格“物”致知:多模态预训练再次入门

©PaperWeekly 原创 · 作者|Chunyuan Li
单位|Microsoft Research Researcher
研究方向|深度生成模型
本文简要阐述了基于视觉和语言信息的多模态学习的缘由和发展现状,并介绍一种多模态预训练的方法 Oscar 来引导大家入门了解这个领域。为什么说是再次入门呢?因为前段时间在已经涌现出不少多模态预训练的方法,而我们展现一种另外一种打开多模态数据的方式,希望离多模态预训练的正确打开方式更近一些。

为什么关注多模态学习?
我们人类往往是通过多种渠道感知外部世界的,例如,用眼睛看到的图像,或者用耳朵听到的声音。尽管任何单个渠道可能都不完整或嘈杂,但是人类可以自然地对齐并融合从多个渠道收集的信息,以提取了解世界所需的关键概念。
人工智能的核心愿望之一是开发一种技术,以赋能计算机,使其具有从多模态(或多通道)数据中有效学习的能力。具体的一些功能,举例来说:
Visual Question Answering: 基于图片的语言问答
Image-Text Retrieval: 以文本为输入来搜索出与最语义上相似的图像
Image Captioning: 使用自然语言描述图像的内容
其它很多同时涉及到语言和图片的任务
从实用的角度讲,现代的计算机系统与人交互的信息通常也是模态的,包括语言,图片,语音等等, 比如微信里的对话方式,购物网站上的商品展示等等。多模态往往会比单一模态提供更加丰富的信息,达到更好的用户体验。
举个例子,在疫情状态下远程工作的我们,往往通过进行语音沟通,但有时候搭配着屏幕共享(视觉信息)是不是能更加愉快地聊天呢?这就是多模态学习的一种体现。

多模态学习初入门
最近,视觉和语言预训练(Vision-Language Pretraining, 简称 VLP)在解决多模态学习方面已显示出巨大的进步。这类方法最有代表性地通常包括如下两步:
预训练:是以自监督的方式在海量“图像-文本”数据(Image-Text Pair,或者叫做“图文对”)上训练大型的基于 Transformer 的模型(例如根据上下文预测被掩盖掉的语言或者图像的元素)
微调:可以对预训练模型的交叉模式表示进行微调,以适应各种下游视觉和语言任务
VilBERT [1] , LXMERT [2] , VL-BERT [3] , Unicoder-VL [4] , UNITER [5] , VLP [6] , 12-in-1 [7] , ...(闲话:排名不分先后,如有漏缺,请联系作者改动)
但是,现有的 VLP 方法只是将图像区域特征和文本特征连接起来作为模型的输入以进行预训练,并不为模型提供任何线索,希望模型能利用 Transformer 的自我注意机制,使用蛮力来学习图像文本语义对齐方式。

多模态学习再入门:格“物”以致知
在本文中,我们介绍一种新的多模态预训练方法 Oscar(Object-Semantics Aligned Pre-training):把物体用作视觉和语言语义层面上的定位点 (Anchor Point,或者成为锚点),以简化图像和文本之间的语义对齐的学习任务。
利用这一发现,我们开发了一个新颖的 VLP 框架,该方法可以在六项标准的视觉和语言任务上创造出最新的性能。
这样的方式,可以总结为自儒学经典《大学》里的“格物以致知” [8] :人接触、感觉、认识事物(物体),然后产生并获得知识。不过,我们这里的“物”,专指的是物体标签(Object Tags),而非泛指世上万事万物。
查阅有关该技术的细节,请查看【论文】[9] 和【代码】[10] 。

以物体为定位点
尽管观察到的数据在不同的通道(模态)之间变化,但我们假设重要因素倾向于在多个通道之间共享(例如,“狗”可以通过视觉和言语描述),在通道上捕获通道不变(或模态不变)因素。语义级别。
在视觉和语言任务中,图像中的显著的物体通常可以由先进的物体检测方法检测到,并且此类物体会经常在配对文本中提及。例如,在 MS COCO [11] 数据集上,图像及其配对文本共享至少1个,2 个或 3 个物体的百分比分别为 49.7%,22.2% 和 12.9%。
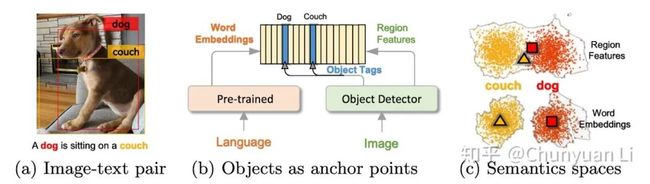
▲ 图1:该图显示了Oscar通过它在语义空间中表示图文对的过程。(a)输入图像-文本对的示例。(b)物体标签用作定位点,以将图像区域与预训练语言模型的词嵌入对齐。(c)预训练的语言语义空间比图像区域特征更具区分性。
图1a 中显示了一个示例图文对。通过使用诸如 Faster R-CNN [12] 之类的预训练物体检测器(object detector [13]),可以将图像表示为一组视觉区域特征,每个视觉区域特征都与一个物体标签关联。
因此,可以使用诸如 BERT 的预训练语言模型将句子表示为一系列单词嵌入。重要的是,在 Oscar 中,我们使用来自预先训练的 BERT 的对应词嵌入来构造物体标签的表示。
如图 1b 所示,它在共享空间中显式地将图像和句子耦合在一起,从而使物体扮演定位点的角色,以对齐视觉和语言的语义。经过大量的纯文本预训练之后,BERT [14] 的单词嵌入空间在语义上得到了很好的构造-这将进一步为共享空间提供良好的初始化。
在此示例中,由于重叠区域,“狗”和“沙发”在视觉特征空间中相似,但在单词嵌入空间中却很独特,如图 1c 所示。

