一、总线种类
IDE总线(并行):理论值133Mbps(兆位)
SATA(1、2、3)借口(串行ATA):理论值分别是是300Mbps、600Mbps、6Gbps
USB (串行)3.0:理论值是4480Mbps
SCSI(small Computer SYstem Interface):小型计算机借口 【传输速度比较快】 (并行总结) 【Ultra SCSI 320Mbps】
SCSI:8 ,7target(目标); 16,15target(目标)
SAS:(串行口的SCSI)串行附加存储
二、SCSI与SAS比较:
|
|
端口
|
体积
|
容量
|
转速
|
|
SCSI
|
并行
|
大
|
大
|
块
|
|
SAS
|
串行
|
小
|
小
|
慢
|
三、RAID由来
对于非常繁忙的服务器来说如果有很多用户同时下载东西,而且并行下载,下载的还都不一样,这意味着什么?这意味着每秒钟传输的数据块量将会非常非常大的,那它的硬盘将会疯狂的再转,仍然满足不了需求?这又是为什么呢?因为我们整个存储设备的速度太慢了。这我们该如何办呢?这时我们应该找一个更快的有着更大的I/O设备,但是我们发现一个文件再强也不可能有那么强的功能。如果我们将多个设备组合起来并行工作是不是快了不少呀!这时就出现了将多个设备连起来来完成一个任务。
这时又出现了一种接口。例如,在主板上加了一个更强大 的控制器,而特殊的是这个控制器不是连接硬盘的而是连接一个设备 ,而这个设备有特殊接口,它能够将一个接口一分为多个接口,而每一个接口都可以接一个SATA盘或SCSI盘,我们可以将多个SATA盘接到多个SATA口上去,用几个控制器当做一个设备向计算机输出。这里的主板看来就是一个主机,是一块盘,因为就一个接口,A控制口就和B的控制芯片通信,这个控制芯片本身在内部把它分解成了多个盘,这里主机是看不到这多个设备的,这时的控制器就是特殊的控制器了。就是我们今天要说的RAID控制器。如图
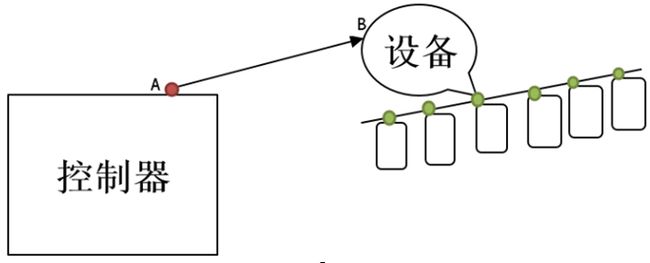
在早期只有IDE和SCSI硬盘时,硬盘还很小,而且容易损坏,性能很差,怎么办?在当时用的最多的是SLED(single largely on large)单个的非常大的很昂贵的磁盘,由于太贵了小机构是用不起的,但是这种硬盘速度比较快,存储能力也比较强,但是买不起,这个就比较麻烦,总要想办法来解决的,在1987年的美国加州大学伯克利分校的几个人发表了一篇论文,A Case for Redundant Arrays of Inexpensive Disks(RAID)廉价冗余磁盘阵列,就是用某种特殊方式将这几块磁盘组合起来,能够起到有比较大的空间,而且速度比较快,跟SLED比较起来比较便宜,当时有很多人看到这篇论文,都想尝试去实现这种应用,当他们实现之后发现要想设备达到很好的性能控制器芯片和外围的硬件设备,总体的价格和SLED的价格差不多了,这时候就重命名称作独立冗余磁盘阵列,出现了条带化。
四、RAID命令和软RAID的操作
RAID:独立冗余磁盘阵列
组合方式:
SATA
SAS
逻辑RIAD:
/dev/md#:后面的数字 例如: /dev/md0
/dev/md1
md:(multi disks)多磁盘或多设备
lsmod列出模块
mdadm:将任何块设备做成RAID【用户空间工具,管理工具】
创建软RAID
模式化的命令:
1、创建模式
-C
专用选项:
-l:级别
-n:设备个数
-a{yes|no}:自动为其创建设备文件.回答yes
-c:数据块大小,(2^n),默认为64k
-x #:指定空闲盘个数
①例如:创建一个2G的RIAD0,我们可以用4个512MB的分区,也可以用2个1G的分区【注意:两块盘大小要一样】。
mdadm –C /dev/md0 –a yes –l 0 –n 2 /dev/sda{5,6}
创建设备/dev下的md0,自动创建设备文件的,然后设置级别为0,一共两个设备,设备是/dev下的sda5和sda6.如图

