大部分的时间可能
都是用来传输数据。这样,一个连接到速度较快的服务器的HTTP事务就会很容易耗尽所有可用Modem带宽。如果
并行加载多个对象时,每个对象都去竞争这有限的带宽,每个对象都会以较慢的速度按比例加载,这样带来的性能
提升就很小,甚至没有。
实际上,浏览器确实使用了并行连接,但是会将连接的总数限制在一个较小的值(通常是4个)。服务器可以随意关
闭来自特定客户端的超量连接。
4.5 持久连接
WEB客户端经常会打开到同一个站点的连接。比如,一个WEB页面上的大部分内嵌图片通常来自同一个WEB站点,而
且相当一部分指向其他对象的超链接都是指向同一个站点。因此,初始化了对某服务器的应用程序很可能在不久的将
来对那台服务器发起更多的请求。这种性质被称为站点本地性。
因此,HTTP/1.1允许HTTP设备在事务处理结束之后将TCP连接保持在打开状态,以便为未来的HTTP请求重用现存的
连接。持久连接会在不同事务之间保持打开状态,直到客户端或者服务器决定将其关闭。
4.5.1 持久及并行连接
并行连接可以提高复合页面的传输速度。但也有一些缺点:
1、每个事务都会打开/关闭一条新的连接、会耗费时间和带宽
2、由于TCP慢启动特性,每条新连接的性能都会有所降低
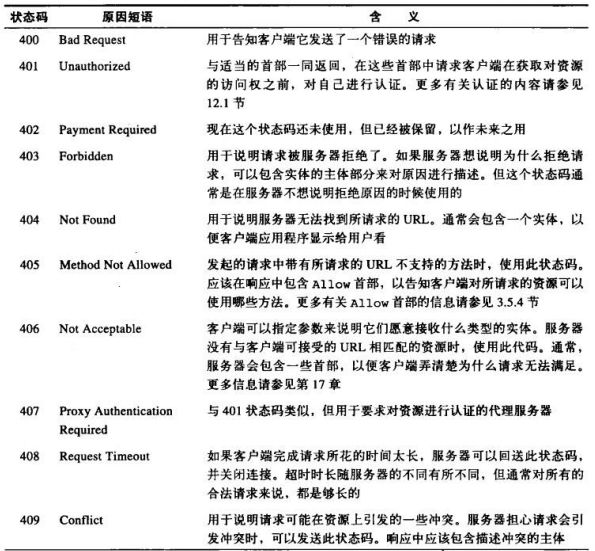
3、可打开的并行连接数量有限
持久连接比并行连接更好在降低了时延和建立连接的开销。但是管理持久连接需要特别小心。
4.5.2 HTTP/1.0+keep-alive连接
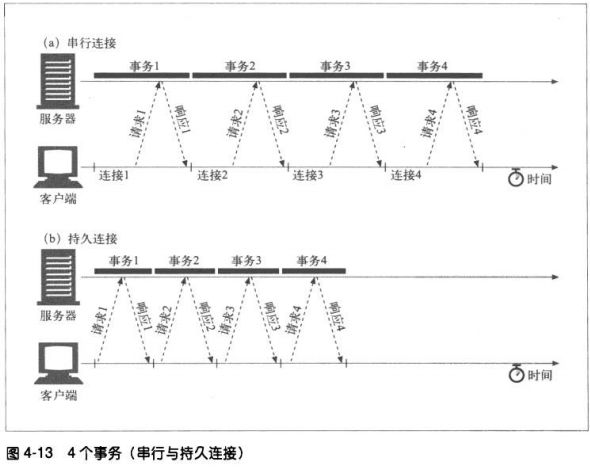
4.5.3 Keep-Alive操作
实现HTTP/1.0 keep-alive连接的客户端可以通过包含 Connection: Keep-Alive首部请求将一条连接保持在打开
状态。
如果服务器愿意为下一条请求将连接保持在打开状态,就在响应中包含相同的首部。如果响应中没有 Connection:
Keep-Alive 首部,客户端就会认为服务器不支持keep-alive,会在响应报文之后关闭连接。
4.5.4 Keep-Alive选项
keep-alive首部只是请求将连接保持在活跃状态。发出keep-alive请求之后,客户端和服务器并不一定同意进行
keep-alive会话。它们可以在任意时刻关闭空闲的keep-alive连接,并可随意限制keep-alive连接所处理事务数量
可以用keep-alive通用首部中指定的、由逗号分隔的选项来调节行为:
1、timeout是在keepalive响应首部发送的。它估计了服务器希望将连接保持在活跃状态的时间。并非承诺值
2、max也是在响应首部发送的。估计了服务器还希望为多少个事务保持此连接的活跃状态,并非承诺值。
3、keep-alive首部还可以支持任意未经处理的属性,这些属性主要用于诊断调试。语法:name [=value]
4.5.5 keep-alive连接的限制和规则
*HTTP/1.0中,并非默认使用,客户端需发送一个请求首部来激活keep-alive连接
*请求首部必须随所有希望保持持久连接的报文一起发送
*如果此响应中没有Connection: Keep-Alive响应首部,就可以知道服务器发出响应后是否会关闭连接了
*代理和网关必须执行Connection首部的规则。代理或网关必须在将报文转发出去或将其高速缓存之前,删除在
Connection首部中命名的所有首部字段以及首部自身。
*严格来说,不该与无法确定是否支持Connection首部的代理服务器建立keep-alive连接
*除非重复发送请求会产生其他一些副作用,否则如果在客户端收到完整的响应之前连接就关闭了,客户端就一定要
做好重试请求的准备。
4.5.6 Keep-Alive和哑代理
WEB客户端的Connection: keep-alive首部应该只会对这条离开客户端的
TCP链路产生影响。
1、Connection首部和盲中继
问题出在代理上—-尤其是那些不理解Connection首部,而且不知道在沿
着转发链路将其发送出去之前,应该将该首部删除的代理。很多老的或简
单的代理都是盲中继(blind relay),它们只是将字节从一个连接转发到
另一个连接中去,不对Connection首部进行特殊处理。
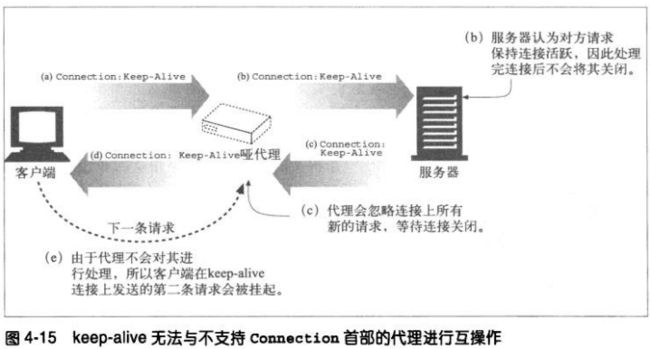
2、代理和逐跳首部
为避免此类代理通信问题,现代的代理都决不能转发Connection首部和
所有名字出现在Connection值中的首部。另外,还有几个不能作为
Connection首部值列出,也不能被代理转发或作为缓存响应使用的首
部。其中包括:Proxy-Authenticate/Proxy-Connection/Transfer-
Encoding/Upgrade.
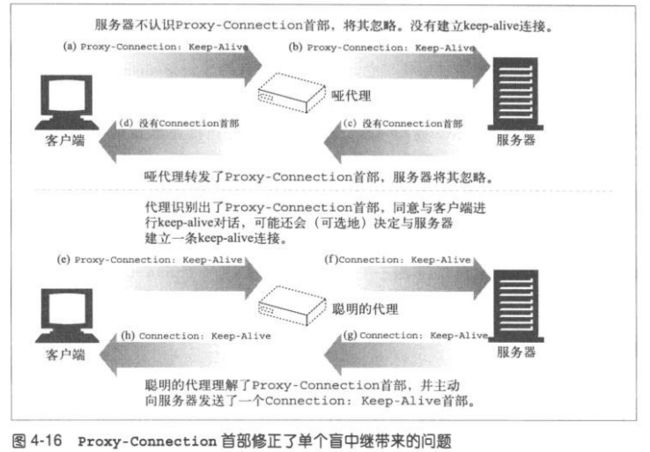
4.5.7 插入Proxy-Connection
Netscape的做法是,浏览器向代理发送非标准的Proxy-Connection扩展首
部,而不是官方的Connection首部。如果代理是盲中继,会将无意义的
Proxy-Connection首部转发给服务器,而服务器会忽略此首部。但如果是一
个能够理解持久连接的代理,就会用一个Connection首部代替这个首部,将
其发送给服务器。
在客户端和服务器之间只有一个代理时,可以使用这种方案来解决问题,但
是,一旦在哑代理的任意一侧还有一个聪明的代理,问题就会再次发生。
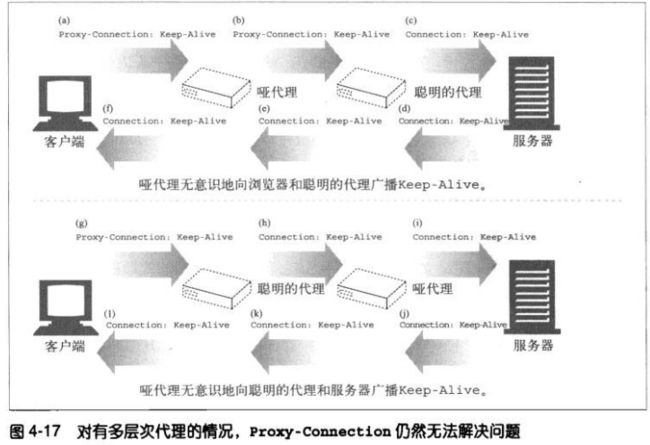
4.5.8 HTTP/1.1 持久连接
HTTP/1.1 逐渐停止了对keep-alive的支持,用一种名为持久连接
(persistent connection)的改进型设计取代。
HTTP/1.1 持久连接在默认情况下是激活的,除非特别指明,否则,HTTP/1.1
假定所有的连接都是持久的。要在事务结束之后将连接关闭,HTTP/1.1应用
程序必须向报文中显式地添加一个Connection: close首部。但是,客户端
和服务器仍然可以随时关闭空闲连接,不发送close并不意味着服务器承诺永
远将连接保持在打开状态。
4.5.9 持久连接的限制和规则
*发送了Connection: close请求首部后,客户端就无法在那条连接上发送更
多的请求了。
*若客户端不想在连接上发送其他请求了,就应该在最后一个请求中发送close
*只有当连接上所有的报文都有正确的、自定义报文长度时(也就是说,实体
部分的长度和相应的Content-Length一致,或者是用分块传输编码方式编码
的)—–连接才能持久保持
*HTTP/1.1的代理必须能分别管理与客户端和服务器的持久连接—-每个持久
连接都只适用于一跳传输
*由于较老的代理会转发Connection首部,所以,HTTP/1.1的代理服务器不
应与HTTP/1.0客户端建立持久连接。
*尽管服务器不该在传输报文的过程中关闭连接,而且在关闭连接之前至少应
该响应一条请求。但不管Connection首部取什么值,HTTP/1.1设备都可在
任意时刻关闭连接。
*HTTP/1.1 应用程序必须能从异步的关闭中恢复出来,只要不存在可能会累积
起来的副作用,客户端都应该重试这条请求。
*除非重复发起请求会产生副作用,否则如果在客户端收到整条响应之前连接
关闭了,客户端都必须要重新发起请求。
*一个用户客户端对任何服务器或代理最多只能维护两条持久连接,以防止服
务器过载。代理可能需要更多到服务器的连接来支持并发用户的通信,所以,
如果有N个用户试图访问服务器,代理最多要维持2N条到任意服务器或父代
理的连接。
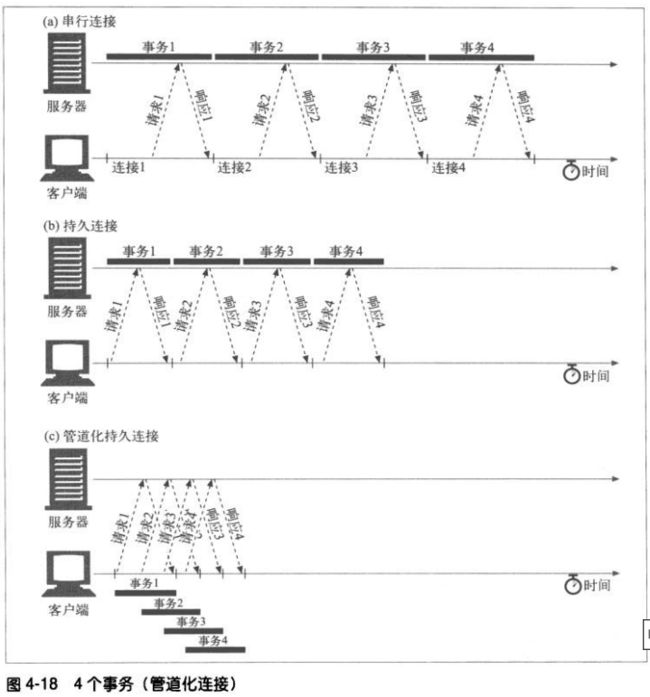
4.6 管道化连接
在响应到达之前,可以将多条请求放入队列。当第一条请求通过网络流向另一端
的服务器时,第二条和第三条请求也可以开始发送了。这样可以降低网络的环回
时间,提高性能。
对管道化连接有几条限制:
!如果HTTP客户端无法确认连接是持久的,就不该使用管道
!必须按照与请求相同的顺序回送HTTP响应。HTTP报文中没有序列号标签,
因此如果收到的响应失序了,就无法进行匹配
!HTTP客户端必须做好连接会在任意时刻关闭的准备,还要准备好重发所有
未完成的管道化请求
!HTTP客户端不应该用管道化的方式发送会产生副作用的请求(如POST)。总
之,出错的时候,管道化方式会阻碍客户端了解服务器执行的是一系列管道
化请求中的哪一些。由于无法安全的重试POST这样的非幂等请求,所以出
错时,就存在某些方法永远不会被执行的风险。
4.7 关闭连接的奥秘
4.7.1 “任意”解除连接
所有HTTP客户端,服务器或代理都可在任意时刻关闭一条TCP传输连接。通常
在一条报文结束时关闭。
4.7.2 Content-Length及截尾操作
每条HTTP响应都应该有精确的length首部,用以描述响应主体的尺寸。一些
老的HTTP服务器会省略这个首部或者包含错误的长度指示,这样就要依赖服
务器发出的连接关闭来说明数据的真实结尾。
客户端或代理收到一条随连接关闭而结束的HTTP响应,且实际传输的实体长
度与length首部不匹配,接收端就该质疑长度的正确性。
如果接收端是个缓存代理,就不该缓存这条响应(降低今后将潜在的错误报文
混合起来的可能)。代理应将有问题的报文原封不动的转发出去。
4.7.3 连接关闭容限、重试以及幂等性
如果一个事务,不管是执行一次还是多次,得到的结果都相同,这个事务就是
幂等的。实现者们可以认为GET/HEAD/PUT/DELETE/TRACE/OPTIONS方法
都共享这一特性。客户端不该以管道化方式传送非幂等请求(如POST)。否
则连接的过早终止就会造成一些不确定的后果。要发送一条非幂等请求,就需
要等待来自前一条请求的响应状态。
尽管用户Agent代理可能会让操作员来选择是否对请求进行重试,但一定不能
自动重试非幂等方法或序列。比如,大多数浏览器会在重载一个缓存的POST
响应时提供一个对话框,询问用户是否希望再次发起事务处理。
4.7.4 正常关闭连接
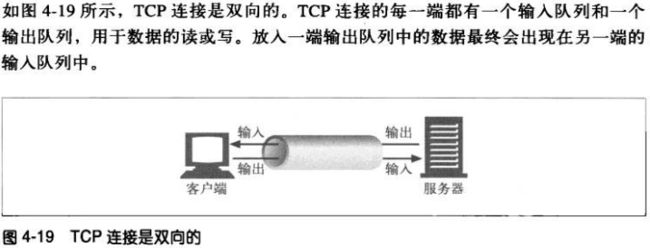
1、完全关闭与半关闭
应用程序可以关闭TCP输入和输出信道中的任意一个,或者将两者都关闭
了。套接字调用close()会将TCP连接的输入和输出信道都关闭了—-完全
关闭。还可以用套接字调用shutdown()单独关闭输入或输入信道—-半
关闭。
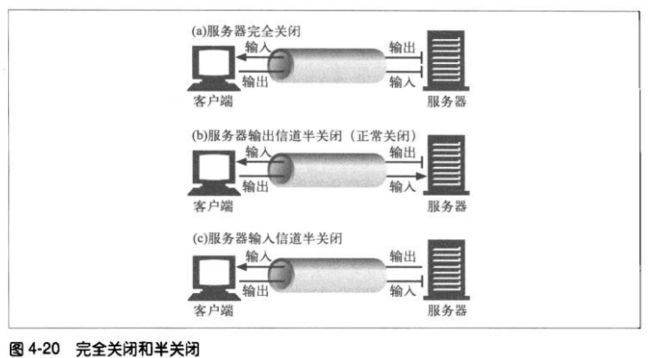
2、TCP关闭及重置错误
简单的HTTP应用程序可以只使用完全关闭。但当应用程序开始与很多其他
类型的HTTP客户端、服务器和代理进行对话且开始使用管道化持久连接
时,使用半关闭来防止对等实体收到非预期的写入错误就变得很重要了。
总之,关闭连接的输出信道总是很安全的。连接另一端的对等实体会在从其
缓冲区中读出所有数据后收到一条通知,说明流结束了,这样它就知道你将
连接关闭了。
关闭连接的输入信道比较危险,除非你知道另一端不打算再发送其他数据
了。若另一端向你已经关闭的信道发送数据,操作系统就会向另一端的机器
回送一条TCP“连接被对端重置”的报文。大部分操作系统会将这种情况作
为很严重的错误来处理,删除对端还未读取的所有缓存数据。
3、正常关闭
实现正常关闭的应用程序首先应该关闭它们的输出信道,然后等待连接另一
端的对等实体关闭它的输出信道。之后,连接就会被完全关闭。
但不幸的是,无法确保对等实体会实现半关闭,或对其进行检查。因此,想
要正常关闭连接的应用程序应该先半关闭其输出信道,然后周期性地检查其
输入信道的状态(查找数据,或流的末尾)。如果在一定时间区间内对端没
有关闭输入信道,应用程序可以强制关闭连接,以节省资源。
第二部分 HTTP结构
第五章 WEB服务器
WEB服务器会做些什么
1、建立连接—-接受一个客户端连接,或者如果不希望与这个客户端建立连接,就将
其关闭
2、接受请求—-从网络中读取一条HTTP请求报文
3、处理请求
4、访问资源
5、构建响应
6、发送响应
7、记录事务处理过程
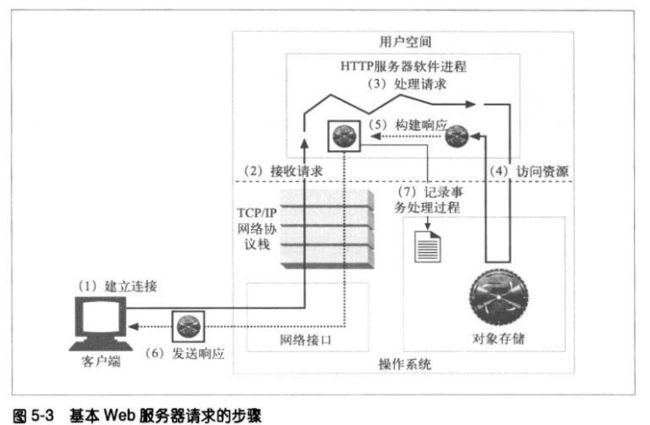
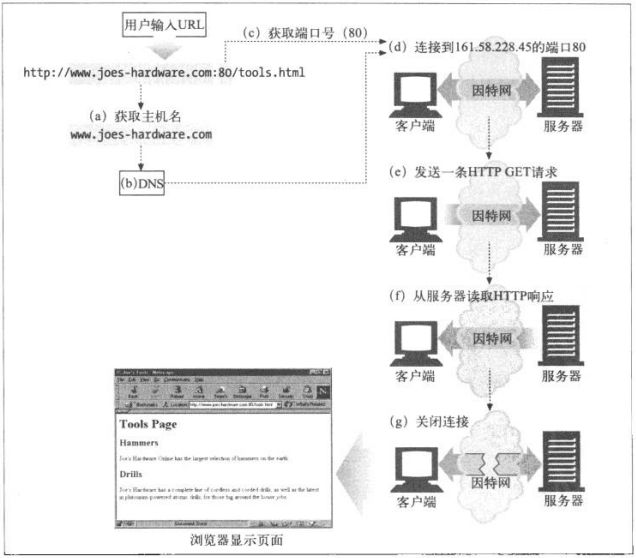
5.1 第一步—-接受客户端连接
5.1.1 处理新连接
客户端请求一条道服务器的TCP连接时,服务器会建立连接,判断连接的另一端
是哪个客户端,从TCP连接中将IP地址解析出来。(不同操作系统在对TCP连接
进行操作时会使用不同的接口和数据结构,Unix下,TCP连接由一个套接字表
示,可以用getpeername调用从套接字中获取客户端IP)一旦新的连接建立起来
并被接受,服务器就会将新连接添加到其现存服务器连接列表中,做好监视连接
上数据传输的准备。
5.1.2 客户端主机名识别
可以用‘反向DNS’对大部分web服务器进行配置,以便将客户端IP地址转换成
客户端主机名。web服务器可以将客户端主机名用于详细的访问控制和日志记
录。但需要注意的是,主机名查找可能花费较长时间,这会降低事务处理的速
度。很多大容量的服务器要么禁止主机名解析,要么只允许对特定内容进行解
析。 可以用HostnameLookups启用Apache的主机查找功能。

5.1.3 通过ident确定客户端用户
有些web服务器支持IETF的ident协议。服务器可以通过ident协议找到发起
HTTP连接的用户名。这些信息对web服务器的日志记录很有用—流行的通用日
志格式(CommonLogFormat)的第二个字段就包含了每条HTTP请求的ident
用户名。
如果客户端支持ident协议,就在TCP端口113上监听ident请求。
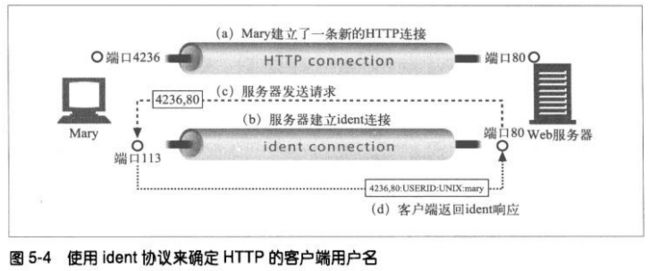
可以通过Apache的identitycheck on指令告知Apache web服务器使用ident查
找功能。若没有ident信息可用,Apache会用连字符来填充ident日志字段。
5.2 第二步—-接受请求报文
连接上有数据到达时,web服务器会从网络连接中读取数据,并将请求报文中的内
容解析出来
**解析请求行,查找请求方法、指定的资源标识符(URI)以及版本号,各项间由
一个空格分隔,并以一个回车换行(CRLF)序列作为行的结束。
**读取以CRLF结尾的报文首部
**检测到以CRLF结尾的、标识首部结束的空行(如果有)
**如果有的话,读取请求主体
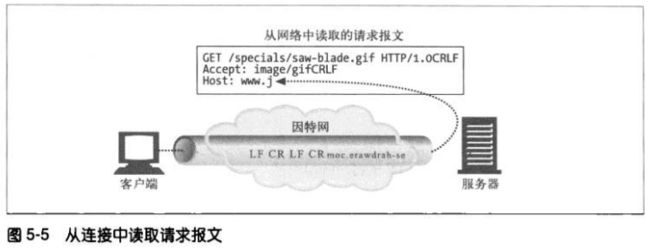
解析请求报文时,服务器会不定期从网络上接收输入数据。网络连接可能随时有延
迟。服务器需要从网络中读取数据,将部分数据临时存储在内存中,直到收到足以
进行解析的数据并理解其意义为止。
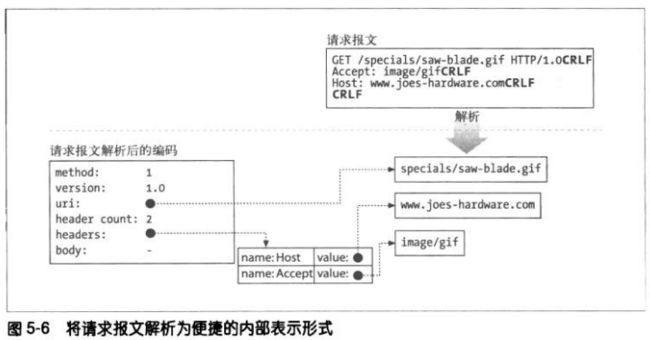
5.2.1 报文的内部表示法
有些web服务器还会用便于进行报文操作的内部数据结构来存储请求报文。比
如,数据结构中可能包含有指向请求报文中各个片段的指针及其长度,这样就可
以将这些首部存在一个快速查询表中,以便快速访问特定的首部的具体值。
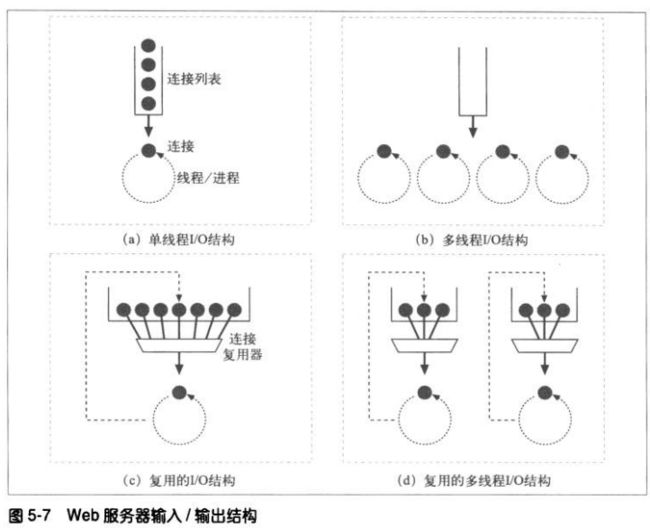
5.2.2 连接的输入/输出处理结构
因为请求可能会在任意时刻到达,所以WEB服务器会不停的观察有无新的WEB
请求,不同的服务器结构会以不同的方式为请求服务。
①单线程服务器
单线程的服务器一次只处理一个请求,直到其完成为止。一个事务处理结束之
后,才会处理下一条连接。在处理过程中,其他所有连接都会被忽略,只适用
于低负荷的服务器。
②多进程及多线程服务器
多进程和多线程服务器用多个进程,或更高效的线程同时对请求进行处理。可
以根据需要创建,或者预先创建一些线程/进程(会预先创建一些线程的系
统,被称为“工作池”系统,因为池中会有一组线程在等待工作)。有些服务
器会为每条连接分配一个线程/进程,但当服务器同时要处理很多连接时,需
要的进程或线程数量可能会消耗太多的内存或系统资源。因此很多多线程服务
器都会对线程/进程的最大数量进行限制。
③复用I/O的服务器
为了支持大量的连接,很多WEB服务器都采用了复用结构。在复用结构中,
要同时监视所有连接上的活动。当连接的状态发生变化时(比如有数据可
用,或者出现错误时),就对那条连接进行少量的处理。处理结束之后,将
连接返回到开放连接列表中,等待下一次的状态变化。只有在有事情可做时
才会对连接进行处理,在空闲连接上等待的时候并不会绑定进程和线程。
④复用的多线程服务器
有些系统会将多线程和复用功能结合在一起,以利用计算机平台上的多个
CPU。多个线程(通常是一个物理处理器)中的每一个都在观察打开的连接
(或打开的连接中的一个子集),并对每条连接执行少量的任务。
注:进程是一个独立的程序控制流,有自己的变量集。线程是一种更快、更高效的进程版本。
5.3 第三步 处理请求
一旦WEB服务器收到了请求,就可以根据方法、资源、首部和可选的主体部分来
对请求进行处理了。
5.4 第四步 对资源的映射及访问
5.4.1 docroot
WEB服务器支持各种不同类型的资源映射,但最简单的资源映射形式就是用请
求URI作为名字来访问WEB服务器文件系统中的文件。通常,WEB服务器会有
一个文档的根目录(document root 或docroot)。服务器从请求报文中获取
URI,并将其附加在文档根目录后面。

服务器要注意,不能让URL退到docroot之外,将文件系统的其他部分暴露出
来。
1、虚拟托管的docroot
虚拟托管的WEB服务器会在同一台WEB服务器上提供多个web站点,每个站点
在服务器上都有自己独有的文档根目录。虚拟托管web服务器会根据URI或
Host首部的IP地址或主机名来识别要使用的正确文档的目录。通过这种方式,
即使请求URI完全相同,托管在同一服务器上的两个web站点亦可以拥有完全
不同的内容了。
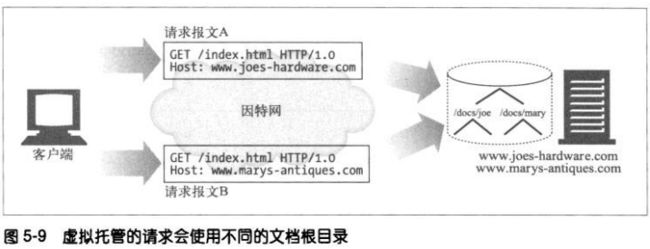
对于大多数web服务器来说,配置虚拟托管的文档根目录是很简单的。对常见
的Apache web服务器来说,需要为每个虚拟web站点配置一个VirtualHost
块,而且每个虚拟服务器都要包含DocumentRoot。

