AlphaZero实践——中国象棋(附论文翻译)
原创文章,转载请注明出处: AlphaZero实践——中国象棋(附论文翻译)
请安装TensorFlow1.0,Python3.5,uvloop
项目地址: https://github.com/chengstone/cchess-zero
关于AlphaGo和后续的版本AlphaGo Zero等新闻大家都耳熟能详了,今天我们从论文的分析,并结合代码来一起讨论下AlphaZero在中国象棋上的实践。
实际上在GitHub上能够看到有很多关于AlphaGo的实践项目,包括国际象棋、围棋、五子棋、黑白棋等等,我有个好友在实践麻将。
从算法上来说,大家都是基于AlphaGo Zero / AlphaZero的论文来实现的,差别在于不同Game的规则和使用了不同的trick。
论文分析
我们要参考的就是AlphaGo Zero的论文《Mastering the Game of Go without Human Knowledge》和AlphaZero的论文《Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm》。
小弟不才,献丑翻译了这两篇论文,时间仓促,水平有限✧(≖ ◡ ≖✿),您要是看不惯英文,希望这两篇翻译能提供些许帮助。
《Mastering the Game of Go without Human Knowledge》
《Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm》
建议在本地用jupyter notebook打开看,我发现从GitHub上看的话,有些公式没有显示出来,另外图片也没有显示出来。
Mastering the Game of Go without Human Knowledge
先从《Mastering the Game of Go without Human Knowledge》说起,算法根据这篇论文来实现,AlphaZero只有几点不同而已。
总的来说,AlphaGo Zero分为两个部分,一部分是MCTS(蒙特卡洛树搜索),一部分是神经网络。
我们是要抛弃人类棋谱的,学会如何下棋完全是通过自对弈来完成。
过程是这样,首先生成棋谱,然后将棋谱作为输入训练神经网络,训练好的神经网络用来预测落子和胜率。如下图:

蒙特卡洛树搜索算法
MCTS就是用来自对弈生成棋谱的,结合论文中的图示进行说明:
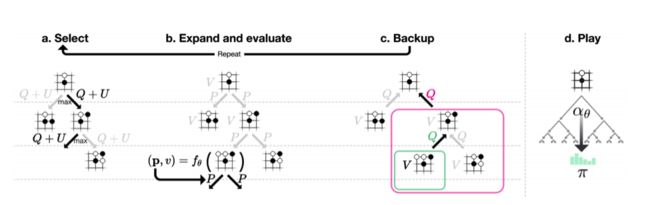
论文中的描述:
AlphaGo Zero中的蒙特卡洛树搜索。
- a.每次模拟通过选择具有最大行动价值Q的边加上取决于所存储的先验概率P和该边的访问计数N(每次访问都被增加一次)的上限置信区间U来遍历树。
- b.展开叶子节点,通过神经网络(P(s, ·), V (s)) = f_θ(s)来评估局面s;向量P的值存储在叶子结点扩展的边上。
- c.更新行动价值Q等于在该行动下的子树中的所有评估值V的均值。
- d.一旦MCTS搜索完成,返回局面s下的落子概率π,与N^(1 /τ)成正比,其中N是从根状态每次移动的访问计数, τ是控制温度的参数。
按照论文所述,每次MCTS使用1600次模拟。过程是这样的,现在AI从白板一块开始自己跟自己下棋,只知道规则,不知道套路,那只好乱下。每下一步棋,都要通过MCTS模拟1600次上图中的a~c,从而得出我这次要怎么走子。
来说说a~c,MCTS本质上是我们来维护一棵树,这棵树的每个节点保存了每一个局面(situation)该如何走子(action)的信息。这些信息是,N(s, a)是访问次数,W(s, a)是总行动价值,Q(s, a)是平均行动价值,P(s, a)是被选择的概率。
a. Select
每次模拟的过程都一样,从父节点的局面开始,选择一个走子。比如开局的时候,所有合法的走子都是可能的选择,那么我该选哪个走子呢?这就是select要做的事情。MCTS选择Q(s, a) + U(s, a)最大的那个action。Q的公式一会在Backup中描述。U的公式如下:

这个可以理解成:U(s, a) = c_puct × 概率P(s, a) × np.sqrt(父节点访问次数N) / ( 1 + 某子节点action的访问次数N(s, a) )
用论文中的话说,c_puct是一个决定探索水平的常数;这种搜索控制策略最初倾向于具有高先验概率和低访问次数的行为,但是渐近地倾向于具有高行动价值的行为。
计算过后,我就知道当前局面下,哪个action的Q+U值最大,那这个action走子之后的局面就是第二次模拟的当前局面。比如开局,Q+U最大的是当头炮,然后我就Select当头炮这个action,再下一次Select就从当头炮的这个棋局选择下一个走子。
b. Expand
现在开始第二次模拟了,假如之前的action是当头炮,我们要接着这个局面选择action,但是这个局面是个叶子节点。就是说当头炮之后可以选择哪些action不知道,这样就需要expand了,通过expand得到一系列可能的action节点。这样实际上就是在扩展这棵树,从只有根节点开始,一点一点的扩展。
Expand and evaluate这个部分有个需要关注的地方。论文中说:在队列中的局面由神经网络使用最小批量mini-batch 大小为8进行评估;搜索线程被锁定,直到评估完成。叶子节点被展开,每个边(s_L, a)被初始化为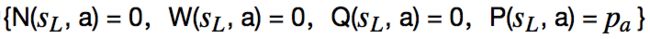 然后值v被回传(backed up)。
然后值v被回传(backed up)。
如果我当前的局面没有被expand过,不知道下一步该怎么下,所以要expand,这个时候要用我们的神经网络出马。把当前的局面作为输入传给神经网络,神经网络会返回给我们一个action向量p和当前胜率v。其中action向量是当前局面每个合法action的走子概率。当然,因为神经网络还没有训练好,输出作为参考添加到我们的蒙特卡洛树上。这样在当前局面下,所有可走的action以及对应的概率p就都有了,每个新增的action节点都按照论文中说的对若干信息赋值, 。这些新增的节点作为当前局面节点的子节点。
c. Backup
接下来就是重点,evaluate和Backup一起说,先看看Backup做什么事吧:边的统计数据在每一步t≤L中反向更新。访问计数递增, ,并且动作价值更新为平均值,
,并且动作价值更新为平均值,  。我们使用虚拟损失来确保每个线程评估不同的节点。
。我们使用虚拟损失来确保每个线程评估不同的节点。
我们来整理一下思路,任意一个局面(就是节点),要么被展开过(expand),要么没有展开过(就是叶子节点)。展开过的节点可以使用Select选择动作进入下一个局面,下一个局面仍然是这个过程,如果展开过还是可以通过Select进入下下个局面,这个过程一直持续下去直到这盘棋分出胜平负了,或者遇到某个局面没有被展开过为止。
如果没有展开过,那么执行expand操作,通过神经网络得到每个动作的概率和胜率v,把这些动作添加到树上,最后把胜率v回传(backed up),backed up给谁?
