序
消息类场景是表格存储(Tablestore)主推的方向之一,因其数据存储结构在消息类数据存储上具有天然优势。为了方便用户基于Tablestore为消息类场景建模,Tablestore封装Timeline模型,旨在让用户更快捷的实现消息类场景需求。在推出Timeline(v1、v2两个版本)模型以来,受到了大量用户关注。伴随模型推广与输出,Tablestore陆续发布了一系列专题文章,重点讨论介绍了IM场景的架构设计、模型概念以及Feed 流系统架构的设计方案,相信给很多用户提供了场景实现新思路。文章列表见《表格存储权威指南》。
但依然会有用户困惑,“框架、结构、模型等概念介绍了这么多,该如何基于Timeline模型,实现具体场景呢?”。
本文就是为了让用户更快速的上手,带用户基于Timeline2.0 模型,详细讲解如何实现一个简易的IM系统。并开源了相应的实现代码。源码链接
相关系列文章见:《现代IM系统中的消息系统架构 - 架构篇》、《现代IM系统中的消息系统架构 - 模型篇》
梗概
生活中最常见的即时聊天类软件如:钉钉、微信等,都可以描述为:实现了即时通讯能力的聊天工具。其中聊天会话可分为两大类,分别是:单聊、群聊(公众号类似单聊)。这里我们以钉钉(Ding Talk)的功能为参照,详细说明相应的功能基于Tablestore的Timeline模型如何实现。如:新消息提醒,未读消息数统计,查看会话中更久的聊天内容,群名模糊检索,关键字查询历史记录,以及多客户端同步等。让用户在实现方案上有更清晰的认识,对模型的抽象概念、接口有更好的理解。
下面会按照聊天系统的功能模块分段,分别介绍每一部分的功能、方案介绍、表设计以及实现代码等。功能模块主要分为:消息存储、关系维护、即时感知、多端同步。
功能模块
消息存储
消息系统中,消息存储是最基本的功能。对于消息存储(提供消息的读、写、持久化),一方面需要持久化写入,保证消息数据的不丢失,另一方面,适合用户的快速、高效查询。在IM场景中,写入方式通常是单行、批量写入,而读取需要按照消息队列范围读取。有时用户还有对于历史消息的模糊查询需求,这时就需要使用多维检索、全文检索的能力。
消息的存储都是基于Timeline模型,具体模型见文章《Tablestore发布Timeline 2.0模型》。样例中,消息数据的表结构见下图:
表设计:im_timeline_store_table
存储库
功能:会话窗口消息展示
存储库是聊天会话消息所对应的存储表,消息以会话分类存储,每个会话是一个消息队列。单个消息队列(TimelineQueue)通过timelineId唯一标识,所有消息基于sequenceId有序排列。消息体中含有发送人、消息id(消息去重)、消息发送时间、消息体内容、消息类型(类型包含图片、文件、普通文本,本文仅适用文本)等。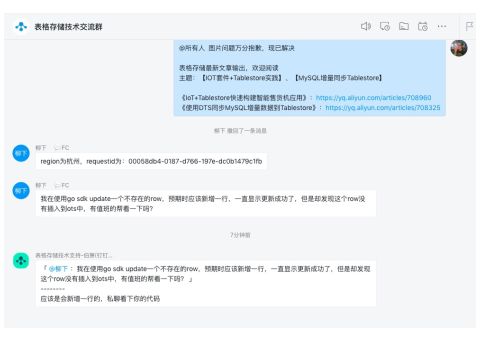
如上图,当用户点击某一个会话时,窗口会展示相应会话的最新一页消息。图片里的消息都是从存储库拉取的,通过timelineId获取该会话的Queue实例,然后调用Queue的scan接口与ScanParam参数(sequenceId范围+倒序)拉取最新的一页消息。当用户向上滚动,展示完这一页消息后,客户端会基于第一次请求的最小sequencId发起第二次请求,获取第二页消息记录,单页消息数通常选择20-30条。会话的消息可以选择在客户端持久化,然后在感知到新消息之后更新本地消息,增加缓存减少网络IO。
核心代码
public List fetchConversationMessage(String timelineId, long sequenceId) {
TimelineStore store = timelineV2.getTimelineStoreTableInstance();
TimelineIdentifier identifier = new TimelineIdentifier.Builder()
.addField("timeline_id", timelineId)
.build();
ScanParameter parameter = new ScanParameter()
.scanBackward(sequenceId)
.maxCount(30);
Iterator iterator = store.createTimelineQueue(identifier).scan(parameter);
List appMessages = new LinkedList();
while (iterator.hasNext() && counter++ <= 30) {
TimelineEntry timelineEntry = iterator.next();
AppMessage appMessage = new AppMessage(timelineId, timelineEntry);