2、用户的主目录docroot
Docroot的另一种常见应用是在WEB服务器上为人们提供私有的web站点。通
常会把那些以斜杠和波浪号(/~)开始,后面跟着用户名的URI映射为此用户的
私有文档目录。私有docroot通常是用户主目录下那个名为public_html的目
录,但也可将其配置为其他值。
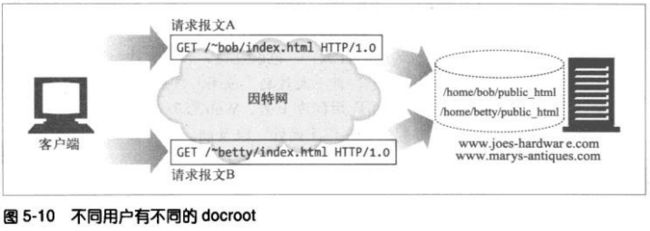
5.4.2 目录列表
web服务器可以接受对目录URL的请求,其路径可以解析为一个目录,而不是
文件。我们可以对大多数的服务器进行配置,使其在客户端请求目录URL时采
取不同的动作。
@返回一个错误
@不返回目录,返回一个特殊的默认“索引文件”
@扫描目录,返回一个包含目录内容的HTML页面
大多数服务器都会去查找目录中一个名为index.html或index.htm的文件来代
表此目录。如果用户请求的是一个目录的URL,而且这个目录中有一个名为
index.html或者index.htm的文件,服务器就会返回那个文件的内容。
在Apache服务器上可以用配置指令DirectoryIndex来配置要作为默认目录文
件使用的文件名集合。该指令会按照优先顺序列出所有可以作为目录索引文件
使用的文件名。下列配置会使Apache在收到一个目录URL请求时,在目录中
搜索命令中列出来的任意一个文件:
DirectoryIndex index.html index.htm home.html home.htm index.cgi
如果用户请求目录URI时,没有提供默认的索引文件,而且没有禁止使用目录
索引,很多web服务器都会自动返回一个html文件,此文件中会列出那个目录
里的文件名以及每个文件的大小和修改日期,还包括到每个文件的URI链接。
可以通过以下Apache命令禁止自动生成目录索引文件:
Options-Indexes
5.4.3 动态内容资源的映射
web服务器还可以将URI映射为动态资源—-也就是说,映射到按需动态生成内
容的程序上去。
Apache允许用户将URI路径名组件映射为可执行文件目录。服务器收到一条带
有可执行路径组件的对URI请求时,会试着去执行相应的服务器目录中的程
序。例如,下列Apache配置就表明所有路径以/cgi-bin/开头的URI都应该执
行在目录/usr/local/etc/httpd/cgi-programs/中找到的相应文件。
ScriptAlias /cgi-bin/ /usr/local/etc/httpd/cgi-programs/
Apache还允许用户用一个特殊的文件扩展名来标识可执行文件。通过这种方
式就可以将可执行脚本放在任意目录中了。下面的配置指令说明要执行所有
以.cgi 结尾的web资源
AddHandler cgi-script .cgi
CGI是早期出现的一种简单、流行的服务器应用程序执行接口。现代的应用程
序服务器都有更强大有效的服务器动态内容支持机制,包括微软的动态服务器
页面(Active Server Page)和Java servlet。
5.4.4 服务器端包含项
很多WEB服务器还提供了对服务器端包含项(SSI)的支持。如果某个资源被
标识为存在服务器端包含项,服务器就会在将其发送给客户端之前对资源内容
进行处理。
要对内容进行扫描,以查找(通常包含在特定的HTML注释中的)特定的模
板,这些模板可以是变量名,也可以是嵌入式脚本。可以用变量的值或可执行
脚本的输出来取代特定模板。这是创建动态内容的一种简便方式。
5.4.5 访问控制
服务器可以为特定资源进行访问控制。
5.5 第五步 构建响应
5.5.1 响应实体
如果事务处理产生了响应主体,就将内容放在响应报文中回送过去。如果有响
应主体的话,响应报文中通常包括:
!描述了响应主体MIME类型的Content-Type首部
!描述了响应主体长度的Content-Length首部
!实际报文的主体内容
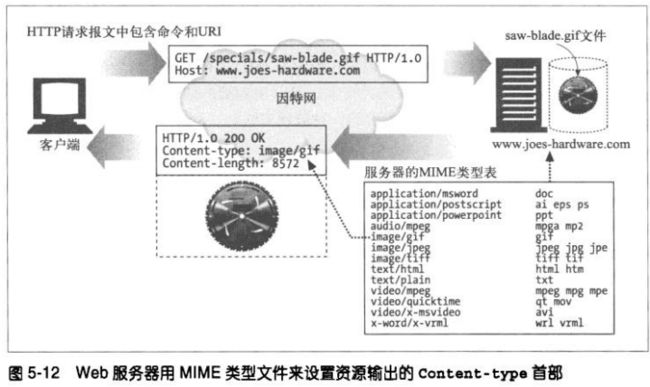
5.5.2 MIME类型
!MIME类型
服务器可以用文件的扩展名来说明MIME类型。
!魔法分类
Apache服务器可以扫描每个资源的内容,并将其与一个已知模式表(魔法文
件)进行匹配,以决定每个文件的MIME类型,这样会比较慢,但是很方便,
尤其是文件没有标准扩展名的时候。
!显式分类(Explicit typing)
可以对服务器进行配置,使其不考虑文件的扩展名或内容,强制特定文件或目
录内容拥有某个MIME类型。
!类型协商
有些服务器可以以多种文档格式来存储资源,这种情况下,通过配置服务器,
使其可以通过与用户协商来决定使用哪种格式及相关的MIME类型最好。
5.5.3 重定向
**永久删除的资源
资源肯能以及被移动到新位置,或重新命名,有了新的URL。301 Moved
Permanently 就用于此类重定向
**临时删除的资源
状态码303 See Other 以及状态码 307 Temporary Redirect 用于此类。
**URL增强
服务器通常用重定向来重写URL,往往用于嵌入上下文。当请求到达时,服
务器会生成一个新的包含了嵌入式状态信息的URL,并将用户重定向到这个
新的URL上去。客户端会跟随这个重定向信息,重新发起请求,但这次的请
求会包含完整的、经过状态增强的URL。这是在事务间维护状态的一种有效
方式。303、307用于此类重定向。
**负载均衡
若一个超载的服务器收到一条请求,可以将客户端重定向到一个负载不太重
的服务器上去。303、307用于此类重定向。
**服务器关联
服务器上可能会有某些用户的本地信息。服务器可将客户端重定向到包含了
客户端信息的那个服务器上去。303、307可用于此类重定向。
**规范目录名称
客户端请求的URI是一个不带尾部斜线的目录名时,大多数服务器都会将客
户端重定向到一个加了斜线的URI上,这样相对链接就可以正常 工作了。
5.6 第六步 发送响应
服务器通过链接发送数据时也会面临与接收数据一样的问题。服务器可能有很多条
到各个客户端的连接。服务器要记录连接的状态,还要特别注意对持久连接的处
理。对非持久连接来说,服务器应在发送了整条报文之后,关闭自己这一端的连
接。
对持久连接来说,连接可能扔保持打开状态,这种情况下,服务器要注意正确的计
算Content-Length首部,不然客户端就无法知道响应什么时候结束。
5.7 第七步 记录日志
第六章 代理
6.1 WEB的中间实体
HTTP的代理服务器既是WEB服务器又是客户端。
6.1.1 私有和共享代理
**公共代理
集中式代理的费效比更高,更容易管理。某些代理应用,比如高速缓存代理服
务器,会利用用户间共同的请求,这样汇入同一个代理服务器的用户越多,它
就越有用。
**私有代理
有些浏览器辅助产品,以及一些ISP服务,会在用户的PC上直接运行一些小型
代理,以便扩展浏览器特性,提高性能。
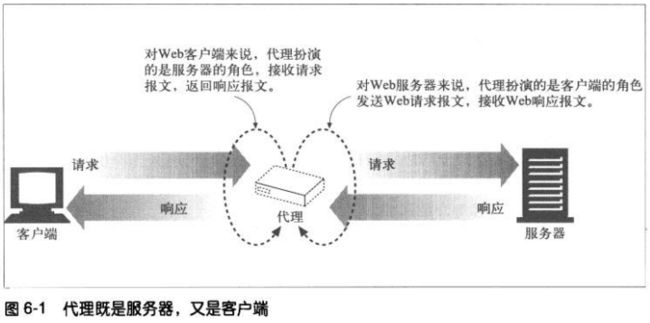
6.1.2 代理和网关的对比
严格来说,代理连接的是两个或多个使用相同协议的应用程序,而网关连接的则
是两个或多个使用不同协议的端点。网关扮演“协议转换器”角色,即使客户端
和服务器使用不同协议,客户端也能通过它和服务器完成事务处理。
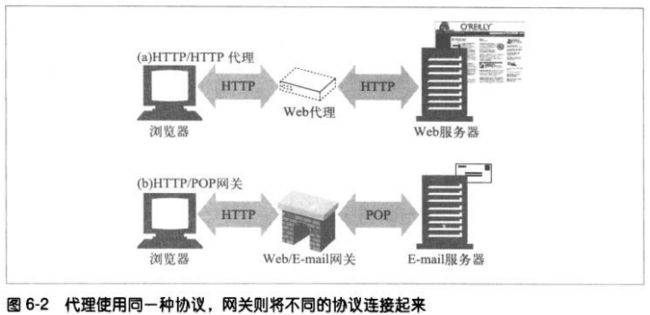
实际上,代理和网关的区别很模糊,由于浏览器和服务器实现的是不同版本的
HTTP,代理也需要做协议转换工作。而商业化代理服务器也会实现网关功能来
支持SSL安全协议,socks防火墙、ftp访问以及基于web的应用程序。
6.2 为什么使用代理
改善安全些,提高性能,节省费用。代理服务器可以看到并接触到所有流过HTTP
流量,所以代理可以监视流量并对其进行修改,实现WEB增值服务。
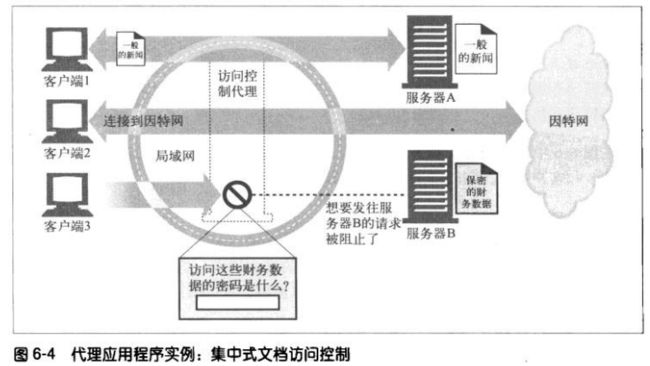
**在集中式代理服务器上可以对所有访问控制功能进行配置。
为防止有些用户刻意绕过,可以静态配置服务器,使其仅接受来自代理的请求。
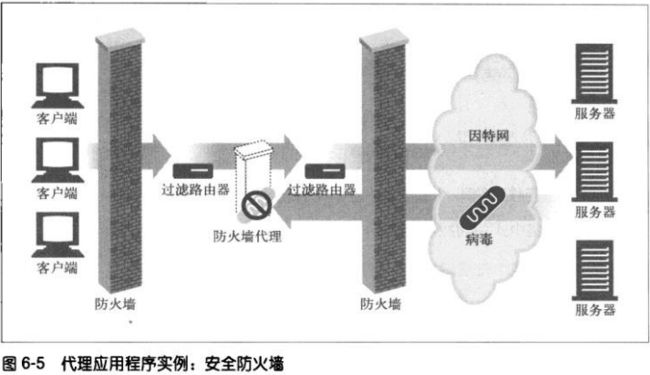
**安全防火墙
代理服务器会在网络中单一安全节点上限制哪些应用层协议的数据可以流入或流
出一个组织。还可以提供用来消除病毒的WEB和E–mail代理使用的那种挂钩程
序。
**WEB缓存
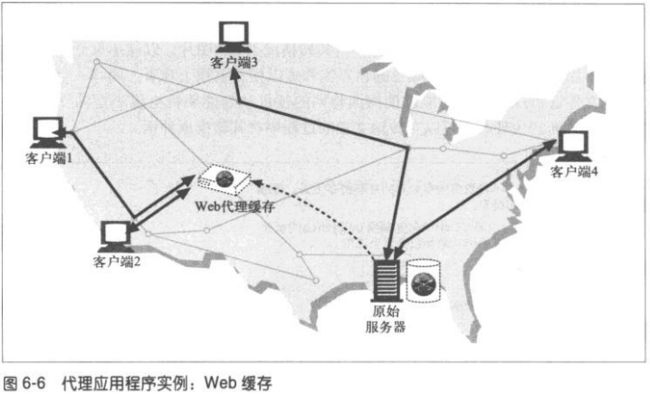
**反向代理
代理可以假扮WEB服务器,这些被称为替代物(surrogate)或反向代理
(reverse proxy)的代理接收发给WEB服务器的真实请求,但与WEB服务器不
同的是,它们可以发起与其他服务器的通信,以便按需定位所请求的内容。
可以用这些反向代理来提高访问慢速WEB服务器上公共内容时的性能。在这种配
置中,通常将这些反向代理称为服务器加速器(server accelerator)。还可以
将反向代理与内容路由功能配合使用,以创建按需复制内容的分布式网络。
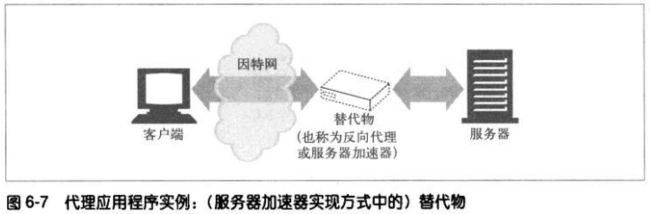
**内容路由器
代理可以根据因特网流量状况以及内容类型将请求导向特定的WEB服务器。
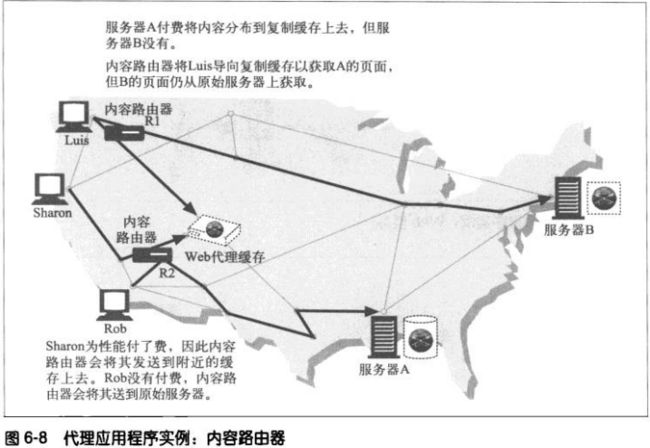
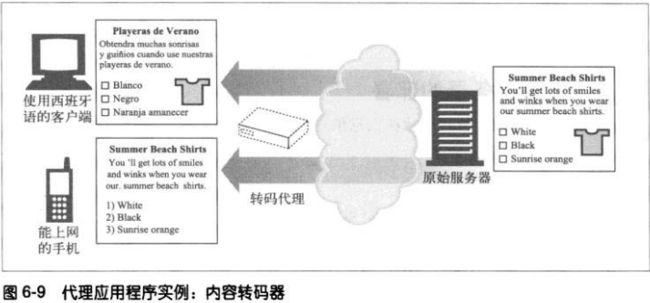
**转码器
代理服务器在将内容发给客户端之前,可以修改内容的主体格式。在这种数据表
示法之间进行的透明转换被称为转码。
转码代理可以在传输GIF图片时将其转换成JPEG图片,也可以对图片进行压缩,
或降低颜色的色彩饱和度以便在电视上看。也可以对文本文件进行压缩,甚至可
以在传输文档过程中将其转换成外语。
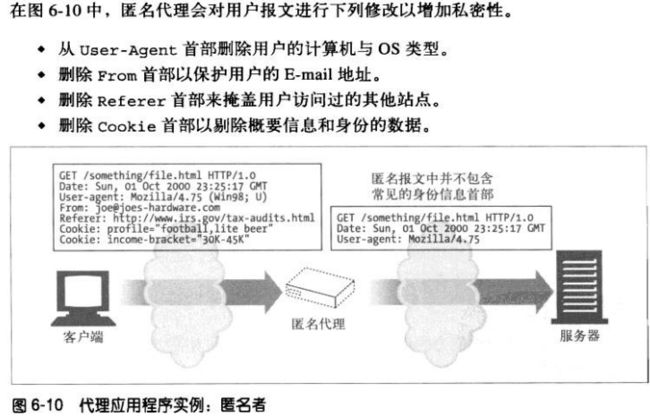
**匿名者
匿名者代理会主动从HTTP报文中删除身份特性(客户端IP,From首部、
Referer首部、cookie、URI的会话ID),从而提供高度的私密性和匿名性。
(但是由于删除了识别信息,用户浏览体验可能会下降,有些WEB站点可能无法
正常工作)
6.3 代理会去往何处
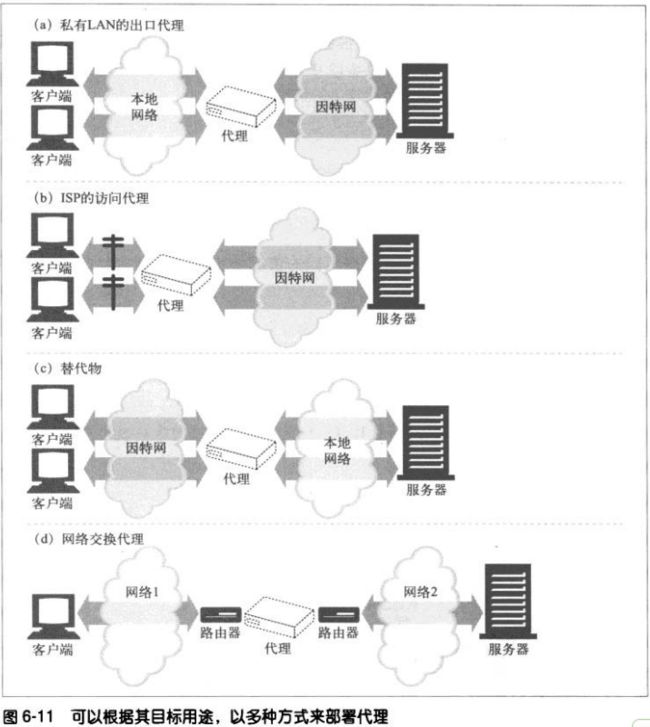
6.3.1 代理服务器的部署
**出口代理
将代理固定在本地网络的出口点,以便控制本地网络与Internet之间的流量。
**访问(入口)代理
代理常被放在ISP访问点上,用以处理来自客户的聚合请求。ISP使用缓存代理
来存储常用的文档副本,以提高用户的下载速度。
**反向代理
代理常被部署在网络边缘,在WEB服务器之前,作为反向代理使用,在那里
它们可以处理所有传送给web服务器的请求。并只在必要时向WEB服务器请
求资源。反向代理可以提高web服务器的安全性,或者将快速的web服务器缓
存存放在较慢的服务器之前,提高性能。反向代理通常会直接冒用web服务器
的名字和IP地址,这样所有的请求就会被发送给代理而不是服务器了。
**网络交换代理
将具有足够处理能力的代理放在网络之间的Internet对等交换点上,通过缓存
来减轻Internet节点的拥塞,并对流量进行监视。
6.3.2 代理的层次结构
可通过代理层次结构(proxy hierarchy)将代理级联起来。在层次结构中,会
将报文从一个代理传给另一个,直到原始服务器,在通过代理传回客户端。
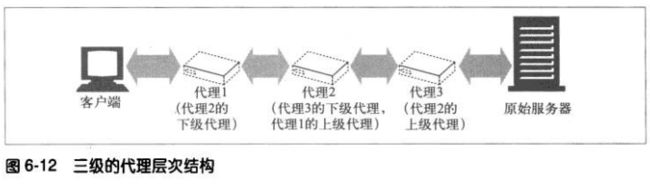
层次结构中的代理服务器被赋予了父和子的关系。靠近服务器的的被称作父代
理,靠近客户端的被称作子代理。
代理层次结构的内容路由
层次不一定都是静态,代理服务器可以根据众多因素,将报文转发给一个不断
变化的代理服务器和原始服务器集。
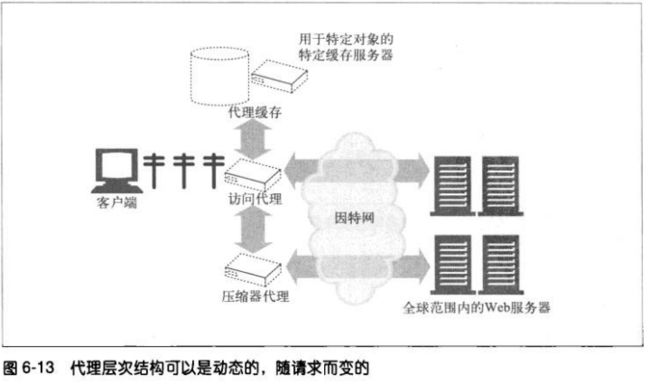
**负载均衡
子代理可能会根据当前父代理上的工作负载级别来决定如何选择一个父代
理
**地理位置附近的路由
子代理可能会选择负责原始服务器所在物理区域的父代理。
**协议/类型路由
子代理可能会根据URI将报文转发到不同的父代理和原始服务器上去。某些
特定类型的URI可能要通过一些特殊的代理服务器转发请求,以便进行特殊
的协议处理。
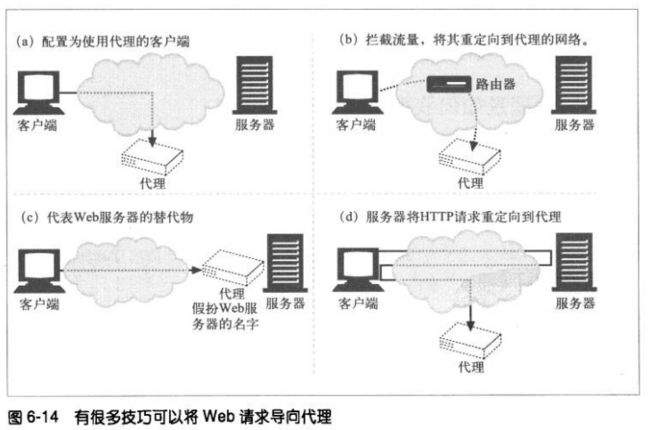
6.3.3 代理如何获取流量
①修改客户端
很多web客户端,包括网景和微软的浏览器,都支持手动和自动的代理配置。
②修改网络
网络基础设施通过各种手段将网络流量导入代理
③修改DNS的命名空间
手工编辑DNS名称列表,或者用特殊的动态DNS服务器根据需要来确定适当
的代理或服务器。
④修改服务器
通过重定向
6.4 客户端的代理设置
手工配置
预先配置浏览器
代理的自动配置(提供一个URI,指向JavaScript编写的配置文件,客户端取回这个
文件,并运行以决定是否使用代理以及使用哪个代理)
WPAD的代理发现(Web Proxy Autodiscovery Protocol)
6.4.1 手工配置
6.4.2 客户端代理配置:PAC文件
PAC文件是一些小的JavaScript程序,可以在运行过程中计算代理设置。访问每
个文档时,JavaScript函数都会选择恰当的代理服务器。
要使用PAC文件,就要用JavaScript PAC文件的URI来配置浏览器(与手工配置
类似,但要在“automatic configuration”框中提供一个URI)。浏览器会从这
个URI获取PAC文件,并用JavaScript逻辑为每次访问计算恰当的代理服务器。
PAC文件后缀通常是.pac,MIME类型为 application/x-ns-proxy-autoconfig

6.4.3 客户端代理配置:WPAD
WPAD协议的算法会使用发现机制和逐级上升策略为浏览器查找合适的PAC文
件。实现WPAD协议的客户端需要:
用WPAD找到PAC的URI
从指定的URI获取PAC文件
执行PAC 文件来判定代理服务器
为请求使用代理服务器
WPAD会使用一系列的资源发现技术来判定适当的PAC文件。当前的WPAD协议
规范按顺序定义了下列技术:
动态主机配置协议(Dynamic Host Configuration Protocol,DHCP)
服务定位协议(Service Location Protocol ,SLP)
DNS知名主机名
DNS SRV记录
TXT记录中的DNS服务器URI
6.5 与代理请求有关的一些棘手问题
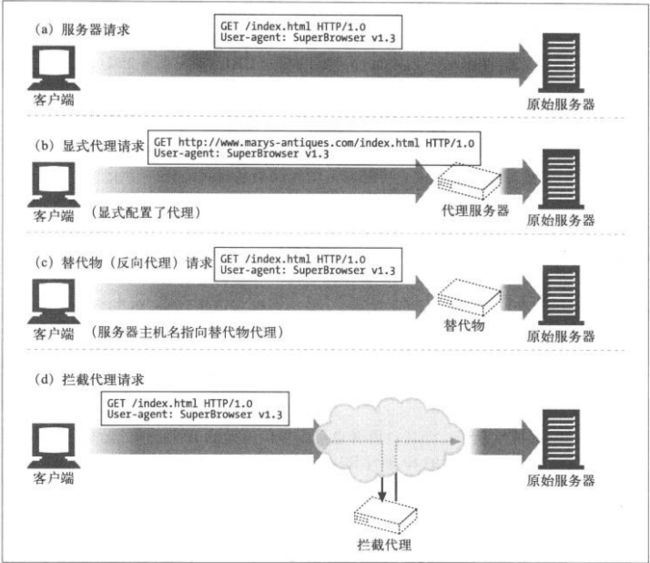
6.5.1 代理URI与服务器URI的不同
客户端向服务器发送请求时,请求行中只包含部分URI(没有协议、主机或端
口),如下图:

但客户端向代理发送请求时,请求行中则包含完整的URI。如:

在原始的HTTP设计中,客户端会直接与单个服务器进行对话。不存在虚拟主
机,也没有为代理制定什么规则。单个服务器都知道自己的主机名和端口,所
以,为了避免发送冗余信息,客户端只需给出部分URI即可。
代理出现后,使用部分URI就有问题了。代理需要知道目标服务器的名称,这
样它们才能自己建立自身与服务器的连接。基于代理的网关要知道URI的协议
才能连接到FTP资源和其他协议上去。
6.5.2 与虚拟主机一样的问题
代理缺少协议、主机、端口的问题与虚拟主机服务器面临的问题相同。但是解
决方案却有所不同。
**显式的代理要求在请求报文中使用完整的URI来解决这个问题;
**虚拟主机要求使用Host首部来承载主机和端口信息。
6.5.3 拦截代理会收到部分URI
只要客户端正确地实现了HTTP,它们就会在请求中包含完整的URI,发送给
经过显式配置的代理。这样就解决了部分问题。但是,客户端并不总是知道自
己在与代理进行对话,因为有些代理对于客户端是不可见的。客户端的流量可
能经过反向代理或者拦截代理。这两种情况下,客户端都会认为它在与WEB
服务器进行对话,不会发送完整的URI。
6.5.4 代理既可以处理代理请求,也可以处理服务器请求
由于将流量重定向到代理服务器的方式有所不同,通用的代理服务器应该同时
支持完整URI和部分URI。使用规则如下:
**如果是完整URI,代理就应该是这个完整URI
**如果提供的是部分URI,而且有HOST首部,就应该用HOST首部来确定
原始服务器的名字和端口号
**如果是部分URI且没有host首部
##若代理是反向代理,可以用真实的服务器地址和端口号来配置代理
##若流量被拦截,且拦截者可以提供原始的IP地址和端口,代理就可以
使用拦截技术提供的IP地址和端口号
##所有方法都失败了,代理没有足够信息来确定原始服务器,就必须返
回一条错误报文
6.5.5 转发过程中对URI 的修改
代理服务器要在转发报文时修改请求URI的话,需要特别小心,对URI的微小
修改,甚至是看起来无害的修改,都可能给下游服务器带来一些互操作性问
题。
特别是,HTTP规范禁止一般的拦截代理在转发URI时重写其绝对路径部分。
唯一的例外是可以用“/” 来取代空路径。
6.5.6 URI的客户端自动扩展和主机名解析
没有代理时,浏览器会获取你输入的URI,尝试着寻找响应的IP地址。如果找
到了主机名,浏览器会尝试相应的IP地址直到获取成功的连接为止。
但是,如果没有找到主机,很多浏览器会尝试某种主机名自动“扩展”机制。
6.5.7 没有代理时URI的解析
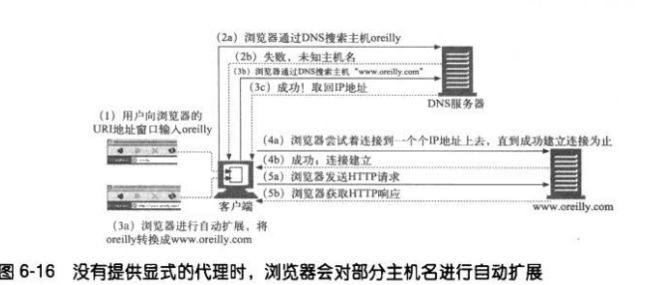
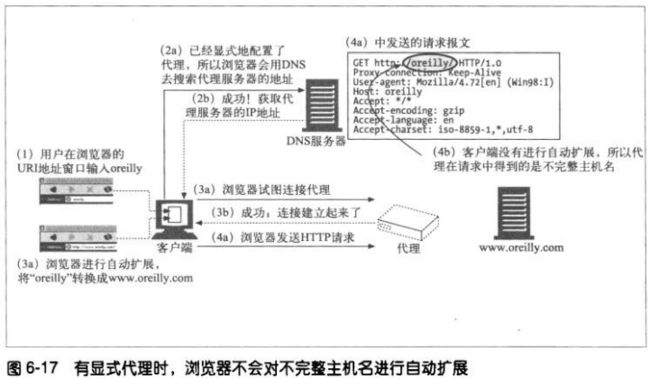
6.5.8 有显式代理时URI的解析
使用显式代理时,用户URI会直接发送给代理,浏览器就不再执行所有这些便
捷的扩展功能了。
6.5.9 有拦截代理时URI的解析
使用不可见的拦截代理时,对主机名的解析会略有不同,因为对客户端来说,
是没有代理的!这种情况下的行为与使用服务器的情形很类似,浏览器会自动
扩展主机名,知道DNS成功为止。建立到服务器的连接时有一个很重要的区
别。

6.6 追踪报文
由于代理的使用,我们需要能追踪经过代理的报文流,以检测出各种问题。
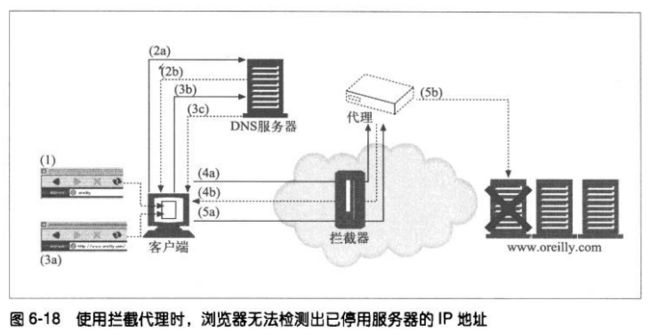
6.6.1 Via首部
Via首部字段列出了与报文途径的每个中间节点(代理或网关)有关的信息。

代理也可以用Via首部来检测网络中的路由环路。代理应该在发送一条请求之前,
在Via首部插入一个与其自身有关的独特字符串,并在输入的请求中查找这个字符
串,以检测网络中是否存在路由环路。
1、Via的语法
Via首部字段包含一个由逗号分隔的路标(waypoint)。每个路标都表示一个独立
的代理服务器或网关,且包含与那个中间节点的协议和地址有关的信息。

Vi首部的正规语法如下:

**协议名
中间节点收到的协议。如果协议为HTTP,协议名就是可选的。否则,要在版本
之前加上协议名,中间用“/”分隔。网关将HTTP请求连接到其他协议时,可
能会使用非HTTP协议。
**协议版本
所受到的报文版本。版本的格式与协议有关。
**节点名
中间节点的主机和可选端口号(若没有就使用默认的)。某些情况下,可以用
一个假名来代替。
**节点注释
进一步描述这个节点的可选注释。
2、Via的请求和响应路径
请求和响应报文都会经过代理传输,因此,请求和响应报文中都要有Via首部。
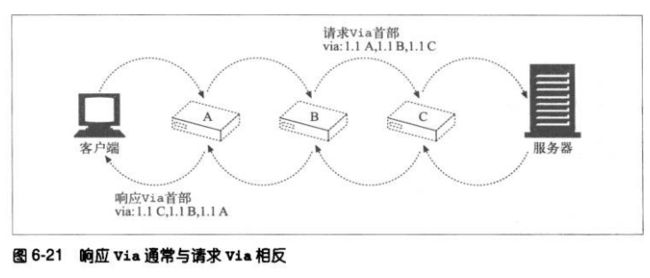
3、Via与网关
有些代理会为使用非HTTP协议的服务器提供网关功能,Via首部记录了这些协议转
换。
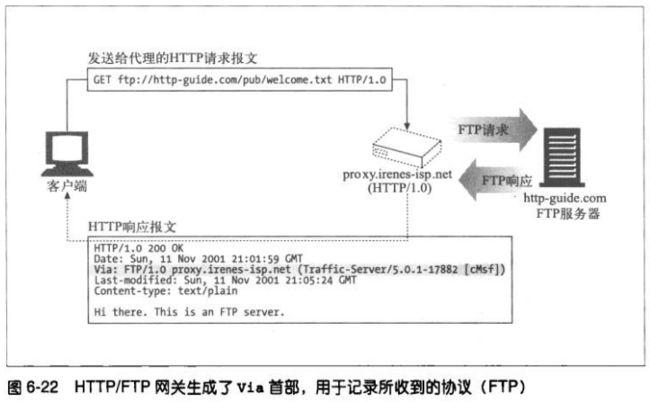
4、Via首部和Server
Server响应首部字段对原始服务器使用的软件进行了描述。
如果响应报文是通过代理转发,一定要确保代理没有修改Server首部。Server首部
是用于原始服务器的,代理应该添加的是Via首部。
5、Via的隐私和安全问题
对那些需要隐藏内部网络的组织来说,代理应该将一个(接受协议值相同的)有序
Via路标条目序列合并成一个联合条目。