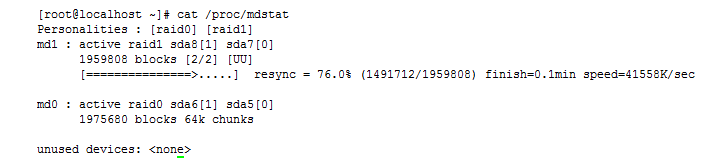
这时候我们可以用cat /proc/mdstat如图:

用cat /proc/mdstat可以查看查看当前系统上所有处于启用状态RAID设备。看图正在启用raid0。md0是raid0级别的设备,有两个设备sda6和sda5,chunk大小为64k。
②例如:创建一个2G的RIAD1,也可以用2个2G的分区【注意:两块盘大小要一样】(不过这里尽量建立三个分区,有一个留给下边演示如果前面两个有一个坏了,用于替补)
mdadm –C /dev/md1 –a yes –l 1 –n 2 /dev/sda{7,8}
创建设备/dev下的md1,自动创建设备文件的,然后设置级别为1,一共两个设备,设备是/dev下的sda7和sda8.如图
![]()
用cat /proc/mdstat查看可以看出raid1和raid0其它信息还是差不多相同的,但是多了一段信息,那个信息表示镜像磁盘要将每一个信息位都要对应起来,修改了任何一个磁盘的内容,另一个磁盘的同意位置内容也会修改。这两个磁盘要镜像成一模一样,所以它们要同步进行,同步完成后,这个磁盘就为可用状态了。
我们再用fdisk -l 查看当前系统上识别几块硬盘。但是我们主要不是看这个主要是让你们看一下raid1的大小是不是2G如图:
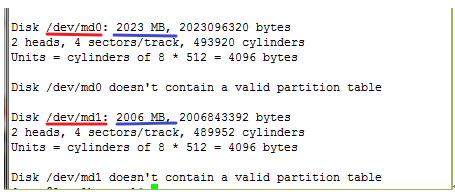
上面红线可用看到是md0的两个1G组成的大小是2G,而下面红线划的md1的两个2G组成的大小也是2G。(蓝线划的是各自大小)
2、管理模式
--add,--remove,--fail|-f
模拟损坏
mdadm /dev/md# --fail /dev/sda8表示把/dev/md#阵列中的/dev/sda8模拟给损坏了。如图

查看是不是已经给损坏了。
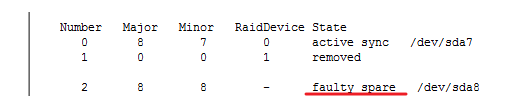
红线划的就是我们模拟后的结果。这个已经损坏了,我们是不是可以把它给移除了。这是们用
mdadm /dev/md1 –r /dev/sda8将其移除。如图
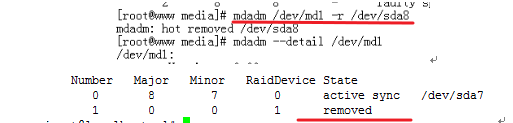
我们发现图上就剩一块盘了,显示removde,已经移除了。这是我们发现RAID1已经成了瘸腿状态了,我们这时候应该用提前的那个/dev/sda9来顶替被移除的/dev/sda8。如图:

