串的模式匹配算法(KMP)
以下内容主要参考与严蔚敏版的数据结构教材。
假设现在有一个主串s和一个子串t(模式串),通常主串的长度要大于子串的长度。在主串中找到和子串一样的子串并返回主串中找到的那个子串的第一个字符在主串中的位置叫做模式匹配。一个简单的例子如图1所示。
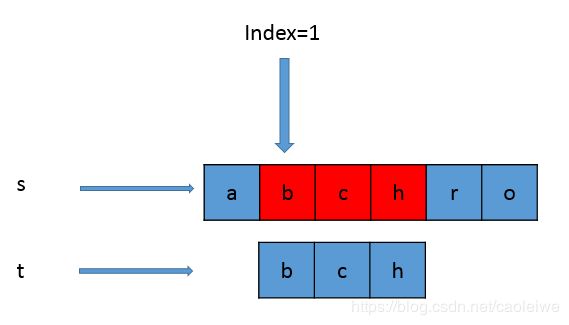
串的模式匹配的基本算法在开始的时候,在主串中索引 i i i指向 p o s pos pos位置的字符,在模式串中索引 j j j指向 i n d e x = 0 index=0 index=0的位置的字符。如果索引 i i i和索引 j j j指向的字符相同则索引 i i i和索引 j j j分别加一并比较其对应的字符。如果索引 i i i和索引 j j j指向的字符不相同,则索引 i i i指向本轮比较的主串中第一个比较的字符的下一个字符(如果本轮比较是第一轮则索引 i i i指向 p o s + 1 pos+1 pos+1位置的字符),索引 j j j指向 i n d e x = 0 index=0 index=0的位置的字符,然后继续比较。如果在当前的这一轮比较中模式串中的每一个字符都和主串中一个连续的字符序列相等则返回主串中本轮比较的第一个比较的字符的索引,否则返回-1。
串的模式匹配的基本算法简单易懂,当主串中不存在多个与模式串部分匹配的子串时,串的模式匹配的基本算法的时间复杂度可以接近 O ( m + n ) O(m+n) O(m+n),m和n分别为主串和模式串中字符串的长度,这时的效率还是比较高的。但是当主串中存在多个与模式串部分匹配的子串时,串的模式匹配的基本算法的时间复杂度可以接近 O ( m ∗ n ) O(m*n) O(m∗n)且主串的索引 i i i需要不停的回溯。
串的模式匹配的KMP算法是对串的模式匹配的基本算法的改进,使得当主串中存在多个与模式串部分匹配的子串时,算法的时间复杂度也可以达到 O ( m + n ) O(m+n) O(m+n)。其改进在于:每当一趟匹配过程中出现字符比较不等时,不需回溯主串的索引 i i i,而是利用已经得到的“部分匹配”的结果将模式串向右滑动一定的距离后继续进行比较。
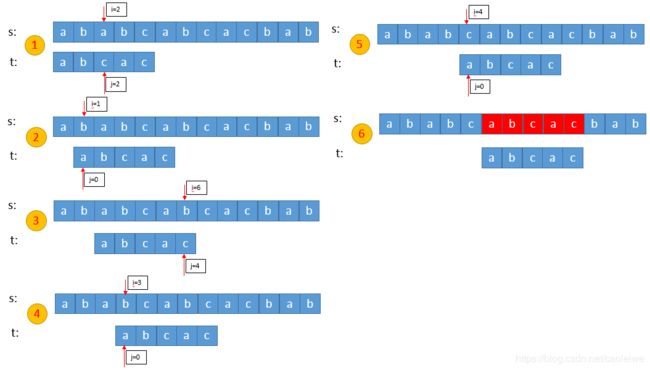

串的模式匹配的基本算法的一个例子如图2所示。在第一趟比较中我们知道主串的第0、1个字符是 a a a和 b b b,因此模式串中的第0个字符 a a a无需再和主串的第1个字符比较,而是直接和第2个字符比较。在第三趟比较中我们知道主串的第3、4、5个字符是 b b b, c c c和 a a a,因此模式串中的第0个字符 a a a无需再和主串的第3、4、5个字符比较,而是将模式串向右滑动三个字符让模式串中的第1个字符 b b b和主串的第6个字符 b b b比较。串的模式匹配的KMP算法在图2的例子的匹配过程如图3所示。
假设主串为 s 0 , s 1 , . . . , s n − 1 s_0,s_1,...,s_{n-1} s0,s1,...,sn−1,模式串为 p 0 , p 1 , . . . , p m − 1 p_0,p_1,...,p_{m-1} p0,p1,...,pm−1。从以上分析我们可以知道,为了实现改进算法,当匹配过程中产生失配( s i ! = p j s_i!=p_j si!=pj)时模式串需要向右滑动几个字符(即主串中的 s i s_i si字符应该继续和模式串中的哪一个字符继续进行比较,主串的字符索引 i i i不需要回溯)。假设此时应该与模式串中的第k( k < j k
- p 0 , p 1 , . . . , p k − 1 p_0,p_1,...,p_{k-1} p0,p1,...,pk−1= s i − k , . . . , s i − 2 , s i − 1 s_{i-k},...,s_{i-2},s_{i-1} si−k,...,si−2,si−1
已经得到的备份匹配结果是:
- p j − k , . . . , p j − 2 , p j − 1 p_{j-k},...,p_{j-2},p_{j-1} pj−k,...,pj−2,pj−1= s i − k , . . . , s i − 2 , s i − 1 s_{i-k},...,s_{i-2},s_{i-1} si−k,...,si−2,si−1
从以上两个式子可以推出:
- p 0 , p 1 , . . . , p k − 1 p_0,p_1,...,p_{k-1} p0,p1,...,pk−1= p j − k , . . . , p j − 2 , p j − 1 p_{j-k},...,p_{j-2},p_{j-1} pj−k,...,pj−2,pj−1
因此如果模式串中存在满足上式的两个子串,则当匹配过程中产生失配( s i ! = p j s_i!=p_j si!=pj)时仅需将模式串向右滑动几个字符,使得模式串中的第k个字符与主串中的第i个字符对齐,并从模式串中的第k个字符开始继续比较即可。
