【Elasticsearch】模仿淘宝,将搜索框的业务逻辑抽象成DSL语句
目标
仅提供一个搜索API,就能兼容前端的各种查询需求
环境
- ElasticSearch 5.6.8
- kibana 5.6.8
需求
- 界面根据用户点击,拼接用户的查询需求
input:
{
1. 匹配查询:
keywords: 商品名 , 不传入默认值为"烤箱 家用小烤箱"
2. 过滤查询(布尔查询):
匹配
category: 商品分类
brand: 品牌
范围
price: 价格
规格查询
屏幕尺寸:5寸
3. 分页查询
4. 分组查询
}
- 后台接收搜索参数,拼接成DSL。
需求的拆分与实现
【1】搜索框检索 - 匹配查询
匹配查询 match-query 官方文档
【1】 业务逻辑
![]()
用户进入商品搜索页面后,默认进行一次查询。
- 设定默认搜索词可以避免触发大量数据涌入前端
- 默认搜索词可以根据以后业务升级成动态数据,比如广告业务
【1】 DSL
GET /_search
{
"query": {
"match" : {
"name" : "华为"
}
},
"from": 0, // 分页查询 "from" 代表 page - 1
"size": 40 // 分页查询,每页显示数据量
}
【2】分类项显示 - 聚合查询 - 词条查询
聚合查询-词条查询 aggs-terms 官方文档
【2】业务逻辑

- “搜索”被点击后会显示所有分类的一个表
【2】DSL
GET /_search
{
"query": {
"match" : {
"name" : "烤箱 家用小烤箱"
}
},
"aggs": {
"skuCategoryGroup": { // skuCategoryGroup 表示自定义组名
"terms": {
"field": "categoryName",
"size": 500
}
}
}
}
【2】值得注意
值得注意的是,聚合查询的结果会放在ES response里的,层级结构要关系,这个关乎java代码的编写

【3】单击分类进行过滤 - 过滤查询 - 布尔查询
布尔查询,不同的版本有差异,这里选用后置布尔查询
- 2.x版本的
post_filter,跟query,aggs是同级的,用java代码拼接起来可以解耦 post_filter嵌套bool布尔查询,语义合适
Elasticsearch 中文指南 post_filter 后置过滤查询
bool 布尔查询 官方文档
综上,这个业务用了ES 2.x的语法post_filter,加上服务器版本5.6.8的ES文档中的bool布尔查询。
PS: 语法上的组合使用,先去kibana验证可行性才能继续往后开发
【3】业务逻辑
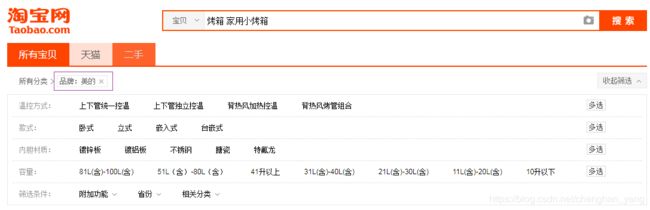
- 点击“美的”品牌,只在匹配查询的结果集中取"美的"品牌
【3】DSL
"post_filter": {
"bool": {
"filter": [ // must 、filter 、should 、must_not。 filter 区别于must: 不做搜索排名处理(打分算法)
{
"term": {
"brandName": {
"value": "美的"
}
}
}
]
}
}
【4】单击规格进行过滤 - 在【3】的实现下加入规格的参数
【4】业务逻辑
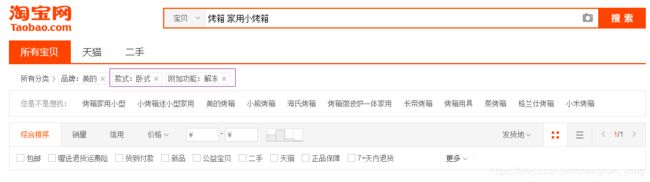
【4】获得并显示规格参数
规格参数是在match_query 的基础上使用后置过滤器post_filter筛选的,跟品牌的思路是一致的,但是会遇到以下问题:
- 商品规格有多个,品牌对应只有一个,问题:商品表,规格表,两张表的数据,如何把规格在一次DSL中抓取出来
- 品牌的传参,问题:点击"卧式", DSL告诉ES要搜{“款式” : “卧式”},建立一个字段叫"卧式",显然不合理
解决思路:
- 反三范式设计,商品表冗余规格的字段spec,用json存起来
| skuid | name | brand(品牌) | spec(规格) | spec_template(对应规格的模板) |
|---|---|---|---|---|
| 1 | 美的家用烤箱 可解冻 | 美的 | {“款式”:“卧式”,“附加功能”:“解冻”} | 厨具 |
主要目的 :减少表连接,并且把规格名和规格内容的关系也保留的起来
- java程序处理spec(规格)字段的数据