从图中可以看出,我们已经成功了。我们可以cat /proc/mdstat一下。发现同sda7与sda8同步传输数据一样的同步传输数据。等数据完全传输完成后这时候如果把sda7给损坏,sda9上的数据也是正常的(不给于演示步骤同上类似)。
3、监控模式
-F :监控模式
-D| --detail:查看RAID阵列的详细信息
例如:mdadm -D /dev/md1 我们可以查看md1的相关信息的。
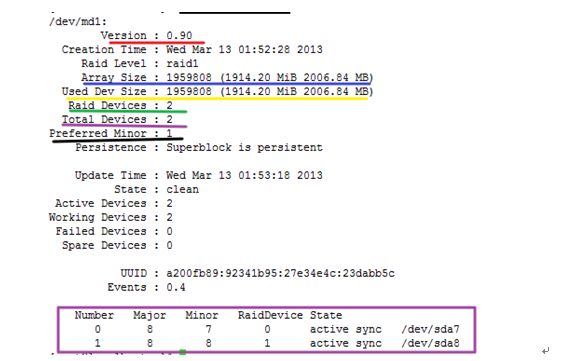
红色划的显示版本信息的,蓝色显示阵列大小,×××显示所有设备大小,绿色显示一共有多少设备,紫色显示一共有多少设备,黑色显示优先使用哪个设备,而且下面紫色方框里说明了,是一个镜像有两个设备,都处于正常使用当中。
4、增长模式
-G
5、装配模式
-A
停止阵列:
mdadm -S /dev/md1
--stop
我们先 cat /proc/mdstat查看一下如图:

蓝色线划的就是md1、md2阵列。这时候我们用mdadm –S /dev/md1停止md1的阵列。我们再查看一下如图:

蓝色方框中就是答案,只剩下md0阵列了。
watch:周期性的执行指定命令,并以全屏方式显示结果
-n #:指定周期长度,单位为秒,默认为2
格式:watch -n # 'COMMAND(命令)'
Mdadm –D –scan :
显示当前主机上每一个RAID设备了,以及每个RAID关联到设备本身,这个设备的UUID号。【我们可以把这个将当前RAID信息保存在/etc/mdadm.conf下以后再重新装设备的时候就不用在指设备了自动读取这个配置文件并装配的】
mdadm -D --scan > /etc/mdadm.conf
六、RAID级别
RAID level::级别,仅代表磁盘组织方式不同,没有上下之分。(使用这几种方式不仅要考虑速度,也要考虑设备的可用性)
级别:
|
|
性能提升
|
冗余能力
|
空间利用率
|
需要的磁盘数
|
|
0条带技术
|
读、写
|
无
|
ns
|
至少2块
|
|
1表示镜像
|
写能力下降读能力提升
|
有
|
1/2
|
至少2块
|
|
5:(轮流为校验盘)
|
读、写能力提升
|
有
|
(n-1)/n
|
至少三块
|
|
10先镜像后条带技术
|
读写提升
|
有
|
1/2
|
至少4块
|
|
01先条带后镜像技术
|
读写提升
|
有
|
1/2
|
至少4块
|
|
50
|
读写提升
|
有
|
(n-2)/n
|
至少6块
|
|
jbod
|
无提升
|
无
|
100%
|
至少2块
|
磁盘镜像:用镜像的技术保留数据可用性。
校验码:如果是四块盘,就用前三块盘。而第四块是备份.(浪费空间的n分之一,可允许一块盘出错,不允许多块盘出错)
图像:
1、RAID0

2、RAID1
3、RAID5
4、RAID10
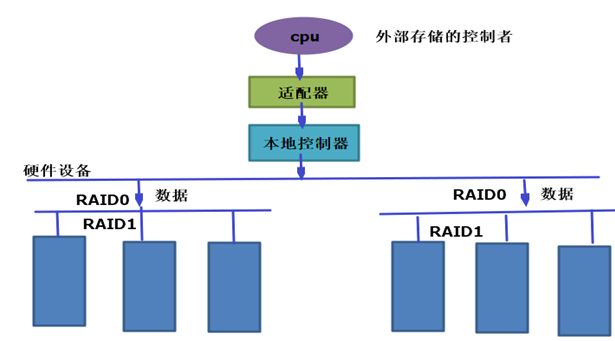
5、RAID01

6、RAID50
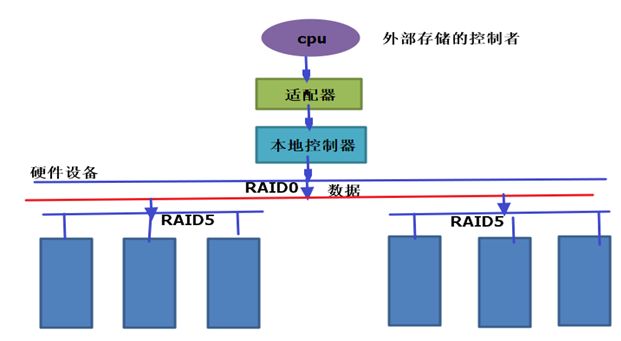
7、jbod