除非这些条目都在同一个组织的控制下,而且已经用了假名取代了主机名,否则不
能合并。同样,接收协议值不同的条目也不能合并。
6.6.2 TRACE方法
当TRACE请求到达目的服务器时,整条请求报文都会被封装在一条HTTP响应的主
体中回送给发送端。当TRACE响应到达时,客户端可以检查服务器收到的确切报
文,已经所经过的代理列表。TRACE响应的Content-Type为 message/http,状态
为200 OK。
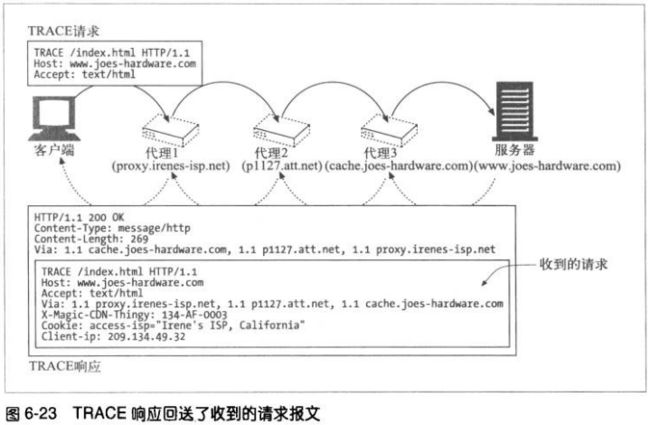
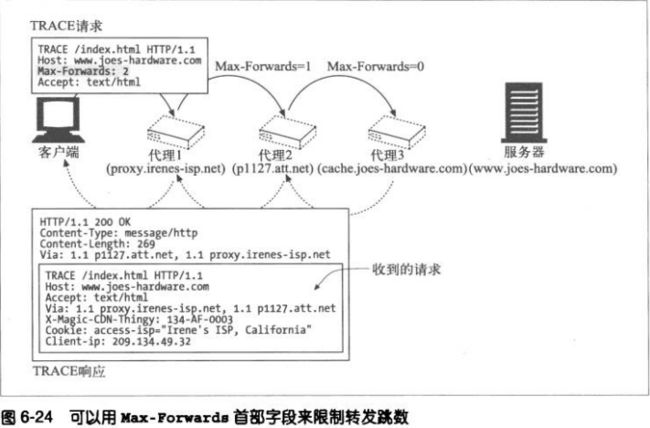
Max-Forwards首部可以来限制TRACE和OPTIONS请求所经过的代理跳数,可用
来测试是否报文出现无限循环,或者查看链中特定代理服务器的效果。
Max-Forwards请求首部包含了一个整数,用来说明这条请求报文还可以被转发的
次数。若为零,那么接收者即使不是服务器,也必须将TRACE报文回送客户端
6.7 代理认证
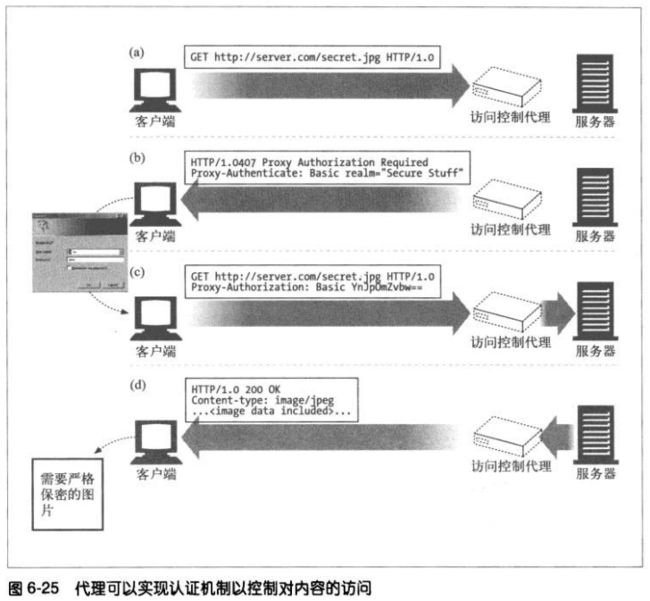
代理可作为访问控制设备使用。HTTP定义了一种名为代理认证的机制,这种机制可
以阻止对内容的请求,直到用户向代理提供了有效的访问权限证书为止。
##对受限内容的请求到达一台代理服务器时,代理服务器可以返回一个要求使用访
问证书的407 Proxy Authnenticate Required状态码,以及一个用于描述怎样提
供这些证书的Proxy-Authenticate首部字段。
##客户端收到407响应,会尝试从本地数据库中,或通过提示用户来搜集所需证书
##只要获得了证书,客户端就会重新发请求,在Proxy-Authentication首部字段提
供证书
##若证书有效,代理会将请求沿着链路往下传送,否则返回另一条407应答
6.8 代理的互操作性
6.8.1 处理代理不支持的首部和方法
代理必须对不认识的首部字段进行转发,而且必须维持同名首部字段的相对顺
序。若代理不熟悉某个方法,只要有可能,就应该尝试着将报文转发到下一跳节
点上去。
6.8.2 OPTIONS: 发现对可选特性的支持
通过OPTIONS方法,客户端或代理可以发现服务器或其上某个特定资源所支持的
功能。通过这个方法,客户端可以在与服务器进行交互之前,确定服务器的能
力,这样就可以更方便地与具备不同特性的代理和服务器进行互操作了。
如果OPTIONS请求的URI是个星号(*),请求的就是整个服务器所支持的功能。
如果URI是个实际资源地址,OPTIONS请求就是在查询那个资源的可用特性。如
果成功,OPTIONS方法就会返回一个包含了各种首部字段的200 OK响应。
HTTP/1.1在响应中唯一指定的首部字段是Allow首部,这个首部用于描述服务器
所支持的各种方法。
6.8.3 Allow首部
Allow实体首部字段列出了请求URI标识的资源所支持的方法,若是星号,则是整
个服务器所支持的方法列表。可以将Allow首部作为请求首部,建议在新的资源上
支持某些方法,但应该在相应的响应中包含一个Allow首部,列出它实际支持的方
法。代理不能对Allow首部字段进行修改。
第七章 缓存
WEB缓存是可以自动保存常见文档副本的HTTP设备。
缓存减少了冗余的数据传输;缓解了网络瓶颈问题,不需要更多带宽就能更快加载页面;降低了对原始服务器的要求;降低了距离延时。
7.1 冗余的数据传输
7.2 带宽瓶颈
本地网络带宽比远程服务器提供的带宽要宽。
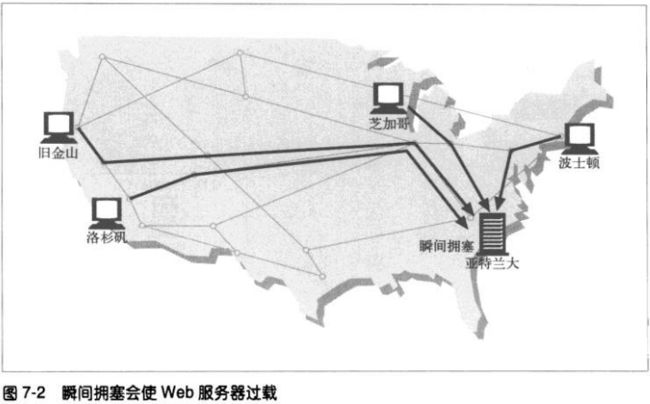
7.3 瞬间拥塞(Flash Crowds)
7.4 距离延时
每台路由器都会增加流量的延时,光速自身也会造成延时。
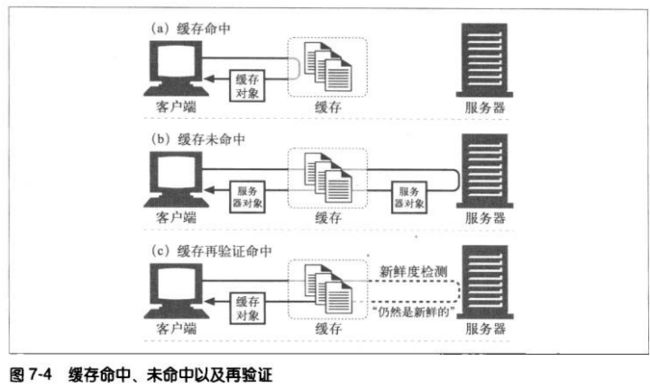
7.5 命中和未命中的
可以用已有的副本为某些到达缓存的请求提供服务。称为缓存命中(cache hit),
其他请求由于没有副本可用而不转发给服务器,称为缓存未命中(cache miss)
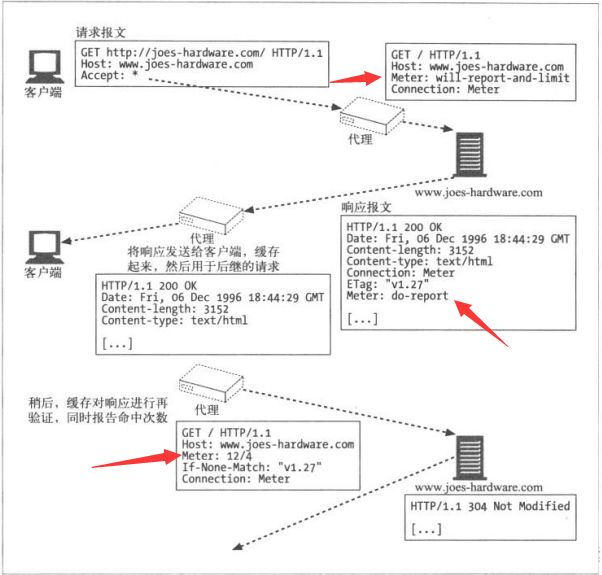
7.5.1 再验证
缓存不时对服务器内容进行检测,称为HTTP再验证(revalidation)。为了有效
地进行再验证,HTTP定义了一些特殊的请求,不用从服务器上获取整个对象,就
可以检测出内容是否为最新。
大部分缓存只有在客户端发起请求,且副本旧得足以需要检测的时候,才会对副
本进行再验证。
缓存对缓存的副本进行再验证时,会向原始服务器发送一个小的再验证请求,若
内容无变化,会得到响应304 Not Modified。若缓存知道副本仍有效,就会再次
将副本标记为暂时新鲜,并将副本提供给客户端。这称为再验证命中或缓慢命
中。这种会比单纯的缓存命中要慢,但是比缓存未命中更快些。
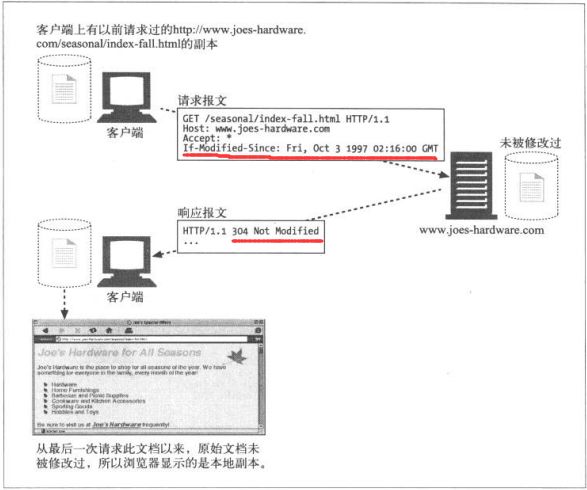
HTTP提供了几个工具用于再验证。最常用的是 If-Modified-Since首部,将这个
首部添加到GET请求中,就可以告诉服务器,只有在缓存了对象的副本后,又对
其进行了修改,才发送此对象。
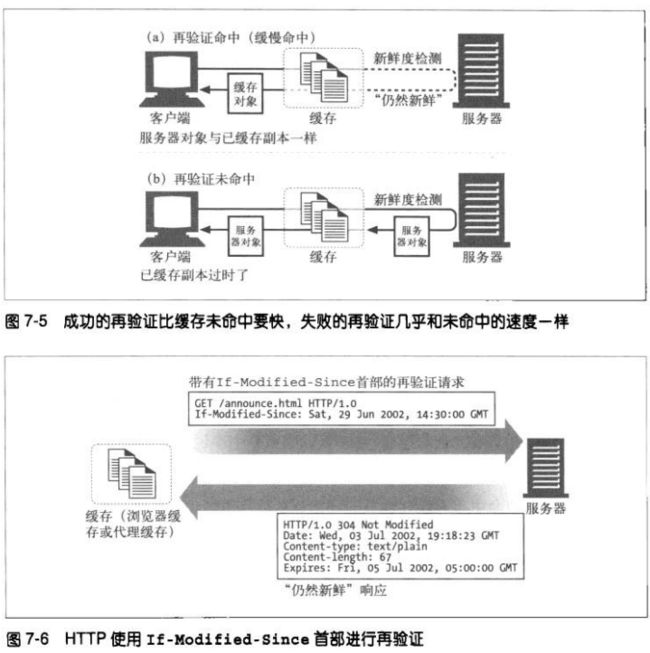
如果服务器对象与已缓存副本不同,服务器向客户的发送一条普通的带有完整内
容的HTTP 200 OK响应
若服务器对象被删除,回送404, 缓存也会将其副本删除。
7.5.2 命中率
有缓存提供服务的请求所占比例。40%的命中率对于中等规模的WEB缓存来说是
比较合理的。有时也被称为文档命中率。
7.5.3 字节命中率
由于文档并非同一尺寸,所以文档命中率不能说明一切,因此有些人更愿意用字
节命中率作为度量值。缓存提供的字节在所有字节中所占的比例。
文档命中率说明阻止了多少通往外部网络的web事务,事务有一个通常都很大的
固定时间成分,提高文档命中率对降低整体时延很有好处。提高字节命中率则可
以节省带宽。
7.5.4 区分命中和未命中的情况
HTTP并未提供一种手段来区分响应时缓存还是原始服务器的。响应码都是200
OK,有些商业代理会在Via首部添加一些额外情况来描述缓存中发生的情况。
客户端可用使用Date首部来判定,若响应中的日期比较早,客户端通常可以认为
这是一个缓存响应。
7.6 缓存的拓扑结构
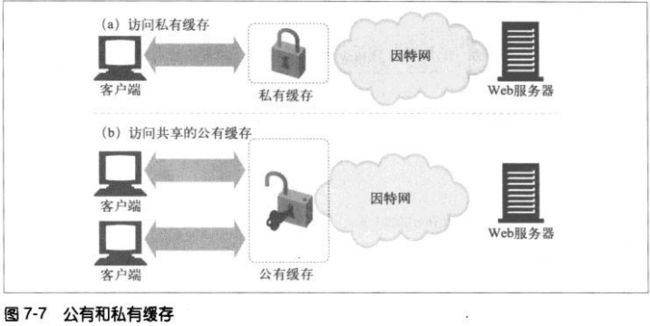
7.6.1 私有缓存
WEB浏览器一般内建有私有缓存。 chrome://cache about:cache
7.6.2 共有代理缓存
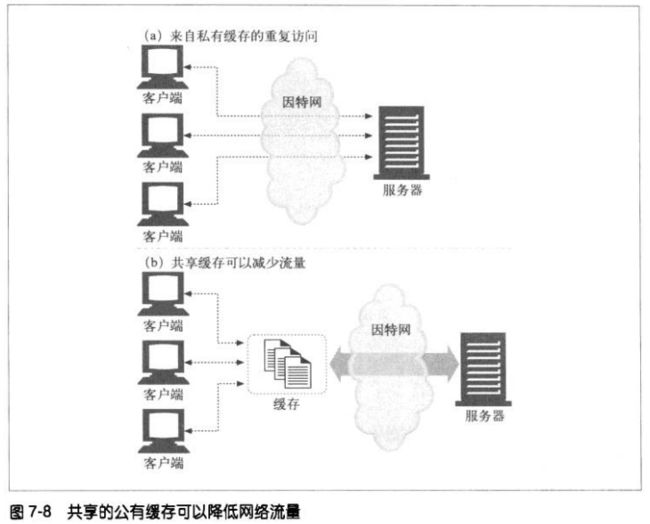
7.6.3 代理缓存的层次结构
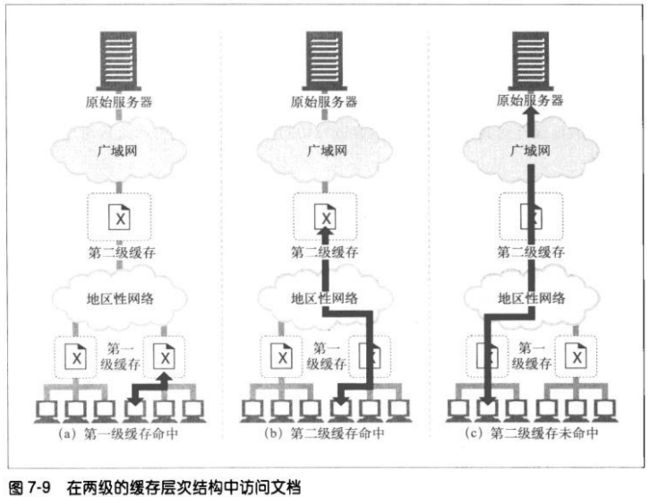
7.6.4 网状缓存、内容路由以及对等缓存
网状缓存结构中的代理更加复杂,它们做出动态的缓存通信决策,决定与哪个父
缓存进行对话,或者直连服务器。这种代理缓存会决定选择何种路由对内容进行
访问、管理和传送,因此可将其称为内容路由器。
网状缓存中为内容路由设计的缓存需要完成:
根据URL动态选择父缓存或服务器
根据URL动态选择一个特定父缓存
前往父缓存之前,在本地搜索已缓存的副本
允许其他缓存对其缓存的部分内容进行访问,但不允许因特网流量通过它们的
缓存
缓存之间这些更为复杂的关系允许不同的组织互为对等实体,将它们的缓存连接
起来以实现共赢。提供可选的对等支持的缓存被称为兄弟缓存(sibling
cache)。HTTP并不支持sibling cache,所以通过一些协议进行扩展,比如因特
网缓存协议(Internet Cache Portocol,ICP)和超文本缓存协议(HyperText
Caching Protocol,HTCP).
7.7 缓存的处理步骤
接受–解析–查询—新鲜度检测–创建响应–发送–日志
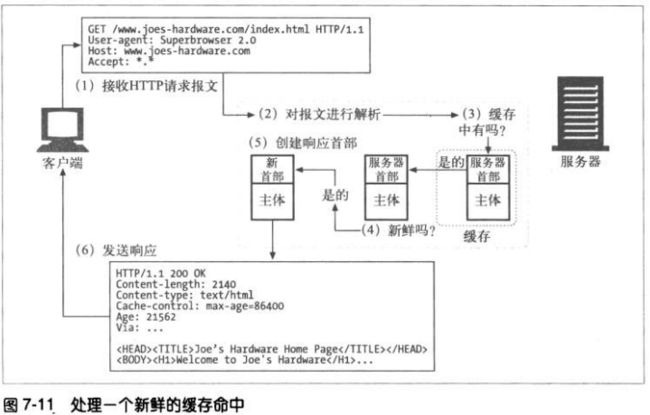
创建响应时,缓存将已缓存服务器的响应首部作为起点,然后进行修改和扩充。比
如修改HTTP/1.0为 HTTP/1.1。缓存还会加入新鲜度信息(Cache-Control、Age以
及Expires首部),而且通常会有一个Via首部来说明请求由一个代理缓存提供的。
但是,缓存不应该调整Date首部。Date首部表示的元素服务器最初产生这个对象的
日期。
7.8 保持副本的新鲜
7.8.1 文档过期
通过特殊的HTTP Cache-Control首部和Expires首部,HTTP让原始服务器向每
个文档附加了一个“过期日期”。

7.8.2 过期日期和使用期
服务器用HTTP/1.0+的Expires首部或HTTP/1.1 的Cache-Control:max-age响
应首部来指定过期日期。由于Cache-Control首部使用的是相对日期而不是绝对
日期,所以我们倾向于使用比较新的Cache-Control首部。绝对日期依赖于计算
机时钟的正确设置。

7.8.3 服务器再验证
仅仅是已缓存文档过期了并不意味着它和原始服务器上目前处于活跃状态的文档
有实际的区别;这只是意味着到了要进行核对的时间了。这种情况称为“服务器
再验证“。
—-如果再验证显示内容发生了变化,缓存会获取一份新的文档副本,并将其存储
在旧文档的位置上,然后发送给客户端。
—-若再验证显示没有变化,缓存只需要获取新的首部,包括一个新的过期日期,
并对缓存中的首部进行更新。
若原始服务器不可访问,但缓存需要再验证,那么缓存必须返回一条错误或用来
描述通信故障的警告报文。否则,来自已经移除的服务器上的页面可能在缓存中
存留任意长时间。
7.8.4 用条件方法进行再验证
HTTP的条件方法可以高效的实现再验证。
HTTP定义了5个条件请求首部。再验证最有用的2个首部是If-Modified-Since和
If-None-Match。其他分别是:If-Unmodified-Since(在进行部分文件的传输
时,获取文件的其余部分之前要确保文件未发生变化)、If-Range(支持对不完
整文档的缓存)、If-Match(用于与WEB服务器打交道时的并发控制)

7.8.5 If-Modified-Since:Date再验证
IMS请求,只有在某个日期之后资源发生了变化,IMS请求才会指示服务器执行请
求。
—-若在指定日期之后,文档未被修改,条件为假,向客户的返回一个小的304响
应报文,但是只会返回那些需要在源端更新的首部。比如Content-Type首部通常
不会被修改,所以一般不会发送。
If-Modified-Since首部可以与Last-Modified服务器响应首部配合工作。
注意:有些服务器并未将If-Modified-Since作为真正的日期来比对。相反,它们
在IMS日期和最后修改日期间进行字符串匹配。这样得到的语义就是“如果最后
的修改不是在这个确定的日期进行的“,而不是”如果在这个日期之后没有被修
改过“。
7.8.6 If-None-Match:实体标签再验证
有些情况仅使用最后修改日期进行再验证时不够的。
—-有些文档可能会周期性重写(比如从一个后台进程中写入),但实际包含的数
据常常是一样的,但是日期会变化。
—-有些文档的修改并不重要,不需要让全世界范围内的缓存都重装数据(比如对
拼写或注释的修改)。
—-有些服务器无法准确的判断其页面的最后修改日期
—-有些服务器提供的文档会在亚秒间隙发生变化,这样一来,以一秒为粒度的修
改日期可能就不够用了
为解决这些问题,HTTP允许用户对被称为实体标签(ETag)的“版本标识
符”进行比较。当发布者对文档进行修改时,可以修改文档的实体标签来说明这
个新的版本。这样如果实体标签被修改了。缓存就可以用If-None-Match来GET
文档的新副本了。
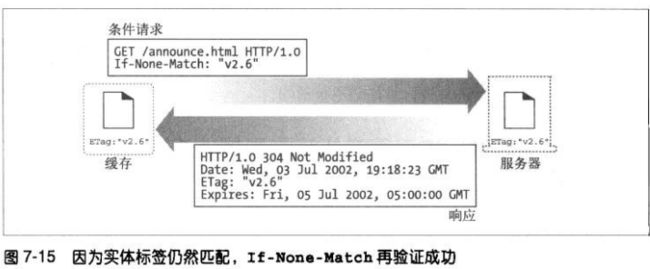
可以在If-None-Match首部包含几个实体标签,来告诉服务器,带有这些实体标
签的对象副本在缓存上已经有了:

7.8.7 强弱验证器
有时,服务器希望在对文档进行一些非实质性或不重要的修改时,不要使所有的
已缓存副本都失效。HTTP/1.1 支持“弱验证器”,如果只对内容进行了少量修
改,就允许服务器声明那是“足够好”的等价体。
服务器用”W/”来标识弱验证器。
ETag: W/”v2.6”
If-None-Match: W/”V2.6”
不管相关实体以何种方式变化,强实体标签都要发生变化,而相关实体在语义上
发送了比较重要的变化时,弱实体标签也应该发送变化。
7.8.8 什么时候应该使用实体标签和最近修改日期
若服务器回送实体标签,客户端就必须使用实体标签验证器。若服务器只返回
Last-Modified值,客户端就可以使用If-Modified-Since验证。若服务器两种都
提供了,客户端就应该使用两种验证方案。
如果HTTP/1.1 缓存或服务器收到的请求带有两种验证首部,那么只有当两个条件
都满足时,才能返回304响应。
7.9 控制缓存的能力
服务器可以通过HTTP定义的几种方式来指定在文档过期之前可以将其缓存多长时
间。按照优先级递减的顺序,服务器可以:
附加Cache-Control:no-store 首部到响应
no-cache
must-revalidate
max-age
附件一个Expires日期到响应
7.9.1 no-Store 与 no-Cache响应首部
这两个首部可以防止缓存提供未经证实的已缓存对象:
标识为no-store的响应会禁止缓存对响应进行复制。缓存通常会像非缓存代理服
务器一样,向客户转发一条no-store响应,然后删除对象。
标识为no-cache的响应实际上是可以存储在本地缓存区中的。只是在与原始服务
器进行新鲜度再验证之前,不能将其提供给客户端使用。
HTTP/1.1 提供pragma:no-cache首部是为了兼容于HTTP/1.0+。

7.9.2 max-age响应首部
这个首部表示从服务器将文档传来开始,可以认为此文档处于新鲜状态的秒数。
还有一个s-maxage,与max-age类似,但是仅适用于共享缓存。
服务器可以请求缓存不要缓存文档,或将其最大使用期设置为0。
7.9.3 Expires响应首部
不推荐适用这个首部,它指定的是实际过期日期而不是秒数。因为很多服务器的
时钟都不同步。
7.9.4 must-revalidate响应首部
可以配置缓存,使其提供一些过期的对象,以提高性能。如果服务器希望缓存严
格遵守过期信息,可以在原始响应中附加Cache-Control: must-revalidate首
部。这个响应首部告诉缓存,在事先没有跟原始服务器进行再验证的情况下,不
能提供这个对象的过期副本。缓存仍可以任意提供新鲜副本。如果在缓存进行
must-revalidate新鲜度检查时,原始服务器不可用,缓存就必须返回一条504
Gateway Timeout错误。
7.9.5 试探性过期
若响应中没有任何关于过期的首部。缓存可以计算出一个试探性最大使用期。可
以使用任意算法,但是如果得到的最大使用期大于24小时,就应该向首部添加一
个Heuristic Expiration Warning (试探性过期警告,警告13)首部。实际很少有
浏览器为用户提供这种告警信息。
LM-Factor算法是一种常用的试探性过期算法,如果文档中包含了最后修改日
期,就可以使用这种算法。
—-如果文档最后一次修改发生在很久以前,那么可能是一份稳定的文档,因此将
其继续保存在缓存中比较安全。若是最近被修改过,说明它可能频繁发生变化,
因此在与服务器进行再验证之前,应该只缓存很短一段时间。
实际的这个算法会计算缓存与服务器对话的时间跟服务器声明文档最后被修改的
时间的差值,取这个间隔时间的一部分,将其作为缓存中新鲜度持续时间。

如果连最后修改日期也没有的话,缓存通常会设置一个默认的一小时或一天,有
的缓存会设置为0。
7.9.6 客户端的新鲜度限制
web浏览器都有Refresh(刷新)或Reload按钮,可以强制对浏览器或代理缓存
中可能过期的内容进行刷新。Refresh按钮会发布一个附加了Cache-Control请求
首部的GET请求,但是其具体行为取决于特定的浏览器、文档以及拦截缓存的配
置。
7.10 设置缓存控制
7.10.1 控制Apache的HTTP首部
mod_headers
通过这个模块可以对单独的首部进行设置。装载了这个模块,就可以用设置单个
HTTP首部的指令来扩充Apache的配置文件了。
下面这个例子将某目录下所有HTML文件都标识为非缓存的:

mod_expires
这个模块提供的程序逻辑可以自动生成带有正确过期日期的Expires首部。通过这
个模块可以为不同的文件类型设置不同的过期日期,还可以使用便捷的冗长描述
信息。

7.10.2 通过HTTP-EQUIV控制HTML缓存
HTML 2.0定义了标签,这个可选标签位于HTML文档顶部,
定义了与该文档有关的HTTP首部。

最初,这个标签是给服务器使用的,但是这个特性会增加服务器的负担,这些值
也只是静态的,而且只支持HTML,不支持很多其他文件类型,所有很少有服务
器和代理支持此特性。

7.11 详细算法
7.11.1 使用期和新鲜生存期
为了分辨已缓存的文档是否足够新鲜,缓存只需要计算两个值:已缓存副本的使
用期(age)和已缓存副本的新鲜生存期(freshness lifetime)。如果已缓存副
本的时长小于新鲜生存期,说明足够新鲜。
文档的使用期就是自从服务器将其发送出来(或最后一此被服务器再验证)之
后“老去”的总时间。
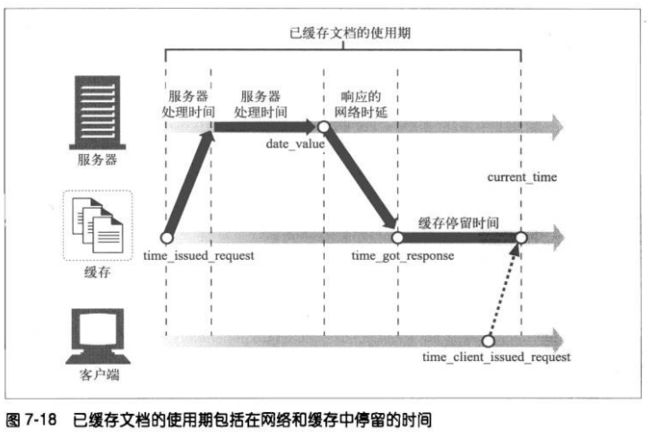
7.11.2 使用期的计算
响应的使用期就是服务器发布响应(或服务器对其进行再验证)之后经过的总时
间。 包括响应在网络和网关中游荡的时间,在中间缓存中存储的时间,以及响应
在你的缓存中停留的时间。
1、表面使用期是基于Date首部的
web应用程序,尤其是缓存代理,要做好与时间值有很大差异的服务器进行交互
的准备,这个问题被称为“时钟偏差”。如果使用期是负的,就将其置为零。
2、逐跳使用期的计算
这样就可以去除时钟偏差造成的负数使用期了。文档经过代理和缓存时,
HTTP/1.1会让每台设备豆浆相对使用期累加到Age首部中,用来解决缺乏通用同
步时钟的问题。但是非HTTP/1.1 的设备无法识别Age首部。
3、对网络时延的补偿
Date首部说明了文档是在什么时候离开原始服务器的,单并未说明文档在到缓存
的传输过程中花费了多长时间。缓存知道它请求文档的时间以及文档抵达的时
间。HTTP/1.1会在这些网络时延上加上整个往返时延,以便对其进行保守的校正
7.11.3 完整的使用期计算方法
7.11.4 新鲜生存期计算
新鲜生存期取决于服务器和客户端的限制。
第八章 集成点:网关、隧道及中继
8.1 网关
网关可以作为某种翻译器使用,它抽象出了一种能到到达资源的方法。应用程序可以(通
过HTTP或其他已经定义的接口)请求网关来处理某条请求,网关可以提供一条响应。网
关可以向数据库发送查询语句,或者生产动态内容。
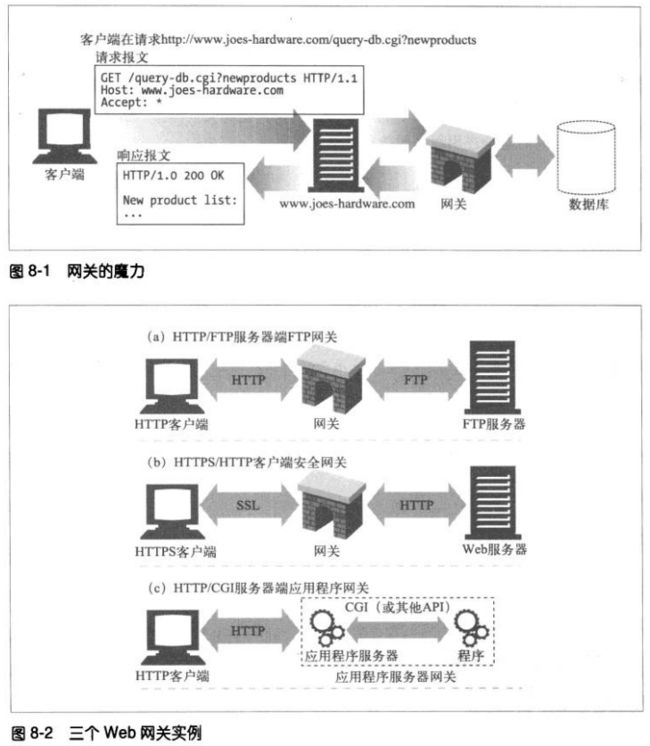
web网关在一侧使用HTTP协议,在另一侧使用另一种协议。
可以用一个斜杠来分隔客户端和服务器端协议,并以此对网关进行描述:
<客户端协议>/<服务器端协议>
因此,将HTTP客户端连接到NNTP新闻服务器的网关就是一个HTTP/NNTP网关。
服务器端网关通过HTTP与客户端对话,通过其他协议与服务器通信(HTTP/*)
客户端网关通过其他协议与客户端对话,通过HTTP与服务器通信(*/HTTP)
8.2 协议网关
将HTTP流量导向网关时所使用的方式与将流量导向代理的方式相同。最常见的方式是显
式的配置浏览器使用网关,对流量进行透明拦截,或者将网关配置为反向代理。
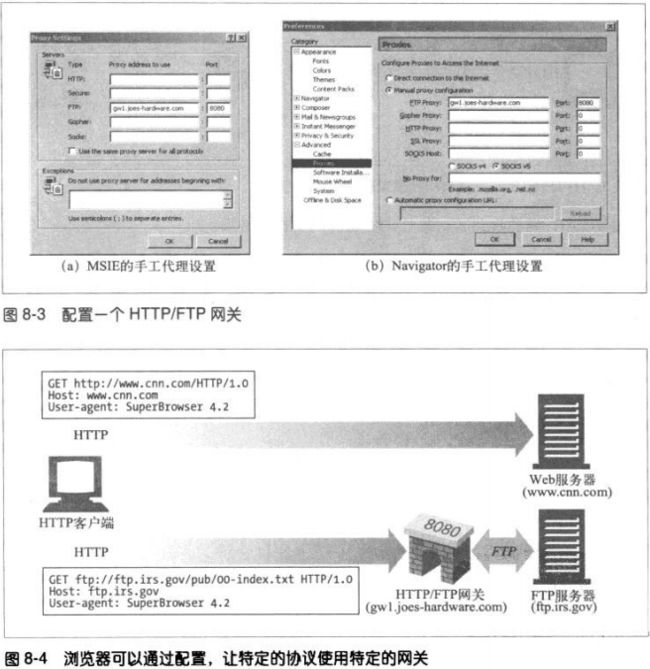
8.2.1 HTTP/*:服务器端web网关
请求流入原始服务器,服务器端web网关会将客户端HTTP请求转换为其他协议。

8.2.2 HTTP/HTTPS:服务器端安全网关
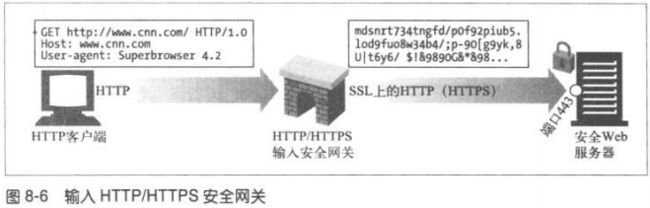
8.2.3 HTTPS/HTTP:客户端安全加速器网关
这些网关位于web服务器之前,通常作为不可见的拦截网关或反向代理使用。
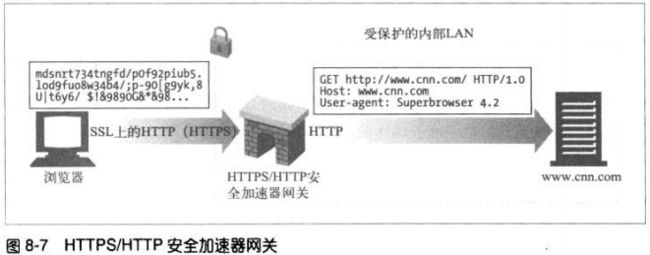
这些网关通常包含专用的解密硬件,比原始服务器更加有效,减轻服务器的负荷。
8.3 资源网关
最常见的网关–应用程序服务器,会将目标服务器与网关结合在一个服务器中实现。应用
程序服务器是服务器端网关,与客户端通过HTTP通信,并与服务器端的应用程序相连。
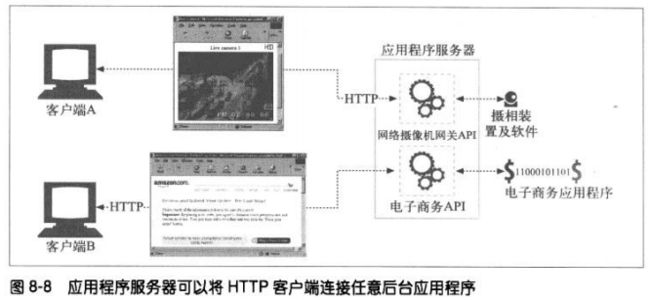
如上图,应用程序服务器并未回送文件,而是将请求通过一个网关应用编程接口
(Application Programming Interface,API)发送给运行在服务器上的应用程序。
第一个流行的应用程序网关API就是通用网关接口(Common Gateway Interface,
CGI),CGI是一个标准接口集,web服务器可以用它来装载应用程序以响应对特定URL
的HTTP请求,并收集程序的输出数据,将其放置HTTP响应中回送。
8.3.1 CGI
CGI应用程序是独立于服务器的。它的处理对用户来说是不可见的。它在服务器和众多
资源类型直接提供了一种简单的、函数形式的粘合方式,用来处理各种需要的转换。
这个接口还能很好的保护服务器。但是这种分离会造成性能的耗费,为每条CGI请求引
发一个新进程的开销是很高的,会限制那些使用了CGI的服务器的性能。为此,人们开
发了快速CGI,它会作为持久守护进程运行,消除了为每个请求建立或拆除新进程所带
来的性能损耗。
8.3.2 服务器扩展API
服务器扩展API为web开发者提供了强大的接口,以便他们将自己的模块与HTTP服务
器直接相连。扩展API允许程序员将自己的代码嫁接到服务器上,或者用自己的代码将
服务器的一个组件完整的替换。
大多数服务器都会为开发者提供一个或多个扩展API,它们通常会绑定在服务器自身结
构上,所以大多数都是某种服务器类型特有的。
微软的FPSE(FrontPage 服务器端扩展)就是一个例子,它为使用frontpage的作者
进行web发布提供支持。FPSE能够对frontpage客户端发送的RPC(remote
porcedure call 远程过程调用)命令进行解释,这些命令会在HTTP(POST方法)上
捎回。
8.4 应用程序接口和WEB服务
随着web应用程序提供的服务越来越多,HTTP可以作为一种连接应用程序的基础软件来
使用。因特网委员会开发了一组允许web应用程序之间相互通信的标准和协议。web服务
是应用程序共享信息的一种新机制,它是构建在标准的web技术(比如HTTP)之上的。
web服务器可以用XML通过SOAP来交换信息。XML(Extensible Markup Language,扩
展标记语言)提供了一种创建数据对象的定制信息,并对其进行解释的方法。
SOAP(Simple Object Access Protocol ,简单对象访问协议)是向HTTP报文中添加
XML信息的标准方式。
8.5 隧道
WEB隧道可以通过HTTP应用程序访问使用非HTTP协议的应用程序。它允许用户通过
HTTP连接发送非HTTP流量,这样这类流量就可以穿过只允许WEB流量通过的防火墙
了。
8.5.1 用CONNECT 建立HTTP隧道
web隧道是用HTTP的CONNECT方法建立的。该方法请求隧道网关创建一条到达任意
目的的服务器和端口的TCP连接,并对客户端和服务器之后的后继数据进行盲转发。
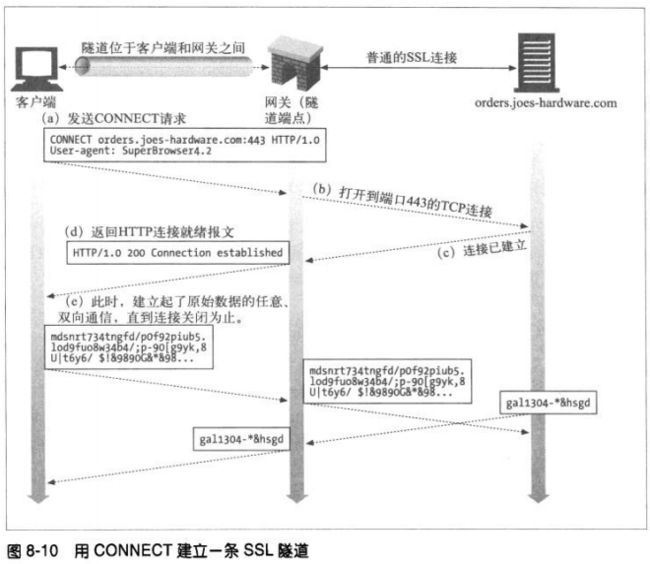
1、CONNECT请求
除了起始行,CONNECT的语法与其他HTTP方法类似。一个后面跟着冒号和端口号的
主机名取代了请求URI。主机和端口都必须指定。
2、CONNECT 响应
和普通HTTP报文一样,响应码200 表示成功。响应中的原因短语通常被设置
为“Connection Established”。与普通HTTP响应不同,这个响应不需要包含
Content-Type首部。
8.5.2 数据隧道、定时及连接管理
管道化数据对网关是不透明的,所以网关不能对分组的顺序和分组流作任何假设。一
旦隧道建立,数据就可以在任意时间流向任意方向了。隧道的两端必须做好在任意时
刻接受来自任一端分组的准备,且必须立即转发。隧道一端对数据的消耗不足可能会
将另一端的数据生产者挂起,造成死锁。
作为一种性能优化,允许客户端发送了CONNECT请求之后,接受响应之前,发送隧道
数据。这就意味着网关必须能够正确处理跟在请求之后的数据。尤其是,网关不能假
设网络I/O请求只会返回首部数据,网关必须确保在连接准备就绪时,将与首部一同读
进来的数据发送给服务器。在请求之后以管道方式发送数据的客户端,如果发现回送
的响应是认证请求,或者其他非200但不致命的错误状态,就必须做好从发请求的准
备。
如果在任意时刻,隧道的任意一个端点断开了连接,那个端点发出的所有未传输数据
都会被传送给另一端,之后,到另一端的连接也会被代理终止。如果还有数据要传输
给关闭连接的端点,数据会被丢弃。
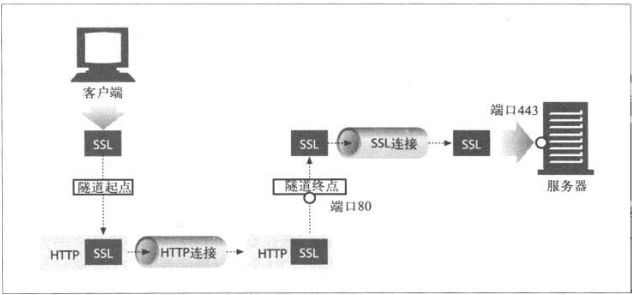
8.5.3 SSL隧道
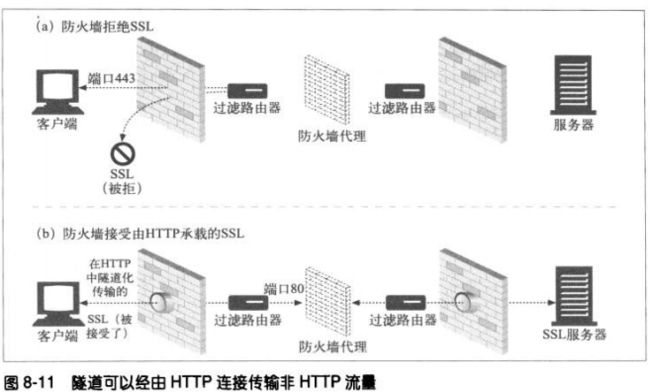
为了让SSL流量经现存的代理防火墙进行传输,HTTP中添加了一项隧道特性,在此特
性中,可以将原始的加密数据放在HTTP报文中,通过普通的HTTP信道传送。
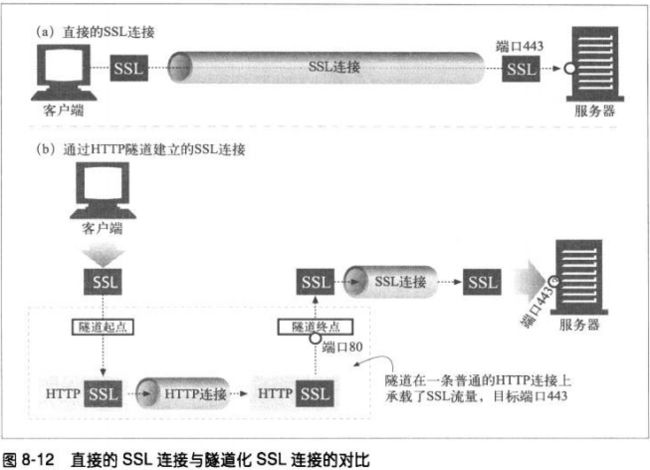
8.5.4 SSL隧道与HTTP/HTTPS网关的对比
由网关初始化与远端HTTPS服务器的SSL会话,然后代表客户端执行HTTPS事务。响应
会由代理接收并解密,然后通过不安全的HTTP传送给客户端。但是这样会由几个缺
点:
客户端到网关之间的连接是非安全的HTTP;
尽管代理是已认证主体,但是客户端无法对远端服务器执行SSL客户端认证(基于
X509证书的认证;
网关要支持完整的SSL实现。
对于SSL 隧道机制来说,无需在代理中实现SSL,SSL会话是建立在产生请求的客户端
和web服务器之间的,中间的代理只负责传输。
8.5.5 隧道认证
可以将代理的认证支持与隧道配合使用,对客户端使用隧道的权利进行认证。
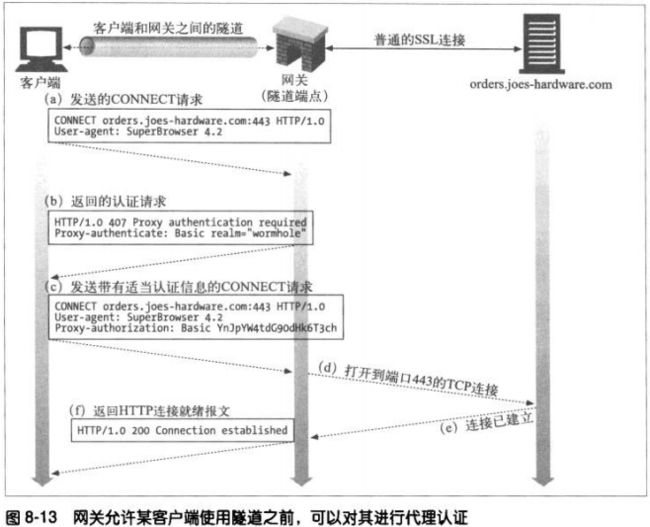
8.5.6 隧道的安全性考虑
总的来说,隧道网关无法验证目前使用的协议就是它原本打算经过隧道传输的协议。
因此,比如说,一些用户可能会通过本打算用于SSL 的隧道,越过防火墙来传递游戏
流量,而恶意用户可能会用隧道打开Tlenet会话,或用隧道绕过公司的E-mail扫描器
来发送E-mail。为降低对隧道的滥用,网关应该只为特定的端口(比如443)打开隧
道。
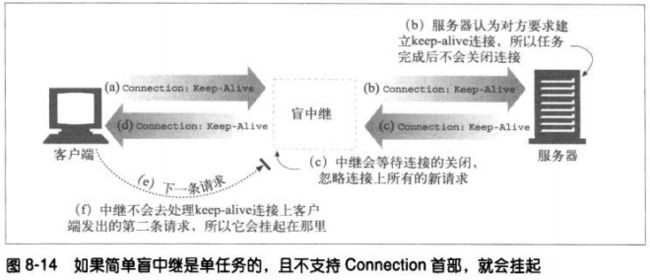
8.6 中继
HTTP中继(relay)是没有完全遵循HTTP规范的简单HTTP代理。中继负责处理HTTP中
建立连接的部分,然后对字节进行盲转发。
某些简单的盲中继实现中存在一个常见的问题是,由于它们无法正确处理Connection首
部,所以有潜在的挂起keep-alive连接的可能。
第九章 WEB机器人
WEB机器人是能在无需人类干预的情况下自动进行一系列WEB事务处理的软件程序。很多机器人会从一个站点逛到另一个站点,获取内容,跟踪超链,并对它们找到的数据进行处理。人文给它们起了一些各具特色的名字,比如“爬虫”,“蜘蛛”等。
9.1 爬虫及爬行方式
WEB爬虫是一种机器人,它们会递归地对各种信息性WEB站点进行遍历,获取第一个
web页面,然后获取那个页面指向的所有web页面,然后是那些页面指向的所有页面。
递归进行追踪这些web链接的机器人会沿着HTML超链创建的网络爬行,所以将其称为爬
虫(crawler)或蜘蛛(spider)。
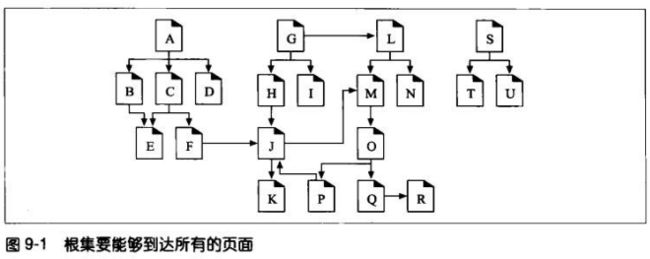
9.1.1 从哪儿开始:根集
爬虫开始访问的URL初始集合,被称作根集(root set)。挑选根集时,应该从足够多
不同的站点中选择URL。
如上图,要抵达所有页面,根集中只需要有A,G,S就可以了。
通常,一个好的根集会包括一些大的流行WEB站点,一个新创建页面的列表和一个不
经常被链接的无名页面列表。
9.1.2 链接的提取以及相对链接的标准化
爬虫在WEB上移动时,会不停地对HTML页面进行解析。主要对每个页面上的URL链
接进行分析,并将这些链接添加到需要爬行的页面列表中去。这个列表经常会迅速扩
张。爬虫要通过简单的HTML解析,将这些链接提取出来,并将相对URL转换为绝对形
式。
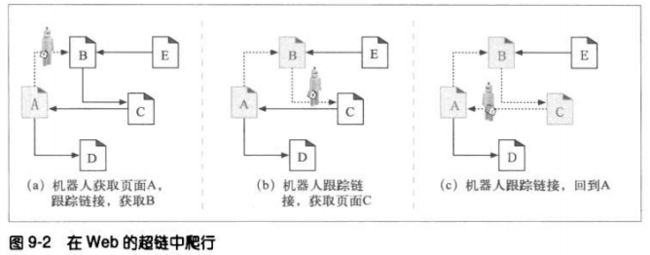
9.1.3 避免环路
机器人必须知道它们到过何处,以避免环路的出现。
9.1.4 循环与复制
环路对爬虫的危害:
使爬虫陷入循环之中。
爬虫不断地获取相同的页面时,另一端的服务器也在遭受打击,可能造成DoS。
爬虫应用程序会被重复的内容所充斥。
9.1.5 面包屑留下的痕迹
由于URL数量巨大,所以要使用负载的数据结构以便快速判定哪些URL是曾经访问过
的。数据结构在访问速度和内存使用方面都应该是非常高效的。
机器人知晓要用到搜索树或散列表,以快速判定某个URL是否被访问过。
大规模爬虫对其访问过的地址进行管理时使用的一些技术:
—-树和散列表
复杂的机器人可能会用到搜索树或散列表来记录已访问的URL,这些事加速URL查
找的软件数据结构。
—-有损的存在位图
为减小空间,使用有损数据结构,比如存在位数组(presence bit array)。用一
个散列函数将每个URL都转换成一个定长的数字,这个数字在数组中有个相关
的“存在位”。爬行过一个URL时,就将相应的“存在位“置位。
—-检查点
一定要将已访问URL列表保存到硬盘上,以防止机器人程序崩溃。
—-分类
单个机器人的能力有限,大型web机器人采用“集群”方式,每个独立的计算机是
一个机器人,以汇接方式工作。为每个机器人分配特定的URL“片”来进行爬行。
机器人个体之间可能需要相互通信,来回传送URL,以覆盖出故障的对等实体的爬
行范文或协调其工作。
9.1.6 别名与机器人环路