把spec的字段全部放进set集合里面做第一轮去重 ——》 规格字段都是独一无二的,可以使用ES的aggs去重
{“款式”:“卧式”,“附加功能”:“解冻”}
{“款式”:“卧式”,“附加功能”:“定时”}
{“款式”:“立式”,“附加功能”:“解冻”}
第二轮去重,key去重,并设定key对应的取值,粒度太小,适合把第一轮去重的结果交给java代码去重
“款式” : "卧式 立式"
"附加功能" : “解冻 定时”
至此,界面就可以显示这样的筛选添加了
新的问题:{"款式" : "卧式"} ,前端这么传字符串,后端不可能写死一个key 为 “款式”的解析代码。
- 解决思路1:后端维护一个字典把诸如
“款式”、“附加功能”作为产品参数的解析规则。 - 解决思路2:前端加个
spec_前缀或者导入数据时加个spec_前缀,后端解析成本小
这里使用思路二。
新的问题:{“附加功能”:“定时”} 的语义是在附加功能中,使用关键词:定时,不分词得查询
这里引用一个实践
// 把spec 字段转换成一个map
for (SkuInfo skuInfo : skuInfos) {
String spec = skuInfo.getSpec();
Map map = JSON.parseObject(spec, Map.class);
skuInfo.setSpecMap(map);
}
//存进ES的时候,map的数据类型如何映射为ES的Field
skuEsMapper.saveAll(skuInfos);
使用kibana能查询到对应的文档字段被映射为
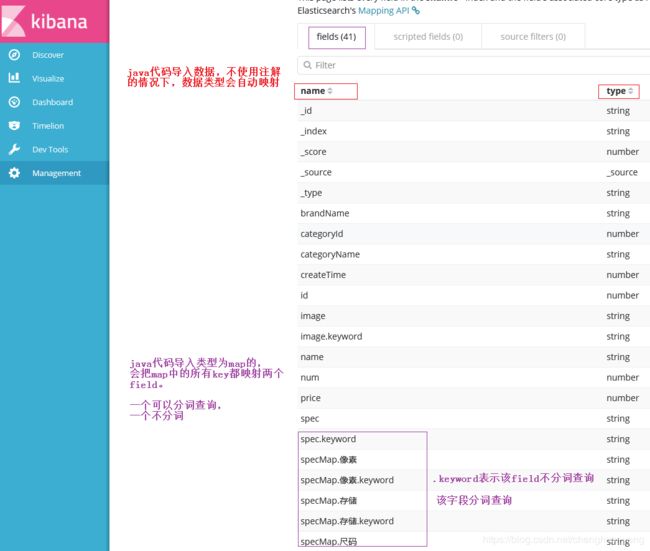
【4】DSL
把规格参数的查询,加入bool布尔查询的代码块中
"post_filter": {
"bool": {
"filter": [ // must 、filter 、should 、must_not。 filter 区别于must: 不做搜索排名处理(打分算法)
{
"term": {
"brandName": {
"value": "美的"
}
}
},
{
"term": {
"specMap.款式.keyword": {
"value": "卧式"
}
}
},
]
}
}
【5】整体DSL语句
{
"from": 0, // 分页
"size": 40,
"query": {
"match": {
"name": "烤箱 家用小烤箱"
}
},
"post_filter": {
"bool": {
"filter": [
{
"term": {
"brandName": { // 品牌筛选
"value": "美的"
}
}
},
{
"range": { // 价格区间
"price": {
"from": "0",
"to": "500",
"include_lower": true,
"include_upper": true
}
}
},
{
"term": { // 参数筛选
"specMap.款式.keyword": {
"value": "卧式"
}
}
}
]
}
},
"aggregations": {
"skuCategoryGroup": {
"terms": {
"field": "categoryName",
"size": 500
}
},
"skuBrandGroup": { // 品牌分组查询,用于显示
"terms": {
"field": "brandName",
"size": 5000
}
},
"skuSpecGroup": { // Spec第一轮去重,DSL过滤即可
"terms": {
"field": "spec.keyword",
"size": 500000
}
}
},
"highlight": { // 关键词高亮配置
"pre_tags": [
""":red">"""
],
"post_tags": [
""
],
"fields": {
"name": {}
}
}
}
SpringBoot 操作 ElasticSerach
版本由起步依赖决定,直接导入pom即可
org.springframework.boot
spring-boot-starter-data-elasticsearch
application.yml文件配置一下
spring:
data:
elasticsearch:
cluster-name: es
cluster-nodes: 127.0.0.1:9300
将DSL做成动态拼接的,使用ElasticSerachTemplate即可。