非自回归也能预训练:基于插入的硬约束生成模型预训练方法

论文标题:
POINTER: Constrained Text Generation via Insertion-based Generative Pre-training
论文作者:
Yizhe Zhang (MSR), Guoyin Wang (Duke), Chunyuan Li (MSR), Zhe Gan (MSR), Chris Brockett (MSR), Bill Dolan (MSR)
论文链接:
arxiv.org/pdf/2005.00558
非自回归生成有着更高的效率,但是,当前鲜有研究针对非自回归生成模型的预训练方法。
本文提出一种新的基于插入的非自回归预训练方法,用动态规划构造训练数据,并使用新的beam search方法,实现log级别的非自回归生成。在两个硬约束数据集上的实验表明,该方法比起基线模型有大幅提高。
硬约束文本生成与非自回归预训练
约束性文本生成(Constrained Text Generation)是文本生成中非常重要的部分,可以分为两类:软约束生成(Soft-Constrained)和硬约束生成(Hard-Constrained)。
软约束生成就是给定一些关键词(或关键信息),生成的文本要包含给定的关键内容,但不一定要完全包括。
硬约束生成就是要完全包含给定的词汇,不允许删除。
结合这两年得到广泛研究的基于插入的非自回归生成,我们可以很容易把这种方法应用到硬约束文本生成上,因为基于插入的非自回归方法有两个优点:
它不删除给定的词汇,而是不断增加新词,符合硬约束的要求;
它可以有log级别的生成效率。
下图是硬约束插入式非自回归生成的一个例子。给定的关键信息是,经过4次迭代,每次迭代新插入的词为蓝色,模型最终生成了期望的句子。

此外,由于这种插入的方法非常类似BERT的掩码预训练方法,所以,我们完全有可能像BERT那样,为插入式非自回归模型进行类似的预训练,从而利用大规模无监督语料,提高硬约束生成的效果。这就是本文的主要创新点。
总的来说,本文有以下贡献:
提出POINTER——一种插入式非自回归预训练模型,并能用BERT初始化;
基于POINTER使用一种简单但有效的Beam Search方法,进一步提高效果;
在两个硬约束生成数据集上,POINTER实现了显著的效果,并且有着最高的生成效率。
非自回归预训练
本节介绍POINTER的模型、训练及推理方法。首先介绍符号。记原始输入的硬约束为,第轮模型生成的句子是,最后生成的句子是。由于模型是以插入的方法生成的,从而前一轮的句子是下一轮生成句子的子序列。
模型建模最终句子的概率可以表示为:
所以,在每一轮,模型就是要根据前一轮生成的句子去选择要在哪里插入哪些词。在介绍生成步骤之前,首先来介绍一下如何构造训练数据。
训练数据构造
对于一个完整的句子,我们想要构造一个生成序列,相邻每一对就是一个训练实例。
由于我们想要让动词、名词等实词首先生成,而形容词、副词、助词等词最后生成,我们首先就要构造出符合这个模式的训练实例。