我们知道这其实是一路递归下去的过程,一直在Select,递归必须要有结束条件,不然就是死循环了。所以分出胜负和遇到叶子节点就是递归结束条件,把胜率v或者分出的胜平负value作为返回值,回传给上一层。
这个过程就是evaluate,是为了Backup步骤做准备。因为在Backup步骤,我们要用v来更新W和Q的,但是如果只做了一次Select,棋局还没有结束,此时的v是不明确的,必须要等到一盘棋完整的下完才能知道v到底是多少。就是说我现在下了一步棋,不管这步棋是好棋还是臭棋,只有下完整盘期分出胜负,才能给我下的这步棋评分。不管这步棋的得失,即使我这步棋丢了个车,但最后我赢了,那这个v就是积极的。同样即使我这步棋吃了对方一个子,但最后输棋了,也不能认为我这步棋就是好棋。
用一幅图概括一下这个过程:

当值被回传,就要做Backup了,这里很关键。因为我们是多线程同时在做MCTS,由于Select算法都一样,都是选择Q+U最大节点,所以很有可能所有的线程最终选择的是同一个节点,这就尴尬了。我们的目的是尽可能在树上搜索出各种不同的着法,最终选择一步好棋,怎么办呢?论文中已经给出了办法,“我们使用虚拟损失来确保每个线程评估不同的节点。”
就是说,通过Select选出某节点后,人为增大这个节点的访问次数N,并减少节点的总行动价值W,因为平均行动价值Q = W / N,这样分子减少,分母增加,就减少了Q值,这样递归进行的时候,此节点的Q+U不是最大,避免被选中,让其他的线程尝试选择别的节点进行树搜索。这个人为增加和减少的量就是虚拟损失virtual loss。
现在MCTS的过程越来越清晰了,Select选择节点,选择后,对当前节点使用虚拟损失,通过递归继续Select,直到分出胜负或Expand节点,得到返回值value。现在就可以使用value进行Backup了,但首先要还原W和N,之前N增加了虚拟损失,这次要减回去,之前减少了虚拟损失的W也要加回来。
然后开始做Backup,“边的统计数据在每一步t≤L中反向更新。访问计数递增, ,并且动作价值更新为平均值,
,并且动作价值更新为平均值, 。”,这些不用我再解释了吧?同时我们还要更新U,U的公式上面给出过。这个反向更新,其实就是递归的把值返回回去。有一点一定要注意,就是我们的返回值一定要符号反转,怎么理解?就是说对于当前节点是胜,那么对于上一个节点一定是负,明白这个意思了吧?所以返回的是-value。
。”,这些不用我再解释了吧?同时我们还要更新U,U的公式上面给出过。这个反向更新,其实就是递归的把值返回回去。有一点一定要注意,就是我们的返回值一定要符号反转,怎么理解?就是说对于当前节点是胜,那么对于上一个节点一定是负,明白这个意思了吧?所以返回的是-value。
d. play
按照上述过程执行a~c,论文中是每步棋执行1600次模拟,那就是1600次的a~c,这个MCTS的过程就是模拟自我对弈的过程。模拟结束后,基本上能覆盖大多数的棋局和着法,每步棋该怎么下,下完以后胜率是多少,得到什么样的局面都能在树上找到。然后从树上选择当前局面应该下哪一步棋,这就是步骤d.play:"在搜索结束时,AlphaGo Zero在根节点s0选择一个走子a,与其访问计数幂指数成正比, ,其中τ是控制探索水平的温度参数。在随后的时间步重新使用搜索树:与所走子的动作对应的子节点成为新的根节点;保留这个节点下面的子树所有的统计信息,而树的其余部分被丢弃。如果根节点的价值和最好的子节点价值低于阈值v_resign,则AlphaGo Zero会认输。"
,其中τ是控制探索水平的温度参数。在随后的时间步重新使用搜索树:与所走子的动作对应的子节点成为新的根节点;保留这个节点下面的子树所有的统计信息,而树的其余部分被丢弃。如果根节点的价值和最好的子节点价值低于阈值v_resign,则AlphaGo Zero会认输。"
当模拟结束后,对于当前局面(就是树的根节点)的所有子节点就是每一步对应的action节点,选择哪一个action呢?按照论文所说是通过访问计数N来确定的。这个好理解吧?实现上也容易,当前节点的所有节点是可以获得的,每个子节点的信息N都可以获得,然后从多个action中选一个,这其实是多分类问题。我们使用softmax来得到选择某个action的概率,传给softmax的是每个action的logits(N(s_0,a)^(1/τ)),这其实可以改成1/τ * log(N(s_0,a))。这样就得到了当前局面所有可选action的概率向量,最终选择概率最大的那个action作为要下的一步棋,并且将这个选择的节点作为树的根节点。
按照图1中a.Self-Play的说法就是,从局面st进行自我对弈的树搜索(模拟),得到a_t∼ π_t,a_t就是动作action,π_t就是所有动作的概率向量。最终在局面s_T的时候得到胜平负的结果z,就是我们上面所说的value。
至此MCTS算法就分析完了。
神经网络
上面说过,通过MCTS算出该下哪一步棋。然后接着再经过1600次模拟算出下一步棋,如此循环直到分出胜负,这样一整盘棋就下完了,这就是一次完整的自对弈过程,那么MCTS就相当于人在大脑中思考。我们把每步棋的局面s_T、算出的action概率向量π_t和胜率z_t(就是返回值value)保存下来,作为棋谱数据训练神经网络。
神经网络的输入是局面s,输出是预测的action概率向量p和胜率v,公式:![]() 。训练目标是最小化预测胜率v和自我对弈的胜率z之间的误差,并使神经网络走子概率p与搜索概率π的相似度最大化。按照论文中所说,“具体而言,参数θ通过梯度下降分别在均方误差和交叉熵损失之和上的损失函数l进行调整,
。训练目标是最小化预测胜率v和自我对弈的胜率z之间的误差,并使神经网络走子概率p与搜索概率π的相似度最大化。按照论文中所说,“具体而言,参数θ通过梯度下降分别在均方误差和交叉熵损失之和上的损失函数l进行调整,![]() ,其中c是控制L2权重正则化水平的参数(防止过拟合)。”简单点说就是让神经网络的预测跟MCTS的搜索结果尽量接近。
,其中c是控制L2权重正则化水平的参数(防止过拟合)。”简单点说就是让神经网络的预测跟MCTS的搜索结果尽量接近。
胜率是回归问题,优化自然用MSE损失,概率向量的优化要用softmax交叉熵损失,目标就是最小化这个联合损失。
神经网络结构
网络结构没什么好说的,按照论文中的描述实现即可,下面是结构图:
到此,这篇论文基本上介绍的差不多了,有些训练和优化方面的细节这里就不介绍了。过程就是神经网络先随机初始化权重,使用MCTS下每一步棋,当树中节点没有被展开时通过神经网络预测出走子概率和胜率添加到树上,然后使用自我对弈的数据训练神经网络,在下一次自我对弈中使用新的训练过的神经网络进行预测,MCTS和神经网络你中有我、我中有你,如此反复迭代,网络预测的更准确,MCTS的结果更强大。实际上神经网络的预测可以理解为人的直觉。
Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm
接下来一起看看AlphaZero的论文。
算法上没有区别,只有几个不同点:
- 1、在AlphaGo Zero中,自我对弈是由以前所有迭代中最好的玩家生成的。每次训练迭代之后,与最好玩家对弈测量新玩家的能力;如果以55%的优势获胜,那么它将取代最好的玩家,而自我对弈将由这个新玩家产生。相反,AlphaZero只维护一个不断更新的单个神经网络,而不是等待迭代完成。自我对弈是通过使用这个神经网络的最新参数生成的,省略了评估步骤和选择最佳玩家的过程。
- 2、比赛结果除了胜负以外,还有平局。
- 3、围棋是可以进行数据增强的,因为围棋的规则是旋转和反转不变的。但是象棋、将棋等就不行。
好像也没啥大变化,我们重点要考虑的是输入特征的表示。
输入特征的表示
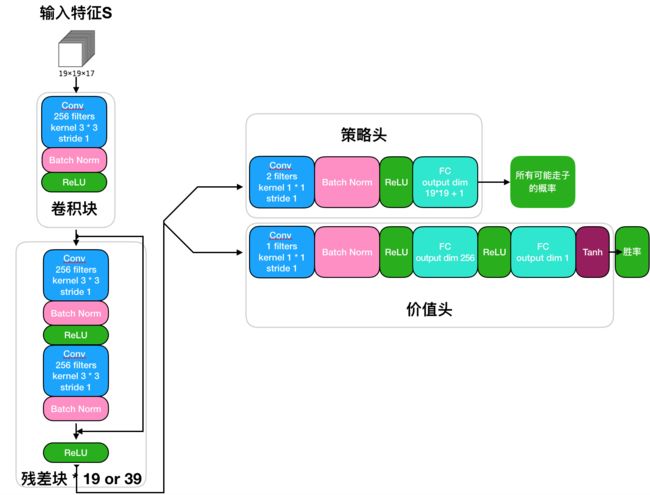
刚刚介绍神经网络的结构时,没有对输入特征进行说明,先看看论文中的图示。
网络结构图上能够看出神经网络的输入是19×19×17维度的图像栈。包含17个二值(只有两个值0和1)特征平面,8个特征平面X_t由二进制值组成,表示当前玩家存在的棋子(如果交点i在时间步t包含玩家颜色的棋子,那么X_t^i = 1;如果交叉点是空的,包含对手棋子,或者t <0,X_t^i = 0)。另外8个特征平面Y_t表示对手的棋子的相应特征。为什么每个玩家8个特征平面呢?是因为这是8步历史走子记录,就是说最近走的8步棋作为输入特征。最后的特征面C表示棋子颜色(当前的棋盘状态),是常量,如果是黑色棋子,则为1,如果是白色棋子则为0。这些平面连接在一起,给出输入特征![]() 。