9.1.7 规范化URL
大多数web机器人都试图通过将URL“规范化”为标准格式来消除上面那些显而易见的
别名。通过下列步骤来转换为规范的格式
1、若无指定端口,向主机名添加“:80”
2、将所有转义字符%xx转换成等价字符
3、删除#标签
机器人需要知道web服务器是否大小写无关才能避免大小写的别名问题 需要知道服务器上这个目录下的索引页面配置才能知道默认页面是否为别名
$即使知道主机名和IP地址都指向同一台计算机,它也还要知道WEB服务器是否配置为
进行虚拟主机操作,才能判断是否为别名。
9.1.8 文件系统连接环路
文件系统中的符号连接会造成特定的潜在环路。因为它们会在目录层次深度有限的情
况下,造成深度无限的假象。
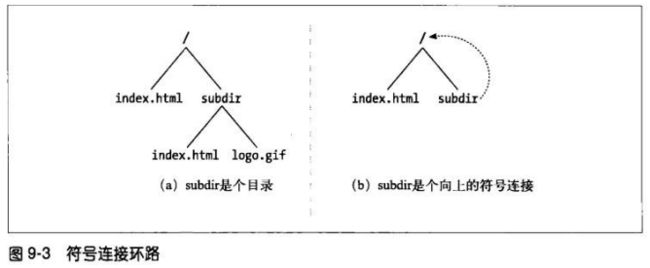
上图b的问题是subdir/是个指向“/”的环路。但由于URL看起来有所不同,所以机器
人无法但从URL本身判断出文档时相同的。需要有某种循环检测方式,才能避免陷入循
环。
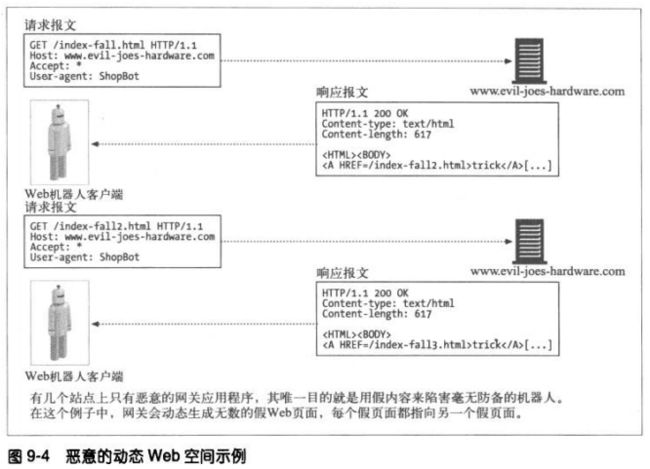
9.1.9 动态虚拟WEB空间
恶意网管可能会有意创建一些复杂的爬虫循环来陷害机器人。比如发布一个看起来像
普通文件,实际上却是网关应用程序的URL。这个应用程序可以在传输中构造出包含了
到同一服务器上虚构URL链接的HTML。请求这些虚构的URL时,服务器就会捏造出一
个带有新的虚构URL的新HTML页面来。
即使这个恶意服务器并不包含任何文件,它也可以通过无限虚拟的WEB空间将机器人
带入无尽的旅途。由于每次URL和HTML看起来有很大不同,机器人很难检测的环路。
9.1.10 避免循环和重复
经过良好设计的机器人中要包含一组试探方式,以避免出现环路。
规范化URL
广度优先的爬行
节流–限制从一个web站点获取的页面数量。
限制URL大小–通常是1KB。现在很多站点都会用URL来管理用户的状态(比如在一个
页面引用的URL中存储用户ID)。用URL长度来限制爬虫可能会带来麻
烦,但如果每当请求的URL到达某个特定长度时,就记录以及错误,就
可以为用户提供一种检测某特定站点上所发生情况的方法。
URL/站点黑名单
模式检测–文件系统的符号连接和类似的错误配置造成的环路会遵循某种模式。比如
URL随着组件的复制逐渐增加。有些机器人会将具有重复组件的URL当做潜
在的环路。重复并不都是立即出现,有些环路可能以其他间隔为周期。
/subdir/images/subdir/images/subdir/images/…
内容指纹–获取页面内容中的字节,并计算出一个校验和。必须对校验和函数进行选
择,以求不同页面具有相同校验和的几率非常低。比如MD5这样的。
有些服务器会在传输过程中对页面进行动态修改,所以有时机器人会在校验
和的计算中忽略web页面内容中的某些部分,比如嵌入的链接。而且,无论
定制了什么页面内容的动态服务端包含(比如添加日期,访问计数等)都可
能阻碍重复检查。
人工监视–所有产品级的机器人都要有诊断和日志功能。
9.2 机器人的HTTP
9.2.1 识别请求首部
尽管机器人倾向于只支持最小的HTTP集,但大部分机器人确实实现并发送了一些识别
首部—User-Agent。建议机器人实现者发送一些基本的首部信息,以通知各站点机器
人的能力、标识符、以及它是从何处起源。
基本识别首部应该包括如下内容:
User-Agent
From—-提供机器人的用户、管理者的E-mail地址
Accept—-告知服务器可以发送哪些媒体类型。
Referer—-提供包含当前请求URL的文档的URL。
9.2.2 虚拟主机
请求中不包含Host首部的话,可能会使机器人将错误的内容与一个特定的URL关联起
来。因此,HTTP/1.1要求使用Host首部。

9.2.3 条件请求
尽量减少机器人所要获取内容的数量通常是很有意义的。只在内容发生变化时才重新
获取内容变得很重要。
有些机器人实现了条件HTTP请求,它们会对时间戳或实体标签进行比较,查看它们最
近获取的版本是否已经升级。
9.2.4 对响应的处理
很多机器人的兴趣主要在于用简单的GET方法来获取所请求的内容。但是,使用了某些
HTTP特性(比如条件请求)的机器人,想要与服务器进行交互的机器人则要能对各种
不同类型的HTTP响应进行处理。
1、状态码
所有机器人都应该理解200和404这样的状态码。它们还应该能够根据响应的一般类别
对它并不十分理解的状态码进行处理。有些服务器并不能总是返回适当的错误代码,
认识到这一点是很重要的。有些服务器甚至会将HTTP 200 OK与描述错误状态的报文
主体文本一同返回。
2、实体
除了HTTP首部所嵌的信息之外,机器人也会在实体中查找信息。HTML原标签,比如
原标签http-equiv,就是内容编写者用于嵌入资源附加信息的一种方式。
有些服务器实际上会在发送HTML页面之前先对其内容进行解析,并将http-equiv指令
作为首部包含进去。
9.2.5 User-Agent导向
站点管理者应该设计一个处理机器人请求的策略。比如,它们可以为所有其他特性不
太丰富的浏览器和机器人开发一些页面,而不是将其内容限定在特定浏览器所支持的
范围。
9.3 行为不当的机器人
失控的机器人—-造成DoS
失效的URL
很长的错误URL
爱打听的机器人—-一旦爬去到一些敏感信息,应该有某种机制可以将这些数据丢弃,并
将所有搜索索引或归档文件中将其删除。
动态网关访问—-机器人并不知道它们访问的是什么内容。机器人可能会获取一个内容来
自网关应用程序的URL。
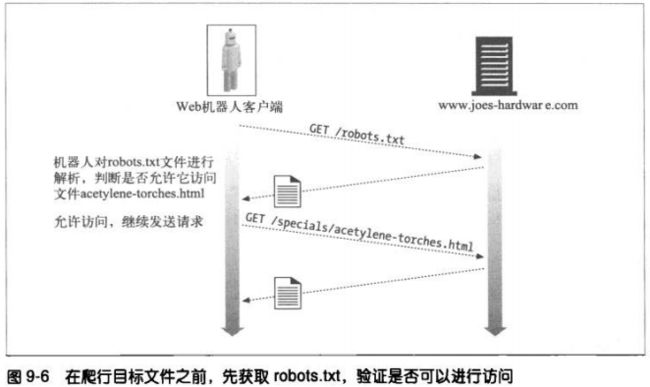
9.4 拒绝机器人访问
robots.txt。所有WEB服务器都可在服务器的文档根目录中提供一个可选的、名为
robots.txt的文件。这个文件包含的信息说明了机器人可以访问服务器的哪些部分。
9.4.1 拒绝机器人访问标准
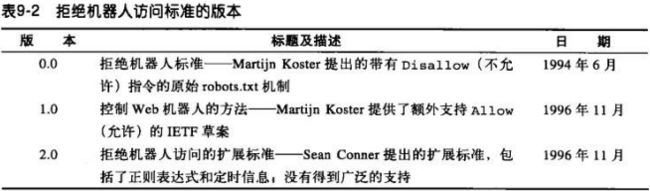
目前大多采用0.0 和 1.0版本。
9.4.2 WEB站点和robots.txt文件
如果一个web站点有robots.txt文件,那么在访问这个web站点上的任意URL 之前,机
器人都必须获取并对它进行处理。每个站点仅有一个robots资源,每个虚拟站点的虚
拟的docroot都可以有一个不同的robots文件。
1、获取robots.txt
机器人通过GET方法获取robots文件。若有,服务器将其放在一个text/plain主体中返
回。
2、响应码
很多站点都没有robots资源,机器人会根据robots检索的结果采取不同的行动。
服务器响应成功状态,机器人则必须对内容进行解析,并使用排斥规则获取站点内容
若为404,机器人则认为站点资源不收robots限制
若为401或403,机器人就应该认为此站点的访问时完全受限的
若是503,机器人就该推迟对站点的访问,知道可以获取资源为止
若是重定向,机器人就该跟着重定向知道找到资源为止
9.4.3 robots.txt文件的格式
采用了面向行的语法。robots.txt文件中有三种类型的行:空行、注释行、规则行。规
则行看起来就像HTTP首部一样,用于模式匹配。比如:

文件中的行可以从逻辑上划分成“记录”。每条记录都为一组特定的机器人描述了一
组排斥规则。
每条记录都包含了一组规则行,由一个空行或者文件结束符终止。记录以一个或多个
User-Agent行开始,说明哪些机器人会受此记录的影响,后面跟着一些disallow和
allow行,用来说明这些机器人可以访问哪些URL。
1、User-Agent行

如果机器人无法找到与其名字相匹配的User-Agent行,而且也无法找到通配的User-
Agent: * 行,就是没有记录与之匹配,访问不受限。
由于机器人名时与大小写无关的子字符串进行匹配,所以:User-Agent:bot 就与
Bot,Robot、Bottom-Feeder、Spambot等都相匹配。
2、Disallow和Allow
用来说明显示禁止或显示允许特定机器人使用哪些URL路径。

3、Disallow/Allow前缀匹配
Disallow和Allow规则要求大小写相关的前缀匹配。空字符串可以起到通配符的效果。
进行比较之前,要将规则路径或URL路径中被转义的字符都反转为字符。%2f除外。
如果规则路径为空字符串,就与所有内容都匹配。

9.4.4 其他有关知识
机器人应该忽略所有他不理解的字段(在user-agent、disallow、allow之外)
为了实现向后兼容,不能在中间断行
注释可以出现在文件的任何地方
0.0版的机器人访问标准不支持Allow行。
9.4.5 缓存和robots.txt的过期
机器人会周期性获取robots文件,并缓存起来。在过期之前就一直使用缓存的副本。
缓存遵循标准的HTTP缓存控制机制。
如果没有提供Cache-Control指令,规范草案允许将其缓存7天。
9.4.6 拒绝机器人访问的Perl代码
9.4.7 HTML的robot-control元标签
HTML页面的作者有一种更直接的方式可以限制机器人访问那些独立的页面。可以直接
在HTML文档中添加robot-control标签。遵循这个HTML标签规则的机器人仍然可以
获取文档,但如果有机器人排斥标签,它们会自动忽略这些文档。
机器人排斥标签如下形式,通过HTML的META标签实现:
1、机器人的META指令
NOINDEX:告诉机器人不要对页面内容进行处理,忽略文档(就是说不要在任何索引
或数据库中包含此内容)
NOFOLLOW:告诉机器人不要爬行这个页面的任何外链接。
INDEX:机器人可以对页面内容进行索引
FOLLOW:机器人可以爬行外链
NOARCHIVE:机器人不该缓存这个页面的本地副本
ALL:等价于INDEX/FOLLOW
NONE:等价于 NOINDEX/NOFOLLOW
与所有META标签类似,机器人META标签必须出现在HTML页面的HEAD区域中。

2、搜索引擎的META标签

9.5 机器人规范



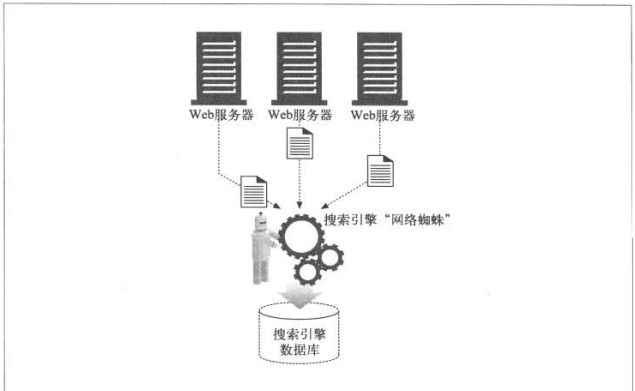
9.6 搜索引擎
9.6.1 大格局
在WEB发展初期,搜索引擎就是一些相当简单的数据库,可以帮助用户在web上定位
文档。而现在对于数十亿页面数百万用户,搜索引擎就需要用复杂的爬虫来获取这些
页面,还要用负载的查询引擎处理用户的查询。
9.6.2 现代搜索引擎结构
现在的搜索引擎都构建了一些名为“全文索引”的复杂本地数据库,装载了全世界的
web页面,以及这些页面所包含的内容。这些索引就像web上所有文档的卡片目录一
样。
搜索引擎爬虫会搜集web页面,并将其添加到全文索引中去。同时,搜索引擎用户会
通过hotbot或Google这样的web搜索网关对全文索引进行查询。web页面总是在不断
变化,而且爬行一大块web很花时间,所以全文索引充其量就是web的一个快照。
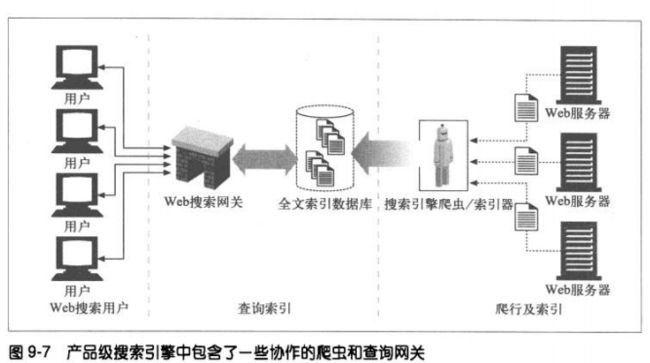
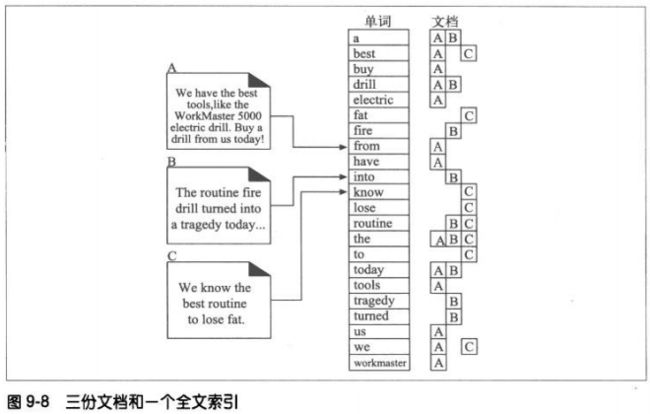
9.6.3 全文索引
全文索引就是一个数据库,给它一个单词,它可以立即提供包含那个单词的所有文
档。创建了索引之后,就不需要对文档自身进行扫描了。
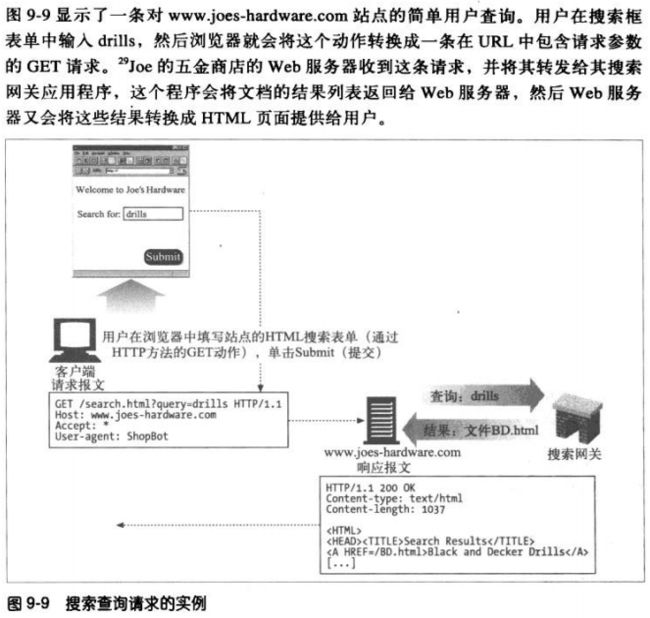
9.6.4 发布查询请求
用户向web搜索引擎网关发布一条请求时,会填写一个HTML表单,他的浏览器会用一
个HTTP GET或POST请求将这个表单发送给网关,网关程序对搜索引擎请求进行解
析,并将web UI 查询转换成搜索全文索引所需的表达式。
9.6.5 对结果进行排序,并提供查询结果
一旦搜索引擎通过其索引得到了查询结果,网关应用程序就会获取结果,并将其拼成
结果页面提供给用户。
相关性排名(relevancy ranking),这是对一系列搜索结果的评分和排序处理。比
如,某个单词出现在更多的文档中。
9.6.6 欺诈
为了想要在搜索引擎结果中排在前列,很多网管都列出了无数关键字,甚至是毫不相
关的,使用一些假冒页面,或者采用欺诈的手段—-用网关应用程序来生成一些在某些
特定单词上可以更好的欺骗搜索引擎相关性算法的假冒页面。
第十章 HTTP-NG
10.1 HTTP发展中存在的问题
复杂性:
HTTP相当复杂,而且其特性之间是相互依存的。由于复杂的、相互交织的要求,以及连
接管理、报文处理和功能逻辑之间的混合作用,想要实现HTTP软件变得很难。
可扩展性:
HTTP很难实现递增式扩展,很多流传下来的HTTP应用程序中都没有自主的功能性扩展技
术,使协议的扩展无法兼容。
性能:
HTTP中的很多低效特性会随着高时延、低吞吐量的无线访问技术的广泛使用而更加严重
传输依赖性:
HTTP是围绕TCP/IP网络协议栈设计的。
10.2 HTTP-NG的活动
10.3 模块化及功能增强
NG工作组建议将协议模块化为三层,而不是将连接管理、报文处理、服务器处理逻辑和
协议方法全部混在一起。
第一层:报文传输层,这一层不考虑报文的功能,而是致力于端点间报文的不透明传输。
该层支持各种子协议栈,主要负责处理高效报文传输以及处理。NG组为本层提出了一个
名为WebMUX的协议
第二层:远程调用层,定义了请求/响应的功能,客户端可以通过这些功能调用对服务器
资源进行操作。本层试图提供一种像CORBA/DCOM和JaveRMI那样的面向对象的可扩展
框架。
第三层:web应用层,提供大部分的呢荣管理逻辑,所有的HTTP方法,以及HTTP/1.1首
部参数都是在这里定义的。本层还支持其他构建在远程调用基础上的服务,比如
WebDAV。
10.4 分布式对象
分布式对象系统对可扩展性和功能特性都很有帮助。
10.5 第一层:报文传输
报文传输层为报文传输提供了一个API,无论底层实际采用的是什么网络协议栈都可以使
用。
本层关注的是提高报文传输的性能、其中包括:
对报文进行管道化和批量化传输
重用连接
同一条连接并行的复用多个报文流
对报文进行有效的分段,使报文边界的确定更容易
10.6 第二层:远程调用
本层提供了通用的请求/响应框架,客户端可通过此框架对服务器资源操作。本层并不关
心特定操作的实现及语义(缓存、安全性、方法逻辑等),它只关心允许客户端远程调用
服务器操作的接口。NG小组建议本层采用二进制连接协议。这个协议支持一种高性能的
可扩展技术,通过这种技术可以调用服务器上经过良好描述的操作,并返回结果。
10.7 第三层:web应用
本层是执行语义和应用程序特定逻辑的地方。这一层描述了一个用于提供应用程序特定服
务的系统,这些服务并不单一,不同的应用程序可能使用不同的API。HTTP-NG结构允
许多个应用共存于本层,共享底层特性,它还提供了一种添加新应用程序的机制。
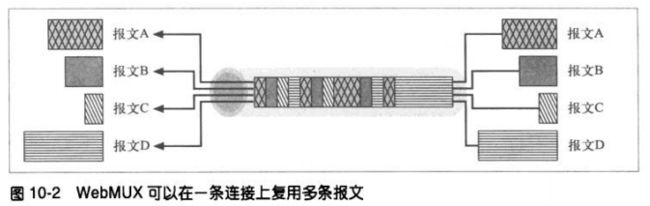
10.8 webMUX
它实现了在一个复用的TCP连接上并行地传输报文。可以对以不同速度产生和消耗的独立
报文流进行高效的分组,并将其复用到一条或少数几条TCP连接上去。
10.9 二进制连接协议
HTTP-NG定义了一些“对象类型”,并为每种对象类型分配了一组方法。为每种对象类
型分配了一个URI,以便将对它的描述和它的方法宣传出去。
二进制连接协议通过一条有状态的连接承载了从客户端发往服务器的操作调用请求,以及
服务器的应答。除了请求报文和应答报文外,这个协议还定义了几种内部控制报文,用来
提高连接的效率和强壮性。
第三部分 识别、认证与安全
第十一章 客户端识别与cookie机制
11.1 个性化接触
HTTP最初是一个匿名、无状态的请求/响应协议。服务器处理来自客户端的请求,然后向
客户端回送一条响应。
比如电商网站:
个性化问候、有的放矢的推荐、管理信息的存档、记录会话。
11.2 HTTP首部
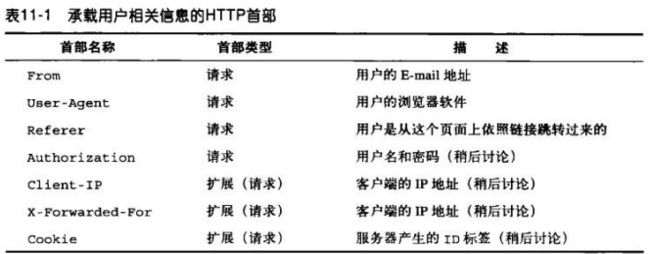
From首部包含了用户的E-mail地址,实际上通常由自动化的机器人或蜘蛛发送。
11.3 客户端IP地址
通常HTTP首部不提供客户端IP地址,但是WEB服务器可以找到承载HTTP请求的TCP连接
另一端的IP地址。
Unix系统,函数调用getpeername就可以返回发送端机器的客户端ip地址
status = getpeername(tcp_connection_socket,…..)
但是ip仅能区分机器,而不能区分用户。而且NAT的存在导致一个ip后有许多客户端。
HTTP代理和网关通常会打开一些新的,到服务器的TCP连接。
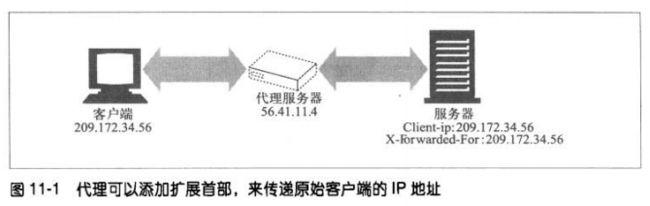
11.4 用户登录
为了使web站点的登录更加简便,HTTP中包含了一种内建机制,可以用www-
Authenticate首部和Authorization首部向web站点传送用户相关信息。
如果服务器希望用户登录,可以向浏览器回送一条HTTP响应代码401 Login Required。
然后浏览器会显示一个登录对话框,并用Authorization首部在下一条对服务器的请求中
提供这些信息。
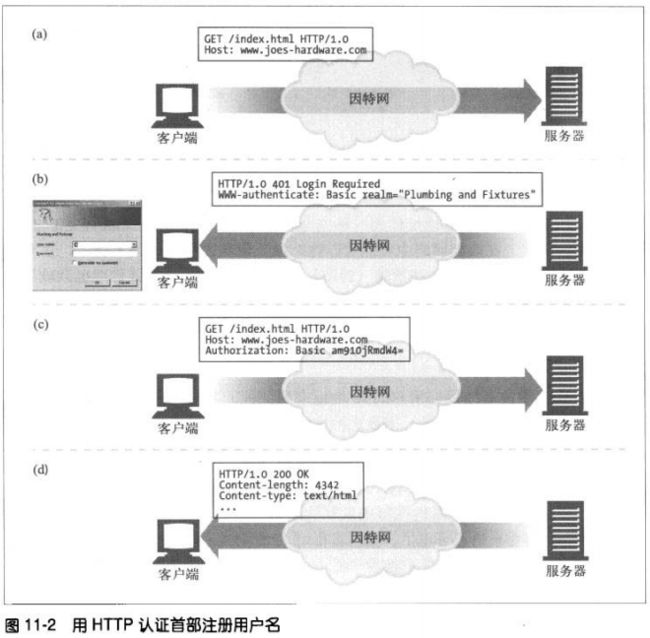
只要输入了用户名和密码,浏览器就重复原来的请求,这次会带上用户名和密码。今后的
请求要使用用户名和密码时,浏览器会自动将存储下来的值发送出去,甚至站点没有要求
发送时也会发送。
11.5 胖URL
有些web站点会为每个用户生成特定版本的URL来追踪用户的身份。通常会对真正的URL
进行扩展,在URL路径开始或结束的地方添加一些状态信息。用户浏览站点时,web服务
器会动态生成一些超链,继续维护URL中的状态信息。
改动后包含了用户状态信息的URL 称为胖URL。如下例子:

可以通过胖URL 将web服务器上若干个独立的HTTP事务捆绑成一个“会话”或“访
问”。用户首次访问这个web站点时,会生成一个唯一的ID,用服务器可以识别的方式将
这个ID添加到URL中去,然后服务器就会将客户端重新导向这个胖URL。不论什么时候,
只要服务器收到了对胖URL的请求,就可以去查找那个用户ID相关的所有增量状态(购物
车等),然后重写所有的输出超链,使其成为胖URL,以维护用户的ID。
这个胖URL无法共享,因为包含了特定用户的状态信息。为每个URL生成用户特有版本就
意味着不再有可供公共访问的URL需要缓存了。而且会造成服务器的额外负担。
用户跳转到其他站点或请求一个特定URL时,就很容易在无意中“逃离”胖URL会话。导
致丢失他的进展信息,得重新开始。
除非用户收藏了特定的胖URL,否则用户退出时,所有信息会丢失。
11.6 cookie
11.6.1 cookie的类型
笼统的分为两类:会话cookie和持久cookie。
会话cookie是一种临时cookie,它记录了用户访问站点时的设置和偏好。用户退出浏
览器时,会话cookie就被删除了。
持久cookie的生存时间更长一些,它们存储在硬盘上,浏览器退出,计算机重启时它
们已然存在。通常会用持久cookie维护某个用户会周期性访问的站点的配置文件和登
录名会话cookie和持久cookie之间唯一的区别就是它们的过期时间。如果设置了
Discard参数,或者没有设置Expires或Max-Age参数来说明扩展的过期时间,这个
cookie就是一个会话cookie。
11.6.2 cookie如何工作
用户首次访问web站点时,web服务器对用户一无所知。服务器希望这个用户再次回
来,所以想给这个用户设置一个cookie,这样它就可以识别出这个用户了。cookie中
包含了一个由名字=值(name=value)这样的信息构成的任意列表,并通过Set-
Cookie或Set-Cookie2 HTTP响应(扩展)首部将其添加到用户身上。
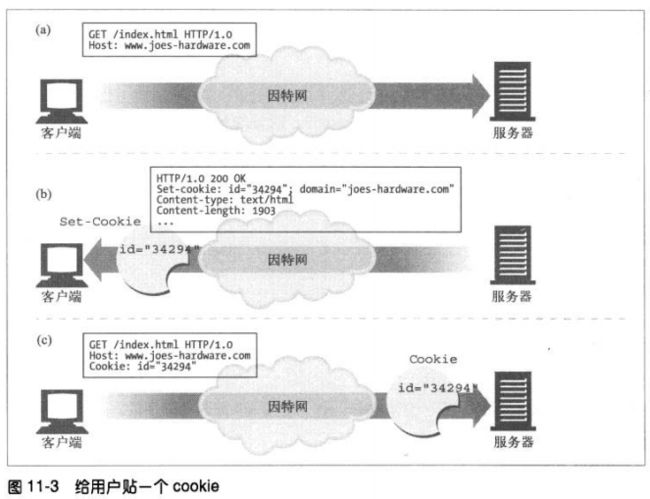
cookie中可以包含任意信息,但它们通常只包含一个服务器为了跟踪而产生的独特的
识别码。浏览器会记住从服务器返回的cookie内容,并将cookie集存储在浏览器的
cookie数据库中。
11.6.3 cookie罐:客户端的状态
cookie的基本思想就是让浏览器积累一组服务器特有的信息,每次访问服务器时都将
这些信息提供给它。因为浏览器要负责存储cookie信息,所以此系统被称为客户端侧
状态,这个cookie规范的正式名称为HTTP状态管理机制(HTTP state management
mechanism)。
1、网景的Navigator的cookie
存储在一个名为cookies.txt的文本文件中
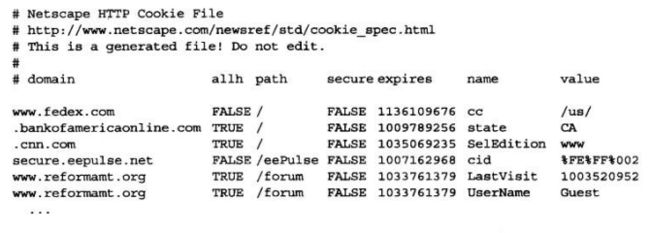
文本文件中每一行都代表一个cookie。有7个用tab键分隔的字段。
domain(域)—-cookie的域
allh—-是域中所有主机获取cookie,还是只有指定了名字的主机获取
path—-域中与cookie相关的路径前缀
secure–是否只有在使用SSL连接时才发送这个cookie
expiration–从格林尼治标准时间1970年1月1日00:00:00开始的cookie过期秒数
name—-cookie变量的名字
value—-cookie变量的值
2、微软IE的cookie
IE将cookie存储在高速缓存目录下独立的文本文件中。可以通过浏览这个目录来查看
cookie。
11.6.4 不同站点使用不同cookie
浏览器通常只向每个站点发送2-3个cookie,只向服务器发送服务器产生的那些
cookie。很多WEB站点会与第三方厂商达成协议,由其来管理广告。这些广告做的像
web站点的一个组成部分,而且确实发送了持久cookie。用户访问另一个由同一广告
公司提供服务的站点,(由于域是匹配的)浏览器就会再次回送早先设置的持久
cookie。营销公司可以将此技术与Referer首部结合,搜集用户习惯。
1、cookie的域属性
产生cookie的服务器可以向Set-Cookie响应首部添加一个Domain属性来控制哪些站
点可以看到这个cookie。
2、cookie的路径属性
cookie规范甚至允许用户将cookie与部分web站点关联起来。通过Path属性实现。这
个属性列出的URL路径前缀下所有cookie都是有效的。
Set-cookie: pref=compact; domain=”baidu.com”; path=/autos/
如果用户访问www.baidu.com/autos/xxxx 就会带上pref=compact cookie
11.6.5 cookie成分
现在使用的cookie规范有两个不同的版本:0(Netscape cookies)和 1 (RFC
2965).