appMessages.add(appMessage);
}
return appMessages;
} 
存储库的消息需要永久保存,是整个应用的全量消息存储。存储库数据过期时间(TTL)需要设为-1。
功能:多维组合、全文检索
全文检索能力就是对存储库的消息内容做模糊查询,因而需要对存储库的数据建立多元索引。具体索引字段,需要根据设计需求设计。如钉钉公开群的检索,需要对群ID、消息发送人、消息类型、消息内容、以及时间建立索引,其中消息内容需要使用分词字符串类型,从而提供模糊查询的能力。

核心代码
public List fetchConversationMessage(String timelineId, long sequenceId) {
TimelineStore store = timelineV2.getTimelineStoreTableInstance();
TimelineIdentifier identifier = new TimelineIdentifier.Builder()
.addField("timeline_id", timelineId)
.build();
ScanParameter parameter = new ScanParameter()
.scanBackward(sequenceId)
.maxCount(30);
Iterator iterator = store.createTimelineQueue(identifier).scan(parameter);
List appMessages = new LinkedList();
int counter = 0;
while (iterator.hasNext() && counter++ <= 30) {
TimelineEntry timelineEntry = iterator.next();
AppMessage appMessage = new AppMessage(timelineId, timelineEntry);
appMessages.add(appMessage);
}
return appMessages;
} 
另外,为了做消息的权限管理,仅允许用户检索自己有权限查看的消息,可在消息体字段中扩展接收人ID数组,这样对所有群做检索时,需要增加接收人字段为自己的用户ID这一必要条件,即可实现消息内容的权限限制。 样例中没有实现这一功能,用户可根据需求自己增加、修改。
同步库
功能:新消息即时统计
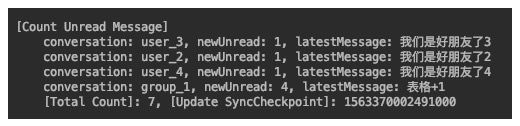
当客户端在线时,应用的系统服务会维护客户端的长连接,因而可以感知客户端在线。当用户的同步库有新消息写入时(即有新消息),应用会发出信号通知客户端有新消息,然后客户端会基于同步库checkpoint点,拉取同步库中该sequenceId之后的所有新消息,统计各会话的新消息数,并更新checkpoint点。
如上图,对于一个在线客户端,每个会话都会维护一个未读消息的计数(小红点),也会有一个总未读数的计数,这个数量一般会存储在客户端本地,或者通过redis持久化。这些未读消息,指的就是通过同步库拉取并统计过,但是还未被用户点开的消息数量。在拉取到新消息列表后,客户端(或应用层)会遍历所有新消息,然后将新消息所对应会话的未读计数累加1,这样实现了未读消息的即时感知与更新。只有当用户点开会话后,会话的未读计数才会清零。
在更新未读数的同时,会话列表中还会有最新消息的简短摘要信息以及最新消息的发送时间等。这些可以在遍历新消息列表时不断更新。这些统计、摘要都是依托同步库,而非存储库实现的。
核心代码
public List fetchSyncMessage(String userId, long lastSequenceId) {
TimelineStore sync = timelineV2.getTimelineSyncTableInstance();
TimelineIdentifier identifier = new TimelineIdentifier.Builder()
.addField("timeline_id", userId)
.build();
ScanParameter parameter = new ScanParameter()
.scanForward(lastSequenceId)
.maxCount(30);
Iterator iterator = sync.createTimelineQueue(identifier).scan(parameter);
List appMessages = new LinkedList();
int counter = 0;
while (iterator.hasNext() && counter++ <= 30) {