。
国际象棋就不同了,加入了各种特征平面,用来表示不同的情况,王车易位啦,多少回合没有进展啦(没有吃子),重复的局面啦(多次重复会被判平局)等等,这些不是我想说的,这些特征可以根据不同的棋种自己去设计,我们重点关注的是棋子的特征。
对于围棋而言,每个棋子都是一样的,都是一类。而国际象棋分为6种棋子:车、马、象、后、王、兵,那在特征平面上怎么表示呢,总不能使用0~5吧。还是用0和1来表示棋盘上有子还是没子,然后既然是6类棋子,想当然的使用one-hot编码了,所以特征平面分成了6个平面,每一个平面用来表示不同种类棋子在棋盘上的位置。
以上就是介绍的全部了,更多的细节,比如优化参数设为多少、学习率退火设为多少等等请阅读论文。
中国象棋的实现
原理讲了一大堆,该上代码了,这里根据论文中的算法实现一个中国象棋程序。
完整代码请参见项目地址
输入特征的设计
先实现神经网络的部分,那么就要先设计输入特征。其实跟国际象棋差不多,棋子分为:车、马、炮、象、士、将、兵,共7种棋子,那就是每个玩家7个特征平面,一共14个特征平面。至于论文中其他的特征平面,比如颜色、回合数、重复局面、历史走子记录等等我没有实现,只使用了当前棋盘上每个玩家每个棋子的位置特征作为输入,一共14个平面,当然论文中说的其他特征平面您也可以实现一下试试。棋盘大小是9*10,所以输入占位符就是:
self.inputs_ = tf.placeholder(tf.float32, [None, 9, 10, 14], name='inputs')
接下来是定义输入的概率向量pi(π),需要确定向量的长度,意味着需要确定所有合法走子的集合长度。函数如下:
# 创建所有合法走子UCI,size 2086
def create_uci_labels():
labels_array = []
letters = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i']
numbers = ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9']
Advisor_labels = ['d7e8', 'e8d7', 'e8f9', 'f9e8', 'd0e1', 'e1d0', 'e1f2', 'f2e1',
'd2e1', 'e1d2', 'e1f0', 'f0e1', 'd9e8', 'e8d9', 'e8f7', 'f7e8']
Bishop_labels = ['a2c4', 'c4a2', 'c0e2', 'e2c0', 'e2g4', 'g4e2', 'g0i2', 'i2g0',
'a7c9', 'c9a7', 'c5e7', 'e7c5', 'e7g9', 'g9e7', 'g5i7', 'i7g5',
'a2c0', 'c0a2', 'c4e2', 'e2c4', 'e2g0', 'g0e2', 'g4i2', 'i2g4',
'a7c5', 'c5a7', 'c9e7', 'e7c9', 'e7g5', 'g5e7', 'g9i7', 'i7g9']
for l1 in range(9):
for n1 in range(10):
destinations = [(t, n1) for t in range(9)] + \
[(l1, t) for t in range(10)] + \
[(l1 + a, n1 + b) for (a, b) in
[(-2, -1), (-1, -2), (-2, 1), (1, -2), (2, -1), (-1, 2), (2, 1), (1, 2)]] # 马走日
for (l2, n2) in destinations:
if (l1, n1) != (l2, n2) and l2 in range(9) and n2 in range(10):
move = letters[l1] + numbers[n1] + letters[l2] + numbers[n2]
labels_array.append(move)
for p in Advisor_labels:
labels_array.append(p)
for p in Bishop_labels:
labels_array.append(p)
return labels_array长度一共是2086。关于UCCI的资料可以参考:中国象棋通用引擎协议 版本:3.0
概率向量pi的占位符定义:
self.pi_ = tf.placeholder(tf.float32, [None, 2086], name='pi')self.z_ = tf.placeholder(tf.float32, [None, 1], name='z')self.learning_rate = tf.placeholder(tf.float32, name='learning_rate')self.momentum = 0.9
optimizer = tf.train.MomentumOptimizer(learning_rate=self.learning_rate, momentum=self.momentum, use_nesterov=True) 这里需要特殊说明一下,我实现的是多GPU训练,关于多GPU训练神经网络的实现可以参考TensorFlow官方的例子,和TensorFlow多GPU并行计算实例---MNIST。
实现思想是把输入数据按照使用的gpu数量均分:
inputs_batches = tf.split(self.inputs_, self.num_gpus, axis=0)
pi_batches = tf.split(self.pi_, self.num_gpus, axis=0)
z_batches = tf.split(self.z_, self.num_gpus, axis=0)tower_grads = [None] * self.num_gpus
self.loss = 0
self.accuracy = 0
self.policy_head = []
self.value_head = []
with tf.variable_scope(tf.get_variable_scope()):
"""Build the core model within the graph."""
for i in range(self.num_gpus):
with tf.device('/gpu:%d' % i): # 不同的gpu分别使用不同的name scope
with tf.name_scope('TOWER_{}'.format(i)) as scope:
# 将上面均分的输入数据输入给各自的gpu进行运算
inputs_batch, pi_batch, z_batch = inputs_batches[i], pi_batches[i], z_batches[i]
# **划重点!运算图的构建一定要单独写在新的函数中,这样运行才不会出错,否则TensorFlow会提示不能重复使用变量。**
loss = self.tower_loss(inputs_batch, pi_batch, z_batch, i) # 构建神经网络计算图的函数,一会详细说。
# reuse variable happens here
tf.get_variable_scope().reuse_variables()
grad = optimizer.compute_gradients(loss)
tower_grads[i] = grad # 保存每一个gpu的梯度
self.loss /= self.num_gpus # loss是多个gpu的loss总和,所以要取平均
self.accuracy /= self.num_gpus # acc也是同理
grads = self.average_gradients(tower_grads) # 同理,对所有梯度取平均