11.6.6 cookie版本0
有网景公司定义。版本0的cookie定义了set-cookie响应首部、cookie请求首部以及用
于控制cookie的字段。

1、版本0的set-cookie首部


2、版本0的cookie首部
客户端发送请求时,会将所有与域、路径和安全过滤器相匹配的未过期cookie都发送
给这个站点。所有cookie都被组合到一个cookie首部中。
11.6.7 cookies 版本1(RFC 2965)
这个版本引入了Set-Cookie2首部和Cookie2首部,也能与版本0系统进行互操作。
主要改动:
@为每个cookie关联解释性文本
@允许在浏览器退出时,不考虑过期时间,强制销毁
@用相对秒数,而不是绝对日期来表示cookie的Max-Age
@通过URL端口号,而不仅是域和路径来控制cookie的能力
@通过cookie首部回送域、端口和路径过滤器(如果有)
@为实现互操作性使用的版本号
@在cookie首部从名字中区分出附加关键字的$前缀

1、版本1的Set-Cookie2首部


2、版本1的Cookie首部
版本1的cookie会带回与传送的每个cookie相关的附加信息,用来描述每个cookie途
径的过滤器。
每个匹配的cookie都必须包含来自相应set-cookie2首部的所有domain、port、path
属性

3、版本1的cookie2首部和版本协商
cookie2请求首部负责在能够理解不同cookie规范版本的客户端和服务器之间进行互操
作性的协商。cookie2首部告知服务器,用户Agent代理解析新形式的cookie,并提供
了所支持的cookie标准版本
如果服务器理解新形式的cookie,就能识别出cookie2首部,并在响应首部发送set-
cookie2。如果客户端从一个响应中同时获取了set-cookie和set-cookie2首部,就会
忽略老的的set-cookie首部
如果客户端即支持版本0又支持版本1的cookie,但从服务器获得版本0的set-cookie首
部,就该带版本0的cookie首部发送cookie,而且还应该发送cookie2:
$version=“1”来告诉服务器它是可以升级的。
11.6.8 cookie与会话跟踪
可以用cookie在用户与某个站点进行多项事务处理时对用户进行跟踪。

11.6.9 cookie与缓存
@如果无法缓存文档,就要将其标示出来
文档所有者最清楚文档是否不可缓存。若不可缓存,需要显式注明—-比如除了set-
cookie首部之外的文档时可缓存的,就使用:Cache-Control: no-cache=“Set-
Cookie”。另一种更通用的做法是为可缓存文档使用:Cache-Control: public,
这样有助于节省带宽。
@缓存set-cookie首部需要小心
若响应中有set-cookie首部,就可以对主体进行缓存。但需要注意对set-cookie的
缓存
有些缓存在将响应缓存起来之前会删除set-cookie首部,但这样会引发一些问题。
强制缓存与服务器重新验证每条请求,并将返回的所有set-cookie首部都合并到客
户端的响应中去,可以改善此类情况。服务器可以添加下面这个首部要求再验证:
Cache-Control: must-revalidate, max-age=0
即便内容实际是可以缓存的,比较保守的缓存也可能会拒绝所有包含set-cookie首
部的响应。有些缓存允许缓存set-cookie图片,但不缓存文本模式。
@处理带有cookie首部的请求
带有cookie的请求到达,就是在提示得到的结果可能是私有的。一定要将私有内容
标识为不可缓存的。
11.6.10 cookie、安全性和隐私
cookie是可以禁止的,而且可以通过日志分析或其他方式来实现大部分跟踪记录,所
有cookie自身并不是很大的安全隐患。
第十二章 基本认证机制
12.1 认证
认证就是要给出一些身份证明。
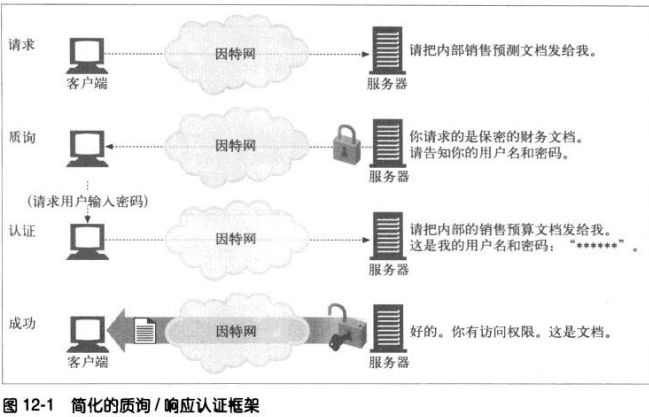
12.1.1 HTTP的质询/响应认证框架
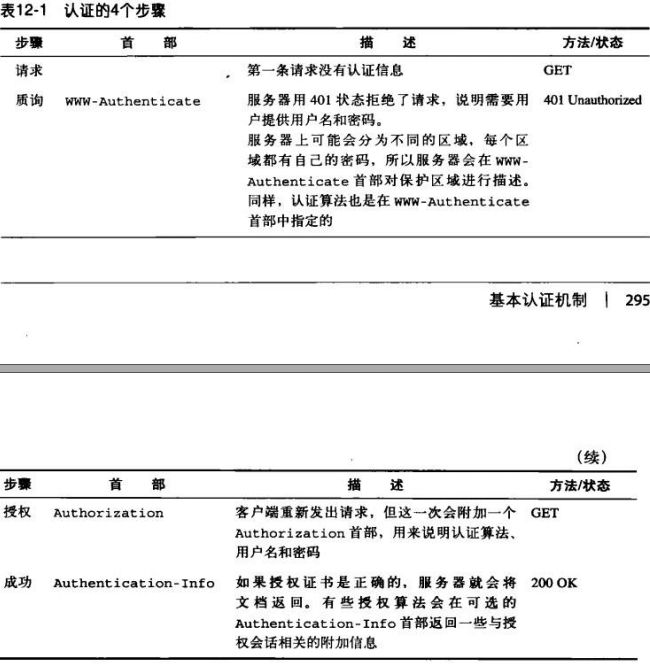
12.1.2 认证协议与首部
HTTP通过一组可定制的控制首部,为不同认证协议提供了一个可扩展框架。下表列出
的首部格式和内容会随着认证协议的不同而发生变化。认证协议也是在HTTP认证首部
中指定的。
HTTP定义了两个官方的认证协议:基本认证和摘要认证。
12.1.3 安全域
WEB服务器会将受保护的文档组织成一个安全域(security realm)。每个安全域都可
以有不同的授权用户集。
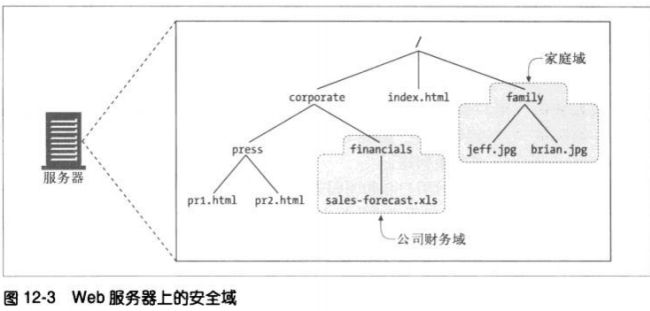
下面是一个假想的基本认证质询,它指定了一个域:
HTTP/1.0 401 Unauthorized
WWW-Authenticate: Basic realm=“Corporate Financials”
域应该有一个描述性的字符名,帮助用户了解应该使用哪个用户名和密码。
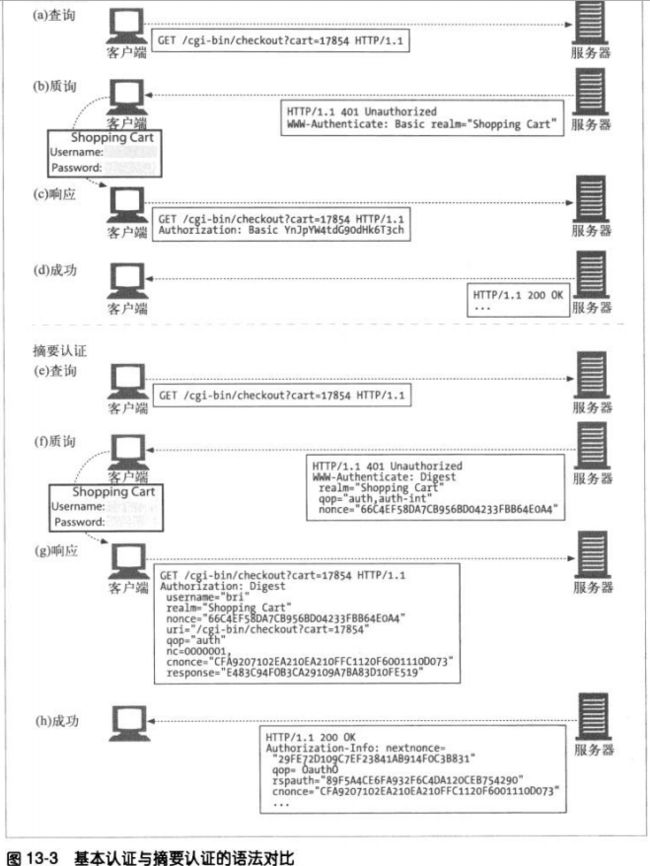
12.2 基本认证
基本认证中,服务器可以拒绝一个事务,质询客户端,请用户提供用户名和密码。服务器
会返回401状态码并指定安全域。浏览器收到响应时会打开一个对话框,请用户输入这个
域的用户名和密码。然后将用户名和密码稍加扰码,用Authorization首部回送给服务器
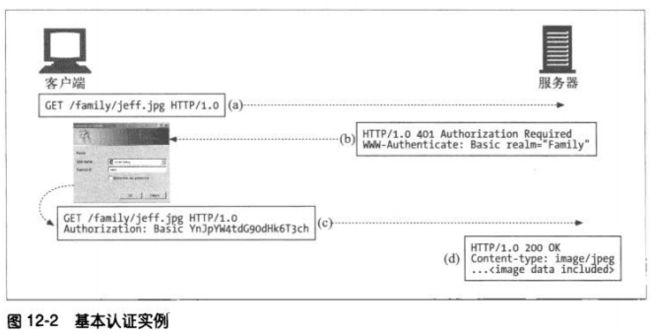
12.2.1 基本认证实例

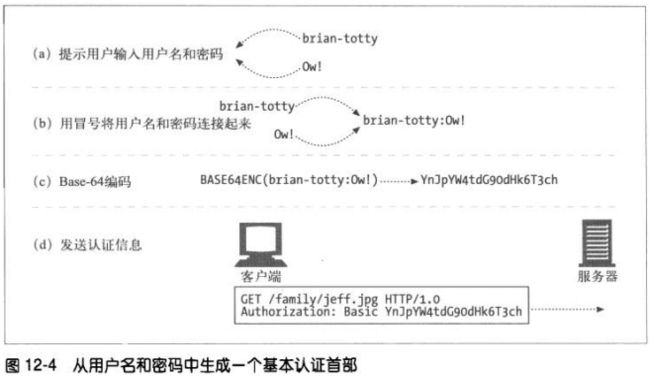
12.2.2 Base-64编码
将一个8位字节序列划分为一些6位的块,用每个6位的块在一个特殊的由64个字符组
成的字母表中选择一个字符。这个字母表包含大部分字母和数字。
12.2.3 代理认证
中间的代理也可以实现认证功能。可以在代理服务器上对访问策略进行集中管理。代
理认证和服务器认证的步骤相同,但是首部和状态码有所不同。

12.3 基本认证的安全缺陷
base-64编码易解码;
即使密码难解码,但是第三方仍可以捕获到修改后的内容,并将修改过的用户名密码重放
给服务器,获得访问权限;
基本认证没有提供任何针对代理和作为中间人的中间节点的防护措施,它们没有修改认证
首部,但是却修改了报文的其他部分,严重改变了事务的本质;
假冒服务器很容易骗过基本认证。
第十三章 摘要认证
13.1 摘要认证的改进
永不以明文方式在网络上发送密码
可以防止恶意用户捕获并重放认证的握手过程
可以有选择地防止对报文内容的篡改
防范其他几种常见攻击方式
13.1.1 用摘要保护密码
客户端会发送一个“指纹”或密码的“摘要”,这是密码的不可逆扰码。客户端和服
务器都知道密码,因此服务器可以验证所提供的摘要是否与密码匹配。
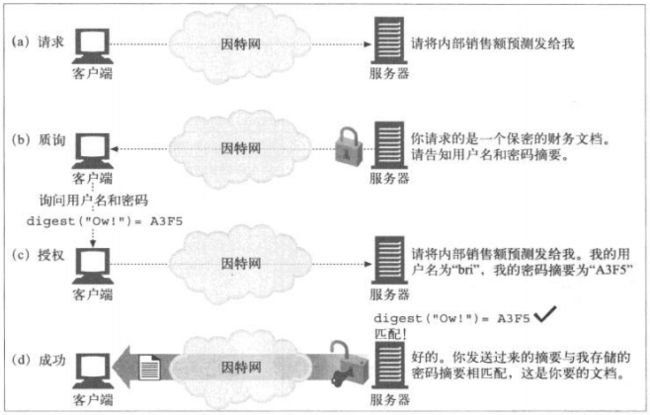
13.1.2 单向摘要
摘要是一种单向函数,主要用于将无限的输入值转换为有限的输出值,常见的摘要函
数MD5,会将任意长度字节的序列转换为一个128位的摘要。
MD5输出的128摘要通常被写成32个十六进制字符,每个字符表示4位。

13.1.3 用随机数防止重放攻击
服务器想客户端发送一个称为随机数的令牌。
13.1.4 摘要的握手机制
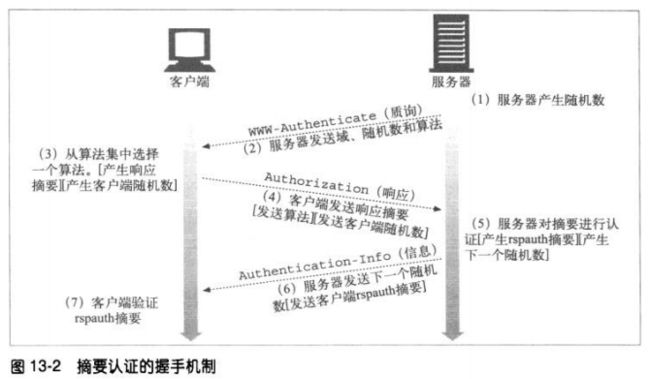
13.2 摘要的计算
13.2.1 摘要算法的输入数据
摘要是根据下列三个组件计算:
由单向散列函数H(d)和摘要KD(s,d)组成的一对函数,其中s是密码,d是数据
一个包含了安全信息的数据块,包括密码,称为A1
一个包含了请求报文中非保密属性的数据块,称为A2
H 和 KD 处理两块数据A1,A2,产生摘要。
13.2.2 H(d)和 KD(s,d)
默认使用MD5算法
H(D)=MD5(D)
KD(S,D)=H(concatenate(S,D))
13.2.3 与安全性相关的数据A1
A1是密码和受保护信息的产物,包含有用户名、密码、保护域和随机数等内容。A1只
涉及安全信息,与底层报文无关。
RFC 2617定义了两种计算A1的方式
MD5
为每条请求运行单向散列函数。A1是由冒号连接的 用户名、域、密码三元组
MD5-sess
只在第一次WWW-Authenticate握手时运行一次散列函数,对用户名、域、密码进行
一次CPU密集型散列,并将其放在当前随机数和客户端随机数(cnonce)的前面。

13.2.4 与报文有关的A2
A2表示的是域报文自身有关的信息,比如URL,请求方法和报文实体的主体部分。A2
防止方法、资源或报文被篡改。A2会与H,KD,A1一起用于摘要的计算。
RFC 2617根据所选择的保护质量(qop)、为A2定义了两种策略:
1、只包含HTTP请求方法和URL,当qop=“auth”时使用,是默认的
2、添加了主体部分,qop=“auth-int”时使用

13.2.5 摘要算法总述


13.2.6 摘要认证会话
客户端响应对保护空间的WWW-Authenticate质询时,会启动一个此保护空间的认证
会话。
在客户端收到另一条来自保护空间的任意一台服务器的WWW-Authenticate质询之
前,认证会话会一直持续。客户端应该记住用户名、密码、随机数、随机数计数以及
一些与认证会话有关的隐晦值,以便将来在此保护空间中构建请求的Authorization首
部时使用。
随机数过期时,即便老的Authorization首部所包含的随机数不新鲜了,服务器也可以
选择接受其中的信息。服务器也可以返回一个带新随机数的401响应。让客户端重试此
请求,指定这个响应为stale=true,表示服务器告知客户端用新随机数重试,而不用输
入用户名和密码。
13.2.7 预授权
普通认证方式中,事务结束之前,每个请求都要有一次请求/质询的循环。
若客户端事先知道下一个随机数是什么,就可以取消这个请求/质询循环。
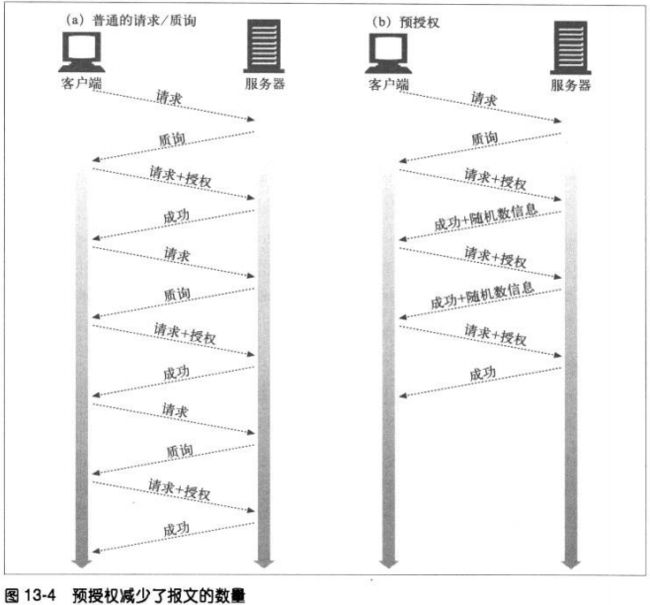
三种获得预先随机数的方式:
服务器预先在Authentication-Info成功首部中发送下一个随机数
服务器允许在一小段时间内使用同一个随机数
客户端和服务器使用同步的、可预测的随机数生成算法
1、预先生成下一个随机数
这种发送实际上破坏了对同一台服务器的多条请求进行管道化的功能。因为在下一条
请求之前,一定要收到下一个随机数才行
2、受限的随机数重用机制
比如服务器允许将某个随机数使用5此或使用10秒
这样可能导致重放攻击。但是可以通过控制随机数生存周期达到平衡。或者通过其他
特性–增量计数器和IP地址测试。并不能完全消除安全隐患
3、同步生存随机数
13.2.8 随机数的选择

13.2.9 对称认证
通过提供客户端随机值来实现对客户端对服务器的认证。只要提供了qop指令,就要求
执行对称认证。

13.3 增强保护质量
可以在三种摘要首部中提供qop字段:WWW-Authenticate、Authorization和
Authentication-Info。
通过qop字段,客户端和服务器可以对不同类型及质量的保护进行协商。比如,即便会严
重降低传输速度,有些事务也要检查报文主体的完整性。
服务器首先在WWW-Authenticate首部输出由逗号分隔的qop选项列表,然后客户端从
中选择一个它支持且满足需求的选项,并将其放在Authorization的qop字段中回送。
RFC 2617定义了两种保护质量的初始值:表示认证的auth,带有报文完整性保护的认证
auth-int。
13.3.1 报文完整性保护
若qop=“auth-int”,H(实体的主体部分)就是对实体主体部分,而不是报文主体
部分的散列。
对于发送者,要在应用任意传输编码方式之前计算,对于接收者,则应去除所有编码
之后计算。对于任何含有多个部分的内容类型来说,多个部分的边界和每部分中嵌入
的首部都要包含在内。
13.3.2 摘要认证首部

13.4 应该考虑的实际问题
13.4.1 多重质询
服务器可以对某个资源发起多重质询。比如既提供基本认证质询,又提供摘要认证质
询。客户端面对多重质询时,必须以它所能支持的最强的质询机制来应答。
13.4.2 差错处理
在摘要认证中,如果某个指令或其值使用不当,或者缺少某个必要指令,就应该使用
响应400 Bad Request。
如果请求的摘要不匹配,就应该记录一次登录失败。
认证服务器一定要确保URI指令指定的资源与请求行中指定的资源相同。如果不同,就
返回400响应。这个字段包含的内容与请求URL中的内容时重复的,用来应对中间代理
可能对客户端请求进行的修改。
13.4.3 保护空间
域值,与被访问服务器的标准根URL结合在一起,定义了保护空间。
通过域可以将服务器上的受保护资源划分为一组保护空间,每个空间都有自己的认证
机制或授权数据库。域值是一个字符串,通常由服务器分配,可能会有认证方案特有
的附加语义。
保护空间确定了可以自动应用证书的区域。若之前某条请求已经被授权,在一段时间
内,该保护空间中所有其他请求都可以重用同一个证书。
对保护空间的具体计算取决于认证机制:
基本认证中,客户端会假定请求URI中或其下的所有路径都与当前的质询处于同一个保
护空间内。客户端可以预先提交对此空间中资源的认证,无需等待来自服务器的另一
条质询。
摘要认证中,质询的WWW-Authenticate: domain字段对保护空间做了更精确的定
义。通常认为,domain列表中的所有URI和逻辑上处于这些前缀之下的所有URI都位
于同一个保护空间中。
若没有domain字段或该字段为空,质询服务器上的所有URI就都在保护空间内。
13.4.4 重写URI
代理可以通过改变URI语法,而不改变所描述的实际资源的方式来重写URI。
对主机名标准化或使用IP取代
可以用%转义形式来取代嵌入的字符
若某类型的一些附加属性不会影响从特定服务器获取资源,就可将其附加或插入到URI
中
13.4.5 缓存
共享的缓存收到包含Authorization首部的请求和转接那条请求产生的响应时,除非响
应中提供了下列两种Cache-Control指令之一,否则一定不能将那条响应作为对其他请
求的应答。
1、原始响应中Cache-Control有指令must-revalidate。 强制再验证
2、包含指令public。
13.5 安全性考虑
13.5.1 首部篡改
为了提供一个简单明了的防首部篡改系统,要么进行端到端加密,要么对首部进行数
字签名。摘要认证的重点在于提供一种防篡改认证机制,但并不一定要将这种保护扩
展到数据上去。具有一定保护级别的首部只有WWW-Authenticate和Authorization
13.5.2 重放攻击
重放攻击指有人将从某个事务中窃取的认证的证书用于另一个事务。
一种完全可避免重放攻击的方式就是为每个事务都使用一个唯一的随机数。
13.5.3 多重认证机制
服务器支持多重认证机制时,通常会在WWW-Authenticate首部提供选项。但是需要
让客户端去选择可用认证方案中功能最强的。
13.5.4 词典攻击
密码猜测
13.5.5 恶意代理攻击和中间人攻击
这种攻击可以采用窃听的形式,也可以删除提供的所有选项,用最弱的认证策略。
防止这些攻击的唯一简便方式是SSL
13.5.6 选择明文攻击
使用摘要认证的客户端会用服务器提供的随机数来生成响应。但如果中间有一个被入
侵的或恶意的代理在拦截流量,就可以很容易地为客户端的响应计算提供随机数。使
用已知密钥来计算响应可以简化响应的密码分析过程。这被称为选择明文攻击
(chosen plaintext attack)。
预先计算的词典攻击
批量暴力型攻击
13.5.7 存储密码
摘要认证机制将对比用户的响应与服务器内部存储的内容。
与Unix机器中传统的密码文件不同,如果摘要认证密码文件被入侵了,攻击者就能马
上使用域中的所有文件,不需要再进行解码了。
解决的方法:
就像密码文件中包含的是明文密码一样来保护它
确保域名在所有域中是唯一的。
第十四章 安全HTTP
14.1 保护HTTP的安全
HTTPS
使用HTTPS时,所有的HTTP请求和响应数据在发送到网络之前,都要进行加密。
HTTPS在HTTP下面提供了一个传输级的密码安全层。可以使用SSL,也可以使用其后继
者—传输安全层(Transport Layer Security,TLS)。两者类似,本书不太严格使用
SSL来表示SSL和TLS。

大部分困难的编码及解码工作都是在SSL库中完成的,所以WEB客户端和服务器在使用安
全HTTP时无需过多的修改其协议处理逻辑。大多情况下,只需要SSL的输入\输出调用取
代TCP的调用,再增加其他几个调用来配置和管理安全信息就行了。
14.2 数字加密
14.2.1 密码编制的机制与技巧
密码学是对报文进行编/解码的机制与技巧。
14.2.2 密码
密码学基于一种名为密码(cipher)的秘密代码。密码是一套编码方案——一种特殊
的报文编码方式和相应解码方式的结合体。
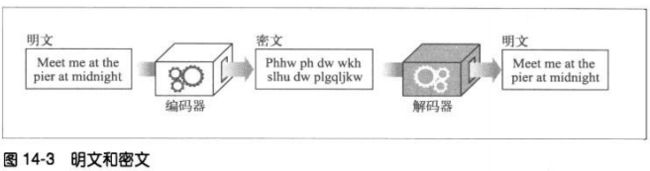
14.2.3 密码机
14.2.4 使用了密钥的密码
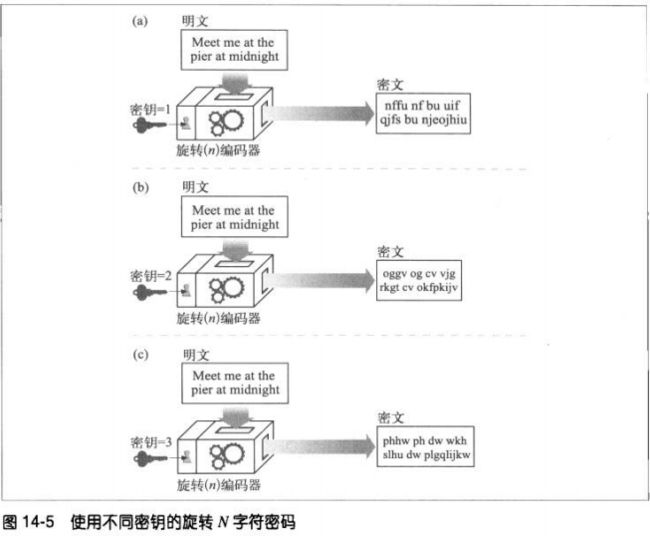
编码算法和编码机都可能会落入他人之手,所以大部分机器上有一些号盘,可以将其
设置为大量不同的值以改变密码的工作方式。
这些密码参数被称为密钥(key)。要在密码机输入正确的密钥,解密过程才能正确进
行。
与金属钥匙或机械设备中的号盘设置相比,数字密钥只是一些数字。这些数字密钥值
是编/解码算法的输入。编码算法就是一些函数,这些函数会读取一块数据,并根据算
法和密钥值对其进行编/解码。
14.3 对称密钥加密技术
在编码时使用的密钥值和解码时一样(E=D),这种的称为对称密钥(symmetric-key),
统称为密钥k。
流行的对称密钥加密算法有:DES,Triple-DES,RC2,RC4
14.3.1 密钥长度与枚举攻击
很多情况下,编/解码算法是公开的,因此密钥就是唯一保密的东西了。
好的加密算法会迫使攻击者尝试每个可能的密钥,才能破解。用暴力去尝试所有密钥
值称为枚举攻击(enumeration attack)。
可用密钥值的数量取决于密钥中的位数,以及可能的密钥中有多少是有效的。就对称
密钥加密技术来说,通常所有的密钥值都是有效的。但有些失部分有效,比如RSA,
有效密钥必须以某种方式与质数相关,可能的密钥值中只有少量密钥具备此特性。
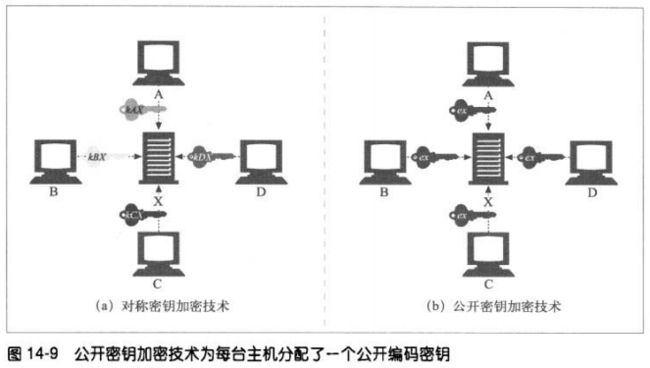
14.3.2 建立共享密钥
对称密钥加密的技术缺点之一就是发送者和接收者在互相对话之前,一定要有一个共
享的保密密钥。
如果有N个节点,每个节点都要和其他所有N-1个节点进行安全对话,总共大概会有
N*N个密钥,将变得很难管理。
14.4 公开密钥加密技术
使用了两个非对称密钥,一个用来对报文编码,另一个用来对报文解码。编码密钥是公开
的,但只有主机才知道私有的解密密钥。
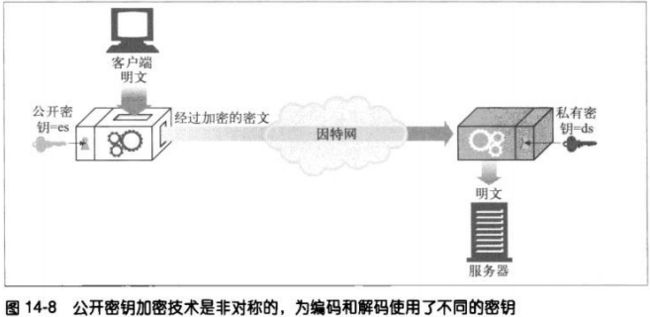
将密钥分隔开来可以让所有人都能对报文进行编码,但只有其所有者才能对报文进行解
码。
14.4.1 RSA
所有公开密钥非对称加密系统所面临的共同挑战是,要确保即便有人得到了下面的线
索也无法计算出私有密钥:
##公开密钥
##一小片拦截的报文
##一条报文与之相关的密文(对任意文本允许加密器就可以得到)
RSA算法就是这样一个公开密钥加密系统。破解它的难度相当于对一个极大的数进行
质因数分解的难度。
14.4.2 混合加密系统和会话密钥
公开密钥加密算法的计算可能会很慢,比较常见的是在两个节点间通过公开密钥加密
技术建立起安全通信,然后用安全通道产生并发送临时的随机对称密钥,通过更快的
对称加密技术对其余的数据进行加密。
14.5 数字签名
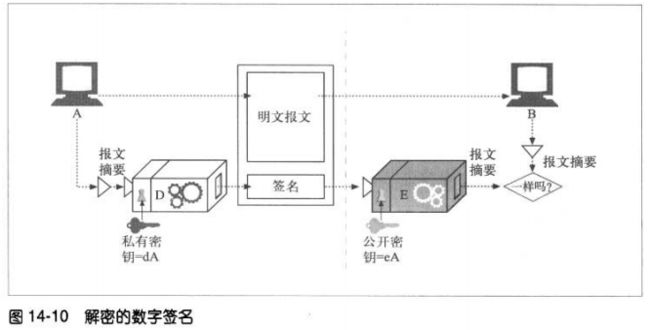
数字签名是附加在报文上的特殊加密校验码。使用数字签名有两个好处:
1、签名可以证明作者编写了这条报文。只有作者才会有最机密的私有密钥。
2、签名可以防止报文被篡改。
数字签名通常是用非对称公开密钥技术产生的。
如下例子:
发送端–节点A将变长报文提取为定长的摘要。对摘要应用一个“签名”函数,这个函数
会将用户的私有密钥作为参数 。一旦计算出签名,节点A就将其附加在报文的末尾,并将
报文和签名都发给B
接收端–如果节点B需要确定报文确实是A写的,而且没被篡改过,节点B就可以对签名进
行检查。B接收经私有密钥扰码的签名,并应用了使用公开密钥的反函数。如果拆包后的
摘要与节点B自己的摘要不匹配,说明报文要么被篡改了,要么不是A的私有密钥。
14.6 数字证书
数字证书中包含了由某个受信任组织担保的用户或公司的相关信息。
14.6.1 证书的主要内容
对象的名称(人、服务器、组织等)
过期时间
证书发布者
来自证书发布者的数字签名
数字证书通常还包括对象的公开密钥、以及对象和所用签名算法的描述性信息。
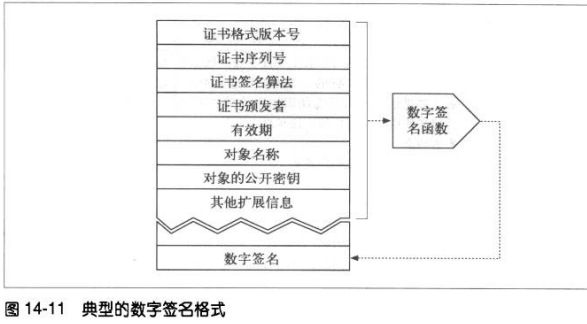
14.6.2 X.509 v3证书
X.509 v3证书提供了一种标准的方式,将证书信息规范至一些可解析字段中。