Oscar训练方式
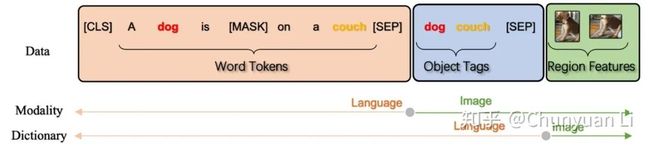
▲ 图2:Oscar的输入数据表达。我们将(图像-文本)对表示为三元组(橙色的单词序列,蓝色的物体标签,绿色的图片区域特征)。Oscar提出了用物体(在这个例子里是“狗”或“沙发”)来对齐跨域语义;如果删除物体,Oscar退化为以前的预训练方法。输入三元组可以从两个角度理解:模态视角和字典视角。
通过将对象标签作为新组件引入,Oscar 在两个方面与现有的 VLP 不同:
输入表示。如下图 2 所示,我们将每个(图像-文本)样本定义为一个三元组(单词序列,物体标签,区域特征)。
预训练目标。根据三元组中三个项目的分组方式,我们从两个不同的角度查看输入:模态视角和字典视角。每一种视角都允许我们设计一个新颖的预训练目标:
1)字典视图的掩盖码恢复损失,它衡量模型根据上下文恢复丢失元素(单词或对象标签)的能力;
2)模态视角的对比损失,它衡量模型区分原始三元组及其“污染”版本(即原始物体标签被随机采样的标签替换)的能力。
我们的 Oscar 模型在包含 650 万对数据的大规模图像文本数据集上进行了预训练。Oscar 针对各种视觉和语言理解和生成任务进行了微调和评估, 包括
Visual Question Answering (VQA) [15]
Graph Question Answering (GQA) [16]
Natural Language Visual Reasoning for Real (NLVR2) [17]
Image-Text Retrieval [18]
Text-Image Retrieval [19]
Image Captioning on COCO dataset [20]
Novel Object Captioning (NoCaps) [21]
整体 预训练+微调 的流程如图 3 所示:
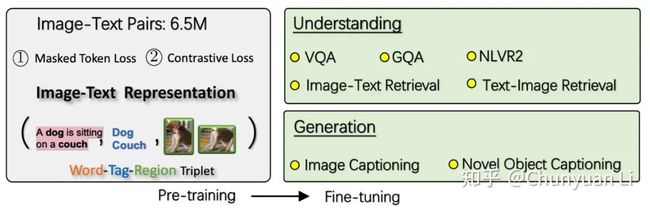
▲ 图3:Oscar以三元组作为输入,以两个损失函数为目标进行预训练(在单词和标签上掩盖恢复损失,以及在标签和其他标签之间的对比损失),然后对其进行微调以实现五个理解和两个生成任务。

实验效果:六个任务上的最优结果
为了考虑参数的利用效率,我们在下表 1 中比较了不同大小的模型。Oscar 在六项任务上均达到了最新水平。在大多数任务上,我们的基本款模型(base model)要优于以前的大型模型(large model),通常情况下会大大提高。
它表明 Oscar 具有很高的参数利用效率,我们认为部分原因是物体的使用大大简化了图像和文本之间语义对齐的学习。
在这里,VLP 基线方法是从 UNITER [5] , VilBERT [1] , LXMERT [2] , VLP [6] , VL-BERT [3] , Unicoder-VL [4] , 和 12-in-1 [7] 收集的。请注意,Oscar 接受了 650 万对的预训练,这比 UNITER 的 918 万对和 IXME 的 960 万对都少,这也说明了 Oscar 的数据利用率很高。
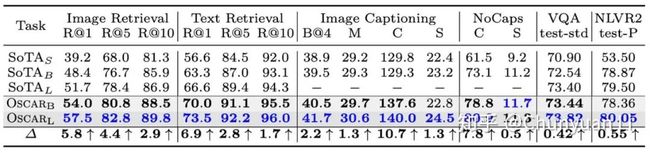
▲ 表1: Oscar在六项主流的视觉和语言任务上均取得了最佳表现。下标为S,B和L的SoTA(最新技术水平)表示通过小型,基础和大型模型(尺寸相对于BERT大小而测量)可获得的最佳性能。蓝色表示任务的最佳结果,灰色背景的行表示由Oscar产生的结果。