self.train_op = optimizer.apply_gradients(grads, global_step=global_step)实现神经网络计算图
这里完全是按照论文所述的神经网络结构实现的,大家可以对照上面的结构图,是一一对应的。稍有不同的是,filters size我设为128,没有使用256。另外残差块的数量我默认使用了7层,没有使用19或者39,大家电脑给力的话可以尝试修改一下。
def tower_loss(self, inputs_batch, pi_batch, z_batch, i):
# 卷积块
with tf.variable_scope('init'):
layer = tf.layers.conv2d(inputs_batch, self.filters_size, 3, padding='SAME') # filters 128(or 256)
layer = tf.contrib.layers.batch_norm(layer, center=False, epsilon=1e-5, fused=True,
is_training=self.training, activation_fn=tf.nn.relu) # epsilon = 0.25
# 残差块
with tf.variable_scope("residual_block"):
for _ in range(self.res_block_nums):
layer = self.residual_block(layer)
# 策略头
with tf.variable_scope("policy_head"):
policy_head = tf.layers.conv2d(layer, 2, 1, padding='SAME')
policy_head = tf.contrib.layers.batch_norm(policy_head, center=False, epsilon=1e-5, fused=True,
is_training=self.training, activation_fn=tf.nn.relu)
# print(self.policy_head.shape) # (?, 9, 10, 2)
policy_head = tf.reshape(policy_head, [-1, 9 * 10 * 2])
policy_head = tf.contrib.layers.fully_connected(policy_head, self.prob_size, activation_fn=None)
self.policy_head.append(policy_head) # 保存多个gpu的策略头结果(走子概率向量)
# 价值头
with tf.variable_scope("value_head"):
value_head = tf.layers.conv2d(layer, 1, 1, padding='SAME')
value_head = tf.contrib.layers.batch_norm(value_head, center=False, epsilon=1e-5, fused=True,
is_training=self.training, activation_fn=tf.nn.relu)
# print(self.value_head.shape) # (?, 9, 10, 1)
value_head = tf.reshape(value_head, [-1, 9 * 10 * 1])
value_head = tf.contrib.layers.fully_connected(value_head, 256, activation_fn=tf.nn.relu)
value_head = tf.contrib.layers.fully_connected(value_head, 1, activation_fn=tf.nn.tanh)
self.value_head.append(value_head) # 保存多个gpu的价值头结果(胜率)
# 损失
with tf.variable_scope("loss"):
policy_loss = tf.nn.softmax_cross_entropy_with_logits(labels=pi_batch, logits=policy_head)
policy_loss = tf.reduce_mean(policy_loss)
# value_loss = tf.squared_difference(z_batch, value_head)
value_loss = tf.losses.mean_squared_error(labels=z_batch, predictions=value_head)
value_loss = tf.reduce_mean(value_loss)
tf.summary.scalar('mse_tower_{}'.format(i), value_loss)
regularizer = tf.contrib.layers.l2_regularizer(scale=self.c_l2)
regular_variables = tf.trainable_variables()
l2_loss = tf.contrib.layers.apply_regularization(regularizer, regular_variables)
# loss = value_loss - policy_loss + l2_loss
loss = value_loss + policy_loss + l2_loss # softmax交叉熵损失 + MSE + l2损失
self.loss += loss # 多个gpu的loss总和
tf.summary.scalar('loss_tower_{}'.format(i), loss)
with tf.variable_scope("accuracy"):
# Accuracy 这个准确率是预测概率向量和MCTS的概率向量的比较
correct_prediction = tf.equal(tf.argmax(policy_head, 1), tf.argmax(pi_batch, 1))
correct_prediction = tf.cast(correct_prediction, tf.float32)
accuracy = tf.reduce_mean(correct_prediction, name='accuracy')
self.accuracy += accuracy
tf.summary.scalar('move_accuracy_tower_{}'.format(i), accuracy)
return loss
def residual_block(self, in_layer):
orig = tf.identity(in_layer)
layer = tf.layers.conv2d(in_layer, self.filters_size, 3, padding='SAME') # filters 128(or 256)
layer = tf.contrib.layers.batch_norm(layer, center=False, epsilon=1e-5, fused=True,
is_training=self.training, activation_fn=tf.nn.relu)
layer = tf.layers.conv2d(layer, self.filters_size, 3, padding='SAME') # filters 128(or 256)
layer = tf.contrib.layers.batch_norm(layer, center=False, epsilon=1e-5, fused=True, is_training=self.training)
out = tf.nn.relu(tf.add(orig, layer))
return out训练网络
def train_step(self, positions, probs, winners, learning_rate):
feed_dict = {
self.inputs_: positions,