基于X.509 证书的签名有好几种,包括WEB服务器证书、客户端电子邮件证书、软件
代码证书和证书颁发机构证书
14.6.3 用证书对服务器进行认证
通过HTTPS建立一个安全web事务之后,现代的浏览器会自动获取所连接服务器的数
字证书,如果服务器没有证书,安全连接就会失败。服务器证书中包含很多字段,包
括:
web站点的名称和主机名
web站点的公开密钥
签名颁发机构的名称
来自签名颁发机构的签名
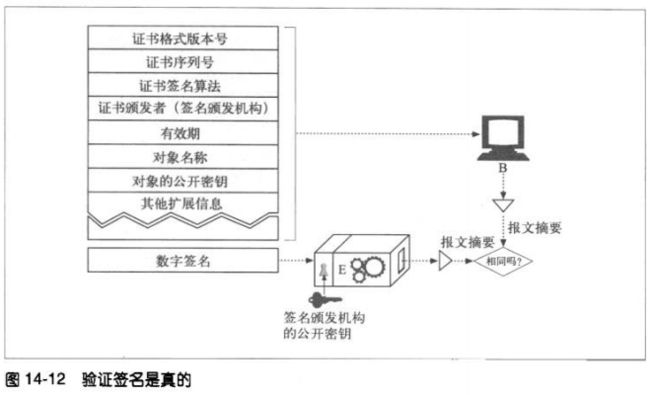
14.7 HTTPS——细节介绍
14.7.1 HTTPS概述
HTTPS就是在安全的传输层上发送的HTTP。HTTPS没有将未加密的HTTP报文发送给
TCP,并进行传输,它在将HTTP报文发送给TCP之前,先发送给一个安全层,进行加
密。
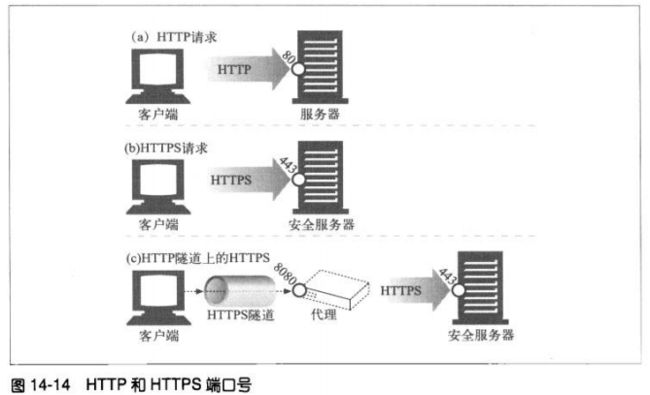
14.7.2 HTTPS方案
在HTTPS协议中,URL的方案前缀为https。请求一个客户端对某web资源执行某事务
时,回去检查URL的方案。
##若URL方案为http,客户端就会打开一条到服务器端口80(默认)的连接,并向其
发送老的HTTP命令。
##若是https方案,客户端会打开到服务器443端口的连接。然后与服务器“握手”,
以二进制格式与服务器交换一些SSL安全参数,附上加密的HTTP命令
SSL是个二进制协议,与HTTP完全不同,其流量承载在443端口。若到达80端口,大
部分web服务器会将二进制的SSL流量,理解为错误的HTTP并关闭连接。
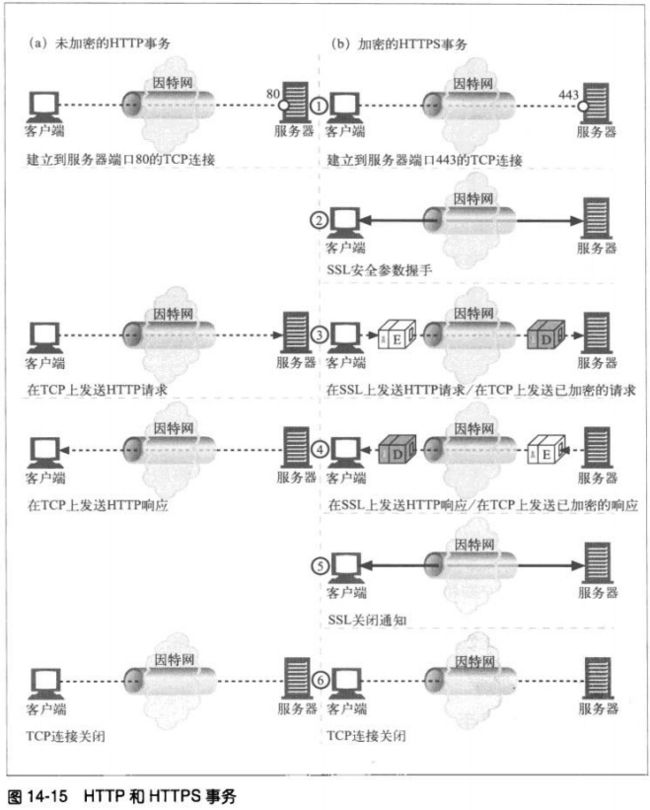
14.7.3 建立安全传输
客户端首先打开一条到web服务器端口443的连接。一旦建立了tcp连接,客户端和服
务器就会初始化SSL层,对加密参数进行沟通,并交换密钥。握手完成后,SSL初始化
就完成了,客户端可以将请求报文发送给安全层了。在将这些报文发送给TCP之前,先
对其加密。
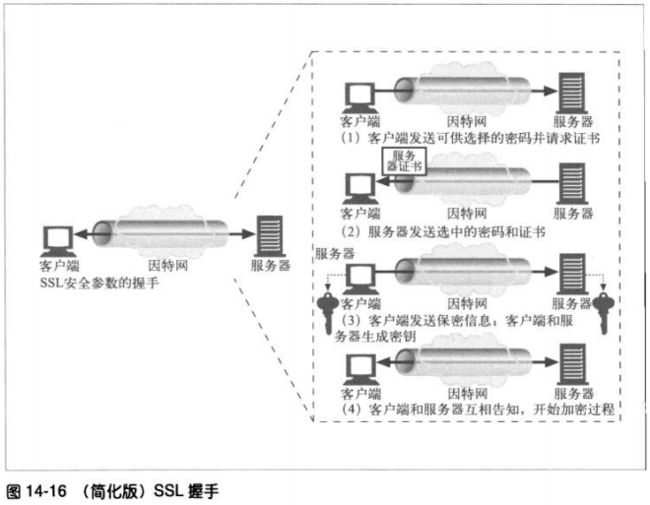
14.7.4 SSL握手
在发送已加密的HTTP报文之前,客户端和服务器要进行一次SSL握手,这个握手完成
以下工作:
#交换协议版本号
#选择一个两端都了解的密码
#对两端的身份进行认证
#生成临时的会话密钥,以便加密信道。
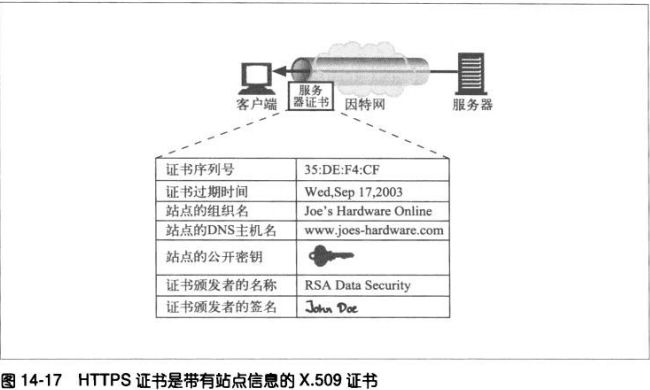
14.7.5 服务器证书
SSL支持双向认证,将服务器证书承载回客户端,将客户端证书回送给服务器。
服务器证书是一个显示了组织的名称、地址、服务器DNS域名以及其他信息的X.509
v3 派生证书。
14.7.6 站点证书的有效性
有效性验证步骤如下:
日期检测——证书的起始和结束日期。
签名颁发者可信度检测——每个证书都是由某些证书颁发机构(CA)签发的,它们负
责为服务器担保。有些证书会携带到受信CA的有效签名路径,浏览器可能会选择接受
所有此类证书。也就是说,如果某受信CA为“sam的签名商店”签发了一个证书,而
sam的签名商店也签发了一个站点的证书,浏览器可能会将其作为从有效CA路径导出
的证书而接受。
签名检测——一旦判定签名授权是可信的,浏览器就要对签名使用签名颁发机构的公
开密钥,并将其与校验码进行比较,查看证书的完整性。
站点身份检测——为防止服务器复制他人证书,或拦截其他人流量,大部分浏览器都
会试着去验证证书中的域名与它们所对话服务器的域名是否匹配。
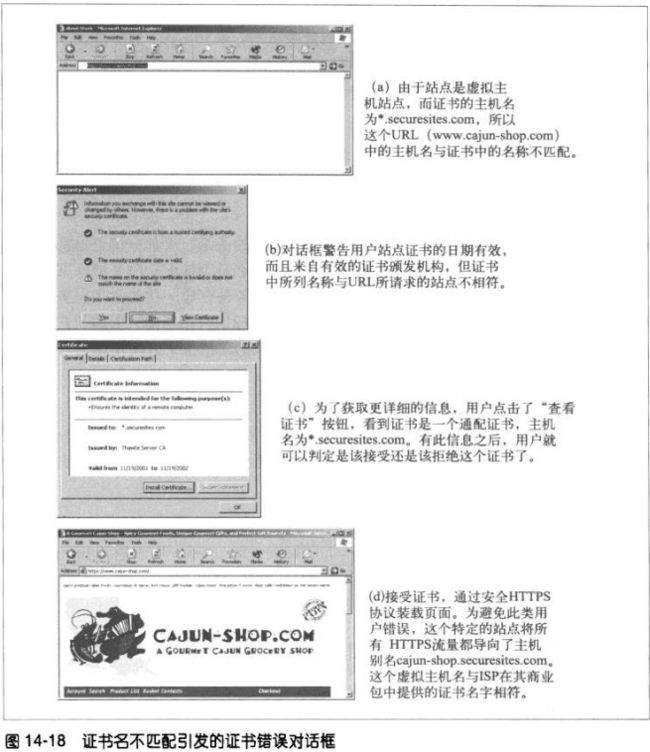
14.7.7 虚拟主机与证书
有些流行的web服务器程序只支持一个真实,如果用户请求的是虚拟主机名,与证书
名称不严格匹配,浏览器就会告警。
为防止这个问题,在开始处理安全事务时,将所有用户重定向到证书列出的官方主机
名。
14.8 HTTPS客户端实例
14.8.1 OpenSSL
由一些志愿者开发,目标是开发一个强壮而功能完备的商业级工具集,以实现SSL和
TLS协议以及一个全功能的通用加密库。
14.8.2 简单的HTTPS客户端


14.8.3 执行OpenSSL客户端

只要完成了签名4个部分,客户端就有了一条打开的SSL连接。这样它就可以查询连接
的状态,选择参数,检查服务器证书了。
这个例子中,客户端和服务器对DES-CBC3-MD5批量加密密码进行了沟通。
只要建立起SSL信道,并且客户端对站点证书无异议,就可以通过安全信道来发送
HTTP请求了。
14.9 通过代理以隧道形式传输安全流量
为了使HTTPS与代理配合工作,要进行几处修改以告知代理连接到何处。一种常用技术就
是HTTPS SSL隧道协议。
使用HTTPS隧道协议,客户端首先要告知代理,它想连接的安全主机和端口。这是在开始
加密之前以明文形式告知的。
HTTP通过新的名为CONNECT的扩展方法来发送明文形式的端点信息。CONNECT方法
会告诉代理,打开一条到所期望主机和端口号的连接。
之后,直接在客户端和服务器之间以隧道形式传输数据。CONNECT方法就是一条单行的
文本命令,它提供了由冒号分隔的安全原始服务器的主机名和端口号。

在请求中的空行之后,客户端会等待来自代理的响应。代理会对请求进行评估,确保它是
有效的。如果一切正常,代理会建立一条到服务器的连接。成功之后,就像客户端发送
200 Connection Established响应

第四部分 实体、编码和国际化
第十五章 实体和编码
15.1 报文是箱子,实体是货物

HTTP/1.1版定义了10个基本字体的实体首部字段:
Content-Type
实体中所承载对象的类型
Content-Length
所传送实体主体的长度或大小
Content-Language
与所传送对象最相配的人类语言
Content-Encoding
对象数据所做的任意变换(比如,压缩)
Content-Location
一个备用位置,请求时可通过它来获得对象
Content-Range
如果这是部分实体,这个首部来说明它是整体的哪个部分
Content-MD5
实体主体内容的校验和
Last-Modified
所传送内容在服务器上创建或最后修改的日期时间
Expires
实体数据将要失效的日期时间
Allow
该资源允许的各种请求方法
ETag
这份文档特定实例的唯一验证码。没有正式定义为实体首部
Cache-Control
应该如何缓存文档。同样未正式定义为实体首部
实体主体
首部字段以一个空白的CRLF行结束,随后就是实体主体的原始内容。

15.2 Content-Length:实体的大小
这个大小是包含了所有内容编码的,比如文本文件进行了gzip压缩,那么大小就是压缩后
的。
除非使用了分块编码,否则这个首部就是带有实体主体的报文必须使用的。使用这个首部
是为了能够检测出服务器崩溃而导致的报文截尾,并对共享持久连接的多个报文进行正确
分段。
15.2.1 检测截尾
HTTP早期版本采用关闭连接的方法来划定报文的结束。但是,没有Content-Length
的话,客户端无法区分是否是报文结束时正常关闭连接。客户端需要通过Content-
Length来检测报文截尾。
15.2.2 错误的Content-Length
有些客户端和服务器以及代理包含了特别的算法,用来检测和纠正与有缺陷服务器的
交互过程。HTTP/1.1规定用户Agent代理应该在接收接检测到无效长度时通知客户。
15.2.3 Content-Length与持久连接
Content-Length首部对于持久连接是必不可少的。但是在采用分块编码(chunked
encoding)时,使用持久连接可以没有Content-Length首部。这种情况下,数据时
分为一系列的块来发送的,每块都有大小说明。哪怕服务器在生成首部的时候不知道
整个实体的大小(通常因为是动态生成的),仍然可以使用分块编码传输若干已知大
小的块。
15.2.4 内容编码
如果主体进行了内容编码,则Content-Length首部就是编码后的主体字节长度。
15.2.5 确定实体主体长度的规则
①如果特定的HTTP报文类型中不允许带有主体,就忽略Content-Length首部,它是
对(没有实际发送出来的)主体进行计算的。这时,Content-Length首部是提示性
的,并不说明实际的主体长度。
例如HEAD响应,服务器发送等价的GET请求中会出现的首部,但不要包括主体。
②如果报文中含有描述传输编码的Transfer-Encoding首部,那实体就应由一个称
为“零字节块”(zero-byte chunk)的特殊模式结束,除非报文已经因连接关闭而结
束。
③若报文中有Content-Length首部(且报文允许有实体主体)而没有非恒等的
Transfer-Encoding首部字段,那么Content-Length的值就是主体的长度。当上述两
个首部同时存在时,就忽略Content-Length首部。
④若报文使用了multipart/byteranges(多部分/字节范围)媒体类型,且没用
Content-Length首部指出实体主体的长度,那么多部分报文中的每个部分都要说明它
自己的大小。
⑤如果上述规则都不匹配,实体就在连接关闭时结束。
HTTP/1.1规范建议,对于带有主体但没有Content-Length首部的请求,服务器如果
无法确定其报文长度,就该发送400 或 411 Length Required的响应,411表示服务
器要求收到正确的Content-Length首部。
15.3 实体摘要
服务器使用Content-MD5首部发送对实体主体运行MD5算法的结果。只有原始服务器才
可以这么做,中间代理和缓存不应该修改或添加这个首部。Content-MD5首部是在对内
容作了有所需要的编码之后,还没有做任何传输编码之前,计算得出。客户端需先进行传
输编码的解码,再计算所得的未进行传输编码的实体主体的MD5。比如一份文档经gzip
压缩,然后采用分块编码发送,那么就对整个gzip压缩的主机进行MD5计算。
除了检查完整性,MD5还可用来当做散列表的关键字来快速定位文档。
作为对HTTP的扩展,建议增加新的Want-Digest首部,允许客户端说明期望响应中使用
的摘要类型,并使用质量值来建议多种摘要并说明有限顺序。
15.4 媒体类型和字符集
Content-Type的值是标准化的MIME类型,都在互联网号码分配机构(Internet Assigned
Numbers Authority,IANA)中注册。MIME类型由一个主媒体类型后面跟一条斜线以及
一个子类型组成。

需注意,Content-Type首部说明的是原始实体主体的媒体类型,如果实体内容经过编码的
话,说明的仍是编码钱的实体主体类型。
15.4.1 文本的字符编码
Content-Type首部支持可选的参数来进一步说明内容的类型。charset(字符集)参数
就是个例子。它说明把实体中比特转换为文本文件中的字符的方法。
Content-Type: text/html; charset=ios-8859-4
15.4.2 多部分媒体类型
mutipart电子邮件报文 中包含多个报文,它们合在一起作为单一的复杂报文发送。每一
部分独立,有各自的描述其内容的集;不同部分之间用分界字符连接在一起。
HTTP也支持多部分主体。不过通常只在两种情况下:提交填写好的表格、或是作为承载
若干文档片段的范围响应。
15.4.3 多部分表格提交
当提交填写的HTTP表格时,变长的文本字段和上传的对象都作为多部分主体里面独立的
部分发送,这样表格中就可以填写各种不同类型和长度的值。
HTTP使用Content-Type:multipart/form-data 或 Content-Type:multipart/mixed
这样的首部以及多部分主体来发送这种请求。例如:
Content-Type: multipart/form-data; boundary=[asdfghjk]
其中的boundary参数说明了分割主体中不同部分所用的字符串。


15.4.4 多部分范围响应
HTTP对范围请求的响应也可以是多部分的。Content-Type: multipart/byteranges首
部和带有不同范围的多部分主体。

15.5 内容编码
15.5.1 内容编码过程
①服务器生成原始响应报文,其中有原始的Content-Type 和 Content-Length首部
②内容编码服务器(也可能就是原始服务器的下行代理)创建编码后的报文。编码后的
报文有同样的Content-Type但Content-Length可能不同(主体被压缩)。内容编码
服务器在编码后的报文增加Content-Encoding首部,这样接收的应用程序就可以进
行解码了。
③接收程序得到报文后,进行解码,得到原始报文。
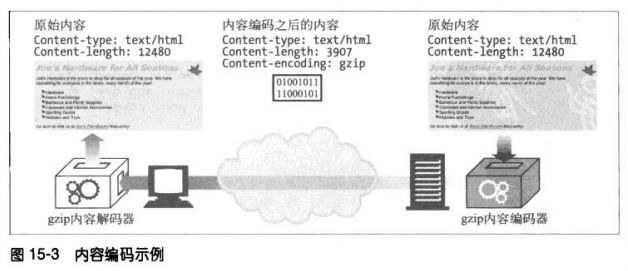
15.5.2 内容编码类型

gzip、compress以及deflate编码都是无损压缩算法,这些算法中,gzip通常是效率最
高的。
15.5.3 Accept-Encoding首部
客户端把自己支持的内容编码方式列表放在请求的Accept-Encoding首部里发送。若请
求中没有该首部,服务器就认为客户端能够接受任何编码方式。

客户端还可以给每种编码附带Q(质量)值来说明编码的优先级。从0.0-1.0,大优。
15.6 传输编码和分块编码
传输编码也是作用在实体主体上的可逆变换,但使用它们是由于架构方面的原因,与内容的
格式无关。使用传输编码是为了改变报文中的数据在网络上传输的方式。

15.6.1 可靠传输
在HTTP中,只有少数情况下,所传输的报文主体可能会引发问题。
@未知的尺寸
如果不先生存内容,某些网关应用程序和内容编码器就无法确定报文主体的最终大
小。通常,这些服务器希望在指定大小之前就开始传输数据。因为HTTP协议要求
Content=Length首部必须在数据之前,有些服务器就使用传输编码来发送数据,并
用特别的结束脚注表明数据结束。
@安全性
可以使用传输编码来把报文内容扰乱,然后再传输。但是由于SSL的发展,很少使用
传输编码来实现安全性了。
15.6.2 Transfer-Encoding首部
Transfer-Encoding首部用来告知接收方为了可靠的传输报文,已经对其进行了何种编码
TE首部用在请求中,告知服务器可以使用哪些传输编码扩展。
传输编码的值都是大小写无关的。最新的HTTP规范只定义了一种传输编码——分块编码
TE首部也可以设置Q值,但是禁止将分块编码的Q值设置为0.0。
15.6.3 分块编码
分块编码把报文分割为若干个大小已知的块。块之间紧挨着发送。
①分块与持久连接
若客户端和服务器不是持久连接,客户端就不需要知道它正在读取的主体的长度,而
只需要读到服务器关闭主体连接为止。
当使用持久连接,在服务器写主体之前,必须知道它的大小并在Content-Length首部
中发送。如果服务器动态创建内容,就可能在发送之前无法知道主体的长度。分块编
码提供了解决方案,只要允许服务器把主体逐块发送,说明每块的大小就可以了。因
为主体是动态创建的,服务器可以缓冲它的一部分,发送其大小和相应的块,然后在
主体发送完之前重复这个过程。服务器可以用大小为0的块作为主体结束的信号,这样
就可以继续保持连接,为下一个响应做准备。
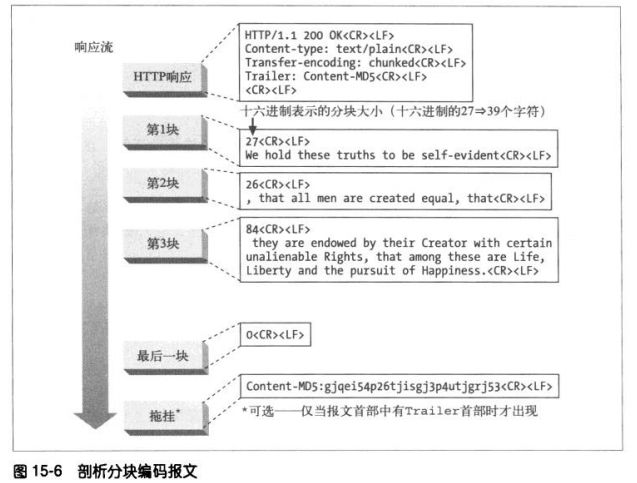
客户端也可以发送分块的数据给服务器,但是并不知道服务器是否接受,所以有可能
收到411 Length Required响应拒绝分块请求。
②分块报文的拖挂
若客户端TE首部中说明它可以接受拖挂,就可以在分块的报文最后加上拖挂。
拖挂中可以包含附带的首部字段,它们的值在报文开始的时候可能是无法确定的。上
图例子中的Content-MD5就是。报文首部中包含一个Trailer首部,列出了跟在分块报
文之后的首部列表。
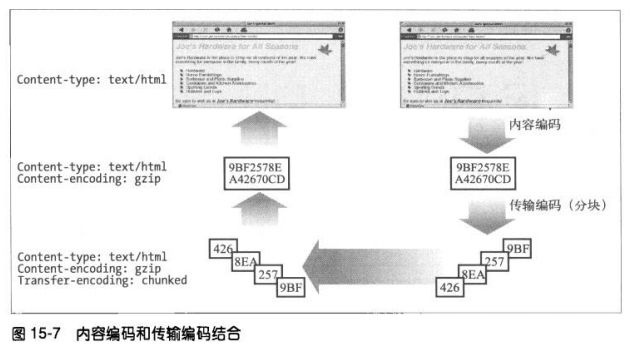
15.6.4 内容编码与传输编码的结合
15.6.5 传输编码的规则
传输编码集合中必须包括“分块”,唯一例外是使用关闭连接来结束报文。
但使用分块传输编码时,它必须是最后一个作用到报文主体之上的。
分块传输编码不能多次作用到一个报文主体上。
如果服务器收到无法理解的经过传输编码的报文,应该用501 Unimplemented状态码回
复
15.7 随时间变化的实例
网站对象并不是静态的。通用的URL会随着时间变化而指向对象的不同版本。
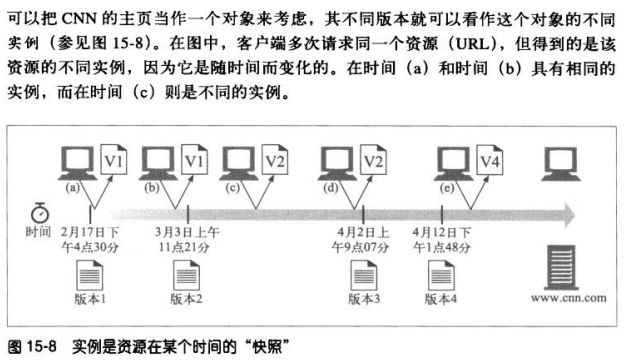
HTTP协议规定了称为实例操控(instance manipulations)的一系列请求和响应操作,用
以操控对象的实例。两个主要的实例操控方法就是:范围请求和差异编码。这两种方法都要
求客户端能够标示它所拥有(如果有的话)的资源的特定副本,并在一定条件下请求新的实
例。
15.8 验证码和新鲜度
有条件的请求(conditional request),比如验证缓存副本是否有效。这种请求要求客户
端使用验证码(validator)来告知服务器它当前拥有的版本号,并仅当它的当前副本不再
有效时才要求发送新的副本。
15.8.1 新鲜度
服务器通过Expires和Cache-Control来告知客户端将内容缓存多长时间。客户端和服务
器为了能正常使用Expires首部,必须时钟同步。

15.8.2 有条件的请求与验证码
有条件的请求是通过以”If-“开头的有条件首部来实现。有条件的首部使得方法仅在条件
为真时才执行。若条件不满足,服务器就发回一个HTTP错误码。
每个有条件的请求都通过特定的验证码来发挥作用。验证码是文档实例的一个特殊属
性,用来测试条件是否为真。从概念上说,可以把验证码看做文件的序列号、版本号或
最后发生改变的日期。Last-Modified和ETag是HTTP使用的两种主要验证码。

HTTP把验证码分为两类:弱验证码和强验证码。弱验证码不一定能唯一标识资源的一个
实例,而强验证码必须如此。弱验证码的一个例子是对象的大小字节数。而资源内容的
加密校验和(MD5)就是强验证码。
最后修改时间就被当做弱验证码。它的精度最大为1秒。ETag首部被当做强验证码。
有时候,客户端和服务器可能需要采用不那么精确的实体标记验证方法。例如,某服务
器可能想对一个很大、被广泛缓存的文档进行美化修饰,但不想在缓存服务器再验证时
产生很大的传输流量。这种情况下,服务器可以在标记前面加上“W/”前缀来广播一
个“弱”实体标记。对于弱实体标记来说,只有当关联的实体在语义上发生了重大改变
时,标记才会变化。

15.9 范围请求
通过范围请求,HTTP客户端可以通过请求曾获取失败的实体的一个范围,来恢复下载该实
体。但是有一个前提,就是从客户端上一次请求该实体到这次发出范围请求时间段内,对象
不曾改变。
上例中,客户端请求的是文档开头4000字节之后的部分。还可以用Range首部来请求多个
范围。例如,客户端同时连接到多个服务器,为了加速下载文档而从不同服务器下载同一个
文档的不同部分。服务器可以通过在响应中包含Accept-Range首部的形式来向客户端说明
可以接受的范围请求。这个首部的值是计算范围的单位,通常是以字节计算的。
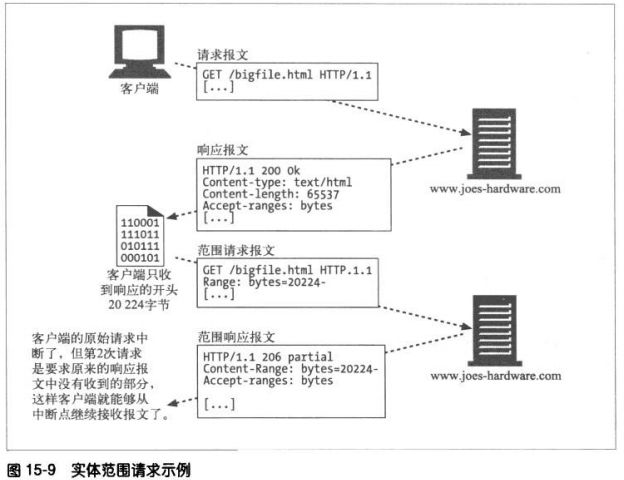
Range首部在流行的点到点(Peer-to-Peer,P2P)文件共享客户端软件中得到广泛应用。
注意范围请求也属于一类实例操控,因此针对特定的对象实例来交换信息。也就是说,客户
端的范围请求仅当客户端和服务器拥有文档的同一版本才有意义。
15.10 差异编码
差异编码通过交换对象改变的部分而不是完整对象来优化传输性能。(类似于增量更新),
它也是针对特定对象实例来交换信息。
客户端必须告诉服务器它有页面的哪个版本,愿意接受页面最新版的差异(delta),它懂
得哪些将差异应用于现有版本的算法。服务器必须检查它是否有这个页面的客户端现有版
本,计算客户端现有版本与最新版之间的差异。然后服务器必须计算差异,发送给客户端,
告知客户端所发送的是差异,并说明最新版页面的新标识(ETag)。
如果客户端想告诉服务器它愿意接受该页面的差异,只要发送A-IM首部就可以了。A-IM是
Accept-Instance(接受实例操控)的缩写。服务器发送一个特殊的响应代码——226 IM
Used,告知客户端它正在发送的是所请求对象的实例操控,而不是完整的对象自身。
一个IM首部用于说明计算差异的算法。
新的ETag首部和Delta-Base首部说明用于计算差异的基线文档的ETag。
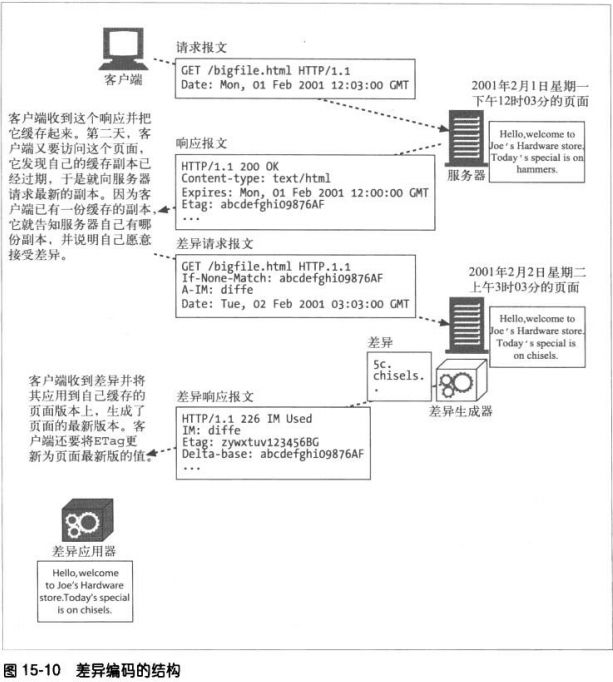

实例操控、差异生成器和差异应用器
客户端可以使用A-IM首部说明可以接受的一些实例操控的类型。服务器在IM首部中说明使
用的是何种实例操控。

服务器侧的“差异生成器”根据基线文档和该文档的最新实例,用客户端指明的算法计算差
异。客户端侧的“差异应用器”得到差异,将其应用于基线文档,得到文档的最新实例。
例如:采用Unix系统的diff-e命令产生差异。客户端就可以用Unix系统中文本编辑器ed提
供的功能来应用差异,因为diff-e 产生一系列命令来把file1 转化为 file2
diff-e算法是对文件进行逐行比较,因此不适用二进制文件。vcdiff算法更强大,且产生的
差异更小。
第十六章 国际化
16.1 HTTP对国际性内容的支持
服务器通过HTTP协议的Content-Type首部中的charset参数和Content-Language首部告
知客户端文档的字母表和语言。
同时,客户端发送Accept-Charset首部和Accept-Language首部,告知服务器它理解哪些
字符集编码算法和语言以及其中的优先顺序。
16.2 字符集与HTTP
16.2.1 字符集是把字符转换为二进制的编码
HTTP字符集的值说明如何把实体内容的二进制码转换为特定字母表中的字符。每个字符
集标记都命名了一种把二进制码转换为字符的算法。

有些字符编码(比如UTF-8,iso-2022-jp)更加复杂,它们是可变长编码,也就是说每个
字符的位数都是可变的。这种类型的编码允许使用额外的二进制位表示拥有大量字符的
字母表(比如汉语和日语),仅用较少的二进制位来表示标准的拉丁字符。
16.2.2 字符集和编码如何工作
把二进制码转换为字符要经过两个步骤:
①将二进制码转换成字符代码,它表示了特定编码字符集中某个编号的字符。
②字符代码用于从编码字符集中选择特定的元素
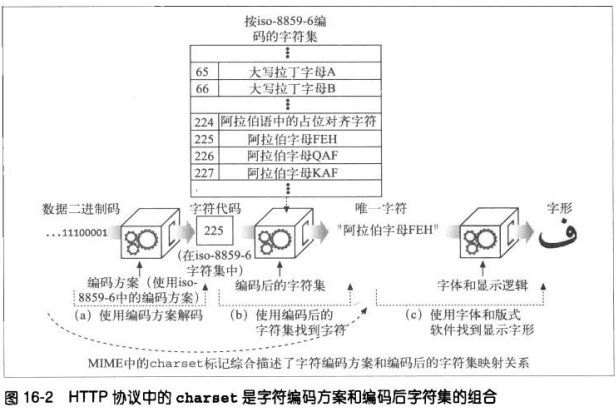
16.2.3 字符集不对,字符就不对

16.2.4 标准化的MIME charset值
特定的字符编码方案和特定的已编码字符集组合成一个MIME字符集。

16.2.5 Content-Type首部和Charset首部以及META标志
服务器可以通过charset参数把MIME字符集标记发送给客户端。
如果没有显式列出字符集,接收方可能就要设法从文档内容中推断出字符集。对于HTML
内容来说,可以在描述charset的 标记中找到字符
集。
16.3 多语言字符编码入门
16.3.1 字符集术语
①字符
字符是指字母、数字、标点、表意文字、符号或其他文本形式的书写“原子”。
②字形
表述字符的笔画图案或唯一的图形化形状。若一个字符有多种写法,就有多个字形。
③编码后字符
分配给字符的唯一数字编号。
④代码空间
计划用于字符代码值的整数范围。
⑤代码宽度
每个(固定大小的)字符代码所用的位数。
⑥字符库
特定的工作字符集(全体字符的一个子集)
⑦编码后字符集
组成字符库的已编码字符集,并为每个字符分配代码空间中的一个代码。
⑧字符编码方案
把数字化的字符代码编码成一系列二进制码的算法。
16.3.2 字符
字符是书写的最基本构建单元。

16.3.3 字形、连笔以及表示形式

16.3.4 编码后字符集
编码后字符集经常使用数组来实现,把整数映射到字符,通过代码数值来索引,数组的
元素就是字符。
1、US-ASCII:所有字符集的始祖
American Standard Code for Information Interchange 美国标准信息交换代码。
代码值只是从0~127。
2、iso-8859
是US-ASCII的8位超集。为不同地区定制了不同字符集:

3、JIS X 0201
把ASCII扩展到日文半款片假名字符的一个极小化的字符集。Japanese Industrial
Standard——JIS
4、UCS
Universal Character Set,统一字符集。
16.3.5 字符编码方案
①固定宽度
用固定数量的比特表示每个编码后的字符。能够被快速处理,但有可能浪费空间
②可变宽度(无模态)
对不同的字符代码数字采用不同数量的比特。
③可变宽度(有模态)
有模态编码使用特殊的“转义”模式在不同的模态之间切换。例如,可以用有模态的
编码在文本中使用多个互相有重叠的字符集。可以有效支持复杂的书写系统。
16.4 语言标记与HTTP
英语的标记是en,德语是de,韩语是ko。巴西葡萄牙语是pt-BR,美式英语是en-US等等
16.4.1 Content-Language首部
描述实体的目标受众语言。
16.4.2 Accept-Language首部
在该首部中可放入多个语言标记,从左到右的优先顺序。
16.4.3 语言标记的类型

16.4.4 子标记
语言标记有一个或多个部分,用连字符分隔,称为子标记。

16.4.5 大小写
所有的标记不区分大小写。习惯用小写表示一般的语言,用大写表示特定的国家。
16.4.6 IANA语言标记注册
第一个和第二个语言子标记的值由各种标准文档以及相关的维护组织定义。如果语言标
记由标准的国家和语言值组成,标记就不需要专门注册。只有那些无法用标准的国家和
语言值构成的语言标记才需要专门向IANA注册。
16.4.7 第一个子标记——名字空间
第一个子标记通常是标准化的语言记号,选自ISO 639语言标准集合。不过也可以用字母
i来标识在IANA中注册的名字,或x表示私有的或扩展的名字。
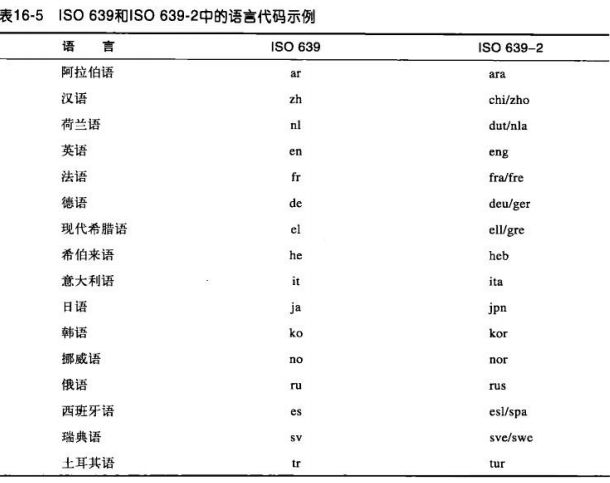
16.4.8 第二个子标记——名字空间
第二个子标记通常是标准化的国家记号,选自ISO 2166中的国家代码和地区标准集合。
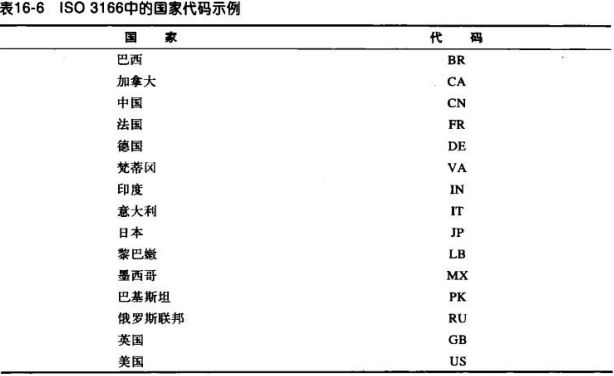
其余子标记——除了最长可以到8个字符之外,第三个和其后的子标记没有特殊规则。
16.5 国际化的URI
转义和反转义
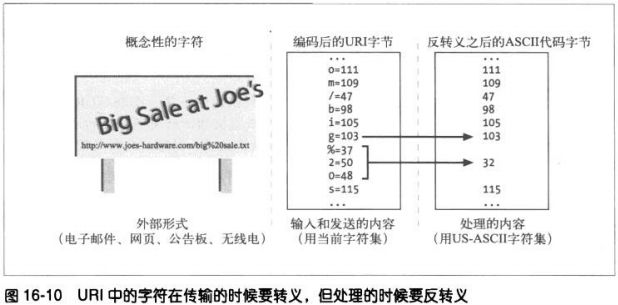
第十七章 内容协商与转码
17.1 内容协商技术
有三种方法可以决定服务器上哪个页面最适合客户端:让客户端选择、服务器判定,或让中
间代理来选。我们称之为:客户端驱动的协商、服务器驱动的协商、透明协商。
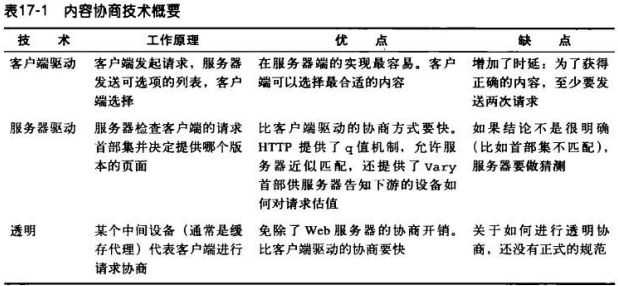
17.2 客户端驱动的协商
服务器实际上有两种方法为客户端提供选项:一是发送回一个HTML文档,里面有到该页面
的各种版本的链接和每个版本的描述信息;二是回送300 Multiple Choices响应码。客户
端浏览器收到这种响应时,前一种情况下,会显示一个带有链接的页面;后一种情况下、可
能会弹出对话窗口,让用户做选择。无论如何,决定是由客户端的浏览器用户做出的。
除了增加延时并对每个页面进行多次请求之外,还有一个缺点就是需要多个URL:公共页面
一个,每种特殊页面一个。
17.3 服务器驱动的协商
有两种机制可供HTTP服务器评估发送什么响应给客户端比较合适。
①检查内容协商首部集。服务器可查看客户端发的Accept首部集。
②根据其他非内容协商首部进行变通。例如,根据客户端的User-Agent首部来发响应。
17.3.1 内容协商首部集
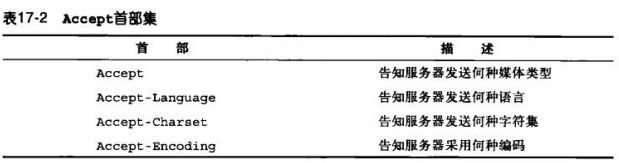
需要注意这些与之前的实体首部非常类似,但是实体首部集像运输标签,它描述了把报
文从服务器传输给客户端的过程必须的各种报文主体属性。而内容协商首部集是由客户
端发送给服务器用于交换偏好信息的。

由于HTTP是无状态协议,服务器不会再不同的请求间追踪客户端的偏好,所以客户端必
须在每个请求中发送偏好信息。
17.3.2 内容协商首部中的质量值
Accept-Language: en;q=0.5, fr;q=0.0 , nl;q=1.0, tr;q=0.0
注意排列顺序并不影响,只关心q值。
当服务器找到可匹配的偏好情况,服务器可以修改文档,通过转码来匹配客户端的偏
好。
17.3.3 随其他首部集而变化
服务器也可以根据其他首部集来匹配响应,比如User-Agent首部,服务器知道老版本的
浏览器不支持JavaScript语言,这样就不向其发送有JavaScript的页面版本。
由于缓存需要尽量提供文档中正确的”最佳“版本,HTTP协议定义了服务器在响应中发
送的Vary首部。这个首部告知缓存(还有客户端和所有下游的代理)服务器根据哪些首
部来决定发送响应的最佳版本。
17.3.4 Apache中的内容协商
将索引页面文件放在和站点相关的Apache服务器的适当目录下。两种方式启用内容协
商:
①在网站目录中,为网站中每个有变体的URI创建一个type-map(类型映射)文件。这
个type-map文件列出了每个变体和其相关的内容协商首部集。
②启用MultiViews指令。这样会使Apache自动为目录创建type-map文件。
1、使用type-map文件
Apache服务器需要知道type-map文件的命名规则,可在服务器的配置文件中设置
handler来说明type-map文件的后缀名。
AddHandler type-map .var

2、使用MultiView
前提是必须在网站目录下的access.conf文件中的适当小结
(//)使用OPTION指令来启用。
启用之后,如果浏览器请求了名为joes-hardware的资源,服务器就会查找所有名字里
含有此内容的文件,并为它们创建type-map文件。
17.3.5 服务器端扩展
比如微软的ASP Active Server Pages。
17.4 透明协商
17.4.1 进行缓存与备用候选
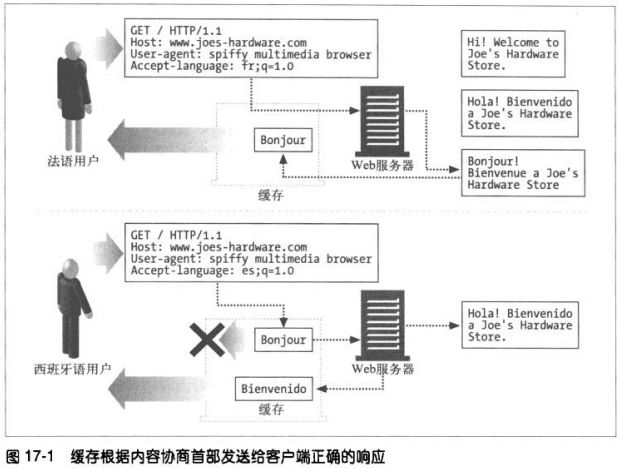
17.4.2 Vary首部
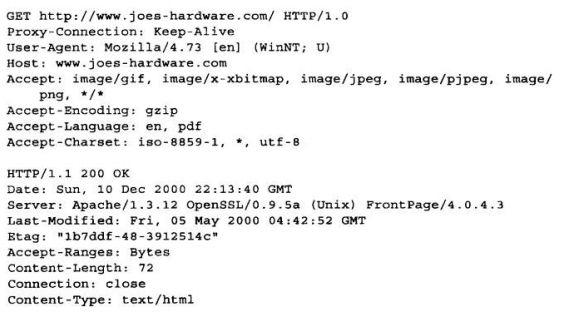
HTTP的Vary响应首部中列出了所有客户端请求首部,服务器可以用这些首部来选择文档
或产生定制内容。例如,若提供的文档取决于User-Agent首部,Vary首部就必须包含
User-Agent首部。
新请求到达时,缓存会根据内容协商首部集来寻找最佳匹配。但在把文档提供给客户端
之前,它必须检查服务器有没有在已缓存响应中发送Vary首部。如果有,那新请求中那
些首部的值必须与旧的已缓存请求里相应的首部相同。
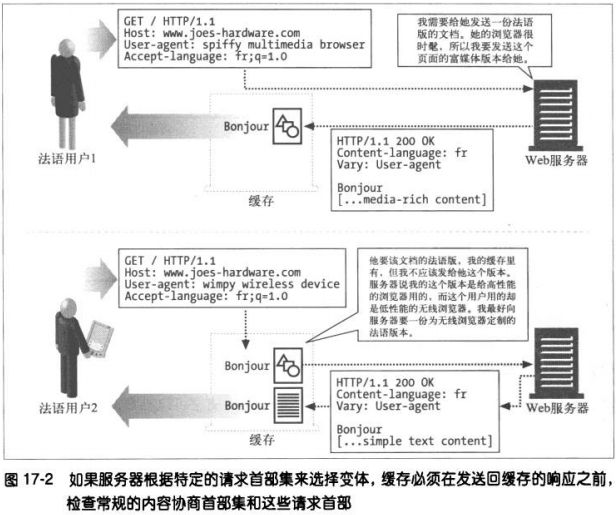

17.5 转码

17.5.1 格式转换
格式转换可以由内容协商首部集来驱动,也可以由User-Agent首部来驱动。
17.5.2 信息综合
从文档中提取关键的信息片段称为信息综合(information synthesis),这种操作的例
子包括根据小节标题生成文档大纲,或者从页面中删除广告和商标。
根据内容关键字对页面分类是更精细的技术,常用于web页面分类系统,如门户网站。
17.5.3 内容注入
前面两类转码通常会减少文档内容,但内容注入会增加文档内容,比如自动广告生成器
和用户追踪系统。
17.5.4 转码与静态预生成的对比
转码的替代做法是在web服务器上建立web页面的不同副本。
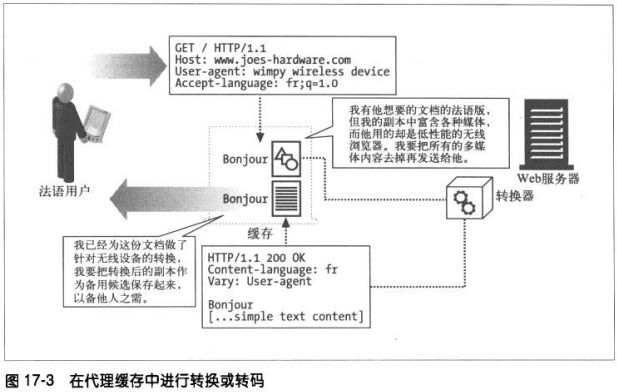
第五部分 内容发布与分发
第十八章 WEB主机托管
对内容资源的存储、协调以及管理的职责统称为WEB主机托管。
18.1 主机托管服务
18.2 虚拟主机托管
18.2.1 虚拟服务器请求缺乏主机信息
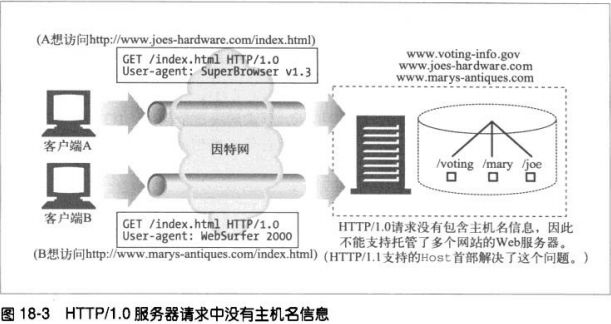
18.2.2 设法让虚拟主机托管正常工作
4中技术:
①通过URL路径进行主机托管
在URL中增添专门的路径部分,以便服务器判断是哪个网站。
产生多余的前缀,而且描述主页链接的常见约定:http://xxx.sss.com/index.html 就不
能用了。
②通过端口号进行主机托管
③通过IP地址进行主机托管
为不同的虚拟站点分配专门IP地址,把这些地址都绑定到一台单独的机器上。这样,
web服务器可以通过IP地址来识别网站名。
服务器可以通过查询HTTP连接的目的ip地址,来判定客户端的目标网站。
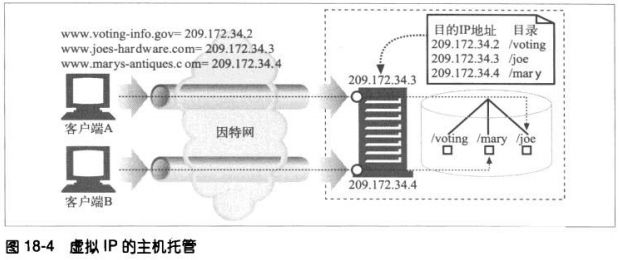
在计算机系统上能绑定的虚拟IP地址通常是由限制的。
IP地址是稀缺资源。有很多虚拟站点的托管者不一定能为被托管的网站获取足够多的IP。
想要通过复制服务器来增加容量时,IP地址短缺的问题就更严重了。
④通过HOST首部进行主机托管
HTTP/1.0增强版和HTTP/1.1正式版定义了Host首部来携带网站名称。
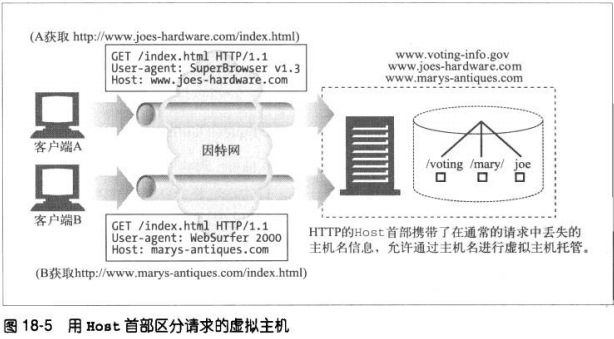
18.2.3 HTTP/1.1 的Host首部
1、语法与用法
Host = “Host” “:” host [ “:” port ]
注意:
若URL中包含IP,Host首部就应当包含同样的地址。
若URL中包含主机名,Host首部必须包含同样的名字。而且不应该包含这个主机名对应
的ip地址和包含这个主机名的其他别名。
若客户端显示使用代理,客户端就必须把原始服务器的名字和端口放在Host首部中。
HTTP/1.1 的web服务器必须用400 状态码来响应所有缺少Host首部的HTTP/1.1请求报
文。
2、缺少Host首部
少量老式浏览器不发送Host首部,这样服务器可能会把用户导向某个默认页面,也可能
返回错误页面提示客户升级。
3、解释Host首部
若在HTTP请求报文中URL是绝对的(包含方案和主机部分),就忽略Host首部的值。
若URL中没有主机部分,而请求带有Host首部,主机、端口就从host首部中取。
前两步无法获取有效主机,返回400响应。
18.3 使网站更可靠
18.3.1 镜像的服务器集群
镜像的服务器常常组成层次化的关系。某个服务器可能充当“内容权威”——它含有原
始内容。这个服务器称为主原始服务器(master origin server),从主原始服务器接收
内容的镜像服务器称为复制原始服务器(replica origin server)。一种简单的部署是用
网络交换机把请求分发给服务器。每个网站的ip地址就设置为交换机的ip地址。
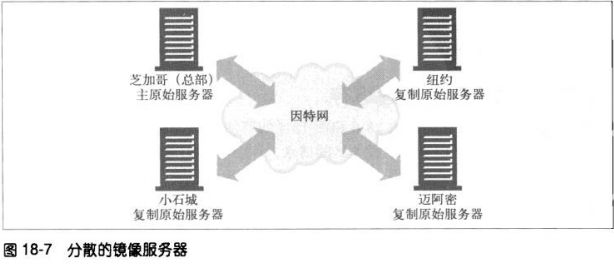
分散的镜像服务器可以通过HTTP重定向和DNS重定向来把客户端的请求导向特定的服务
器。
18.3.2 内容分发网络
内容分发网络(CDN)就是对特定内容进行分发的专门网络。这个网络的中间节点可以是
服务器、反向代理或缓存。
18.3.3 CDN中的反向代理缓存
复制原始服务器可以通过反向代理缓存来代替。反向代理缓存可以像镜像服务器一样接
受服务器请求。它们代表原始服务器中的一个特定集合来接收服务器请求。
反向代理和镜像服务器之间的区别在于反向代理通常是需求驱动的。它们不会保存原始
服务器的全部内容副本,它们只保存客户端请求的那部分内容。内容在其告诉缓存中的
分布情况取决于它们收到的请求,原始服务器不负责更新它们的内容。有些反向代理具
有“预取”特性,可在用户请求之前就从服务器上载入内容。
18.3.4 CDN中的代理缓存
与反向代理不同在于,传统的代理缓存能收到发往任何WEB服务器的请求。代理缓存的
内容一般都是按需驱动的,不能指望它是对原始服务器内容的精确复制。按需驱动的代
理缓存可以部署在拦截环境中,2层或3层设备可以拦截web流量并发送给代理缓存。
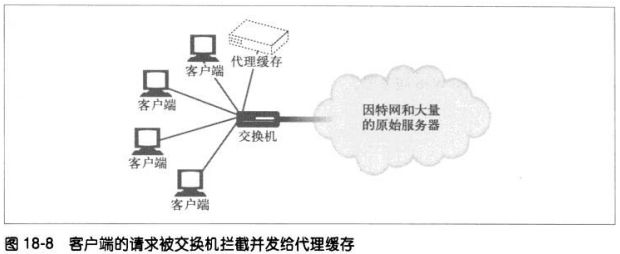
第十九章 发布系统
19.1 FrontPage为支持发布而做的服务器扩展
FrontPage是微软提供的一种通用web写作和发布工具包。
19.1.1 FrontPage服务器扩展
这些服务器端组件和web服务器集成在一起,在网站和运行FrontPage的客户端(以及
其他支持这些扩展的客户端)之间提供了必要的转接工作。
我们主要关注FrontPage客户端和FPSE之间的发布协议。
FrontPage的发布协议在HTTP的POST请求之上实现了一个RPC(Remote Procedure
Call,远程过程调用)层。它允许FrontPage客户端向服务器发送命令来更新网站上的文
档、进行搜索以及在多个web作者之间进行协作。
web服务器看到以FPSE(在非IIS服务器上就以一组CGI程序的方式实现)为接收地址的
POST请求,就对其进行相应的引导。只要中间的防火墙和代理都配置为允许使用POST
方法,FrontPage就能与服务器持续通信。
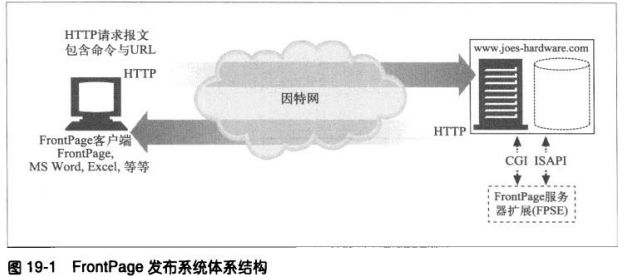
19.1.2 FrontPage术语表FrontPage
虚拟服务器
在同一服务器上运行的多个网站之一,每个都有唯一的域名和ip地址。支持虚拟服务
器的web服务器称为多路托管(multi-hosting)web服务器。配置有多个ip地址的机
器称为多宿主(multi-homed)服务器。
根web
web服务器默认的顶层内容目录,或是在多路托管环境下,虚拟web服务器的顶层内
容目录。要访问根web,只需指定服务器的URL,每个服务器只能有一个根web。
子web
根web的已命名子目录或另一个完全由FPSE扩展的子web。子web可以是完全独立的
实体,能够指定自己的管理和写作权限。此外,子web还能提供方法(比如搜索)的
作用范围。
19.1.3 FrontPage的RPC协议
该协议构建在POST方法之上,它把RPC的方法及其相关的变量嵌入在POST请求的主体
中。
在开始处理之前,客户端需要知道服务器上目标程序(FPSE包中能够执行这些POST请
求的相关部分)的位置和名称。接下来它会发送一个特殊GET请求。
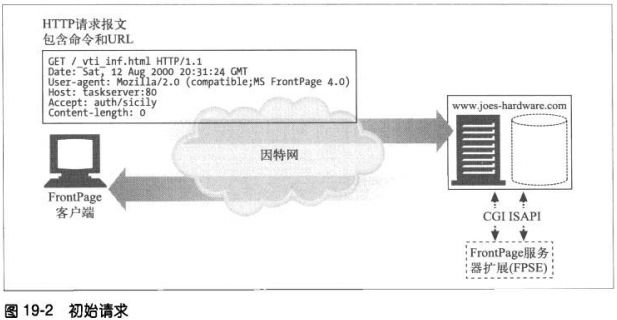

1、请求
POST请求的主体包含RPC命令,形式是method= 及任何需要的参数。
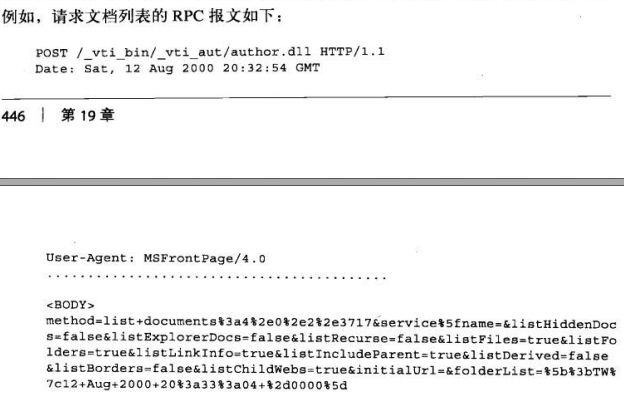
与CGI程序一样,方法中的空格被编码为“+”,所有其他非字母数字的字符被编码
为%XX的格式。
某些元素的含义:
service_name
方法应该在该URL表示的网站上执行。必须是已有文件夹或者已有文件夹的下层文件夹
listHiddenDocs
若为true,则显示网站中隐藏的文档。所谓隐藏就是指其URL的路径部分以”_”开头。
listExploreDocs
值为true,就列出任务列表。
2、响应
大多数RPC协议方法都有返回值,大多常见的返回值都用来表示方法成功 和各种错误。
有些方法还有第三种类别的返回值,称为“采样返回码”。FrontPage会对这些代码进
行适当的解释,为用户提供准确的反馈。
19.1.4 FrontPage的安全模型
FPSE安全模型定义了3中用户:管理员、作者以及浏览者。所有权限都是累积的,就是
说所有的管理员都能编写和浏览FrontPage的网站。类似的,所有作者都有浏览权限。
对于给定的由FPSE扩展的网站,管理员、作者、以及浏览者的列表都要定义好,所有的
子web可以从根web继承权限,也可以自定义。对于非IIS服务器,所有的FPSE程序都要
保存在标记为“可执行”的目录中。
在IIS服务器上,权限是通过给定根web目录或子web的根目录上的ACL来制定的。当IIS
收到请求,首先登录,并模拟用户,接着发送请求到上述的三个DLL之一。收到请求的
DLL根据目标文件夹上定义的ACL检查所扮演用户的证书。若通过,则请求的操作由扩展
DLL来执行,否则向客户端发回“permission denied”报文。
19.2 WebDAV与协作写作
WebDAV(web Distributed Authoring and Versioning,分布式写作与版本管理)为
web发布增添了新的功能——协作。
19.2.1 WebDAV的方法
WebDAV定义了一些新的HTTP方法并修改了其他一些HTTP方法的操作范围。
PROPFIND——获取资源的属性。
PROPPATCH——在一个或多个资源上设定一个或多个属性。
MKCOL——创建集合
COPY——从指定的源端把资源或者资源集合复制到指定的目的地。目的地可在另外一
台机器上。
MOVE——与COPY类似,但是是剪切。
LOCK——锁定一个或多个资源。
UNLOCK——将之前的锁定的资源解锁。
WebDAV修改的HTTP方法有DELETE/PUT/OPTIONS.
19.2.2 WebDAV与XML
WebDAV的方法通常都需要在请求和响应中关联大量的信息。HTTP通常用报文首部来交
换这类信息。然而,这有一定的局限性,包括难以有选择地对请求中多个资源应用首部
信息、不利于表示层次结构等。
借助XML解决这个问题:
@对那些描述数据处理方式的指令进行格式化的方法。
@在服务器上对复杂的响应进行格式化的方法。
@交换与所处理的集合和资源有关的定制信息的方法。
@承载数据自身的灵活工具
19.2.3 WebDAV首部集
DAV——用于了解服务器的WebDAV能力。WebDAV支持的所有资源在响应OPTIONS
请求时都要含有此首部。
DAV = “DAV” “:” “1” [“,” “2”] [ “,” 1#extend ]
Depth——用于把WebDAV扩展到支持含有多级层次关系的资源组。类似于目录深度。
用到Depth首部的方法有:LOCK/COPY/MOVE
Destionation——用来辅助COPY或MOVE方法识别目标URI。
If——定义的唯一一个状态令牌是锁定令牌。If首部定义了一组条件,如果这些条件都取
实践中,最常见的需要满足的条件是先获得锁。
Lock-Token——UNLOCK方法需要这个首部指定要删除的锁。LOCK方法的响应中也有
Lock-Token首部,载有关于锁定令牌的必须信息。
Overwrite——用于COPY/MOVE方法,指定是否要覆盖目标。
Timeout——客户端用这个请求首部指定要求锁定的超时值。
19.2.4 WebDAV的锁定与防止覆写
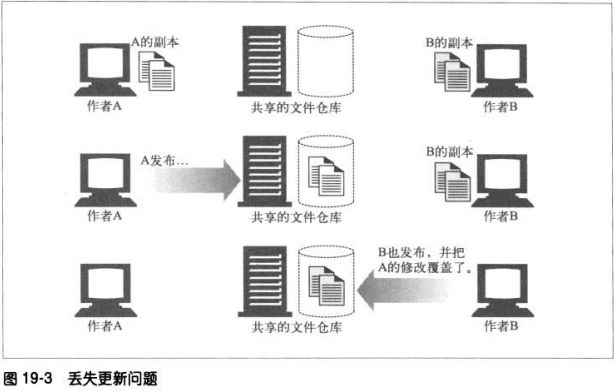
WebDAV支持两种类型的锁:
1—对资源或集合的独占写锁
2—对资源或集合的共享写锁
独占写锁保证只有锁的拥有者有写权限。这种锁完全消除了潜在的冲突。共享写锁允许
多个人在某个给定的文件上工作。WebDAV通过PROPFIND方法提供了属性发现机制,
可以判断对锁定的支持和所支持的锁定的类型。
WebDAV中有两个新方法支持锁定机制:LOCK UNLOCK
为了实现锁定,还需要有一种识别作者的机制。WebDAV采用的是摘要认证。
批准锁定时,服务器将域内唯一的令牌返回给客户端。与此相关的规范是
opaquelocktoken锁定令牌URI方案。当客户端随后要执行写操作时,它连接到服务器
并完成摘要认证步骤。一旦认证完成,WebDAV客户端就发出带有锁定令牌的PUT请
求,这样,只有正确的用户加上锁定令牌才可以完成写操作。
19.2.5 LOCK方法
WebDAV中的一个强大特性就是它能够允许单个LOCK请求锁定多个资源。WebDAV的
锁定不要客户端保持与服务器的连接。
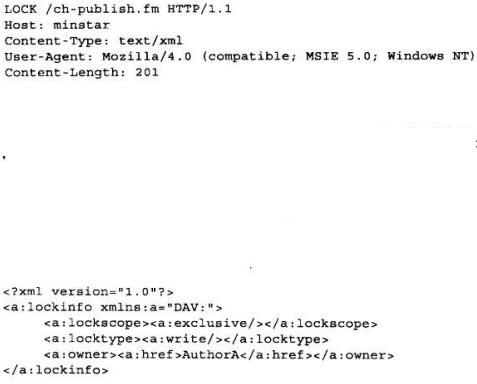
提交的XML以 元素作为基元素。在 结构中,有以下3中子元素:


元素充当着存储锁信息的容器。嵌在其中的子元素有 ,它
持有请求发送来的信息。此外 中含有以下子元素。
用称为opaquelocktoken的URI方案唯一标识的锁。该令牌用于在将来的请求中标识锁
的所有权。
它是Depth首部的值的副本。
指明锁的超时时间。
1、opaquelocktoken方案
设计用来在所有时间内对所有资源提供唯一令牌的方案。为了确保唯一性,WebDAV规
范采用IS0-11578中描述的UUID机制。
在实际实现时,有一定的回旋余地。服务器可以选择为每个LOCK请求生成一个UUID,
或者生成单个UUID并通过在结尾附加额外的字符来维护唯一性。如果采用后者,就必须
保证附加的扩展部分永远不会重用。
2、XML元素
该元素提供了发现活跃的锁的机制。如果有人试图去给已经被锁定文件上锁,他会收到
指明当前拥有者的XML元素 ,列出了所有未解除的锁和响应的属性。
3、锁的刷新和Timeout首部
为了刷新锁,客户端需要重新提交锁定请求,并把锁定令牌放在If首部中。
除了接受服务器给定的超时时间,客户端可以在Timeout首部中指定要求的超时值。
服务器没有义务必须满足这些选项。但是,客户端必须在XML元素 中提供锁
定过期的时间。无论如何,锁定超时只是一个指导值,服务器不一定受其约束。管理员
可以重设,某些异常时间也可能导致服务器重设锁,客户端应避免锁定时间太长。
19.2.6 UNLOCK方法
用于解除资源上的锁。
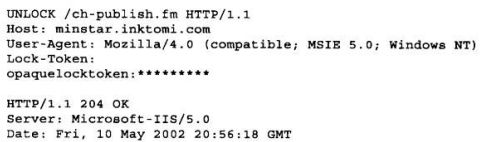
要使UNLOCK操作成功,WebDAV要满足:已经成功完成了摘要认证,,要与在Lock-
Token首部中发送的锁定令牌相匹配。
若解锁成功,会向客户端发送204 No Content状态码。
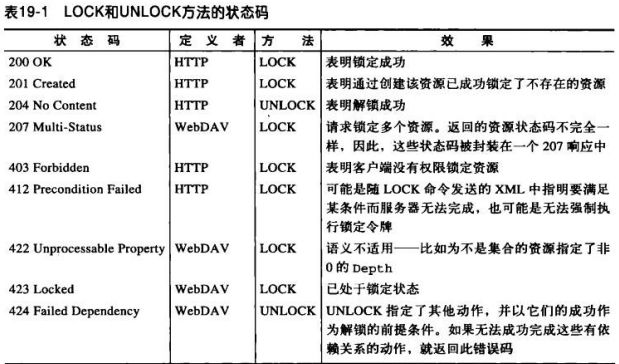
19.2.7 属性和元数据
属性描述了资源的信息,包括作者名字、修改日期、内容分级等等。HTML中的元标记的
确提供了把这种信息嵌入在内容之中的机制,但很多中资源(二进制数据)都无法嵌入
元数据。
像WebDAV这样的分布式协作系统对属性的需求就更复杂了。比如文档被编辑后,应该
更新这个属性以反映新的作者。WebDAV专门把这种可动态修改的属性称为“活”属
性。与之相对的是更长久的静态属性,比如Content-Type, “死”属性。
19.2.8 PROPFIND方法
该方法用于获取一个给定文件或一组文件(集合)的属性。它支持3中类型的操作:
@请求所有属性及其值
@请求一组属性及其值
@请求所有属性的名称

请求原始指定了从PROPFIND方法返回的属性。下面这些列表总结了用于
PROPFIND请求的一些XML元素:
-
要求返回所有属性的名字和值。 -
指定要返回属性名字的集合
指定需要返回值的属性。例如: ……

——多重响应的容器
——标识资源的URI。
——包含特定请求的HTTP状态码。
——将一个和 元素组织在一起。
19.2.9 PROPPACH方法
该方法为对指定资源设置或删除多个属性提供了原子化机制。原子化机制可以保证要么
所有请求都成功,要么跟所有请求都没发出一样。
PRPPATCH方法的XML基元素是 。它作为一个容器使用,容纳了需要
修改的属性。
指定要设置的属性值。含有一个或多个 子元素。若属性已经存在,其值被覆盖。
指定要删除的属性。

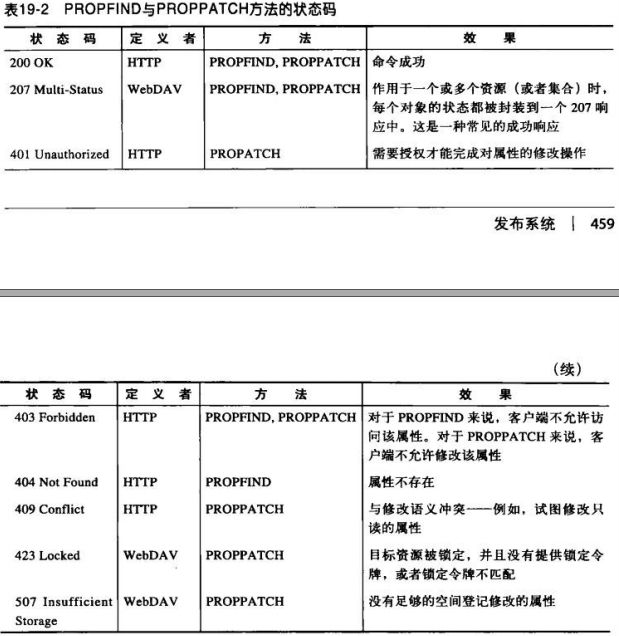
19.2.10 集合与名字空间管理
集合是指对预定义的层次结构中的资源进行的逻辑或物理上的分组。集合的一个典型例
子就是目录。集合作为其他资源(也包括其他集合)的容器使用。类似于文件系统中的
目录一样。
WebDAV使用了XML的名字空间机制。XML名字空间的分区在阻止所有名字空间冲突的
同时,还允许进行精确的结构控制。
WebDAV提供5中方法对名字空间进行操作。
19.2.11 MKCOL方法
该方法允许客户端在服务器上指定的URL处创建集合。