整个匹配算法的关键是对于模式串当匹配过程中产生失配( s i ! = p j s_i!=p_j si!=pj)时应该从模式串中的第几个字符和主串中的第 i i i个子串继续开始比较。我们用数组 n e x t [ t . s i z e ( ) ] next[t.size()] next[t.size()]来表示当匹配过程中产生失配( s i ! = p j s_i!=p_j si!=pj)时模式串中和主串中的第 i i i个子串继续开始比较的字符索引。下面讲解 n e x t [ t . s i z e ( ) ] next[t.size()] next[t.size()]数组每个元素值得求解。
- n e x t [ j ] = − 1 next[j]=-1 next[j]=−1(j=0)表明当匹配过程中产生失配( s i ! = p 0 s_i!=p_0 si!=p0)时(在模式串的第0个字符处产生失配)应该从模式串的第0个字符和主串的第 i + 1 i+1 i+1个字符开始继续比较。
- n e x t [ j ] = M a x { k ∣ 0 < k < j 且 p 0 , p 1 , . . . , p k − 1 next[j]=Max\{k|0
- n e x t [ j ] = 0 next[j]=0 next[j]=0(以上两种情况之外的其它情况)
由以上定义可知 n e x t [ 0 ] = − 1 next[0]=-1 next[0]=−1并设 n e x t [ j ] = k next[j]=k next[j]=k这表明在模式串中存在下列关系 p 0 , p 1 , . . . , p k − 1 p_0,p_1,...,p_{k-1} p0,p1,...,pk−1= p j − k , . . . , p j − 2 , p j − 1 p_{j-k},...,p_{j-2},p_{j-1} pj−k,...,pj−2,pj−1其中k为满足 0 < k < j 0
- 如果 p k p_k pk= p j p_j pj则表明模式串中存在 p 0 , p 1 , . . . , p k − 1 , p k p_0,p_1,...,p_{k-1},p_{k} p0,p1,...,pk−1,pk= p j − k , . . . , p j − 2 , p j − 1 , p j p_{j-k},...,p_{j-2},p_{j-1},p_{j} pj−k,...,pj−2,pj−1,pj且不可能存在 k ′ > k k^{'}>k k′>k满足该关系。如果存在 k ′ > k k^{'}>k k′>k满足该关系则有 p 0 , p 1 , . . . , p k − 1 , p k , . . . , p k ′ p_0,p_1,...,p_{k-1},p_{k},...,p_{k^{'}} p0,p1,...,pk−1,pk,...,pk′= p j − k ′ , . . . , p j − k , . . . , p j − 2 , p j − 1 , p j p_{j-k^{'}},...,p_{j-k},...,p_{j-2},p_{j-1},p_{j} pj−k′,...,pj−k,...,pj−2,pj−1,pj则 n e x t [ j ] = k next[j]=k next[j]=k这就和前提条件相矛盾,因此得证。所以此时 n e x t [ j + 1 ] = n e x t [ j ] + 1 next[j+1]=next[j]+1 next[j+1]=next[j]+1
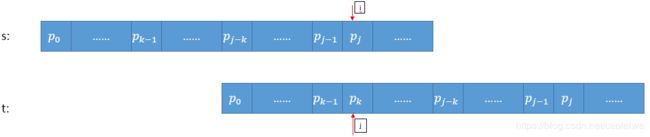
- 如果 p k p_k pk!= p j p_j pj则 p 0 , p 1 , . . . , p k − 1 , p k p_0,p_1,...,p_{k-1},p_{k} p0,p1,...,pk−1,pk!= p j − k , . . . , p j − 2 , p j − 1 , p j p_{j-k},...,p_{j-2},p_{j-1},p_{j} pj−k,...,pj−2,pj−1,pj,此时为求 n e x t [ j + 1 ] next[j+1] next[j+1],把当前的情况 p 0 , p 1 , . . . , p k − 1 , p k p_0,p_1,...,p_{k-1},p_{k} p0,p1,...,pk−1,pk!= p j − k , . . . , p j − 2 , p j − 1 , p j p_{j-k},...,p_{j-2},p_{j-1},p_{j} pj−k,...,pj−2,pj−1,pj看成主串和模式串都是模式串的模式匹配过程,如图4所示。在当前的匹配过程中已有 p 0 = p j − k p_0=p_{j-k} p0=pj−k, p 1 = p j − k + 1 p_1=p_{j-k+1} p1=pj−k+1, p k − 1 = p j − 1 p_{k-1}=p_{j-1} pk−1=pj−1,则当 p j ! = p k p_j!