self.training: True,
self.learning_rate: learning_rate,
self.pi_: probs,
self.z_: winners
}
_, accuracy, loss, global_step, summary = self.sess.run([self.train_op, self.accuracy, self.loss, self.global_step, self.summaries_op], feed_dict=feed_dict)
self.train_writer.add_summary(summary, global_step)
return accuracy, loss, global_step使用神经网络预测
预测的代码稍微麻烦一些,因为我们自对弈训练时是多线程在跑的,传过来的输入数据可能并不能被gpu数量均分,比如我有2个gpu,但是传进来的输入size是3,这样的话就有一个gpu跑2个数据,一个gpu跑1个数据。可实际上这样代码是跑不起来的,会报错,我google了半天也没找到解决办法。
我的解决方案是,先看看输入数据的长度能否被gpu数量整除,如果能,那就一切正常,直接把输入传给网络就好,神经网络会将数据按照gpu数量均分。
一旦不能整除,那就把输入数据分成两部分,一部分是能被gpu数量整除的数据,一部分是余下的数据。比如我有2个gpu,输入数据的长度是5,那么把这5份数据分成4份和1份。4份数据的处理就是正常处理,直接把数据传给网络就好,神经网络会将数据按照gpu数量均分。
余下的那部分数据怎么处理呢?把余下的数据不断堆叠起来,直到数据能够被gpu数量均分为止。假如剩下1份数据,那就复制1份,变成2份相同的数据,这样正好被2个gpu数量均分。只不过这2个gpu处理后返回的数据,我们只要一个gpu的结果就行了,抛弃另外一个。
这段代码我只在aws的2个gpu的环境下跑过,更多的gpu就没试过了,也许有bug也不一定,您可以跑跑看:)
#@profile
def forward(self, positions): # , probs, winners
# print("positions.shape : ", positions.shape)
positions = np.array(positions)
batch_n = positions.shape[0] // self.num_gpus
alone = positions.shape[0] % self.num_gpus
if alone != 0: # 判断是否不能被gpu均分
if(positions.shape[0] != 1): # 如果不止1份数据。因为有可能输入数据的长度是1,这样肯定不能被多gpu均分了。
feed_dict = {
self.inputs_: positions[:positions.shape[0] - alone], # 先将能均分的这部分数据传入神经网络
self.training: False
}
action_probs, value = self.sess.run([self.policy_head, self.value_head], feed_dict=feed_dict)
action_probs, value = np.vstack(action_probs), np.vstack(value)
new_positions = positions[positions.shape[0] - alone:] # 取余下的这部分数据
pos_lst = []
while len(pos_lst) == 0 or (np.array(pos_lst).shape[0] * np.array(pos_lst).shape[1]) % self.num_gpus != 0:
pos_lst.append(new_positions) # 将余下的这部分数据堆叠起来,直到数量的长度能被gpu均分
if(len(pos_lst) != 0):
shape = np.array(pos_lst).shape
pos_lst = np.array(pos_lst).reshape([shape[0] * shape[1], 9, 10, 14])
# 将数据传入网络,得到不能被gpu均分的数据的计算结果
feed_dict = {
self.inputs_: pos_lst,
self.training: False
}
action_probs_2, value_2 = self.sess.run([self.policy_head, self.value_head], feed_dict=feed_dict)
# print("action_probs_2.shape : ", np.array(action_probs_2).shape)
# print("value_2.shape : ", np.array(value_2).shape)
action_probs_2, value_2 = action_probs_2[0], value_2[0]
# print("------------------------")
# print("action_probs_2.shape : ", np.array(action_probs_2).shape)
# print("value_2.shape : ", np.array(value_2).shape)
if(positions.shape[0] != 1): # 多个数据的计算结果
action_probs = np.concatenate((action_probs, action_probs_2),axis=0)
value = np.concatenate((value, value_2),axis=0)
# print("action_probs.shape : ", np.array(action_probs).shape)
# print("value.shape : ", np.array(value).shape)
return action_probs, value
else: # 只有1个数据的计算结果
return action_probs_2, value_2
else:
# 正常情况,能被gpu均分
feed_dict = {
self.inputs_: positions,
self.training: False
}
action_probs, value = self.sess.run([self.policy_head, self.value_head], feed_dict=feed_dict)
# print("np.vstack(action_probs) shape : ", np.vstack(action_probs).shape)
# print("np.vstack(value) shape : ", np.vstack(value).shape)
# 将多个gpu的计算结果堆叠起来返回
return np.vstack(action_probs), np.vstack(value)自对弈训练
自对弈训练的思想在上面分析论文时已经说过了,程序自己跟自己下棋,将每盘棋的数据保存起来,当数据量达到我们设置的大小时就开始训练神经网络。
def run(self):
batch_iter = 0
try:
while(True):
batch_iter += 1
play_data, episode_len = self.selfplay() # 自我对弈,返回下棋数据
print("batch i:{}, episode_len:{}".format(batch_iter, episode_len))
extend_data = []
for state, mcts_prob, winner in play_data:
states_data = self.mcts.state_to_positions(state)
extend_data.append((states_data, mcts_prob, winner)) # 将棋盘特征平面、MCTS算出的概率向量、胜率保存起来
self.data_buffer.extend(extend_data)