假设集合已经存在,那么请求会失败,状态码是405 Method Not Allowed。
若没有写权限,状态码是403
若发出MKCOL /colA/colB,而colA不存在,状态码是409 Conflict。
19.2.12 DELETE方法
若要删除一个目录,就要提供Depth首部。若没有指定Depth首部,则该目录的所有文
件和子目录都被删除。响应中也有Content-Location首部,其值就是刚被删除的集合。
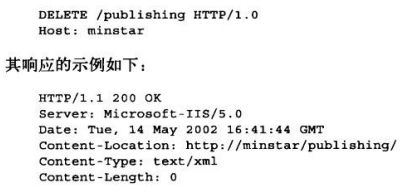
删除集合时,若某个文件被其他人锁定,那么集合自身也无法删除,服务器会以207状态
码响应。
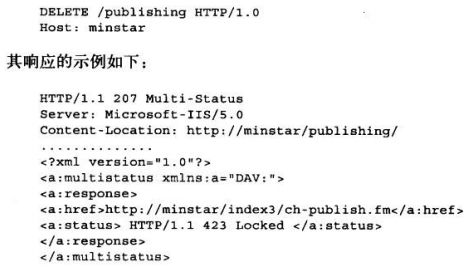
19.2.13 COPY MOVE方法
COPY和MOVE方法都将请求URL作为源,HTTP的Destination首部的内容作为目标。
MOVE方法还需要把源URL复制到目的地,检查新创建的URI的完整性,再把源删除。
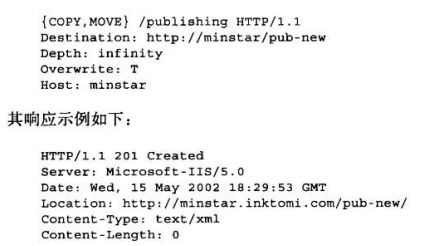
在对集合进行操作时,COPY和MOVE的行为受到Depth首部的影响。若Depth值为0,
方法就只作用于资源本身。
对于MOVE方法,Depth值只允许为无穷大。
1、Overwrite首部的效果
若设置该首部的值为T而且目标已存在,就在COPY或MOVE 之前对目标资源进行Depth
值为无穷大的DELETE操作。若设置为F,而目标资源存在,则操作失败。
2、对属性的COPY/MOVE
复制集合或元素时,默认会复制其所有属性。但请求可以带有可选的XML主体来提供额
外的操作信息。

3、被锁定的资源与COPY/MOVE
资源被锁定就禁止移动或复制到目标上。若在一个自己有锁的现存集合中创建目标,所
复制或移动的资源就会被加到那个锁中。

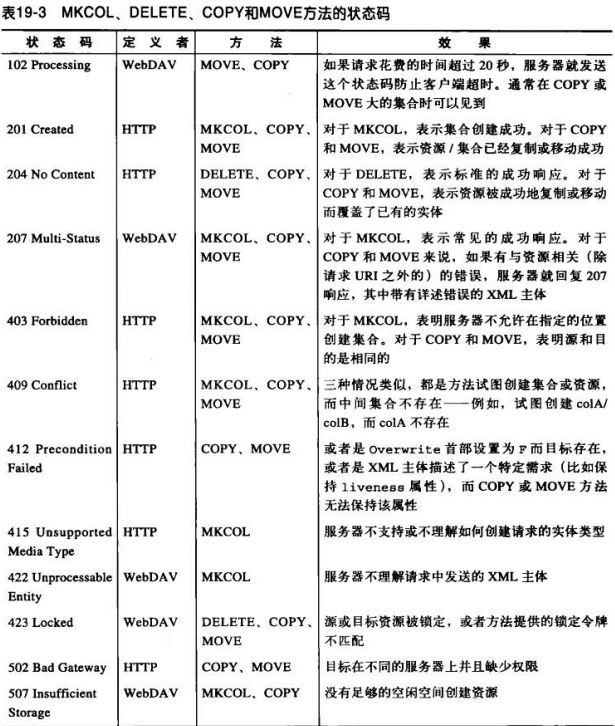
19.2.14 增强的HTTP/1.1方法
1、PUT方法
WebDAV修改了该方法以支持锁定。
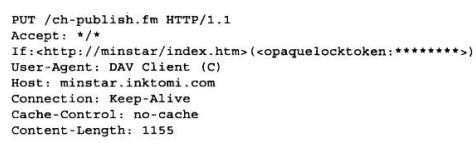
为了支持锁定,WebDAV在PUT请求中增加了If首部。
2、OPTIONS方法
客户端可以用OPTIONS方法验证WebDAV的能力。
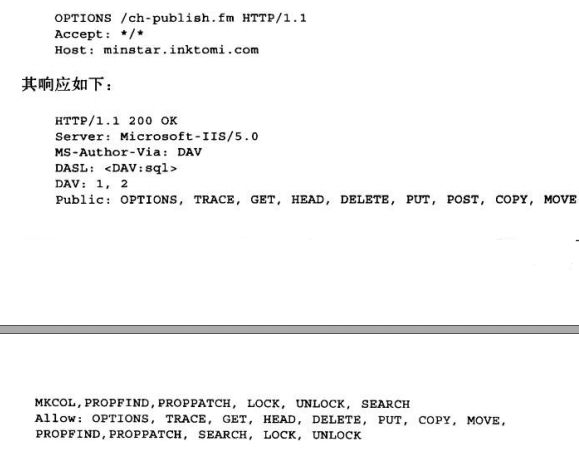
DAV首部携带了DAV遵从级别的信息。有两类遵从:
①要求服务器遵从RFC2518每节中的所有MUST需求。若资源只能达到第一类遵从,就
在DAV首部中发送1。
②满足所有第一类的需求,并增加对LOCK方法的支持。除LOCK方法之外,第二类遵从
还要求支持Timeout和Lock-Token首部以及 和 这俩
元素。
DASL首部说明了在SEARCH方法中使用的查询语法的类型。
第二十章 重定向与负载均衡
20.3 重定向协议概览
①配置创建客户端报文的浏览器应用程序,使其将报文发送给代理
②NDS解析程序会选择用于报文寻址的IP地址。对于不同物理地域,这个ip可能不同。
③web服务器可以通过HTTP重定向将请求反弹给不同的web服务器。
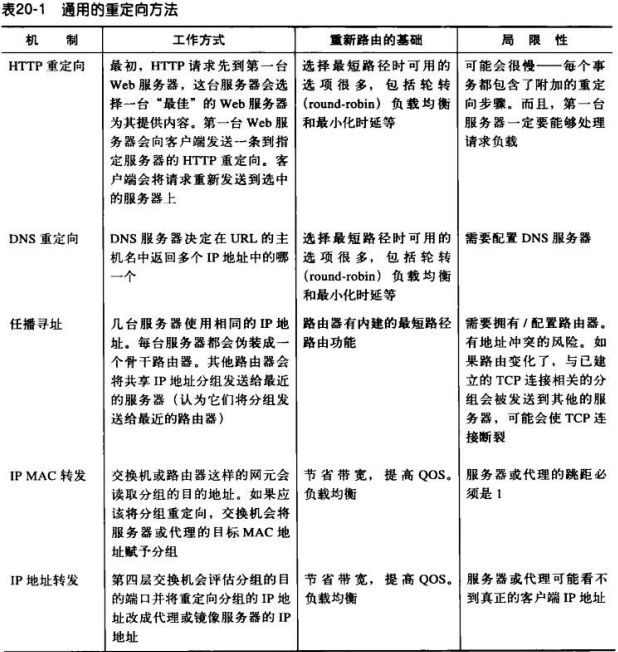
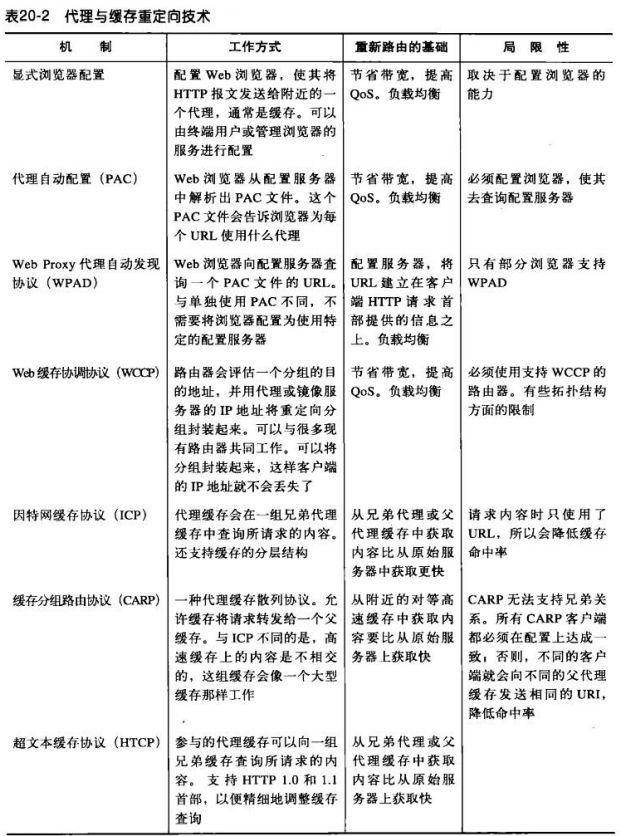
20.4 通用的重定向方法
20.4.1 HTTP重定向
服务器将短的重定向报文发回给客户端实现重定向。与其他形式重定向相比,优点之一
就是重定向服务器知道客户端的IP地址;理论上讲,它可以做出更合理的选择。
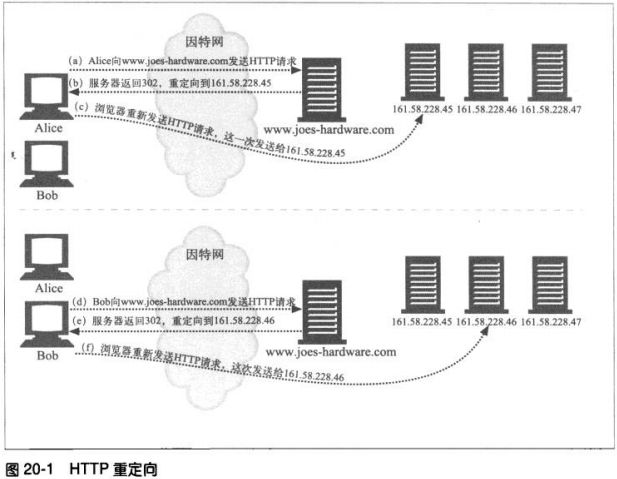
缺点:
@需要原始服务器进行大量处理来判断要重定向到哪台服务器上去。
@增加了用户延时,因为访问页面需要进行两次往返
@若重定向服务器故障,站点就会瘫痪。
20.4.2 DNS重定向
DNS解析程序可能是客户端自己的操作系统,可能是客户是网络中的一台DNS服务器,
或者是一台远距离的DNS服务器。DNS允许将几个IP地址关联到一个域中,可以配置
DNS解析程序或对其进行编程,以返回可变的IP地址。
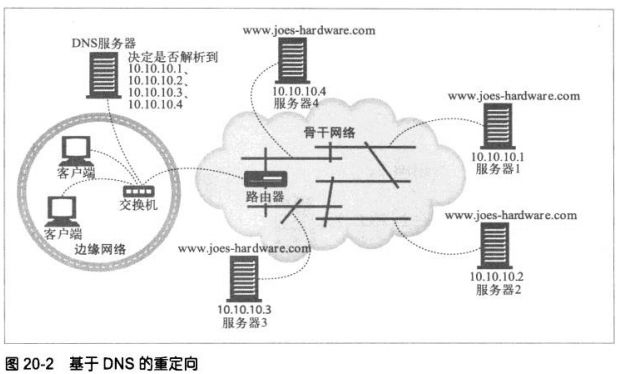
1、DNS轮转
在web服务器集群中平衡负载。这是一种单纯的负载均衡策略,没有考虑任何客户端与
服务器的相对位置,或服务器当前的负载情况。
2、多个地址及轮转地址的循环
大多数DNS客户端只会使用多地址其中的第一个地址。为了均衡负载,大多数DNS服务
器都会在每次完成查询之后对地址进行轮转。这种地址轮转通常称作DNS轮转。

3、用来平衡负载的DNS轮转
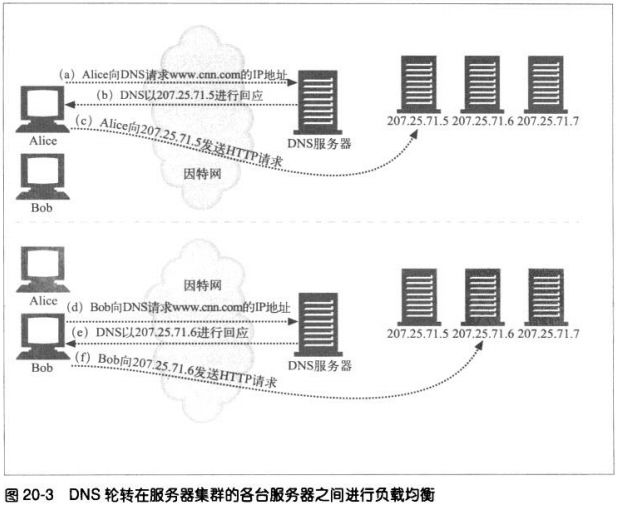
4、DNS缓存带来的影响
由于DNS查找的结果可能被记住,并被各种应用程序、操作系统和一些简易的子DNS服
务器重用。很多WEB浏览器都会对DNS查找,然后一次次的使用相同的地址,以减少
DNS查找的开销。因此,DNS轮转通常不会平衡单个客户端的负载。
5、其他基于DNS 的重定向算法
负载均衡算法——DNS服务器会跟踪服务器的负载,将负载最轻的服务器放在列表最前
面。
邻接路由算法——DNS服务器将用户导向地理上最近的web服务器。
故障屏蔽算法——DNS服务器可以监视网络的状况,并将请求绕过有故障的地方。
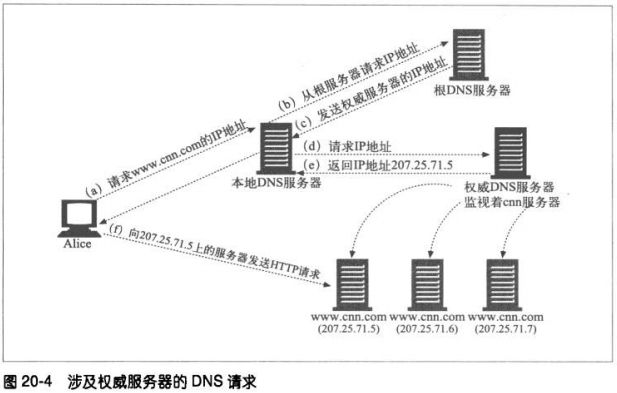
通常,运行复杂服务器跟踪算法的DNS服务器就是在内容提供者控制之下的一个权威服
务器。
10.4.3 任播寻址
在任播寻址中,几个地理上分散的web服务器拥有完全相同的IP地址,而且会通过骨干
路由器的“最短路径”路由功能将客户端的请求发送给离它最近的服务器。要使用这种
方法工作,每台服务器都要向邻近的骨干路由器广告,表明自己是一台路由器。
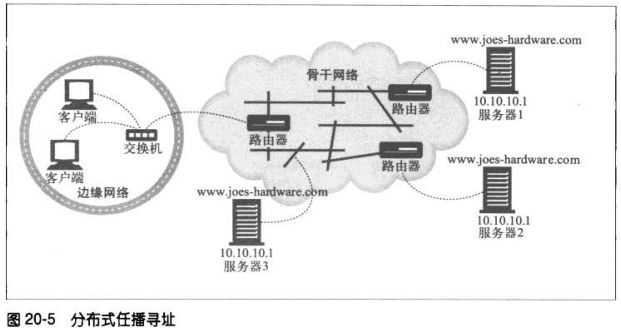
20.4.4 IP MAC转发
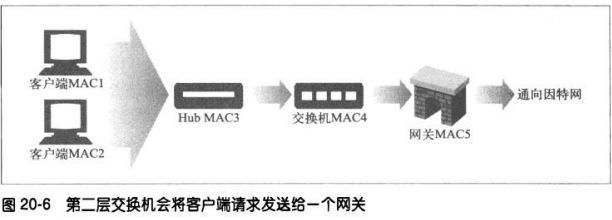
四层交换机可以检测出四层地址(ip 和 端口号),并由此来选择路由。在一条四层交换
机上可将所有的目的端口为80的web流量都发送到某个代理上去。
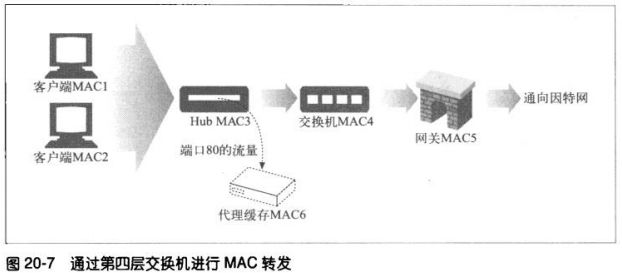
因为MAC地址转发只是点对点的,所以服务器或代理只能位于离交换机一跳远的地方。
20.4.5 ip地址转发
在IP地址转发中,交换机或其他四层设备会检测输入分组中的ip地址,并通过修改目的ip
地址对分组进行相应的转发。这种类型的转发称为NAT。
还有个问题就是对称路由。
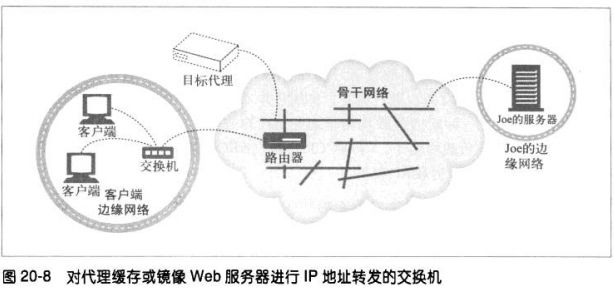
有两种方式可以控制响应返回的路径:
①将分组的源ip地址改成交换机的ip地址。这种方式称为完全NAT,其中的IP转发设备会
对目的IP地址和源IP地址都进行转换。这样的缺点是服务器不知道客户端的IP地址。
②若源IP地址仍然是客户端的ip地址,就要确保没有从服务器到客户端的直接路由(绕过
交换机的)。
20.4.6 网元控制协议
NECP允许网元(NE,路由器和交换机等负责转发IP分组的设备)与服务器元素进行交
互。 NECP并未显式提供对负载均衡的支持;它只是为SE(服务器元素)提供了一种发
送负载均衡信息给NE的方式,这样NE就可以在它认为合适的情况下进行负载均衡了。
NECP支持例外。SE可以决定它不能为某些特定的源IP地址提供服务,并将这些地址发送
给NE。然后NE可以将来自这些IP地址的请求转发给原始服务器。
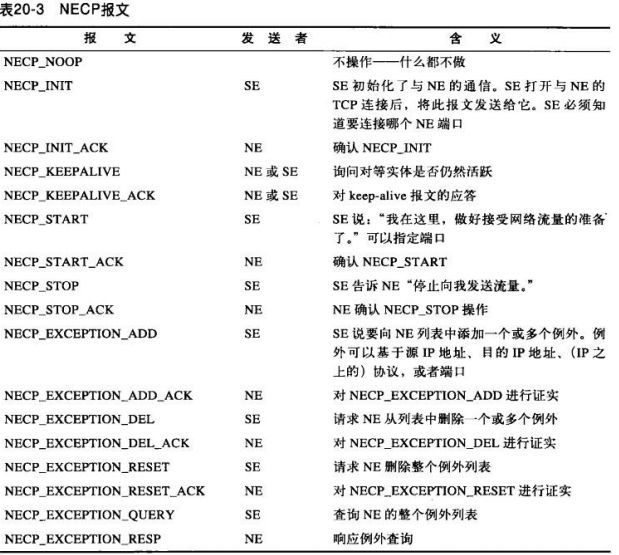
20.5 代理的重定向方法
20.5.1 显式浏览器配置
有两个缺点:
代理无法响应的情况下,也不会去联系服务器。
对网络架构进行修改,并将这些修改通知给所有的终端用户都是很困难的。
20.5.2 代理自动配置
通过代理自动配置协议(PAC)。必须配置浏览器,为这个PAC文件关联一个特定的服
务器。这样,浏览器每次重启的时候都可以获取这个PAC文件了。
PAC文件是个JavaScript文件,其中必须定义函数:
function FindProxyForURL(url, host)
浏览器要为请求的每条URL调用这个函数:
return_value = FindProxyForURL(url_of_request, host_in_url);
其返回值是一个字符串,用来说明浏览器应该到哪里请求这个URL。返回值可以是所关
联代理名称列表(比如, PROXY proxy1.domain.com)或是字符串“DIRECT”,这个字符
串说明浏览器应该绕开所有的代理,直接连接原始服务器。
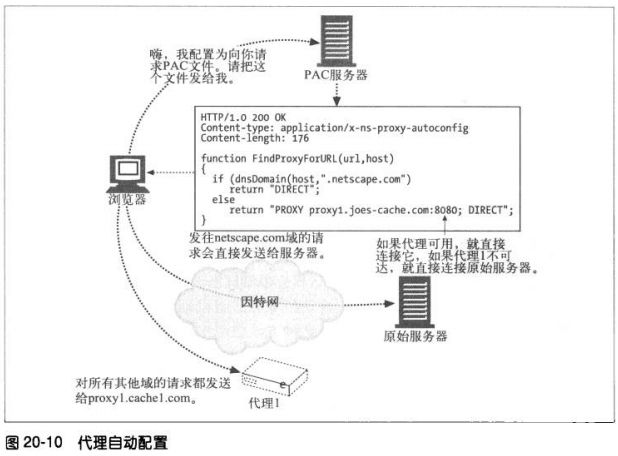
20.5.3 web代理自动发现协议
1、PAC文件自动发现
WPAD允许HTTP客户端定位一个PAC文件,,并使用这个PAC文件找到适当的代理服务
器的名字。
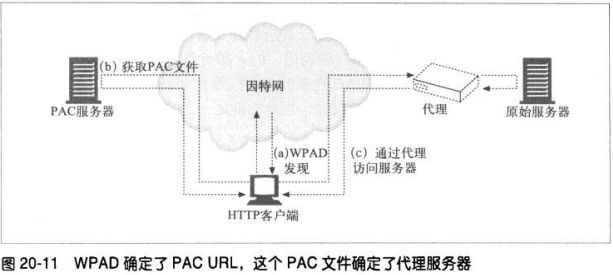
WPAD协议发现了PAC文件URL,这个URL也被称为配置URL (CURL)。
2、WPAD算法
资源发现的技术:
DHCP
SLP(服务定位协议)
DNS知名主机名
DNS SRV记录
DNS TXT记录中提供的服务URL
这5个技术中,要求WPAD客户端必须支持DHCP和DNS知名主机名技术。
客户端会按顺序使用上面的技术发送一系列资源发现请求。客户端只会尝试它们所支持
的机制。只要某次尝试成功了,客户端就会用得到的信息来构建PAC CURL。
若从那个CURL上成功获取PAC文件,则过程结束。如果没有,客户端就从它在预定义的
资源发现请求系列里中断的地方开始恢复。若尝试了所有的技术之后,仍未获取到PAC
文件,WPAD协议就失败了,客户端会配置为不使用代理。
客户端首先会尝试DHCP,然后是SLP.接着是DNS的机制。
客户端会在DNS SRV/知名主机名和DNS TXT记录等方法中循环多次。每次DNS查找都
会在QNAME前加上wpad,用以说明请求的资源类型。

3、用DHCP进行CURL发现
必须将CURL存储在WPAD客户端可以查询的DHCP服务器上。如果DHCP服务器中配置
了这种信息,就可以在DHCP可选代码252中获取CURL。
若WPAD客户端已经在其初始化过程中执行了DHCP查询,DHCP服务器可能就已经提供
了那个值。若无法通过客户端OS API获得这个值,客户端就向DHCP服务器发送一条
DHCPINFORM报文获取这个值。
可选代码252是STRING类型,可以是任意长度。包含了一个指向PAC文件的URL。
4、DNS A记录查找
必须将合适代理服务器的IP地址存储在WPAD客户端可以查询的DNS服务器上。WPAD
客户端会向DNS服务器发送一个A记录查询,以获取CURL。成功查询到的结果中会包含
代理服务器的IP地址。

5、获取PAC文件
只要创建了CURL,WPAD客户端通常会向CURL发送一条GET请求。同时,必须发送一些
带有适当CFILE格式信息的Accept首部。这些CFILE格式都是它们所能处理的。

6、何时执行WPAD
下列两种情况
①web客户端启动的时候
②只要有来自网络栈的通知,就说明客户端主机的IP地址变了
客户端还必须根据HTTP的过期时间,为之前下载的PAC文件的过期时间尝试一个发现周
期。PAC文件过期时,客户端遵循过期时间,重新运行WPAD过程是很重要的。
7、WPAD欺骗
IE5实现允许在客户端不干预,自动检测代理设置。第三级域名可能是不可信的。
8、超时
每个阶段限制在10秒内是比较合理的。
20.6 缓存重定向方法
WCCP重定向
Cisco系统公司开发的WCCP可以是路由器将web流量重定向到代理缓存中去。WCCP负责
路由器和缓存服务器之间的通信,这样路由器就可以对缓存进行验证,在缓存之间进行负载
均衡,并将特定的流量发给特定的缓存。
1、WCCP重定向如何工作
@启动包含了一些支持WCCP的路由器和缓存的网络,它们之间可以互相通信。
@一组路由器及其目标缓存构成一个WCCP服务组。服务组的配置说明了要将何种流量发往
何处、流量是如何发送以及如何在服务组的缓存之间进行负载均衡。
@若服务组配置为重定向HTTP流量,服务组中的路由器就会将HTTP请求发送给服务组中的
缓存。
@HTTP请求抵达服务组中的路由器时,路由器会(根据对请求IP的散列或掩码/值的配对策
略)选择服务组中的某个缓存为请求提供服务。
@路由器向缓存发送请求分组,可以用缓存的IP地址来封装分组,也可以通过IP MAC转发
实现。
@若缓存无法为请求提供服务,就将分组返回给路由器进行普通转发。
@服务组中成员互相交换心跳。
2、WCCP2报文




3、报文组件
每条WCCP2报文都由一个首部和一些组件构成。首部信息包含报文类型、WCCP版本和报
文长度(不包括首部的长度)。
每个组件都以一个描述组件类型和长度的4字节首部开始。组件长度不包括组件首部的长
度。

4、服务组
5、GRE分组封装
支持WCCP的路由器会用服务器的IP地址将HTTP分组封装起来,将其重定向到特定的服务
器上去。分组封装中还包含了IP首部的proto字段,用来说明通用路由器封装(GRE).proto
字段的存在告诉接收代理,它有一个封装的分组。
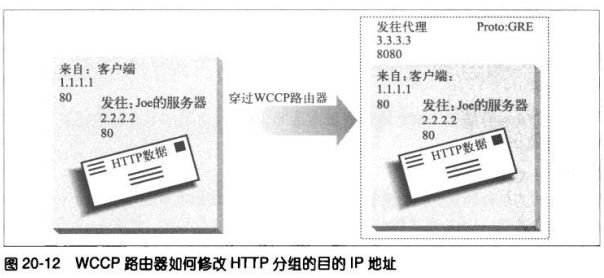
6、WCCP负载均衡
WCCP可以在几个接收服务器之间进行负载均衡。若某特定接收服务器停止发送心跳,
WCCP路由器就会将请求流量直接发到因特网上,再收到心跳,再次向节点发送。
20.7 因特网缓存协议
ICP允许缓存在其兄弟缓存中查找命中内容。ICP是一个对象发现协议。它会同时询问附近
多个缓存,看看它们的缓存中是否有特定的URL。附近缓存如果有,就返回一个简短的报文
HIT,若没有,就返回MISS。然后,缓存就可以打开一条到拥有此对象的邻居缓存的HTTP
连接了。
ICP报文是一个以网络字节序表示的32位封装结构,这样更便于解析。可以由UDP承载报
文,但是UDP并不可靠,因此使用ICP的程序要具有超时功能,以检测丢失的数据报。
1、Opcode–操作码
8位二进制值,用以描述ICP报文的含义。基本的opcode包括ICP_OP_QUERY请求报文和
ICP_OP_HIT/ICP_OP_MISS响应报文。
2、版本
8位的版本号。
3、报文长度
以字节为单位的ICP报文总长。因为只有16位,因此ICP报文长度不能超过16383字节。
URL通常都小于16KB。
4、请求编号
用请求编号来记录多个同时发起的请求和响应。ICP应答报文必须与触发应答的ICP请求报
文数相同。
5、选项
32位的选项字段是个包含了若干标记的位矢量,这些标记可用来修改ICP的行为。ICPv2定
义了两个标记,ICP_FLAG_HIT_OBJ 用来启动或禁止在ICP响应中返回文档数据。
ICP_FLAG_SRC_RTT 标记请求由兄弟缓存测量的、到原始服务器环回时间的估计值。
6、可选数据
ICPv2使用了可选数据的低16位来装载从兄弟缓存到原始服务器的可选环回时间的估计值
7、发送端主机地址
承载了报文发送端32位IP地址的著名字段,实际中并未使用。
8、净荷
净荷内容的变化取决于报文的类型。对ICP_OP_QUERY来说,净荷是一个4字节的原始请求
端主机地址,后面跟着一个由NUL结尾的URL。对ICP_OP_HIT_OBJ 来说,净荷是一个由
NUL结尾URL,后面跟着一个16位的对象长度,接着是对象数据。
20.8 缓存阵列路由协议
CARP是微软和网景提出的一个标准,通过这个协议来管理一组代理服务器。
CARP是ICP的一个替代品。
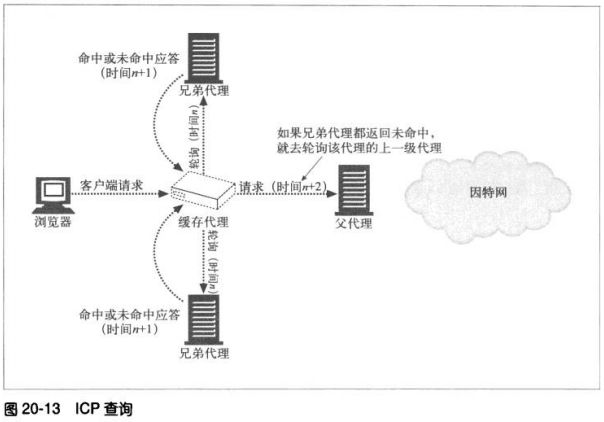
通过ICP协议连接起来的每个代理服务器都是将内容进行了冗余镜像的独立缓存服务器,这
就说明在不同的代理服务器之间复制web对象条目是可行的。而用CARP连接起来的一组服
务器会被当做一个大型服务器,其中每个组件服务器都只包含全部缓存文档的一部分。
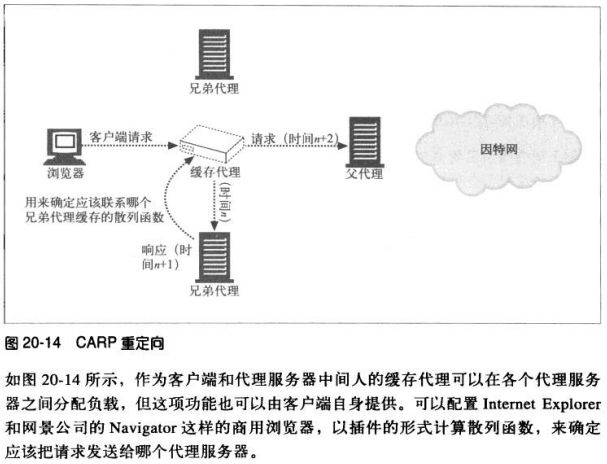
但CARP的缺点就是,如果某个代理服务器不可用了,就要重新修改散列表以反映这种变
化,而且必须重新配置现存代理服务器上的内容。
CARP重定向需要完成:
1、保存一个参与CARP的代理服务器列表。周期性地查询这些代理服务器,看它们是否活
跃。
2、为每个代理服务器计算一个散列函数。散列函数的返回值要考虑此代理所能处理的负载
量。
3、定义一个独立的散列函数,这个函数会根据所请求的web对象的URL返回一个数字。
4、将URL散列函数的结果代入代理服务器的散列函数,得到一个数字阵列。这些数字中的
最大值决定了要为这个URL使用的代理服务器。
上述4个任务,可以有浏览器、插件或中间服务器执行。
为每个代理服务器集群创建一个表,表中列出了集群中所有服务器。表中的每个条目都应该
包含全局参数的相关的信息,比如,负载因子、生存时间、倒计数值和应该以和频率查询成
员之内的全局参数。可以通过TPC接口对此表进行远程维护。只要表中的字段被RPC修改
了,就可以使其对下游的客户端和代理可见、或将其发布给它们。这项发布工作是在HTTP
中进行的,这样,所有的客户端或代理服务器都可以在不引入另一种代理间协议的基础上消
化表格信息了。客户端和代理服务器只用了一个知名的URL 来获取这张表。
20.9 超文本缓存协议
ICP协议中,在向兄弟缓存查询资源是否存在时,只允许缓存发送URL。HTCP允许兄弟缓
存之间通过URL和所有的请求及响应首部来相互查询文档是否存在。而且HTCP允许兄弟缓
存监视或请求在对方的缓存中添加或删除所选中的文档,并修改对方已缓存文档的缓存策
略。
首部——Header部分包含32位的报文长度,8位的主要协议版本和8位的次要协议版本。报
文长度包含所有首部、数据和认证部分的长度。
数据——Data部分包含了HTCP报文,结构如图20-5所示,数据组件如表20-6所示。


20.9.1 HTCP认证
认证部分是可选的。结构如图所示:

20.9.2 设置缓存策略
SET报文允许缓存请求对已缓存文档的缓存策略进行修改。

第二十一章 日志记录与使用情况跟踪
21.1 记录内容
通常只记录事务的基本信息就可以了:
HTTP方法;
客户端和服务器的HTTP版本;
所请求资源的URL;
响应的HTTP状态码;
请求和响应报文的尺寸;
事务开始时的时间戳;
Referer首部和User-Agent首部的值。
21.2 日志格式
21.2.1 常见日志格式
最常见的日志格式就是常用日志格式。最初由NCSA定义。


注意,remotehost字段可以是主机名也可以是IP地址。
21.2.2 组合日志格式
在常用日志格式上增加了两个字段:User-Agent和Referer。

21.2.3 网景扩展日志格式
扩展了常用日志格式,以支持与代理和web缓存这样的HTTP应用程序相关的字段。

21.2.4 网景扩展2日志格式

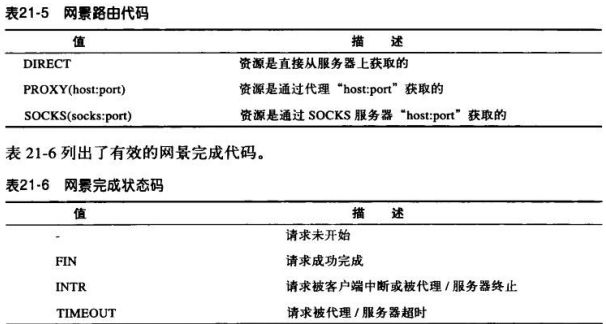

21.2.5 Squid代理日志格式
Squid代理缓存源于早期的一个web代理缓存项目。是一个开源项目,有很多工具可以用
来辅助管理Squid应用程序。



21.3 命中率测量
原始服务器通常处于计费的目的保留详细的日志记录。
但是缓存服务器位于客户端和服务器之间,处理了很多请求。这样,服务器就会有日志文件
遗漏。因此,内容提供者会对其最重要的页面进行缓存清除,有意将这些内容设置为无法缓
存。
代理缓存会自己保留日志,因此可以通过命中率测量协议来让缓存周期性的向原始服务器汇
报缓存访问的统计数据。
21.3.1 概述
命中率测量协议定义了一种HTTP扩展,提供一些基本功能,缓存和服务器可以实现这些
功能来共享访问信息,规范已缓存资源的可使用次数。
21.3.2 Meter首部
通过Meter首部,缓存和服务器在相互间传输与用法和报告有关的指令。这与Cache-
Control首部很类似。