改进的图像文本对齐效果
我们使用 t-SNE 可视化工具,把 COCO 测试集的图像-文本对的语义特征空间画在了二维平面上。对于每个图像区域和单词序列,我们将其传递通过模型,并将其最后一层输出用作特征。比较带有和不带有物体标签的预训练模型。
图 4 中的结果揭示了一些有趣的发现。第一个发现是关于同一个物体的两种不同模态的:借助对象标签,可以大大减少两个模态之间同一对象的距离。
例如,Oscar 中 Person 的图片和文本表示比基线方法中的视觉表示和文本表示更接近,这个在图 4 中用红色曲线表示。
第二个发现是不同物体间的:添加物体标签后,具有相关语义的对象类越来越接近(但仍可区分) 而这在基线方法中有些混合,例如图 4 中用灰色曲线表示的动物(zebra, elephant, sheep等)。
这证明了物体标签在学习对齐语义中的重要性:物体被用做定位点链接和规范化了跨模式的特征学习。
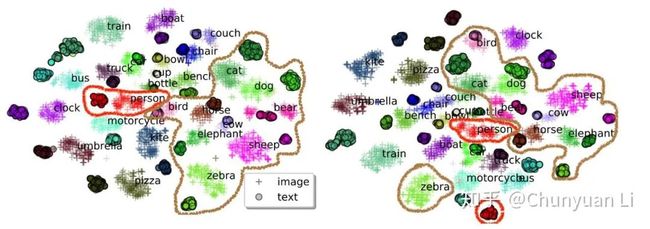
▲ 图4:使用t-SNE进行2D可视化。来自同一对象类的点共享相同的颜色。Oscar(左)改进了不带物体标签的基线上的跨域对齐(右)。红色和灰色曲线分别覆盖具有相同和相关语义的物体。

展望未来
Oscar 展示了在对齐图像和语言时使用物体作为定位点的强大功能。未来工作的有趣方向包括将 Oscar 推广到包括语音或多语言能力等更多形式的方法,以及使用物体作为自然桥梁从图像中提取知识以改善自然语言任务。真正做到格物以致知。
致谢 :
This research was conducted by Xiujun Li, Xi Yin, Chunyuan Li, Pengchuan Zhang, Xiaowei Hu, Lei Zhang, Lijuan Wang, Houdong Hu, Li Dong, Furu Wei, Yejin Choi, and Jianfeng Gao. The implementation in our experiments depends on open source GitHub repositories; we acknowledge all the authors who made their code public, which tremendously accelerates our project progress.
参考链接
[1] https://arxiv.org/abs/1908.02265
[2] https://github.com/airsplay/lxmert
[3] https:///arxiv.org/abs/1908.08530
[4] https://arxiv.org/abs/1908.06066
[5] https://github.com/ChenRocks/UNITER
[6] https://arxiv.org/abs/1909.11059
[7] https://arxiv.org/abs/1912.02315
[8] https://www.zhihu.com/question/20594905
[9] https://arxiv.org/abs/2004.06165
[10] https://github.com/microsoft/Oscar
[11] http://cocodataset.org/#home
[12] https://arxiv.org/abs/1506.01497
[13] https://en.wikipedia.org/wiki/Object_detection
[14] https://arxiv.org/abs/1810.04805
[15] https://visualqa.org/
[16] https://cs.stanford.edu/people/dorarad/gqa/index.html
[17] https://lil.nlp.cornell.edu/nlvr/
[18] https://github.com/kuanghuei/SCAN
[19] https://github.com/kuanghuei/SCAN
[20] http://cocodataset.org/#captions-2015
[21] https://nocaps.org/

点击以下标题查看更多往期内容:
大规模计算时代:深度生成模型何去何从
小样本分割最新综述
NLP中的Mask全解
对比学习(Contrastive Learning)相关进展梳理
将“softmax+交叉熵”推广到多标签分类问题
针对复杂问题的知识图谱问答最新进展

#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
???? 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
???? 投稿邮箱:
• 投稿邮箱:[email protected]
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
????
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。