AppMessage appMessage = new AppMessage(userId, iterator.next());
appMessages.add(appMessage);
}
return appMessages;
} 在统计到会话列表中不存在的会话时,客户端会做一次额外请求。通过timelineID获取会话的基本描述信息,如群头像或好友的头像、群名称等,并初始化未读数计时器0,然后累加新消息数、更新最新消息摘要等。
同步库对于IM场景下的新消息即时感知统计这一核心功能,就是通过写入冗余的方式,提升新消息读取统计的效率与速度。对于IM场景没有收件箱的概念,因而同步库中冗余消息并没有永久保存的价值,提供7天过期时间已经足够保证功能正常。用户可以根据自身需求,调整同步库的数据过期时间(TTL)。
功能:异步写扩散
在本文的样例中,单聊会话的消息在写完存储库后同时写入了同步库,只有两行的写入开销很小。但是对于群会话,写完存储库后要获取群用户列表,然后依次写入相应用户的同步库。这种方式在群少、用户少时不会有问题,但随着用户体量、活跃度的增加,同步的写的方式就会面临性能问题,因此建议用户对群写扩散使用异步任务实现。
用户可以基于表格存储实现一个任务队列,将写扩散任务写入队列中后直接返回,然后由其他进程保证任务队列的执行。任务队列保存了群ID、消息的完整信息,消费进程不断轮询读取新任务,获取任务后,才会从群关系表中获取完整的群成员列表,并做相应的写扩散。
任务队列可以直接基于Tablestore实现,表设计为两列主键,第一列为topic,第二列为自增列,一个topic对应一个队列,任务会被有序写入单个队列中。当并发量持续膨胀后,可对任务做hash分桶,随机写入多个topic。这样可以增加消费者数量(消费并发量),提升写扩散效率。对应任务队列消费,用户只需要维护每个topic的checkpoint点。checkpoint点之前的为已完成任务,通过getRange的方式顺序获取checkpoint点之后未执行的新任务,保证任务的执行。失败的任务可以重新写入任务队列来提升容错,并增加重试计数。出现多次失败后放弃重写,然后将该任务写入特殊的问题队列,方便应用的开发者们查询、定位问题。
元数据管理
所谓元数据,就是描述数据的数据。在这里主要体现为两类:用户元数据、会话元数据。这里群的元数据信息:群ID(复用群的timelineId)、群名称、创建时间等信息,可以直接基于timelineMeta的管理表完成实现,所有Group类型的TimelineMeta可以映射为一个Group。但是用户的元数据却不能复用TimelineMeta,所以需要单独的表实现。
用户元数据
即用户的属性信息,通过用户ID识别特定用户。在上面提到的用户关系中,通过用户的标识ID确认用户身份,但用户的属性信息,如:性别、签名、头像等信息,还是需要单独维护。因此需要单独维护。
表设计:im_user_table
用户元数据以user_id为标识,与同步库中的timeline_id一一对应。用户同步新消息时,只会拉取同步库中自己对应的单个消息队列(TimelineQueue)。因此,为了唯一ID的方便管理,我们可以选择user_id与用户同步库的timeline_id使用同一个值。这样一来,在消息写扩散时,只需知道群内用户的user_id列表回好友user_id,即可以完成写扩算。
功能:用户检索
对于用户,添加好友的需求有很多种,这里我们只需要维护用户表,并且创建多元索引,即可轻松实现。样例中没有实现,用户可以根据自己需求配置不同的索引字段设置,这里我们仅简单分析一下需求:
- 通过用户ID:主键查询;
- 二维码(含用户ID信息):主键查询;
- 用户姓名:多元索引,用户名字段设置分词字符串;
- 用户标签:多元索引,数组字符串索引提供签检索、嵌套索引提供多标签打分检索排序;
- 附近的人:多元索引,GEO索引查询附近、特定地理围栏的人;
详细的多元索引功能,用户可参看官网文档:多元索引
会话元数据
即会话的属性信息,通过唯一会话ID识别特定会话,属性信息会包含:会话类别(群、单聊、公众号等)、群名称、公告、创建时间等。同时,通过群名称模糊查找群,也会是会话元数需要的重要能力。
在Timeline模型中,提供了Timeline Meta的管理能力,只需通过相应的接口便可实现会话meta的管理。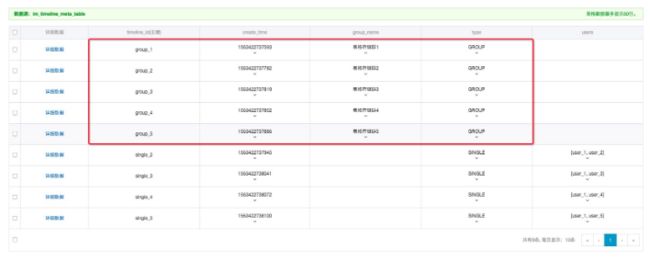
存储库中管理的是会话的消息队列(TimelineQueue),这里与会话元数据中的行一一对应。客户端用户选中特定会话后,应用从相应的消息队列倒序批量拉取消息展示到客户端,群聊单聊的使用方式一样,因而并不做会话类型的区分。
功能:群检索
用户如果有加入群的需求,首先需要查询到特定的群。查询群的方式与用户查询方式类似,功能也可以做相同的实现。用户可以根据自己需求定制不同的索引字段设置,需求实现方式如下:
- 群ID:主键查询;
- 二维码(含用户ID信息):主键查询;
- 群名:多元索引,用户名字段设置分词字符串;
- 群标签:多元索引,数组字符串索引提供签检索、嵌套索引提供多标签打分检索排序;
注:会话元数据可以直接维护单聊会话与人的映射关系。对于单聊的meta增加一列users字段,存放两个用户ID,这样不用额外维护关系表(基于单聊关系表im_user_relation_table创建timeline_id为第一列主键的二级索引)。
关系维护
完成了元数据管理以及用户和群的检索,剩下的就是如何添加好友、加入群聊了。这里就涉及到IM体统中另一个重要的功能点。关系维护包含:人与人的关系、人与群的关系以及人与会话的。下面我们介绍如何基于Tablestore解决这一关系维护的需求。
单聊关系
功能:人与单聊会话的关系
单聊场景下,参与者仅有两个人,同时不考虑顺序。无论是我联系小明或是小明联系我,对应的会话必须有且仅有一个。如果使用表格存储维护这个关系,建议用如下的设计方式。
第一列为主用户ID、第二列为次用户ID,在两个人成为好友后,关系表中需要插入两行数据,分别以自己的用户ID为main_user,以好友的用户ID为sub_user,然后将共同的会话timline_id作为属性列,并且可以维护相互之间不同的昵称、显示。
表设计:im_user_relation_table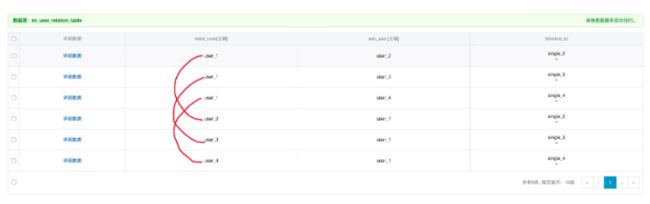
基于该单聊关系表,还可以建立多元索引,方便用户好友列表的获取,同时支持加好友时间排序、昵称排序等功能。如果考虑到延时、费用等因素,即时使用多元索引,直接通过getRange接口也可以快速拉、高效的获取自己所有好友列表,实现好友关系的维护与查询。
功能:人与人的关系
借助以上表,人与人的关系可以很简单实现,比如我判断我与小明的好友关系,直接通过单行查询知道我们的好友关系是否存在,如果存在就不会展示加好友按钮。而如果非好友,这是完成好友添加后,写入两行不同主键顺序行,并生成一个唯一的timelineId即可。这个设计的好处在于用户可以直接通过自己的ID与好友的ID快速获取会话信息。只要用户在写入两行时做好一致性维护。
如果好友关系一旦解除,可以直接拼出关系表中两行主键对用户关系,通过做物理删除(删除行)或逻辑删除(属性列状态修改)结束两两个人的好友关系即可;
核心代码
public void establishFriendship(String userA, String userB, String timelineId) {
PrimaryKey primaryKeyA = PrimaryKeyBuilder.createPrimaryKeyBuilder()
.addPrimaryKeyColumn("main_user", PrimaryKeyValue.fromString(userA))
.addPrimaryKeyColumn("sub_user", PrimaryKeyValue.fromString(userB))
.build();
RowPutChange rowPutChangeA = new RowPutChange(userRelationTable, primaryKeyA);
rowPutChangeA.addColumn("timeline_id", ColumnValue.fromString(timelineId));
PrimaryKey primaryKeyB = PrimaryKeyBuilder.createPrimaryKeyBuilder()
.addPrimaryKeyColumn("main_user", PrimaryKeyValue.fromString(userB))
.addPrimaryKeyColumn("sub_user", PrimaryKeyValue.fromString(userA))
.build();
RowPutChange rowPutChangeB = new RowPutChange(userRelationTable, primaryKeyB);
rowPutChangeB.addColumn("timeline_id", ColumnValue.fromString(timelineId));
BatchWriteRowRequest request = new BatchWriteRowRequest();
request.addRowChange(rowPutChangeA);
request.addRowChange(rowPutChangeB);
syncClient.batchWriteRow(request);
}
public void breakupFriendship(String userA, String userB) {