if len(self.data_buffer) > self.batch_size: # 保存的数据达到指定数量时
self.policy_update() # 开始训练
except KeyboardInterrupt:
self.log_file.close()
self.policy_value_netowrk.save(self.global_step)训练网络
def policy_update(self):
"""update the policy-value net"""
# 从数据中随机抽取一部分数据
mini_batch = random.sample(self.data_buffer, self.batch_size)
#print("training data_buffer len : ", len(self.data_buffer))
state_batch = [data[0] for data in mini_batch]
mcts_probs_batch = [data[1] for data in mini_batch]
winner_batch = [data[2] for data in mini_batch]
# print(np.array(winner_batch).shape)
# print(winner_batch)
winner_batch = np.expand_dims(winner_batch, 1)
# print(winner_batch.shape)
# print(winner_batch)
start_time = time.time()
old_probs, old_v = self.mcts.forward(state_batch) # 先通过正向传播预测下网络输出结果,用于计算训练后的KL散度
for i in range(self.epochs): # 一共训练5次
# 训练网络。敲黑板!这里的学习率需要特别注意。我在aws上用的是g2.2xlarge,24小时只能下差不多200盘棋,很慢。
# 所以学习率是在这里是动态调整的。当然您也可以使用指数衰减学习率,在上面定义学习率的地方就需要修改成类似下面这句:
# self.learning_rate = tf.maximum(tf.train.exponential_decay(0.001, self.global_step, 1e3, 0.66), 1e-5)
# 然后这里训练网络的地方学习率就不用作为参数传递了,也可以在训练网络函数里面不使用传递的学习率参数。
accuracy, loss, self.global_step = self.policy_value_netowrk.train_step(state_batch, mcts_probs_batch, winner_batch,
self.learning_rate * self.lr_multiplier) #
new_probs, new_v = self.mcts.forward(state_batch) #使用训练后的新网络预测结果,跟之前的结果计算KL散度
kl_tmp = old_probs * (np.log((old_probs + 1e-10) / (new_probs + 1e-10)))
# print("kl_tmp.shape", kl_tmp.shape)
kl_lst = []
for line in kl_tmp:
# print("line.shape", line.shape)
all_value = [x for x in line if str(x) != 'nan' and str(x)!= 'inf'] #除去inf值
kl_lst.append(np.sum(all_value))
kl = np.mean(kl_lst)
# kl = scipy.stats.entropy(old_probs, new_probs)
# kl = np.mean(np.sum(old_probs * (np.log(old_probs + 1e-10) - np.log(new_probs + 1e-10)), axis=1))
if kl > self.kl_targ * 4: # early stopping if D_KL diverges badly
break
self.policy_value_netowrk.save(self.global_step)
print("train using time {} s".format(time.time() - start_time))
# 通过计算调整学习率乘子
# adaptively adjust the learning rate
if kl > self.kl_targ * 2 and self.lr_multiplier > 0.1:
self.lr_multiplier /= 1.5
elif kl < self.kl_targ / 2 and self.lr_multiplier < 10:
self.lr_multiplier *= 1.5
explained_var_old = 1 - np.var(np.array(winner_batch) - old_v.flatten()) / np.var(np.array(winner_batch))
explained_var_new = 1 - np.var(np.array(winner_batch) - new_v.flatten()) / np.var(np.array(winner_batch))
print(
"kl:{:.5f},lr_multiplier:{:.3f},loss:{},accuracy:{},explained_var_old:{:.3f},explained_var_new:{:.3f}".format(
kl, self.lr_multiplier, loss, accuracy, explained_var_old, explained_var_new))
self.log_file.write("kl:{:.5f},lr_multiplier:{:.3f},loss:{},accuracy:{},explained_var_old:{:.3f},explained_var_new:{:.3f}".format(
kl, self.lr_multiplier, loss, accuracy, explained_var_old, explained_var_new) + '\n')
self.log_file.flush()自我对弈
自我对弈就是通过MCTS下每一步棋,直到分出胜负,并返回下棋数据。
def selfplay(self):
self.game_borad.reload() # 初始化棋盘
states, mcts_probs, current_players = [], [], []
z = None
game_over = False
winnner = ""
start_time = time.time()
while(not game_over): # 下棋循环,结束条件是分出胜负
action, probs, win_rate = self.get_action(self.game_borad.state, self.temperature) # 通过MCTS算出下哪一步棋
################################################
# 这部分代码是跟我的设计有关的。因为在输入特征平面中我没有使用颜色特征,
# 所以传给神经网络数据时,要把当前选手转换成红色(先手),转换的其实是棋盘的棋子位置
# 这样神经网络预测的始终是红色先手方向该如何下棋
state, palyer = self.mcts.try_flip(self.game_borad.state, self.game_borad.current_player, self.mcts.is_black_turn(self.game_borad.current_player))
states.append(state)
prob = np.zeros(labels_len)