为此,我们对句子的每个词给一个重要性得分(importance score),它通过如下方式计算:
其中,是词的TF-IDF得分,是词的Part-of-Speech得分,是词的YAKE得分。YAKE是一种无监督关键词抽取方法。
在这个得分公式中,越高,表示词就越重要,它就要首先生成。注意到每个得分都归一化到[0,1]之间。
在得到句子中每个词的重要性得分之后,我们就可以逆序构造训练实例了。
具体来说,首先对源句子,从中抹去得分较低的一部分词,得到。
然后再对中剩下的词,再抹去一部分得分较低的词,得到,以此类推,得到初始句子。这里停止的标准是只剩不到个词。
那么,现在的问题是,怎么决定每次要抹去哪些词。换句话说,要选择保留哪些词,它们要满足某些条件,要达到怎样的优化目标。本文使用下面的公式计算:
这里是当前句子的长度,表示第个词被抹去,表示这个词被保留,并且约束是,不能有连续两个词被抹去。
为了求解上述公式,本文使用了一种动态规划算法。
注意到,原文上述公式中的max是min,笔者认为是笔误,否则上述公式就有一组平凡解。这个公式既鼓励重要的词首先生成,又鼓励尽可能多地生成词(越多越好)。
然而,根据文本描述,笔者在此处有一个疑问:对于约束“不能有连续两个词被抹去”。
原文给出的解释是“The reason for this constraint is that the insertion-based generation only allows maximally one new token to be generated between two existing tokens”。
也就是说,由于插入式模型一次只能在相邻词之间插入一个字符,所以在这里我们也不能一次抹去相邻两个字符。
但是实际上,即使抹去连续的词,这些词仍然可以在对数时间内以插入的方式生成。
训练
在得到训练实例后,就作为模型的输入,让模型去生成。回忆插入式生成,首先选择一个槽(slot,即相邻词之间的那个空位),然后生成该槽的词。
重新组织一下,就可以统一为:对当前输入的每个词,去预测“紧跟在”它后面是否要插入一个词,要插入哪个词。
这又可以进一步统一为:去预测词典中的一个词,这里是一个特殊词,表示实际上不插入。
为了表示就是最后的句子,额外构造一个训练实例,其中的长度和相同,而且每个词都是[NOI]。
也就是说,当作为输入的时候,模型需要为每个词输出[NOI],也就表示在每个词后面我们不再插入新词了,也就表示生成结束。
下图是模型生成的一个例子。
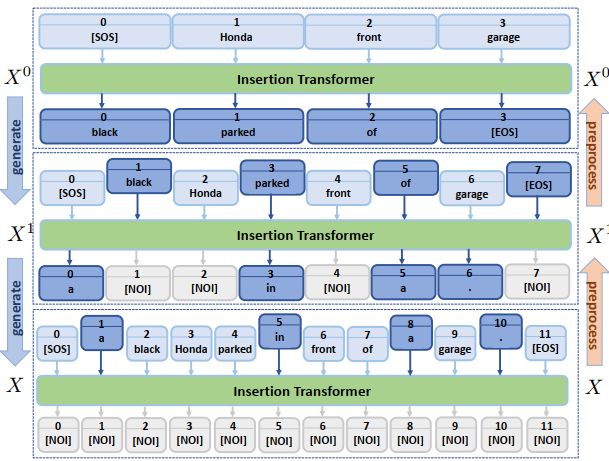
由于这个插入的过程和BERT预训练的方式一样,我们可以首先用BERT去初始化POINTER,然后再使用其他语料去预训练POINTER。
训练目标就是对每个训练实例,优化它的对数似然。
推理
在推理的时候,如果一个词后面生成了[NOI]且生成过程没有结束,那么在下一轮,这个[NOI]就不必再插入进去,因为它实际上表示的是没有插入。