PrimaryKey primaryKeyA = PrimaryKeyBuilder.createPrimaryKeyBuilder()
.addPrimaryKeyColumn("main_user", PrimaryKeyValue.fromString(userA))
.addPrimaryKeyColumn("sub_user", PrimaryKeyValue.fromString(userB))
.build();
RowDeleteChange rowPutChangeA = new RowDeleteChange(userRelationTable, primaryKeyA);
PrimaryKey primaryKeyB = PrimaryKeyBuilder.createPrimaryKeyBuilder()
.addPrimaryKeyColumn("main_user", PrimaryKeyValue.fromString(userB))
.addPrimaryKeyColumn("sub_user", PrimaryKeyValue.fromString(userA))
.build();
RowDeleteChange rowPutChangeB = new RowDeleteChange(userRelationTable, primaryKeyB);
BatchWriteRowRequest request = new BatchWriteRowRequest();
request.addRowChange(rowPutChangeA);
request.addRowChange(rowPutChangeB);
syncClient.batchWriteRow(request);
}
群聊关系
功能:群聊会话与人的关系
群聊时,主要的查询需求还是获取当前群内用户的列表。一方面方便群属性的展示,另一方面为应用做写扩散提供快速获取收件人列表的查询。因而在表设计上,我们会建议用户使用两列主键:第一列为群ID,第二列为用户ID。通过这样的设计,可以直接给予getRange接口拉取群所有用户的信息。
群聊关系表解决了群到用户的映射关系,但我们还需要用户到群的映射关系。如果为了查询用户所在群的列表而新键一张表,冗余成本、一致性维护成本就很高。这里可以使用两种索引来解决反向的映射关系。样例中,我们使用了二级索引,将用户ID字段作为索引主键,从而可以直接基于索引查询单用户的群列表。同步实时性更好,成本更低。
当然用户也可以使用多元索引:对群、用户、入群时间做索引,可以查询到某用户的所有在群列表,并且基于入群时间排序。
表设计:im_group_relation_table
基于群关系表,可以直接基于关系主表通过getRange的方式获取单个群内所有的用户。在做写扩散时,可以直接获取群内用户ID列表,提升写扩散的效率。同时,也方便展示群内用户列表。
核心代码
public List listMySingleConversations(String userId) {
PrimaryKey start = PrimaryKeyBuilder.createPrimaryKeyBuilder()
.addPrimaryKeyColumn("main_user", PrimaryKeyValue.fromString(userId))
.addPrimaryKeyColumn("sub_user", PrimaryKeyValue.INF_MIN)
.build();
PrimaryKey end = PrimaryKeyBuilder.createPrimaryKeyBuilder()
.addPrimaryKeyColumn("main_user", PrimaryKeyValue.fromString(userId))
.addPrimaryKeyColumn("sub_user", PrimaryKeyValue.INF_MAX)
.build();
RangeRowQueryCriteria criteria = new RangeRowQueryCriteria(userRelationTable);
criteria.setInclusiveStartPrimaryKey(start);
criteria.setExclusiveEndPrimaryKey(end);
criteria.setMaxVersions(1);
criteria.setLimit(100);
criteria.setDirection(Direction.FORWARD);
criteria.addColumnsToGet(new String[] {"timeline_id"});
GetRangeRequest request = new GetRangeRequest(criteria);