# 神经网络返回的概率向量也需要转换,假如当前选手是黑色,转换成红色后,由于棋盘位置的变化,概率向量(走子集合)是基于红色棋盘的
# 要把走子action转换成黑色选手的方向才行。明白我的意思吧?
if self.mcts.is_black_turn(self.game_borad.current_player):
for idx in range(len(probs[0][0])):
act = "".join((str(9 - int(a)) if a.isdigit() else a) for a in probs[0][0][idx])
prob[label2i[act]] = probs[0][1][idx]
else:
for idx in range(len(probs[0][0])):
prob[label2i[probs[0][0][idx]]] = probs[0][1][idx]
mcts_probs.append(prob)
################################################
current_players.append(self.game_borad.current_player)
last_state = self.game_borad.state
self.game_borad.state = GameBoard.sim_do_action(action, self.game_borad.state) # 在棋盘上下算出的这步棋,得到新的棋盘状态
self.game_borad.round += 1 # 更新回合数
self.game_borad.current_player = "w" if self.game_borad.current_player == "b" else "b" # 切换当前选手
if is_kill_move(last_state, self.game_borad.state) == 0: # 刚刚下的棋是否吃子了
self.game_borad.restrict_round += 1 # 更新没有进展回合数
else:
self.game_borad.restrict_round = 0
if (self.game_borad.state.find('K') == -1 or self.game_borad.state.find('k') == -1):
# 条件满足说明将/帅被吃了,游戏结束
z = np.zeros(len(current_players))
if (self.game_borad.state.find('K') == -1):
winnner = "b"
if (self.game_borad.state.find('k') == -1):
winnner = "w"
z[np.array(current_players) == winnner] = 1.0
z[np.array(current_players) != winnner] = -1.0
game_over = True
print("Game end. Winner is player : ", winnner, " In {} steps".format(self.game_borad.round - 1))
elif self.game_borad.restrict_round >= 60: # 60回合没有进展(吃子),平局
z = np.zeros(len(current_players))
game_over = True
print("Game end. Tie in {} steps".format(self.game_borad.round - 1))
# 认输的部分没有实现
# elif(self.mcts.root.v < self.resign_threshold):
# pass
# elif(self.mcts.root.Q < self.resign_threshold):
# pass
if(game_over):
self.mcts.reload() # 游戏结束,重置棋盘
print("Using time {} s".format(time.time() - start_time))
return zip(states, mcts_probs, z), len(z) # 返回下棋数据MCTS实现
关键的代码来了,函数通过MCTS进行若干次模拟(论文是1600次,我用了1200次),然后根据子节点的访问量决定要下哪步棋。
#@profile
def get_action(self, state, temperature = 1e-3):
# MCTS主函数,模拟下棋
self.mcts.main(state, self.game_borad.current_player, self.game_borad.restrict_round, self.playout_counts)
# 取得当前局面下所有子节点的合法走子和相应的访问量。
# 这个所有子节点可能并不会覆盖所有合法的走子,这个是由树搜索的质量决定的,加大模拟次数会搜索更多不同的走法,
# 就是加大思考的深度,考虑更多的局面,避免出现有些特别重要的棋步却没有考虑到的情况。
actions_visits = [(act, nod.N) for act, nod in self.mcts.root.child.items()]
actions, visits = zip(*actions_visits)
probs = softmax(1.0 / temperature * np.log(visits)) #+ 1e-10
move_probs = []
move_probs.append([actions, probs])
if(self.exploration):
# 训练时,可以通过加入噪声来探索更多可能性的走子
act = np.random.choice(actions, p=0.75 * probs + 0.25*np.random.dirichlet(0.3*np.ones(len(probs))))
else:
act = np.random.choice(actions, p=probs) # 通过节点访问量的softmax选择最大可能性的走子
win_rate = self.mcts.Q(act) # 将节点的Q值当做胜率
self.mcts.update_tree(act) # 更新搜索树,将算出的这步棋的局面作为树的根节点来看看MCTS的类定义:
from collections import deque, defaultdict, namedtuple
QueueItem = namedtuple("QueueItem", "feature future")
c_PUCT = 5
virtual_loss = 3
cut_off_depth = 30
class MCTS_tree(object):
def __init__(self, in_state, in_forward, search_threads): # 参数search_threads我默认使用16个搜索线程
self.noise_eps = 0.25
self.dirichlet_alpha = 0.3 #0.03
# 根节点的先验概率加入了噪声
self.p_ = (1 - self.noise_eps) * 1 + self.noise_eps * np.random.dirichlet([self.dirichlet_alpha])
# 定义根节点,传入概率和局面(棋子位置)
self.root = leaf_node(None, self.p_, in_state)
self.c_puct = 5 #1.5
# 保存前向传播(预测)函数
self.forward = in_forward
self.node_lock = defaultdict(Lock)
# 虚拟损失
self.virtual_loss = 3
# 用来保存正在扩展的节点
self.now_expanding = set()
# 保存扩展过的节点
self.expanded = set()
self.cut_off_depth = 30
# self.QueueItem = namedtuple("QueueItem", "feature future")
self.sem = asyncio.Semaphore(search_threads)
# 保存搜索线程的队列
self.queue = Queue(search_threads)
self.loop = asyncio.get_event_loop()
self.running_simulation_num = 0叶子节点的类定义:
class leaf_node(object):
# 定义节点时,传入父节点,概率和棋盘状态(棋子位置)
def __init__(self, in_parent, in_prior_p, in_state):
self.P = in_prior_p # 保存概率,其他值默认是0
self.Q = 0
self.N = 0
self.v = 0
self.U = 0
self.W = 0
self.parent = in_parent # 保存父节点
self.child = {} # 子节点默认是空
self.state = in_state # 保存棋盘状态MCTS主函数,模拟下棋:
def is_expanded(self, key) -> bool:
"""Check expanded status"""
return key in self.expanded
#@profile
def main(self, state, current_player, restrict_round, playouts):
node = self.root
# 先通过神经网络扩展根节点
if not self.is_expanded(node): # and node.is_leaf() # node.state
# print('Expadning Root Node...')
positions = self.generate_inputs(node.state, current_player)
positions = np.expand_dims(positions, 0)
action_probs, value = self.forward(positions) # 通过神经网络预测走子概率
if self.is_black_turn(current_player): # 判断走子概率是否需要根据先手/后手进行转换
action_probs = cchess_main.flip_policy(action_probs)
# 取得当前局面所有合法的走子,有关中国象棋的算法就不在这里讨论了,感兴趣可以查看源代码
moves = GameBoard.get_legal_moves(node.state, current_player)
# print("current_player : ", current_player)
# print(moves)
node.expand(moves, action_probs) # 扩展节点
self.expanded.add(node) # 将当前节点加入到已扩展节点集合中
coroutine_list = []
for _ in range(playouts): # 模拟1200次,异步的方式执行,一共使用了16个线程
coroutine_list.append(self.tree_search(node, current_player, restrict_round))
coroutine_list.append(self.prediction_worker())
self.loop.run_until_complete(asyncio.gather(*coroutine_list))async def tree_search(self, node, current_player, restrict_round) -> float:
"""Independent MCTS, stands for one simulation"""
self.running_simulation_num += 1
# reduce parallel search number
with await self.sem: # 异步执行树搜索,共16个线程
value = await self.start_tree_search(node, current_player, restrict_round)
self.running_simulation_num -= 1
return value
# ***树搜索函数***
async def start_tree_search(self, node, current_player, restrict_round)->float:
"""Monte Carlo Tree search Select,Expand,Evauate,Backup"""
now_expanding = self.now_expanding
# 如果当前节点正在被扩展,就小睡一会
while node in now_expanding:
await asyncio.sleep(1e-4)
if not self.is_expanded(node): # 如果节点没有被扩展过,要扩展这个节点
"""is leaf node try evaluate and expand"""
# add leaf node to expanding list
self.now_expanding.add(node) # 加入到正在扩展集合中
positions = self.generate_inputs(node.state, current_player)
# 这里有个trick,就是并不是一个节点一个节点的使用神经网络预测结果,这样效率太低
# 而是放到队列中,通过prediction_worker函数统一管理队列,将队列中的一组(16个)输入传给神经网络,得到预测结果
# 这一切都是异步的
# push extracted dihedral features of leaf node to the evaluation queue
future = await self.push_queue(positions) # type: Future
await future
action_probs, value = future.result()
if self.is_black_turn(current_player): # 根据当前棋手的颜色决定是否对走子概率翻转
action_probs = cchess_main.flip_policy(action_probs)
moves = GameBoard.get_legal_moves(node.state, current_player)
# print("current_player : ", current_player)
# print(moves)
node.expand(moves, action_probs) # Expand操作,使用神经网络预测的结果扩展当前节点
self.expanded.add(node) #
# remove leaf node from expanding list
self.now_expanding.remove(node)
# must invert, because alternative layer has opposite objective
return value[0] * -1 # 返回神经网络预测的胜率,一定要取负,理由在论文分析时已经说过了
else: # 如果节点被扩展过,执行Select
"""node has already expanded. Enter select phase."""
