selenium模拟浏览器并下载网页阅读器文件
在某泉书局买了一本电子书,遍寻下载按钮未果,问了客服后得知,该书局电子书仅提供网页阅览,并且不予退款,遂怒,决心设法下载之,此为背景
使用Chrome的开发者模式分析后得知,该书局网页的电子书是动态加载的,往下翻页时,浏览器才会接收到新的电子书内容。刚开始,我抱着试一试的心态直接使用urlretrieve下载抓到的电子书页面链接,发现返回的是不相关的内容,果然还是要登录后才能抓取文件。Google之后,我决定尝试一下selenium
使用selenium模拟登录
创建一个浏览器对象:
建议创建Chrome对象,文章后边会有解释
from selenium import webdriver
url = 'https://wqbook.wqxuetang.com/'
#create a browser object
driver = webdriver.Chrome("C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe")
driver.get(url)
登录按钮在页面右上角,通过分析网页html,获得登录按钮的标签,然后模拟点击,进入登录页面

# enter login-in page
login_page = driver.find_element_by_xpath("//a[@data-id='login']")
print(login_page.text)
login_page.click()
同理通过分析html,找到登录页面的输入框,然后输入账号密码, 登陆进去
#输入账号
input_account = driver.find_element_by_id('account')
input_account.send_keys('********')
#输入密码
input_passwd = driver.find_element_by_id('password')
input_passwd.send_keys('******')
#模拟点击登录按钮
login_button = driver.find_element_by_xpath("//input[@οnclick='return post_login();']")
login_button.click()
完成登录就结束了爬取任务的第一步,虽然很简单,但是这一步是整个任务的基础,如果没有登录的认证,是不可能抓到想要的数据的。
获取电子书每一页图片的链接
这一步是比较繁琐的,应该可以用程序实现,但是目前我还没去寻找对应的解决方案。
这一步总的思路就是在前边selenium创建会话的基础上,在Chrome的开发者模式下手动翻动页面,直到电子书所有内容都加载完毕,然后使用chrome的批量导出链接功能,清洗数据后得到电子书每一页的链接
selenium进入电子书阅读页面
这里看起来selenium又进入了新的链接,跟之前登录完全没关系,实际上如果没有之前的登录认证,这里就只能加载电子书的前一小部分预览内容
pdf_url = 'https://wqbook.wqxuetang.com/read/pdf/193921'
driver.get(pdf_url)
然后就是手动翻页,注意先按F12进入开发者模式,然后再翻页,这样才能抓取到浏览器收到的内容

确保电子书所有页面都完全加载之后,就到了导出页面链接的一部了。Chrome相比火狐可以一键导出所有链接,这正是我推荐使用Chrome的理由
注意这里导出为了fetch格式,是因为我觉得这种格式的数据清洗非常方便
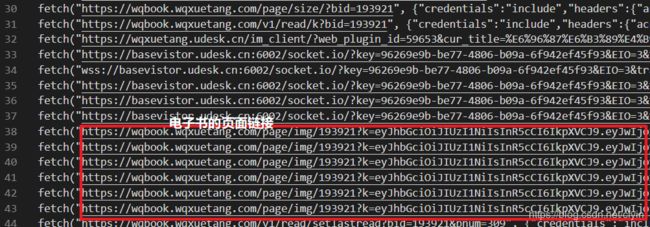
数据清洗。去除重复是因为最后获得的链接数目远大于电子书页面数。注意一定要保证链接的顺序,不然等下载完还得挨个对页面排序,那就太麻烦了。
import re
rawUrlList = []
raw_file = 'fetch.txt'
with open(raw_file) as file_object:
for line in file_object:
if re.findall('https://wqbook.wqxuetang.com/page/img/193921?.*', line):
rawUrlList.append(line.split('"')[1])
print(len(rawUrlList))
#去除重复,同时保证链接的顺序不变
urlList = []
for url in rawUrlList:
if url not in urlList:
urlList.append(url)
len(urlList)
下载
import time
from random import random
import urllib.request as request
start_point = 200
def jpgDownload(url, fileName, i):
try:
if i < start_point:
pass
else:
request.urlretrieve(url, fileName)
time.sleep(1 + 2 * random())
print(fileName + ' downloaded!')
except Exception as e:
time.sleep(2 + random())
print(e)
jpgDownload(url, fileName)
这个是下载文件的函数。开始加了一个start_point,是因为网站有反爬虫措施,每次下载八九十张图片,他就开始返回一些不相关的内容了。加这个变量是为了方便从断点处重新开始。中间每次下载使用的是随机的等待时间,这样爬虫的特征相对会隐蔽一些。
import os
directory = "./wqbook"
if not os.path.exists(directory):
os.makedirs(directory)
for i in range(len(urlList)):
url = urlList[i]
fileName = directory + '/' + str(i) + '.jfif'
jpgDownload(url, fileName, i)
这里文件后缀我用的是jfif,因为我单独在浏览器中打开一个文件链接后(注意,这个测试应该在整个工作开始之前),点击另存为,它默认的格式就是jfif,其实jpg也行。
其他问题
因为中间有中断,导致文件下载不能连续,但是文件的命名是跟下载过程紧密相关的,如果重新开始下载后发现文件名错位了怎么办?这时就要请出powershell了
把所有错位的文件放在一个文件夹里,powershell切换到这个目录下。
举一个例子,现在有近百张以数字命名的图片的名字错位,需要修改(如139.jfif改成137.jfif,以此类推):
PS D:\code\Jupyter\wenquanbook\rename> $i = 137;
PS D:\code\Jupyter\wenquanbook\rename> foreach ($file_name in Get-ChildItem *.jfif) {
>> echo "The Loop: ";
>> echo $i;
>> echo $file_name;
>> $new_file_name = -Join($i, '.jfif');
>> Rename-Item $file_name $new_file_name;
>> $i = $i + 1
>> }