GetRangeResponse response = syncClient.getRange(request);
List singleConversations = new ArrayList(response.getRows().size());
for (Row row : response.getRows()) {
String timelineId = row.getColumn("timeline_id").get(0).getValue().asString();
String subUserId = row.getPrimaryKey().getPrimaryKeyColumn("sub_user").getValue().asString();
User friend = describeUser(subUserId);
Conversation conversation = new Conversation(timelineId, friend);
singleConversations.add(conversation);
}
return singleConversations;
} 
功能:人与群聊会话的关系
获取单用户所有加入群列表,可以基于主表创建二级索引,将用户字段设为索引的第一列主键。索引的数据结构见下图。这样基于二级索引,可以直接通过getRange的方式获取单用户加入的群的TimlineId列表。
二级索引:im_group_relation_global_index
核心代码
public List listMyGroupConversations(String userId) {
PrimaryKey start = PrimaryKeyBuilder.createPrimaryKeyBuilder()
.addPrimaryKeyColumn("user_id", PrimaryKeyValue.fromString(userId))
.addPrimaryKeyColumn("group_id", PrimaryKeyValue.INF_MIN)
.build();
PrimaryKey end = PrimaryKeyBuilder.createPrimaryKeyBuilder()
.addPrimaryKeyColumn("user_id", PrimaryKeyValue.fromString(userId))
.addPrimaryKeyColumn("group_id", PrimaryKeyValue.INF_MAX)
.build();
RangeRowQueryCriteria criteria = new RangeRowQueryCriteria(groupRelationGlobalIndex);
criteria.setInclusiveStartPrimaryKey(start);
criteria.setExclusiveEndPrimaryKey(end);
criteria.setMaxVersions(1);
criteria.setLimit(100);
criteria.setDirection(Direction.FORWARD);
criteria.addColumnsToGet(new String[] {"group_id"});
GetRangeRequest request = new GetRangeRequest(criteria);
GetRangeResponse response = syncClient.getRange(request);
List groupConversations = new ArrayList(response.getRows().size());
for (Row row : response.getRows()) {
String timelineId = row.getPrimaryKey().getPrimaryKeyColumn("group_id").getValue().asString();
Group group = describeGroup(timelineId);
Conversation conversation = new Conversation(timelineId, group);
groupConversations.add(conversation);
}
return groupConversations;
} 
即时感知
让客户端即时感知消息的实现方案,可以参考《Feed 流设计总纲》一文中会话池的维护方式,这里作简要描述,不会在样例中实现。
会话池方案
即时感知新消息正是IM(Instant Message)场景下核心所在。让客户端及时感知到新信息的到来,然后客户端接收到通知后才会从同步库中拉取更新的消息,让用户更快速、更及时地提醒用户阅读新消息。可是,接受者如何才能快速感知到自己有了新消息呢?