# select child node with maximum action scroe
last_state = node.state
action, node = node.select_new(c_PUCT) # Select操作,根据Q+U最大选择节点
current_player = "w" if current_player == "b" else "b"
if is_kill_move(last_state, node.state) == 0:
restrict_round += 1
else:
restrict_round = 0
last_state = node.state
# 为选择的节点添加虚拟损失,防止其他线程继续探索这个节点,增加探索多样性
# add virtual loss
node.N += virtual_loss
node.W += -virtual_loss
# evolve game board status
# 判断这个节点状态下,是否分出胜负
if (node.state.find('K') == -1 or node.state.find('k') == -1):
# 分出胜负了,设置胜率1或者0
if (node.state.find('K') == -1):
value = 1.0 if current_player == "b" else -1.0
if (node.state.find('k') == -1):
value = -1.0 if current_player == "b" else 1.0
# 一定要符号取反
value = value * -1
elif restrict_round >= 60: # 60回合无进展(吃子),平局
value = 0.0
else:
# 没有分出胜负,在当前节点局面下继续树搜索
value = await self.start_tree_search(node, current_player, restrict_round) # next move
# 当前节点搜索完毕,去掉虚拟损失,恢复节点状态
node.N += -virtual_loss
node.W += virtual_loss
# on returning search path
# update: N, W, Q, U
node.back_up_value(value) # 执行节点的Backup操作,更新节点的各类数值
# must invert
return value * -1 # 一定要符号取反
# 管理队列数据,一旦队列中有数据,就统一传给神经网络,获得预测结果
async def prediction_worker(self):
"""For better performance, queueing prediction requests and predict together in this worker.
speed up about 45sec -> 15sec for example.
"""
q = self.queue
margin = 10 # avoid finishing before other searches starting.
while self.running_simulation_num > 0 or margin > 0:
if q.empty():
if margin > 0:
margin -= 1
await asyncio.sleep(1e-3)
continue
item_list = [q.get_nowait() for _ in range(q.qsize())] # type: list[QueueItem]
features = np.asarray([item.feature for item in item_list]) #
action_probs, value = self.forward(features)
for p, v, item in zip(action_probs, value, item_list):
item.future.set_result((p, v))
async def push_queue(self, features):
future = self.loop.create_future()
item = QueueItem(features, future)
await self.queue.put(item)
return future最后看看叶子节点的Select、Expand和Backup的实现。
# Select,选择Q+U最大的节点
def select_new(self, c_puct):
return max(self.child.items(), key=lambda node: node[1].get_Q_plus_U_new(c_puct))
# 返回节点的Q+U
def get_Q_plus_U_new(self, c_puct):
"""Calculate and return the value for this node: a combination of leaf evaluations, Q, and
this node's prior adjusted for its visit count, u
c_puct -- a number in (0, inf) controlling the relative impact of values, Q, and
prior probability, P, on this node's score.
"""
U = c_puct * self.P * np.sqrt(self.parent.N) / ( 1 + self.N)
return self.Q + U
# 参数是所有合法走子moves,和神经网络预测的概率向量action_probs
#@profile
def expand(self, moves, action_probs):
tot_p = 1e-8
action_probs = action_probs.flatten()
for action in moves:
# 模拟执行每一个合法走子,得到相应的局面(棋子位置)
in_state = GameBoard.sim_do_action(action, self.state)
# 从概率向量中得到当前走子对应的概率
mov_p = action_probs[label2i[action]]
# 创建新节点,传入父节点(因为是扩展当前节点,所以当前节点是新节点的父节点)、概率、棋盘状态
new_node = leaf_node(self, mov_p, in_state)
self.child[action] = new_node # 将新节点添加到当前节点的子节点集合中
tot_p += mov_p
for a, n in self.child.items():
n.P /= tot_p
# 更新节点的各项参数
def back_up_value(self, value):
self.N += 1 # 计数加一
self.W += value # 更新总行动价值
self.v = value
self.Q = self.W / self.N # 更新平均行动价值
self.U = c_PUCT * self.P * np.sqrt(self.parent.N) / ( 1 + self.N) # 更新U以上,就是自对弈训练神经网络的全部内容了,关于中国象棋的实现部分请看项目代码。
最后
我来说说训练情况,因为是从白板一块开始训练,刚开始都是乱下,从乱下的经验当中学会下棋是需要大量对弈才行的。解的空间是很稀疏的,相当于100个数据,有99个是负例,只有1个正例。论文中训练了700K次的mini-batch,国际象棋开源项目chess-alpha-zero也训练了10K次。我呢,训练不到4K次,模型刚刚学会用象和士防守,总之仍然下棋很烂。如果您有条件可以再多训练试试,我自从收到信用卡扣款400美元通知以后就把aws下线了:D 贫穷限制了我的想象力O(∩_∩)O
参考资料
深入浅出看懂AlphaGo元深入浅出看懂AlphaGo如何下棋- 围棋开源项目
AlphaGOZero-python-tensorflow TensorFlow多GPU并行计算实例---MNIST- 国际象棋开源项目
chess-alpha-zero FEN文件格式着法表示中国象棋通用引擎协议 版本:3.0- 五子棋开源项目
AlphaZero_Gomoku - 黑白棋开源项目
reversi-alpha-zero - 中国象棋开源项目
IntelliChess - 中国象棋UI项目
ChineseChess