在解码的时候,对每个位置,可以选择用Greedy Decoding或者Beam Decoding。本文提出Inner-Layer Beam Search (ILBS),进一步提高生成的效果。
具体来说,从左到右,对每个词,首先得到它预测的top-B个词,然后rank当前B个候选句子的得分,取其中最大的一大作为当前插入的词,然后继续往右走到下一个位置,直到最后一个位置,保留B个候选句子。
实验
本文在数据集EMNLP2017 WMT News和Yelp English Review上实验,预训练数据集为12.6G的Wikipedia,实验细节详见原文。
实验过程大致是首先按照预训练数据集的构造方法构造训练、验证和测试集,以此评估模型的硬约束生成能力。
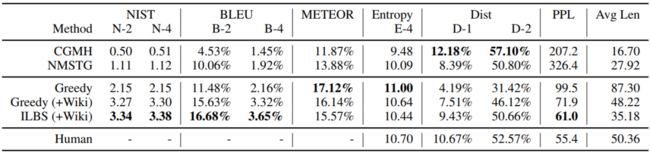
下面两个表分别是在News和Yelp上的实验结果,可以看到,在NIST、BLEU、METEOR、PPL得分上,POINTER相比基线模型取得了显著的提升,而Dist评估的是模型生成的多样性,且基线模型CGMH和NMSTG是基于采样的方法,自然在Dist得分上也就比POINTER高。
另外一个值得关注的点是,POINTER生成的生成的句子长度更加接近人类。最后,使用POINTER预训练可以显著提高生成文本的流畅度。

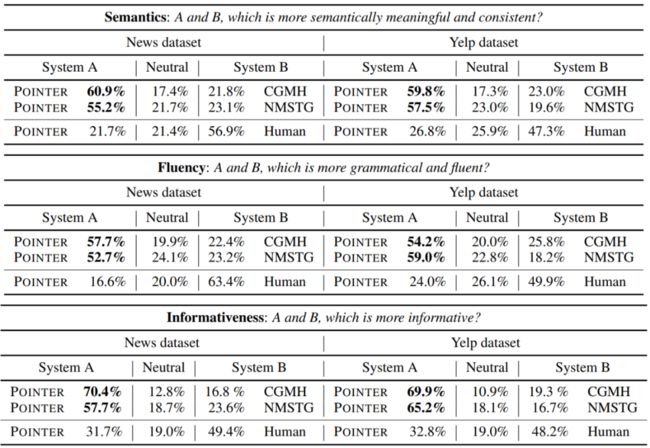
下表是人工测评的结果。在语义度、流畅度和信息度上,POINTER都显著好于基线模型,但仍然和人工写作的文本有所差异。
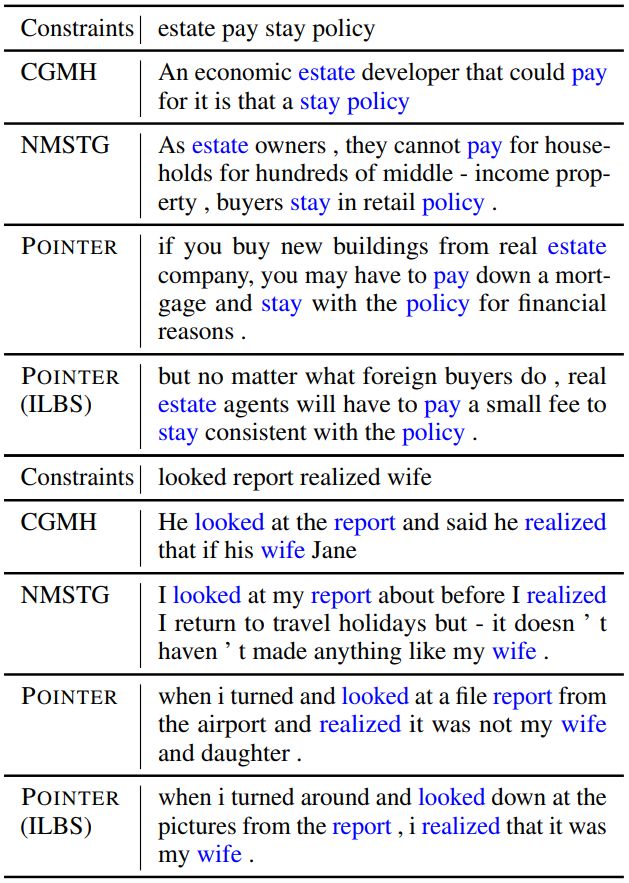
下图是数据集Yelp上的两个具体例子。和基线模型相比,POINTER生成的句子不但考虑了所有的硬约束,并且句子更加通顺流畅,也更加符合硬约束的原义。
在推理时间方面,在1000个句子上,CGMH需要33小时,NMSTG需要487秒,而POINTER只需要67秒,具体显著的速度优势。
小结
本文提出POINTER——一种用于硬约束生成的插入式非自回归生成的预训练方法。使用BERT初始化、POINTER预训练和Inner-Layer Beam Search,POINTER在两个数据集上取得了显著的效果提升,而且具有效率优势。
未来关于非自回归模型预训练的研究可以有以下方向:
更加通用的预训练:不仅仅是插入式的预训练,而且是适用于各种任务的预训练方法,还可以探索适用在NMT上的预训练方法;
更加高效的预训练:POINTER是对数级别的预训练,未来可以像BERT那样将其降低到常数级;
更加简单的预训练:POINTER的预训练需要人工构造训练数据,本质也是用规则指定了训练的方向,如何设计像BERT一样简单有效的自动预训练方法,是今后非自回归预训练研究的一大重点。
????
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。