让在线的客户端周期性的刷新拉取?这样的方式毫无疑问可以满足需求,但伴随而来的是大量无效的网络资源浪费。同时应用的压力也会随着用户量的不断增长变得更沉重。而当白天大量非活跃用户在线时,压力更为明显。面对这一问题,应用通常会维护一个推送会话池。会话池记录了在线客户端与用户信息,当在线用户有新的消息写入,通过推送池获取该用户的会话,然后通知客户端拉取同步库新消息。这样同步消息的压力只会随着真实消息量而增长,避免了大量不必要的同步库查询请求。
实现会话推送池的方案很多,可以使用内存型数据库,也可以直接使用表格存储,同时保证会话推送池的持久化。
在即时感知上,最直观的就是会话表中变动的未读消息数统计了。统计新消息的实现方式上,已在本文的【消息存储 > 第二类:同步库 > 新消息即时统计】部分做了详尽描述,不理解的可返回去重新看一下。持久化未读消息数是很必要的,否则在更换设备或重新登录后。未读消息数被清零,将会忽略很多新消息提醒,这是我们不能接受的。
其他
多端同步
实现了以上功能,IM系统的基本需求已经完成。但实现多端数据同步上,还有两个注意事项。
其一,我们对于单客户端情况下,用户同步库做了一个checkpoint点的持久化,对应的概念是:“已读最新消息的sequenceId”。此时,checkpoint点无客户端的区分,如果使用本地做持久化,多端同步时就会出现问题,不同客户端统计的未读消息数就会不一致。这是需要通过应用服务端维护checkpoint点,同时会话的未读消息数也需要在应用服务侧维护,这样才能保证多端统计数一致。同时,当有未读消息的会话被点击,会话未读数清0时,要让服务有感知,然后通知到其他在线端,维护实时一致性。
其二,多端情况下,自己在一个客户端发送了新消息,其他客户端在没有其他新消息时,是无法感知并刷新自己的发送消息,这在多端同步中也是要解决的小问题。这时,简单的解决方案就是将自己发送的消息,也写入自己的同步库。只要再统计未读信息时,对自己的信息不计数,但在最新消息摘要中需要做更新。这样,多端同步问题很容易实现。
添加好友、入群申请
添加好友或入群,不是主动发起请求就会直接完成的,这里需要主动方申请后,审核方完成统一才会真实完成。因而只有在审核方才会有权限发起关系的创建。
那如何让被添加用户或群主感知到申请?当然是借助同步库,作为一种新的消息类型或者特殊的会话,让用户即时感知到新申请,尽早完成审批。申请列表如果需要持久化,也可单独建表维护,只要保证用户新申请的即时感知即可。
样例实操
本位为了与用户一起梳理IM系统应用的功能点,基于Tablestore实现的样例简单功能,完整的样例代码已完成开源,代码地址:源码链接。用户可以结合文章、代码一起阅读。代码在本地运行,使用前请确保:
- 开通服务、创建实例
- 获取AK
- 设置样例配置文件
- 实例支持二级索引(需要主动申请);
样例配置
在home目录下创建tablestoreCong.json文件,填写相应参数如下:
# mac 或 linux系统下:/home/userhome/tablestoreCong.json
# windows系统下: C:\Documents and Settings\%用户名%\tablestoreCong.json
{
"endpoint": "http://instanceName.cn-hangzhou.ots.aliyuncs.com",
"accessId": "***********",
"accessKey": "***********************",
"instanceName": "instanceName"
}endpoint:实例的接入地址,控制台实例详情页获取;
accessId:AK的ID,获取AK链接提供;
accessKey:AK的密码,获取AK链接提供;
instanceName:使用的实例名;
样例入口
样例中共有三个入口,用户需要根据先后顺序执行,使用后及时释放资源,避免不必要的费用浪费;
| 入口 | 入口类名 | 功能 |
|---|---|---|
| 初始化 | InitChartRoomExample | 创建所有需要的表,同时根据配置创建相应的多元索引与二级索引 |
| 模拟调用 | ClientRequestExample | 应用的接口使用,样例未做前后端联调调用,用户可通过接口返回数据的打印了解使用方式。 |
| 释放资源 | ReleaseChartRoomExample | 释放所有资源,先释放索引后删表 |
项目结构

专家服务
表格存储有一批精通Timeline领域的技术专家,在打造IM、Feed流场景方面有着独到的见解。更多文章欢迎前往《表格存储Tablestore权威指南》。如果您:
- 渴望寻觅Timeline领域高手过招;
- 调研Timeline场景解决方案;
- 准备入门Timeline场景;
- 对表格存储(Tablestore)产品感兴趣;
原文链接
本文为云栖社区原创内容,未经允许不得转载。