=p_k pj!=pk时应该从模式串的第 n e x t [ k ] = k ′ ′ next[k]=k^{''} next[k]=k′′个字符继续开始比较,如果 p j = p k ′ ′ p_j=p_{k^{''}} pj=pk′′则说明在主串中第j+1个字符之前存在一个长度为 k ′ ′ + 1 k^{''}+1 k′′+1的最长子串满足 p 0 , p 1 , . . . , p k ′ ′ p_0,p_1,...,p_{k^{''}} p0,p1,...,pk′′= p j − k ′ ′ , . . . , p j p_{j-k^{''}},...,p_{j} pj−k′′,...,pj( 0 < k ′ ′ < k < j 0
由以上定义写出的获取模式串 n e x t next next数组值的基础算法有一定缺陷。对于模式串 a a a a b aaaab aaaab利用基础算法算得的 n e x t next next数组值为 { − 1 , 0 , 1 , 2 , 3 } \{-1,0,1,2,3\} {−1,0,1,2,3}。当运用KMP算法和主串 a a a b a a a a b aaabaaaab aaabaaaab进行匹配时,在第一趟比较中 s [ 3 ] = b ! = t [ 3 ] = a s[3]=b!=t[3]=a s[3]=b!=t[3]=a根据 n e x t next next数组值 s [ 3 ] = b s[3]=b s[3]=b应该继续和 t [ 2 ] = a t[2]=a t[2]=a、 t [ 1 ] = a t[1]=a t[1]=a、 t [ 0 ] = a t[0]=a t[0]=a继续开始比较。实际上因为模式串的第3个字符和第0、1、2个字符相同因此它们不需要再和主串中的第3个字符比较因而浪费了三次比较的时间。这里应该直接将模式串的第0个字符和主串的第4个字符比较。这就是说按上面的定义 n e x t [ j ] = k next[j]=k next[j]=k而模式中 p k p_{k} pk= p j p_j pj则当主串中的字符 s i s_i si和模式串中的字符 p j p_j pj比较不等时不需要再和 p k p_k pk进行比较而是直接和 p n e x t [ k ] p_{next[k]} pnext[k]进行比较,即此时 n e x t [ j ] next[j] next[j]的值应改为 n e x t [ k ] next[k] next[k]的值,如果此时 p k p_{k} pk= p j p_j pj!= p n e x t [ k ] p_{next[k]} pnext[k],否则还要递归进行改动。
//普通算法
void getNext(string t,vector<int> &next)
{
next[0] = -1;
int j = -1;
int i = 0;
while (i<(t.size()-1))
{
if (j==-1||(t[i]=t[j]))
{
i++;
j++;
next[i] = j;
}
else
{
j = next[j];
}
}
}
//改进算法
void getNextPro(string t, vector<int>& next)
{
next[0] = -1;
int j = -1;
int i = 0;
while (i < (t.size())-1)
{
if (j == -1 || (t[i] = t[j]))
{
i++;
j++;
if (t[i] != t[j])
next[i] = j;
else
next[i] = next[j];
}
else
{
j = next[j];
}
}
}
//KMP模式匹配算法
int IndexKMP(string s, string t, int pos)
{
int i = pos;
int j = 0;
vector<int> next(t.size(),-1);
getNextPro(t, next);
while ((i < s.size()) && (j < t.size()))
{
if ((j==-1)||(s[i]==t[j]))
{
i++;
j++;
}
else
{
j = next[j];
}
}
if (j >= t.size())
{
return (i - j);
}
else
{
return -1;
}
}
//基础版的模式匹配算法
int Index(string s, string t, int pos)
{
int i = pos;
int j = 0;
while ((i < s.size()) && (j < t.size()))
{
if (s[i] == t[j])
{
i++;
j++;
}
else
{
j = 0;
i = i-j+1;
}
}
if (j >= t.size())
{
return (i - j);
}
else
{
return -1;
}
}